Table des matières[Cacher][Montrer]
Nous vivons une époque passionnante, avec des annonces sur les technologies de pointe chaque semaine. OpenAI vient de publier le modèle de pointe de synthèse texte-image DALLE 2.
Seules quelques personnes ont eu un accès précoce à un nouveau système d'IA capable de générer des graphiques réalistes à partir de descriptions en langage naturel. Il est toujours fermé au public.
Stability AI a ensuite publié le Diffusion stable model, une variante open-source de DALLE2. Ce lancement a tout changé. Partout sur Internet, les gens publiaient des résultats rapides et étaient surpris par l'art réaliste.
Qu'est-ce que la diffusion stable ?
Diffusion stable est un modèle d'apprentissage automatique capable de créer des images à partir de texte, de modifier des images en fonction du texte et de remplir des détails sur des images à faible résolution ou peu détaillées.
Il a été formé sur des milliards de photos et peut fournir des résultats équivalents à DALL-E2 ainsi que le À mi-parcours. IA de stabilité l'a inventé, et il a été rendu public le 22 août 2022.
Mais avec des ressources de calcul locales limitées, le modèle de diffusion stable prend beaucoup de temps pour créer des images de haute qualité. L'exécution du modèle en ligne à l'aide d'un fournisseur de cloud nous fournit des ressources de calcul presque infinies et nous permet d'obtenir d'excellents résultats beaucoup plus rapidement.
L'hébergement du modèle en tant que microservice permet également à d'autres applications créatives d'exploiter plus facilement le potentiel du modèle sans avoir à gérer les complexités de l'exécution de modèles ML en ligne.
Dans cet article, nous tenterons de démontrer comment développer un modèle de diffusion stable et le déployer sur AWS.
Construire et déployer une diffusion stable
BentoML et Amazon Web Services EC2 sont deux options pour héberger le modèle Stable Diffusion en ligne. BentoML est un framework open source pour la mise à l'échelle machine learning prestations de service. Avec BentoML, nous allons créer un service de dispersion fiable et le déployer sur AWS EC2.
Préparation de l'environnement et téléchargement du modèle de diffusion stable
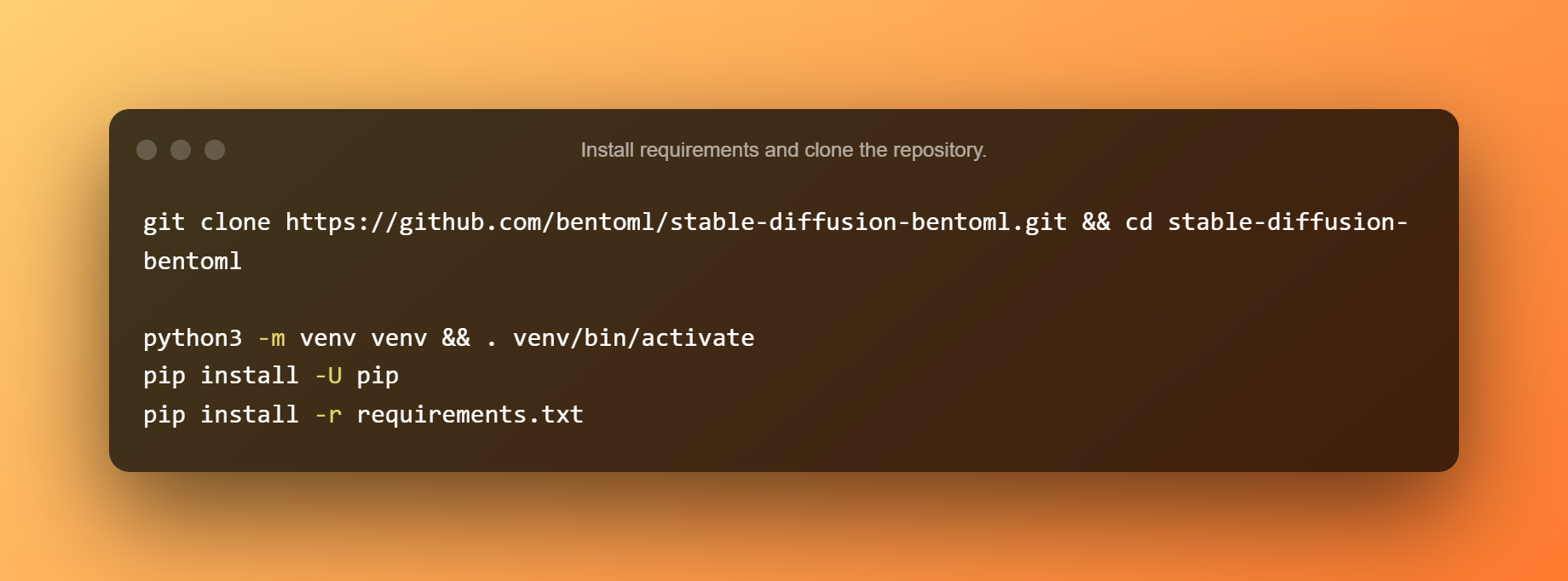
Installez les exigences et clonez le référentiel.
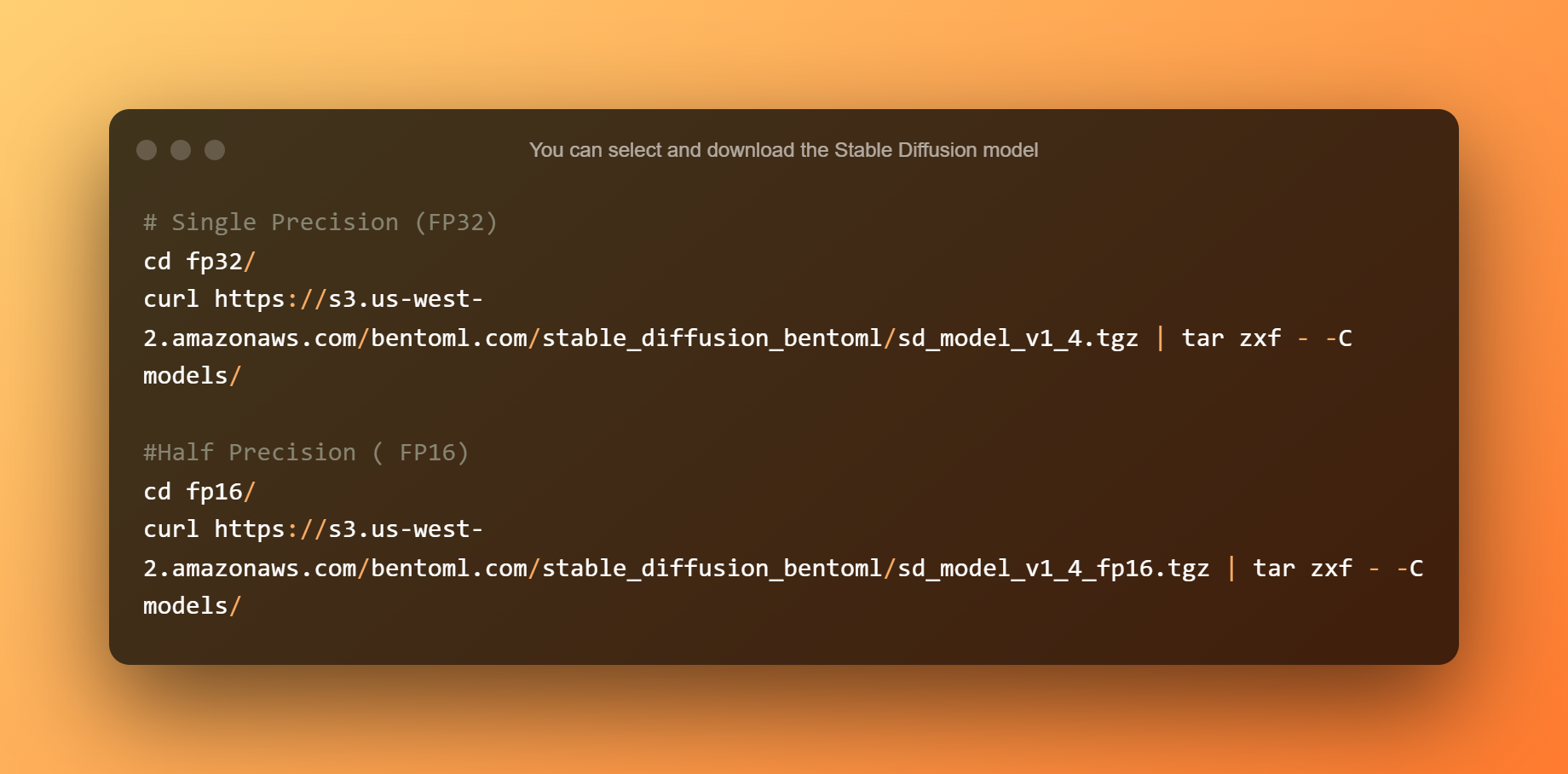
Vous pouvez sélectionner et télécharger le modèle Stable Diffusion. La simple précision convient aux CPU ou aux GPU avec plus de 10 Go de VRAM. La demi-précision est idéale pour les GPU avec moins de 10 Go de VRAM.
Construire une diffusion stable
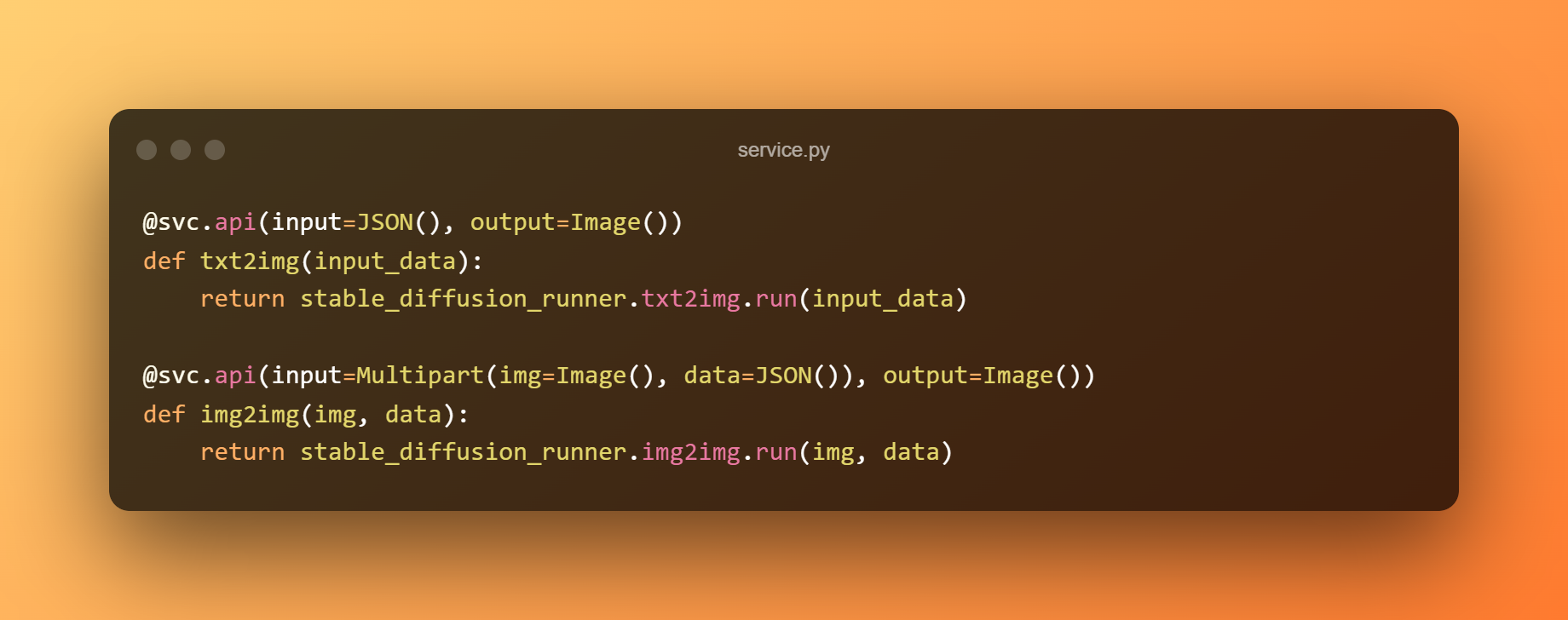
Nous allons créer un service BentoML pour servir le modèle derrière un API RESTful. L'exemple suivant utilise le modèle simple précision pour la prédiction et le module service.py pour connecter le service à la logique métier. Nous pouvons exposer les fonctions en tant qu'API en les marquant avec @svc.api.
De plus, nous pouvons définir les types d'entrée et de sortie des API dans les paramètres. Le point de terminaison txt2img, par exemple, reçoit une entrée JSON et produit une sortie Image, tandis que le point de terminaison img2img accepte une image et une entrée JSON et renvoie une sortie Image.
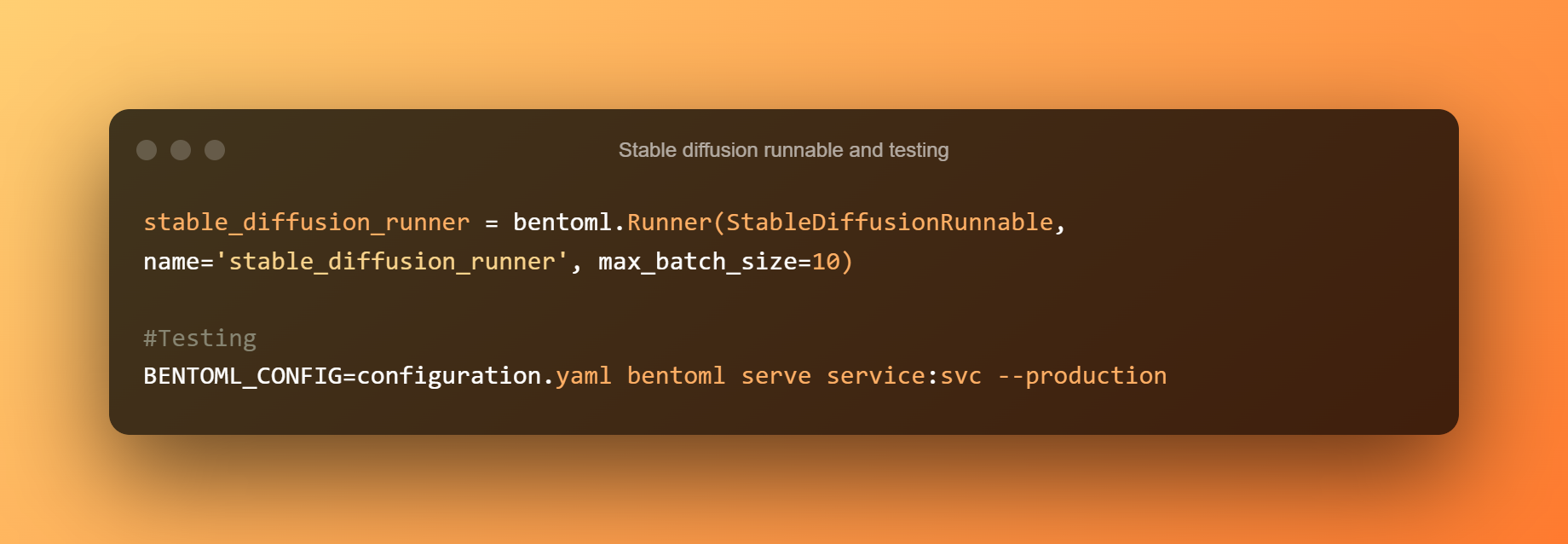
Un StableDiffusionRunnable définit la logique d'inférence essentielle. L'exécutable est chargé d'exécuter les méthodes de pipe txt2img du modèle et d'envoyer les entrées pertinentes. Pour exécuter la logique d'inférence de modèle dans les API, un Runner personnalisé est construit à partir de StableDiffusionRunnable.
Utilisez ensuite la commande suivante pour démarrer un service BentoML à des fins de test. Exécution locale du Modèle de diffusion stable l'inférence sur les processeurs est plutôt lente. Chaque demande prendra environ 5 minutes à traiter.
Texte à l'image
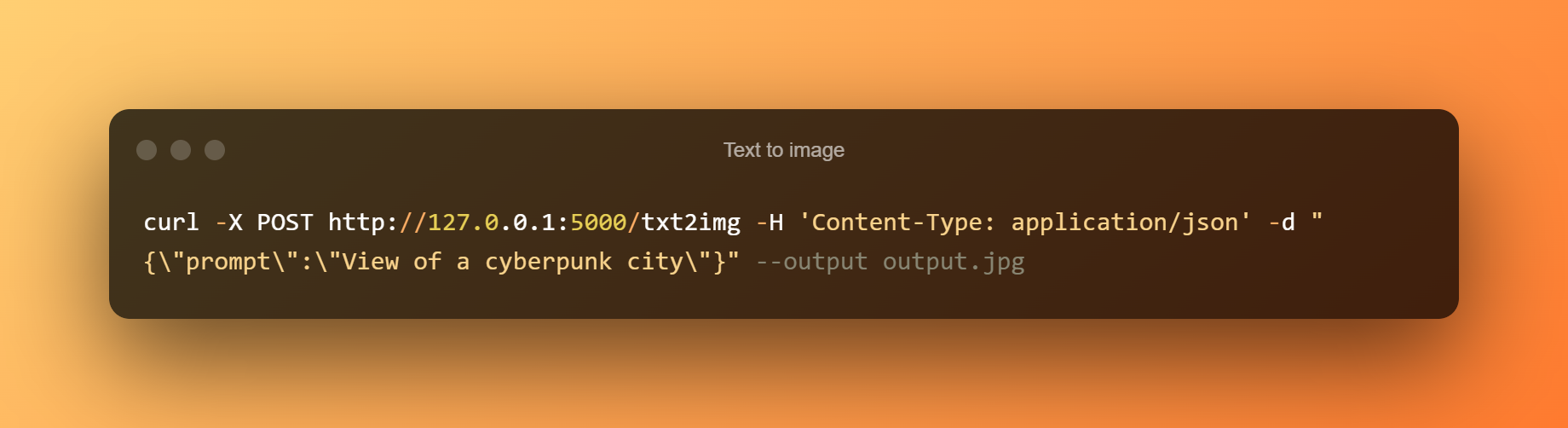
Sortie texte vers image

Le fichier bentofile.yaml définit les fichiers et dépendances requis.
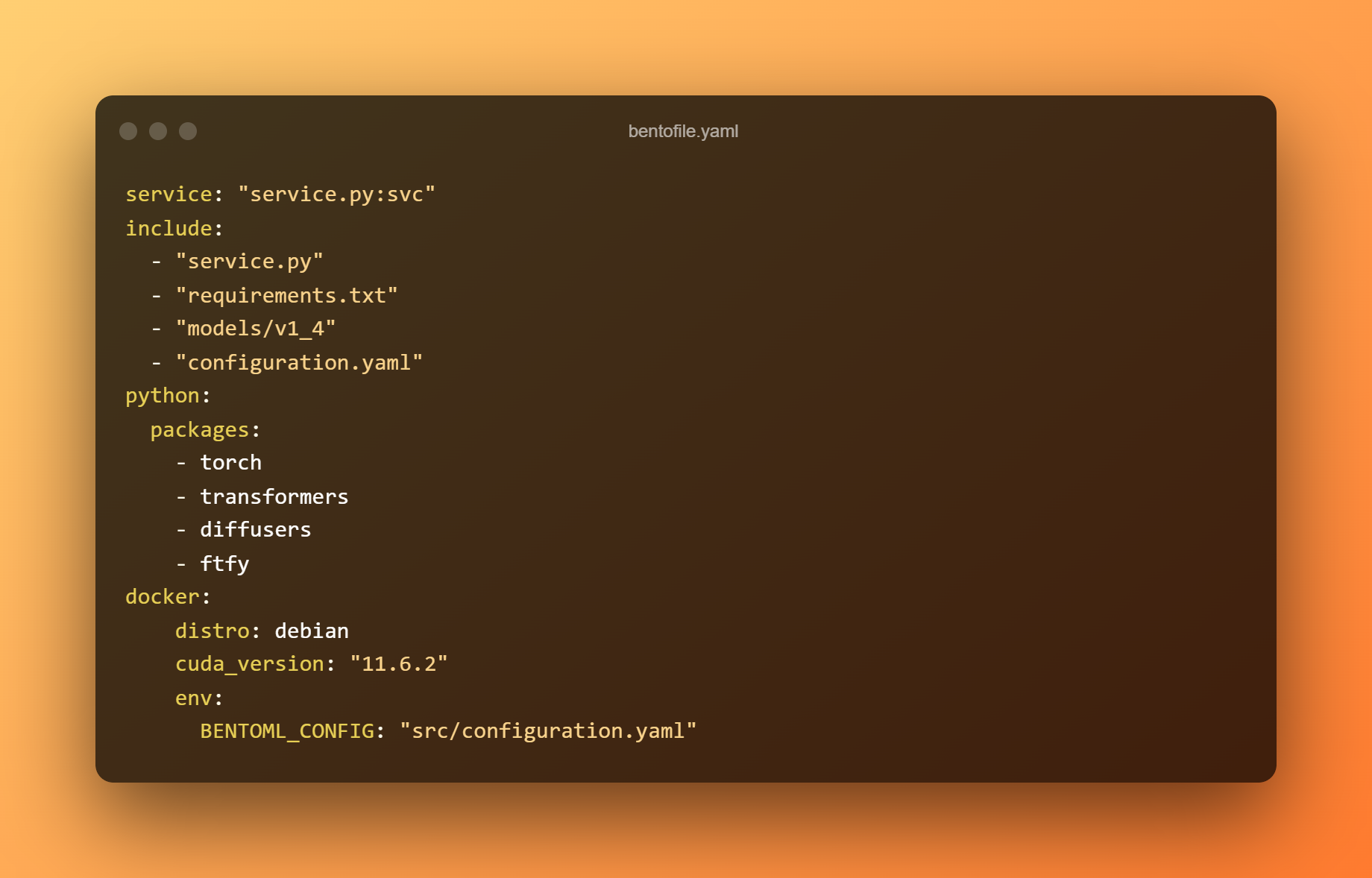
Utilisez la commande ci-dessous pour construire un bento. Un Bento est le format de distribution d'un service BentoML. Il s'agit d'une archive autonome qui contient toutes les données et configurations nécessaires pour démarrer le service.

Le bento Stable Diffusion est terminé. Si vous n'avez pas réussi à générer correctement le bento, pas de panique ; vous pouvez télécharger un modèle prédéfini à l'aide des commandes répertoriées dans la section suivante.
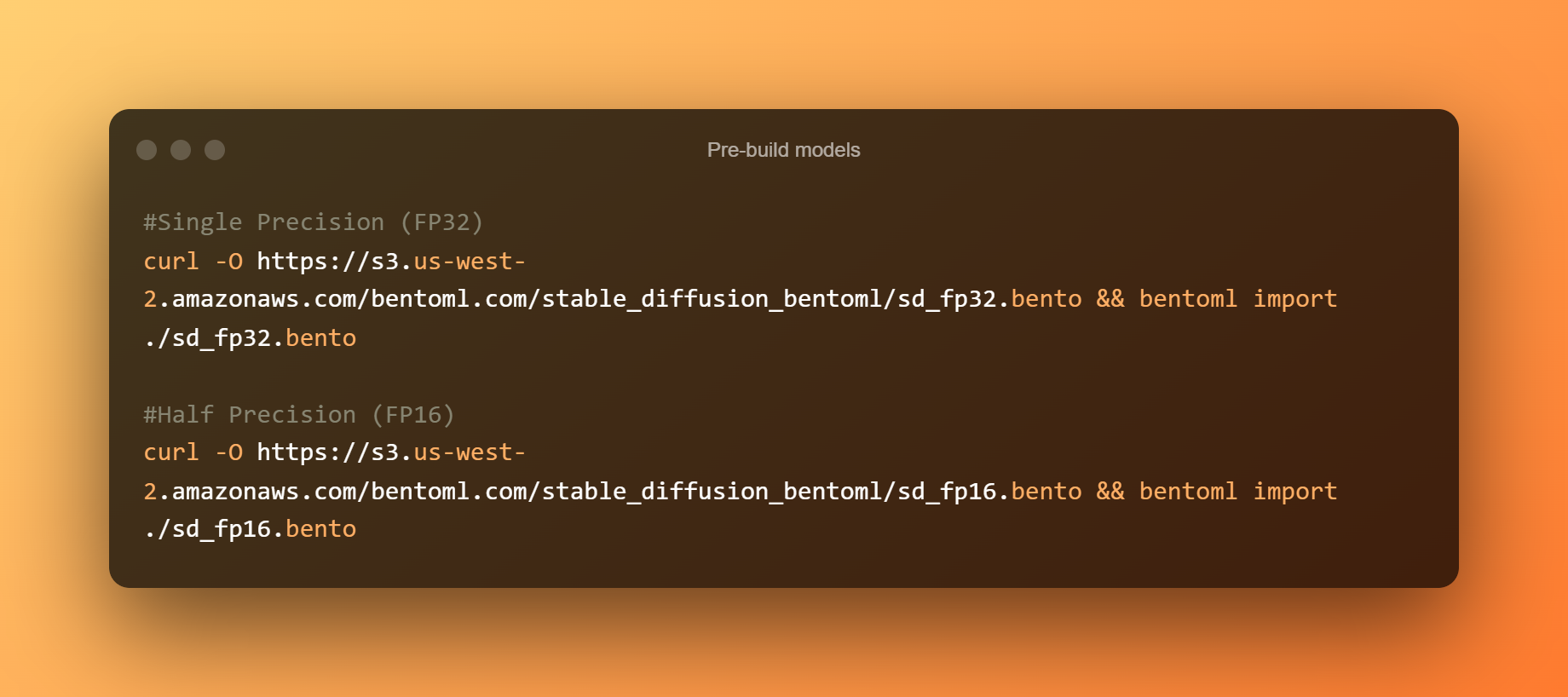
Modèles pré-construits
Voici les modèles de pré-construction :
Déployer le modèle de diffusion stable sur EC2
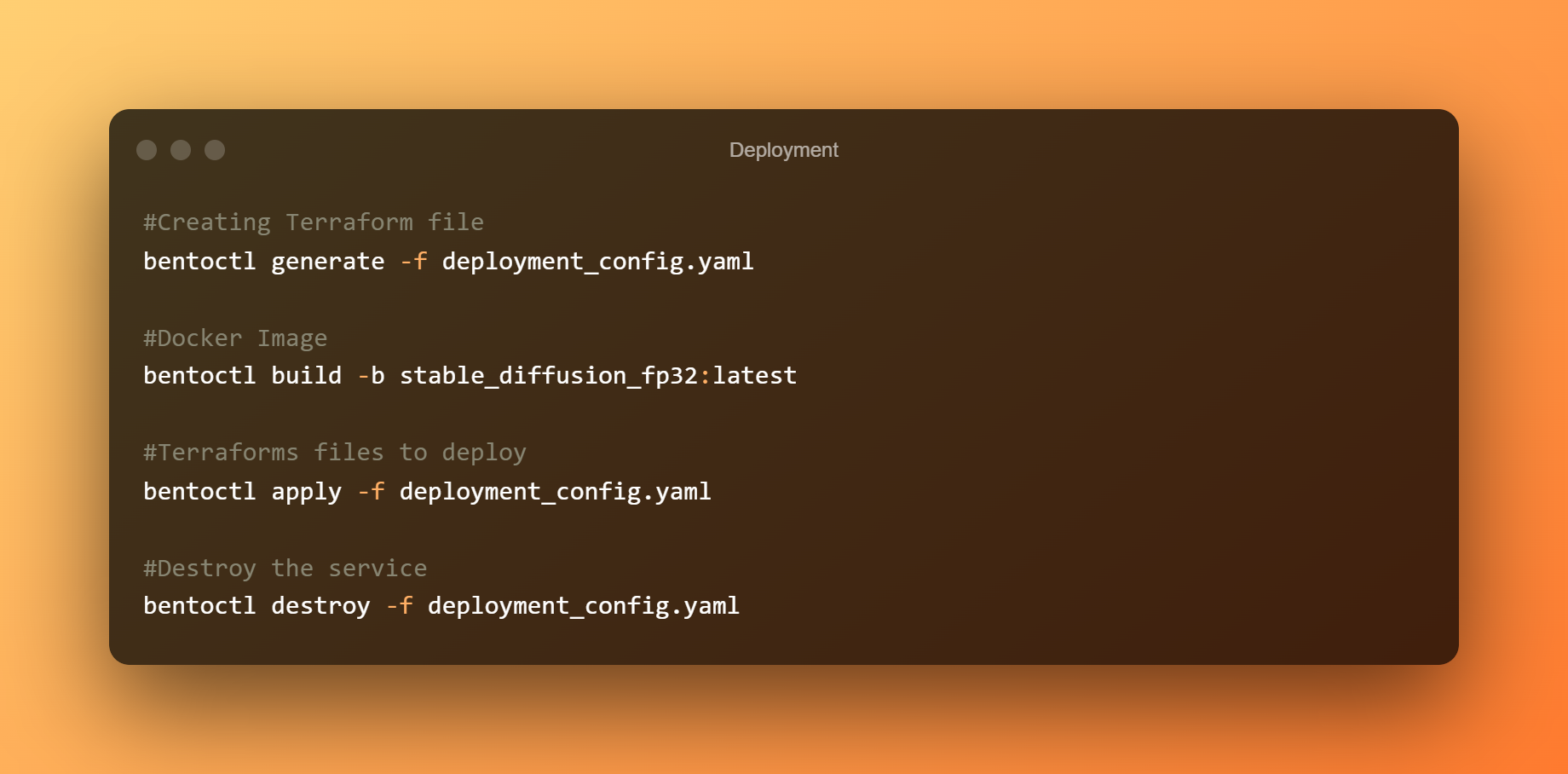
Pour déployer le bento sur EC2, nous allons utiliser bentoctl. bentoctl peut vous permettre de déployer vos bentos sur n'importe quel plateforme cloud en utilisant Terraform. Pour créer et appliquer des fichiers Terraform, installez l'opérateur AWS EC2.

Dans le fichier de déploiement config.yaml, le déploiement a déjà été configuré. N'hésitez pas à modifier selon vos besoins. Le Bento est déployé par défaut sur un hôte g4dn.xlarge avec le L'apprentissage en profondeur AMI GPU PyTorch 1.12.0 (Ubuntu 20.04) AMI sur la région us-west-1.
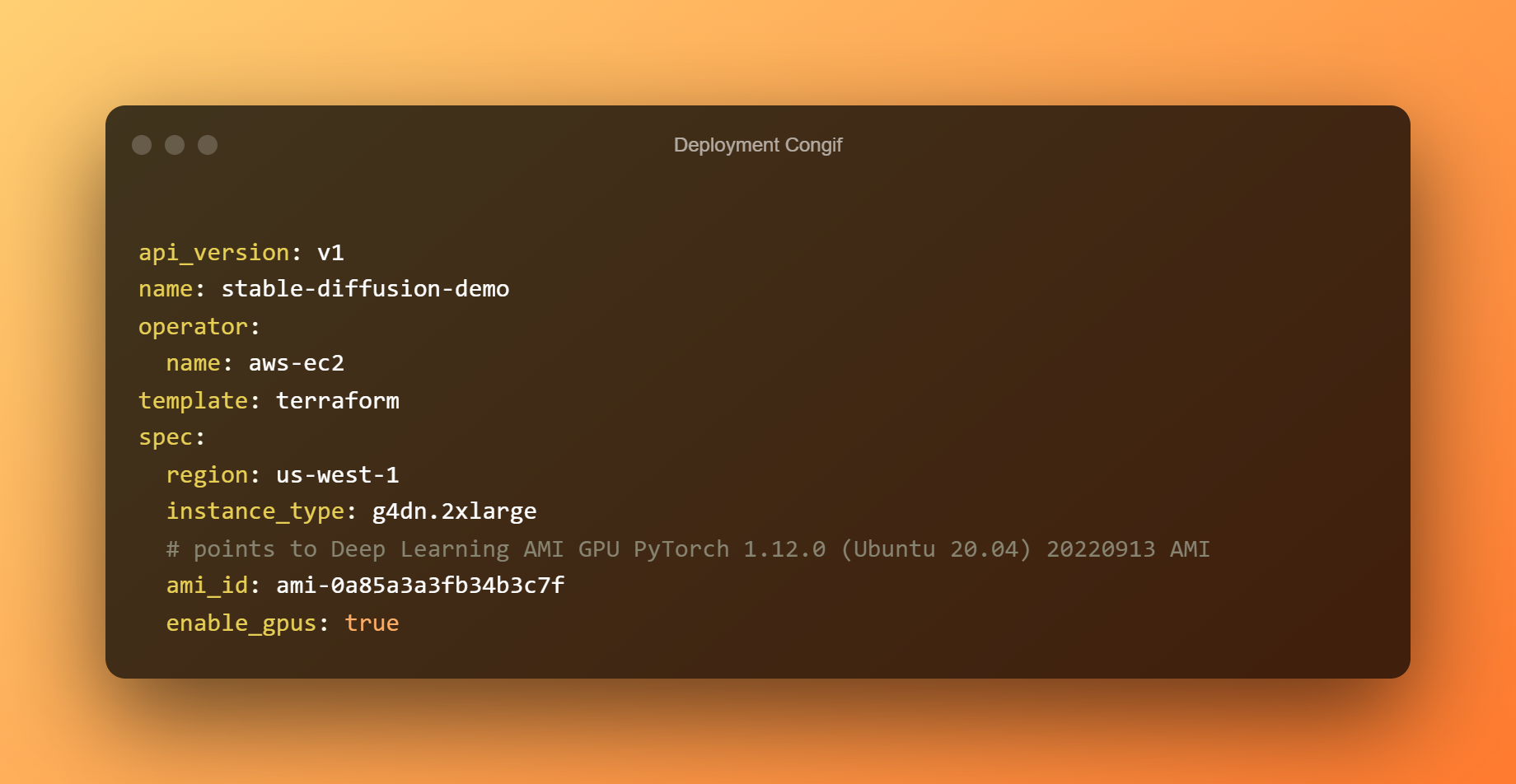
Créez les fichiers Terraform maintenant. Créez l'image Docker et chargez-la sur AWS ECR. Selon votre bande passante, le téléchargement d'images peut prendre beaucoup de temps. Lors du déploiement du bento sur AWS EC2, utilisez les fichiers Terraform.
Pour accéder à l'interface utilisateur Swagger, connectez-vous à la console EC2 et ouvrez l'adresse IP publique dans un navigateur. Enfin, si le service Stable Diffusion BentoML n'est plus requis, supprimez le déploiement.
Conclusion
Vous devriez être en mesure de voir à quel point la SD et ses modèles compagnons sont fascinants et puissants. Le temps nous dira si nous allons réitérer davantage sur le concept ou passer à des approches plus sophistiquées.
Cependant, des initiatives sont actuellement en cours pour former des modèles plus grands avec des ajustements pour mieux saisir l'environnement et les instructions. Nous avons tenté de développer le service Stable Diffusion à l'aide de BentoML et l'avons déployé sur AWS EC2.
Nous avons pu exécuter le modèle Stable Diffusion sur du matériel plus puissant, créer des images avec une faible latence et nous étendre au-delà d'un seul ordinateur en déployant le service sur AWS EC2.





Soyez sympa! Laissez un commentaire