La representación neuronal es una técnica emergente en el aprendizaje profundo que tiene como objetivo aumentar la canalización clásica de gráficos por computadora con redes neuronales.
Un algoritmo de renderizado neuronal requerirá un conjunto de imágenes que representen diferentes ángulos de la misma escena. Estas imágenes luego se alimentarán a una red neuronal para crear un modelo que pueda generar nuevos ángulos de la misma escena.
La brillantez detrás del renderizado neuronal radica en cómo puede recrear con precisión escenas fotorrealistas detalladas sin tener que depender de métodos clásicos que pueden ser más exigentes desde el punto de vista computacional.
Antes de profundizar en cómo funciona la representación neuronal, repasemos los conceptos básicos de la representación clásica.
¿Qué es la interpretación clásica?
Primero comprendamos los métodos típicos utilizados en el renderizado clásico.
La representación clásica se refiere al conjunto de técnicas utilizadas para crear una imagen 2D de una escena tridimensional. También conocido como síntesis de imágenes, el renderizado clásico utiliza varios algoritmos para simular cómo la luz interactúa con diferentes tipos de objetos.
Por ejemplo, renderizar un ladrillo sólido requerirá un conjunto particular de algoritmos para determinar la posición de la sombra o qué tan bien iluminado estará cada lado de la pared. Del mismo modo, los objetos que reflejan o refractan la luz, como un espejo, un objeto brillante o una masa de agua, también requerirán sus propias técnicas.

En el renderizado clásico, cada activo se representa con una malla poligonal. Luego, un programa de sombreado usará el polígono como entrada para determinar cómo se verá el objeto dada la iluminación y el ángulo especificados.
La representación realista requerirá mucho más poder de cómputo ya que nuestros activos terminan teniendo millones de polígonos para usar como entrada. La salida generada por computadora que es común en los éxitos de taquilla de Hollywood suele tardar semanas o incluso meses en renderizarse y puede costar millones de dólares.
El enfoque de trazado de rayos es particularmente costoso porque cada píxel en la imagen final requiere un cálculo de la ruta que toma la luz desde la fuente de luz hasta el objeto y la cámara.

Los avances en el hardware han hecho que la representación de gráficos sea mucho más accesible para los usuarios. Por ejemplo, muchas de las últimas videojuegos permitir efectos de trazado de rayos, como reflejos y sombras fotorrealistas, siempre que su hardware esté a la altura.
Las últimas GPU (unidades de procesamiento gráfico) están diseñadas específicamente para ayudar a la CPU a manejar los cálculos altamente complejos necesarios para generar gráficos fotorrealistas.
El auge de la representación neuronal
El renderizado neuronal trata de abordar el problema del renderizado de una manera diferente. En lugar de usar algoritmos para simular cómo la luz interactúa con los objetos, ¿qué pasa si creamos un modelo que aprende cómo debería verse una escena desde un cierto ángulo?
Puede considerarlo como un atajo para crear escenas fotorrealistas. Con el renderizado neuronal, no necesitamos calcular cómo interactúa la luz con un objeto, solo necesitamos suficientes datos de entrenamiento.
Este enfoque permite a los investigadores crear renderizados de alta calidad de escenas complejas sin tener que realizar
¿Qué son los campos neuronales?
Como se mencionó anteriormente, la mayoría de los renderizados 3D usan mallas poligonales para almacenar datos sobre la forma y la textura de cada objeto.
Sin embargo, los campos neuronales están ganando popularidad como método alternativo para representar objetos tridimensionales. A diferencia de las mallas poligonales, los campos neuronales son diferenciables y continuos.
¿A qué nos referimos cuando decimos que los campos neuronales son diferenciables?
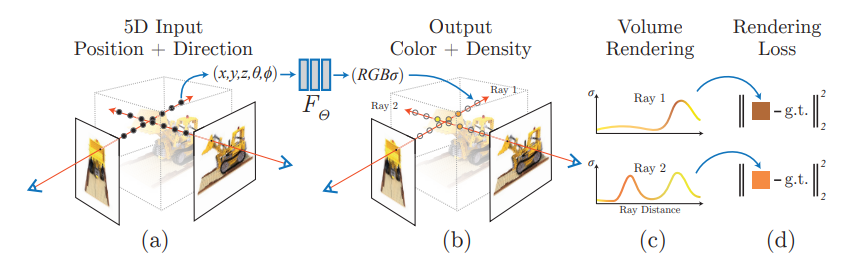
Ahora se puede entrenar una salida 2D de un campo neuronal para que se vuelva fotorrealista simplemente ajustando los pesos de la red neuronal.
Usando campos neuronales, ya no necesitamos simular la física de la luz para renderizar una escena. El conocimiento de cómo se iluminará el render final ahora se almacena implícitamente dentro de los pesos de nuestro red neural.
Esto nos permite crear imágenes y videos novedosos con relativa rapidez a partir de solo un puñado de fotos o secuencias de video.
¿Cómo entrenar un campo neuronal?
Ahora que conocemos los conceptos básicos de cómo funciona un campo neuronal, echemos un vistazo a cómo los investigadores pueden entrenar un campo de radiación neuronal o NERF.
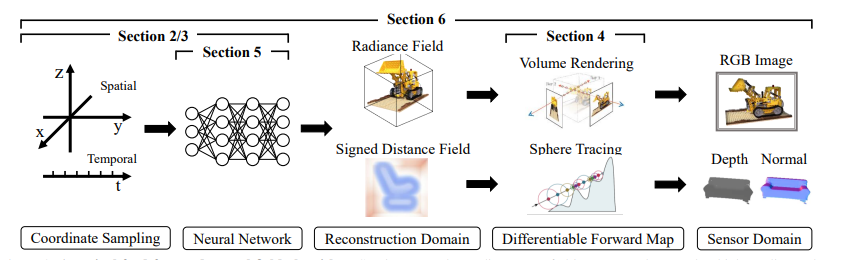
Primero, necesitaremos muestrear las coordenadas aleatorias de una escena e introducirlas en una red neuronal. Esta red podrá entonces producir cantidades de campo.
Las cantidades de campo producidas se consideran muestras del dominio de reconstrucción deseado de la escena que queremos crear.
Luego necesitaremos mapear la reconstrucción a imágenes 2D reales. Luego, un algoritmo calculará el error de reconstrucción. Este error guiará a la red neuronal para optimizar su capacidad de reconstruir la escena.
Aplicaciones de renderizado neuronal
Síntesis de vista novedosa
La síntesis de vista novedosa se refiere a la tarea de crear perspectivas de cámara desde nuevos ángulos utilizando datos de un número limitado de perspectivas.
Las técnicas de renderizado neuronal intentan adivinar la posición relativa de la cámara para cada imagen en el conjunto de datos e introducen esos datos en una red neuronal.
Luego, la red neuronal creará una representación 3D de la escena donde cada punto en el espacio 3D tiene un color y una densidad asociados.

Una nueva implementación de NeRF en Google Street View utiliza una síntesis de vista novedosa para permitir a los usuarios explorar ubicaciones del mundo real como si estuvieran controlando una cámara que graba un video. Esto permite a los turistas explorar destinos de manera inmersiva antes de decidir viajar a un sitio específico.
Avatares fotorrealistas
Las técnicas avanzadas de representación neuronal también pueden allanar el camino para avatares digitales más realistas. Estos avatares se pueden usar para varios roles, como asistentes virtuales o servicio al cliente, o como una forma para que los usuarios inserten su imagen en un videojuego o renderizado simulado.
![]()
Por ejemplo, una publicado en marzo de 2023 sugiere el uso de técnicas de renderizado neuronal para crear un avatar fotorrealista después de unos minutos de video.
Conclusión
La representación neuronal es un campo de estudio emocionante que tiene el potencial de cambiar toda la industria de gráficos por computadora.
La tecnología podría reducir la barrera de entrada para la creación de activos 3D. Es posible que los equipos de efectos visuales ya no tengan que esperar días para renderizar algunos minutos de gráficos fotorrealistas.
La combinación de la tecnología con las aplicaciones VR y AR existentes también puede permitir a los desarrolladores crear experiencias más inmersivas.
¿Cuál crees que es el verdadero potencial de la renderización neuronal?





Deje un comentario