Table des matières[Cacher][Montrer]
La nouvelle IA améliorée a amélioré les capacités, la compréhension et la capacité de produire des images à plus haute résolution. Vous avez peut-être récemment rencontré des images étranges et amusantes flottant sur Internet.
Un chien Shiba Inu est vêtu d'un béret et d'un col roulé noir. Et une loutre de mer à la manière de la "Fille à la perle" du peintre néerlandais Vermeer. Et il y a une tasse de soupe qui ressemble à un monstre laineux.
Ces images n'ont pas été créés par un artiste humain.
Au lieu de cela, DALL-E 2, un nouveau système d'IA capable de convertir des descriptions textuelles en images, les a créés.
Écrivez simplement ce que vous voulez voir, et l'IA le créera pour vous - avec des détails saisissants, une grande qualité et, dans certains cas, une véritable inventivité. Dans cet article, nous examinerons en profondeur la dernière étude d'OpenAI, DALL.E 2, ainsi que son fonctionnement, et bien plus encore. Commençons.
Alors, quel est exactement DALL.E 2?
DALL-E 2 est un « modèle génératif », un type d'algorithme d'apprentissage automatique qui génère une sortie compliquée plutôt que d'effectuer des tâches de prédiction ou de classification sur les données d'entrée.
Vous fournissez à DALL-E 2 une description écrite, et il crée une image qui lui correspond. En combinant des concepts, des qualités et des styles, DALLE 2 d'OpenAI peut produire des graphismes et de l'art innovants et réalistes à partir d'une description linguistique de base.
La dernière version, DALLE 2, serait plus polyvalente, capable de créer des images à partir de légendes à des résolutions plus élevées et dans un plus large éventail de styles créatifs. Par exemple, les images ci-dessous (du billet de blog DALL-E 2) sont créées par la description "Un astronaute à cheval".
Une description se termine "comme un croquis au crayon", tandis que l'autre se termine "de manière photoréaliste".

Il peut également modifier des photographies existantes avec une précision étonnante. Ainsi, vous pouvez ajouter ou supprimer des éléments tout en conservant les couleurs, les reflets et les ombres, tout en conservant l'apparence de l'image d'origine.
Comment cela fonctionne ?
DALL-E 2 utilise les modèles CLIP et diffusion, deux modèles sophistiqués l'apprentissage en profondeur approches développées ces dernières années. Cependant, il est basé sur la même notion que tous les autres les réseaux de neurones: apprentissage de la représentation. CLIP forme simultanément deux les réseaux de neurones sur les images et les légendes.
Un réseau apprend les représentations visuelles dans l'image, tandis que l'autre apprend les représentations textuelles. Au cours de la formation, les deux réseaux tentent de modifier leurs paramètres afin que des images et des descriptions comparables aboutissent à des intégrations similaires.
La «diffusion», un type de modèle génératif qui apprend à créer des images en bruitant et en débruitant progressivement ses échantillons d'apprentissage, est l'autre approche d'apprentissage automatique utilisée dans DALL-E 2. Les modèles de diffusion sont similaires aux auto-encodeurs en ce sens qu'ils transforment les données d'entrée en un représentation d'intégration, puis utiliser les informations d'intégration pour recréer les données d'origine.
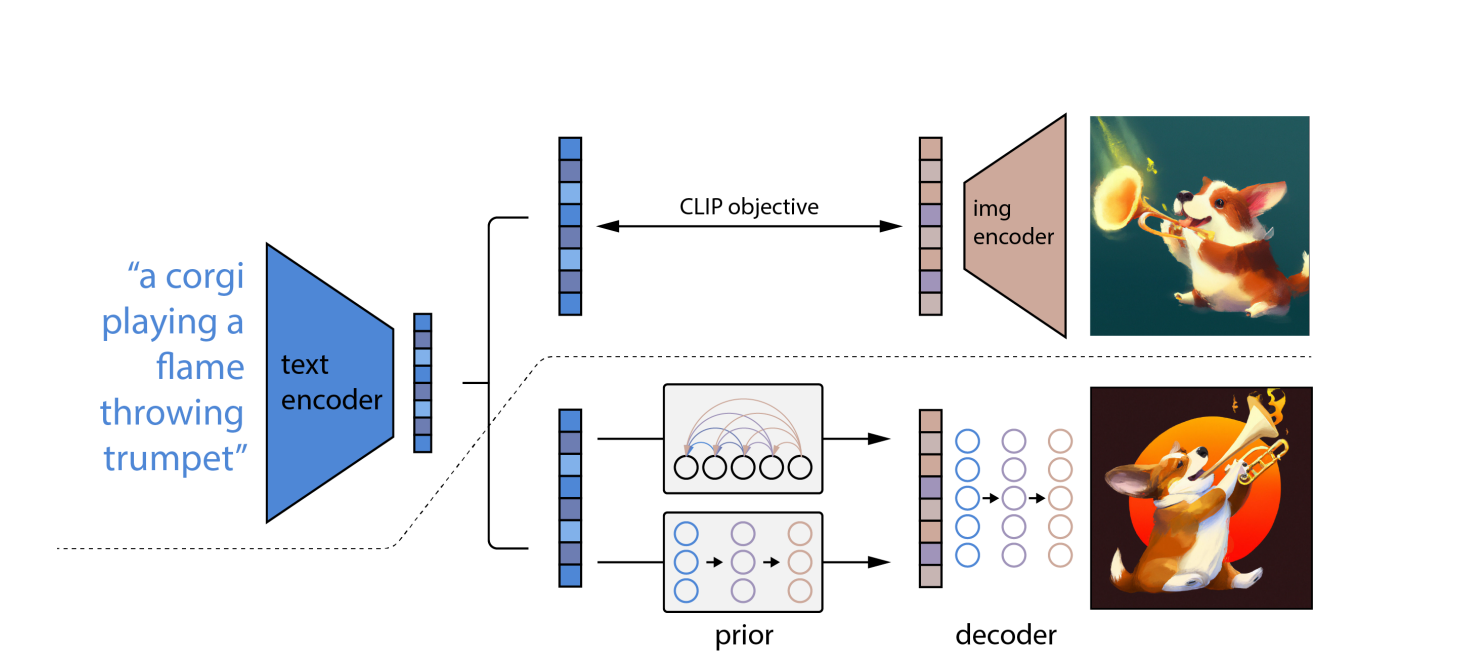
Utilisation d'OpenAI modèle de langage CLIP, qui peut relier des descriptions textuelles à des photographies, traduit d'abord l'invite écrite en une forme intermédiaire qui intègre les propriétés cruciales qu'une image doit avoir pour correspondre à cette invite (selon CLIP).
Deuxièmement, DALL-E 2 crée un CLIP-conforme image utilisant un modèle de diffusion, qui est un réseau de neurones.
Sur des photos déformées avec des pixels aléatoires, des modèles de diffusion sont appris. Ils apprennent à restaurer la forme originale des photos. Les modèles de diffusion peuvent produire des images synthétiques de haute qualité, en particulier lorsqu'ils sont utilisés conjointement avec une approche de guidage qui privilégie la précision à la diversité.
En conséquence, le modèle de diffusion prend les pixels aléatoires et utilise CLIP pour les convertir en une nouvelle image qui correspond à l'invite de mots. En raison du concept de diffusion, DALL-E 2 peut produire des images à plus haute résolution plus rapidement que DALL-E.
Cas d'utilisation DALL.E 2
Au cours des vingt dernières années, vision par ordinateur la technologie est passée d'une simple notion à une percée majeure. Malgré ces progrès, les modèles de reconnaissance d'images et d'objets sont toujours confrontés à des obstacles importants dans la vie quotidienne. L'absence d'ensembles de données est l'un des inconvénients les plus importants de la reconnaissance d'images et de la vision par ordinateur. En raison du manque de données aux deux extrémités, il est presque difficile de former des modèles de reconnaissance d'images pour donner des résultats précis à 100 %.
Heureusement, le nouveau modèle d'apprentissage automatique d'OpenAI peut combler le fossé technologique. DALLE 2 est capable de générer des images étonnantes basées sur des descriptions textuelles. Cette fausse production d'images peut fournir des données aux modèles de reconnaissance d'images en fonction de leurs besoins. L'absence de données est une pierre d'achoppement importante pour l'identification des objets et des images.
À l'ère numérique, les ensembles de données sont omniprésents, mais nous recherchons toujours des raccourcis pour alimenter le modèle d'IA, afin qu'il puisse fournir de bons résultats. Cependant, il n'est pas simple d'entraîner un modèle de reconnaissance d'image. Cela nécessite un grand nombre d'ensembles de données avec peu de différences, que nous n'aurions peut-être pas pu récupérer simplement.
Alors, quelle est la réponse : la réponse est DALLE 2. Le générateur d'images OpenAI, avec sa capacité à produire des images à partir de textes et à modifier celles qui existent déjà, peut aider à combler le fossé. Cela aidera à la génération de données de formation supplémentaires tout en réduisant la quantité d'étiquetage humain nécessaire. Malgré l'avantage significatif, vous devez être conscient des productions d'images frauduleuses et des images qui excluent l'inclusion. Cela pourrait conduire à des méthodes de détection d'image produisant des résultats biaisés.
Limites
DALL.E 2 pourrait bien avoir une influence néfaste s'il tombe entre de mauvaises mains, selon OpenAI. Dans le monde actuel de deep fakes, le modèle pourrait facilement être utilisé pour diffuser de fausses informations ou des images racistes, c'est pourquoi OpenAI n'autorise les développeurs à utiliser DALL.2 que sur invitation. Le modèle doit se conformer à une restriction de contenu rigoureuse pour toutes les suggestions qu'elle reçoit.
Pour exclure le potentiel de DALL.E 2 créant des images hostiles ou violentes, l'ensemble de données a été créé sans aucune arme mortelle. Alors qu'OpenAI a déclaré qu'il prévoyait de le transformer en API à l'avenir, dans le cas de DALL.E 2, il est prêt à procéder avec prudence.
Conclusion
DALL-E 2 est une autre découverte intéressante de la recherche OpenAI qui ouvre la porte à de nouvelles applications.
Un exemple est la création d'ensembles de données massifs pour répondre à l'un des principaux goulots d'étranglement de la vision par ordinateur : les données. Alors que le cas économique de nombreuses applications basées sur DALL-E sera déterminé par le prix et les politiques qu'OpenAI établit pour ses utilisateurs d'API, elles feront sans aucun doute progresser la production d'images.





Soyez sympa! Laissez un commentaire