Inhaltsverzeichnis[Ausblenden][Zeigen]
Die Zukunft ist hier. Und in dieser Zukunft verstehen Maschinen die Welt um sie herum genauso wie Menschen. Computer können Autos fahren, Krankheiten diagnostizieren und die Zukunft genau vorhersagen.
Das mag wie Science-Fiction erscheinen, aber Deep-Learning-Modelle lassen es Wirklichkeit werden.
Diese ausgeklügelten Algorithmen enthüllen die Geheimnisse von künstliche Intelligenz, die es Computern ermöglicht, selbst zu lernen und sich zu entwickeln. In diesem Beitrag tauchen wir in das Reich der Deep-Learning-Modelle ein.
Und wir werden das enorme Potenzial untersuchen, das sie haben, um unser Leben zu revolutionieren. Bereiten Sie sich darauf vor, mehr über Spitzentechnologie zu erfahren, die die Zukunft der Menschheit verändert.

Was genau sind Deep-Learning-Modelle?
Haben Sie schon einmal ein Spiel gespielt, bei dem Sie die Unterschiede zwischen zwei Bildern erkennen müssen?
Es macht Spaß, aber es kann auch hart sein, oder? Stellen Sie sich vor, Sie könnten einem Computer beibringen, dieses Spiel zu spielen und jedes Mal zu gewinnen. Deep-Learning-Modelle leisten genau das!
Deep-Learning-Modelle ähneln superintelligenten Maschinen, die eine große Anzahl von Bildern untersuchen und feststellen können, was sie gemeinsam haben. Sie erreichen dies, indem sie die Bilder zerlegen und jedes einzeln untersuchen.
Anschließend wenden sie das Gelernte an, um Muster zu erkennen und Vorhersagen über neue Bilder zu treffen, die sie noch nie zuvor gesehen haben.

Deep-Learning-Modelle sind künstliche neuronale Netze, die komplizierte Muster und Merkmale aus riesigen Datensätzen lernen und extrahieren können. Diese Modelle bestehen aus mehreren Schichten verknüpfter Knoten oder Neuronen, die eingehende Daten analysieren und ändern, um eine Ausgabe zu generieren.
Deep-Learning-Modelle eignen sich besonders gut für Aufgaben, die große Genauigkeit und Präzision erfordern, wie Bildidentifikation, Spracherkennung, Verarbeitung natürlicher Sprache und Robotik.
Sie wurden in allen Bereichen eingesetzt, von selbstfahrenden Autos bis hin zu medizinischen Diagnosen, Empfehlungssystemen und mehr Predictive analytics.
Hier ist eine vereinfachte Version der Visualisierung, um den Datenfluss in einem Deep-Learning-Modell zu veranschaulichen.
Die Eingabedaten fließen in die Eingabeschicht des Modells, die die Daten dann durch eine Reihe verborgener Schichten leitet, bevor sie eine Ausgabevorhersage liefert.
Jede verborgene Schicht führt eine Reihe mathematischer Operationen an den Eingabedaten durch, bevor sie an die nächste Schicht weitergegeben werden, die die endgültige Vorhersage liefert.
Sehen wir uns nun an, was Deep-Learning-Modelle sind und wie wir sie in unserem Leben einsetzen können.
1. Faltungs-Neuronale Netze (CNNs)
CNNs sind ein Deep-Learning-Modell, das den Bereich des Computersehens verändert hat. CNNs werden verwendet, um Bilder zu klassifizieren, Objekte zu erkennen und Bilder zu segmentieren. Die Struktur und Funktion des menschlichen visuellen Kortex beeinflussten das Design von CNNs.
Wie arbeiten sie?
Ein CNN besteht aus einer Reihe von Convolutional Layers, Pooling Layers und Fully Linked Layers. Die Eingabe ist ein Bild, und die Ausgabe ist eine Vorhersage der Klassenbezeichnung des Bildes.
Die Faltungsschichten eines CNN erstellen eine Merkmalskarte, indem sie ein Skalarprodukt zwischen dem Eingabebild und einem Satz von Filtern erstellen. Die Pooling-Layer reduzieren die Größe der Feature-Map durch Downsampling.
Schließlich wird die Merkmalskarte von den vollständig verbundenen Schichten verwendet, um die Klassenbezeichnung des Bildes vorherzusagen.

Warum sind CNNs wichtig?
CNNs sind unerlässlich, weil sie lernen können, Muster und Merkmale in Bildern zu erkennen, die für Menschen schwer zu erkennen sind. CNNs kann beigebracht werden, Merkmale wie Kanten, Ecken und Texturen anhand großer Datensätze zu erkennen. Nach dem Erlernen dieser Eigenschaften kann ein CNN sie verwenden, um Objekte auf frischen Fotos zu identifizieren. CNNs haben bei einer Vielzahl von Bildidentifikationsanwendungen Spitzenleistung gezeigt.
Wo verwenden wir CNNs?
Das Gesundheitswesen, die Autoindustrie und der Einzelhandel sind nur einige Branchen, die CNNs einsetzen. In der Gesundheitsbranche können sie für die Krankheitsdiagnose, Medikamentenentwicklung und medizinische Bildanalyse von Nutzen sein.
Im Automobilbereich helfen sie bei der Spurerkennung, Objekterkennung, und autonomes Fahren. Sie werden auch im Einzelhandel häufig für die visuelle Suche, bildbasierte Produktempfehlung und Bestandskontrolle eingesetzt.
Zum Beispiel; Google setzt CNNs in einer Vielzahl von Anwendungen ein, darunter Google Objektiv, ein beliebtes Tool zur Bildidentifizierung. Das Programm nutzt CNNs, um Fotos auszuwerten und Nutzern Informationen zu geben.
Google Lens zum Beispiel kann Dinge in einem Bild erkennen und Details darüber anbieten, wie zum Beispiel die Art der Blume.

Es kann auch den aus einem Bild extrahierten Text in mehrere Sprachen übersetzen. Google Lens ist in der Lage, Verbrauchern nützliche Informationen zu liefern, da CNNs dabei hilft, Artikel genau zu identifizieren und Merkmale aus Fotos zu extrahieren.
2. Long Short-Term Memory (LSTM)-Netzwerke
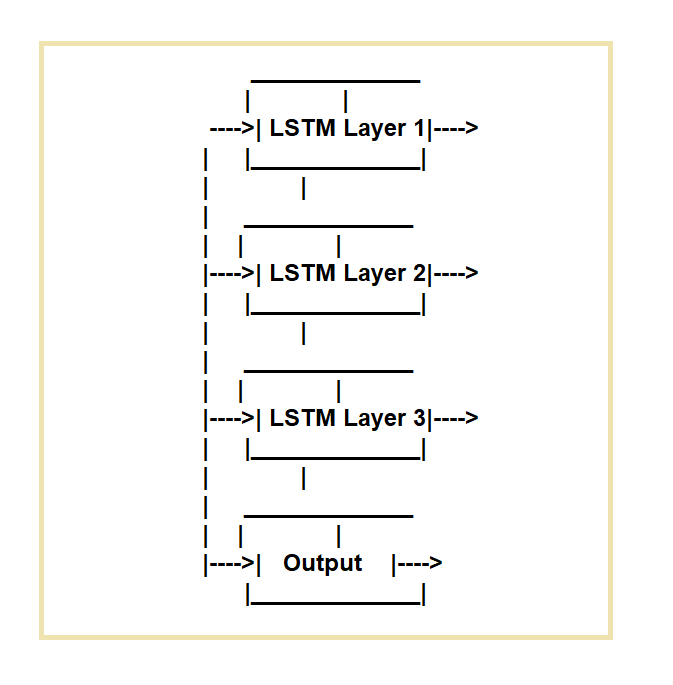
Netzwerke mit langem Kurzzeitgedächtnis (LSTM) werden erstellt, um die Mängel regelmäßig wiederkehrender neuronaler Netzwerke (RNNs) zu beheben. LSTM-Netzwerke sind ideal für Aufgaben, die die Verarbeitung von Datensequenzen über die Zeit erfordern.
Sie funktionieren, indem sie eine spezifische Speicherzelle und drei Gating-Mechanismen verwenden.
Sie regulieren den Informationsfluss in und aus der Zelle. Das Eingangstor, das Vergessenstor und das Ausgangstor sind die drei Tore.
Das Eingangsgatter regelt den Datenfluss in die Speicherzelle, das Vergessensgatter regelt das Löschen von Daten aus der Zelle und das Ausgangsgatter regelt den Datenfluss aus der Zelle heraus.
Was ist ihre Bedeutung?
LSTM-Netzwerke sind nützlich, da sie Datensequenzen mit langfristigen Beziehungen erfolgreich darstellen und prognostizieren können. Sie können Informationen über frühere Eingaben aufzeichnen und aufbewahren, wodurch sie genauere Vorhersagen über zukünftige Eingaben treffen können.
Spracherkennung, Handschrifterkennung, Verarbeitung natürlicher Sprache und Bildbeschriftung sind nur einige der Anwendungen, die von LSTM-Netzwerken Gebrauch gemacht haben.
Wo verwenden wir LSTM-Netzwerke?
Viele Software- und Technologieanwendungen verwenden LSTM-Netzwerke, einschließlich Spracherkennungssysteme, Tools zur Verarbeitung natürlicher Sprachen wie z Sentiment-Analyse, Maschinenübersetzungssysteme und Text- und Bilderzeugungssysteme.
Sie wurden auch bei der Entwicklung von selbstfahrenden Autos und Robotern sowie in der Finanzbranche eingesetzt, um Betrug aufzudecken und zu antizipieren Börse Bewegungen.
3. Generative Adversarial Networks (GANs)
GANs sind a tiefe Lernen Technik, die verwendet wird, um neue Datenbeispiele zu generieren, die einem bestimmten Datensatz ähneln. GANs bestehen aus zwei Neuronale Netze: Einer, der lernt, neue Muster zu produzieren, und einer, der lernt, zwischen echten und erzeugten Mustern zu unterscheiden.
In einem ähnlichen Ansatz werden diese beiden Netzwerke zusammen trainiert, bis der Generator Samples erzeugen kann, die von tatsächlichen nicht zu unterscheiden sind.
Warum verwenden wir GANs
GANs sind wegen ihrer Fähigkeit, qualitativ hochwertige Produkte zu produzieren, von Bedeutung synthetische Daten die für eine Vielzahl von Anwendungen verwendet werden können, einschließlich Bild- und Videoproduktion, Textgenerierung und sogar Musikgenerierung.
GANs wurden auch für die Datenerweiterung verwendet, die die Generierung von ist synthetische Daten um reale Daten zu ergänzen und die Leistung von Modellen für maschinelles Lernen zu verbessern.
Darüber hinaus haben GANs durch die Erstellung synthetischer Daten, die zum Trainieren von Modellen und Nachahmen von Studien verwendet werden können, das Potenzial, Sektoren wie Medizin und Arzneimittelentwicklung zu verändern.

Anwendungen von GANs
GANs können Datensätze ergänzen, neue Bilder oder Filme erstellen und sogar synthetische Daten für wissenschaftliche Simulationen generieren. Darüber hinaus haben GANs das Potenzial, in einer Vielzahl von Anwendungen eingesetzt zu werden, die von der Unterhaltung bis zur Medizin reichen.
Alter und Videos. NVIDIAs StyleGAN2 wurde beispielsweise verwendet, um hochwertige Fotos von Prominenten und Kunstwerken zu erstellen.
4. Deep Belief Networks (DBNs)
Deep Belief Networks (DBNs) sind künstliche Intelligenz Systeme, die lernen können, Muster in Daten zu erkennen. Sie erreichen dies, indem sie die Daten in immer kleinere Blöcke segmentieren und sie auf jeder Ebene gründlicher verstehen.
DBNs können aus Daten lernen, ohne darüber informiert zu werden (dies wird als „unüberwachtes Lernen“ bezeichnet). Dies macht sie äußerst wertvoll für die Erkennung von Mustern in Daten, die eine Person nur schwer oder gar nicht erkennen kann.
Was macht DBNs bedeutsam?
DBNs sind wegen ihrer Fähigkeit, hierarchische Datendarstellungen zu lernen, von Bedeutung. Diese Darstellungen können für eine Vielzahl von Anwendungen wie Klassifizierung, Anomalieerkennung und Dimensionsreduktion verwendet werden.
Die Fähigkeit von DBNs, ein unbeaufsichtigtes Vortraining durchzuführen, das die Leistung von Deep-Learning-Modellen mit minimal gekennzeichneten Daten steigern kann, ist ein wesentlicher Vorteil.

Was sind die Anwendungen von DBNs?
Eine der wichtigsten Anwendungen ist Objekterkennung, in dem DBNs verwendet werden, um bestimmte Arten von Dingen wie Flugzeuge, Vögel und Menschen zu erkennen. Sie werden auch für die Bilderzeugung und -klassifizierung, die Bewegungserkennung in Filmen und das natürliche Sprachverständnis für die Sprachverarbeitung verwendet.
Darüber hinaus werden DBNs häufig in Datensätzen verwendet, um menschliche Körperhaltungen zu bewerten. DBNs sind ein großartiges Werkzeug für eine Vielzahl von Branchen, darunter das Gesundheitswesen und das Bankwesen sowie die Technologie.
5. Deep Reinforcement Learning Networks (DRLs)
Tief Verstärkung lernen Netzwerke (DRLs) integrieren tiefe neuronale Netzwerke mit Reinforcement-Learning-Techniken, damit Agenten in einer komplizierten Umgebung durch Versuch und Irrtum lernen können.
DRLs werden verwendet, um Agenten beizubringen, wie sie ein Belohnungssignal optimieren können, indem sie mit ihrer Umgebung interagieren und aus ihren Fehlern lernen.
Was macht sie bemerkenswert?
Sie wurden effektiv in einer Vielzahl von Anwendungen eingesetzt, darunter Spiele, Robotik und autonomes Fahren. DRLs sind wichtig, weil sie direkt aus rohem sensorischem Input lernen können und es den Agenten ermöglichen, Entscheidungen auf der Grundlage ihrer Interaktionen mit der Umgebung zu treffen.
Wichtige Wendungen
DRLs werden unter realen Umständen eingesetzt, weil sie mit schwierigen Problemen umgehen können.
DRLs wurden in mehrere prominente Software- und Technologieplattformen aufgenommen, darunter OpenAI's Gym, Die ML-Agenten von Unity, und Googles DeepMind Lab. AlphaGo, gebaut von Google DeepMind, beispielsweise, setzt DRL ein, um das Brettspiel Go auf Weltmeisterniveau zu spielen.

Eine andere Verwendung von DRL ist in der Robotik, wo es verwendet wird, um die Bewegungen von Roboterarmen zu steuern, um Aufgaben wie das Greifen von Gegenständen oder das Stapeln von Blöcken auszuführen. DRLs haben viele Verwendungsmöglichkeiten und sind ein nützliches Werkzeug für Schulungsagenten zu lernen und treffen Sie Entscheidungen in komplizierten Umgebungen.
6. Autoencoder
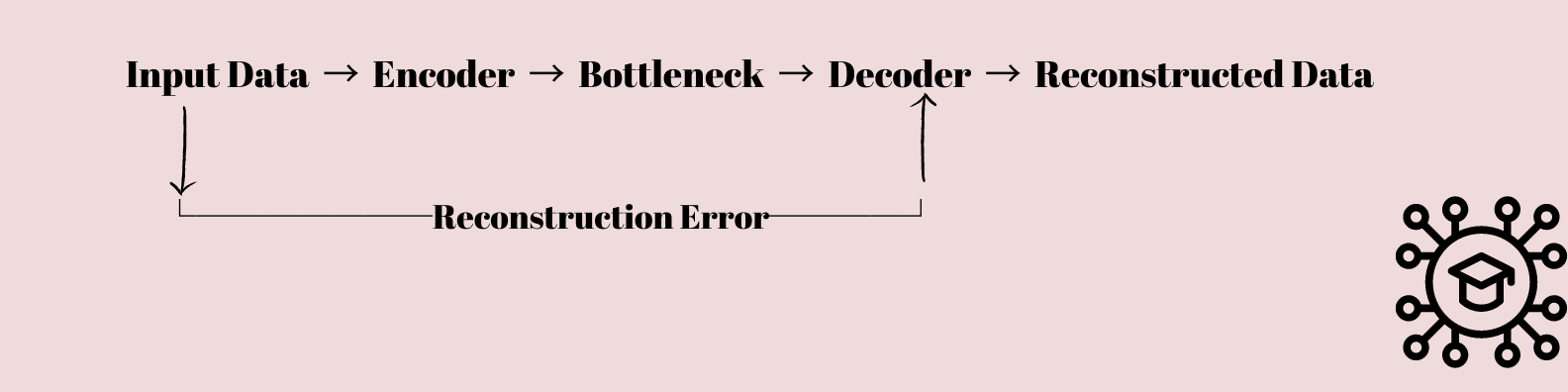
Autoencoder sind eine interessante Art von neuronale Netzwerk das hat das Interesse von Wissenschaftlern und Datenwissenschaftlern geweckt. Sie sind im Wesentlichen darauf ausgelegt, das Komprimieren und Wiederherstellen von Daten zu erlernen.
Die Eingabedaten werden durch eine Reihe von Schichten geleitet, die die Dimensionalität der Daten allmählich verringern, bis sie in eine Engpassschicht mit weniger Knoten als die Eingabe- und Ausgabeschichten komprimiert werden.
Diese komprimierte Darstellung wird dann verwendet, um die ursprünglichen Eingabedaten mithilfe einer Folge von Ebenen neu zu erstellen, die die Dimensionalität der Daten allmählich wieder in ihre ursprüngliche Form bringen.
Warum ist es wichtig?
Autoencoder sind eine entscheidende Komponente von tiefe Lernen weil sie Merkmalsextraktion und Datenreduktion ermöglichen.
Sie sind in der Lage, die Schlüsselelemente der eingehenden Daten zu identifizieren und sie in eine komprimierte Form zu übersetzen, die dann für andere Aufgaben wie Klassifizierung, Gruppierung oder die Erstellung neuer Daten verwendet werden kann.
Wo verwenden wir Autoencoder?
Anomalieerkennung, Verarbeitung natürlicher Sprache und Computer Vision sind nur einige der Disziplinen, in denen Autoencoder zum Einsatz kommen. Autoencoder können beispielsweise zur Bildkomprimierung, Bildentrauschung und Bildsynthese in Computer Vision verwendet werden.
Wir können Autoencoder für Aufgaben wie Texterstellung, Textkategorisierung und Textzusammenfassung in der Verarbeitung natürlicher Sprache verwenden. Es kann anomale Aktivitäten in Daten identifizieren, die von der Norm bei der Anomalieerkennung abweichen.
7. Kapselnetzwerke
Capsule Networks ist eine neue Deep-Learning-Architektur, die als Ersatz für Convolutional Neural Networks (CNNs) entwickelt wurde.
Kapselnetzwerke basieren auf der Vorstellung, Gehirneinheiten, sogenannte Kapseln, zu gruppieren, die dafür verantwortlich sind, die Existenz eines bestimmten Objekts in einem Bild zu erkennen und seine Attribute wie Ausrichtung und Position in ihre Ausgabevektoren zu codieren. Capsule Networks können daher räumliche Interaktionen und perspektivische Schwankungen besser bewältigen als CNNs.
Warum wählen wir Capsule Networks gegenüber CNNs?
Kapselnetzwerke sind nützlich, weil sie die Schwierigkeiten von CNN beim Erfassen hierarchischer Beziehungen zwischen Elementen in einem Bild überwinden. CNNs können Dinge unterschiedlicher Größe erkennen, haben aber Schwierigkeiten zu verstehen, wie diese Dinge miteinander verbunden sind.
Capsule Networks hingegen können lernen, Dinge und ihre Teile sowie ihre räumliche Platzierung in einem Bild zu erkennen, was sie zu einem brauchbaren Konkurrenten für Computer-Vision-Anwendungen macht.
Anwendungsbereiche
Capsule Networks haben bereits vielversprechende Ergebnisse in einer Vielzahl von Anwendungen gezeigt, darunter Bildklassifizierung, Objektidentifikation und Bildsegmentierung.
Sie wurden verwendet, um Dinge auf medizinischen Fotos zu unterscheiden, Personen in Filmen zu erkennen und sogar 3D-Modelle aus 2D-Bildern zu erstellen.
Um ihre Leistung zu steigern, wurden Capsule Networks mit anderen Deep-Learning-Architekturen wie Generative Adversarial Networks (GANs) und Variational Autoencoders (VAEs) kombiniert. Kapselnetzwerke werden voraussichtlich eine immer wichtigere Rolle bei der Verbesserung von Computer-Vision-Technologien spielen, da sich die Wissenschaft des Deep Learning weiterentwickelt.
Beispielsweise; Nibel ist ein bekanntes Python-Tool zum Lesen und Schreiben von Neuroimaging-Dateitypen. Für die Bildsegmentierung verwendet es Capsule Networks.
8. Aufmerksamkeitsbasierte Modelle
Deep-Learning-Modelle, bekannt als aufmerksamkeitsbasierte Modelle, auch bekannt als Aufmerksamkeitsmechanismen, streben danach, die Genauigkeit von zu erhöhen Modelle des maschinellen Lernens. Diese Modelle konzentrieren sich auf bestimmte Merkmale eingehender Daten, was zu einer effizienteren und effektiveren Verarbeitung führt.
Bei Verarbeitungsaufgaben natürlicher Sprache wie maschineller Übersetzung und Sentimentanalyse haben sich Aufmerksamkeitsmethoden als recht erfolgreich erwiesen.
Was ist ihre Bedeutung?
Aufmerksamkeitsbasierte Modelle sind nützlich, weil sie eine effektivere und effizientere Verarbeitung komplizierter Daten ermöglichen.
Traditionelle neuronale Netze Bewerten Sie alle Eingabedaten als gleich wichtig, was zu einer langsameren Verarbeitung und einer geringeren Genauigkeit führt. Aufmerksamkeitsprozesse konzentrieren sich auf entscheidende Aspekte der Eingabedaten, was schnellere und genauere Vorhersagen ermöglicht.

Anwendungsbereiche
Im Bereich der künstlichen Intelligenz haben Aufmerksamkeitsmechanismen ein breites Anwendungsspektrum, darunter die Verarbeitung natürlicher Sprache, Bild- und Audioerkennung und sogar fahrerlose Fahrzeuge.
Aufmerksamkeitsmethoden können beispielsweise verwendet werden, um die maschinelle Übersetzung in der Verarbeitung natürlicher Sprache zu verbessern, indem sie es dem System ermöglichen, sich auf bestimmte Wörter oder Sätze zu konzentrieren, die für den Kontext wesentlich sind.
Aufmerksamkeitsmethoden in autonomen Autos können eingesetzt werden, um das System dabei zu unterstützen, sich auf bestimmte Gegenstände oder Herausforderungen in seiner Umgebung zu konzentrieren.
9. Transformatornetzwerke
Transformer-Netzwerke sind Deep-Learning-Modelle, die Datensequenzen untersuchen und produzieren. Sie funktionieren, indem sie die Eingabesequenz Element für Element verarbeiten und eine Ausgabesequenz gleicher oder unterschiedlicher Länge erzeugen.
Transformer-Netzwerke verarbeiten im Gegensatz zu standardmäßigen Sequence-to-Sequence-Modellen Sequenzen nicht mit rekurrenten neuronalen Netzwerken (RNNs). Stattdessen setzen sie Selbstaufmerksamkeitsprozesse ein, um die Verbindungen zwischen den Teilen der Sequenz zu lernen.
Welche Bedeutung haben Transformatornetzwerke?
Transformer-Netzwerke haben in den letzten Jahren aufgrund ihrer besseren Leistung bei der Verarbeitung natürlicher Sprache an Popularität gewonnen.
Sie eignen sich besonders gut für Texterstellungsaufgaben wie Sprachübersetzung, Textzusammenfassung und Gesprächsproduktion.
Transformatornetzwerke sind rechnerisch wesentlich effizienter als RNN-basierte Modelle, was sie zu einer bevorzugten Wahl für groß angelegte Anwendungen macht.

Wo finden Sie Transformatornetzwerke?
Transformer-Netzwerke werden weithin in einer breiten Palette von Anwendungen eingesetzt, insbesondere in der Verarbeitung natürlicher Sprache.
Die GPT-Reihe (Generative Pre-Trained Transformer) ist ein bekanntes Transformer-basiertes Modell, das für Aufgaben wie Sprachübersetzung, Textzusammenfassung und Chatbot-Generierung verwendet wurde.
BERT (Bidirectional Encoder Representations from Transformers) ist ein weiteres gängiges transformatorbasiertes Modell, das für Anwendungen zum Verständnis natürlicher Sprache wie die Beantwortung von Fragen und die Stimmungsanalyse verwendet wurde.
Beide GPT und BERT wurden mit erstellt PyTorch, ein Open-Source-Deep-Learning-Framework, das für die Entwicklung transformatorbasierter Modelle beliebt ist.
10. Eingeschränkte Boltzmann-Maschinen (RBMs)
Restricted Boltzmann Machines (RBMs) sind eine Art unbeaufsichtigtes neuronales Netzwerk, das auf generative Weise lernt. Aufgrund ihrer Fähigkeit zu lernen und wesentliche Merkmale aus hochdimensionalen Daten zu extrahieren, werden sie häufig in den Bereichen maschinelles Lernen und Deep Learning eingesetzt.
RBMs bestehen aus zwei Schichten, sichtbar und verborgen, wobei jede Schicht aus einer Gruppe von Neuronen besteht, die durch gewichtete Kanten verbunden sind. RBMs sind darauf ausgelegt, eine Wahrscheinlichkeitsverteilung zu lernen, die die Eingabedaten beschreibt.
Was sind eingeschränkte Boltzmann-Maschinen?
RBMs verwenden eine generative Lernstrategie. In RBMs spiegelt die sichtbare Schicht die Eingabedaten wider, während die vergrabene Schicht die Eigenschaften der Eingabedaten codiert. Die Gewichte der sichtbaren und verdeckten Schichten zeigen die Stärke ihrer Verbindung.
RBMs passen die Gewichte und Verzerrungen zwischen den Schichten während des Trainings an, indem sie eine Technik verwenden, die als kontrastive Divergenz bekannt ist. Kontrastive Divergenz ist eine unüberwachte Lernstrategie, die die Vorhersagewahrscheinlichkeit des Modells maximiert.
Welche Bedeutung haben eingeschränkte Boltzmann-Maschinen?
RBMs sind von Bedeutung in Maschinelles Lernen und Deep Learning, weil sie aus großen Datenmengen relevante Merkmale lernen und extrahieren können.
Sie sind sehr effektiv für die Bild- und Spracherkennung und wurden in einer Vielzahl von Anwendungen wie Empfehlungssystemen, Anomalieerkennung und Dimensionsreduktion eingesetzt. RBMs können Muster in riesigen Datensätzen finden, was zu überlegenen Vorhersagen und Erkenntnissen führt.

Wo dürfen eingeschränkte Boltzmann-Maschinen verwendet werden?
Zu den Anwendungen für RBMs gehören Dimensionsreduktion, Anomalieerkennung und Empfehlungssysteme. RBMs sind besonders hilfreich für Stimmungsanalysen und Themenmodellierung im Kontext der Verarbeitung natürlicher Sprache.
Auch Deep Belief Networks, eine Art neuronales Netz zur Sprach- und Bilderkennung, verwenden RBMs. Die Deep Belief Network Toolbox, TensorFlow und Theano sind einige besondere Beispiele für Software oder Technologie, die RBMs verwendet.
Einpacken
Deep-Learning-Modelle werden in einer Vielzahl von Branchen immer wichtiger, darunter Spracherkennung, Verarbeitung natürlicher Sprache und Computer Vision.
Convolutional Neural Networks (CNNs) und Recurrent Neural Networks (RNNs) haben sich als am vielversprechendsten erwiesen und werden in vielen Anwendungen ausgiebig genutzt, jedoch haben alle Deep-Learning-Modelle ihre Vor- und Nachteile.
Forscher beschäftigen sich jedoch immer noch mit Restricted Boltzmann Machines (RBMs) und anderen Varianten von Deep-Learning-Modellen, weil auch sie besondere Vorteile haben.
Es wird erwartet, dass neue und kreative Modelle geschaffen werden, wenn der Bereich des Deep Learning weiter voranschreitet, um schwierigere Probleme zu bewältigen





Hinterlassen Sie uns einen Kommentar