L'IA est partout, mais il peut parfois être difficile de comprendre la terminologie et le jargon. Dans cet article de blog, nous expliquons plus de 50 termes et définitions de l'IA afin que vous puissiez mieux comprendre cette technologie en pleine croissance.
Que vous soyez débutant ou expert, nous parions qu'il y a ici quelques termes que vous ne connaissez pas !
1. Intelligence artificielle
Intelligence artificielle (IA) fait référence au développement de systèmes informatiques capables d'apprendre et de fonctionner de manière indépendante, souvent en imitant l'intelligence humaine.
Ces systèmes analysent les données, reconnaissent les modèles, prennent des décisions et adaptent leur comportement en fonction de l'expérience. En s'appuyant sur des algorithmes et des modèles, l'IA vise à créer des machines intelligentes capables de percevoir et de comprendre leur environnement.
L'objectif ultime est de permettre aux machines d'effectuer des tâches efficacement, d'apprendre à partir des données et de présenter des capacités cognitives similaires à celles des humains.
2. Algorithme
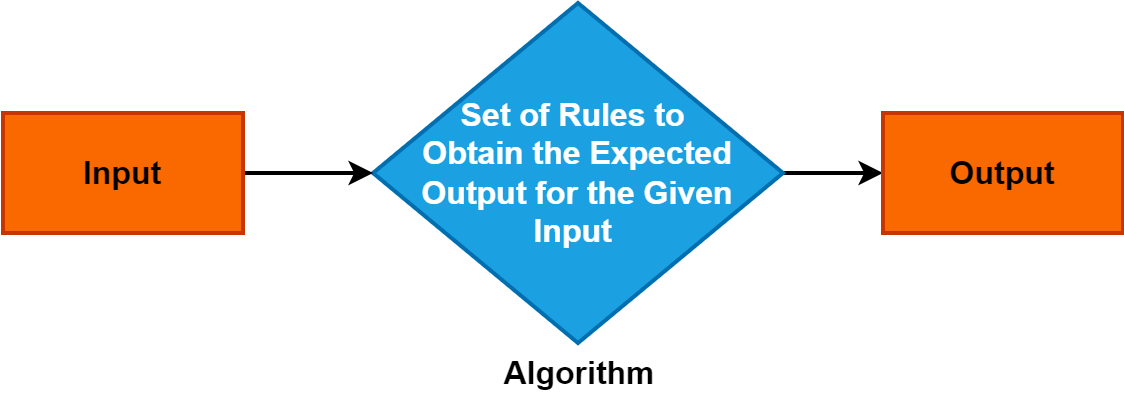
Un algorithme est un ensemble précis et systématique d'instructions ou de règles qui guident le processus de résolution d'un problème ou d'accomplissement d'une tâche spécifique.
Il sert de concept fondamental dans divers domaines et joue un rôle central dans les disciplines de l'informatique, des mathématiques et de la résolution de problèmes. La compréhension des algorithmes est cruciale car ils permettent des approches de résolution de problèmes efficaces et structurées, entraînant des progrès dans la technologie et les processus de prise de décision.
3. Big Data
Les mégadonnées font référence à des ensembles de données extrêmement volumineux et complexes qui dépassent les capacités des méthodes d'analyse traditionnelles. Ces ensembles de données sont généralement caractérisés par leur volume, leur vélocité et leur variété.
Le volume fait référence à la grande quantité de données générées à partir de diverses sources telles que réseaux sociaux, capteurs et transactions.
La vélocité fait référence à la vitesse élevée à laquelle les données sont générées et doivent être traitées en temps réel ou en temps quasi réel. La variété signifie les divers types et formats de données, y compris les données structurées, non structurées et semi-structurées.
4. Data Mining
L'exploration de données est un processus complet visant à extraire des informations précieuses à partir de vastes ensembles de données.
Elle comprend quatre étapes clés : la collecte de données, impliquant la collecte de données pertinentes ; préparation des données, garantie de la qualité et de la compatibilité des données ; extraire les données, utiliser des algorithmes pour découvrir des modèles et des relations ; et l'analyse et l'interprétation des données, où les connaissances extraites sont examinées et comprises.
5. Réseau neuronal
Un système informatique est conçu pour fonctionner comme le cerveau humain, composé de nœuds ou de neurones interconnectés. Comprenons cela un peu plus car la plupart des IA sont basées sur les réseaux de neurones.
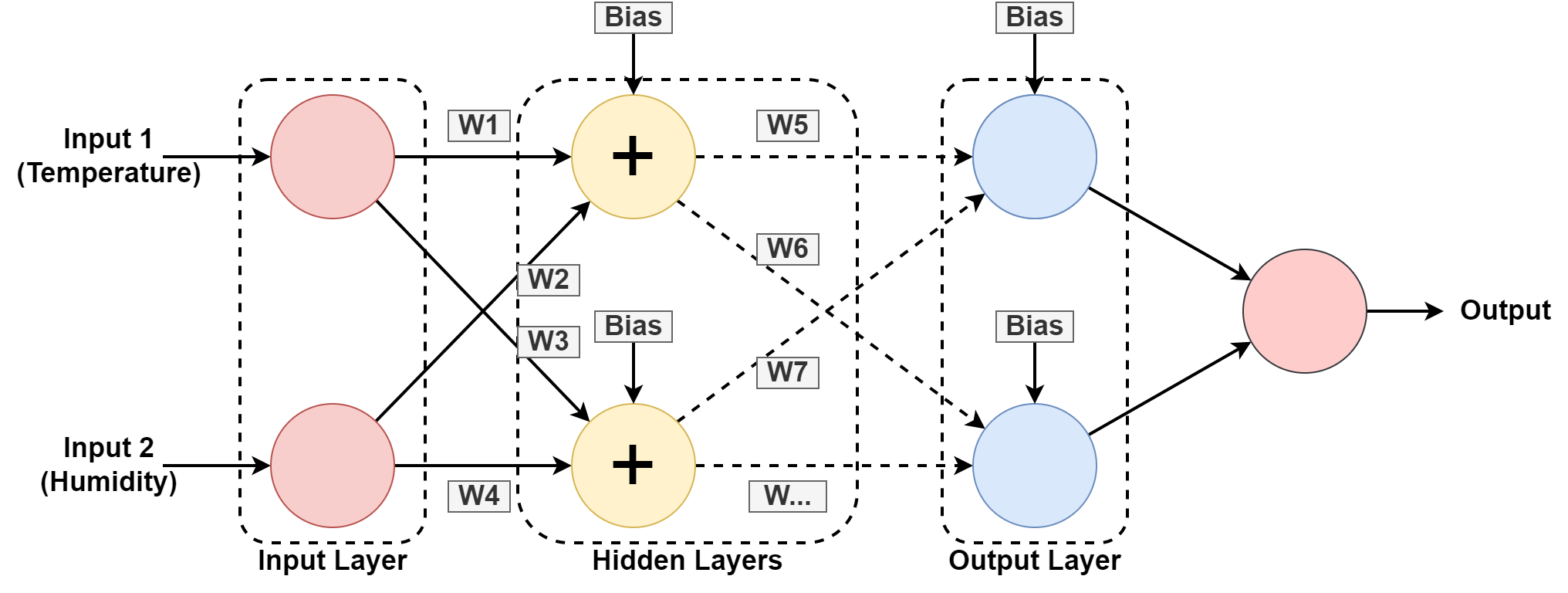
Dans les graphiques ci-dessus, nous prévoyons l'humidité et la température d'un emplacement géographique en apprenant du modèle passé. Les entrées sont l'ensemble de données de l'enregistrement passé.
La le réseau de neurones apprend le motif en jouant avec les poids et en appliquant des valeurs de biais dans les calques masqués. W1, W2….W7 sont les poids respectifs. Il s'entraîne sur l'ensemble de données fourni et donne une sortie sous forme de prédiction.
Vous pourriez être submergé par ces informations complexes. Si tel est le cas, vous pouvez commencer par notre guide simple ici.
6. Apprentissage machine
L'apprentissage automatique se concentre sur le développement d'algorithmes et de modèles capables d'apprendre automatiquement à partir des données et d'améliorer leurs performances au fil du temps.
Cela implique l'utilisation de techniques statistiques pour permettre aux ordinateurs d'identifier des modèles, de faire des prédictions et de prendre des décisions basées sur des données sans être explicitement programmés.
Les algorithmes d'apprentissage automatique (machine learning) analyser et apprendre à partir de grands ensembles de données, permettant aux systèmes d'adapter et d'améliorer leur comportement en fonction des informations qu'ils traitent.
7. Apprentissage en profondeur
L'apprentissage en profondeur, un sous-domaine de l'apprentissage automatique et des réseaux de neurones, exploite des algorithmes sophistiqués pour acquérir des connaissances à partir de données en simulant les processus complexes du cerveau humain.
En utilisant des réseaux de neurones avec de nombreuses couches cachées, les modèles d'apprentissage en profondeur peuvent extraire de manière autonome des caractéristiques et des modèles complexes, ce qui leur permet de s'attaquer à des tâches complexes avec une précision et une efficacité exceptionnelles.
8. Reconnaissance des formes
La reconnaissance de formes, une technique d'analyse de données, exploite la puissance des algorithmes d'apprentissage automatique pour détecter et discerner de manière autonome des modèles et des régularités au sein d'ensembles de données.
En exploitant des modèles informatiques et des méthodes statistiques, les algorithmes de reconnaissance de formes peuvent identifier des structures, des corrélations et des tendances significatives dans des données complexes et diverses.
Ce processus permet l'extraction d'informations précieuses, la classification des données en catégories distinctes et la prédiction des résultats futurs sur la base de modèles reconnus. La reconnaissance de formes est un outil essentiel dans divers domaines, permettant la prise de décision, la détection d'anomalies et la modélisation prédictive.
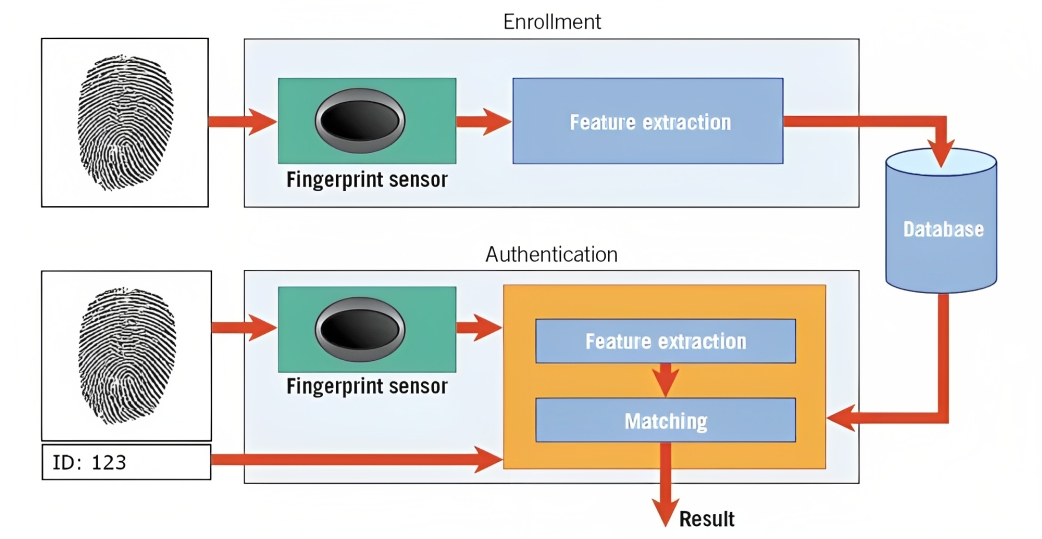
La biométrie en est un exemple. Par exemple, dans la reconnaissance des empreintes digitales, l'algorithme analyse les crêtes, les courbes et les caractéristiques uniques de l'empreinte digitale d'une personne pour créer une représentation numérique appelée modèle.
Lorsque vous tentez de déverrouiller votre smartphone ou d'accéder à une installation sécurisée, le système de reconnaissance de formes compare les données biométriques capturées (par exemple, les empreintes digitales) avec les modèles stockés dans sa base de données.
En faisant correspondre les modèles et en évaluant le niveau de similarité, le système peut déterminer si les données biométriques fournies correspondent au modèle stocké et accorder l'accès en conséquence.
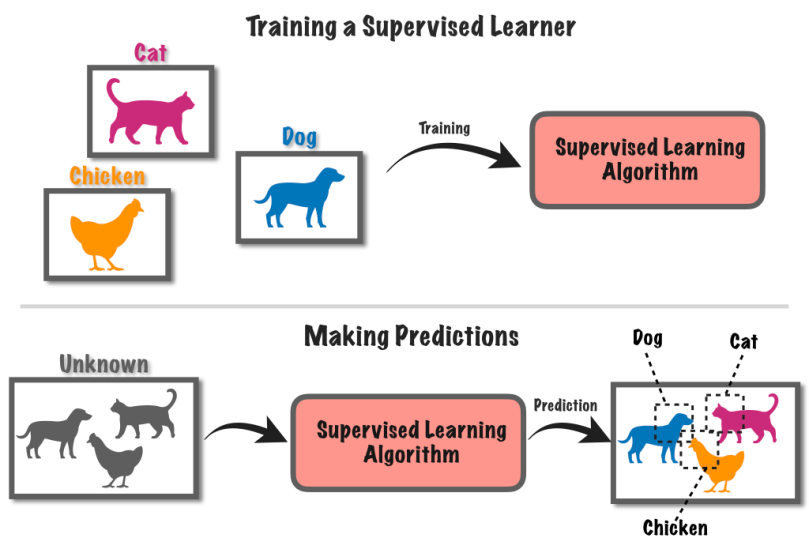
9. Apprentissage supervisé
L'apprentissage supervisé est une approche d'apprentissage automatique qui consiste à former un système informatique à l'aide de données étiquetées. Dans ce procédé, l'ordinateur reçoit un ensemble de données d'entrée ainsi que des étiquettes ou des résultats connus correspondants.
Disons que vous avez un tas de photos, certaines avec des chiens et d'autres avec des chats.
Vous dites à l'ordinateur quelles images ont des chiens et lesquelles ont des chats. L'ordinateur apprend alors à reconnaître les différences entre les chiens et les chats en trouvant des motifs dans les images.
Une fois qu'il a appris, vous pouvez donner à l'ordinateur de nouvelles images, et il essaiera de déterminer s'ils ont des chiens ou des chats en fonction de ce qu'il a appris des exemples étiquetés. C'est comme entraîner un ordinateur à faire des prédictions en utilisant des informations connues.
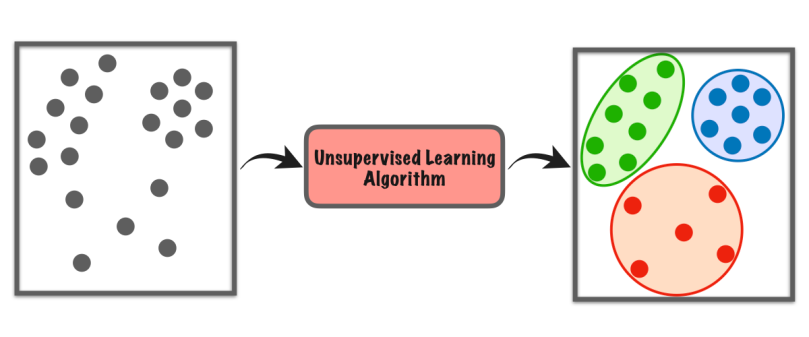
10. Apprentissage non supervisé
L'apprentissage non supervisé est un type d'apprentissage automatique dans lequel l'ordinateur explore seul un ensemble de données pour trouver des modèles ou des similitudes sans aucune instruction spécifique.
Il ne s'appuie pas sur des exemples étiquetés comme dans l'apprentissage supervisé. Au lieu de cela, il recherche des structures ou des groupes cachés dans les données. C'est comme si l'ordinateur découvrait des choses par lui-même, sans qu'un enseignant lui dise quoi chercher.
Ce type d'apprentissage nous aide à trouver de nouvelles idées, à organiser des données ou à identifier des choses inhabituelles sans avoir besoin de connaissances préalables ou de conseils explicites.
11. Traitement du langage naturel (TAL)
Le traitement du langage naturel se concentre sur la façon dont les ordinateurs comprennent et interagissent avec le langage humain. Il aide les ordinateurs à analyser, interpréter et répondre au langage humain d'une manière qui nous semble plus naturelle.
La PNL est ce qui nous permet de communiquer avec des assistants vocaux et des chatbots, et même de trier automatiquement nos e-mails dans des dossiers.
Cela implique d'apprendre aux ordinateurs à comprendre le sens des mots, des phrases et même des textes entiers, afin qu'ils puissent nous aider dans diverses tâches et rendre nos interactions avec la technologie plus fluides.
12. Vision par ordinateur
Vision par ordinateur est une technologie fascinante qui permet aux ordinateurs de voir et de comprendre des images et des vidéos, tout comme nous, les humains, le faisons avec nos yeux. Il s'agit d'apprendre aux ordinateurs à analyser les informations visuelles et à donner un sens à ce qu'ils voient.
En termes plus simples, la vision par ordinateur aide les ordinateurs à reconnaître et à interpréter le monde visuel. Cela implique des tâches telles que leur apprendre à identifier des objets spécifiques dans les images, à classer les images en différentes catégories ou même à diviser les images en parties significatives.
Imaginez une voiture autonome utilisant la vision par ordinateur pour « voir » la route et tout ce qui l'entoure.
Il peut détecter et suivre les piétons, les panneaux de signalisation et d'autres véhicules, les aidant à naviguer en toute sécurité. Ou pensez à la façon dont la technologie de reconnaissance faciale utilise la vision par ordinateur pour déverrouiller nos smartphones ou vérifier nos identités en reconnaissant nos caractéristiques faciales uniques.
Il est également utilisé dans les systèmes de surveillance pour surveiller les endroits bondés et repérer toute activité suspecte.
La vision par ordinateur est une technologie puissante qui ouvre un monde de possibilités. En permettant aux ordinateurs de voir et de comprendre les informations visuelles, nous pouvons développer des applications et des systèmes capables de percevoir et d'interpréter le monde qui nous entoure, rendant nos vies plus faciles, plus sûres et plus efficaces.
13. Les chatbots
Un chatbot est comme un programme informatique qui peut parler aux gens d'une manière qui ressemble à une vraie conversation humaine.
Il est souvent utilisé dans le service client en ligne pour aider les clients et leur donner l'impression de parler à une personne, même s'il s'agit en fait d'un programme exécuté sur un ordinateur.
Le chatbot peut comprendre et répondre aux messages ou aux questions des clients, en fournissant des informations et une assistance utiles, tout comme le ferait un représentant du service client humain.
14. Reconnaissance vocale
La reconnaissance vocale fait référence à la capacité d'un système informatique à comprendre et à interpréter la parole humaine. Il s'agit de la technologie qui permet à un ordinateur ou à un appareil « d'écouter » des mots prononcés et de les convertir en texte ou en commandes qu'il peut comprendre.
Avec reconnaissance vocale, vous pouvez interagir avec des appareils ou des applications en leur parlant simplement au lieu de taper ou d'utiliser d'autres méthodes de saisie.
Le système analyse les mots prononcés, reconnaît les motifs et les sons, puis les traduit en texte ou en actions compréhensibles. Il permet une communication mains libres et naturelle avec la technologie, rendant possibles des tâches telles que les commandes vocales, la dictée ou les interactions à commande vocale. Les exemples les plus courants sont les assistants IA comme Siri et Google Assistant.
15. Analyse des sentiments
Analyse des sentiments est une technique utilisée pour comprendre et interpréter les émotions, les opinions et les attitudes exprimées dans un texte ou un discours. Il s'agit d'analyser la langue écrite ou parlée pour déterminer si le sentiment exprimé est positif, négatif ou neutre.
À l'aide d'algorithmes d'apprentissage automatique, les algorithmes d'analyse des sentiments peuvent analyser et analyser de grandes quantités de données textuelles, telles que les avis des clients, les publications sur les réseaux sociaux ou les commentaires des clients, afin d'identifier le sentiment sous-jacent derrière les mots.
Les algorithmes recherchent des mots, des phrases ou des modèles spécifiques qui indiquent des émotions ou des opinions.
Cette analyse aide les entreprises ou les particuliers à comprendre ce que les gens pensent d'un produit, d'un service ou d'un sujet et peut être utilisée pour prendre des décisions fondées sur des données ou obtenir des informations sur les préférences des clients.
Par exemple, une entreprise peut utiliser l'analyse des sentiments pour suivre la satisfaction des clients, identifier les domaines à améliorer ou surveiller l'opinion publique sur sa marque.
16. Traduction automatique
La traduction automatique, dans le contexte de l'IA, fait référence à l'utilisation d'algorithmes informatiques et de l'intelligence artificielle pour traduire automatiquement un texte ou un discours d'une langue à une autre.
Il s'agit d'apprendre aux ordinateurs à comprendre et à traiter les langages humains afin de fournir des traductions précises. L'exemple le plus courant est Google Traduction.
Avec la traduction automatique, vous pouvez saisir du texte ou de la parole dans une langue, et le système analysera l'entrée et générera une traduction correspondante dans une autre langue. Ceci est particulièrement utile lors de la communication ou de l'accès à des informations dans différentes langues.
Les systèmes de traduction automatique reposent sur une combinaison de règles linguistiques, de modèles statistiques et d'algorithmes d'apprentissage automatique. Ils apprennent à partir de grandes quantités de données linguistiques pour améliorer la précision de la traduction au fil du temps. Certaines approches de traduction automatique intègrent également des réseaux de neurones pour améliorer la qualité des traductions.
17. Robotique
La robotique est la combinaison de l'intelligence artificielle et de l'ingénierie mécanique pour créer des machines intelligentes appelées robots. Ces robots sont conçus pour effectuer des tâches de manière autonome ou avec une intervention humaine minimale.
Les robots sont des entités physiques capables de détecter leur environnement, de prendre des décisions en fonction de ces informations sensorielles et d'effectuer des actions ou des tâches spécifiques.
Ils sont équipés de divers capteurs, tels que des caméras, des microphones ou des capteurs tactiles, qui leur permettent de recueillir des informations sur le monde qui les entoure. À l'aide d'algorithmes d'IA et de programmation, les robots peuvent analyser ces données, les interpréter et prendre des décisions intelligentes pour effectuer les tâches qui leur sont assignées.
L'IA joue un rôle crucial dans la robotique en permettant aux robots d'apprendre de leurs expériences et de s'adapter à différentes situations.
Les algorithmes d'apprentissage automatique peuvent être utilisés pour entraîner des robots à reconnaître des objets, à naviguer dans des environnements ou même à interagir avec des humains. Cela permet aux robots de devenir plus polyvalents, flexibles et capables de gérer des tâches complexes.
18. Drones
Les drones sont un type de robot qui peut voler ou planer dans les airs sans pilote humain à bord. Ils sont également connus sous le nom de véhicules aériens sans pilote (UAV). Les drones sont équipés de divers capteurs, tels que des caméras, des GPS et des gyroscopes, qui leur permettent de collecter des données et de naviguer dans leur environnement.
Ils sont contrôlés à distance par un opérateur humain ou peuvent fonctionner de manière autonome à l'aide d'instructions préprogrammées.
Les drones remplissent un large éventail d'objectifs, notamment la photographie et la vidéographie aériennes, l'arpentage et la cartographie, les services de livraison, les missions de recherche et de sauvetage, la surveillance de l'agriculture et même l'utilisation récréative. Ils peuvent accéder à des zones éloignées ou dangereuses qui sont difficiles ou dangereuses pour les humains.
19. Réalité augmentée (RA)
La réalité augmentée (AR) est une technologie qui combine le monde réel avec des objets ou des informations virtuels pour améliorer notre perception et notre interaction avec l'environnement. Il superpose des images, des sons ou d'autres entrées sensorielles générés par ordinateur sur le monde réel, créant une expérience immersive et interactive.
En termes simples, imaginez porter des lunettes spéciales ou utiliser votre smartphone pour voir le monde qui vous entoure, mais avec des éléments virtuels supplémentaires ajoutés.
Par exemple, vous pouvez pointer votre smartphone vers une rue de la ville et voir des panneaux de signalisation virtuels indiquant les directions, les notes et les critiques des restaurants à proximité ou même des personnages virtuels interagissant avec l'environnement réel.
Ces éléments virtuels se fondent parfaitement dans le monde réel, améliorant votre compréhension et votre expérience de l'environnement. La réalité augmentée peut être utilisée dans divers domaines comme les jeux, l'éducation, l'architecture et même pour des tâches quotidiennes comme la navigation ou l'essai de nouveaux meubles dans votre maison avant de les acheter.
20. Réalité virtuelle (VR)
La réalité virtuelle (VR) est une technologie qui utilise des simulations générées par ordinateur pour créer un environnement artificiel qu'une personne peut explorer et avec lequel interagir. Il plonge l'utilisateur dans un monde virtuel, bloquant le monde réel et le remplaçant par un domaine numérique.
En termes simples, imaginez mettre un casque spécial qui couvre vos yeux et vos oreilles et vous transporte dans un endroit complètement différent. Dans ce monde virtuel, tout ce que vous voyez et entendez semble incroyablement réel, même si tout est généré par un ordinateur.
Vous pouvez vous déplacer, regarder dans n'importe quelle direction et interagir avec des objets ou des personnages comme s'ils étaient physiquement présents.
Par exemple, dans un jeu de réalité virtuelle, vous pourriez vous retrouver à l'intérieur d'un château médiéval, où vous pourrez vous promener dans ses couloirs, ramasser des armes et vous engager dans des combats à l'épée avec des adversaires virtuels. L'environnement de réalité virtuelle répond à vos mouvements et actions, vous faisant vous sentir complètement immergé et engagé dans l'expérience.
La réalité virtuelle n'est pas seulement utilisée pour les jeux mais aussi pour diverses autres applications comme les simulations de formation pour les pilotes, les chirurgiens ou le personnel militaire, les visites guidées architecturales, le tourisme virtuel et même la thérapie pour certaines conditions psychologiques. Il crée un sentiment de présence et transporte les utilisateurs vers de nouveaux mondes virtuels passionnants, rendant l'expérience aussi proche que possible de la réalité.
21. Science des données
Science des données est un domaine qui implique l'utilisation de méthodes, d'outils et d'algorithmes scientifiques pour extraire des connaissances et des informations précieuses à partir de données. Il combine des éléments de mathématiques, de statistiques, de programmation et d'expertise du domaine pour analyser des ensembles de données volumineux et complexes.
En termes plus simples, la science des données consiste à trouver des informations et des modèles significatifs cachés dans un ensemble de données. Cela implique de collecter, de nettoyer et d'organiser des données, puis d'utiliser diverses techniques pour les explorer et les analyser. Data scientists utiliser des modèles statistiques et des algorithmes pour découvrir des tendances, faire des prédictions et résoudre des problèmes.
Par exemple, dans le domaine de la santé, la science des données peut être utilisée pour analyser les dossiers des patients et les données médicales afin d'identifier les facteurs de risque de maladies, de prédire les résultats des patients ou d'optimiser les plans de traitement. En entreprise, la science des données peut être appliquée aux données des clients pour comprendre leurs préférences, recommander des produits ou améliorer les stratégies marketing.
22. Dispute de données
Le data wrangling, également connu sous le nom de data munging, est le processus de collecte, de nettoyage et de transformation des données brutes dans un format plus utile et adapté à l'analyse. Il s'agit de manipuler et de préparer des données pour en assurer la qualité, la cohérence et la compatibilité avec des outils ou des modèles d'analyse.
En termes plus simples, la gestion des données revient à préparer des ingrédients pour la cuisine. Cela implique de collecter des données provenant de différentes sources, de les trier et de les nettoyer pour supprimer toute erreur, incohérence ou information non pertinente.
De plus, les données peuvent devoir être transformées, restructurées ou agrégées pour faciliter le travail et l'extraction d'informations.
Par exemple, la gestion des données peut impliquer la suppression des entrées en double, la correction des fautes d'orthographe ou des problèmes de formatage, la gestion des valeurs manquantes et la conversion des types de données. Cela peut également impliquer de fusionner ou de joindre différents ensembles de données, de diviser les données en sous-ensembles ou de créer de nouvelles variables basées sur des données existantes.
23. Raconter des données
Narration des données est l’art de présenter des données de manière convaincante et engageante pour communiquer efficacement un récit ou un message. Il s'agit d'utiliser visualisations de données, les récits et le contexte pour transmettre les idées et les conclusions d'une manière compréhensible et mémorable pour le public.
En termes plus simples, la narration de données consiste à utiliser des données pour raconter une histoire. Cela va au-delà de la simple présentation de chiffres et de graphiques. Cela implique de créer un récit autour des données, en utilisant des éléments visuels et des techniques de narration pour donner vie aux données et les rendre pertinentes pour le public.
Par exemple, au lieu de simplement présenter un tableau des chiffres des ventes, la narration des données peut impliquer la création d'un tableau de bord interactif qui permet aux utilisateurs d'explorer visuellement les tendances des ventes.
Il pourrait inclure un récit qui met en évidence les principales conclusions, explique les raisons des tendances et suggère des recommandations exploitables basées sur les données.
24. Prise de décision basée sur les données
La prise de décision basée sur les données est un processus consistant à faire des choix ou à prendre des mesures sur la base de l'analyse et de l'interprétation de données pertinentes. Cela implique d'utiliser les données comme base pour guider et soutenir les processus de prise de décision plutôt que de se fier uniquement à l'intuition ou au jugement personnel.
En termes plus simples, la prise de décision basée sur les données signifie l'utilisation de faits et de preuves à partir de données pour informer et guider les choix que nous faisons. Cela implique de collecter et d'analyser des données pour comprendre les modèles, les tendances et les relations et d'utiliser ces connaissances pour prendre des décisions éclairées et résoudre des problèmes.
Par exemple, dans un contexte commercial, la prise de décision basée sur les données peut impliquer l'analyse des données de vente, des commentaires des clients et des tendances du marché pour déterminer la stratégie de tarification la plus efficace ou identifier les domaines à améliorer dans le développement de produits.
Dans le domaine de la santé, cela peut impliquer l'analyse des données des patients pour optimiser les plans de traitement ou prédire les résultats de la maladie.
25. Lac de données
Un lac de données est un référentiel de données centralisé et évolutif qui stocke de grandes quantités de données sous leur forme brute et non traitée. Il est conçu pour contenir une grande variété de types, de formats et de structures de données, tels que des données structurées, semi-structurées et non structurées, sans avoir besoin de schémas prédéfinis ou de transformations de données.
Par exemple, une entreprise peut collecter et stocker des données provenant de diverses sources, telles que les journaux de sites Web, les transactions des clients, les flux de médias sociaux et les appareils IoT, dans un lac de données.
Ces données peuvent ensuite être utilisées à diverses fins, telles que la réalisation d'analyses avancées, l'exécution d'algorithmes d'apprentissage automatique ou l'exploration de modèles et de tendances dans le comportement des clients.
26. Entrepôt de données
Un entrepôt de données est un système de base de données spécialisé spécialement conçu pour stocker, organiser et analyser de grandes quantités de données provenant de diverses sources. Il est structuré de manière à prendre en charge une récupération efficace des données et des requêtes analytiques complexes.
Il sert de référentiel central qui intègre les données de différents systèmes opérationnels, tels que les bases de données transactionnelles, les systèmes CRM et d'autres sources de données au sein d'une organisation.
Les données sont transformées, nettoyées et chargées dans l'entrepôt de données dans un format structuré optimisé à des fins d'analyse.
27. Intelligence d'affaires (BI)
L'intelligence d'affaires fait référence au processus de collecte, d'analyse et de présentation des données d'une manière qui aide les entreprises à prendre des décisions éclairées et à obtenir des informations précieuses. Cela implique l'utilisation de divers outils, technologies et techniques pour transformer les données brutes en informations significatives et exploitables.
Par exemple, un système d'informatique décisionnelle peut analyser les données de vente pour identifier les produits les plus rentables, surveiller les niveaux de stock et suivre les préférences des clients.
Il peut fournir des informations en temps réel sur les indicateurs de performance clés (KPI) tels que les revenus, l'acquisition de clients ou les performances des produits, permettant aux entreprises de prendre des décisions basées sur les données et de prendre les mesures appropriées pour améliorer leurs opérations.
Les outils d'informatique décisionnelle incluent souvent des fonctionnalités telles que la visualisation des données, les requêtes ad hoc et les capacités d'exploration des données. Ces outils permettent aux utilisateurs, tels que analystes d'affaires ou les gestionnaires, pour interagir avec les données, les découper et les découper, et générer des rapports ou des représentations visuelles qui mettent en évidence les informations et les tendances importantes.
28. Analyses prédictives
L'analyse prédictive est la pratique consistant à utiliser des données et des techniques statistiques pour faire des prédictions ou des prévisions éclairées sur des événements ou des résultats futurs. Cela implique l'analyse de données historiques, l'identification de modèles et la construction de modèles pour extrapoler et estimer les tendances, comportements ou événements futurs.
Il vise à découvrir les relations entre les variables et à utiliser ces informations pour faire des prédictions. Cela va au-delà de la simple description d'événements passés; au lieu de cela, il exploite les données historiques pour comprendre et anticiper ce qui est susceptible de se produire à l'avenir.
Par exemple, dans le domaine de la finance, l'analyse prédictive peut être utilisée pour prévoir stock des prix basés sur des données de marché historiques, des indicateurs économiques et d'autres facteurs pertinents.
En marketing, il peut être utilisé pour prédire le comportement et les préférences des clients, permettant des publicités ciblées et des campagnes de marketing personnalisées.
Dans le domaine de la santé, l'analyse prédictive peut aider à identifier les patients à haut risque pour certaines maladies ou à prédire la probabilité d'une réadmission en fonction des antécédents médicaux et d'autres facteurs.
29. Analyse prescriptive
L'analyse prescriptive est l'application de données et d'analyses pour déterminer les meilleures actions possibles à prendre dans une situation particulière ou un scénario de prise de décision.
Cela va au-delà du descriptif et analyses prédictives en fournissant non seulement des informations sur ce qui pourrait se passer dans le futur, mais également en recommandant le plan d'action le plus optimal pour atteindre le résultat souhaité.
Il combine des données historiques, des modèles prédictifs et des techniques d'optimisation pour simuler différents scénarios et évaluer les résultats potentiels de diverses décisions. Il prend en compte plusieurs contraintes, objectifs et facteurs pour générer des recommandations exploitables qui maximisent les résultats souhaités ou minimisent les risques.
Par exemple, dans chaîne d'approvisionnement gestion, l'analyse prescriptive peut analyser les données sur les niveaux de stock, les capacités de production, les coûts de transport et la demande des clients pour déterminer le plan de distribution le plus efficace.
Il peut recommander l'allocation idéale des ressources, telles que les emplacements de stockage des stocks ou les itinéraires de transport, afin de minimiser les coûts et d'assurer une livraison dans les délais.
30. Marketing basé sur les données
Le marketing axé sur les données fait référence à la pratique consistant à utiliser des données et des analyses pour piloter des stratégies marketing, des campagnes et des processus décisionnels.
Cela implique de tirer parti de diverses sources de données pour mieux comprendre le comportement, les préférences et les tendances des clients et d'utiliser ces informations pour optimiser les efforts de marketing.
Il se concentre sur la collecte et l'analyse de données à partir de plusieurs points de contact, tels que les interactions sur le site Web, l'engagement sur les réseaux sociaux, les données démographiques des clients, l'historique des achats, etc. Ces données sont ensuite utilisées pour créer une compréhension globale du public cible, de ses préférences et de ses besoins.
En exploitant les données, les spécialistes du marketing peuvent prendre des décisions éclairées concernant la segmentation, le ciblage et la personnalisation de la clientèle.
Ils peuvent identifier des segments de clientèle spécifiques qui sont plus susceptibles de répondre positivement aux campagnes marketing et adapter leurs messages et offres en conséquence.
De plus, le marketing basé sur les données aide à optimiser les canaux marketing, à déterminer le mix marketing le plus efficace et à mesurer le succès des initiatives marketing.
Par exemple, une approche marketing basée sur les données peut impliquer l'analyse des données client pour identifier les comportements d'achat et les modèles de préférences. Sur la base de ces informations, les spécialistes du marketing peuvent créer des campagnes ciblées avec un contenu personnalisé et des offres qui résonnent avec des segments de clientèle spécifiques.
Grâce à une analyse et une optimisation continues, ils peuvent mesurer l'efficacité de leurs efforts de marketing et affiner leurs stratégies au fil du temps.
31. Gouvernance des données
La gouvernance des données est le cadre et l'ensemble des pratiques que les organisations adoptent pour assurer la bonne gestion, la protection et l'intégrité des données tout au long de leur cycle de vie. Il englobe les processus, les politiques et les procédures qui régissent la manière dont les données sont collectées, stockées, consultées, utilisées et partagées au sein d'une organisation.
Il vise à établir la responsabilisation, la responsabilité et le contrôle des actifs de données. Il garantit que les données sont exactes, complètes, cohérentes et fiables, permettant aux organisations de prendre des décisions éclairées, de maintenir la qualité des données et de répondre aux exigences réglementaires.
La gouvernance des données implique de définir les rôles et les responsabilités pour la gestion des données, d'établir des normes et des politiques de données et de mettre en œuvre des processus pour surveiller et faire respecter la conformité. Il aborde divers aspects de la gestion des données, notamment la confidentialité des données, la sécurité des données, la qualité des données, la classification des données et la gestion du cycle de vie des données.
Par exemple, la gouvernance des données peut impliquer la mise en œuvre de procédures garantissant que les données personnelles ou sensibles sont traitées conformément aux réglementations applicables en matière de confidentialité, telles que le Règlement général sur la protection des données (RGPD).
Cela peut également inclure l'établissement de normes de qualité des données et la mise en œuvre de processus de validation des données pour s'assurer que les données sont exactes et fiables.
32. Sécurité des données
La sécurité des données consiste à protéger nos précieuses informations contre tout accès non autorisé ou vol. Cela implique de prendre des mesures pour protéger la confidentialité, l'intégrité et la disponibilité des données.
Essentiellement, cela signifie s'assurer que seules les bonnes personnes peuvent accéder à nos données, qu'elles restent exactes et non altérées, et qu'elles sont disponibles en cas de besoin.
Pour assurer la sécurité des données, diverses stratégies et technologies sont utilisées. Par exemple, les contrôles d'accès et les méthodes de cryptage permettent de limiter l'accès aux personnes ou aux systèmes autorisés, ce qui rend plus difficile l'accès à nos données pour les tiers.
Les systèmes de surveillance, les pare-feu et les systèmes de détection d'intrusion agissent comme des gardiens, nous alertant des activités suspectes et empêchant tout accès non autorisé.
33. Internet des objets
L'Internet des objets (IoT) fait référence à un réseau d'objets physiques ou de « choses » qui sont connectés à Internet et peuvent communiquer entre eux. C'est comme un vaste réseau d'objets, d'appareils et de machines du quotidien capables de partager des informations et d'effectuer des tâches en interagissant via Internet.
En termes simples, l'IoT consiste à donner des capacités "intelligentes" à divers objets ou appareils qui n'étaient traditionnellement pas connectés à Internet. Ces objets peuvent inclure des appareils électroménagers, des appareils portables, des thermostats, des voitures et même des machines industrielles.
En connectant ces objets à Internet, ils peuvent collecter et partager des données, recevoir des instructions et effectuer des tâches de manière autonome ou en réponse aux commandes de l'utilisateur.
Par exemple, un thermostat intelligent peut surveiller la température, régler les paramètres et envoyer des rapports de consommation d'énergie à une application pour smartphone. Un tracker de fitness portable peut collecter des données sur vos activités physiques et les synchroniser avec une plate-forme basée sur le cloud pour analyse.
34. Arbre de décision
Un arbre de décision est une représentation visuelle ou un diagramme qui nous aide à prendre des décisions ou à déterminer un plan d'action basé sur une série de choix ou de conditions.
C'est comme un organigramme qui nous guide à travers un processus de prise de décision en considérant différentes options et leurs résultats potentiels.
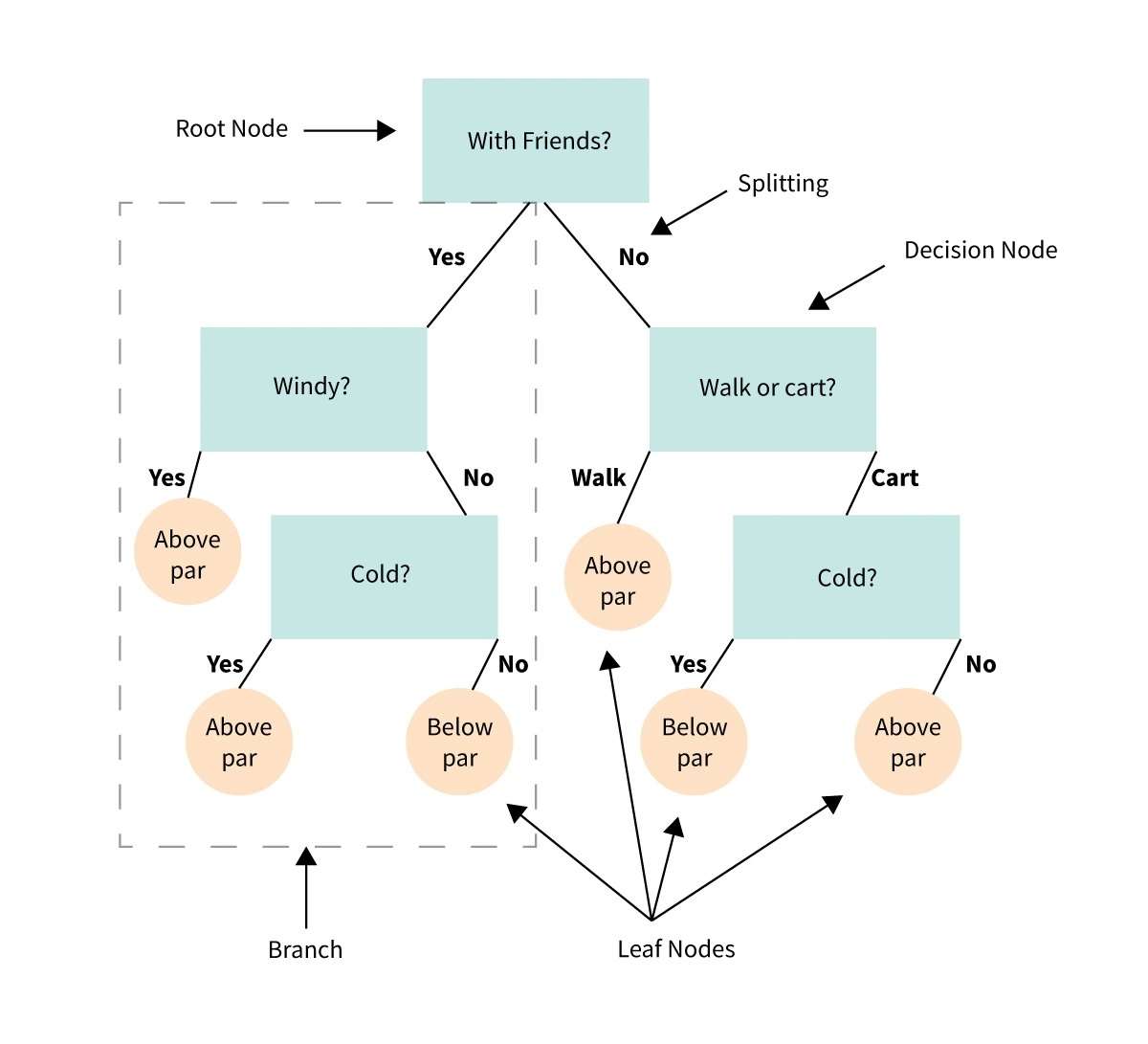
Imaginez que vous avez un problème ou une question et que vous devez faire un choix.
Un arbre de décision décompose la décision en étapes plus petites, en commençant par une question initiale et en se ramifiant en différentes réponses ou actions possibles en fonction des conditions ou des critères à chaque étape.
35. Informatique cognitive
L'informatique cognitive, en termes simples, fait référence aux systèmes informatiques ou aux technologies qui imitent les capacités cognitives humaines, telles que l'apprentissage, le raisonnement, la compréhension et la résolution de problèmes.
Il s'agit de créer des systèmes informatiques capables de traiter et d'interpréter les informations d'une manière qui ressemble à la pensée humaine.
L'informatique cognitive vise à développer des machines capables de comprendre et d'interagir avec les humains de manière plus naturelle et intelligente. Ces systèmes sont conçus pour analyser de grandes quantités de données, reconnaître des modèles, faire des prédictions et fournir des informations significatives.
Considérez l'informatique cognitive comme une tentative de faire en sorte que les ordinateurs pensent et agissent davantage comme des humains.
Cela implique de tirer parti de technologies telles que l'intelligence artificielle, l'apprentissage automatique, le traitement du langage naturel et la vision par ordinateur pour permettre aux ordinateurs d'effectuer des tâches traditionnellement associées à l'intelligence humaine.
36. Théorie de l'apprentissage informatique
La théorie de l'apprentissage informatique est une branche spécialisée dans le domaine de l'intelligence artificielle qui s'articule autour du développement et de l'examen d'algorithmes spécialement conçus pour apprendre à partir de données.
Ce domaine explore diverses techniques et méthodologies de construction d'algorithmes capables d'améliorer de manière autonome leurs performances en analysant et en traitant de grandes quantités d'informations.
En exploitant la puissance des données, la théorie de l'apprentissage informatique vise à découvrir des modèles, des relations et des informations qui permettent aux machines d'améliorer leurs capacités de prise de décision et d'effectuer des tâches plus efficacement.
Le but ultime est de créer des algorithmes capables de s'adapter, de généraliser et de faire des prédictions précises sur la base des données auxquelles ils ont été exposés, contribuant ainsi à l'avancement de l'intelligence artificielle et de ses applications pratiques.
37. Test de Turing
Le test de Turing, proposé à l'origine par le brillant mathématicien et informaticien Alan Turing, est un concept captivant utilisé pour évaluer si une machine peut présenter un comportement intelligent comparable ou pratiquement indiscernable de celui d'un être humain.
Dans le test de Turing, un évaluateur humain s'engage dans une conversation en langage naturel avec une machine et un autre participant humain sans savoir lequel est la machine.
Le rôle de l'évaluateur est de discerner quelle entité est la machine uniquement sur la base de leurs réponses. Si la machine est capable de convaincre l'évaluateur qu'elle est la contrepartie humaine, on dit qu'elle a réussi le test de Turing, démontrant ainsi un niveau d'intelligence qui reflète les capacités humaines.
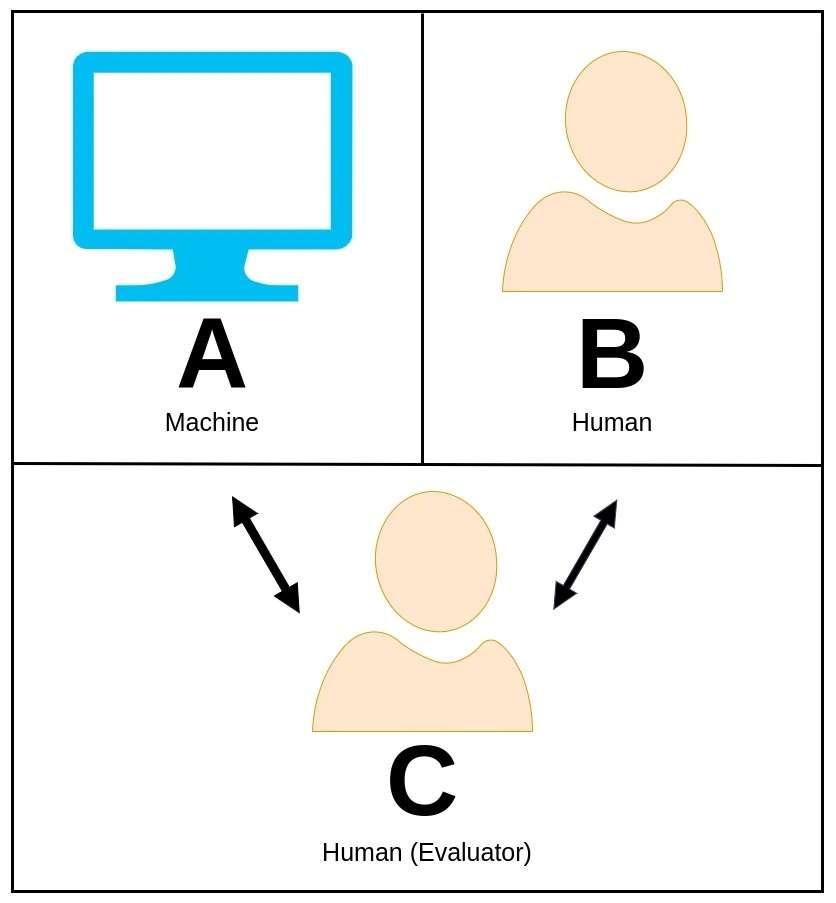
Alan Turing a proposé ce test comme un moyen d'explorer le concept d'intelligence artificielle et de poser la question de savoir si les machines peuvent atteindre une cognition de niveau humain.
En encadrant le test en termes d'indiscernabilité humaine, Turing a souligné le potentiel des machines à présenter un comportement si convaincant qu'il devient difficile de les différencier des humains.
Le test de Turing a suscité de nombreuses discussions et recherches dans les domaines de l'intelligence artificielle et des sciences cognitives. Bien que réussir le test de Turing reste une étape importante, ce n'est pas la seule mesure de l'intelligence.
Néanmoins, le test sert de référence stimulant la réflexion, stimulant les efforts continus pour développer des machines capables d'imiter l'intelligence et le comportement humains et contribuant à l'exploration plus large de ce que signifie être intelligent.
38. Apprentissage par renforcement
Apprentissage par renforcement est un type d'apprentissage qui se produit par essais et erreurs, où un "agent" (qui peut être un programme informatique ou un robot) apprend à effectuer des tâches en recevant des récompenses pour un bon comportement et en faisant face aux conséquences ou aux punitions pour un mauvais comportement.
Imaginez un scénario dans lequel l'agent essaie d'accomplir une tâche spécifique, comme naviguer dans un labyrinthe. Au début, l'agent ne connaît pas le bon chemin à suivre, alors il essaie différentes actions et explore différentes routes.
Lorsqu'il choisit une bonne action qui le rapproche du but, il reçoit une récompense, comme une « tape dans le dos » virtuelle. Cependant, s'il prend une mauvaise décision qui mène à une impasse ou l'éloigne de l'objectif, il reçoit une punition ou une rétroaction négative.
Grâce à ce processus d'essais et d'erreurs, l'agent apprend à associer certaines actions à des résultats positifs ou négatifs. Il détermine progressivement la meilleure séquence d'actions pour maximiser ses récompenses et minimiser les punitions, devenant finalement plus compétent dans la tâche.
L'apprentissage par renforcement s'inspire de la façon dont les humains et les animaux apprennent en recevant des commentaires de l'environnement.
En appliquant ce concept aux machines, les chercheurs visent à développer des systèmes intelligents capables d'apprendre et de s'adapter à différentes situations en découvrant de manière autonome les comportements les plus efficaces grâce à un processus de renforcement positif et de conséquences négatives.
39. Extraction d'entités
L'extraction d'entités fait référence à un processus dans lequel nous identifions et extrayons des informations importantes, appelées entités, à partir d'un bloc de texte. Ces entités peuvent être diverses choses comme les noms de personnes, les noms de lieux, les noms d'organisations, etc.
Imaginons que vous ayez un paragraphe décrivant un article de presse.
L'extraction d'entités impliquerait l'analyse du texte et la sélection de bits spécifiques qui représentent des entités distinctes. Par exemple, si le texte mentionne le nom d'une personne comme « John Smith », le lieu « New York » ou l'organisation « OpenAI », il s'agirait des entités que nous cherchons à identifier et à extraire.
En effectuant une extraction d'entité, nous enseignons essentiellement à un programme informatique à reconnaître et à isoler des éléments significatifs du texte. Ce processus nous permet d'organiser et de catégoriser les informations plus efficacement, ce qui facilite la recherche, l'analyse et l'extraction d'informations à partir de grands volumes de données textuelles.
Dans l'ensemble, l'extraction d'entités nous aide à automatiser la tâche consistant à identifier des entités importantes, telles que des personnes, des lieux et des organisations, dans le texte, à rationaliser l'extraction d'informations précieuses et à améliorer notre capacité à traiter et à comprendre les données textuelles.
40. Annotation linguistique
L'annotation linguistique consiste à enrichir le texte avec des informations linguistiques supplémentaires pour améliorer notre compréhension et notre analyse de la langue utilisée. C'est comme ajouter des étiquettes ou des balises utiles à différentes parties d'un texte.
Lorsque nous effectuons une annotation linguistique, nous allons au-delà des mots et des phrases de base dans un texte et commençons à étiqueter ou à baliser des éléments spécifiques. Par exemple, nous pourrions ajouter des balises de partie du discours, qui indiquent la catégorie grammaticale de chaque mot (comme le nom, le verbe, l'adjectif, etc.). Cela nous aide à comprendre le rôle que joue chaque mot dans une phrase.
Une autre forme d'annotation linguistique est la reconnaissance d'entités nommées, où nous identifions et étiquetons des entités nommées spécifiques, telles que des noms de personnes, de lieux, d'organisations ou de dates. Cela nous permet de localiser et d'extraire rapidement des informations importantes du texte.
En annotant le texte de ces manières, nous créons une représentation plus structurée et organisée de la langue. Cela peut être extrêmement utile dans une variété d'applications. Par exemple, cela aide à améliorer la précision des moteurs de recherche en comprenant l'intention derrière les requêtes des utilisateurs. Il aide également à la traduction automatique, à l'analyse des sentiments, à l'extraction d'informations et à de nombreuses autres tâches de traitement du langage naturel.
L'annotation linguistique est un outil essentiel pour les chercheurs, les linguistes et les développeurs, leur permettant d'étudier les modèles linguistiques, de créer des modèles linguistiques et de développer des algorithmes sophistiqués capables de mieux analyser et comprendre le texte.
41. Hyperparamètre
In machine learning, un hyperparamètre est comme un paramètre ou une configuration spéciale que nous devons décider avant de former un modèle. Ce n'est pas quelque chose que le modèle peut apprendre de lui-même à partir des données ; au lieu de cela, nous devons le déterminer à l'avance.
Considérez-le comme un bouton ou un interrupteur que nous pouvons ajuster pour affiner la façon dont le modèle apprend et fait des prédictions. Ces hyperparamètres régissent divers aspects du processus d'apprentissage, tels que la complexité du modèle, la vitesse d'apprentissage et le compromis entre précision et généralisation.
Par exemple, considérons un réseau de neurones. Un hyperparamètre important est le nombre de couches dans le réseau. Nous devons choisir la profondeur du réseau, et cette décision affecte sa capacité à capturer des modèles complexes dans les données.
D'autres hyperparamètres courants incluent le taux d'apprentissage, qui détermine la rapidité avec laquelle le modèle ajuste ses paramètres internes en fonction des données d'entraînement, et la force de régularisation, qui contrôle dans quelle mesure le modèle pénalise les modèles complexes pour éviter le surajustement.
La définition correcte de ces hyperparamètres est cruciale car ils peuvent avoir un impact significatif sur les performances et le comportement du modèle. Cela implique souvent un peu d'essais et d'erreurs, en expérimentant différentes valeurs et en observant comment elles affectent les performances du modèle sur un ensemble de données de validation.
42. Métadonnées
Les métadonnées font référence à des informations supplémentaires qui fournissent des détails sur d'autres données. C'est comme un ensemble de balises ou d'étiquettes qui nous donnent plus de contexte ou décrivent les caractéristiques des données principales.
Lorsque nous avons des données, qu'il s'agisse d'un document, d'une photographie, d'une vidéo ou de tout autre type d'information, les métadonnées nous aident à comprendre des aspects importants de ces données.
Par exemple, dans un document, les métadonnées peuvent inclure des détails tels que le nom de l'auteur, la date de création ou le format de fichier. Dans le cas d'une photographie, les métadonnées peuvent nous indiquer l'endroit où elle a été prise, les réglages de l'appareil photo utilisés ou même la date et l'heure de sa prise.
Les métadonnées nous aident à organiser, rechercher et interpréter les données plus efficacement. En ajoutant ces informations descriptives, nous pouvons rapidement trouver des fichiers spécifiques ou comprendre leur origine, leur objectif ou leur contexte sans avoir à parcourir tout le contenu.
43. Réduction de la dimensionnalité
La réduction de dimensionnalité est une technique utilisée pour simplifier un jeu de données en réduisant le nombre d'entités ou de variables qu'il contient. C'est comme condenser ou résumer les informations d'un ensemble de données pour le rendre plus gérable et plus facile à utiliser.
Imaginez que vous ayez un ensemble de données avec de nombreuses colonnes ou attributs représentant différentes caractéristiques des points de données. Chaque colonne ajoute à la complexité et aux exigences de calcul des algorithmes d'apprentissage automatique.
Dans certains cas, le fait d'avoir un nombre élevé de dimensions peut compliquer la recherche de modèles ou de relations significatifs dans les données.
La réduction de la dimensionnalité aide à résoudre ce problème en transformant l'ensemble de données en une représentation de dimension inférieure tout en conservant autant d'informations pertinentes que possible. Il vise à capturer les aspects ou les variations les plus importants dans les données tout en éliminant les dimensions redondantes ou moins informatives.
44. Classification du texte
La classification de texte est un processus qui consiste à attribuer des étiquettes ou des catégories spécifiques à des blocs de texte en fonction de leur contenu ou de leur signification. C'est comme trier ou organiser des informations textuelles en différents groupes ou classes pour faciliter une analyse plus approfondie ou la prise de décision.
Prenons un exemple de classification des e-mails. Dans ce scénario, nous voulons déterminer si un e-mail entrant est un spam ou non-spam (également appelé ham). Classification de texte des algorithmes analysent le contenu de l'e-mail et lui attribuent une étiquette en conséquence.
Si l'algorithme détermine que l'e-mail présente des caractéristiques communément associées au spam, il attribue l'étiquette "spam". À l'inverse, si l'e-mail semble légitime et non spam, il attribue l'étiquette "non spam" ou "ham".
La classification de texte trouve des applications dans divers domaines au-delà du filtrage des e-mails. Il est utilisé dans l'analyse des sentiments pour déterminer le sentiment exprimé dans les avis des clients (positif, négatif ou neutre).
Les articles de presse peuvent être classés en différents sujets ou catégories comme le sport, la politique, le divertissement, etc. Les journaux de chat du support client peuvent être classés en fonction de l'intention ou du problème traité.
45. IA faible
L'IA faible, également connue sous le nom d'IA étroite, fait référence aux systèmes d'intelligence artificielle qui sont conçus et programmés pour effectuer des tâches ou des fonctions spécifiques. Contrairement à l'intelligence humaine, qui englobe un large éventail de capacités cognitives, l'IA faible est limitée à un domaine ou à une tâche en particulier.
Considérez l'IA faible comme un logiciel spécialisé ou des machines qui excellent dans l'exécution de tâches spécifiques. Par exemple, un programme d'IA de jeu d'échecs peut être créé pour analyser des situations de jeu, élaborer des stratégies et affronter des joueurs humains.
Un autre exemple est un système de reconnaissance d'images qui peut identifier des objets sur des photographies ou des vidéos.
Ces systèmes d'IA sont formés et optimisés pour exceller dans leurs domaines d'expertise spécifiques. Ils s'appuient sur des algorithmes, des données et des règles prédéfinies pour accomplir efficacement leurs tâches.
Cependant, ils ne possèdent pas une intelligence générale qui leur permette de comprendre ou d'effectuer des tâches en dehors de leur domaine désigné.
46. IA forte
L'IA forte, également connue sous le nom d'IA générale ou d'intelligence artificielle générale (AGI), fait référence à une forme d'intelligence artificielle qui possède la capacité de comprendre, d'apprendre et d'effectuer n'importe quelle tâche intellectuelle qu'un être humain peut effectuer.
Contrairement à l'IA faible, qui est conçue pour des tâches spécifiques, l'IA forte vise à reproduire l'intelligence et les capacités cognitives de type humain. Il s'efforce de créer des machines ou des logiciels qui non seulement excellent dans des tâches spécialisées, mais possèdent également une compréhension et une adaptabilité plus larges pour relever un large éventail de défis intellectuels.
L'objectif d'une IA forte est de développer des systèmes capables de raisonner, de comprendre des informations complexes, d'apprendre de l'expérience, de s'engager dans des conversations en langage naturel, de faire preuve de créativité et d'autres qualités associées à l'intelligence humaine.
Essentiellement, il aspire à créer des systèmes d'IA capables de simuler ou de reproduire la pensée et la résolution de problèmes au niveau humain dans plusieurs domaines.
47. Enchaînement avant
Le chaînage en avant est une méthode de raisonnement ou de logique qui part des données disponibles et les utilise pour faire des inférences et tirer de nouvelles conclusions. C'est comme relier les points en utilisant les informations disponibles pour avancer et obtenir des informations supplémentaires.
Imaginez que vous disposiez d'un ensemble de règles ou de faits et que vous vouliez en tirer de nouvelles informations ou parvenir à des conclusions spécifiques basées sur celles-ci. Le chaînage vers l'avant fonctionne en examinant les données initiales et en appliquant des règles logiques pour générer des faits ou des conclusions supplémentaires.
Pour simplifier, considérons un scénario simple consistant à déterminer quoi porter en fonction des conditions météorologiques. Vous avez une règle qui dit : « S'il pleut, apportez un parapluie » et une autre règle qui dit : « S'il fait froid, portez une veste ». Maintenant, si vous observez qu'il pleut effectivement, vous pouvez utiliser le chaînage vers l'avant pour en déduire que vous devez apporter un parapluie.
48. Chaînage arrière
Le chaînage en arrière est une méthode de raisonnement qui commence par une conclusion ou un objectif souhaité et travaille en arrière pour déterminer les données ou les faits nécessaires pour étayer cette conclusion. C'est comme retracer vos étapes depuis le résultat souhaité jusqu'aux informations initiales requises pour y parvenir.
Pour comprendre le chaînage en arrière, considérons un exemple simple. Supposons que vous souhaitiez déterminer s'il convient d'aller nager. La conclusion souhaitée est de savoir si oui ou non la natation est appropriée en fonction de certaines conditions.
Au lieu de commencer par les conditions, le chaînage en arrière commence par la conclusion et revient en arrière pour trouver les données de support.
Dans ce cas, le chaînage à rebours impliquerait de poser des questions telles que « Est-ce qu'il fait chaud ? » Si la réponse est oui, vous demanderez alors : « Y a-t-il une piscine disponible ? » Si la réponse est encore une fois oui, vous poserez d'autres questions telles que "Y a-t-il assez de temps pour aller nager?"
En répondant de manière itérative à ces questions et en travaillant à rebours, vous pouvez déterminer les conditions nécessaires qui doivent être remplies pour soutenir la conclusion d'aller nager.
49. Heuristique
Une heuristique, en termes simples, est une règle pratique ou une stratégie qui nous aide à prendre des décisions ou à résoudre des problèmes, généralement en fonction de nos expériences passées ou de notre intuition. C'est comme un raccourci mental qui nous permet de trouver rapidement une solution raisonnable sans passer par un processus long ou exhaustif.
Face à des situations ou des tâches complexes, les heuristiques servent de principes directeurs ou de « règles empiriques » qui simplifient la prise de décision. Ils nous fournissent des orientations générales ou des stratégies qui sont souvent efficaces dans certaines situations, même si elles ne garantissent pas la solution optimale.
Par exemple, considérons une heuristique pour trouver une place de parking dans une zone bondée. Au lieu d'analyser méticuleusement chaque place disponible, vous pouvez vous fier à l'heuristique consistant à rechercher des voitures garées avec leurs moteurs en marche.
Cette heuristique suppose que ces voitures sont sur le point de partir, ce qui augmente les chances de trouver une place disponible.
50. Modélisation du langage naturel
La modélisation du langage naturel, en termes simples, est le processus de formation de modèles informatiques pour comprendre et générer le langage humain d'une manière similaire à la façon dont les humains communiquent. Cela implique d'apprendre aux ordinateurs à traiter, interpréter et générer du texte de manière naturelle et significative.
L'objectif de la modélisation du langage naturel est de permettre aux ordinateurs de comprendre et de générer le langage humain d'une manière fluide, cohérente et contextuellement pertinente.
Cela implique la formation de modèles sur de grandes quantités de données textuelles, telles que des livres, des articles ou des conversations, pour apprendre les modèles, les structures et la sémantique du langage.
Une fois formés, ces modèles peuvent effectuer diverses tâches liées à la langue, telles que la traduction, la synthèse de texte, la réponse aux questions, les interactions avec le chatbot, etc.
Ils peuvent comprendre le sens et le contexte des phrases, extraire des informations pertinentes et générer un texte grammaticalement correct et cohérent.





Soyez sympa! Laissez un commentaire