Πίνακας περιεχομένων[Κρύβω][Προβολή]
Τα βιντεοπαιχνίδια συνεχίζουν να αποτελούν πρόκληση για δισεκατομμύρια παίκτες σε όλο τον κόσμο. Μπορεί να μην το γνωρίζετε ακόμα, αλλά και οι αλγόριθμοι μηχανικής μάθησης έχουν αρχίσει να ανταποκρίνονται στην πρόκληση.
Αυτή τη στιγμή υπάρχει σημαντικός όγκος έρευνας στον τομέα της τεχνητής νοημοσύνης για να διαπιστωθεί εάν οι μέθοδοι μηχανικής μάθησης μπορούν να εφαρμοστούν σε βιντεοπαιχνίδια. Η ουσιαστική πρόοδος στον τομέα αυτό το δείχνει μάθηση μηχανής Οι πράκτορες μπορούν να χρησιμοποιηθούν για να μιμηθούν ή ακόμα και να αντικαταστήσουν τον ανθρώπινο παίκτη.
Τι σημαίνει αυτό για το μέλλον του βιντεοπαιχνίδια?
Είναι αυτά τα έργα απλώς για διασκέδαση ή υπάρχουν βαθύτεροι λόγοι για τους οποίους τόσοι πολλοί ερευνητές επικεντρώνονται στα παιχνίδια;
Αυτό το άρθρο θα εξερευνήσει εν συντομία την ιστορία της τεχνητής νοημοσύνης στα βιντεοπαιχνίδια. Στη συνέχεια, θα σας δώσουμε μια γρήγορη επισκόπηση ορισμένων τεχνικών μηχανικής εκμάθησης που μπορούμε να χρησιμοποιήσουμε για να μάθουμε πώς να κερδίζετε παιχνίδια. Στη συνέχεια θα εξετάσουμε μερικές επιτυχημένες εφαρμογές του νευρωνικά δίκτυα για να μάθετε και να μάθετε συγκεκριμένα βιντεοπαιχνίδια.
Σύντομη ιστορία της AI στο Gaming
Προτού εξετάσουμε γιατί τα νευρωνικά δίκτυα έχουν γίνει ο ιδανικός αλγόριθμος για την επίλυση βιντεοπαιχνιδιών, ας δούμε εν συντομία πώς οι επιστήμονες υπολογιστών έχουν χρησιμοποιήσει βιντεοπαιχνίδια για να προωθήσουν την έρευνά τους στην τεχνητή νοημοσύνη.
Μπορείτε να υποστηρίξετε ότι, από την έναρξή τους, τα βιντεοπαιχνίδια ήταν ένας καυτός τομέας έρευνας για ερευνητές που ενδιαφέρονται για την τεχνητή νοημοσύνη.
Αν και δεν είναι αυστηρά ένα βιντεοπαιχνίδι στην καταγωγή, το σκάκι ήταν ένα μεγάλο επίκεντρο στις πρώτες ημέρες της τεχνητής νοημοσύνης. Το 1951, ο Δρ. Dietrich Prinz έγραψε ένα πρόγραμμα σκακιού χρησιμοποιώντας τον ψηφιακό υπολογιστή Ferranti Mark 1. Αυτό ήταν πολύ πίσω στην εποχή που αυτοί οι ογκώδεις υπολογιστές έπρεπε να διαβάζουν προγράμματα από χαρτοταινία.

Το ίδιο το πρόγραμμα δεν ήταν μια πλήρης σκακιστική τεχνητή νοημοσύνη. Λόγω των περιορισμών του υπολογιστή, ο Prinz μπορούσε να δημιουργήσει μόνο ένα πρόγραμμα που έλυνε προβλήματα mate-in-two σκακιού. Κατά μέσο όρο, το πρόγραμμα χρειάστηκε 15-20 λεπτά για να υπολογίσει κάθε πιθανή κίνηση για τους λευκομαύρους παίκτες.
Οι εργασίες για τη βελτίωση του σκακιού και του πούλι Η τεχνητή νοημοσύνη έχει βελτιωθεί σταθερά κατά τη διάρκεια των δεκαετιών. Η πρόοδος έφτασε στο αποκορύφωμά της το 1997 όταν ο Deep Blue της IBM κέρδισε τον Ρώσο γκρανμάστερ Γκάρι Κασπάροφ σε ένα ζευγάρι έξι αγώνων. Στις μέρες μας, οι σκακιστικές μηχανές που μπορείτε να βρείτε στο κινητό σας τηλέφωνο μπορούν να νικήσουν το Deep Blue.
Οι αντίπαλοι της τεχνητής νοημοσύνης άρχισαν να κερδίζουν δημοτικότητα κατά τη χρυσή εποχή των βιντεοπαιχνιδιών arcade. Το Space Invaders του 1978 και το Pac-Man του 1980 είναι μερικοί από τους πρωτοπόρους της βιομηχανίας στη δημιουργία τεχνητής νοημοσύνης που μπορεί να προκαλέσει αρκετά ακόμη και τους πιο βετεράνους παίκτες arcade.
Το Pac-Man, συγκεκριμένα, ήταν ένα δημοφιλές παιχνίδι για να πειραματιστούν οι ερευνητές AI. Διάφορος διαγωνισμούς για την κα Pac-Man έχουν οργανωθεί για να καθορίσουν ποια ομάδα θα μπορούσε να βρει την καλύτερη τεχνητή νοημοσύνη για να κερδίσει το παιχνίδι.
Το παιχνίδι AI και οι ευρετικοί αλγόριθμοι συνέχισαν να εξελίσσονται καθώς προέκυψε η ανάγκη για εξυπνότερους αντιπάλους. Για παράδειγμα, το Combat AI αυξήθηκε σε δημοτικότητα καθώς είδη όπως τα shooters πρώτου προσώπου έγιναν πιο mainstream.
Μηχανική μάθηση στα βιντεοπαιχνίδια
Καθώς οι τεχνικές μηχανικής μάθησης αυξήθηκαν γρήγορα σε δημοτικότητα, διάφορα ερευνητικά έργα προσπάθησαν να χρησιμοποιήσουν αυτές τις νέες τεχνικές για να παίξουν βιντεοπαιχνίδια.
Παιχνίδια όπως το Dota 2, το StarCraft και το Doom μπορούν να λειτουργήσουν ως προβλήματα για αυτά αλγόριθμους μηχανικής μάθησης Για να λύσω. Αλγόριθμοι βαθιάς μάθησης, συγκεκριμένα, μπόρεσαν να επιτύχουν και ακόμη και να ξεπεράσουν τις επιδόσεις σε ανθρώπινο επίπεδο.
Η Περιβάλλον μάθησης Arcade ή ALE έδωσε στους ερευνητές μια διεπαφή για περισσότερα από εκατό παιχνίδια Atari 2600. Η πλατφόρμα ανοιχτού κώδικα επέτρεψε στους ερευνητές να αξιολογήσουν την απόδοση των τεχνικών μηχανικής εκμάθησης στα κλασικά βιντεοπαιχνίδια Atari. Η Google δημοσίευσε ακόμη και τη δική της χαρτί χρησιμοποιώντας επτά παιχνίδια από την ALE

Εν τω μεταξύ, έργα όπως VizDoom έδωσε στους ερευνητές της τεχνητής νοημοσύνης την ευκαιρία να εκπαιδεύσουν αλγόριθμους μηχανικής μάθησης για να παίζουν τρισδιάστατα shooters πρώτου προσώπου.

Πώς λειτουργεί: Μερικές βασικές έννοιες
Νευρωνικά δίκτυα
Οι περισσότερες προσεγγίσεις για την επίλυση βιντεοπαιχνιδιών με μηχανική μάθηση περιλαμβάνουν έναν τύπο αλγορίθμου γνωστό ως νευρωνικό δίκτυο.
Μπορείτε να σκεφτείτε ένα νευρωνικό δίκτυο ως ένα πρόγραμμα που προσπαθεί να μιμηθεί τον τρόπο λειτουργίας ενός εγκεφάλου. Παρόμοια με το πώς ο εγκέφαλός μας αποτελείται από νευρώνες που μεταδίδουν ένα σήμα, ένα νευρικό δίκτυο περιέχει επίσης τεχνητούς νευρώνες.
Αυτοί οι τεχνητοί νευρώνες μεταφέρουν επίσης σήματα μεταξύ τους, με κάθε σήμα να είναι ένας πραγματικός αριθμός. Ένα νευρωνικό δίκτυο περιέχει πολλαπλά στρώματα μεταξύ των επιπέδων εισόδου και εξόδου, που ονομάζεται βαθύ νευρωνικό δίκτυο.
Ενίσχυση μάθησης
Μια άλλη κοινή τεχνική μηχανικής μάθησης που σχετίζεται με την εκμάθηση βιντεοπαιχνιδιών είναι η ιδέα της ενισχυτικής μάθησης.
Αυτή η τεχνική είναι η διαδικασία εκπαίδευσης ενός πράκτορα χρησιμοποιώντας ανταμοιβές ή τιμωρίες. Με αυτήν την προσέγγιση, ο πράκτορας θα πρέπει να είναι σε θέση να βρει μια λύση σε ένα πρόβλημα μέσω δοκιμής και λάθους.
Ας υποθέσουμε ότι θέλουμε ένα AI για να μάθουμε πώς να παίξουμε το παιχνίδι Snake. Ο στόχος του παιχνιδιού είναι απλός: κερδίστε όσο το δυνατόν περισσότερους πόντους καταναλώνοντας αντικείμενα και αποφεύγοντας την αυξανόμενη ουρά σας.
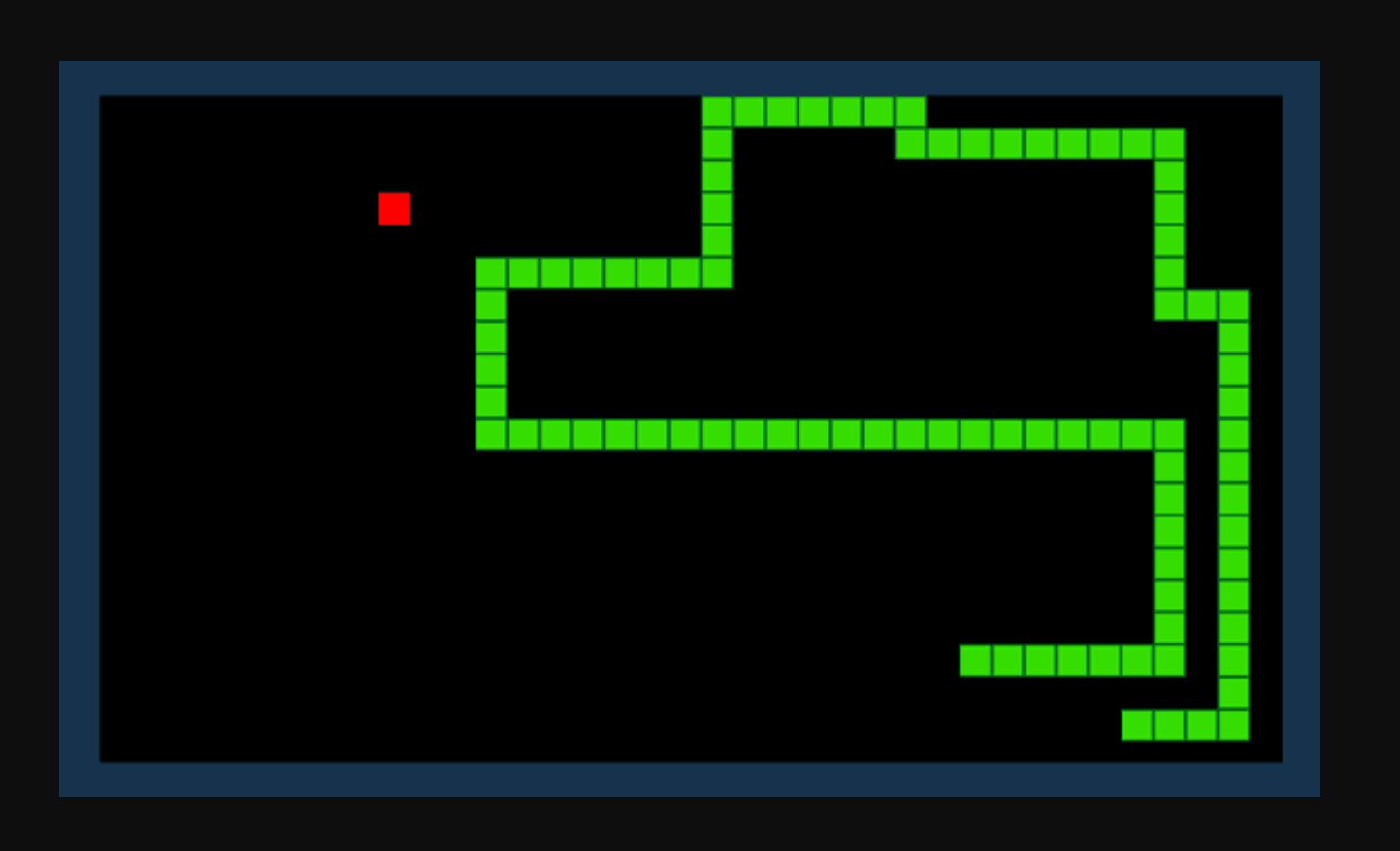
Με την ενίσχυση της εκμάθησης, μπορούμε να ορίσουμε μια συνάρτηση ανταμοιβής R. Η συνάρτηση προσθέτει πόντους όταν ένα φίδι καταναλώνει ένα αντικείμενο και αφαιρεί πόντους όταν το φίδι χτυπήσει ένα εμπόδιο. Δεδομένου του τρέχοντος περιβάλλοντος και ενός συνόλου πιθανών ενεργειών, το ενισχυτικό μας μοντέλο μάθησης θα προσπαθήσει να υπολογίσει τη βέλτιστη «πολιτική» που μεγιστοποιεί τη συνάρτηση ανταμοιβής μας.
Νευροεξέλιξη
Διατηρώντας το θέμα με την έμπνευση από τη φύση, οι ερευνητές βρήκαν επίσης επιτυχία στην εφαρμογή της ML σε βιντεοπαιχνίδια μέσω μιας τεχνικής γνωστής ως νευροεξέλιξης.
Αντί για χρήση κλίση κατάβασης για να ενημερώσουμε τους νευρώνες σε ένα δίκτυο, μπορούμε να χρησιμοποιήσουμε εξελικτικούς αλγόριθμους για να επιτύχουμε καλύτερα αποτελέσματα.
Οι εξελικτικοί αλγόριθμοι συνήθως ξεκινούν δημιουργώντας έναν αρχικό πληθυσμό τυχαίων ατόμων. Στη συνέχεια αξιολογούμε αυτά τα άτομα χρησιμοποιώντας ορισμένα κριτήρια. Τα καλύτερα άτομα επιλέγονται ως «γονείς» και εκτρέφονται μαζί για να σχηματίσουν μια νέα γενιά ατόμων. Αυτά τα άτομα θα αντικαταστήσουν στη συνέχεια τα λιγότερο κατάλληλα άτομα στον πληθυσμό.
Αυτοί οι αλγόριθμοι συνήθως εισάγουν επίσης κάποια μορφή λειτουργίας μετάλλαξης κατά τη διάρκεια του σταδίου διασταύρωσης ή «αναπαραγωγής» για τη διατήρηση της γενετικής ποικιλότητας.
Δείγμα έρευνας για τη μηχανική μάθηση στα βιντεοπαιχνίδια
OpenAI Five

OpenAI Five είναι ένα πρόγραμμα υπολογιστή από την OpenAI που στοχεύει να παίξει το DOTA 2, ένα δημοφιλές παιχνίδι μάχης για πολλούς παίκτες για φορητές συσκευές (MOBA).
Το πρόγραμμα αξιοποίησε υπάρχουσες τεχνικές ενισχυτικής εκμάθησης, κλιμακωμένες ώστε να μαθαίνουν από εκατομμύρια καρέ ανά δευτερόλεπτο. Χάρη σε ένα κατανεμημένο σύστημα εκπαίδευσης, το OpenAI ήταν σε θέση να παίζει παιχνίδια αξίας 180 ετών κάθε μέρα.
Μετά την περίοδο εκπαίδευσης, το OpenAI Five κατάφερε να επιτύχει επιδόσεις σε επίπεδο ειδικών και να επιδείξει συνεργασία με ανθρώπινους παίκτες. Το 2019, το OpenAI five μπόρεσε ήττα Το 99.4% των παικτών σε δημόσιους αγώνες.
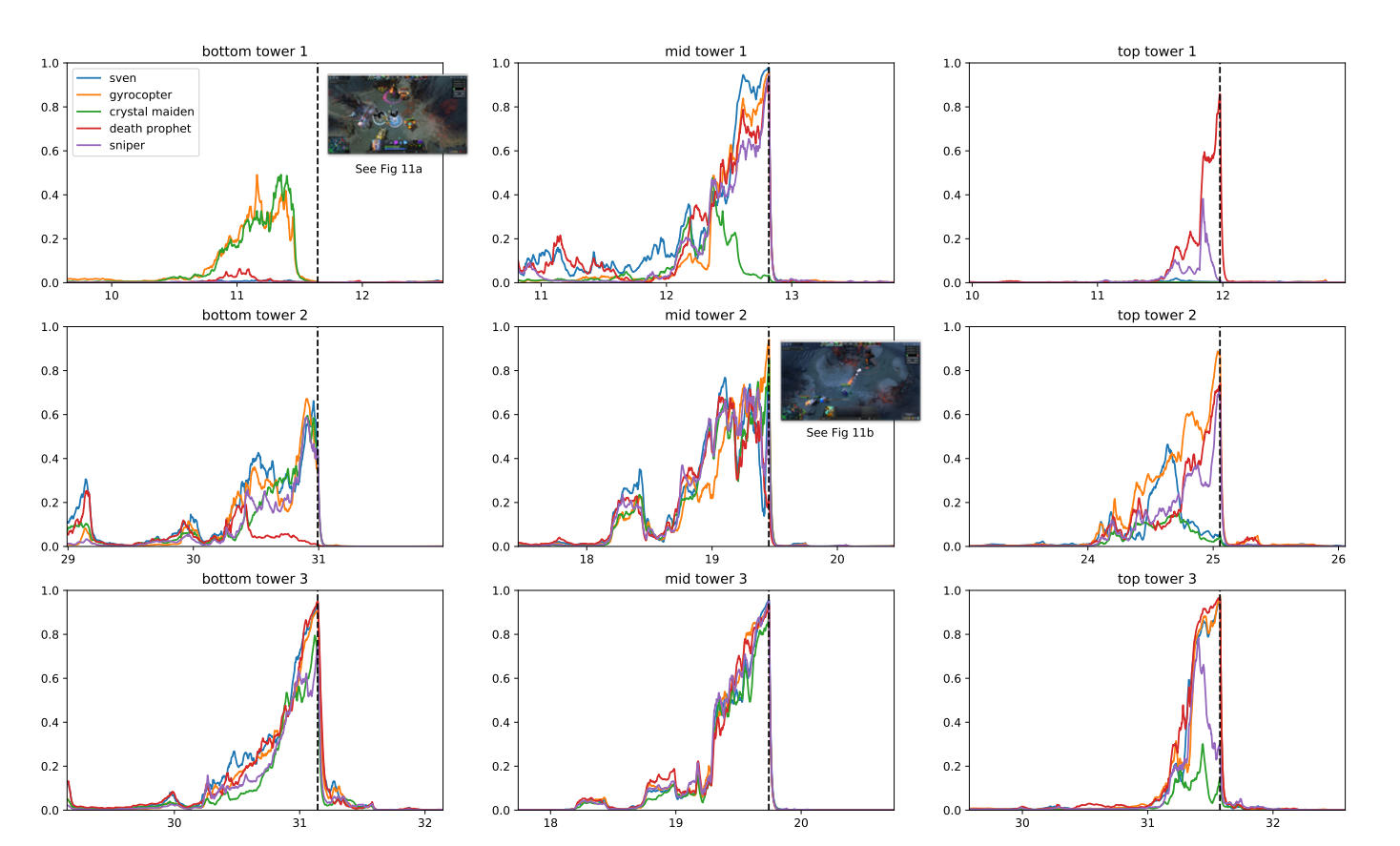
Γιατί το OpenAI αποφάσισε αυτό το παιχνίδι; Σύμφωνα με τους ερευνητές, το DOTA 2 είχε πολύπλοκη μηχανική που ήταν έξω από τα υπάρχοντα βαθιά ενίσχυση μάθησης αλγορίθμους.
Το Super Mario Bros
Μια άλλη ενδιαφέρουσα εφαρμογή των νευρωνικών δικτύων στα βιντεοπαιχνίδια είναι η χρήση του neuroevolution για να παίξετε platformers όπως το Super Mario Bros.
Για παράδειγμα, αυτό είσοδος στο hackathon ξεκινά με την έλλειψη γνώσης του παιχνιδιού και σιγά σιγά χτίζει τα θεμέλια του τι χρειάζεται για να προχωρήσει σε ένα επίπεδο.
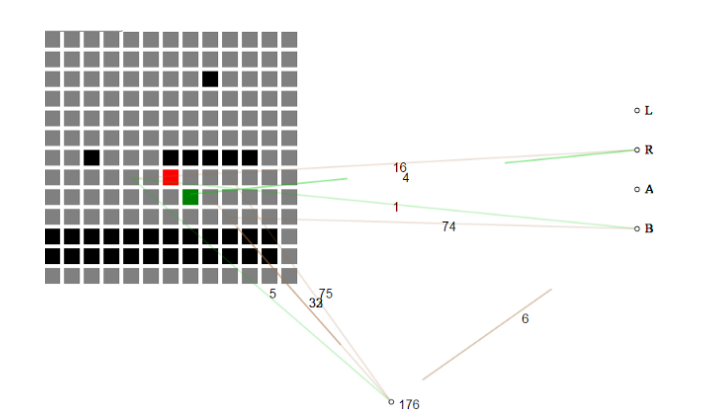
Το αυτό-εξελισσόμενο νευρωνικό δίκτυο παίρνει την τρέχουσα κατάσταση του παιχνιδιού ως ένα πλέγμα από πλακίδια. Αρχικά, το νευρωνικό δίχτυ δεν κατανοεί τι σημαίνει κάθε πλακίδιο, μόνο ότι τα πλακίδια «αέρα» διαφέρουν από τα «πλακίδια εδάφους» και τα «πλακίδια εχθρού».
Η υλοποίηση μιας νευροεξέλιξης από το έργο hackathon χρησιμοποίησε τον γενετικό αλγόριθμο NEAT για να δημιουργήσει διαφορετικά νευρωνικά δίκτυα επιλεκτικά.
Σπουδαιότητα
Τώρα που έχετε δει μερικά παραδείγματα νευρωνικών δικτύων που παίζουν βιντεοπαιχνίδια, ίσως αναρωτιέστε ποιο είναι το νόημα όλων αυτών.
Δεδομένου ότι τα βιντεοπαιχνίδια περιλαμβάνουν περίπλοκες αλληλεπιδράσεις μεταξύ των πρακτόρων και των περιβαλλόντων τους, είναι το τέλειο πεδίο δοκιμών για τη δημιουργία τεχνητής νοημοσύνης. Τα εικονικά περιβάλλοντα είναι ασφαλή και ελεγχόμενα και παρέχουν άπειρη παροχή δεδομένων.
Η έρευνα που έγινε σε αυτόν τον τομέα έδωσε στους ερευνητές πληροφορίες για το πώς τα νευρωνικά δίκτυα μπορούν να βελτιστοποιηθούν για να μάθουν πώς να λύνουν προβλήματα στον πραγματικό κόσμο.
Νευρωνικά δίκτυα εμπνέονται από τον τρόπο λειτουργίας του εγκεφάλου στον φυσικό κόσμο. Μελετώντας πώς συμπεριφέρονται οι τεχνητοί νευρώνες όταν μαθαίνουμε πώς να παίζουμε ένα βιντεοπαιχνίδι, μπορούμε επίσης να αποκτήσουμε μια εικόνα για το πώς ανθρώπινος εγκέφαλος έργα.
Συμπέρασμα
Οι ομοιότητες μεταξύ των νευρωνικών δικτύων και του εγκεφάλου έχουν οδηγήσει σε γνώσεις και στα δύο πεδία. Η συνεχιζόμενη έρευνα για το πώς τα νευρωνικά δίκτυα μπορούν να λύσουν προβλήματα μπορεί κάποια μέρα να οδηγήσει σε πιο προηγμένες μορφές τεχνητή νοημοσύνη.
Φανταστείτε να χρησιμοποιείτε ένα AI προσαρμοσμένο στις προδιαγραφές σας που μπορεί να παίξει ένα ολόκληρο βιντεοπαιχνίδι πριν το αγοράσετε για να σας ενημερώσει εάν αξίζει τον κόπο σας. Θα χρησιμοποιούσαν οι εταιρείες βιντεοπαιχνιδιών νευρωνικά δίχτυα για να βελτιώσουν τον σχεδιασμό του παιχνιδιού, το επίπεδο προσαρμογής και τη δυσκολία του αντιπάλου;
Τι πιστεύετε ότι θα συμβεί όταν τα νευρωνικά δίκτυα γίνουν οι απόλυτοι παίκτες;





Αφήστε μια απάντηση