Arvutiteaduse eesmärk on mõista algoritmide ja andmestruktuuride keerukust.
Teil on sorteerimist vajavate üksuste loend, kuid teil pole aega ega ressursse keerukama sortimisalgoritmi kasutamiseks.
Sisestamise sortimine on üks lihtsamaid sortimisalgoritme, kuid suurte loendite puhul võib see olla aeglane.
Lihtne rakendamine ja arusaamine on muutnud selle meetodi programmeerijate seas lemmikuks. See sobib suurepäraselt väikeste loendite jaoks või siis, kui vajate kiiret lahendust.
Selles blogipostituses vaatleme sisestamise sortimise ajalist keerukust. Seda algoritmi kasutatakse massiivide sortimiseks ja selle käitusaeg on O(n2). See tähendab, et ajaline keerukus suureneb massiivi suurusega.
See algoritm võib aga sageli olla kiirem kui teised sortimisalgoritmid, näiteks kiirsortimine.
Vaatame lähemalt, kuidas sisestussorteerimine käib!
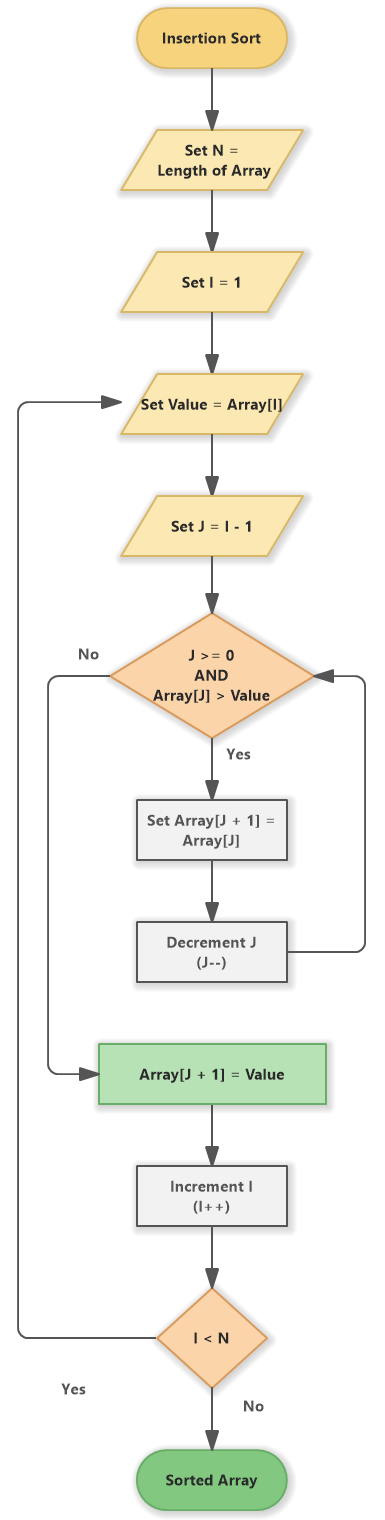
Mis on sisestamise sortimise algoritm?
Üks element korraga, sisestussorteerimine loob sorteeritava massiivi, mida sageli nimetatakse loendiks.
Näiteks kasutatakse sorteerimist keerulistes arvutiprogrammides, näiteks kompilaatorites, kus märkide järjekord on programmi tõlgendamisel oluline.
Kuidas sisestussortimine töötab?
Kui kasutame massiivi sortimiseks sisestussortimist, alustab algoritm loendist väikseima üksuse otsimisest ja selle õigesse kohta sisestamisest.
Seejärel otsib see üles suuruselt järgmise elemendi ja sisestab selle õigesse kohta jne.
Algoritm töötab loendis silmuses, võrreldes iga üksust sellele eelnevaga.
Kui üksused on vales järjekorras, vahetab algoritm need. Seejärel kontrollib see, kas loend on sorteeritud, ja kui on, siis algoritm lõpeb.
Praktikas rakendatakse sisestussortimist sageli mõne koodirea abil, mistõttu on see populaarne valik väikeste massiivide sortimiseks. Selle algoritmi kasutamisel tuleks aga arvestada aja keerukusega.
Näide:
Siin on näide sisestussortimise toimimisest. Kasutame järgmist massiivi:
1, 2, 3, 4, 5, 6
Algoritm alustab loendist väikseima üksuse leidmisega, milleks on 1. Seejärel lisab see õigesse kohta, esimesse kohta. Seejärel leiab see suuruselt järgmise üksuse, milleks on 2. See sisestab selle õigesse asendisse, mis on teine asend.
Seejärel leiab see suuruselt järgmise elemendi, milleks on 3. See sisestab selle õigesse kohta, mis on kolmas positsioon.
Seejärel leiab see suuruselt järgmise elemendi, milleks on 4. See sisestab selle õigesse kohta, mis on neljas positsioon jne. Nimekiri on nüüd sorteeritud!
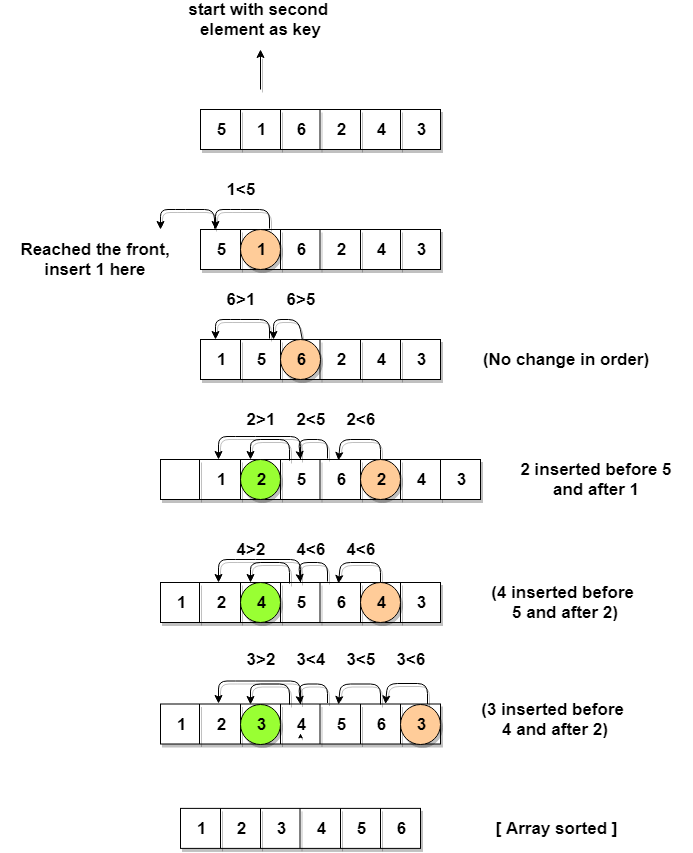
Näitest näeme, et algoritm võtab loendi sortimiseks kuus võrdlust ja vahetust. Seda seetõttu, et see võtab n2 võrdlusi ja vahetusi n üksuse loendi sorteerimiseks. Sel juhul n = 6.
Kuidas parandada sisestamise sortimise aja keerukust?
Sisestussortimise käitusaeg on O(n2), saab seda parandada, kasutades paremat sortimisalgoritmi, näiteks kiirsortimist.
Quicksortil on O(n log n) käitusaeg, mis on palju kiirem kui O(n2).
Kuid mõnel juhul võib sisestamise sortimine olla kiirem kui kiirsortimine.
Näiteks kui loend on juba korras, võtab sisestamise sortimine vähem aega kui kiirsortimine.
Praktikas rakendatakse sisestussortimist sageli mõne koodirea abil, mistõttu on see populaarne valik väikeste massiivide sortimiseks.
Selle algoritmi kasutamisel tuleks aga arvestada aja keerukusega.
Aja keerukus
Halvima juhtumi keerukus O(n2):
Ajaline keerukus suureneb massiivi suurusega. See võtab n2 võrdlusi ja vahetusi n üksuse loendi sorteerimiseks.
Näiteks kui meil on massiiv suurusega 1000, võtab algoritm massiivi sortimiseks 1,000,000 XNUMX XNUMX võrdlust ja vahetust.
Parima juhtumi keerukus O(n):
Ajaline keerukus on sama, mis sisendmassiivi suurus. I
n üksuse loendi sortimiseks kulub n võrdlust ja vahetust. Näiteks kaaluge massiivi suurusega 5. Algoritm võtab massiivi sortimiseks viis võrdlust ja vahetust.
Juhtumi keskmine keerukus O(n2):
Ajaline keerukus on antud juhul halvima ja parima keerukuse vahel.
See võtab n2 võrdlusi ja vahetusi n üksuse loendi sorteerimiseks.
Seega on sisestussorteerimine stabiilne sortimisalgoritm.
Miks on sisestamise sortimine stabiilne?
Sisestamise sortimine on stabiilne, kuna see säilitab sisendmassiivi võrdsete elementide järjekorra.
See on oluline paljude rakenduste, näiteks andmete otsimise või finantsanalüüsi jaoks. Näiteks kui meil on kaks numbriloendit ja tahame neid võrrelda, peame veenduma, et elementide järjekord on säilinud.
Kui loendid ei ole sorteeritud, siis me neid täpselt ei võrdle.





Jäta vastus