Inhaltsverzeichnis[Ausblenden][Zeigen]
Große Text-zu-Bild-Modelle machten einen bedeutenden Fortschritt in der Entwicklung der KI, indem sie eine qualitativ hochwertige und diversifizierte Bildsynthese aus einer gegebenen Textaufforderung erzeugten.
Diese Modelle sind nicht in der Lage, eindeutige Darstellungen von Subjekten in verschiedenen Umgebungen zu synthetisieren oder das Erscheinungsbild von Subjekten in einem gegebenen Referenzsatz zu replizieren.
Neu veröffentlichte Technologien wie DALL.E2 von OpenAI oder StabilityAI Stable Diffusion und Midjourney erobern das Internet bereits im Sturm. Jetzt ist es an der Zeit, die Ergebnisse anzupassen. Doch wie?
Google DreamBooth AI ist da.
DreamBooth hat die Fähigkeit, das Thema eines Bildes zu erkennen, es aus seinem ursprünglichen Kontext zu dekonstruieren und es dann präzise in einen neuen gewünschten Kontext zu synthetisieren. Darüber hinaus kann es mit aktuellen KI-Bildgeneratoren verwendet werden.
In diesem Artikel werfen wir einen tiefen Blick auf DreamBooth, seine Verwendung, sein Tutorial, seine Einschränkungen und vieles mehr.
Was ist Dreambooth?
Traumkabine, ein brandneues Text-to-Image-Diffusionsmodell, wurde von Google vorgestellt. Eine schriftliche Aufforderung kann von Google DreamBooth AI als Anleitung verwendet werden, um eine Vielzahl von Fotos des vom Benutzer ausgewählten Motivs in verschiedenen Einstellungen zu erstellen.
Eine Forschungsgruppe der Boston University und Google hat DreamBooth entwickelt, eine hochmoderne Technik zur Änderung von Text-zu-Bild-Modellen, die umfassend vortrainiert wurden.
Das Gesamtkonzept ist ziemlich einfach: Sie möchten das Sprach-Vision-Wörterbuch so erweitern, dass ungewöhnliche Token-IDs mit benutzerdefinierten Themen verknüpft werden, die Benutzer definieren können.
Das Hauptziel des Modells ist es, Benutzer mit dem zu verbinden Text-zu-Bild-Diffusionsmodell indem sie ihnen die Ressourcen zur Verfügung stellen, die sie benötigen, um fotorealistische Darstellungen der Instanzen ihres ausgewählten Themas zu erstellen.
Folglich scheint diese Technik gut zu funktionieren, um Herausforderungen in einer Reihe von Situationen zusammenzufassen.
Googles DreamBooth unterscheidet sich von früheren Text-zu-Bild-Tools, wie z DALL-E2, Stable Diffusion und Zwischendurch, indem es Benutzern mehr Kontrolle über das Themenbild gibt, bevor sie das Diffusionsmodell mit textbasierten Eingaben manipulieren können.
Eigenschaften
- DreamBooth AI könnte ein Text-zu-Bild-Modell mit 3-5 Bildern verbessern.
- Originale fotorealistische Fotos können mit DreamBooth AI erstellt werden.
- Darüber hinaus kann die DreamBooth-KI Fotos eines Themas aus mehreren Blickwinkeln erstellen.
Anwendung
Kunstwiedergaben
Diese Aufgabe unterscheidet sich speziell von der Stilübertragung, bei der die Semantik der Quellszene beibehalten wird, während der Stil eines anderen Bildes in die Originalszene integriert wird.

Basierend auf dem kreativen Ansatz kann die KI signifikante Szenenänderungen durchführen, während die Identifizierung und die Besonderheiten der Themeninstanz beibehalten werden.
Eigenschaftsänderung
Die Eigenschaften der betroffenen Instanz können von DreamBooth AI geändert werden.

Ausstattung
Die starke Komposition vor dem Generierungsmodell macht die Fähigkeit von DreamBooth AI, Objekte zu verschönern, so interessant.

Rekontextualisierung
DreamBooth AI kann unverwechselbare Bilder für eine bestimmte Subjektinstanz erzeugen, indem sie einem trainierten Modell einen Satz gibt, der die eindeutige Kennung und das Klassennomen enthält.

Es kann das Motiv in einzigartigen, bisher unerhörten Haltungen, Artikulationen und Szenenstrukturen erzeugen, anstatt die Umgebung zu verändern. Realistische Reflexionen und Schatten sowie Wechselwirkungen zwischen dem Motiv und umgebenden Objekten.
Dreambooth-Tutorial
In diesem Tutorial folgen wir dem Google Collab-Notizbuch, und ich werde Sie durchgehen, damit Sie es verstehen und selbst verwenden können.
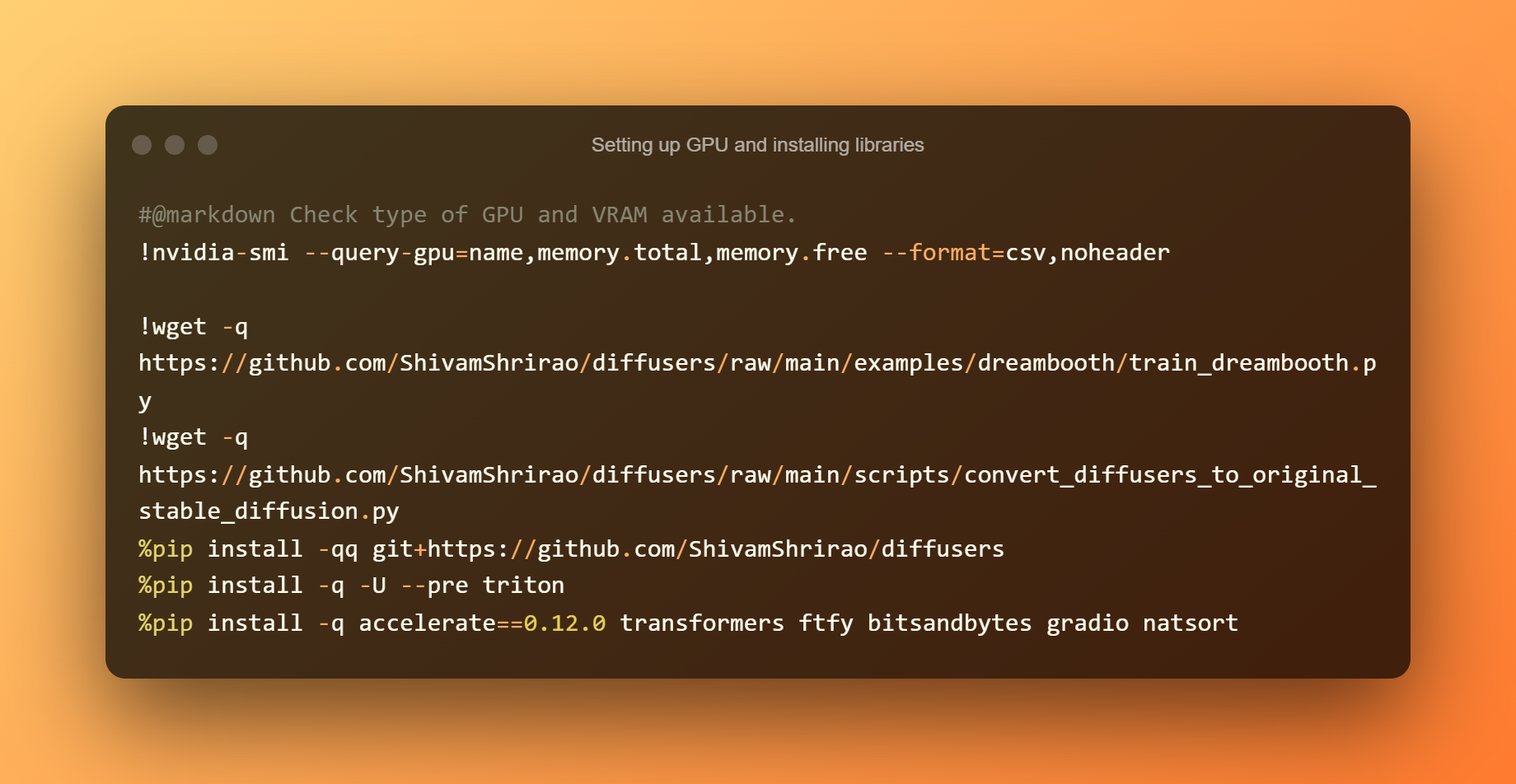
GPU einrichten und Bibliotheken installieren
Herauszufinden, welche GPU- und VRAM-Arten verfügbar sind, ist der erste Schritt. Die Installation einiger Anforderungen und Abhängigkeiten ist ebenfalls erforderlich. Drücken Sie einfach die Play-Taste und warten Sie, bis es beendet ist.
Erstellen Sie ein Konto auf Huggingface und generieren Sie ein Token
Der nächste Schritt ist die Registrierung für ein Huggingface-Konto. Wenn Sie fertig sind, klicken Sie oben rechts auf Einstellungen. Sie gelangen auf die nächste Seite.
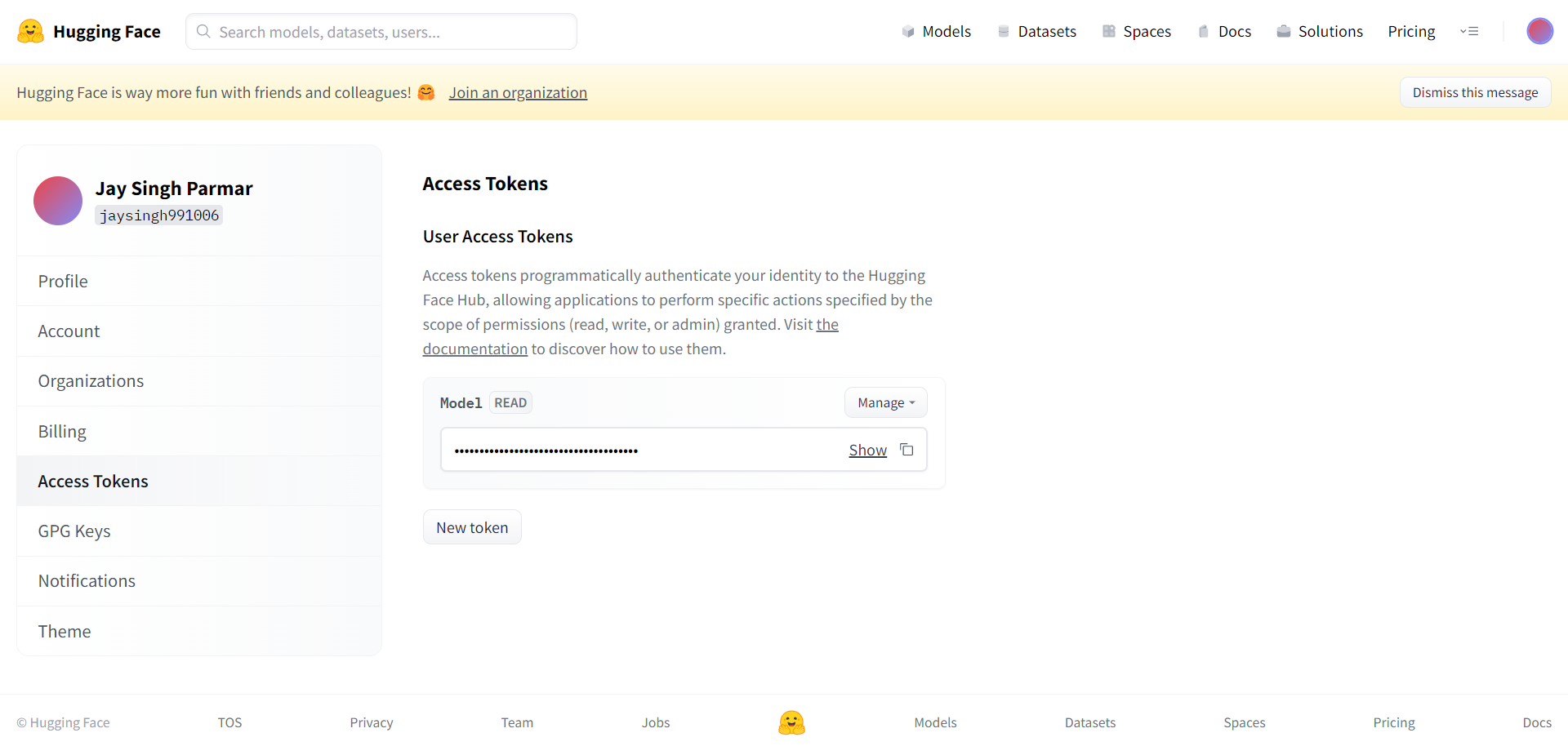
Erstellen Sie das Token und den Namen wie von hier aus angefordert. Das Token sollte kopiert und in die Google-Zusammenarbeit in der Zelle darunter eingefügt werden.

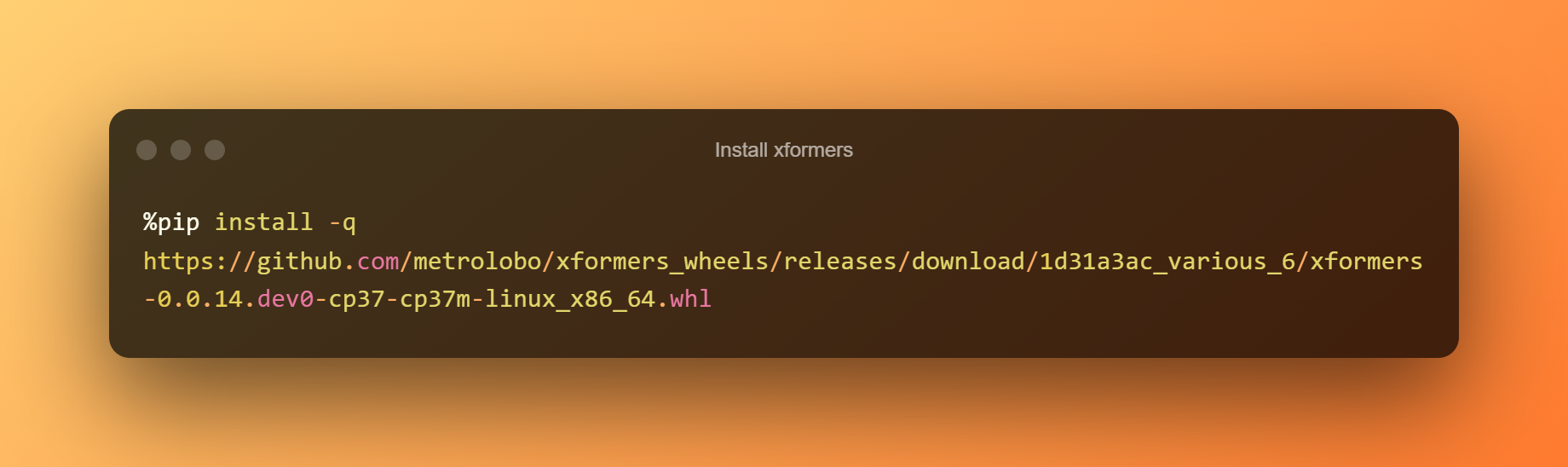
xformers installieren
In dieser Phase können Sie einfach die Wiedergabetaste drücken, um xformers zu installieren, indem Sie auf die Laufzeit klicken.
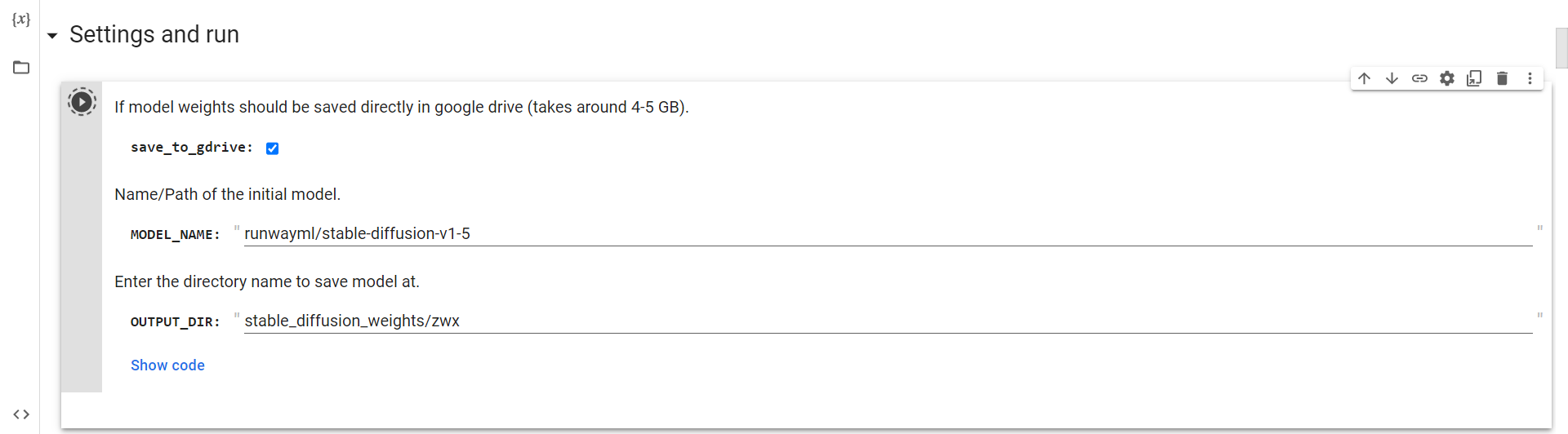
Mit Drive verbinden
Jetzt müssen Sie nur noch diese Zelle ausführen, um eine Verbindung zu Google Drive herzustellen.
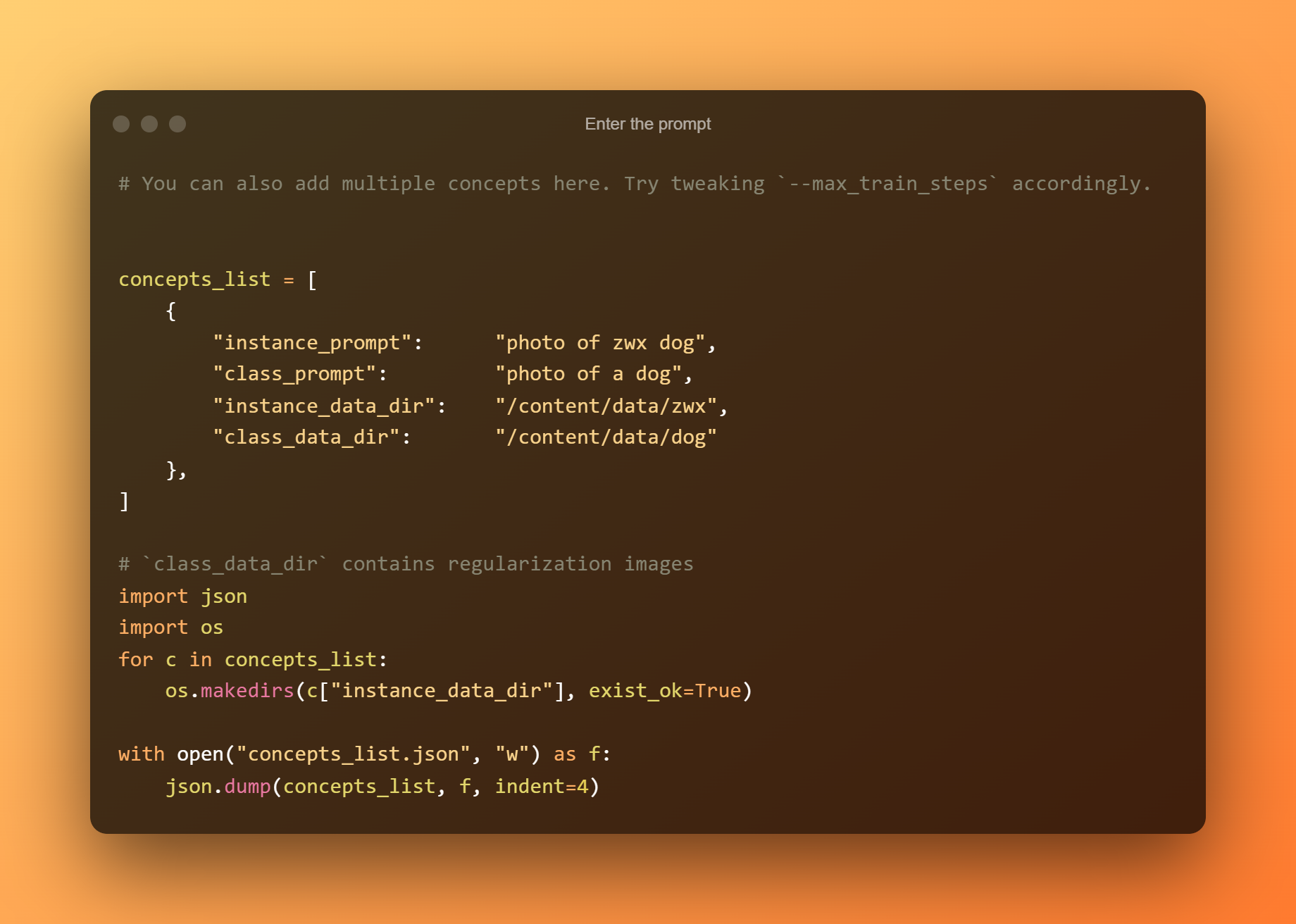
Geben Sie die Eingabeaufforderung ein
In der folgenden Zelle müssen Sie nur die Eingabeaufforderung eingeben.
Bilder hochladen
In diesem Schritt müssen Sie nur die Bilder hochladen, die Sie trainieren möchten.

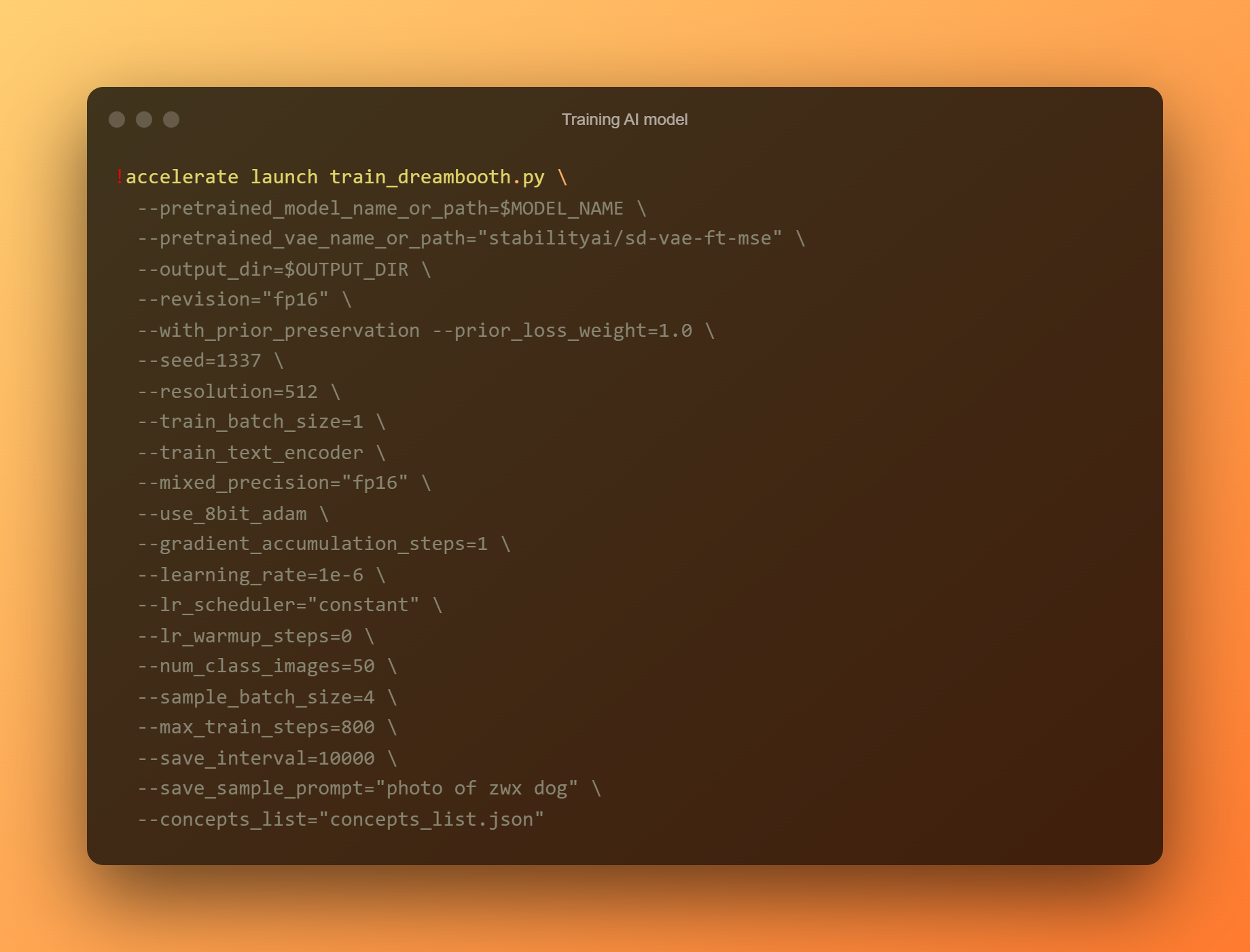
KI-Modell trainieren
Dies ist die wichtigste Phase, da Sie DreamBooth verwenden werden, um ein neues KI-Modell basierend auf all Ihren eingereichten Referenzfotos zu trainieren. Sie müssen sich auf zwei Eingabefelder beschränken. „—instance prompt“ ist der erste Parameter. Hier müssen Sie einen eindeutigen Namen angeben.
Das Argument '–concept list' ist das zweite kritische Eingabefeld. Sie muss umbenannt werden, damit sie mit der im Abschnitt „Ändern der Eingabeaufforderung“ verwendeten übereinstimmt.
Generieren Sie KI-Bilder
Die AI-Bilder werden in diesem Stadium erstellt, wo Sie die Textanweisungen eingeben können.

Dreambooth-Einschränkungen
- Die Eingabeaufforderung wird zu einem Hindernis für Iterationen im Thema mit hohem Detaillierungsgrad. DreamBooth kann den Kontext des Motivs ändern, aber wenn das Modell das Motiv selbst ändern möchte, gibt es Probleme mit dem Rahmen.
- Ein weiteres Problem ist die Überanpassung des Ausgabebildes an das Eingabebild. Wenn nicht genügend Bilder geliefert werden, wird das Thema möglicherweise nicht berücksichtigt oder mit dem Kontext der eingereichten Bilder vermischt. Wenn nach einem Kontext für eine ungerade Generation gefragt wird, geschieht dasselbe.
Zusammenfassung
Um Ausgaben aus einer einzigen Texteingabe zu erzeugen, benötigen die meisten Text-zu-Bild-Modelle Millionen von Parametern und Bibliotheken.
DreamBooth vereinfacht den Erwerb und die Nutzung von Inhalten für Verbraucher, indem lediglich die Eingabe von drei bis fünf thematischen Fotos zusammen mit einem Texthintergrund erforderlich ist.





Hinterlassen Sie uns einen Kommentar