Table des matières[Cacher][Montrer]
- 1. Qu'est-ce que les scripts Python et en quoi diffère-t-il de la programmation Python ?
- 2. Comment fonctionne le garbage collection de Python ?
- 3. Expliquez la différence entre une liste et un tuple
- 4. Que sont les compréhensions de listes et donnez un exemple de leur utilisation ?
- 5. Décrivez la différence entre deepcopy et copy ?
- 6. Comment le multithreading est-il réalisé en Python et en quoi diffère-t-il du multitraitement ?
- 7. Que sont les décorateurs et comment sont-ils utilisés en Python ?
- 8. Expliquez les différences entre *args et **kwargs ?
- 9. Comment garantiriez-vous qu’une fonction ne peut être appelée qu’une seule fois à l’aide de décorateurs ?
- 10. Comment fonctionne l'héritage en Python ?
- 11. Qu'est-ce que la surcharge et le remplacement de méthodes ?
- 12. Décrivez le concept de polymorphisme avec un exemple.
- 13. Expliquez la différence entre les méthodes d'instance, de classe et statiques.
- 14. Décrivez le fonctionnement interne d'un ensemble Python.
- 15. Comment un dictionnaire est-il implémenté en Python ?
- 16. Expliquez les avantages de l'utilisation de tuples nommés.
- 17. Comment fonctionne le bloc try-sauf ?
- 18. Quelle est la différence entre les instructions raise et assert ?
- 19. Comment lire et écrire des données à partir d'un fichier binaire en Python ?
- 20. Expliquez l'instruction with et ses avantages lorsque vous travaillez avec des E/S de fichiers.
- 21. Comment créeriez-vous un module singleton en Python ?
- 22. Nommez quelques façons d'optimiser l'utilisation de la mémoire dans un script Python.
- 23. Comment extrayez-vous toutes les adresses e-mail d’une chaîne donnée à l’aide d’une expression régulière ?
- 24. Expliquer le modèle de conception Factory et son application en Python
- 25. Quelle est la différence entre un itérateur et un générateur ?
- 26. Comment fonctionne le décorateur @property ?
- 27. Comment créeriez-vous une API REST de base en Python ?
- 28. Décrivez comment utiliser la bibliothèque de requêtes pour effectuer une requête HTTP POST.
- 29. Comment vous connecteriez-vous à une base de données PostgreSQL à l'aide de Python ?
- 30. Quel est le rôle des ORM en Python et nommez-en un populaire ?
- 31. Comment profileriez-vous un script Python ?
- 32. Expliquer le GIL (Global Interpreter Lock) dans CPython
- 33. Expliquez l'async/wait de Python. En quoi est-ce différent du filetage traditionnel ?
- 34. Décrivez comment vous utiliseriez concurrent.futures de Python.
- 35. Comparez Django et Flask en termes de cas d'utilisation et d'évolutivité.
- Conclusion
À une époque où la technologie existe dans tous les aspects de nos vies, Python les scripts apparaissent comme un élément clé de l’infrastructure informatique énorme et complexe, ouvrant la voie à un paradigme de facilité d’utilisation et d’utilité.
La force de Python réside non seulement dans sa simplicité syntaxique et sa lisibilité, mais également dans son adaptabilité, qui lui permet de combler facilement le fossé entre les scripts à faible risque de niveau débutant et le développement de logiciels à enjeux élevés au niveau de l'entreprise.
Les vastes bibliothèques et frameworks de Python ouvrent la voie à une aventure technique fluide et imaginative, que ce soit dans les domaines de l'analyse de données, du développement Web, de l'intelligence artificielle ou des serveurs réseau.
En plus d'être un outil de résolution de problèmes, Python favorise également une atmosphère dans laquelle l'innovation est non seulement accueillie mais aussi naturellement intégrée grâce à ses énormes bibliothèques et frameworks, tels que Django pour le développement Web ou Pandas pour l'analyse des données.
Dans un monde où les données sont reines, Python fournit des outils puissants pour manipuler, analyser et visualisation des données, ce qui donne lieu à des informations exploitables et guide les choix stratégiques.
Python n'est pas simplement un langage de programmation ; c'est également une communauté florissante, une plaque tournante où les développeurs, les data scientists et les passionnés de technologie se réunissent pour inventer, créer et faire passer l'industrie informatique au niveau supérieur.
Les développeurs Python sont recherchés par les entreprises de toutes tailles, des startups naissantes aux organisations bien établies, en tant que catalyseurs de l'innovation, de l'amélioration des processus et de l'amélioration du service client.
De plus, sa nature open source favorise une culture d'apprentissage partagé et de croissance collaborative, garantissant qu'elle continuera à progresser avec un monde technologique en évolution rapide.
Apprendre Python en 2023 est un investissement dans un langage qui promet de rester actuel, flexible et essentiel pour gérer les flux et reflux de la technologie.
Il donne accès aux domaines de machine learning, l’analyse des données, la cybersécurité et bien plus encore, autant d’éléments cruciaux pour façonner l’ère numérique.
Par conséquent, nous avons compilé pour vous une liste des meilleures questions d’entretien sur les scripts Python, qui vous permettront de briller en tant que développeur et de réussir l’entretien.
1. Qu'est-ce que les scripts Python et en quoi diffère-t-il de la programmation Python ?
Python est connu pour son adaptabilité et fournit à la fois des compétences en matière de script et de programmation, chacune adaptée à des tâches et à des objectifs particuliers.
Les scripts Python sont fondamentalement le processus d'écriture de scripts plus courts et plus efficaces destinés à gérer des fichiers, à automatiser des processus répétitifs ou à prototyper rapidement des idées.
Ces scripts, souvent autonomes, exécutent efficacement une liste d'actions dans l'ordre.
La programmation Python, en revanche, va plus loin, en mettant l'accent sur la création de programmes plus volumineux et plus complexes avec un code structuré utilisant des bibliothèques, des frameworks et les meilleures pratiques.
Bien qu'ils proviennent tous deux du même langage, les scripts simplifient et automatisent tandis que la programmation crée et invente. Cette différence se voit dans la portée et les objectifs de chaque discipline.
2. Comment fonctionne le garbage collection de Python ?
Le système de récupération de place de Python est un élément clé pour garantir une gestion efficace de la mémoire.
Il fonctionne sans relâche en arrière-plan pour protéger les ressources système contre l'épuisement des fuites de mémoire. Cette approche automatisée est principalement basée sur la méthode de comptage de références, où chaque objet garde une trace du nombre d'autres objets qui le référencent.
Cet objet devient candidat à la récupération de mémoire lorsque ce nombre tombe à 0, ce qui indique que l'élément n'est plus nécessaire.
De plus, Python utilise un garbage collector cyclique, que l'approche simple du comptage de références pourrait manquer, pour rechercher et effacer les cycles de référence.
Ainsi, la stratégie à double couche de comptage de références et de garbage collection cyclique permet une utilisation prudente et efficace de la mémoire, renforçant les performances de Python, en particulier dans les applications gourmandes en mémoire.
Un exemple de code simple montrant comment s'interfacer avec le système de récupération de place de Python est fourni ci-dessous :
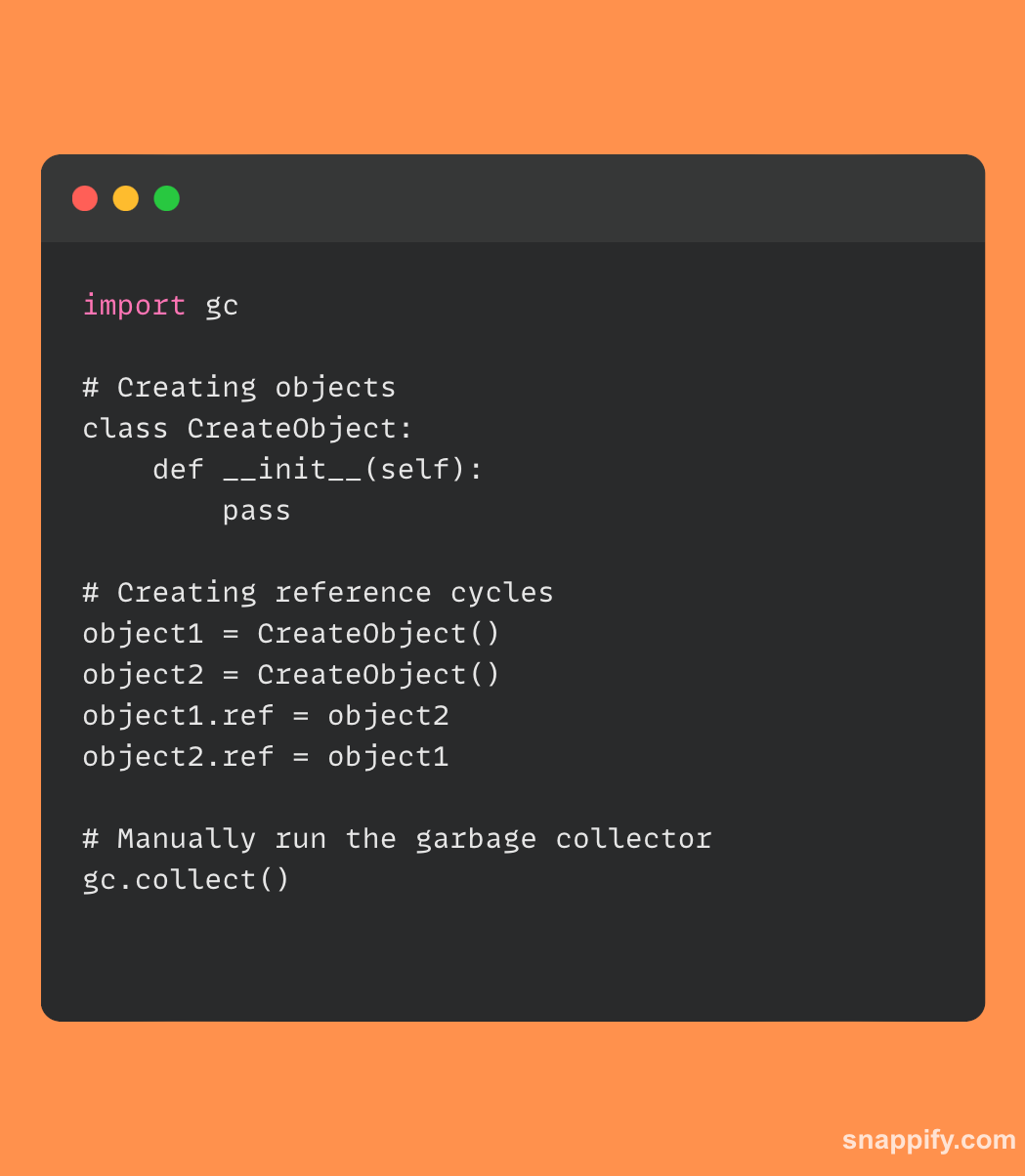
Deux objets sont générés dans cet extrait et croisés pour établir un cycle. Le garbage collector est ensuite déclenché manuellement à l'aide de gc.collect(), montrant comment les programmeurs peuvent interagir avec le mécanisme de gestion de la mémoire de Python si nécessaire.
3. Expliquez la différence entre une liste et un tuple
Les listes et les tuples sont des conteneurs efficaces pour les données dans le monde Python, mais ils ont des propriétés différentes qui répondent à différents objectifs de programmation.
Une liste, indiquée par des crochets, permet une flexibilité en permettant le redimensionnement changeant et dynamique de ses composants.
En revanche, un tuple entre parenthèses est immuable et conserve son état initial pendant l'exécution de la fonction.
Les tuples donnent une séquence solide et immuable tandis que les listes offrent une flexibilité, permettant une variété d'utilisations dans le traitement et la modification des données.
Voici un peu Code Python exemple montrant comment utiliser à la fois les listes et les tuples :

4. Que sont les compréhensions de listes et donnez un exemple de leur utilisation ?
Les compréhensions de listes constituent un moyen efficace et expressif de créer des listes en Python qui combinent la puissance de la logique conditionnelle et des boucles en une seule ligne de code compréhensible.
Ils fournissent une syntaxe simplifiée pour convertir nos intentions en liste, combinant itération et conditionnalité en une structure unique et raffinée.
Les compréhensions de listes donnent essentiellement aux programmeurs la possibilité de créer des listes en exécutant des opérations sur chaque membre et éventuellement en les filtrant en fonction de certains critères, tout en gardant une base de code bien rangée.
Cette fonctionnalité expressive allie efficacité et clarté dans la programmation Python en améliorant la lisibilité tout en offrant éventuellement des gains de calcul dans certaines circonstances.
Une illustration d'une compréhension de liste Python est présentée ci-dessous :
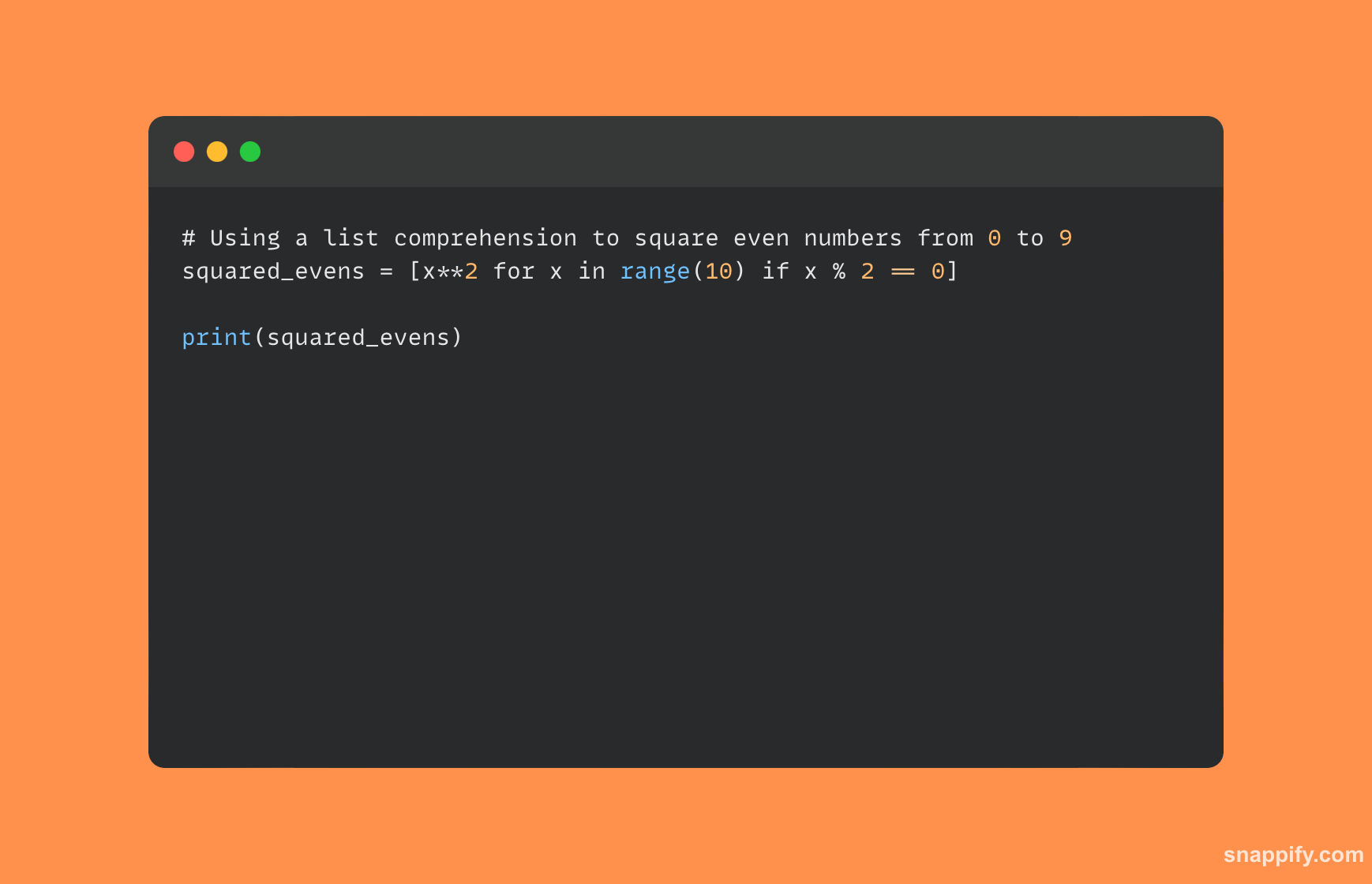
5. Décrivez la différence entre deepcopy et copy ?
La profondeur et l'intégrité des objets dupliqués déterminent la différence entre deepcopy ainsi que copy en Python.
En créant un nouvel élément tout en conservant les références aux objets imbriqués d'origine, un copy crée une réplique superficielle qui tisse leurs destins dans un réseau d'interdépendance.
Deepcopy crée un clone totalement autonome en copiant récursivement l'objet original et tous ses composants hiérarchiques, en coupant toutes les connexions et en maintenant l'autonomie dans les changements.
Par conséquent, en fonction du niveau requis d’indépendance des objets, deepcopy assure une reproduction complète alors que la copie donne simplement une duplication au niveau de la surface.
Voici un code pour montrer comment copy ainsi que deepcopy varient les uns des autres :
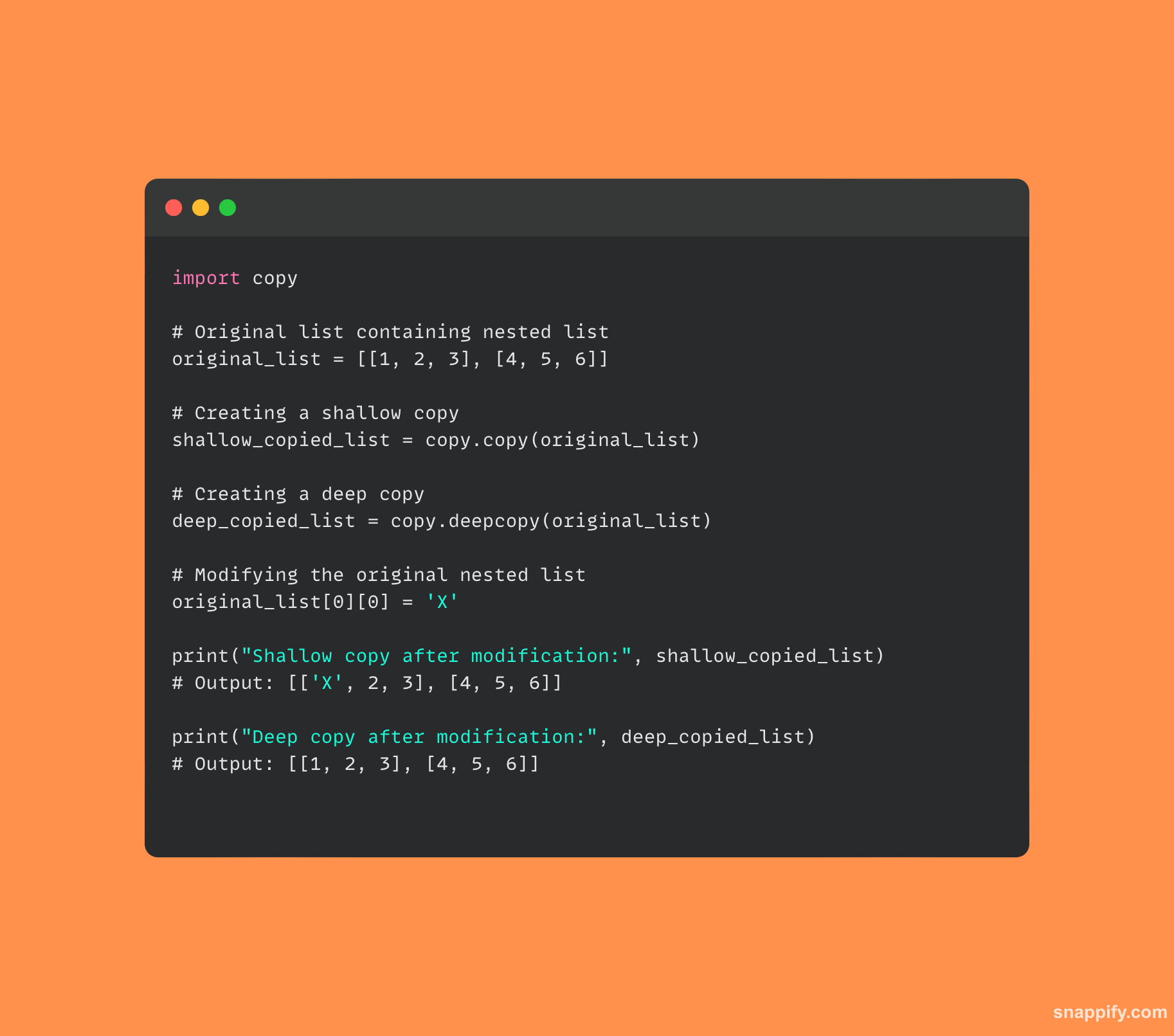
6. Comment le multithreading est-il réalisé en Python et en quoi diffère-t-il du multitraitement ?
Le multitraitement et le multithreading de Python traitent tous deux de l'exécution simultanée, mais en utilisant des paradigmes différents.
Utilisant plusieurs threads au sein d’un seul processus, le multithreading permet l’exécution de tâches simultanées dans un espace mémoire partagé.
Cependant, une véritable exécution de threads parallèles peut être difficile à réaliser en raison du Global Interpreter Lock (GIL) de Python.
D'autre part, le multitraitement utilise plusieurs processus, chacun avec un interpréteur Python et un espace mémoire distincts, garantissant un véritable parallélisme.
Pour les activités liées aux E/S, le multithreading est plus léger et plus pratique, mais le multitraitement excelle dans les situations liées au processeur où une véritable exécution parallèle est cruciale.
Voici un bref exemple de code qui compare le multitraitement au multithreading :
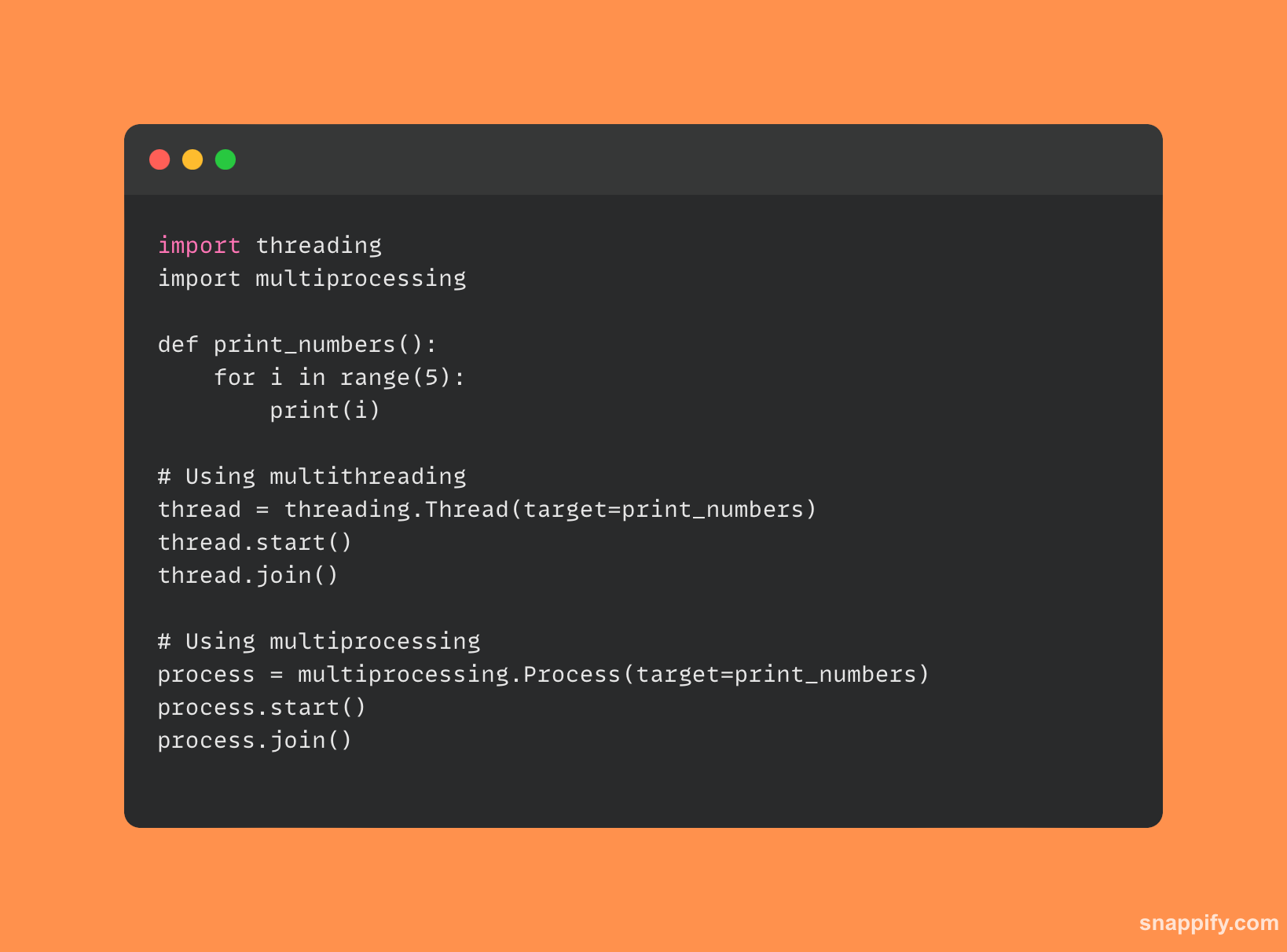
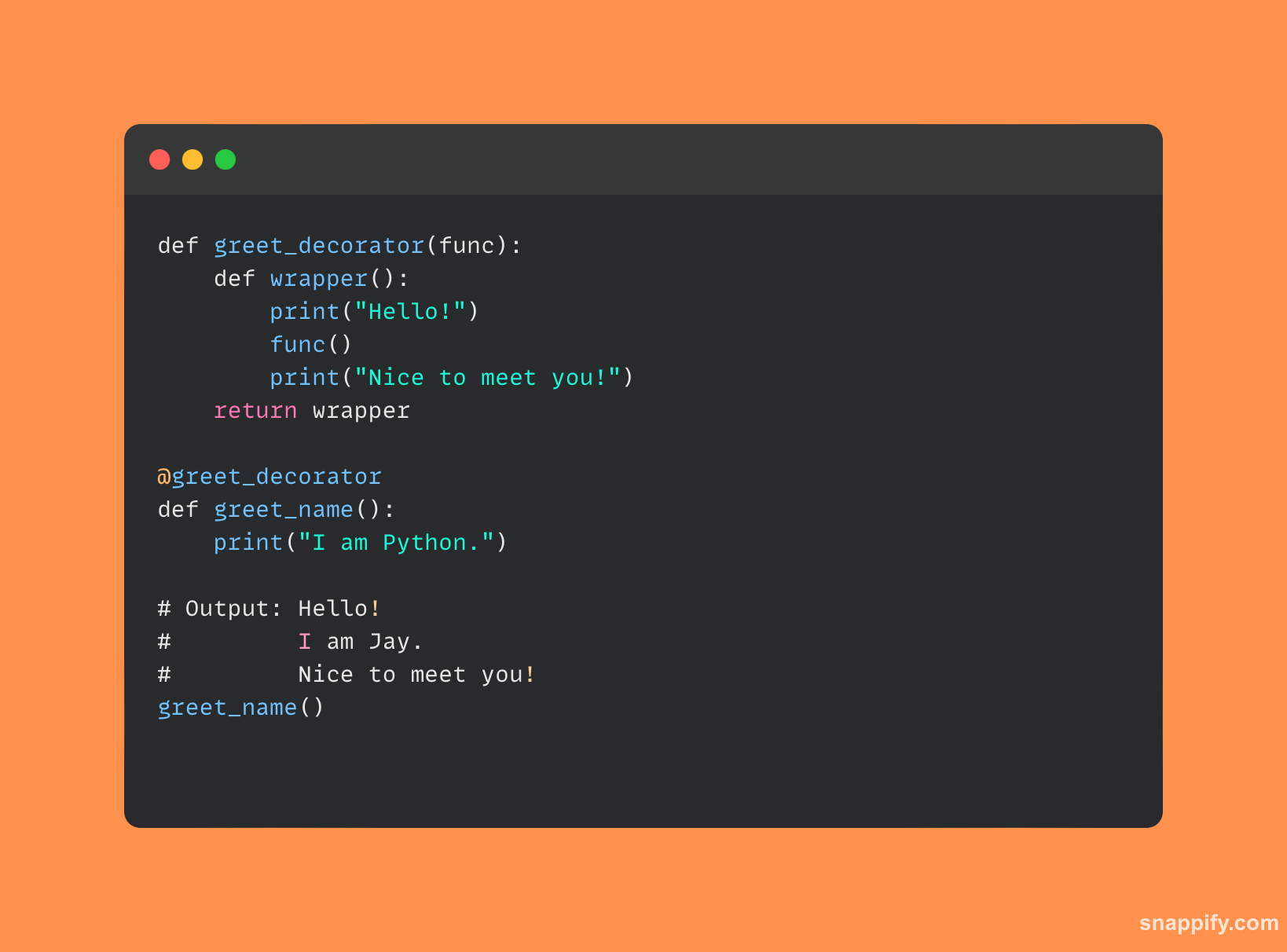
7. Que sont les décorateurs et comment sont-ils utilisés en Python ?
En Python, les décorateurs combinent élégamment utilité et simplicité tout en augmentant ou en modifiant subtilement les fonctions.
Considérez les décorateurs comme un voile qui enveloppe magnifiquement une fonction, ajoutant à ses capacités sans changer sa nature essentielle.
Ces entités, désignées par le symbole @, acceptez une fonction en entrée et affichez une toute nouvelle fonction, offrant un moyen transparent de modifier le comportement de la fonction.
Les décorateurs confèrent un large éventail de fonctionnalités, de la journalisation au contrôle d'accès, en améliorant le code avec de nouvelles couches tout en conservant une syntaxe claire et compréhensible.
Voici un exemple de code Python simple montrant comment les décorateurs sont utilisés :
8. Expliquez les différences entre *args et **kwargs ?
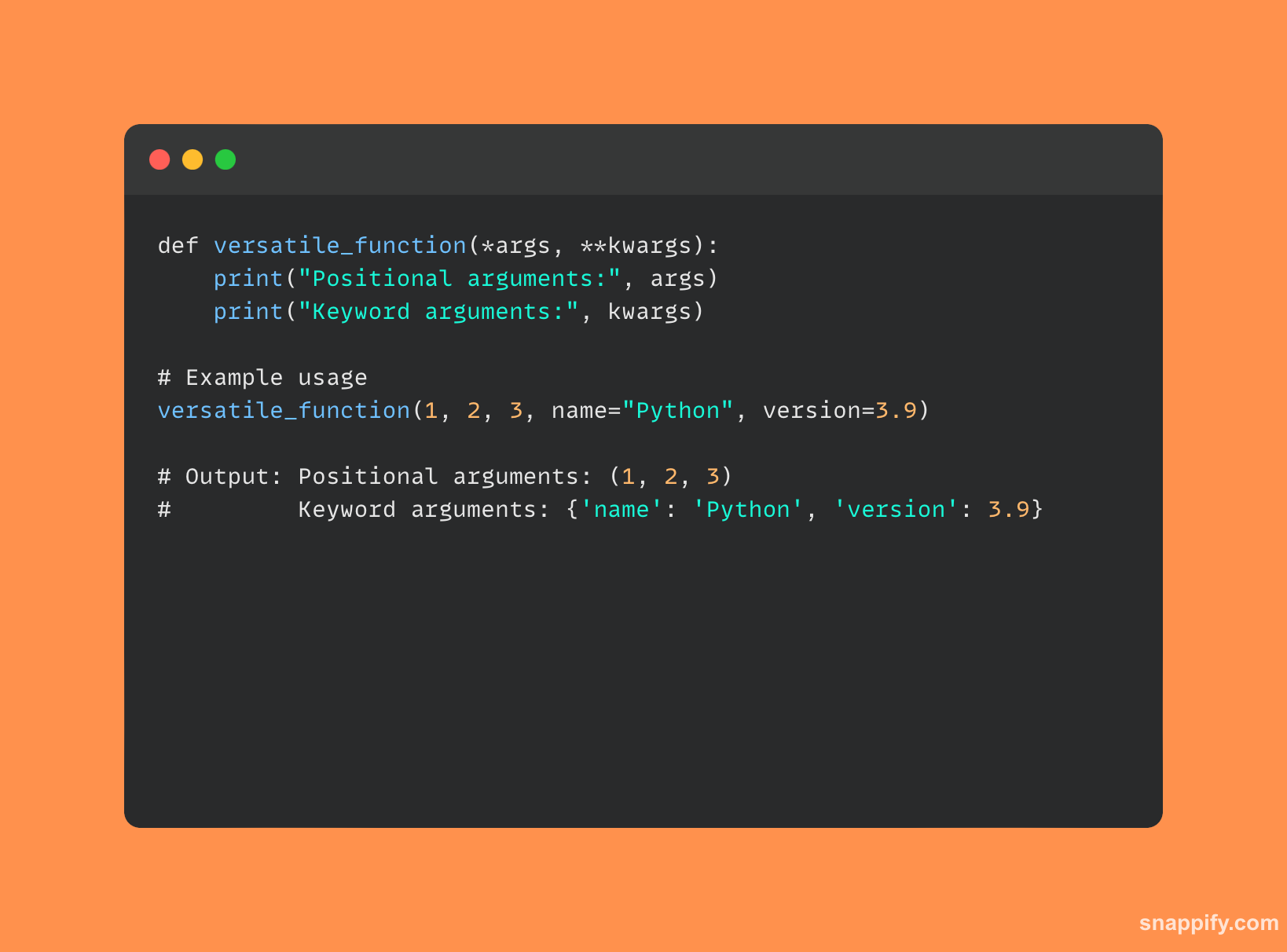
Les paramètres flexibles de Python *args ainsi que **kwargs permettre aux fonctions de prendre correctement une gamme d'arguments.
Une fonction peut accepter n'importe quel nombre d'arguments de position en utilisant le *args paramètre, qui les regroupe dans un tuple.
En revanche, une fonction peut accepter n'importe quel nombre d'arguments-clés en utilisant le **kwargs paramètre, qui les regroupe dans un dictionnaire.
Les deux agissent comme des canaux de dynamisme et de flexibilité dans la construction et l’appel des fonctions, **kwargs offrant une méthode structurée pour gérer une quantité arbitraire d'entrées de mots-clés tout en *args gère gracieusement les entrées de position non définies.
Ensemble, ils améliorent la flexibilité et la durabilité des fonctions Python en gérant habilement et clairement un large éventail de scénarios d'application.
Un exemple de code Python qui utilise *args ainsi que **kwargs est fourni ci-dessous:
9. Comment garantiriez-vous qu’une fonction ne peut être appelée qu’une seule fois à l’aide de décorateurs ?
Les décorateurs Python savent allier l'utilité à l'élégance, ce qui est nécessaire pour garantir la singularité d'exécution d'une fonction.
Il est possible de concevoir un décorateur pour enfermer une fonction et garder une trace de ces informations à l'intérieur en conservant un état interne.
La fonction encapsulée est appelée une fois et exécutée, et le décorateur enregistre l'appel. Les appels suivants sont bloqués, protégeant la fonction des exécutions répétées en garantissant qu'elle ne soit pas perturbée.
Avec l'aide de cette application de décorateurs, les appels de fonctions peuvent être contrôlés de manière subtile mais efficace, garantissant l'unicité d'une manière à la fois belle et discrète.
Voici un exemple de code pour montrer comment les décorateurs peuvent être utilisés pour limiter le nombre de fois qu'une fonction peut être appelée :

10. Comment fonctionne l'héritage en Python ?
Le système d'héritage de Python crée un réseau de liens hiérarchiques entre les classes, permettant de partager les caractéristiques et les fonctions d'une classe parent avec sa progéniture.
Il gère une lignée qui permet aux classes dérivées (enfants) d'hériter, de remplacer ou d'ajouter des fonctionnalités de leurs classes de base (parentes), favorisant ainsi la réutilisation du code et une conception logique et hiérarchique.
La classe enfant peut introduire ses caractéristiques et comportements uniques en plus d'absorber les capacités de son parent, créant ainsi un modèle objet solide et multicouche.
Dans cette approche, l'héritage distribue habilement les fonctionnalités dans les artères de la hiérarchie des classes, créant ainsi une architecture orientée objet unifiée et bien organisée.
Le code Python simplifié suivant illustre l'héritage :

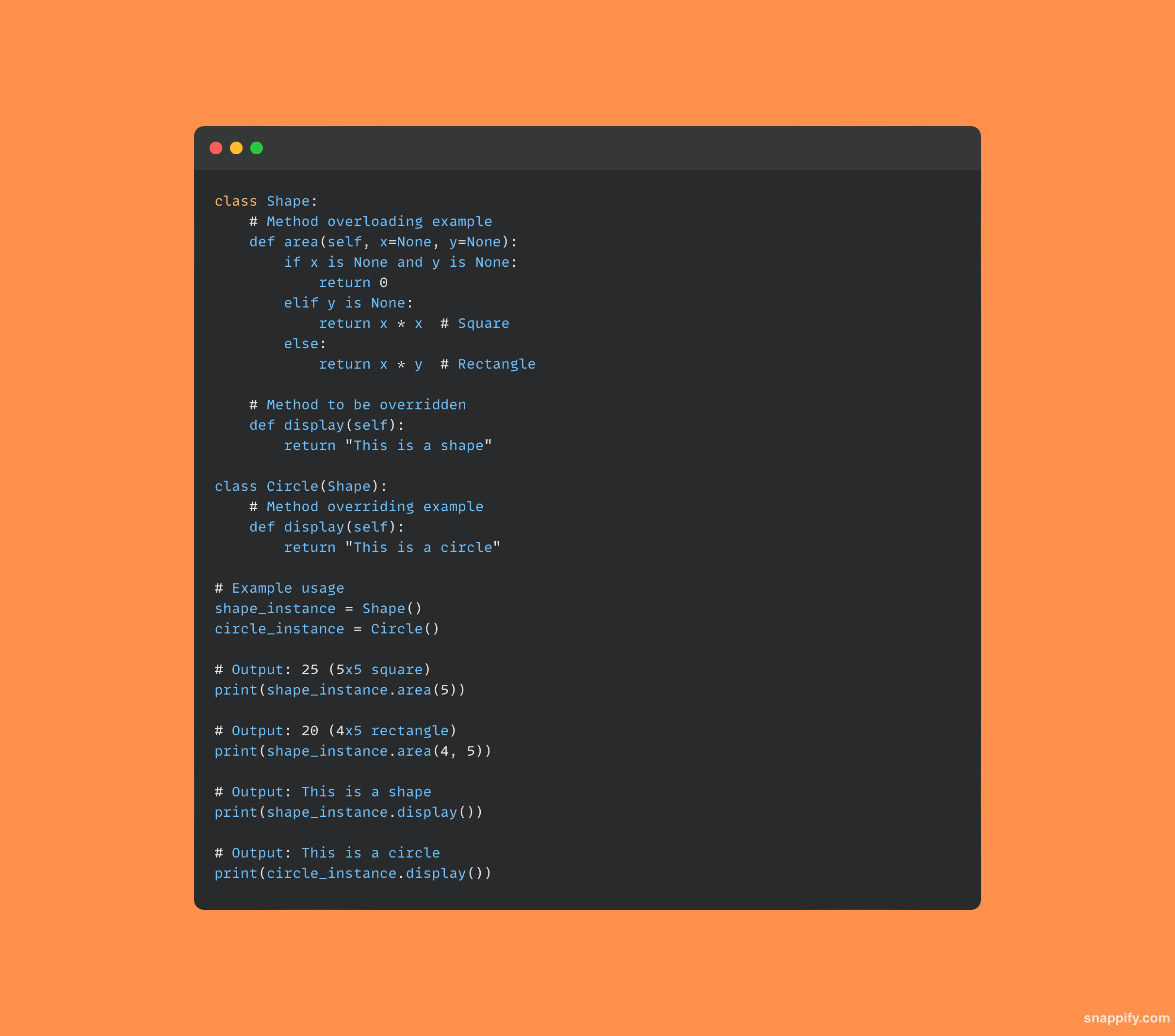
11. Qu'est-ce que la surcharge et le remplacement de méthodes ?
Les deux pierres angulaires de programmation orientée objet, la surcharge et le remplacement de méthodes permettent aux développeurs d'utiliser le même nom de méthode à plusieurs fins.
Une seule méthode peut prendre en charge une variété de types de données et de nombres d'arguments en ayant de nombreuses signatures grâce à la surcharge de méthode.
D'un autre côté, le remplacement de méthode permet à une sous-classe d'ajouter sa propre implémentation spéciale à une méthode déjà définie dans sa classe parent, garantissant ainsi que la version de l'enfant est appelée.
Ensemble, ces stratégies améliorent l'adaptabilité en permettant des comportements de méthode qui dépendent du contexte et des exigences particulières de l'application.
Voici un exemple de code qui illustre les deux concepts :
12. Décrivez le concept de polymorphisme avec un exemple.
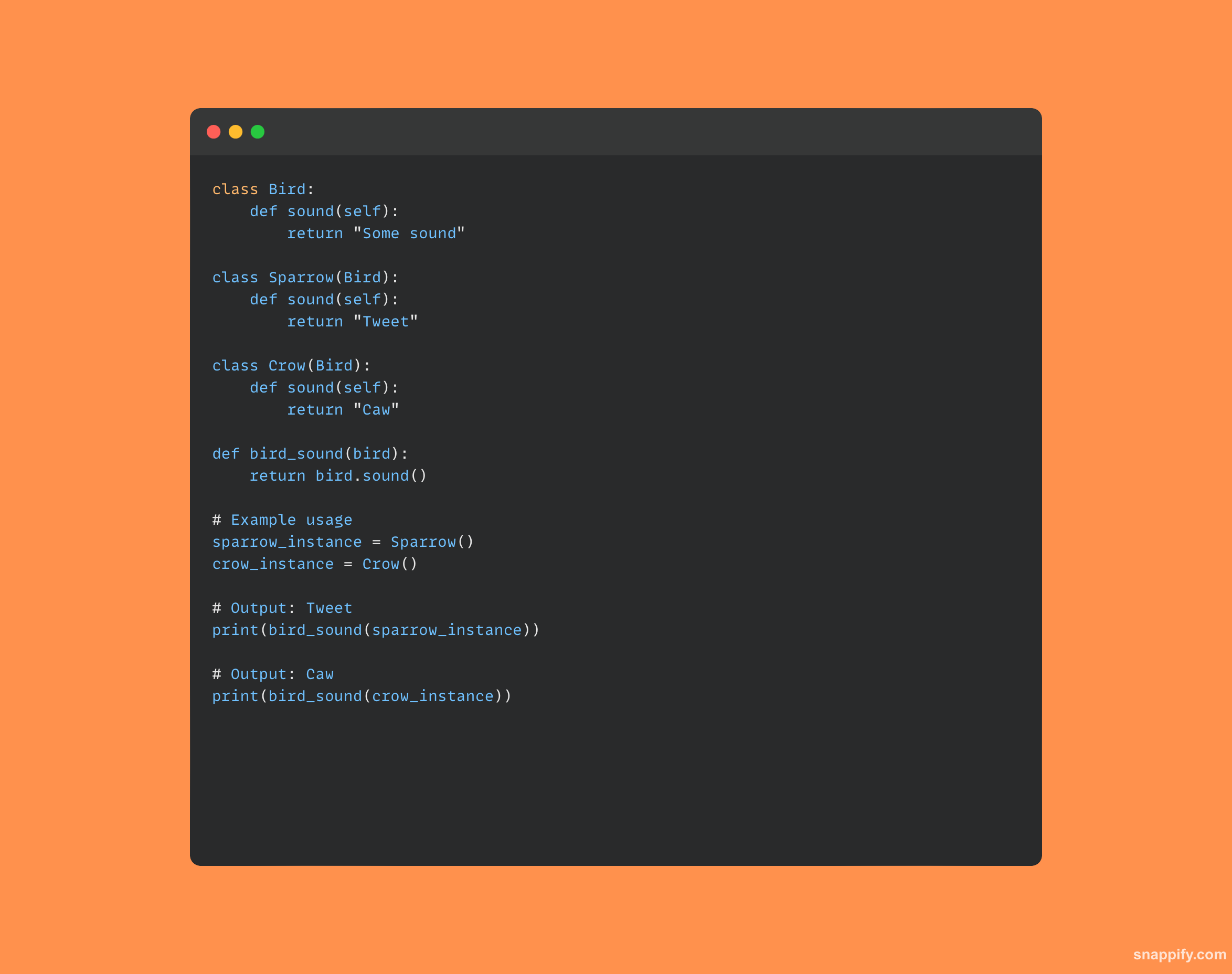
Le polymorphisme est la pratique consistant à utiliser une seule interface pour différents types de données.
Cette idée garantit l'adaptabilité et l'évolutivité de la conception en donnant aux méthodes la liberté de traiter les objets de plusieurs manières en fonction de leur type ou classe intrinsèque.
Essentiellement, le polymorphisme permet des interactions unifiées tout en conservant des comportements distincts en permettant aux objets de différentes classes d'être considérés comme des instances de la même classe par héritage.
Cette fonctionnalité dynamique encourage la simplicité du code en permettant à une seule fonction ou à un seul opérateur d'interagir avec une variété de types d'objets sans aucun problème.
Voici un exemple de code clair qui démontre le polymorphisme :
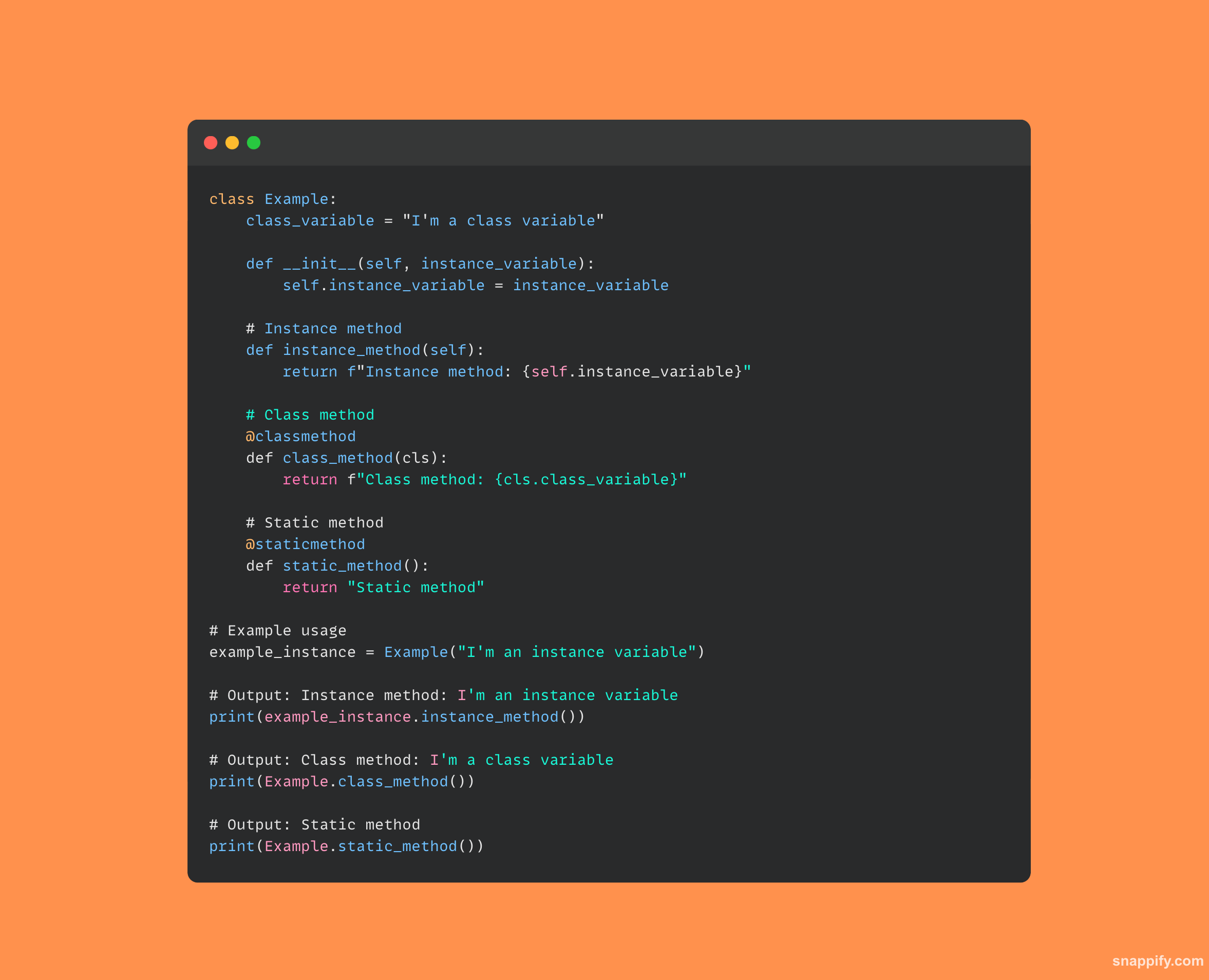
13. Expliquez la différence entre les méthodes d'instance, de classe et statiques.
Les méthodes d'instance, de classe et statiques ont toutes leurs propres manières d'interagir avec les données d'objet et de classe en Python.
Le type le plus répandu, les méthodes d'instance, agit sur les données d'instance de classe et prend en entrée une instance de la classe, généralement appelée self.
La classe elle-même (souvent appelée cls) est acceptée comme argument par les méthodes de classe, désignées par @classmethod, et manipulent les données au niveau de la classe.
Les méthodes statiques, désignées par le symbole dièse @staticmethod, n'affectent pas les états de classe ou d'instance puisqu'il s'agit de fonctions autonomes contenues dans la classe et ne prennent pas self ou cls comme premier paramètre.
Étant donné que chaque type de méthode offre un accès et une utilité différents, les architectures orientées objet sont flexibles et précises.
À titre d'exemple d'un de ces types de méthodes dans le code :
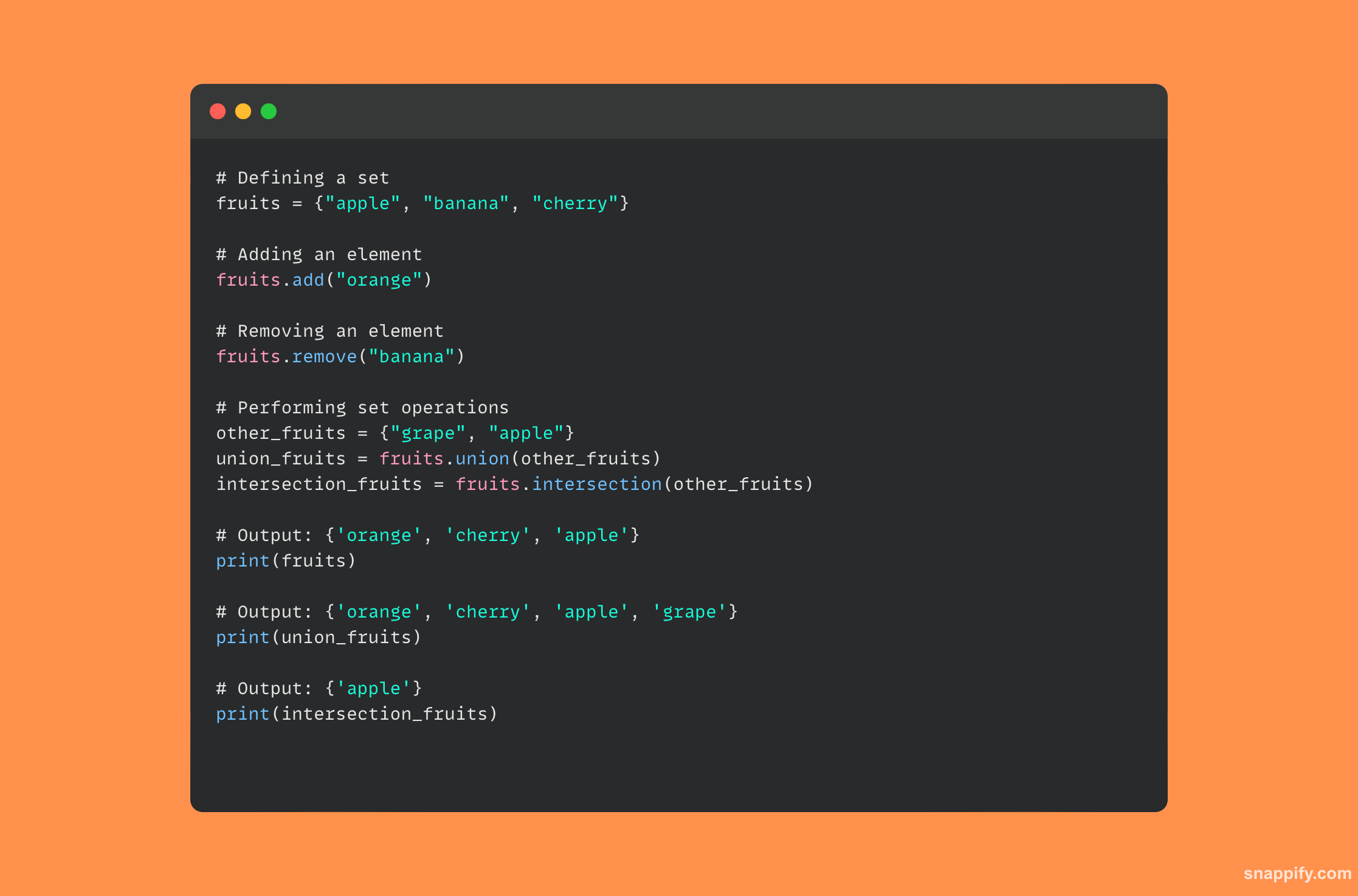
14. Décrivez le fonctionnement interne d'un ensemble Python.
Un interne Structure de données appelée table de hachage est utilisée par un ensemble Python, qui est une collection non ordonnée de composants distincts, pour effectuer des opérations puissantes et efficaces.
Python utilise une fonction de hachage pour gérer et récupérer rapidement les données lorsqu'un élément est ajouté à un ensemble, transformant l'élément en une valeur de hachage qui définit ensuite son emplacement en mémoire.
En facilitant les vérifications rapides des membres et en supprimant les entrées en double, cette technique garantit que chaque élément d'un ensemble est unique et facilement accessible.
Par conséquent, l’architecture inhérente des ensembles tend à optimiser les opérations telles que les unions, les croisements et les différences, ce qui donne lieu à une structure de données petite et efficace.
Voici un morceau de code qui montre comment interagir simplement avec un ensemble Python :
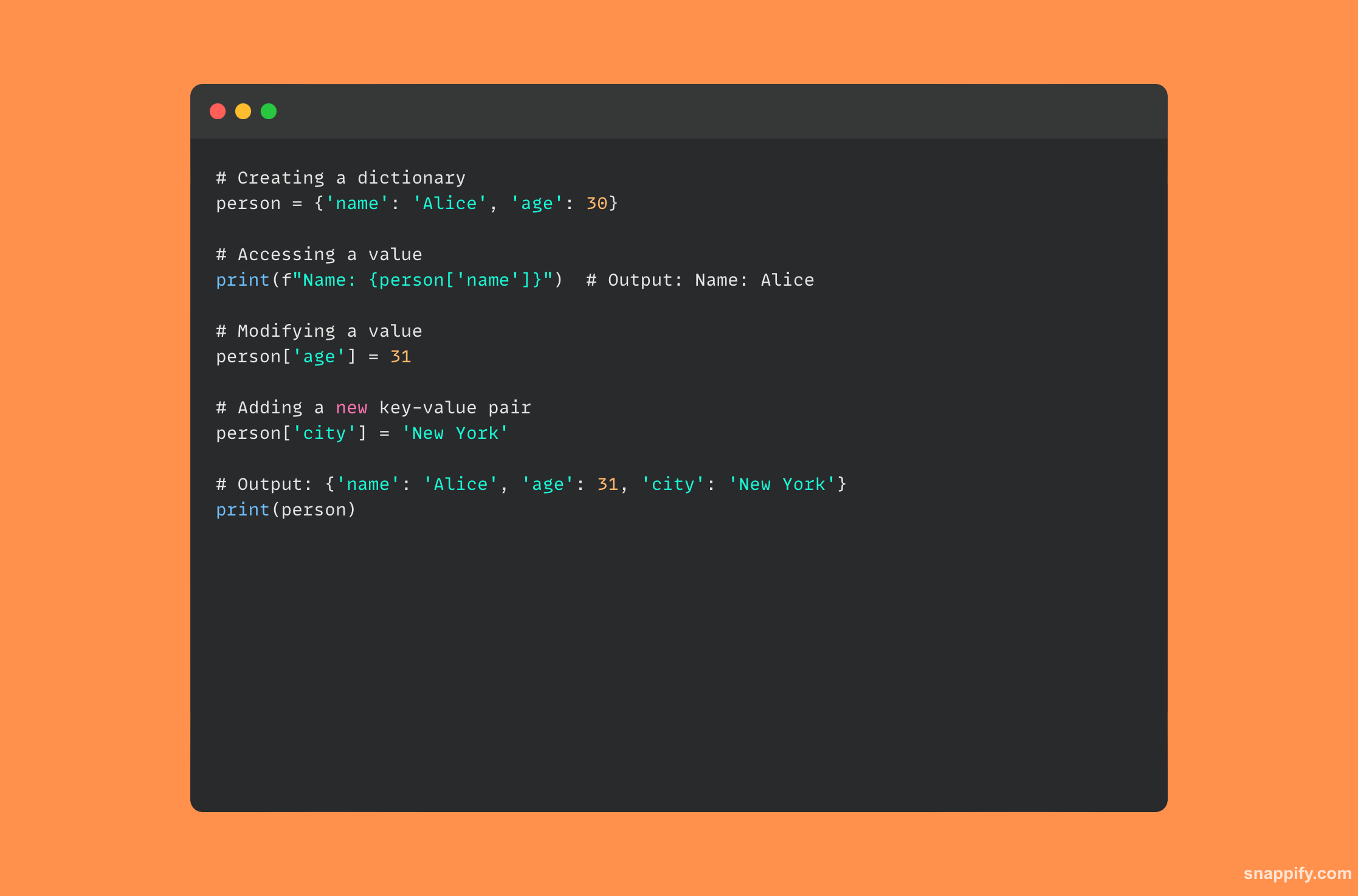
15. Comment un dictionnaire est-il implémenté en Python ?
Une table de hachage sert de base à un dictionnaire en Python et permet une récupération et une manipulation rapides des données. Les dictionnaires sont des collections dynamiques et non ordonnées de paires clé-valeur.
Python utilise une fonction de hachage pour calculer le hachage de la clé lorsqu'une paire clé-valeur est émise, localisant ainsi l'emplacement de l'adresse de stockage de la valeur en mémoire.
Comme la fonction de hachage pointe immédiatement l'interpréteur vers l'adresse mémoire, cette conception offre un accès rapide aux données basées sur des clés et est étonnamment efficace dans les opérations de récupération, d'insertion et de suppression.
Les développeurs peuvent gérer les données facilement et efficacement grâce à la combinaison attrayante de vitesse et de flexibilité offerte par les dictionnaires Python.
Vous trouverez ci-dessous un exemple de code montrant comment utiliser un dictionnaire Python :
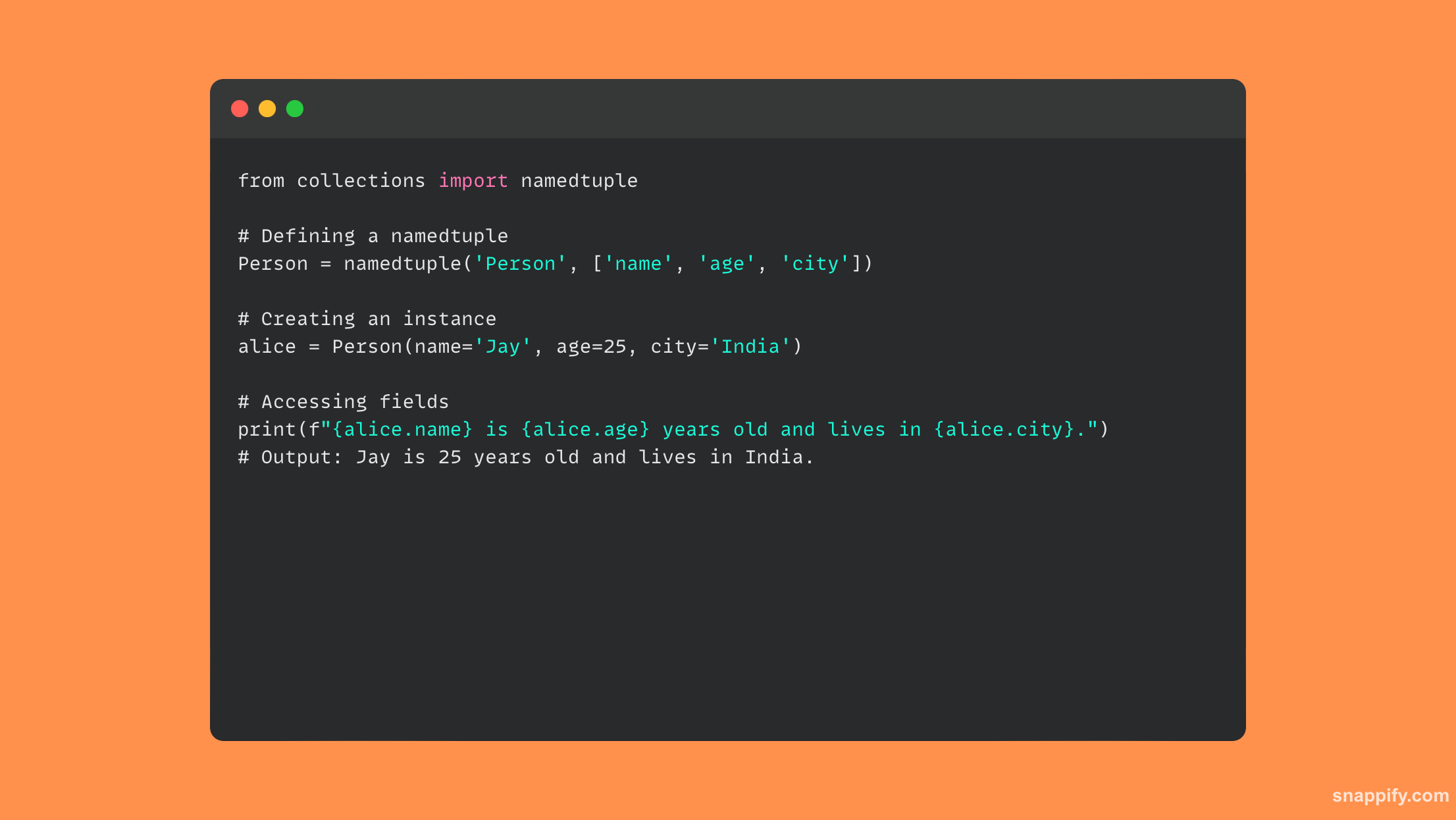
16. Expliquez les avantages de l'utilisation de tuples nommés.
L'utilisation de tuples nommés en Python combine habilement l'expressivité des classes avec la simplicité des tuples, ce qui donne lieu à une petite structure de données explicite.
Le tuple traditionnel est étendu par des tuples nommés, qui conservent l'immuabilité et l'efficacité de la mémoire des tuples tout en ajoutant des champs nommés pour améliorer la lisibilité du code et l'auto-description.
Les tuples nommés favorisent un code clair, compréhensible et performant en établissant des objets simples et légers sans aucune méthode, améliorant ainsi à la fois l'expérience du développeur et les performances de calcul.
En conséquence, les tuples nommés se transforment en un outil puissant qui améliore la structure et la lisibilité des données sans compromettre la vitesse.
Un exemple de code illustrant l'utilisation de tuples nommés est présenté ci-dessous :
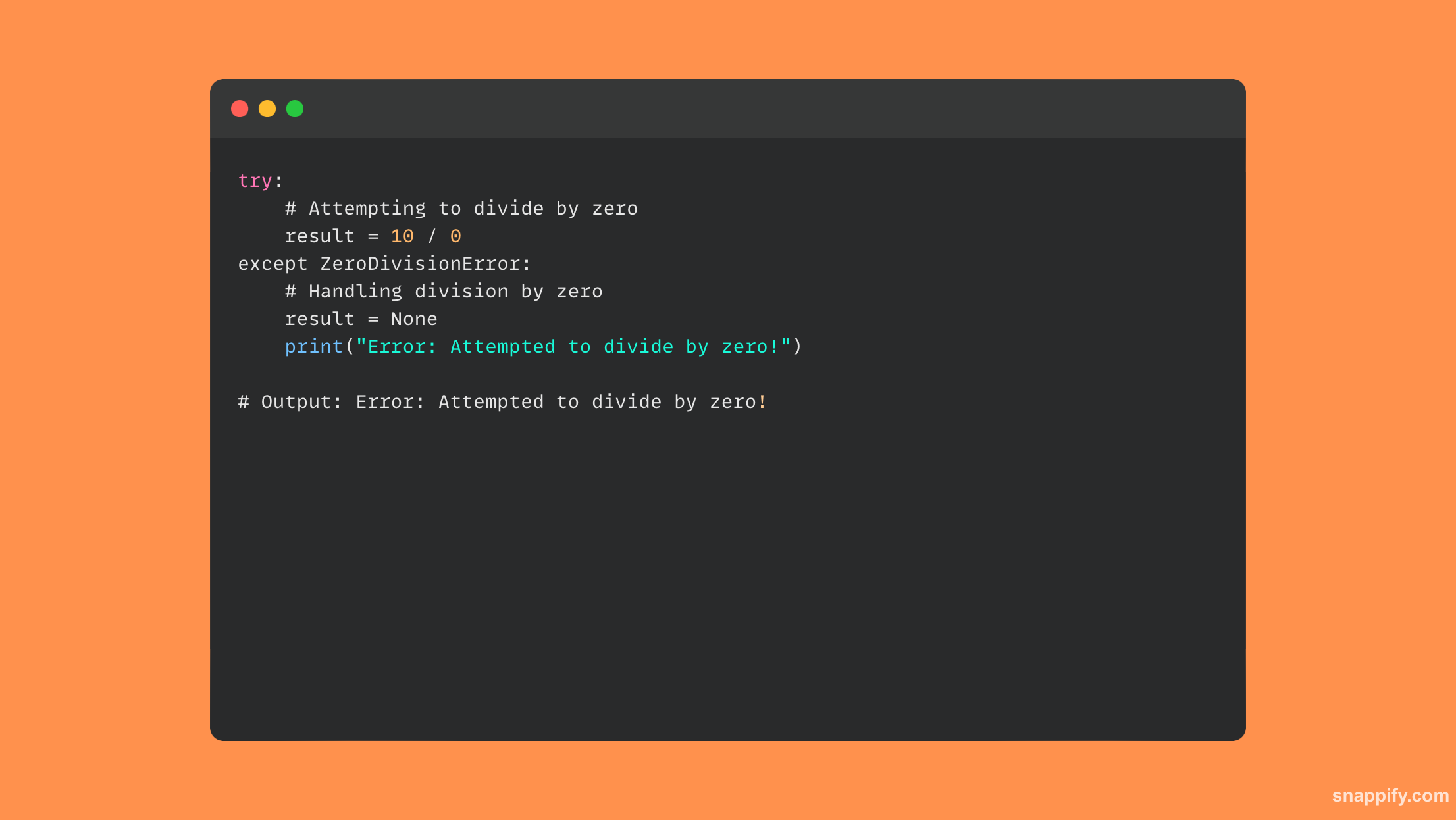
17. Comment fonctionne le bloc try-sauf ?
Le bloc try-sauf agit comme une sentinelle dans la syntaxe expressive Python, se protégeant avec vigilance contre les irrégularités d'exécution et maintenant le bon déroulement de l'exécution malgré les problèmes potentiels.
Lorsqu'un bloc try rencontre une erreur, le contrôle est automatiquement transféré vers le bloc except approprié, où le problème est résolu en signalant, en corrigeant ou peut-être en renvoyant l'exception.
En gérant les exceptions de manière ciblée et contrôlée, ce système protège non seulement contre les pannes perturbatrices, mais améliore également expérience utilisateur et l'intégrité des données.
En conséquence, le bloc try-sauf associe habilement la gestion des erreurs à l’exécution du programme, garantissant ainsi la robustesse et la stabilité des applications.
Voici un petit exemple de code qui utilise le bloc try-sauf :
18. Quelle est la différence entre les instructions raise et assert ?
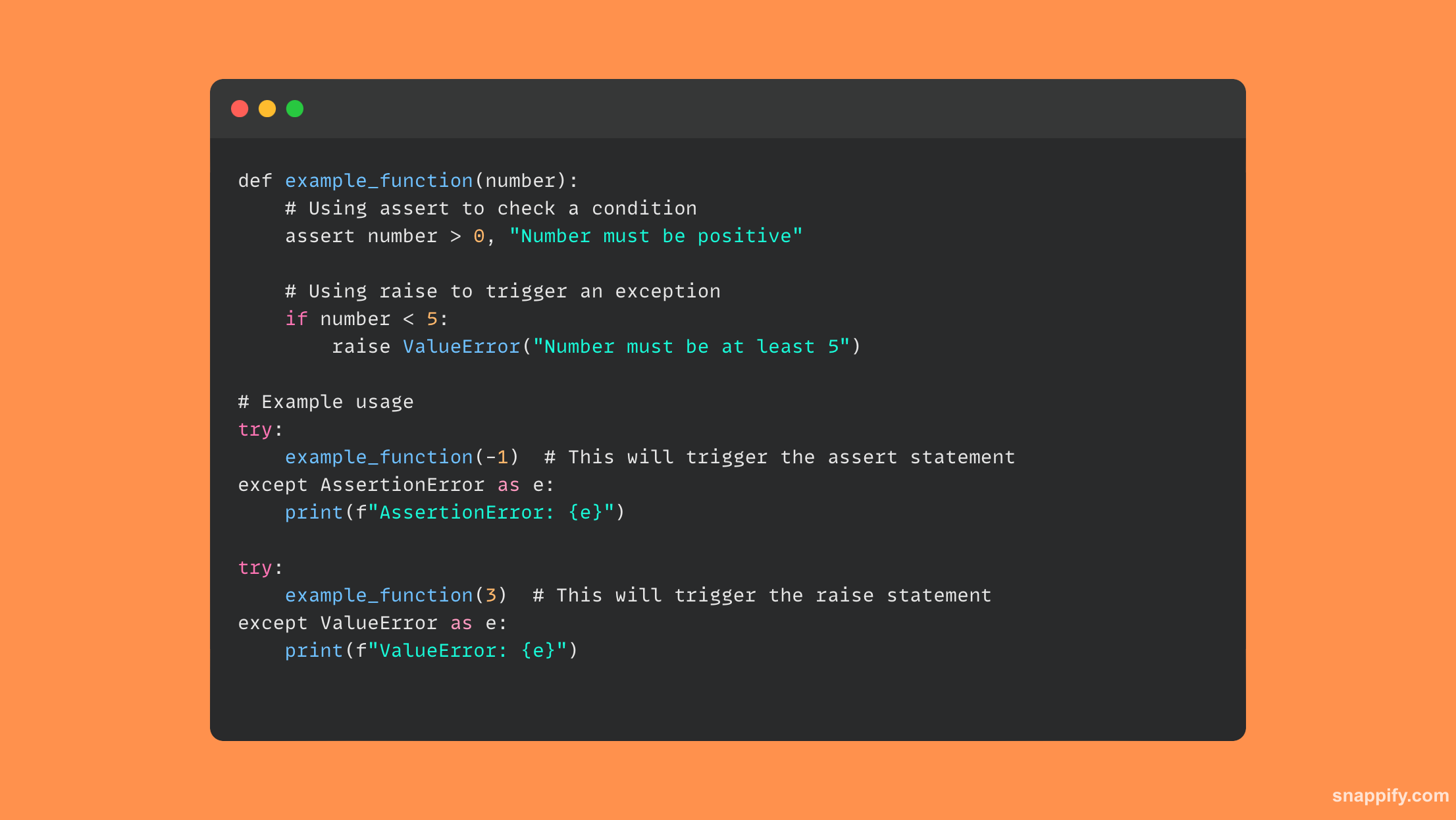
Les instructions raise et assert dans la gestion des erreurs de Python représentent deux expressions distinctes mais liées de la gestion des exceptions.
La raise L'instruction donne au programmeur un contrôle explicite sur les messages d'erreur et leur flux en leur permettant de provoquer explicitement des exceptions spécifiées.
Assert, d'autre part, agit comme un outil de débogage en générant automatiquement un AssertionError si la condition correspondante n'est pas remplie, garantir que le programme fonctionne comme prévu lors du développement.
Assert vérifie simplement les conditions, améliorant ainsi le débogage et la validation, tandis que raise permet un contrôle plus large et plus explicite. Les deux augmentent et affirment permettre une production d’exception contrôlée.
Voici un exemple de code montrant comment utiliser raise ainsi que assert:
19. Comment lire et écrire des données à partir d'un fichier binaire en Python ?
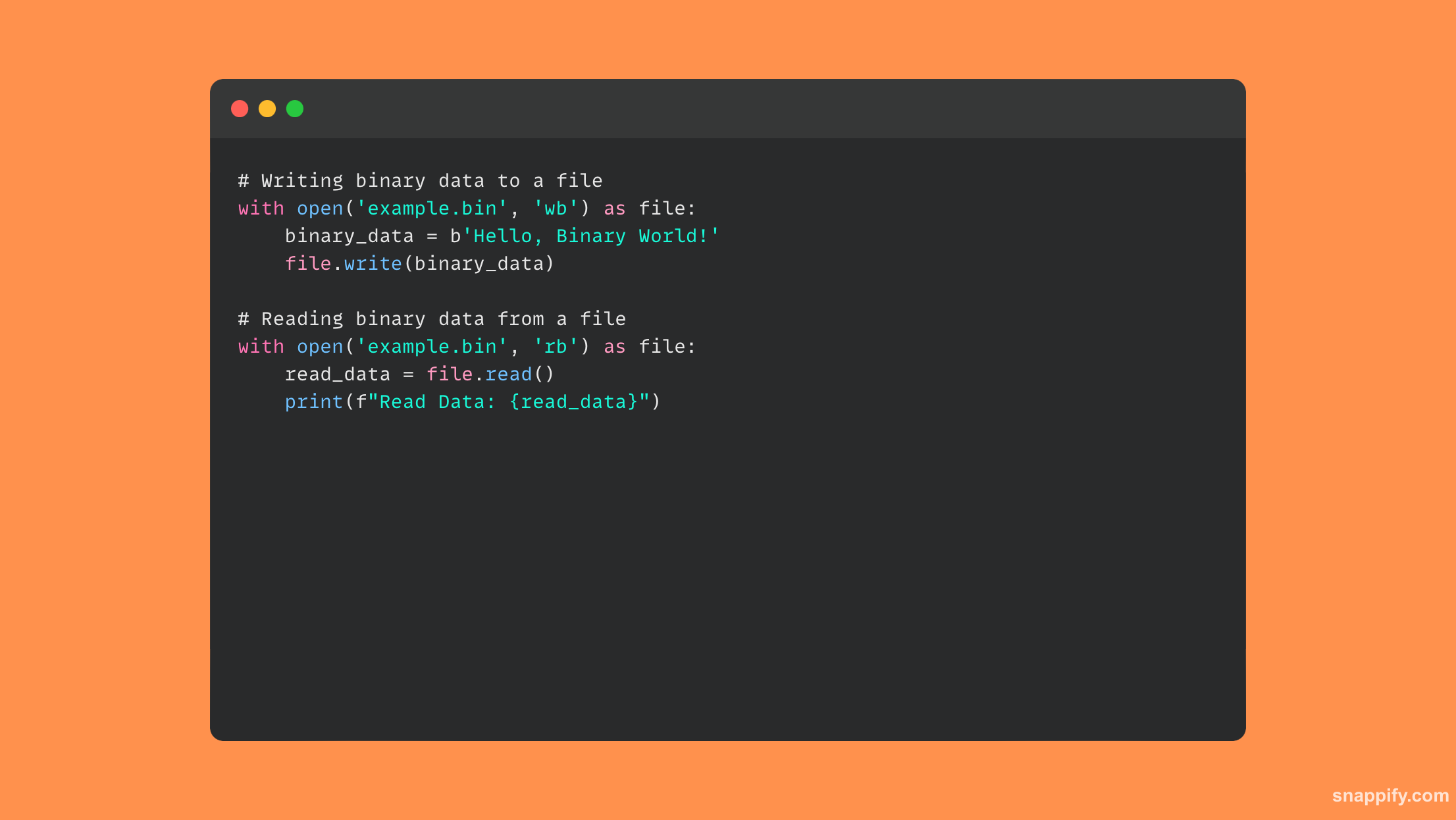
En utilisant la fonction open intégrée avec un spécificateur de mode binaire, l'interfaçage avec des fichiers binaires en Python implique un équilibre entre précision et simplicité.
Le rb or wb Les modes lors de l'ouverture d'un fichier binaire garantiront que les données sont traitées sous leur forme brute non codée lors de la lecture ou de l'écriture de données binaires.
En utilisant ces modes, Python simplifie la gestion des données non textuelles, telles que les images ou les fichiers exécutables, permettant aux programmeurs de gérer et d'analyser les données binaires avec précision et facilité.
Par conséquent, les opérations sur les fichiers binaires en Python ouvrent la porte à un large éventail d’applications, notamment la sérialisation de données, le traitement d’images et l’analyse binaire, pour n’en citer que quelques-unes.
À l'aide d'un fichier binaire, cet exemple de code montre comment lire et écrire des données :
20. Expliquez le with et ses avantages lorsque vous travaillez avec des E/S de fichiers.
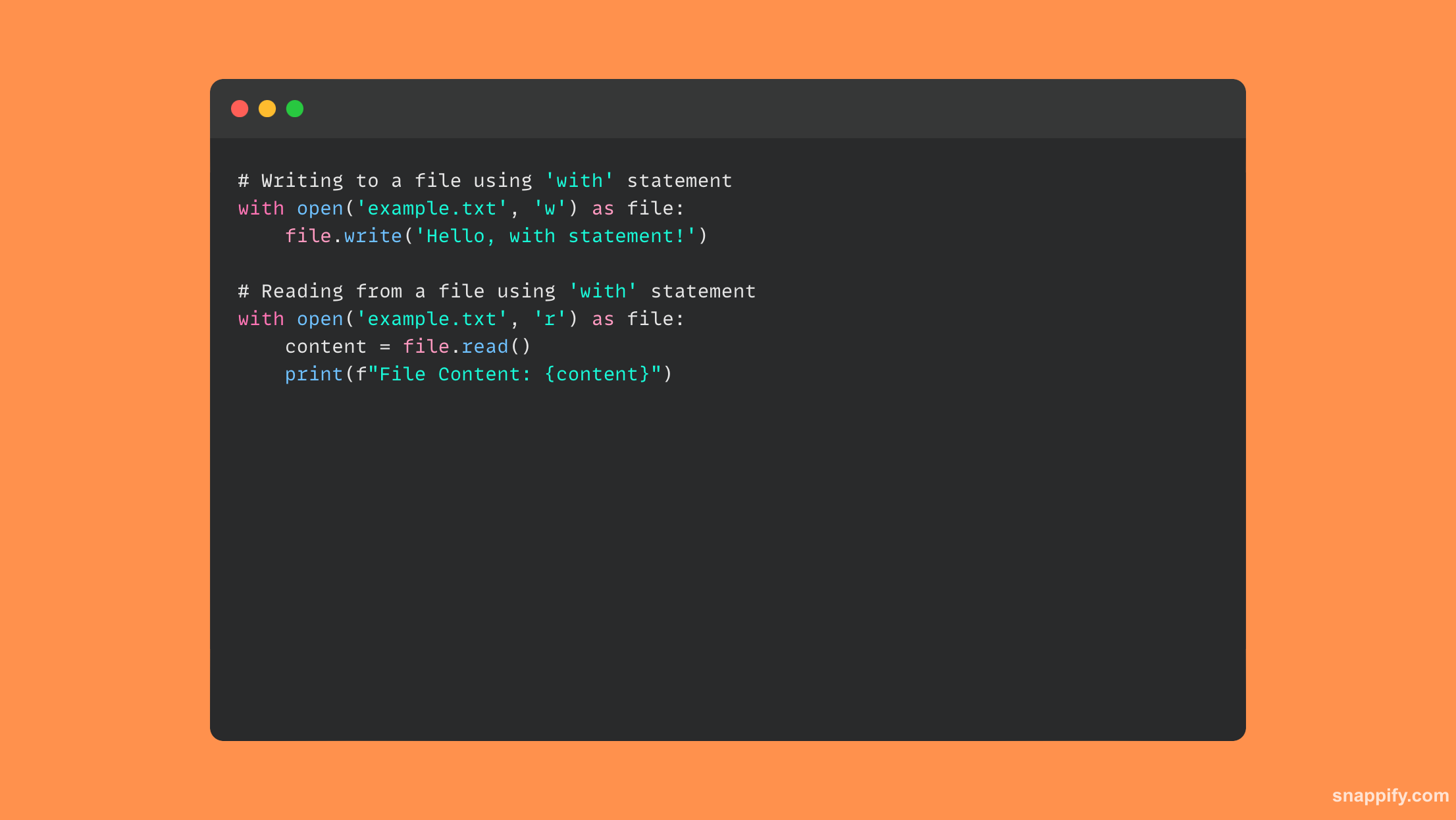
L'instruction with de Python, qui est fréquemment utilisée avec les E/S de fichiers, garantit avec élégance que les ressources sont gérées efficacement grâce à l'idée de gestion du contexte.
Lorsqu'il s'agit de fichiers, withL'instruction ferme immédiatement le fichier après utilisation, même si une exception se produit pendant l'exécution de l'action, protégeant ainsi contre les fuites de ressources et garantissant une terminaison propre.
En éliminant le code passe-partout, ce sucre syntaxique améliore la lisibilité du code. Il augmente également la fiabilité et la simplicité en intégrant la gestion des ressources et la gestion des exceptions.
En conséquence, l'instruction with devient essentielle pour garantir que vos opérations sur les fichiers sont fiables et propres, en vous protégeant contre les problèmes imprévus et en améliorant la clarté du code.
Voici un exemple de code qui utilise le with instruction dans les opérations sur les fichiers :
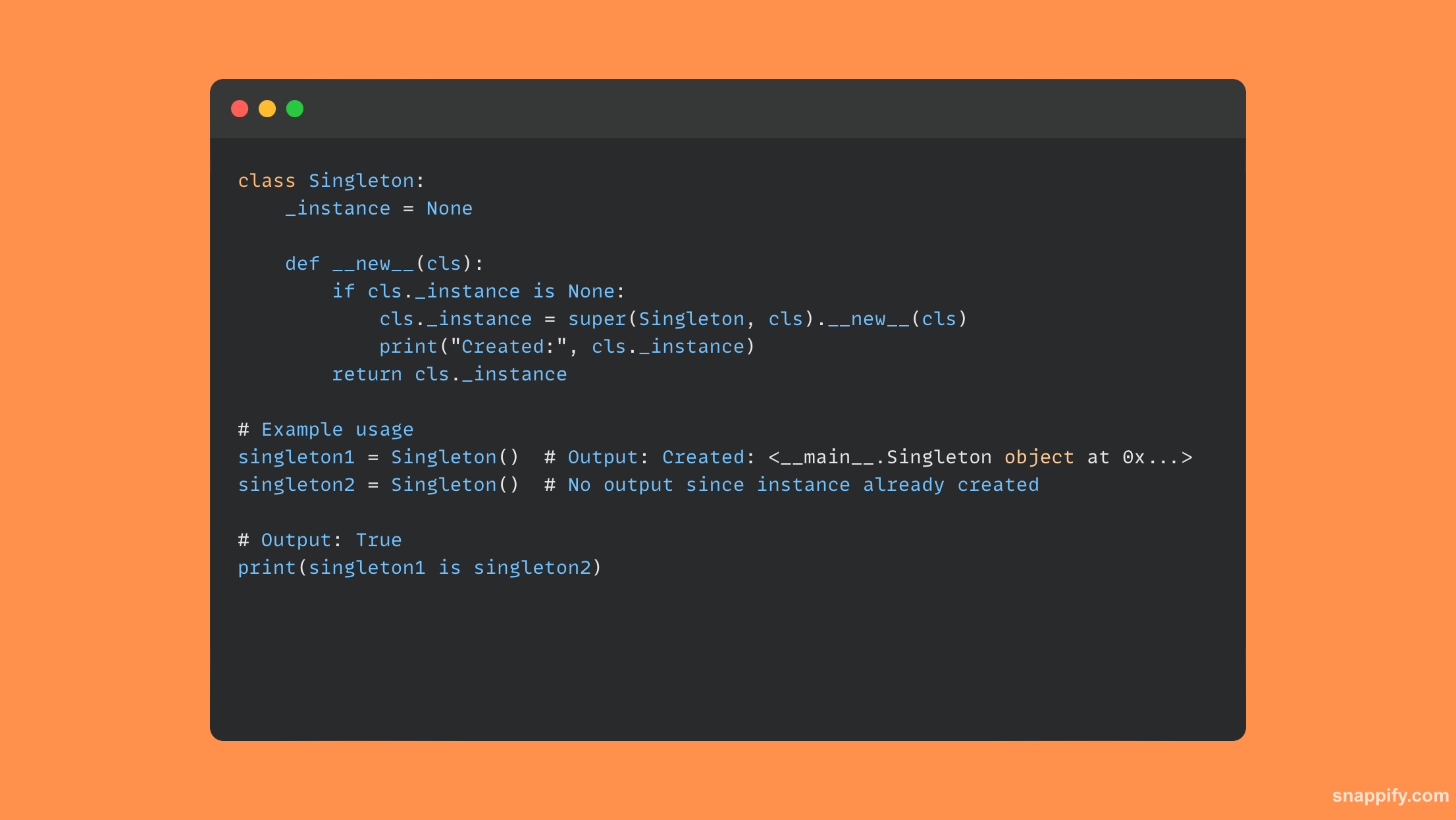
21. Comment créeriez-vous un module singleton en Python ?
Une combinaison de méthodes de classe et de vérifications internes est utilisée pour créer un module singleton en Python, un modèle de conception qui permet uniquement la création d'une seule instance d'une classe.
En gardant la trace de sa propre instance et en fournissant une méthode pour la générer ou la renvoyer, une classe suit ce modèle pour s'assurer que les instanciations ultérieures reproduisent la première instance.
Avec un point de contrôle unique, un accès unifié aux ressources et une protection contre les manipulations concurrentes, singleton assure un point de contrôle unique.
En conséquence, il se transforme en un outil efficace pour encapsuler les ressources partagées, garantissant un accès et une modification cohérents dans tout le programme.
Voici un petit exemple de code Python illustrant une classe singleton :
22. Nommez quelques façons d'optimiser l'utilisation de la mémoire dans un script Python.
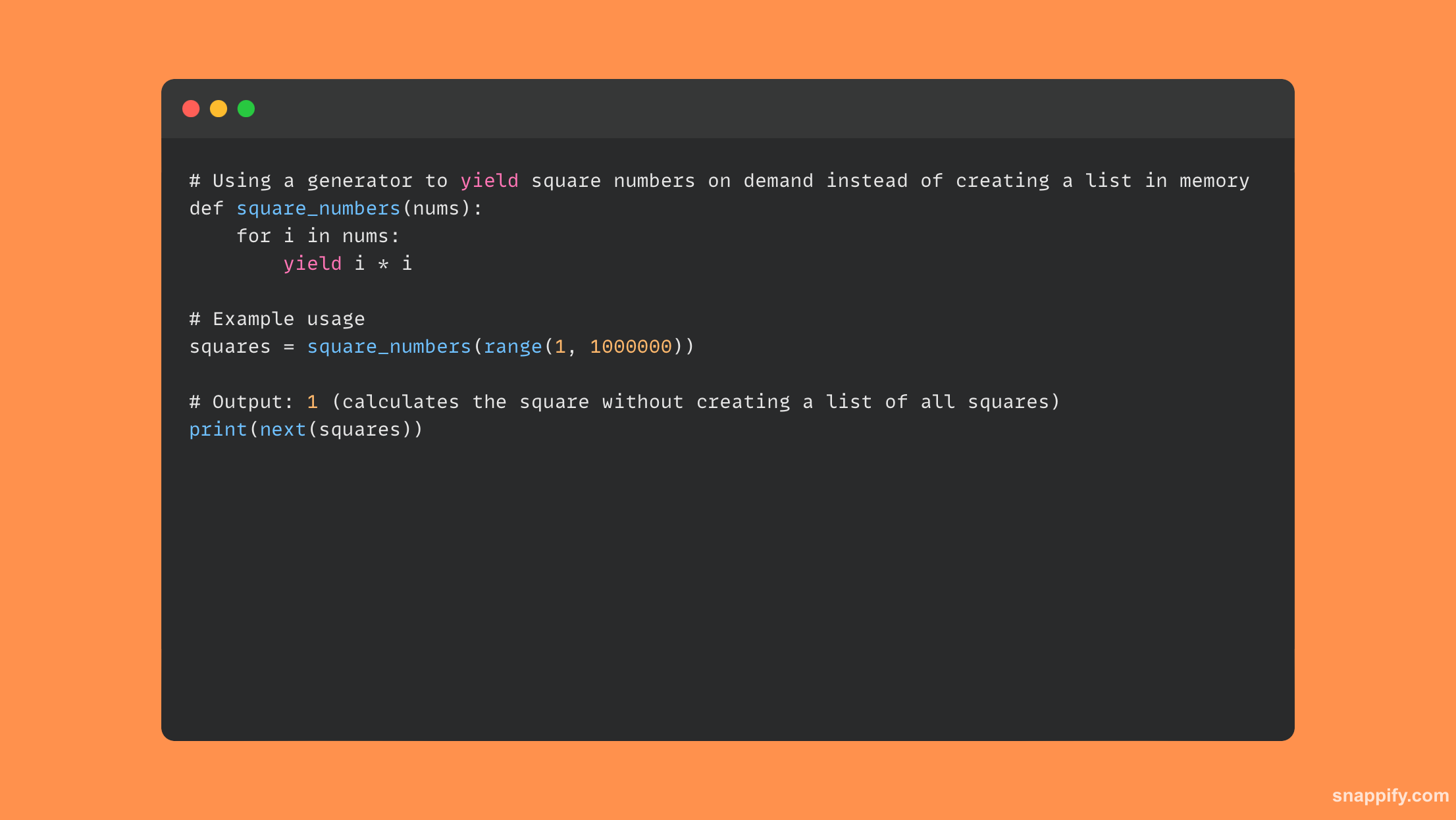
L'optimisation de la consommation de mémoire des scripts Python implique souvent un équilibre minutieux entre le choix de la structure des données, l'amélioration des algorithmes et la gestion des ressources.
Lorsque vous travaillez avec d'énormes ensembles de données, par exemple, l'utilisation de générateurs plutôt que de listes peut minimiser considérablement l'utilisation de la mémoire en évaluant paresseusement les éléments à la volée plutôt que de les conserver en mémoire.
Il est possible de réduire davantage l'utilisation de la mémoire en traitant les données numériques avec des structures de données matricielles plutôt qu'avec des listes et en utilisant avec parcimonie __slots__ déclarations en classe pour contrôler la formation des attributs dynamiques.
Ainsi, en équilibrant les performances et l’utilisation des ressources, vous pouvez garantir que les programmes Python sont non seulement efficaces, mais également réfléchis quant à la quantité de mémoire qu’ils utilisent.
Voici un court exemple de code qui utilise un générateur pour réduire la quantité de mémoire utilisée :
23. Comment extrayez-vous toutes les adresses e-mail d’une chaîne donnée à l’aide d’une expression régulière ?
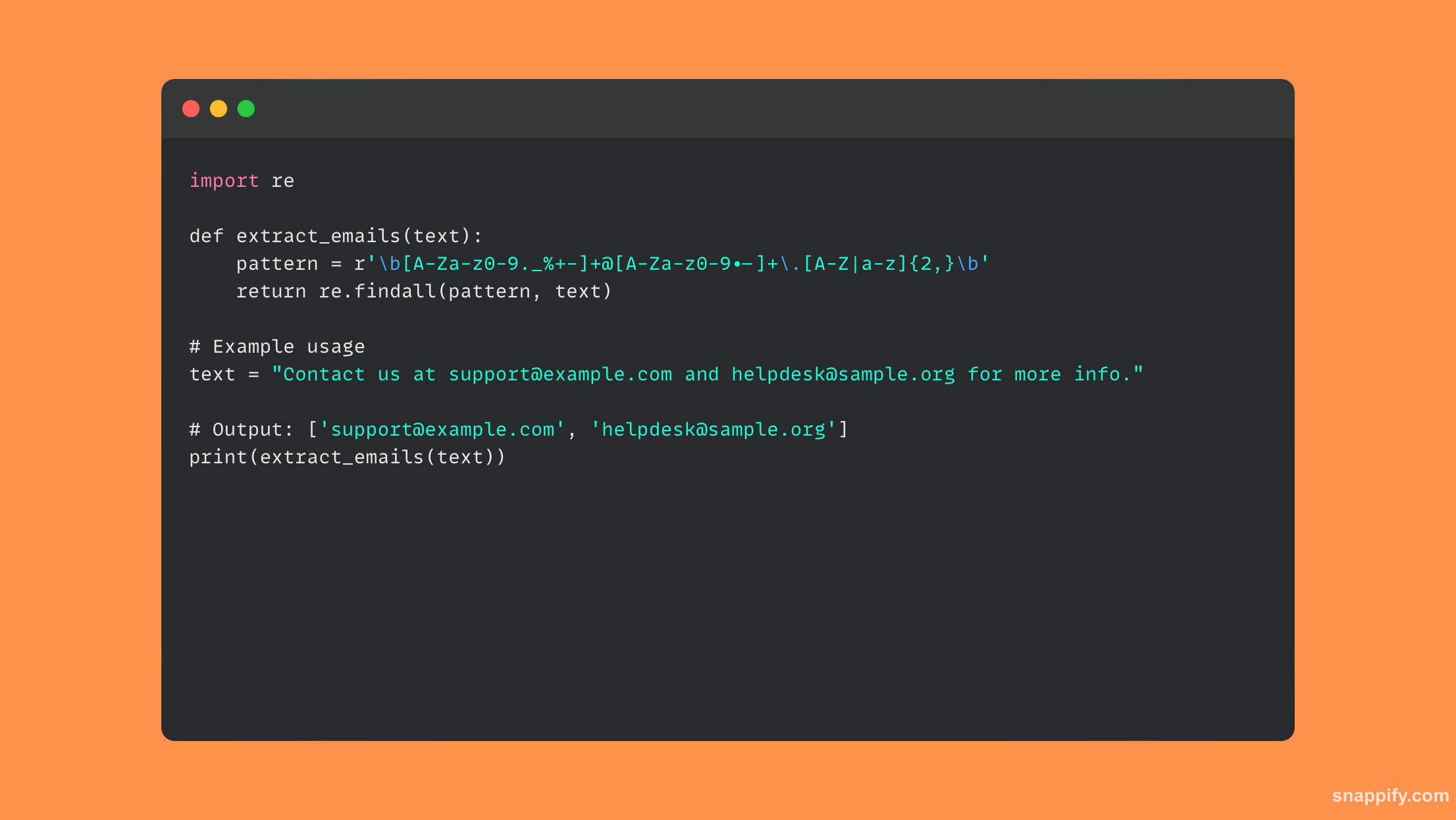
Les expressions régulières (regex) en Python combinent précision et polyvalence pour extraire les adresses e-mail d'une chaîne, permettant au développeur de filtrer habilement le matériel textuel et d'identifier les modèles souhaitables.
Pour établir la structure d'une adresse email, on crée un modèle regex à l'aide du re-module. Ensuite, vous pouvez utiliser findall pour obtenir toutes les occurrences de la chaîne cible.
Cette méthode navigue de manière experte dans le labyrinthe textuel pour obtenir toutes les adresses e-mail masquées, ce qui non seulement accélère le processus d'extraction, mais garantit également son exactitude.
Regex peut être habilement utilisé pour extraire efficacement certaines données de chaînes, augmentant ainsi le traitement et l'analyse des données des scripts Python.
Voici un morceau de code qui utilise regex pour extraire les e-mails :
24. Expliquer le modèle de conception Factory et son application en Python
Le principe fondamental de la programmation orientée objet, le modèle de conception d'usine, est la création d'objets sans identifier la classe précise des objets à générer.
Le modèle Factory peut être implémenté avec élégance en Python en créant une méthode qui renvoie des instances de plusieurs classes en fonction des entrées ou des configurations de la méthode.
Cette procédure, parfois appelée « Factory », agit comme une plate-forme pour le tissage de plusieurs instances de classe, garantissant que les objets sont créés sans que l'appelant n'ait à instancier manuellement les classes.
Ainsi, le modèle Factory maintient une architecture découplée et évolutive tout en améliorant la modularité et la cohésion du code. Il propose également une technique simplifiée pour construire des objets.
25. Quelle est la différence entre un itérateur et un générateur ?
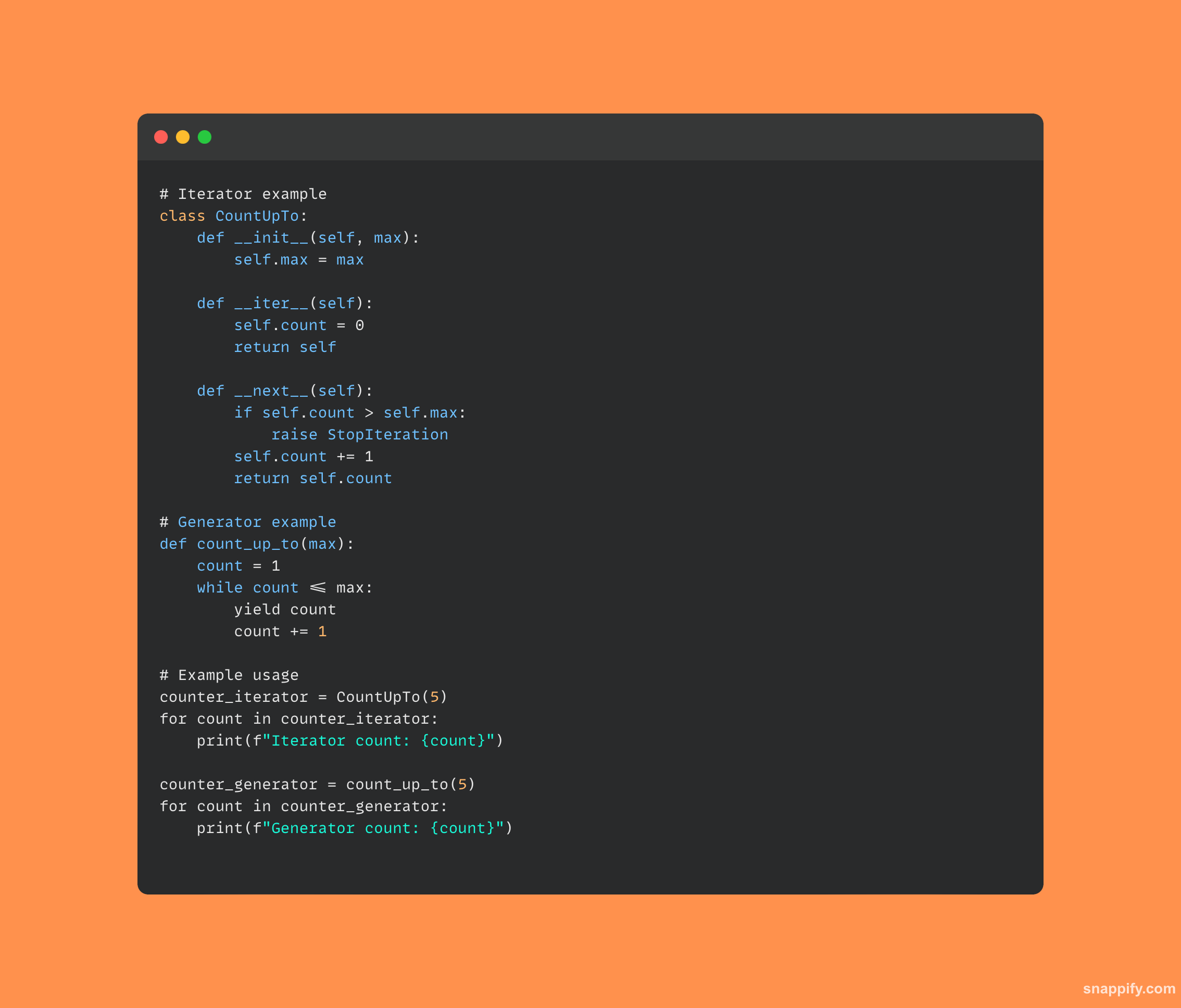
Il ressort clairement des itérateurs et générateurs de Python que les deux constructions permettent de parcourir les valeurs, cependant, il existe des différences subtiles dans la manière dont elles sont implémentées et utilisées.
Un générateur, fréquemment identifié par son utilisation du rendement, maintient automatiquement son état et est implémenté avec une fonction, offrant un moyen concis et économe en mémoire de produire des valeurs à la volée.
Un itérateur, généralement implémenté en tant que classe, utilise des méthodes telles que __iter__ ainsi que __next__ pour gérer son état d’itération et produire des valeurs.
En conséquence, chacun a ses propres avantages en fonction du cas d'utilisation particulier, les itérateurs offrant un moyen approfondi et orienté objet de parcourir les données, tandis que les générateurs offrent une technique d'évaluation légère et paresseuse.
Les deux techniques s'ajoutent à l'arsenal du développeur et permettent d'explorer les données rapidement et efficacement dans diverses situations.
Voici un morceau de code d'un itérateur et d'un générateur en Python :
26. Comment le @property un travail de décorateur ?
Le décorateur '@property' en Python joue une jolie mélodie qui convertit les appels de méthode en accès de type attribut, améliorant ainsi la convivialité et l'expressivité des objets.
Une méthode peut être appelée sans utiliser de parenthèses en utilisant @property, ce qui revient à accéder à un attribut. Cela crée une interface plus claire et plus facile à utiliser pour l'interaction avec les objets.
De plus, il offre un équilibre judicieux entre fonctionnalités et encapsulation, protégeant les états des objets tout en offrant une interface intuitive, permettant aux développeurs de spécifier facilement les attributs à l'aide des méthodes getter et setter.
En combinant la fonctionnalité de la méthode avec l'accessibilité des attributs, le @property decorator apparaît comme un outil crucial et offre un paradigme d'interaction d'objets simple mais efficace.
Un exemple de Python @property le décorateur est illustré ci-dessous :
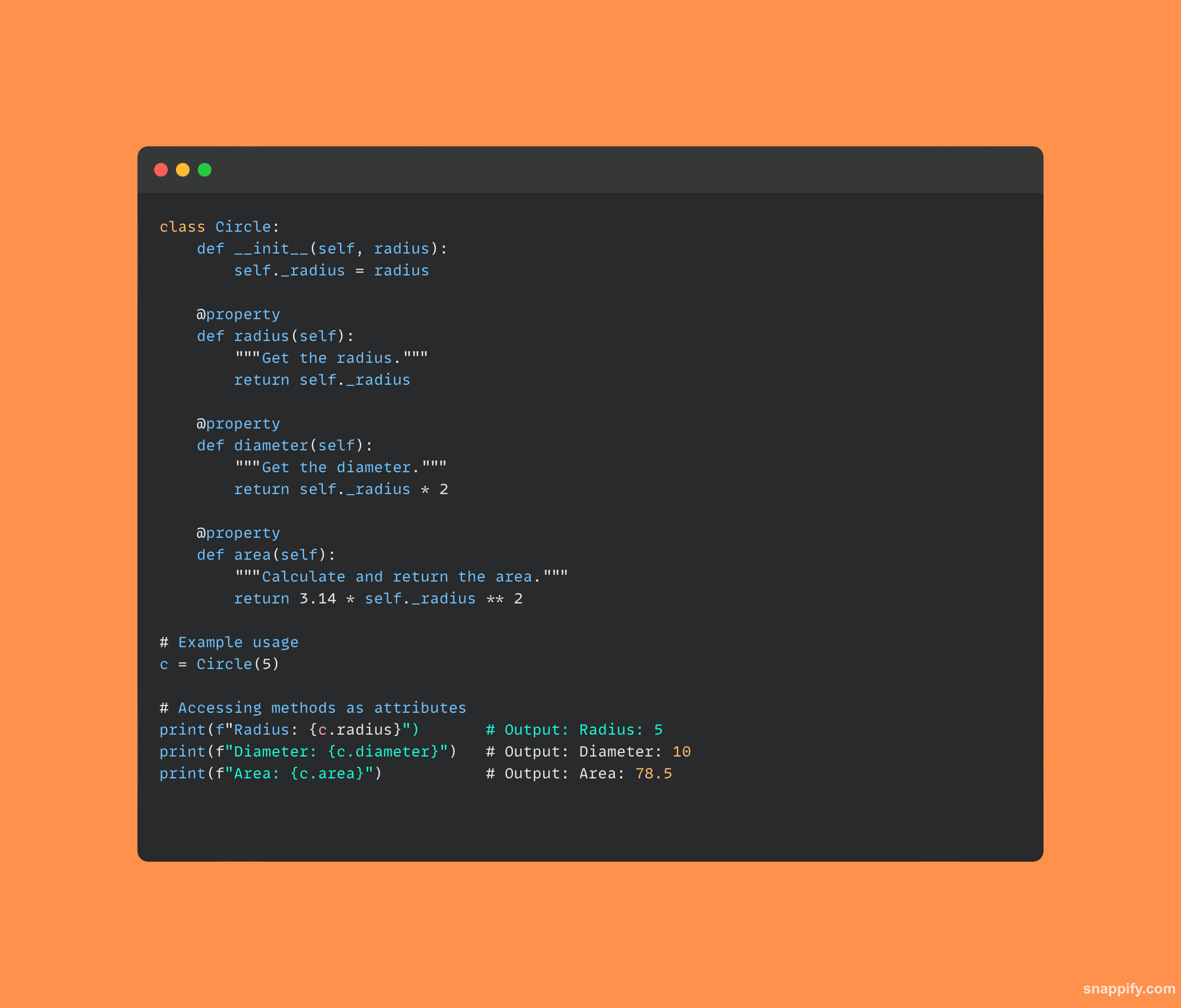
27. Comment créeriez-vous une API REST de base en Python ?
Afin de créer des services Web qui interagissent via des requêtes HTTP, les développeurs utilisent fréquemment la capacité d'expression de frameworks comme Flask tout en créant un simple API REST en Python.
Grâce à sa syntaxe simple et compréhensible, Flask permet aux développeurs de construire des routes accessibles par un certain nombre de méthodes HTTP, notamment GET et POST, pour communiquer avec l'application sous-jacente.
Une API REST construite à l'aide de Flask peut facilement accepter les requêtes HTTP, traiter les données contenues et fournir des informations pertinentes en réponse en spécifiant des points de terminaison uniques liés à diverses fonctionnalités.
Afin de garantir une communication transparente entre les différents composants logiciels dans un environnement en réseau, les développeurs peuvent utiliser de puissantes API REST en utilisant une combinaison de Python et Flask.
Voici un petit morceau de code qui utilise Flask pour créer une API REST :
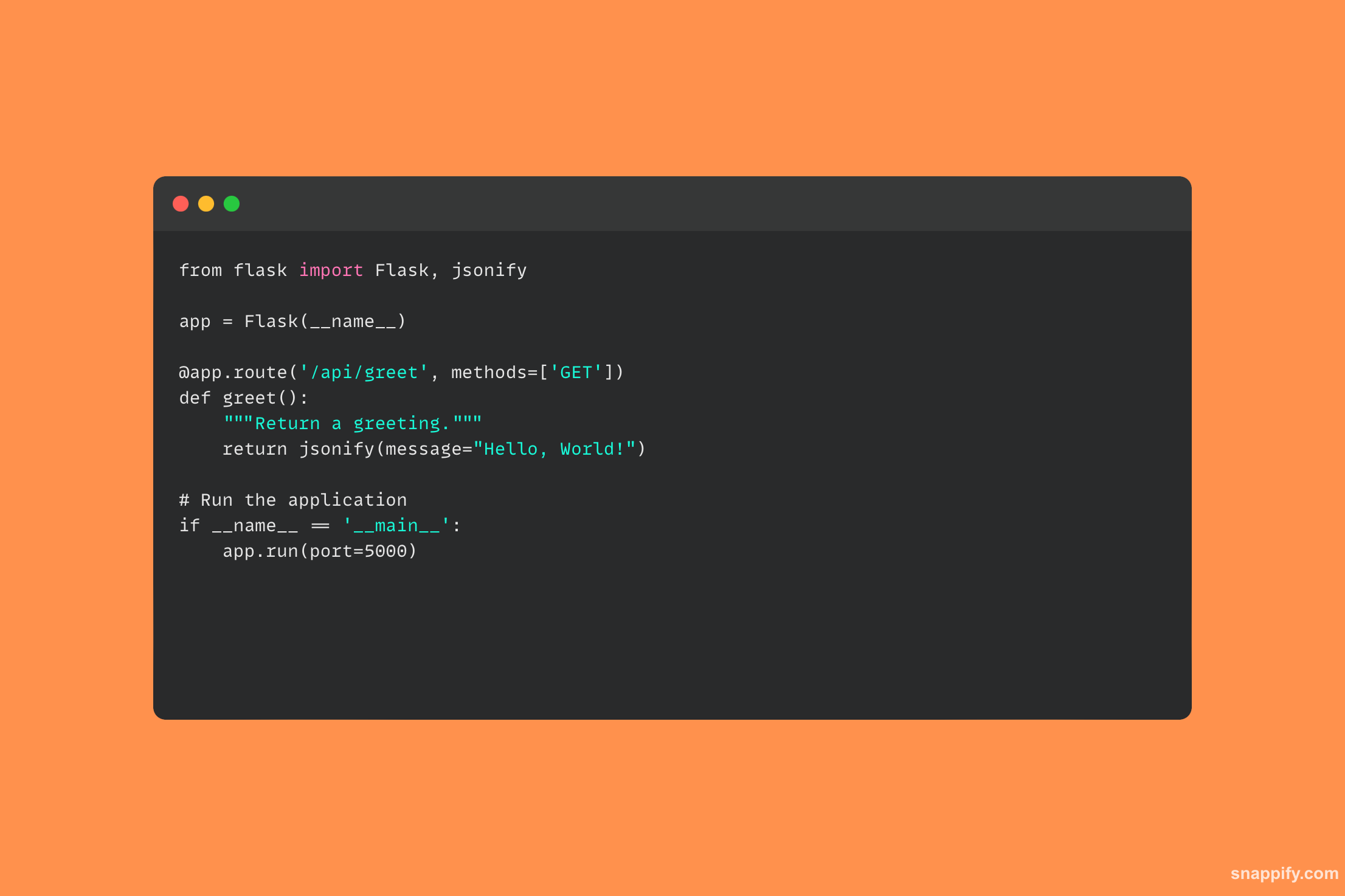
28. Décrivez comment utiliser la bibliothèque de requêtes pour effectuer une requête HTTP POST.
La bibliothèque de requêtes de Python est un outil puissant qui transforme les difficultés de la communication HTTP en une API accueillante et rend simple et naturelle l'interaction avec les services en ligne à l'aide de requêtes HTTP POST.
Une requête POST est effectuée en utilisant la méthode post, en indiquant l'URL de destination et en joignant le matériel à envoyer, qui peut contenir des données de formulaire, du JSON, des fichiers, etc.
La bibliothèque de requêtes gère ensuite la connexion HTTP sous-jacente, envoyant les données à l'URL désignée et en collectant la réponse du serveur pour permettre des interactions Web fluides.
Les développeurs peuvent facilement utiliser les services en ligne, soumettre des données de formulaire et interagir avec les API Web via des requêtes, comblant ainsi le fossé entre les applications locales et le Web mondial.
À l'aide de la bibliothèque de requêtes, l'exemple de code suivant montre comment envoyer une requête HTTP POST :
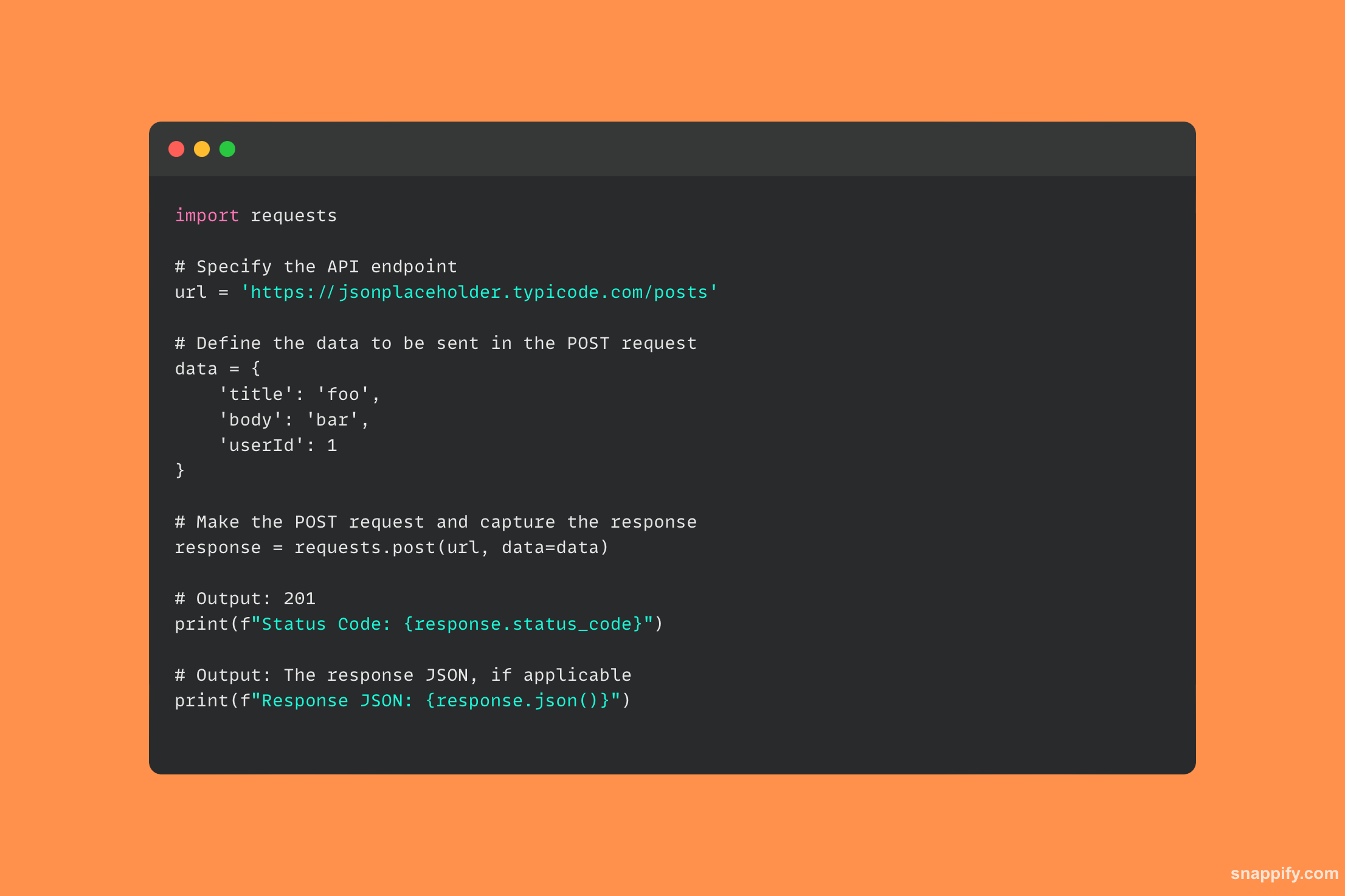
29. Comment vous connecteriez-vous à une base de données PostgreSQL à l'aide de Python ?
L'interaction avec une base de données PostgreSQL à partir d'un environnement Python est gérée avec élégance par le package psycopg2, un pont puissant qui permet des interactions transparentes avec la base de données.
En utilisant psycopg2, les programmeurs peuvent facilement créer des connexions, exécuter des requêtes SQL et obtenir des résultats, en intégrant directement les fonctionnalités de PostgreSQL dans les programmes Python.
Vous pouvez débloquer des fonctions de base de données complexes avec seulement quelques lignes de code, garantissant ainsi que les données sont consultées, modifiées et enregistrées avec précision et efficacité.
Ce module permet aux développeurs d'utiliser pleinement les bases de données relationnelles dans leurs applications en réalisant avec élégance la synergie entre Python et PostgreSQL.
Voici l'exemple de code qui montre comment utiliser le psycopg2 bibliothèque pour établir une connexion à une base de données PostgreSQL :
30. Quel est le rôle des ORM en Python et nommez-en un populaire ?
Le mappage objet-relationnel (ORM) en Python permet aux développeurs de se connecter aux bases de données à l'aide de classes Python et de paradigmes d'objet.
Il agit comme un médiateur harmonieux entre la programmation orientée objet et l'administration de bases de données relationnelles.
SQLAlchemy, l'un des ORM les plus connus de l'environnement Python, propose un ensemble complet d'outils pour interagir avec plusieurs bases de données SQL à l'aide d'une syntaxe de haut niveau orientée objet.
Avec l'aide de SQLAlchemy, les entités de base de données peuvent être représentées sous forme de classes Python, les instances de ces classes servant de lignes dans les tables de base de données.
Cela permet aux programmeurs de travailler avec des bases de données sans avoir à écrire de requêtes SQL brutes.
En raison de la complexité de SQL et de la connectivité des bases de données, les ORM comme SQLAlchemy permettent des interactions de bases de données plus conviviales, sécurisées et maintenables.
Voici un exemple simple montrant le fonctionnement de SQLAlchemy :
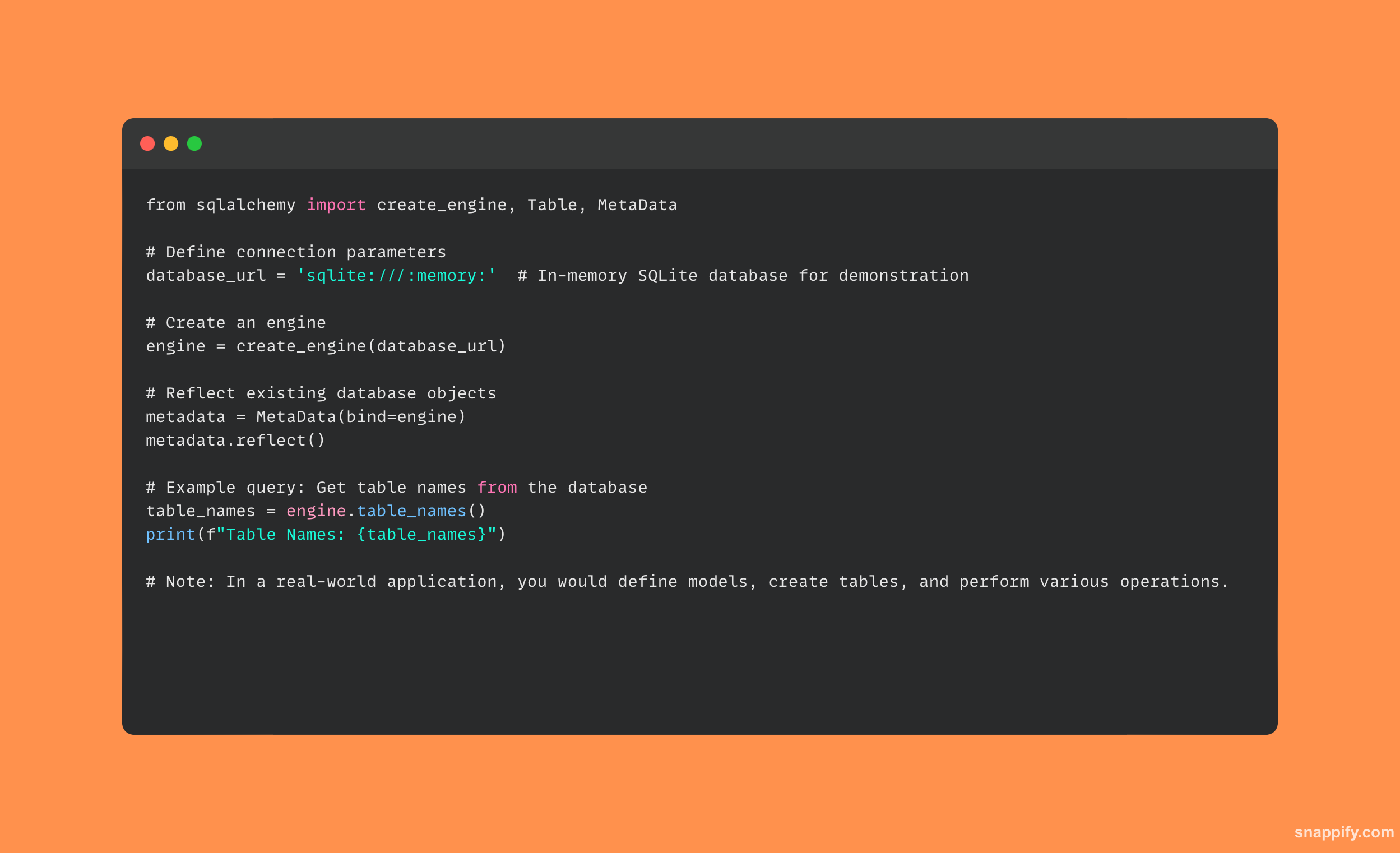
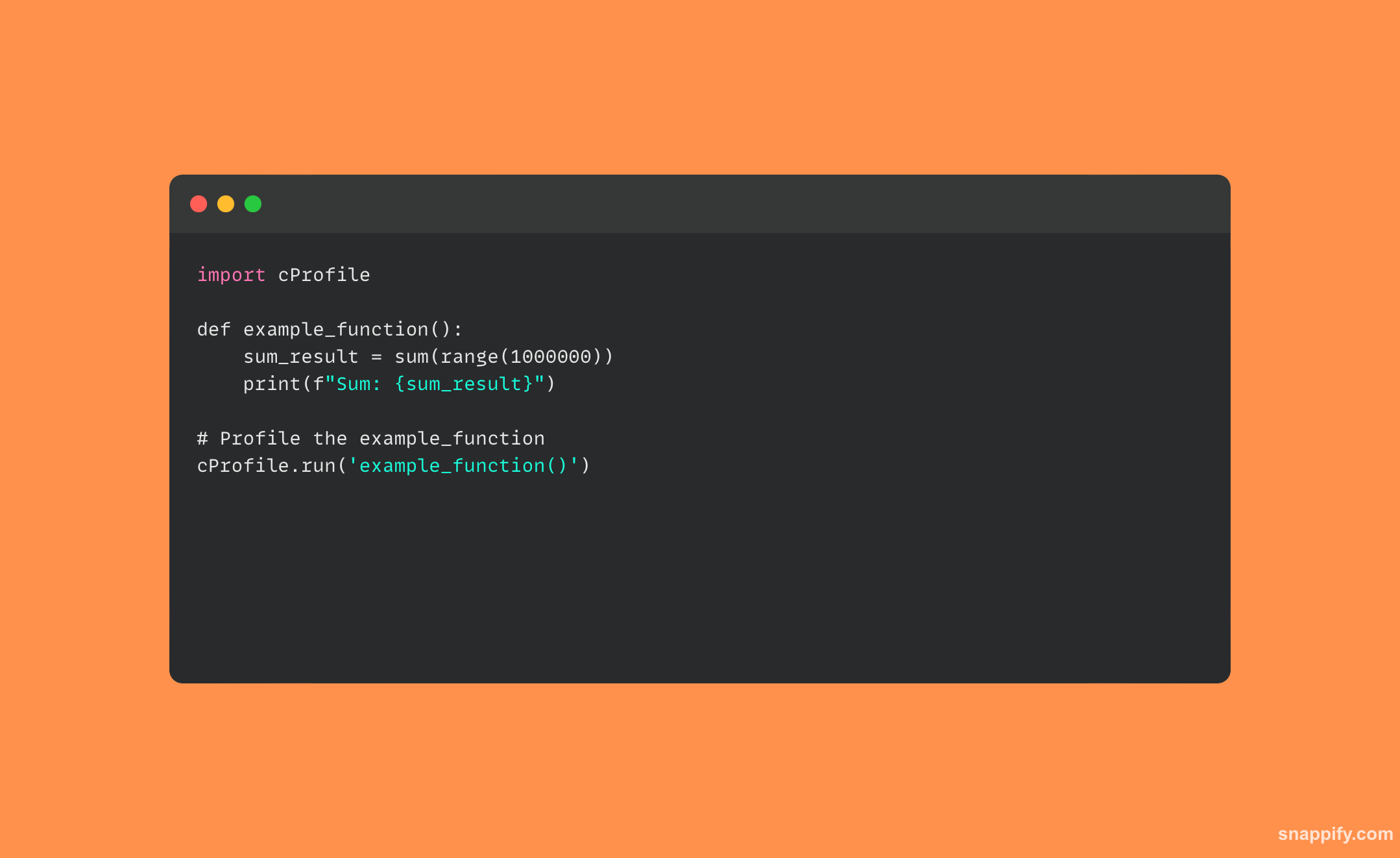
31. Comment profileriez-vous un script Python ?
Un script Python est profilé en analysant sa structure de calcul et les détails temporels et spatiaux de son exécution afin de détecter d'éventuels goulots d'étranglement en termes de performances et d'améliorer l'efficacité.
Les développeurs peuvent analyser soigneusement le comportement de leur code pendant l'exécution en utilisant le module intégré cProfile module.
Ce faisant, ils peuvent obtenir des données détaillées sur les appels de fonction, les temps d'exécution et les relations d'appel, ce qui leur permet d'identifier et de résoudre les goulots d'étranglement en matière de performances.
Vous pouvez garantir que le code fonctionne non seulement correctement mais aussi efficacement, en équilibrant les ressources informatiques et en améliorant les performances globales des applications, en incluant le profilage dans le cycle de vie de développement.
Les développeurs peuvent donc protéger les programmes contre les inefficacités grâce à un profilage minutieux, garantissant qu'ils sont réglés de manière fiable et performants pour une gamme de demandes de calcul.
Voici un exemple simple de profilage de script Python utilisant le cProfile module:
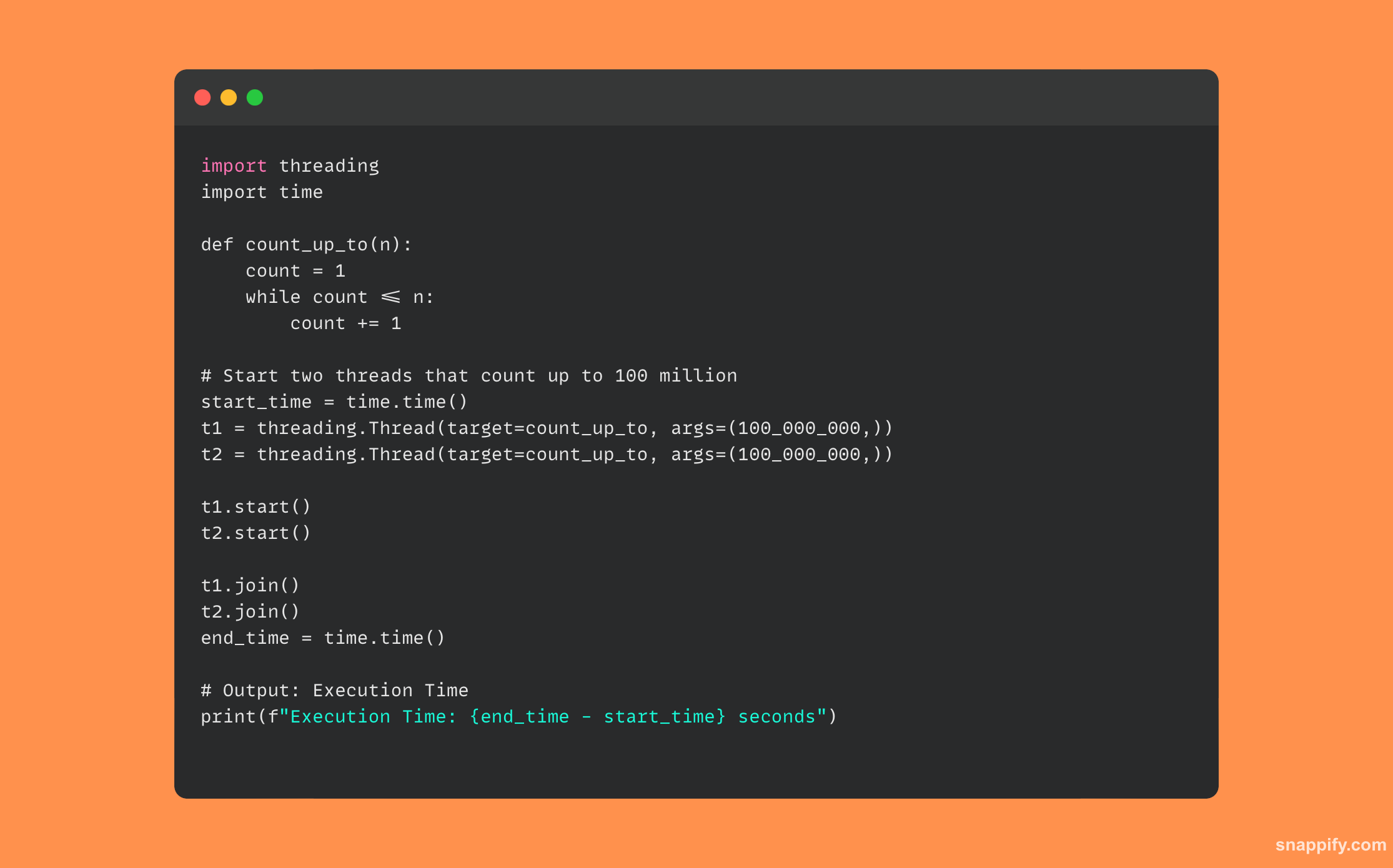
32. Expliquer le GIL (Global Interpreter Lock) dans CPython
Le Global Interpreter Lock (GIL) de CPython fonctionne comme une sentinelle, garantissant qu'un seul thread exécute le bytecode Python à la fois dans un seul processus, même dans les applications multithread.
Même s'il peut sembler être un goulot d'étranglement, le GIL est crucial pour protéger la gestion de la mémoire et les structures de données internes de CPython contre les accès simultanés et pour préserver l'intégrité du système.
La nécessité du multithreading dans les activités liées aux E/S, où les threads doivent attendre que les données soient livrées ou reçues, doit cependant être gardée à l'esprit, car GIL n'élimine pas ce besoin.
Ainsi, même si GIL pose des difficultés pour les activités liées au CPU, la compréhension de son comportement et l'adaptation des techniques, comme l'utilisation du multitraitement ou de la programmation concurrente, permettent aux développeurs de créer des programmes Python efficaces et simultanés.
Voici un exemple de code Python qui utilise des threads et montre comment GIL pourrait avoir un effet sur les tâches liées au processeur :
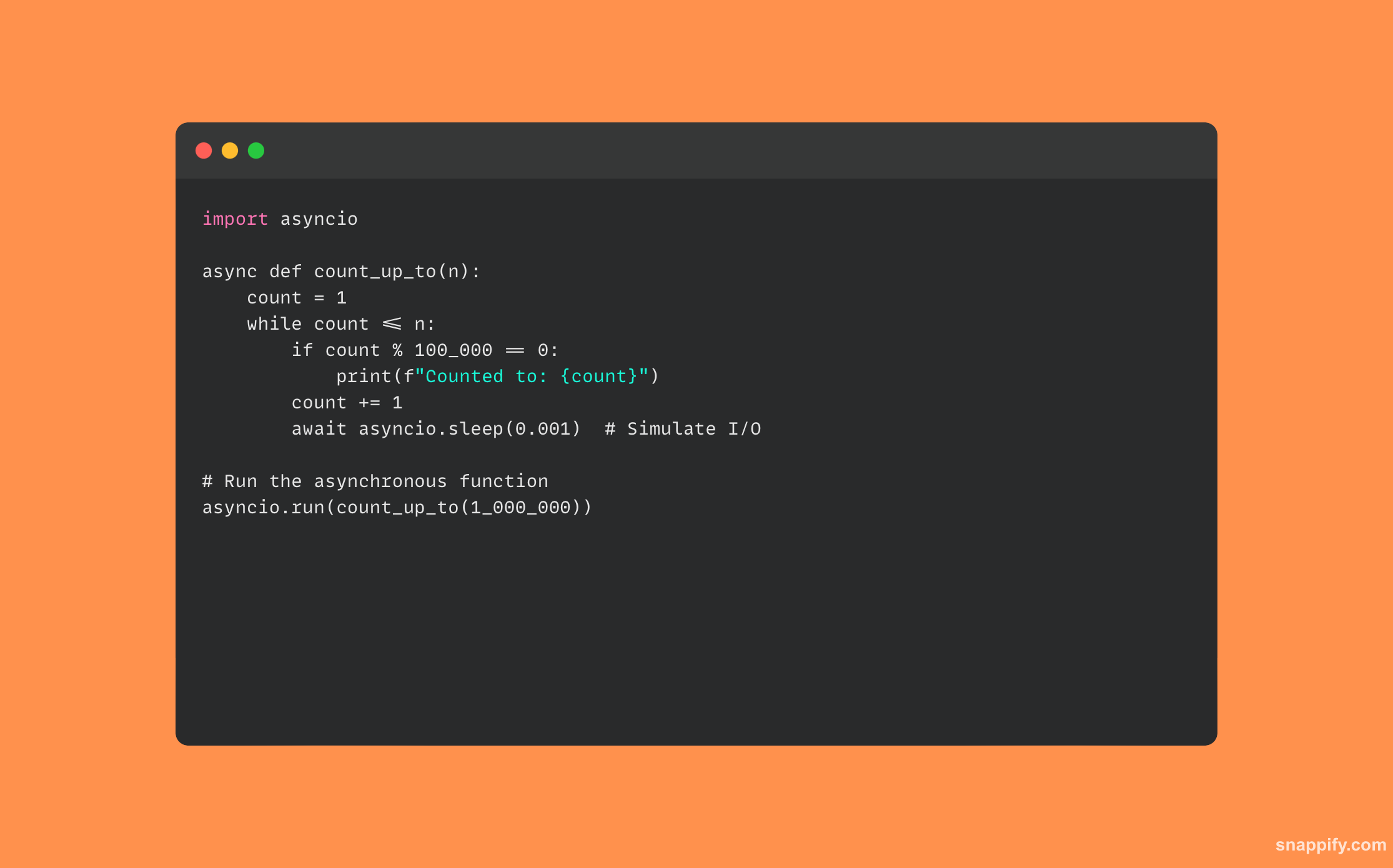
33. Expliquez l'async/wait de Python. En quoi est-ce différent du filetage traditionnel ?
La syntaxe async/wait en Python ouvre le monde de la programmation asynchrone, un paradigme qui permet à certaines fonctions de céder le contrôle à l'environnement d'exécution afin que d'autres activités puissent s'exécuter entre-temps, améliorant ainsi l'efficacité du programme.
Async/await maintient les activités dans un seul thread mais permet à l'exécution de passer d'une tâche à l'autre, garantissant un comportement non bloquant sans la complexité de la gestion des threads.
Cela contraste avec le threading classique, où les threads s'exécutent en parallèle et nécessitent souvent une gestion et une synchronisation compliquées.
En conséquence, les développeurs peuvent gérer efficacement les activités liées aux E/S simultanées et avec une approche plus simple du contrôle de la simultanéité.
Cela favorise un modèle multitâche coopératif dans lequel les processus cèdent volontairement le contrôle.
En conséquence, async/await offre un moyen distinctif et simplifié de concevoir des applications simultanées, en particulier là où les opérations d'E/S sont courantes, en trouvant un équilibre entre performances et complexité.
Un exemple de code Python qui utilise async/await est fourni ci-dessous :
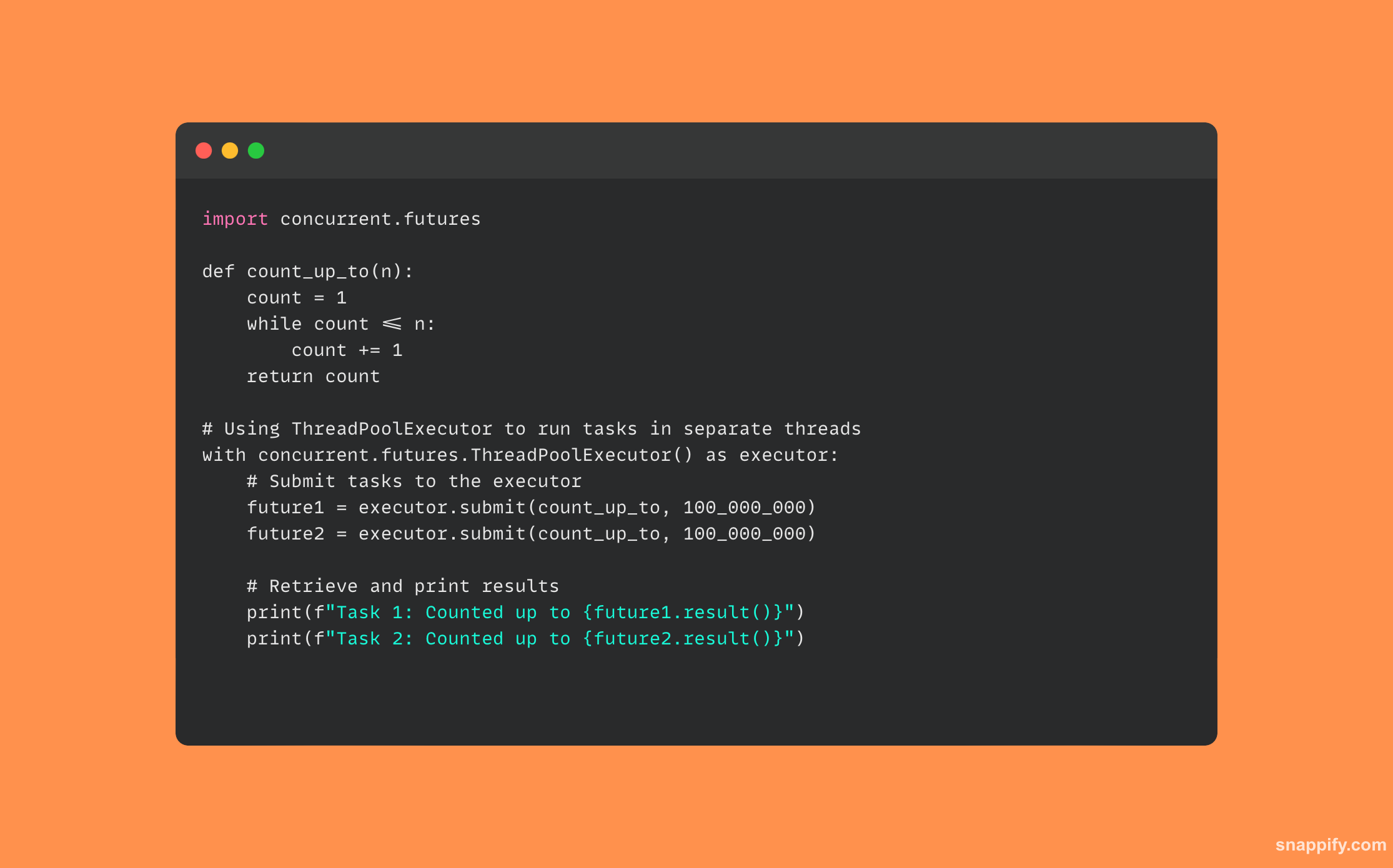
34. Décrivez comment vous utiliseriez Python concurrent.futures.
interface pour l'exécution asynchrone d'appelables via des threads ou des processus, les développeurs peuvent gérer gracieusement les opérations asynchrones et parallèles.
Ce module gère l'allocation des ressources et l'exécution des callables tout en encapsulant les aspects délicats du threading et du multitraitement via les exécuteurs (ThreadPoolExecutor et ProcessPoolExecutor).
Les développeurs peuvent utiliser efficacement des processeurs multicœurs pour les activités liées au processeur et fournir des opérations d'E/S non bloquantes en envoyant des tâches à un exécuteur, qui peut ensuite les exécuter simultanément et même regrouper leurs résultats.
Afin de garantir que les applications soient réactives et performantes, concurrent.futures crée un espace où les calculs complexes et les activités d'E/S peuvent fusionner en douceur.
Voici un exemple de code qui utilise concurrent.futures:
35. Comparez Django et Flask en termes de cas d'utilisation et d'évolutivité.
Deux étoiles dans la constellation des frameworks Web de Python, Django et Flask, brillent chacune de mille feux tout en répondant aux diverses exigences des développeurs.
Pour les programmeurs créant des applications massives basées sur des bases de données, Django est l'outil de choix car il est livré avec un ORM et une interface d'administration intégrée.
Cependant, la conception simple et modulaire de Flask donne aux développeurs la liberté de sélectionner leurs propres composants, ce qui en fait le choix idéal pour les petits projets ou les situations où une solution légère et adaptable est essentielle.
Les deux frameworks peuvent être mis à l’échelle pour répondre à des exigences plus élevées en matière d’évolutivité.
Cependant, la nature allégée de Flask permet des tactiques de mise à l'échelle personnalisées adaptées à des besoins particuliers, tandis que les capacités intégrées de Django peuvent lui donner un petit avantage pour un développement rapide dans des projets plus importants et plus complexes.
Conclusion
Les entretiens de scripting Python nécessitent une connaissance approfondie des capacités, des complexités et des applications du langage.
Une préparation approfondie renforce non seulement les compétences techniques, mais inspire également confiance, aidant les candidats à avancer rapidement et avec précision dans le labyrinthe difficile des questions.
Les aspirants peuvent s'assurer qu'ils sont prêts à gérer les problèmes Python de base et appliqués en examinant des idées clés telles que la concurrence, les principes de la POO et les structures de données, ainsi qu'en se plongeant dans des applications pratiques telles que la programmation Web et la manipulation de données.
En conséquence, avoir une formation complète devient essentiel au succès et peut conduire à des situations où les capacités de programmation Python peuvent exceller et être créatives. Voir Série d'interviews de Hashdork pour une aide à la préparation des entretiens.





Soyez sympa! Laissez un commentaire