Índice del contenido[Esconder][Espectáculo]
Para recopilar información de sitios web para análisis, investigación u objetivos de marketing, el web scraping es una técnica crucial. Afortunadamente, existen numerosas herramientas que admiten navegadores headless y headful, que son útiles para el web scraping.
Los navegadores headfull vienen con una interfaz gráfica de usuario (GUI), mientras que los navegadores headfull no. Estas tecnologías pueden extraer datos de páginas web tanto manual como automáticamente, lo que las hace muy beneficiosas.
Cuando se manejan muchos datos, los navegadores sin cabeza son la mejor opción. Para automatizar su proceso de extracción de datos, necesitará estas herramientas, que le ahorrarán una tonelada de tiempo y trabajo.
Además, lo ayudan a mejorar la precisión y la eficacia de la extracción de datos, lo que podría generar resultados más fructíferos en general.
Estas herramientas también pueden ayudar a reducir la posibilidad de que surjan errores al copiar y pegar datos manualmente porque tienen la capacidad de extraer datos de manera organizada.
En pocas palabras, es imposible trabajar sin herramientas que admitan navegadores headless y headfull si se dedica al web scraping.
En este artículo, veremos los mejores navegadores headless y headfull para web scraping.
1. Datos brillantes
Bright Data es un programa de web scraping que ofrece opciones para la recopilación de datos para empresas y particulares. A diferencia de los sistemas de raspado en línea anteriores, Bright Data viene precargado con varios navegadores, pero funciona como un navegador sin interfaz.
Aunque se ejecuta como un navegador sin cabeza en el backend, esto apunta al hecho de que los usuarios pueden interactuar con él a través de una interfaz gráfica de usuario (GUI), lo que lo hace más accesible y fácil de usar.
Esta funcionalidad será especialmente útil para aquellos que no saben mucho sobre codificación o desean un enfoque más simple para el web scraping. Los usuarios pueden navegar rápidamente por sitios web complejos con interacciones similares a las humanas gracias al navegador headfull de Bright Data.
Para mantener su anonimato y no ser descubierto, también proporciona capacidades de vanguardia como la rotación de IP, la toma de huellas dactilares del navegador y la falsificación de agentes de usuario. Con el uso de IA, Scraping Browser podrá ir más allá incluso de las protecciones de detección de bots más avanzadas.
De hecho, Scraping Browser es tan sofisticado que incluso puede simular las acciones del navegador de un usuario real, brindándole resultados más exitosos y datos precisos.
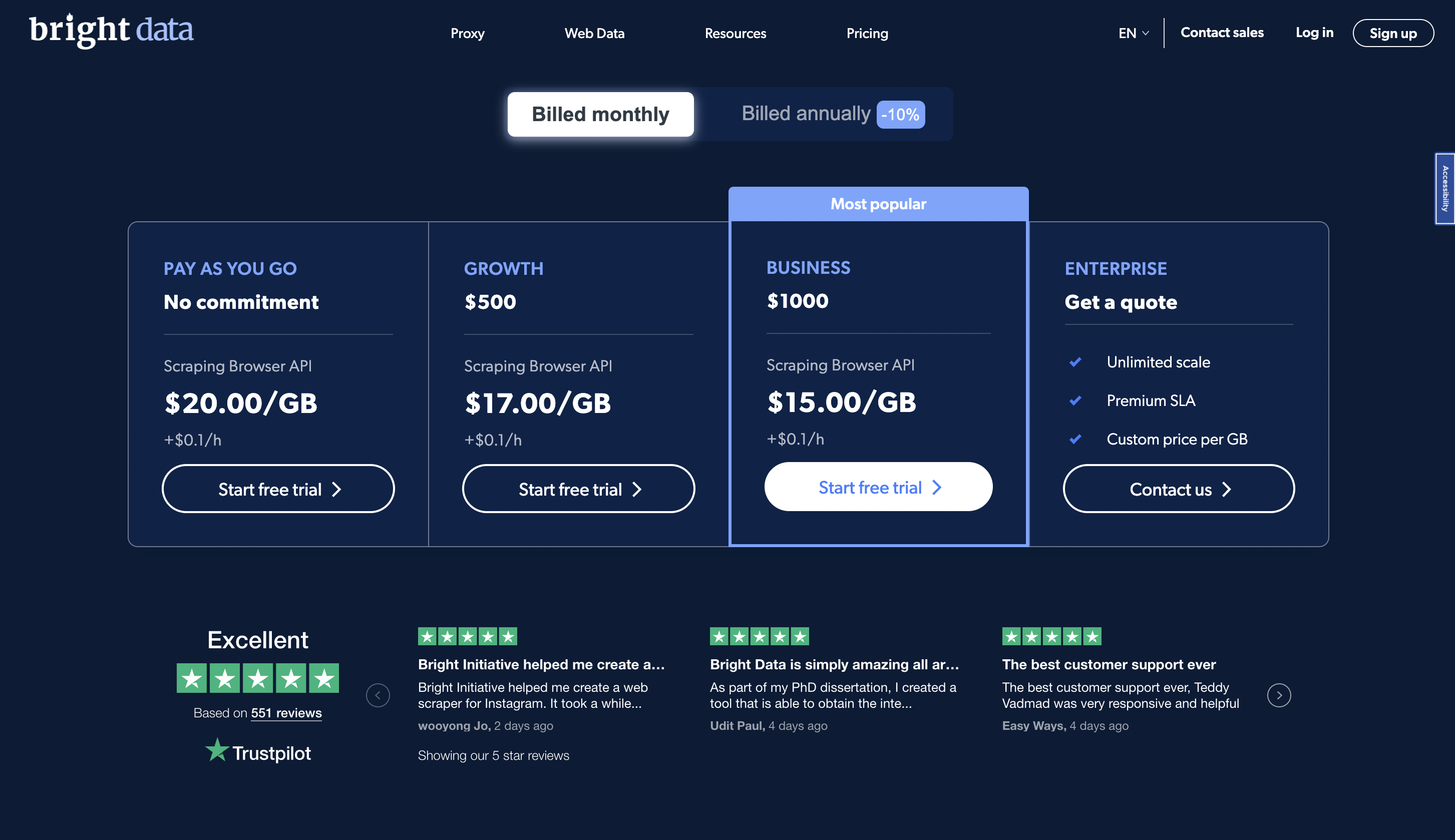
Precios
Puede probar la plataforma de forma gratuita y el precio premium comienza desde $20/GB en un plan de pago por uso.
2. zyte
Como proveedor de herramientas de raspado en línea, Zyte, anteriormente conocido como Scrapinghub, permite a las empresas capturar y analizar datos de Internet a escala.
La plataforma de raspado en línea de Zyte está diseñada para manejar incluso los sitios web más complicados y dinámicos, e incluye una variedad de características de vanguardia como la rotación automatizada de IP, la toma de huellas dactilares del navegador y la suplantación de agentes de usuario para garantizar que sus operaciones de raspado permanezcan privadas y desapercibidas.
El hecho de que la plataforma de web scraping de Zyte sea compatible con los modos de navegación headless y headfull es una de sus ventajas distintivas. El navegador funciona en modo sin cabeza en segundo plano sin una interfaz gráfica de usuario, lo que aumenta su eficiencia para operaciones de raspado extensas.
Sin embargo, el navegador funciona con una GUI en modo headhead, lo que puede resultar ventajoso cuando necesita extraer datos de sitios web con interfaces de usuario complejas.
Además, debido a que la plataforma de Zyte se basa en la base Scrapy gratuita y de código abierto, se puede adaptar para satisfacer sus necesidades específicas y es extremadamente configurable. Puede recuperar de forma rápida y sencilla los datos que desea utilizando Zyte, lo que le brinda una ventaja competitiva en su negocio.
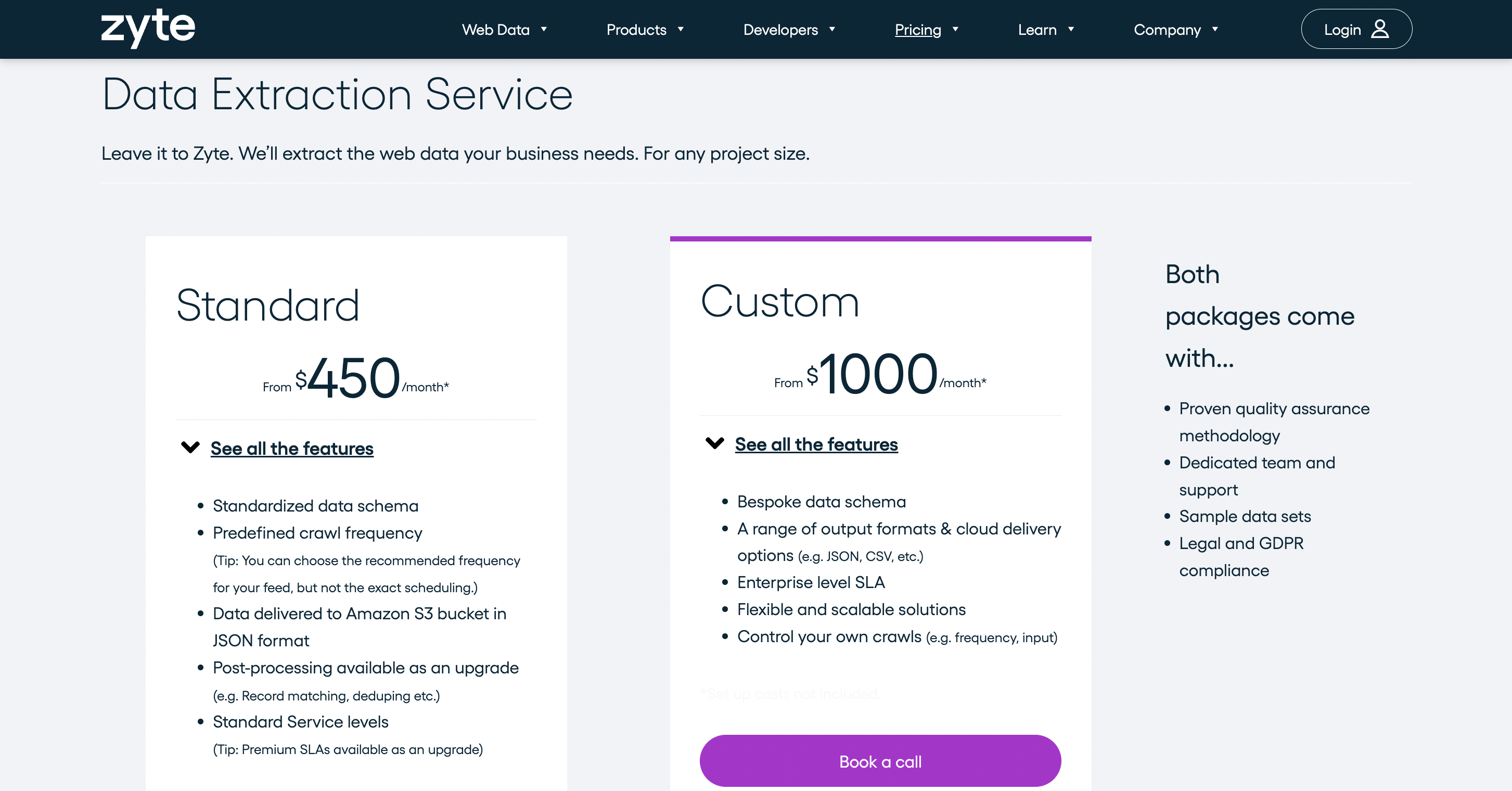
Precios
Ofrece múltiples planes de precios y cobra $ 450 / mes por el servicio de extracción de datos.
3. octoparse
Puede recopilar datos de páginas web sin escribir ningún código con Octoparse, una aplicación de web scraping basada en la nube. Cualquiera que desee copiar texto, fotos o videos puede elegirlos con facilidad gracias a la interfaz fácil de usar.
Octoparse es una herramienta flexible que admite la navegación headless y headfull, es la mejor opción para proyectos de web scraping de cualquier tamaño y complejidad. Ser capaz de raspar páginas web dinámicas e interactivas, lo que puede ser difícil para muchos otros programas de raspado web, es una de sus características más fuertes.
Puede crear procesos de extracción complejos con numerosas fases, declaraciones condicionales y bucles, lo que aumenta la flexibilidad y la personalización de la extracción. Excel, CSV y SQL son solo algunos de los formatos de exportación que proporciona Octoparse, lo que simplifica el uso de los datos extraídos en otros programas.
Además, Octoparse presenta un grupo de proxy integrado que garantiza el raspado anónimo y ayuda a evitar la prohibición de IP.
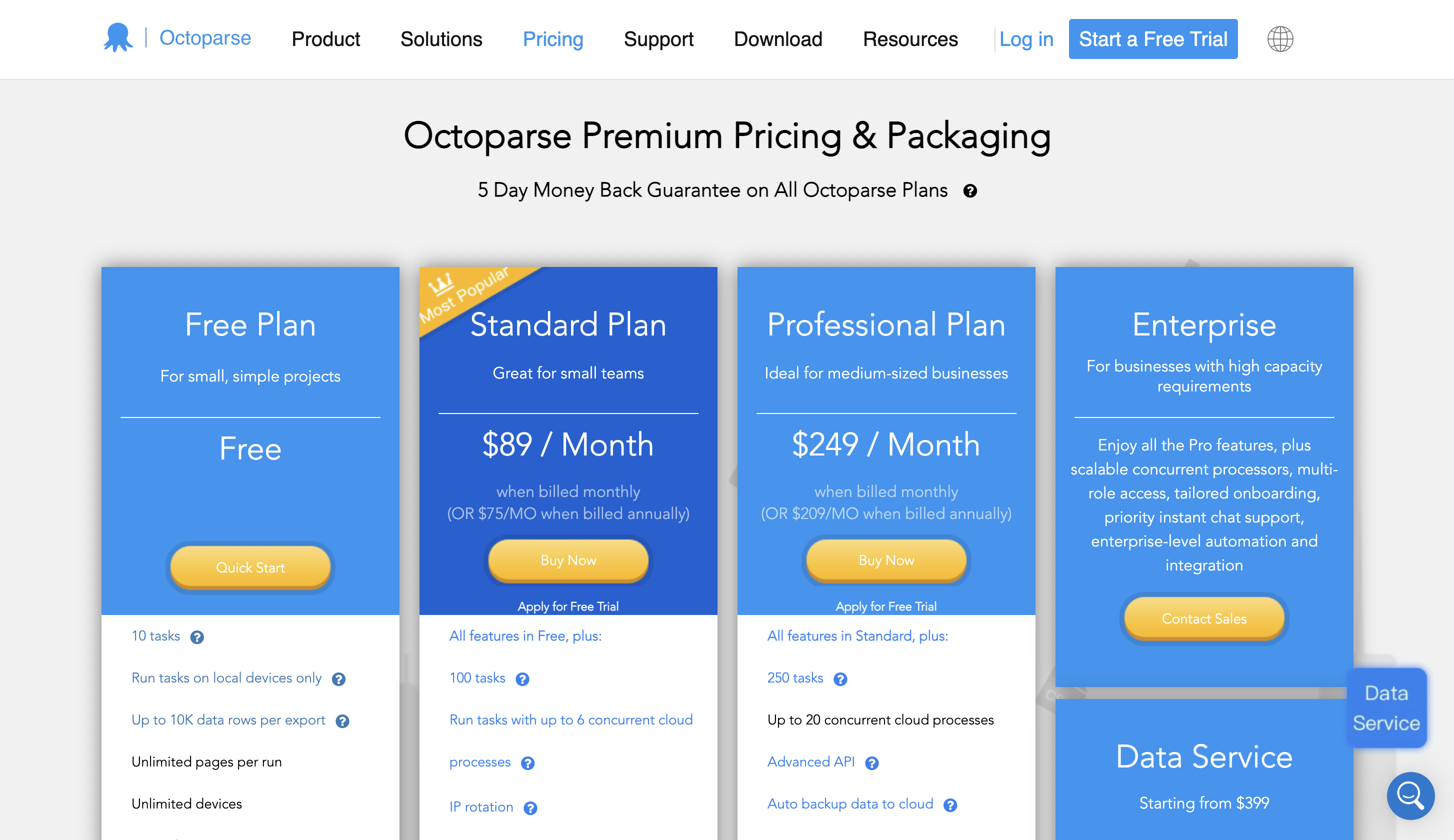
Precios
Puede comenzar a usarlo de forma gratuita y el precio premium comienza desde $ 89 / mes.
4. apificar
Apify es una plataforma todo en uno de raspado web y automatización que ofrece una variedad de funciones potentes. Es compatible con navegadores headless y headful y tiene una interfaz de usuario intuitiva que simplifica incluso a los usuarios sin conocimientos técnicos la creación de tareas de scraping.
Algunas de sus mejores características son la capacidad de Apify para manejar trabajos de scraping difíciles, la compatibilidad con varios idiomas y la ampliación para manejar proyectos de scraping a gran escala.
Además, Apify brinda acceso a un amplio mercado de raspadores listos para usar que se pueden personalizar rápidamente para satisfacer sus demandas únicas.
Con su compatibilidad con navegadores autónomos, Apify puede navegar por interfaces de usuario desafiantes y extraer datos de sitios web dinámicos mientras extrae información de forma rápida y eficiente de grandes volúmenes de datos.
Apify es una herramienta útil para una variedad de aplicaciones de raspado en línea, incluida la generación de clientes potenciales, el análisis competitivo, la investigación de mercado y la agregación de contenido.
Apify aumenta la precisión y la eficiencia mientras ahorra tiempo y esfuerzo al automatizar el proceso de extracción de datos. Es una herramienta sólida tanto para usuarios técnicos como no técnicos debido a su funcionalidad y diseño fácil de usar.
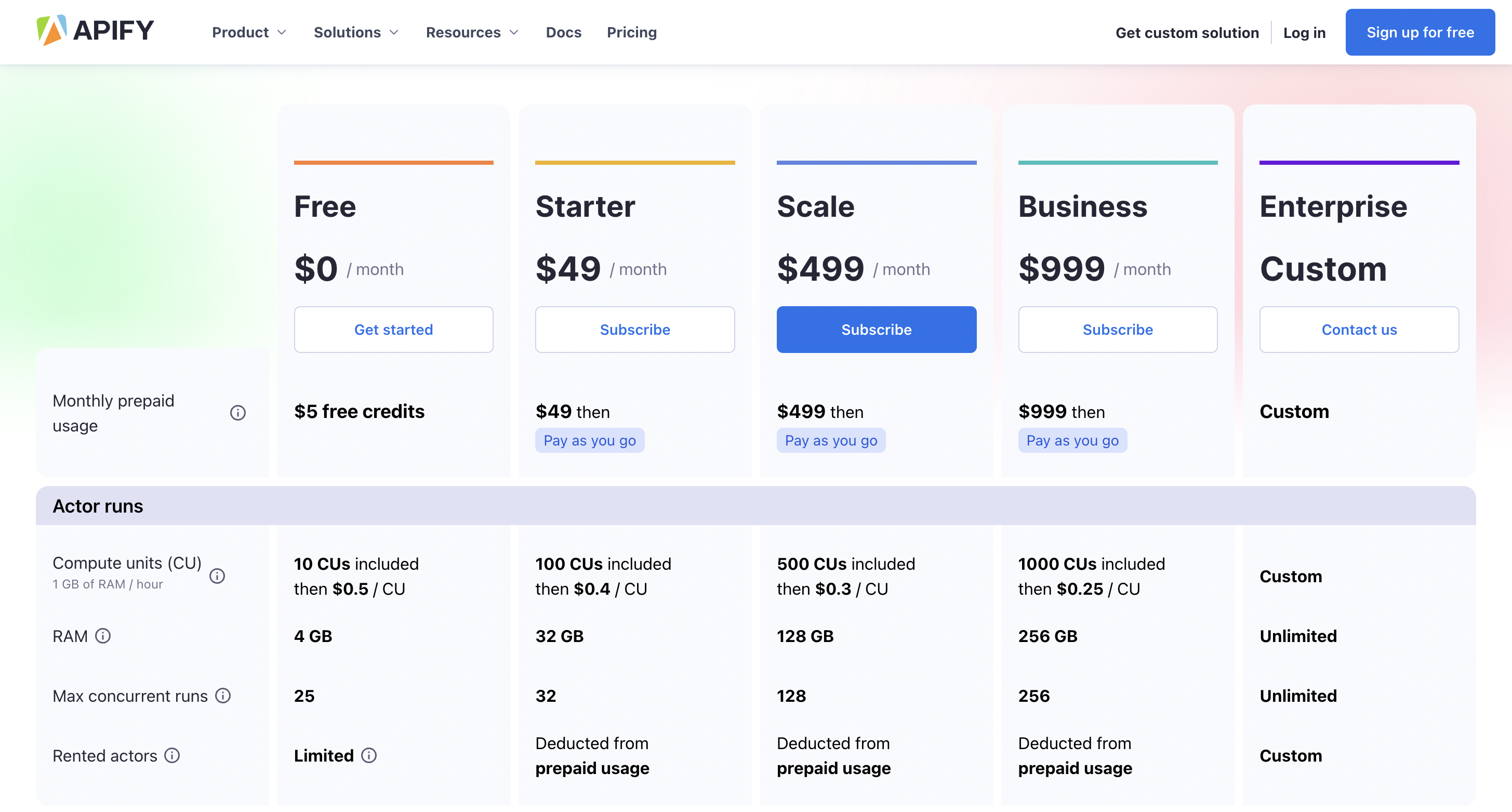
Precios
Puede comenzar a usarlo de forma gratuita y el precio premium comienza desde $ 49 / mes.
5. RaspadoAbeja
La excelente aplicación de raspado en línea ScrapingBee simplifica la automatización del proceso de extracción de datos de los sitios web.
Sus capacidades, como las de manejar la representación de JavaScript, la resolución de CAPTCHA y la rotación de agentes de usuario, permiten eludir las defensas anti-raspado de los sitios web. por lo que es una gran opción para tareas de web scraping.
Los usuarios tienen un alto grado de libertad con esta herramienta porque funciona tanto con navegadores headless como headful. Es importante señalar que ScrapingBee usa navegadores sin cabeza por defecto, lo cual es perfecto para recuperar automáticamente enormes volúmenes de datos.
Para interactuar con sitios web que tienen una interfaz compleja, los usuarios pueden cambiar a navegadores headful. Para garantizar una extracción de datos efectiva, ScrapingBee también mantiene un grupo de proxies geolocalizados que se verifican y modifican periódicamente.
Los usuarios pueden reducir el tiempo y el esfuerzo durante el web scraping al utilizar ScrapingBee como un navegador headless o headfull al mismo tiempo que garantizan la corrección y la integridad de los datos recuperados. También tiene muchas funciones útiles, como formateo de datos, rotación de proxy y conectividad API, lo que la convierte en una herramienta útil tanto para empresas como para estudiantes.
Precios
El precio premium comienza desde $ 49 / mes.
6. ParseHub
Sin necesidad de conocimientos técnicos, los usuarios pueden recopilar datos de sitios web utilizando la aplicación de web scraping ParseHub. Una de sus mayores características es lo fácil que es de usar; los usuarios pueden elegir los datos que desean extraer simplemente haciendo clic en los elementos.
Además, tiene la capacidad de reconocer la paginación automáticamente, lo que facilita a los usuarios extraer información de varias páginas. Para extraer datos de sitios web con interfaces de usuario básicas o complicadas, ParseHub admite navegadores con y sin cabeza.
Además, proporciona rotación automática de IP, lo que dificulta que los sitios web identifiquen y prohíban la actividad de raspado. ParseHub garantiza que los datos se extraigan de manera organizada con la ayuda de sus amplias capacidades de formateo de datos, lo que simplifica el análisis y la integración del sistema.
Además, ParseHub tiene un modo inteligente que reconoce y recopila información automáticamente de sitios web similares. ParseHub puede reconocer y recopilar datos de sitios web con estructuras similares, como sitios web de comercio electrónico, utilizando inteligencia artificial (AI). Esta característica aumenta la precisión y la productividad al requerir menos esfuerzo y ahorrar tiempo.
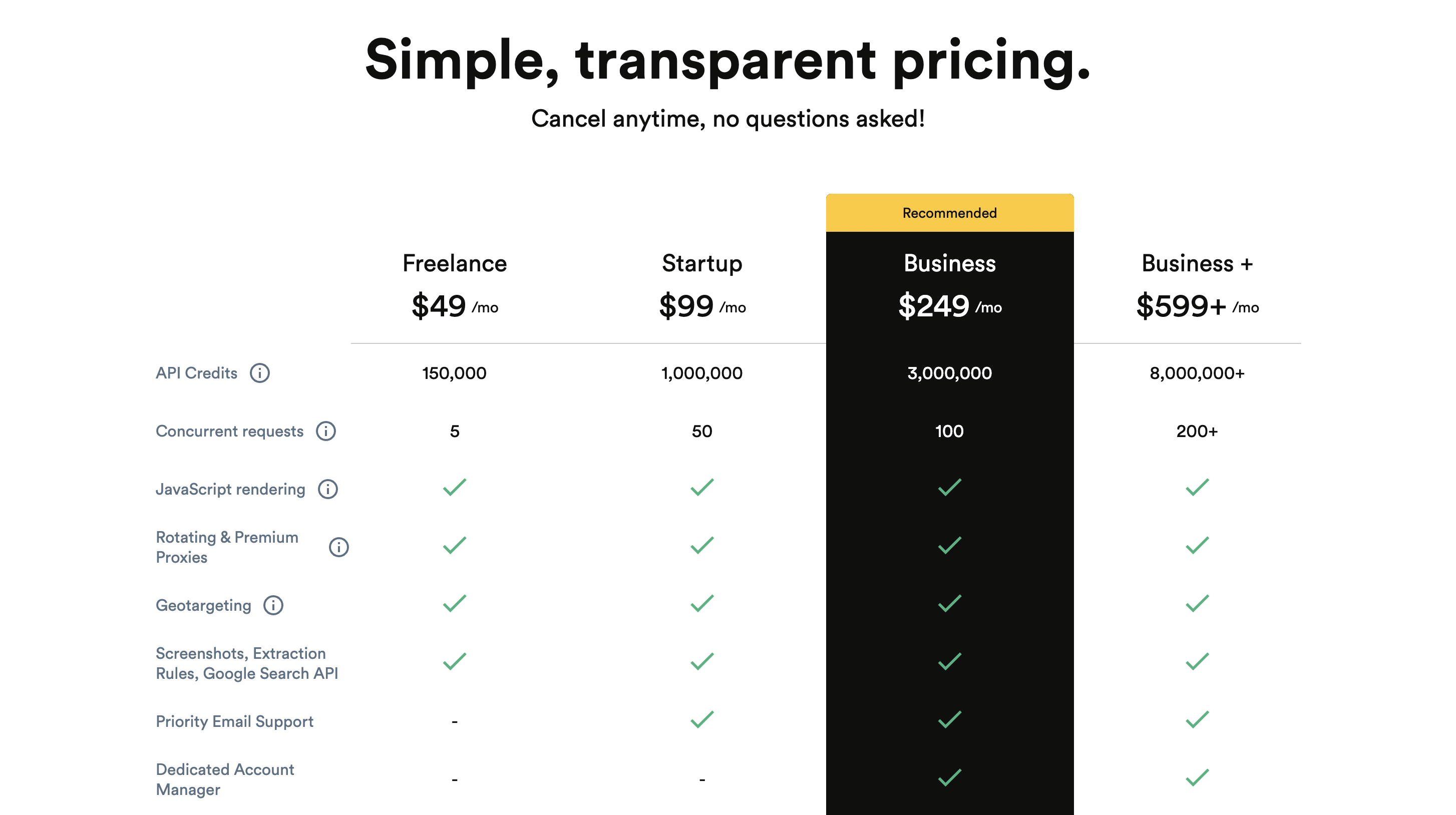
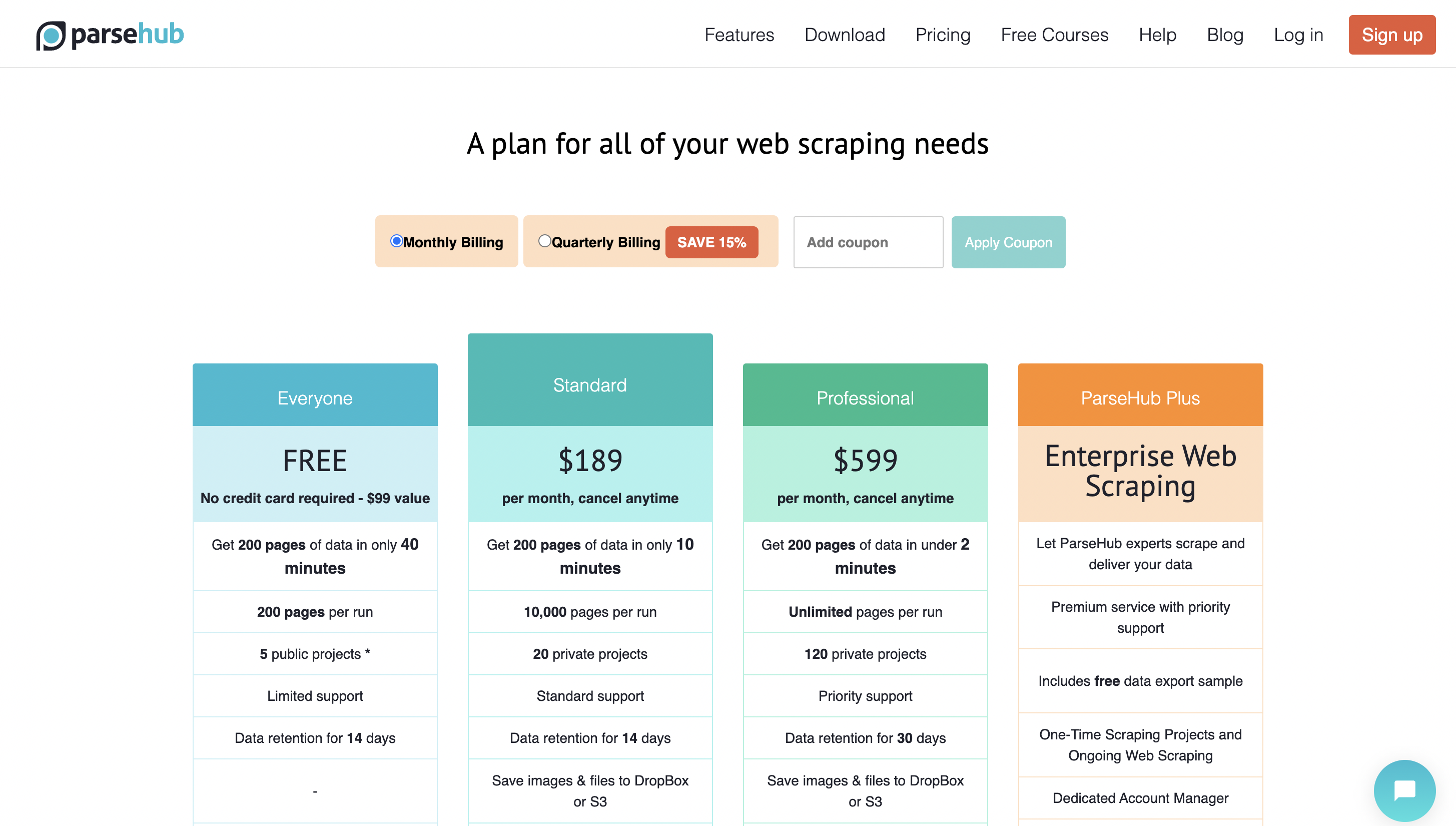
Precios
Puede comenzar a usarlo de forma gratuita y el precio premium comienza desde $ 189 / mes.
7. WebHarvy
WebHarvy es una potente herramienta de raspado en línea que permite a las organizaciones raspar datos de sitios web de manera rápida, precisa y eficiente. Está hecho para extraer información de muchos sitios web, incluidos motores de búsqueda, redes sociales, sitios de comercio electrónico y directorios.
Sin ninguna experiencia previa en codificación, los usuarios pueden explorar y crear trabajos de scraping sin esfuerzo debido a su interfaz fácil de usar. Una de las características más importantes de WebHarvy es su capacidad para recuperar datos de páginas web con tecnología de JavaScript y AJAX a los que otras herramientas de extracción no podrían acceder.
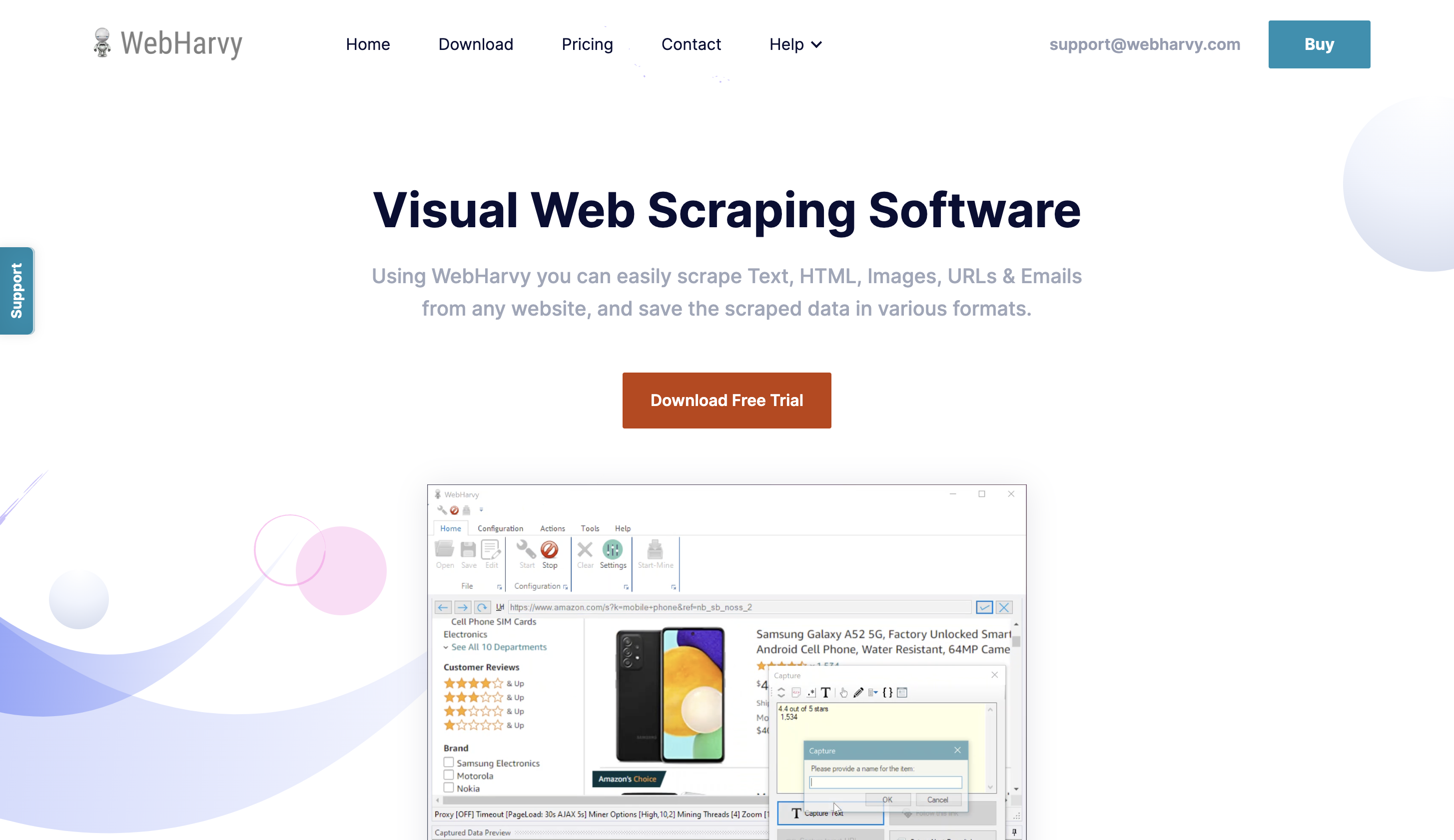
Además, ofrece una interfaz de apuntar y hacer clic que simplifica la elección de la información de una página web que desea extraer. WebHarvy tiene modos de navegación sin cabeza y con cabeza. Para un raspado de datos más rápido y efectivo, puede operar en modo sin cabeza.
El modo Headful es útil cuando se trabaja con sitios web complicados que requieren la participación del usuario. También puede navegar entre numerosas páginas y completar formularios, lo cual es útil cuando se extraen datos de sitios web con varias páginas.
Precios
El precio premium comienza desde $ 129 para una licencia de usuario único.

8. Kit de flujo de datos
Con Dataflow Kit, una sólida herramienta de extracción en línea, se pueden recopilar y analizar datos de una variedad de sitios web, incluidos las redes sociales sitios web, motores de búsqueda, sitios web de comercio electrónico y sitios web de noticias. Una de sus mejores características es su capacidad para recopilar datos de forma rápida y eficiente de sitios web complicados y dinámicos.
Es ideal para raspar sitios web a los que es difícil acceder utilizando otros métodos, ya que es muy fácil de usar. Tanto un navegador sin cabeza como un navegador con cabeza son funcionales con Dataflow Kit. Se proporcionan funciones avanzadas como la rotación de proxy y agente de usuario, la prevención del bloqueo de IP y la detección de antibots para garantizar un raspado efectivo.
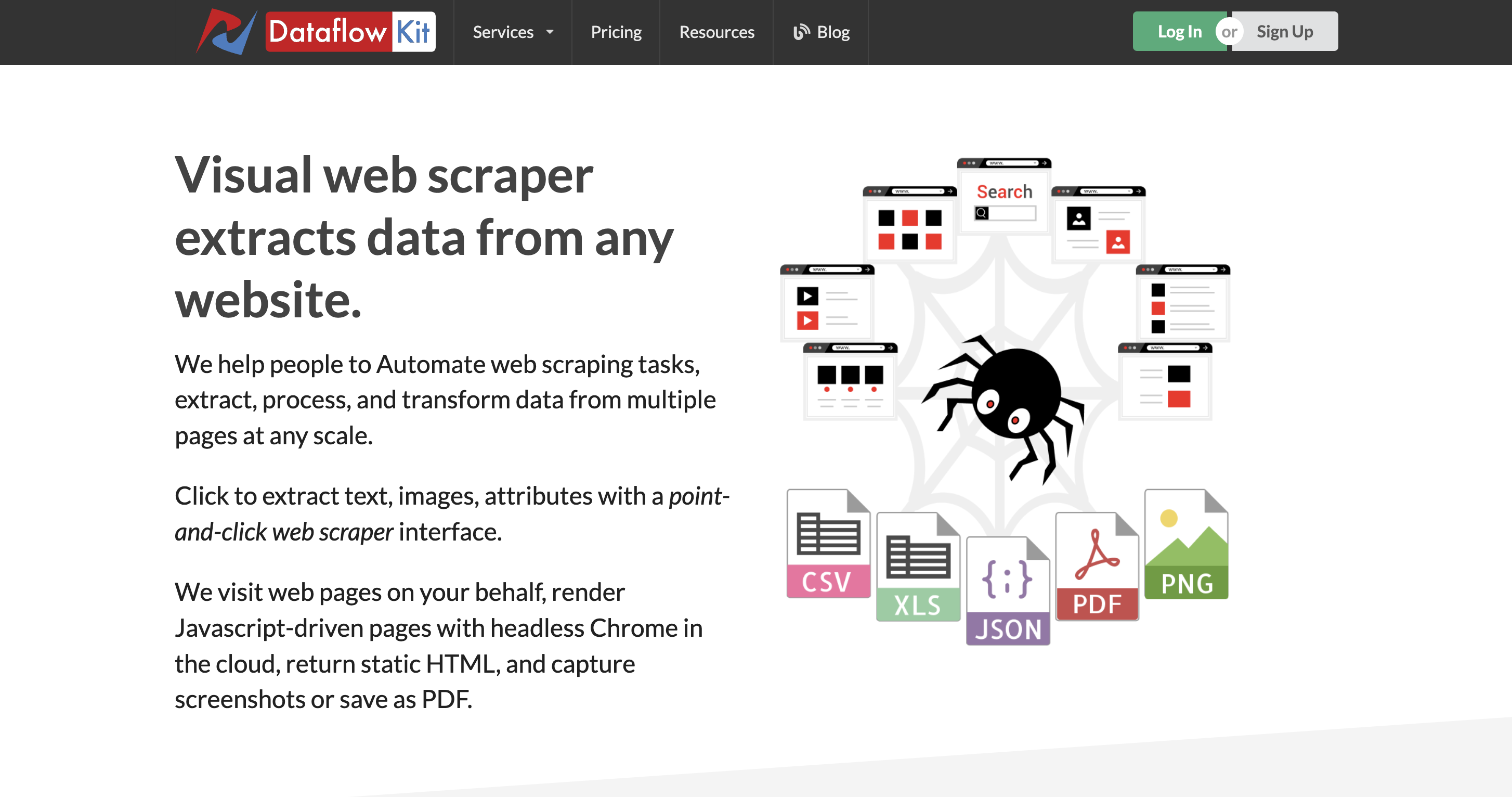
Además, ofrece una interfaz fácil de usar que permite a los clientes crear, planificar y administrar sus actividades de scraping sin ninguna experiencia en programación. Para aplicaciones de web scraping a gran escala, su motor de scraping efectivo es una solución fantástica porque está optimizado para manejar datos de manera rápida y efectiva.
Los datos raspados se pueden exportar simplemente a una variedad de formatos, incluidos CSV, JSON y XML, lo que le permite analizarlos y utilizarlos de la forma que mejor le parezca. Además, Dataflow Kit ofrece una variedad de opciones de interfaz, incluidas API y Zapier, para ayudarlo a optimizar su flujo de trabajo y automatizar su proceso de extracción de datos.
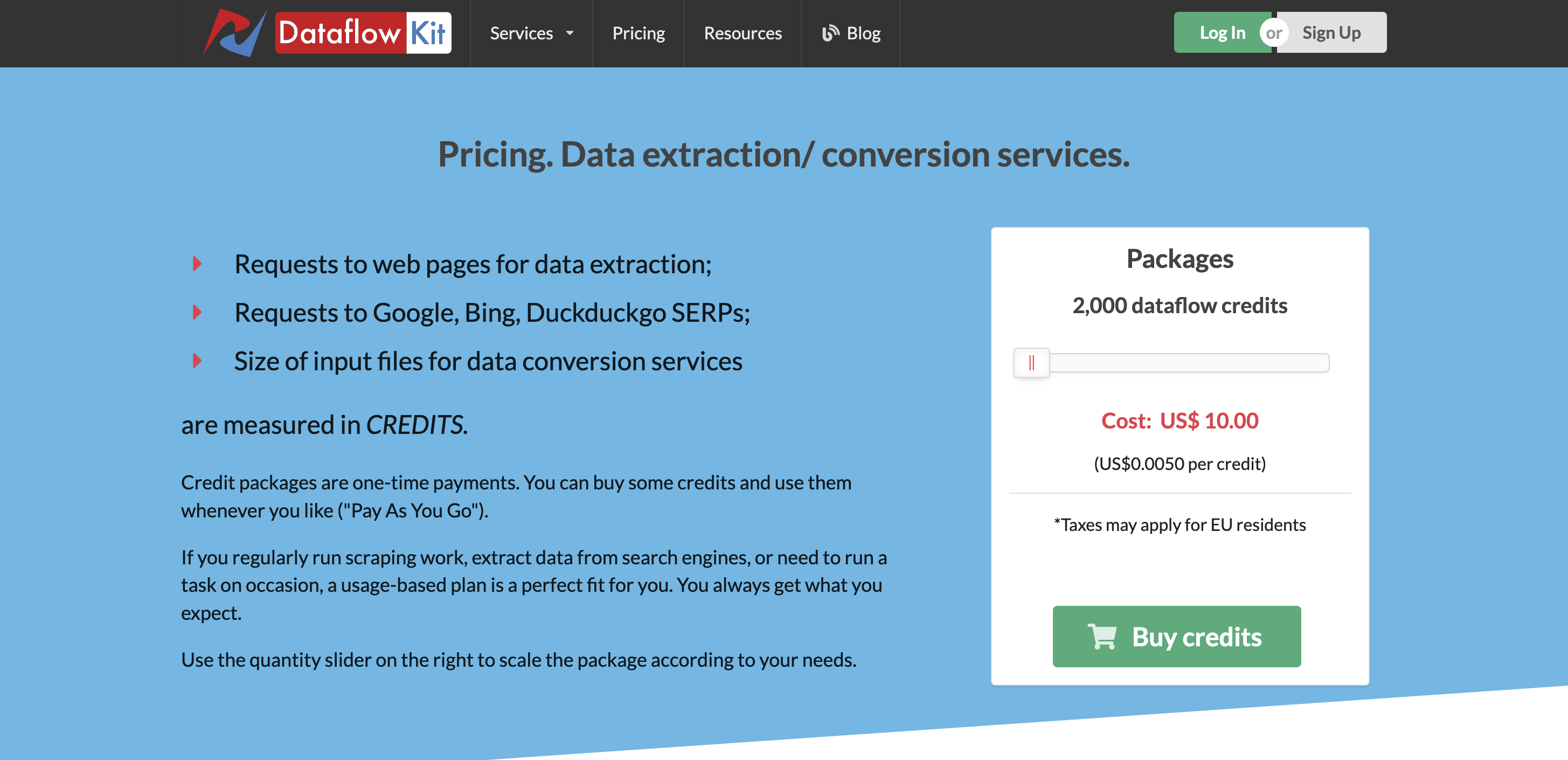
Precios
El precio premium comienza desde $10 por 2000 créditos de flujo de datos, que puede usar según sus necesidades.
9. Import.io
Con la ayuda de la herramienta de raspado web basada en la nube Import.io, los usuarios pueden raspar datos de sitios web sin ninguna experiencia en programación. La simplicidad de uso es una de las características más atractivas de Import.io; todo lo que tiene que hacer es apuntar y hacer clic para encontrar los datos que desea raspar.
Los usuarios pueden evaluar los datos extraídos en tiempo real debido a sus potentes funciones de visualización. Import.io es un navegador sin cabeza que imita a un navegador web y se conecta a sitios web de la misma manera que lo haría una persona pero sin el requisito de una interfaz gráfica de usuario.
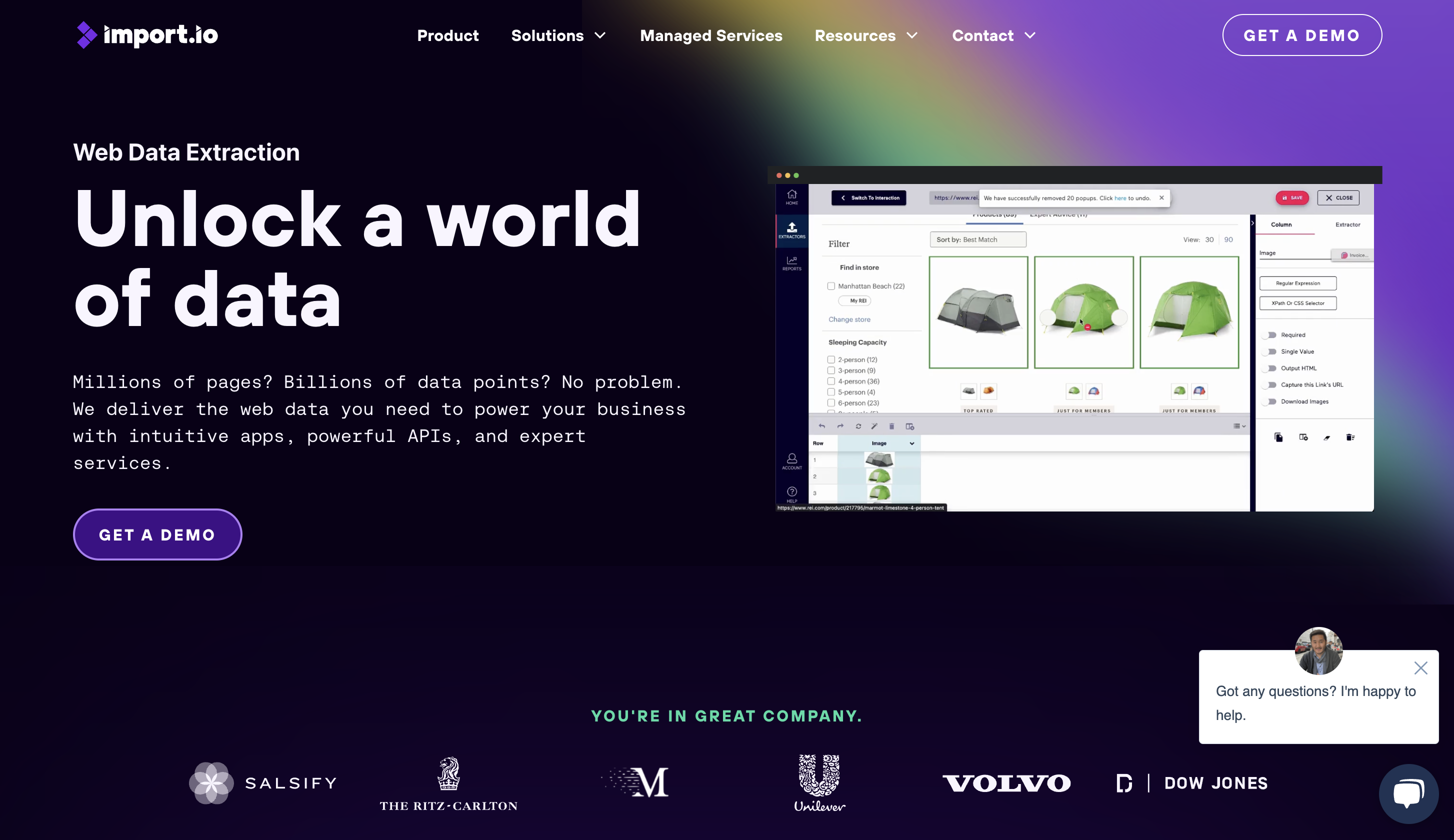
Esto mejora la eficiencia del web scraping y permite a los usuarios extraer datos de sitios web dinámicos que requieren la participación del usuario para mostrar información. Su extractor impulsado por IA permite a los usuarios extraer datos con solo unos pocos clics. El Extractor también puede identificar patrones de datos y extraer datos comparables de numerosas fuentes.
Los usuarios pueden automatizar sus esfuerzos de extracción y recibir actualizaciones frecuentes sobre los datos que desean con sus funciones de programación integrales. Import.io simplifica el uso de los datos extraídos en otras aplicaciones al permitirle vincularse con herramientas populares como Google Sheets y Zapier.
Precios
Los precios no figuran en el sitio web, hable con un experto al respecto.
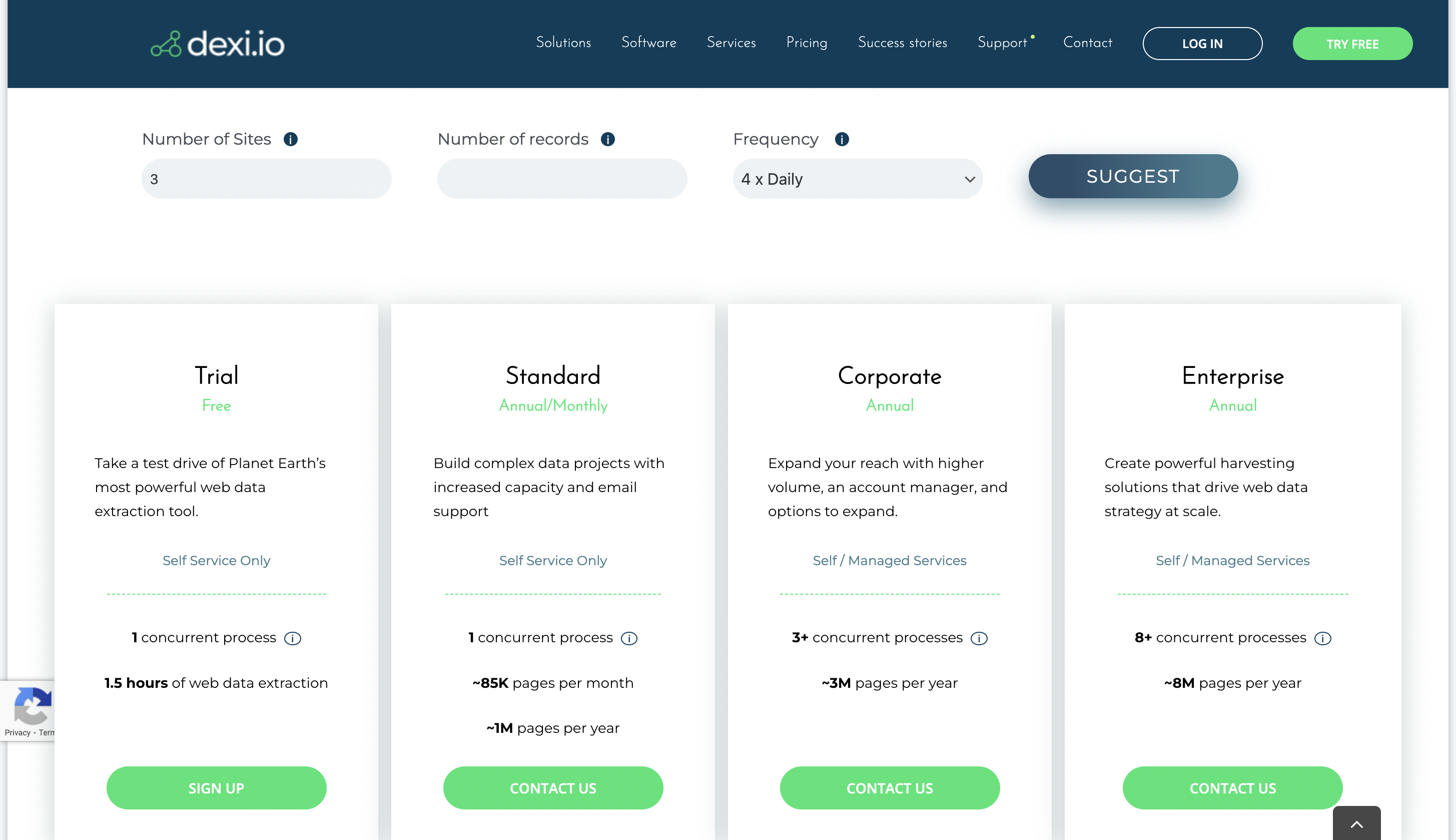
10. Dexi.io
La extracción de datos es simple con la ayuda de la robusta herramienta de web scraping Dexi.io. Puede recopilar datos de sitios web utilizando esta herramienta sin ninguna experiencia de codificación debido a su interfaz fácil de usar y sus posibilidades automatizadas.
Una de sus mejores características es su capacidad para raspar y combinar datos de muchas fuentes, incluidas páginas web, API y bases de datos. Gracias a la capacidad de procesamiento paralelo de Dexi.io, puede raspar grandes volúmenes de datos de manera rápida y efectiva.
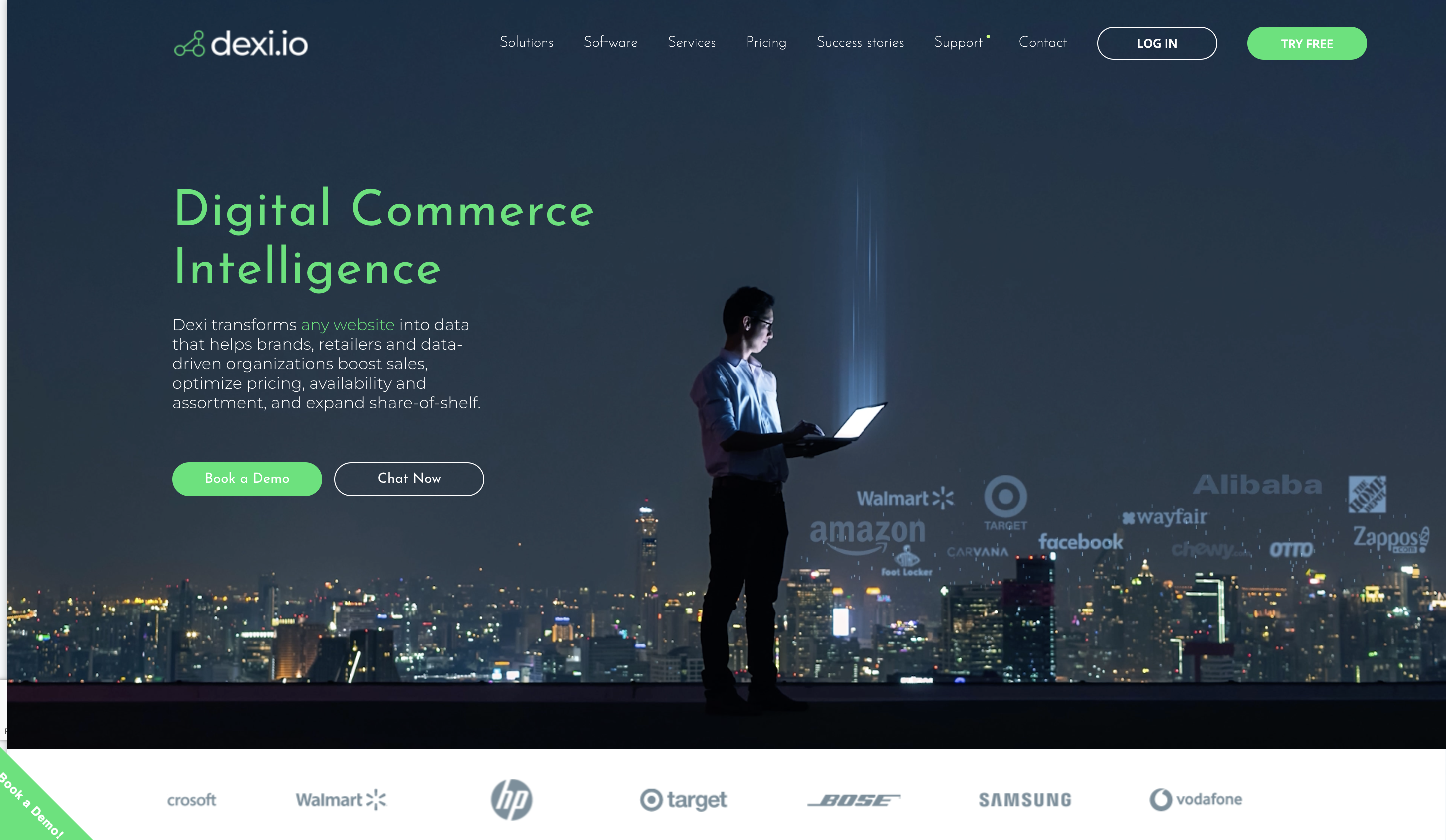
Dexi.io le ofrece la opción de seleccionar la mejor alternativa para sus necesidades de raspado porque funciona como un navegador sin cabeza y como un navegador con cabeza. Mientras que la opción de navegador headfull le permite ver e interactuar con el sitio web como si estuviera usando un navegador típico, la opción de navegador headfull le permite raspar datos sin mostrar la página en un navegador.
Esto simplifica la solución de cualquier problema de raspado y ajusta el procedimiento de raspado a sus preferencias. Puede exportar rápidamente datos extraídos de Dexi.io en una variedad de formatos, como CSV, JSON y Excel, para análisis adicionales o interacción con otras aplicaciones.
Además, proporciona alojamiento en la nube confiable y seguro para sus datos extraídos, lo que garantiza su seguridad y accesibilidad.
Precios
Puede probar la plataforma con su plan de prueba gratuito y comunicarse con el equipo para conocer su precio.
Conclusión
En conclusión, existen varias soluciones de web scraping en el mercado, cada una con ventajas y capacidades específicas. Hay muchas alternativas de datos para elegir, que van desde soluciones todo en uno como Bright Data y ScrapingBee hasta herramientas más especializadas como Apify y ParseHub.
Estos sistemas a menudo tienen capacidades como navegación sin cabeza, rotación de IP, falsificación de agentes de usuario y huellas dactilares del navegador para aumentar la efectividad, la confiabilidad y el secreto del raspado en línea.
Las herramientas de web scraping pueden brindarle acceso rápido y simple a una gran cantidad de información, ya sea que sea el propietario de una pequeña empresa que intenta investigar a sus competidores, un investigador que busca datos para respaldar su trabajo o un analista de datos que busca información sobre el comportamiento del consumidor. .
La posibilidad de errores e inconsistencias puede reducirse mientras potencialmente puede ahorrar tiempo y dinero al automatizar el proceso de recopilación de datos.





Deje un comentario