Diffusionsmodelle haben mit der Veröffentlichung von den Globus im Sturm erobert Ab E2, Googles Bilder, Stable Diffusion und Zwischendurch, Innovationen anregen und die Grenzen des maschinellen Lernens erweitern.
Diese Modelle können aus Worteingabeaufforderungen eine nahezu unbegrenzte Anzahl von Bildern erstellen, einschließlich fotorealistischer, magischer, futuristischer und natürlich niedlicher Bilder.
Diese Fähigkeiten stellen neu dar, was es für Menschen bedeutet, mit Silizium zu interagieren, und geben uns die Möglichkeit, praktisch jedes Bild zu machen, das wir uns vorstellen können.
Wenn sich diese Modelle weiterentwickeln oder das nächste generative Paradigma übernimmt, werden Menschen in der Lage sein, Bilder, Filme und andere immersive Erfahrungen mit nur einem Gedanken zu produzieren.
In diesem Beitrag werden wir die diskutieren Diffusionsmodell, stabile Diffusion, wie es funktioniert und ein Tutorial zum Malen von Diffusionsmodellen, unter anderem.
Was ist das Diffusionsmodell?
Machine-Learning-Modelle, die aus Trainingsdaten neue Daten erstellen können, werden als generative Modelle bezeichnet. Andere generative Modelle umfassen flussbasierte Modelle, Variations-Autoencoder und Generative Adversarial Networks (GANs).
Jeder kann Bilder von ausgezeichneter Qualität erzeugen. Diffusionsmodelle lernen, die Daten wiederherzustellen, indem sie diesen Prozess des Hinzufügens von Rauschen umkehren, nachdem sie die Trainingsdaten durch Hinzufügen von Rauschen beschädigt haben. Anders ausgedrückt: Diffusionsmodelle sind in der Lage, aus dem Rauschen zusammenhängende Bilder zu erzeugen.
Diffusionsmodelle lernen, indem sie Rauschen in Bilder einbringen, dessen Entfernung das Modell später beherrscht. Um realistische Bilder zu erzeugen, wendet das Modell diese Denoising-Technik dann auf zufällige Seeds an.
Durch die Konditionierung des Bildproduktionsprozesses können diese Modelle in Verbindung mit einer Text-zu-Bild-Anleitung verwendet werden, um eine nahezu unbegrenzte Anzahl von Bildern allein aus Text zu generieren. Die Seeds können durch Eingaben von Einbettungen wie CLIP gelenkt werden, um starke Text-zu-Bild-Fähigkeiten zu bieten.
Diffusionsmodelle können eine Vielzahl von Aufgaben ausführen, einschließlich Bilderzeugung, Bildentrauschung, Inpainting, Outpainting und Bitdiffusion.
Was ist nun stabile Diffusion?
Stable Diffusion ist ein maschinelles Lernmodell für die textbasierte Bilderstellung, bereitgestellt von Stabilität.KI. Es ist in der Lage, Bilder aus Text zu generieren.
Komponenten der stabilen Diffusion
Stable Diffusion ist ein System, das aus mehreren Komponenten und Konzepten besteht. Es ist kein einzelnes Modell. Wenn wir hinter die Haube schauen, sehen wir als Erstes, dass es eine Textverständniskomponente gibt, die Textinformationen in eine numerische Darstellung umwandelt, die die Konzepte des Textes erfasst.
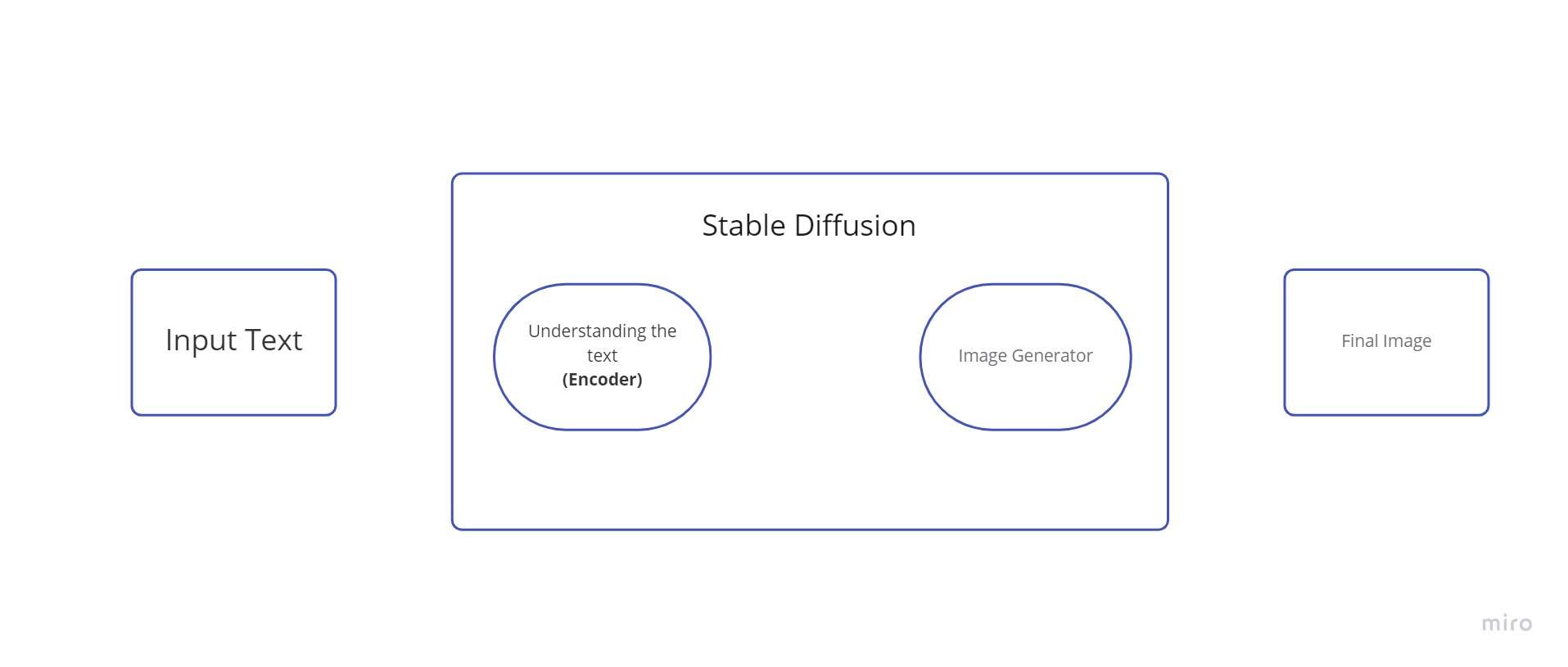
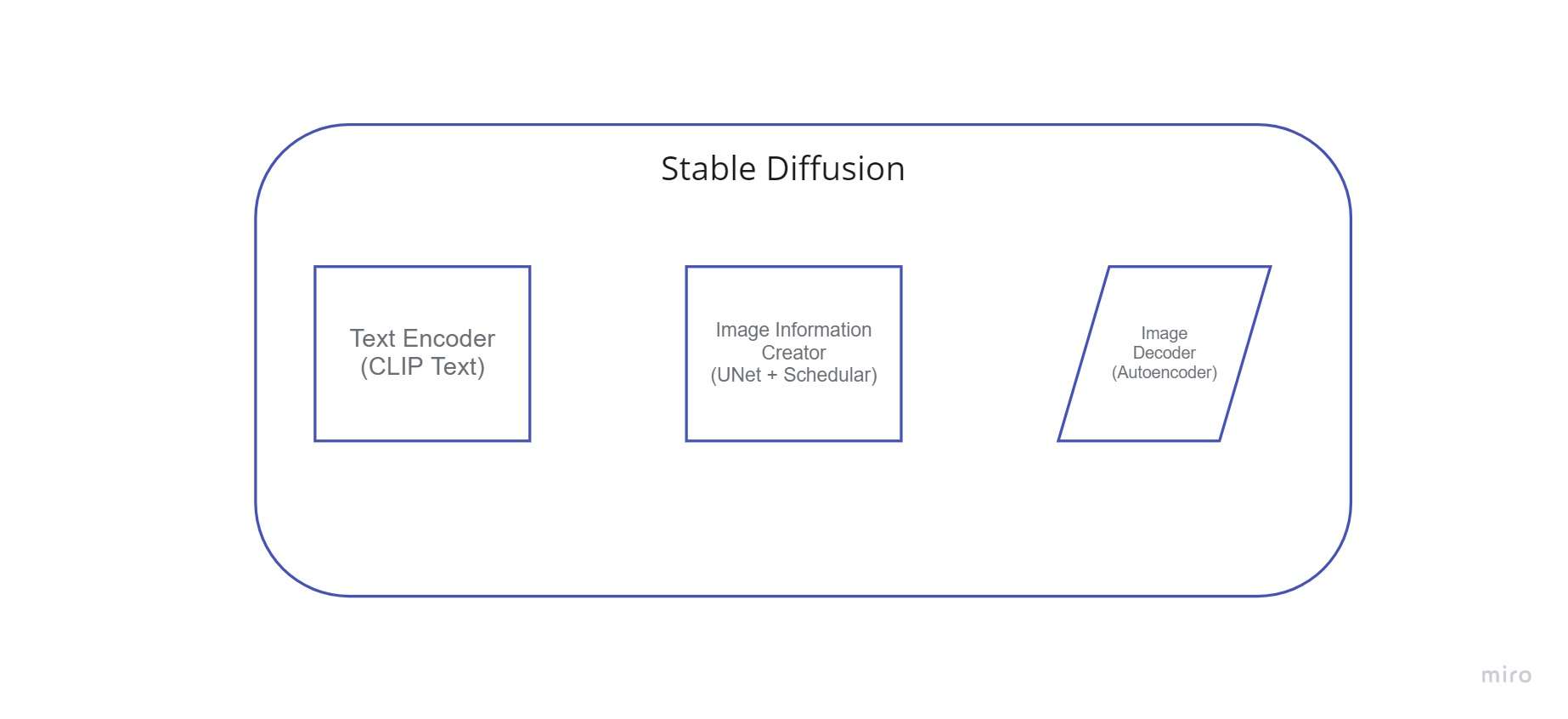
Wir können diesen Text-Encoder als Transformer bezeichnen Sprachmodell (technisch: der Text-Encoder eines CLIP-Modells). Es nimmt den Eingabetext und generiert eine Liste von ganzen Zahlen (einen Vektor) für jedes Wort/Token im Text. Diese Daten werden dann dem Bildgenerator zugeführt, der aus mehreren Komponenten besteht.
Es gibt zwei Schritte im Bildgenerator:
1. Ersteller von Bildinformationen
Die Hauptkomponente in Stable Diffusion ist dieses Element. Hier wird der Großteil der Leistungsverbesserung gegenüber früheren Versionen vorgenommen.
Diese Komponente durchläuft mehrere Stufen, um Bilddaten bereitzustellen. Der Erzeuger von Bildinformationen arbeitet nur innerhalb des Bildinformationsraums (oder latenten Raums).
Aufgrund dieser Eigenschaft ist es schneller als frühere Diffusionsmodelle, die im Pixelraum arbeiteten. Technisch gesehen besteht diese Komponente aus einem Scheduling-Algorithmus und einem UNet neuronale Netzwerk.
Der in diesem Bauteil ablaufende Prozess wird als „Diffusion“ bezeichnet. Durch die schrittweise Verarbeitung der Informationen (durch die nächste Komponente, den Bilddecoder) entsteht schließlich ein hochwertiges Bild.
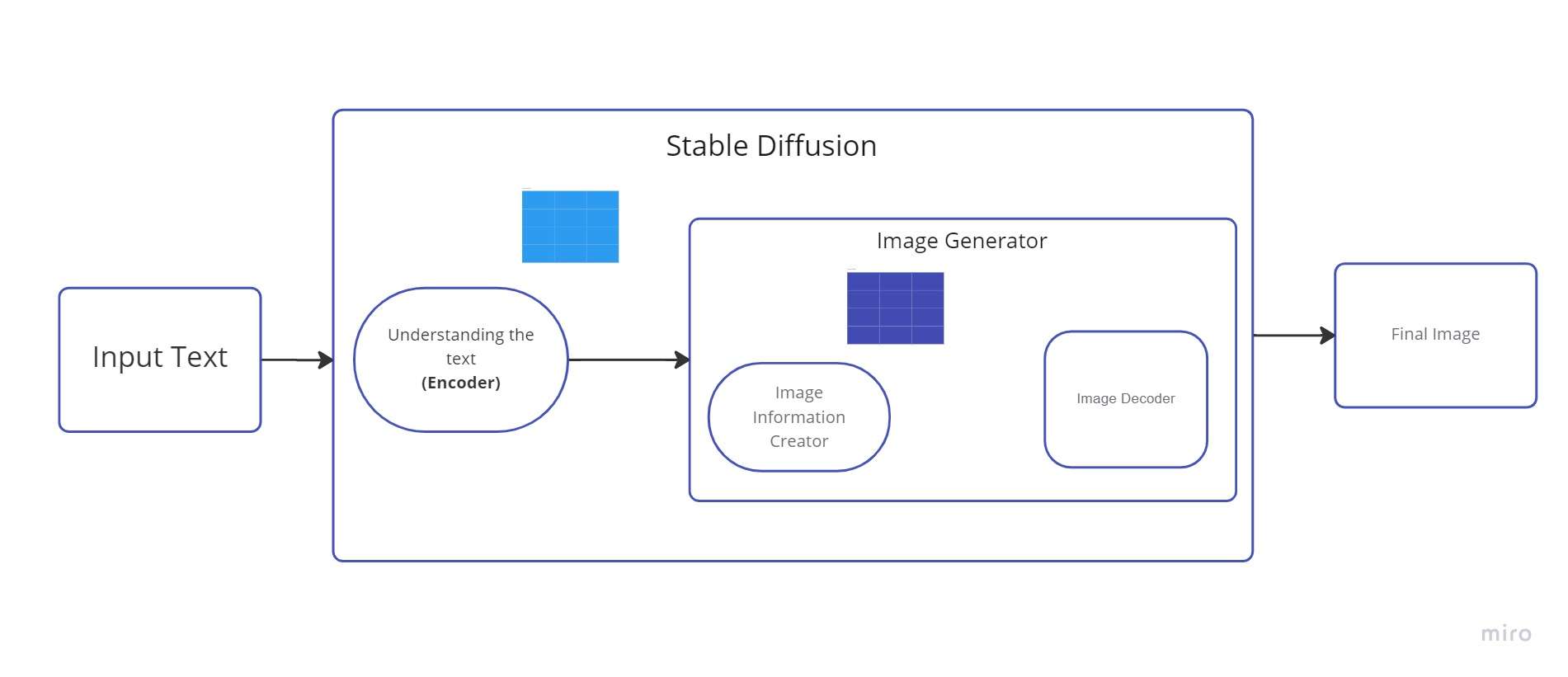
2. Bilddecoder
Unter Verwendung der Daten, die er vom Informationsproduzenten erhält, erstellt der Bilddecodierer ein Bild. Es wird nur einmal ausgeführt, um am Ende der Operation das fertige Pixelbild zu erzeugen.
Stable Diffusion Impainting-Tutorial
Stable Diffusion Picture Inpainting ist die Technik zum Auffüllen fehlender oder beschädigter Bereiche eines Bildes. Der Zweck der Bildübermalung besteht darin, die Tatsache zu verbergen, dass das Bild restauriert wurde.
Diese Technik wird häufig verwendet, um unerwünschte Dinge aus einem Bild zu entfernen oder beschädigte Bereiche historischer Fotografien wiederherzustellen. Stable Diffusion Inpainting ist eine relativ neue Art des Inpaintings, die vielversprechende Effekte erzielt.
Wenn Sie das Inpainting mit stabiler Diffusion ausprobieren möchten, befolgen Sie die nachstehenden Anweisungen, um mit dem Erkunden des Inpaintings und der Änderung vorhandener Fotos zu beginnen:
- Gehe zu Huggingface Stabile Diffusionsimpainting
- Laden Sie Ihr eigenes Bild hoch
- Löschen Sie den Teil Ihres Bildes, der ersetzt werden muss.
- Geben Sie hier Ihre Eingabeaufforderung ein (was Sie anstelle dessen, was Sie entfernen möchten, hinzufügen möchten)
- Wählen Sie „Ausführen“
Im Video oben laden wir ein Bild mit drei Zitronen hoch und tauschen sie gegen Äpfel aus. Ich persönlich empfehle, es mit Ihren eigenen Fotos und Eingabeaufforderungen auszuprobieren.
Zusammenfassung
Im Allgemeinen ist Steady Diffusion Inpainting eine hervorragende Methode, um gefälschte Bilder oder Videos zu erstellen, die extrem echt erscheinen. Während wir uns in Richtung neuer technischer Fortschritte bewegen, wird es mit fortschreitender Technologie immer schwieriger, zwischen authentisch und betrügerisch zu unterscheiden.





Die erste Hälfte hat überhaupt keinen Bezug zur zweiten Hälfte. Es wäre wirklich cool gewesen, wenn der Autor erklärt hätte, wie Inpaint im Rahmen des zuvor erläuterten Modells funktioniert, und hätte Einblicke geben können. Aber nein! Das hätte ein echtes Verständnis erfordert, statt einen zufälligen Text zu sammeln und zu verarbeiten.