Inhaltsverzeichnis[Ausblenden][Zeigen]
Um Informationen von Websites zu Analyse-, Forschungs- oder Marketingzwecken zu sammeln, ist Web Scraping eine entscheidende Technik. Glücklicherweise gibt es zahlreiche Tools, die sowohl Headless- als auch Headful-Browser unterstützen, die beide für das Web Scraping nützlich sind.
Headful-Browser verfügen über eine grafische Benutzeroberfläche (GUI), Headless-Browser nicht. Diese Technologien können sowohl manuell als auch automatisch Daten von Webseiten extrahieren, was sie sehr vorteilhaft macht.
Beim Umgang mit vielen Daten sind Headless-Browser die beste Option. Um Ihren Datenextraktionsprozess zu automatisieren, benötigen Sie diese Tools, die Ihnen eine Menge Zeit und Arbeit sparen.
Darüber hinaus helfen sie Ihnen, die Genauigkeit und Effektivität Ihrer Datenextraktion zu verbessern, was insgesamt zu fruchtbareren Ergebnissen führen kann.
Diese Tools können auch dazu beitragen, die Wahrscheinlichkeit von Fehlern beim manuellen Kopieren und Einfügen von Daten zu verringern, da sie die Fähigkeit haben, Daten auf organisierte Weise zu extrahieren.
Einfach gesagt, es ist unmöglich, ohne Tools zu arbeiten, die sowohl Headless- als auch Headful-Browser unterstützen, wenn Sie sich mit Web Scraping beschäftigen.
In diesem Artikel sehen wir uns die besten Headless- und Headful-Browser für Web Scraping an.
1. Helle Daten
Bright Data ist ein Web-Scraping-Programm, das Auswahlmöglichkeiten für die Datenerfassung für Unternehmen und Einzelpersonen bietet. Im Gegensatz zu früheren Online-Scraping-Systemen ist Bright Data mit einer Reihe von Browsern vorinstalliert, funktioniert aber als Headless-Browser.
Obwohl es im Backend als Headless-Browser ausgeführt wird, deutet dies darauf hin, dass Benutzer über eine grafische Benutzeroberfläche (GUI) damit interagieren können, was es zugänglicher und benutzerfreundlicher macht.
Diese Funktionalität ist besonders nützlich für diejenigen, die nicht viel über Codierung wissen oder einen einfacheren Ansatz für das Web Scraping wünschen. Benutzer können dank des leistungsstarken Browsers von Bright Data schnell durch komplexe Websites mit menschenähnlichen Interaktionen navigieren.
Damit Sie anonym und unentdeckt bleiben, bietet es auch hochmoderne Funktionen wie IP-Rotation, Browser-Fingerprinting und User-Agent-Fake. Durch den Einsatz von KI wird Scraping Browser in der Lage sein, selbst die fortschrittlichsten Bot-Erkennungsschutzmaßnahmen zu übertreffen.
Tatsächlich ist der Scraping-Browser so ausgefeilt, dass er sogar die Aktionen des Browsers eines echten Benutzers simulieren kann, wodurch Sie erfolgreichere Ergebnisse und präzisere Daten erhalten.
AnzeigenPreise
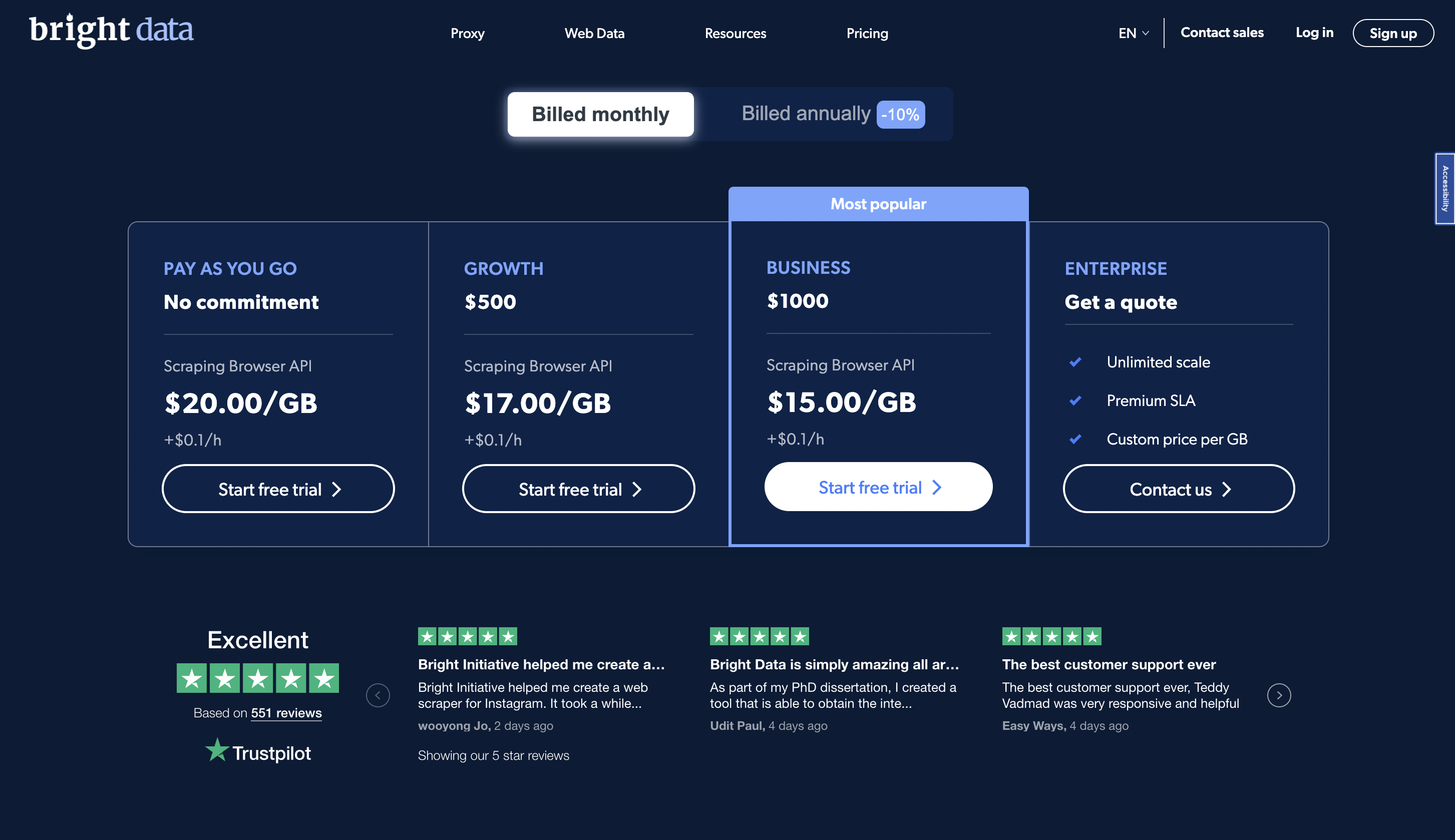
Sie können die Plattform kostenlos testen und die Premium-Preise beginnen bei 20 $/GB in einem Pay-as-you-go-Plan.
2. Zyte
Als Anbieter von Online-Scraping-Tools ermöglicht Zyte – früher bekannt als Scrapinghub – Unternehmen, Internetdaten in großem Umfang zu erfassen und zu analysieren.
Die Online-Scraping-Plattform von Zyte wurde entwickelt, um selbst die kompliziertesten und dynamischsten Websites zu handhaben, und sie enthält eine Vielzahl innovativer Funktionen wie automatisierte IP-Rotation, Browser-Fingerprinting und User-Agent-Spoofing, um sicherzustellen, dass Ihre Scraping-Vorgänge privat und unbemerkt bleiben.
Die Tatsache, dass die Web-Scraping-Plattform von Zyte sowohl Headless- als auch Headful-Surfmodi unterstützt, ist einer ihrer entscheidenden Vorteile. Der Browser arbeitet ohne grafische Benutzeroberfläche im Headless-Modus im Hintergrund, was seine Effizienz bei umfangreichen Scraping-Operationen erhöht.
Der Browser arbeitet jedoch mit einer GUI im Headful-Modus, was von Vorteil sein kann, wenn Sie Daten von Websites mit komplizierten Benutzeroberflächen extrahieren müssen.
Da die Plattform von Zyte auf der kostenlosen und quelloffenen Grundlage Scrapy basiert, kann sie außerdem an Ihre spezifischen Anforderungen angepasst werden und ist äußerst konfigurierbar. Mit Zyte können Sie schnell und einfach die gewünschten Daten abrufen, was Ihnen einen Wettbewerbsvorteil in Ihrem Unternehmen verschafft.
AnzeigenPreise
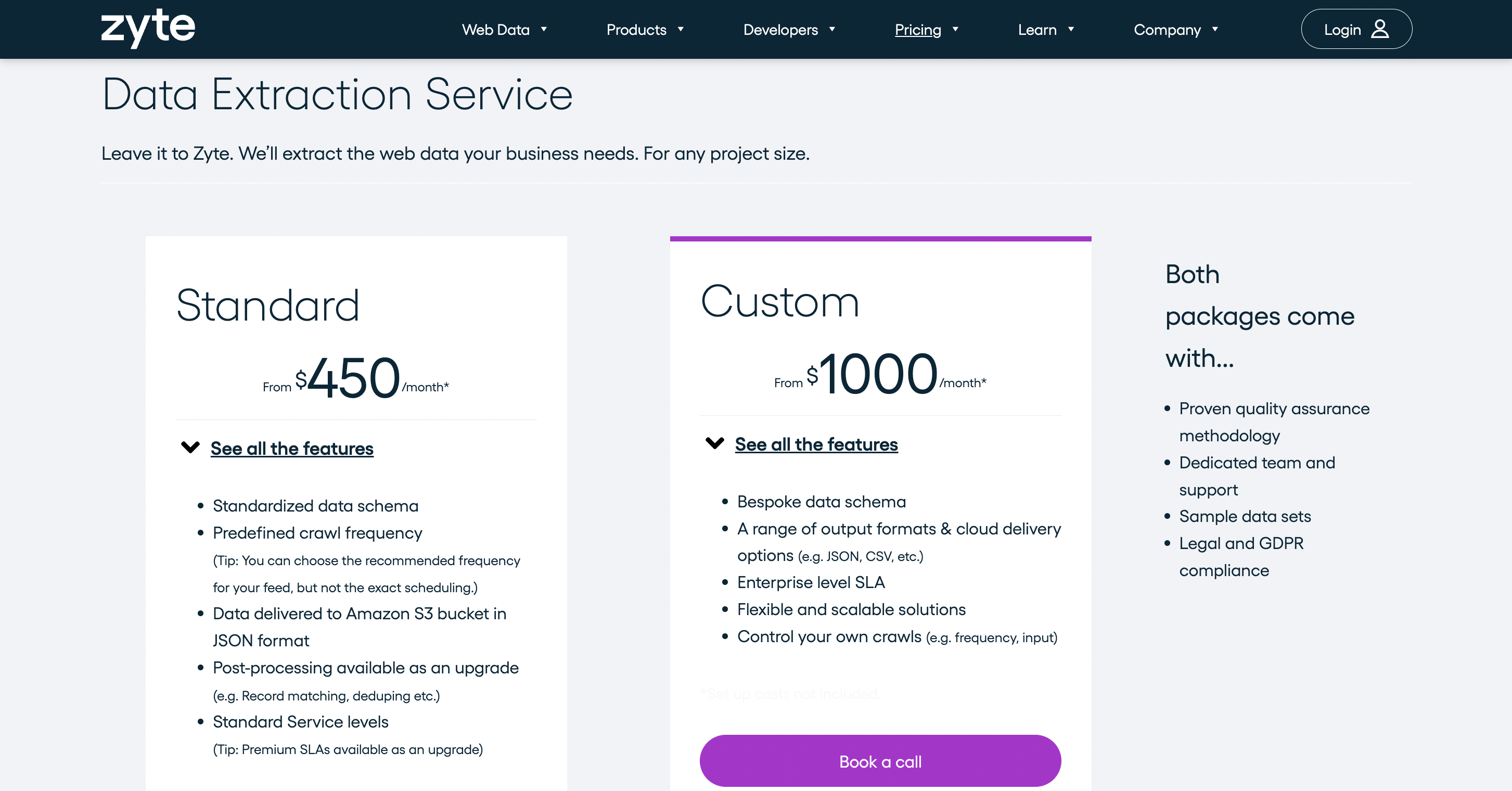
Es bietet mehrere Preispläne und berechnet 450 $/Monat für den Datenextraktionsdienst.
3. Oktoparese
Mit Octoparse, einer Cloud-basierten Web-Scraping-Anwendung, können Sie Daten von Webseiten sammeln, ohne Code schreiben zu müssen. Jeder, der Text, Fotos oder Videos schaben möchte, kann diese dank der benutzerfreundlichen Oberfläche ganz einfach auswählen.
Octoparse ist ein flexibles Tool, das sowohl Headless- als auch Headful-Browsing unterstützt. Es ist die beste Option für Web-Scraping-Projekte jeder Größe und Komplexität. Die Fähigkeit, dynamische und interaktive Webseiten zu schaben, was für viele andere Web-Scraping-Programme schwierig sein kann, ist eine seiner stärksten Eigenschaften.
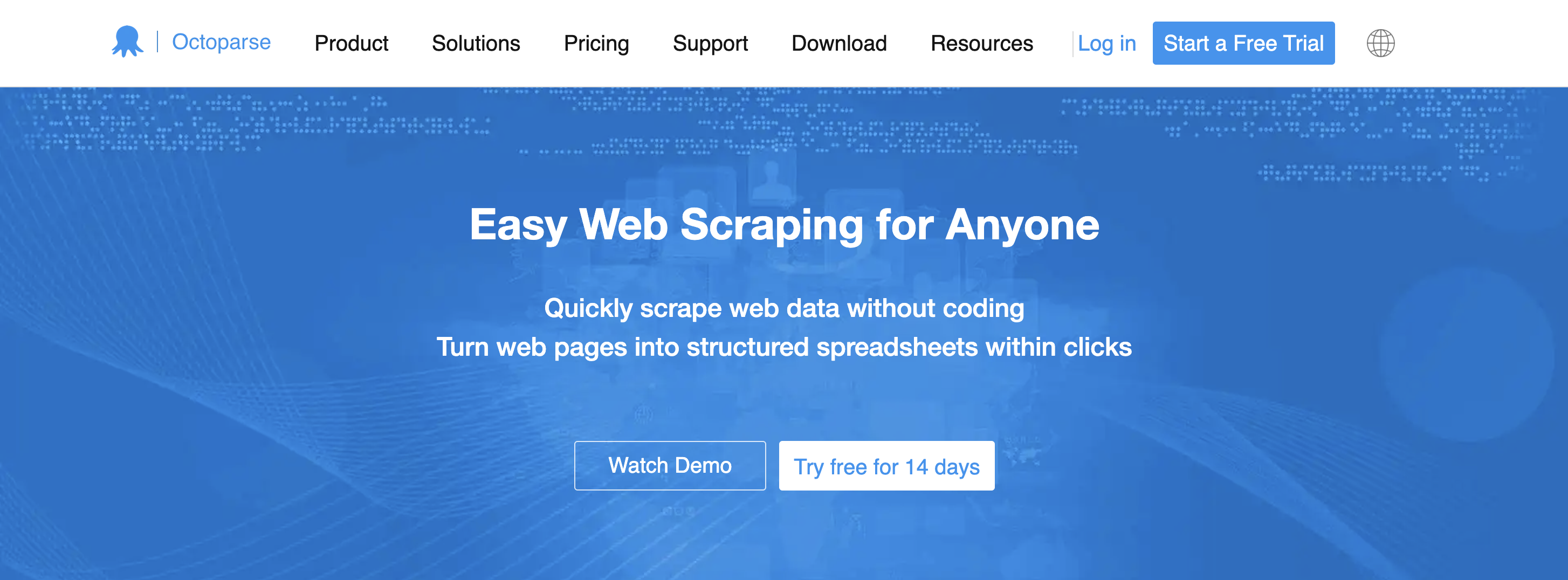
Sie können komplexe Scraping-Prozesse mit zahlreichen Phasen, bedingten Anweisungen und Schleifen erstellen und so die Flexibilität und Anpassbarkeit des Scrapings erhöhen. Excel, CSV und SQL sind nur einige der von Octoparse bereitgestellten Exportformate, die es einfach machen, die extrahierten Daten in anderen Programmen zu verwenden.
Darüber hinaus verfügt Octoparse über einen integrierten Proxy-Pool, der anonymes Scraping gewährleistet und hilft, IP-Sperren zu vermeiden.
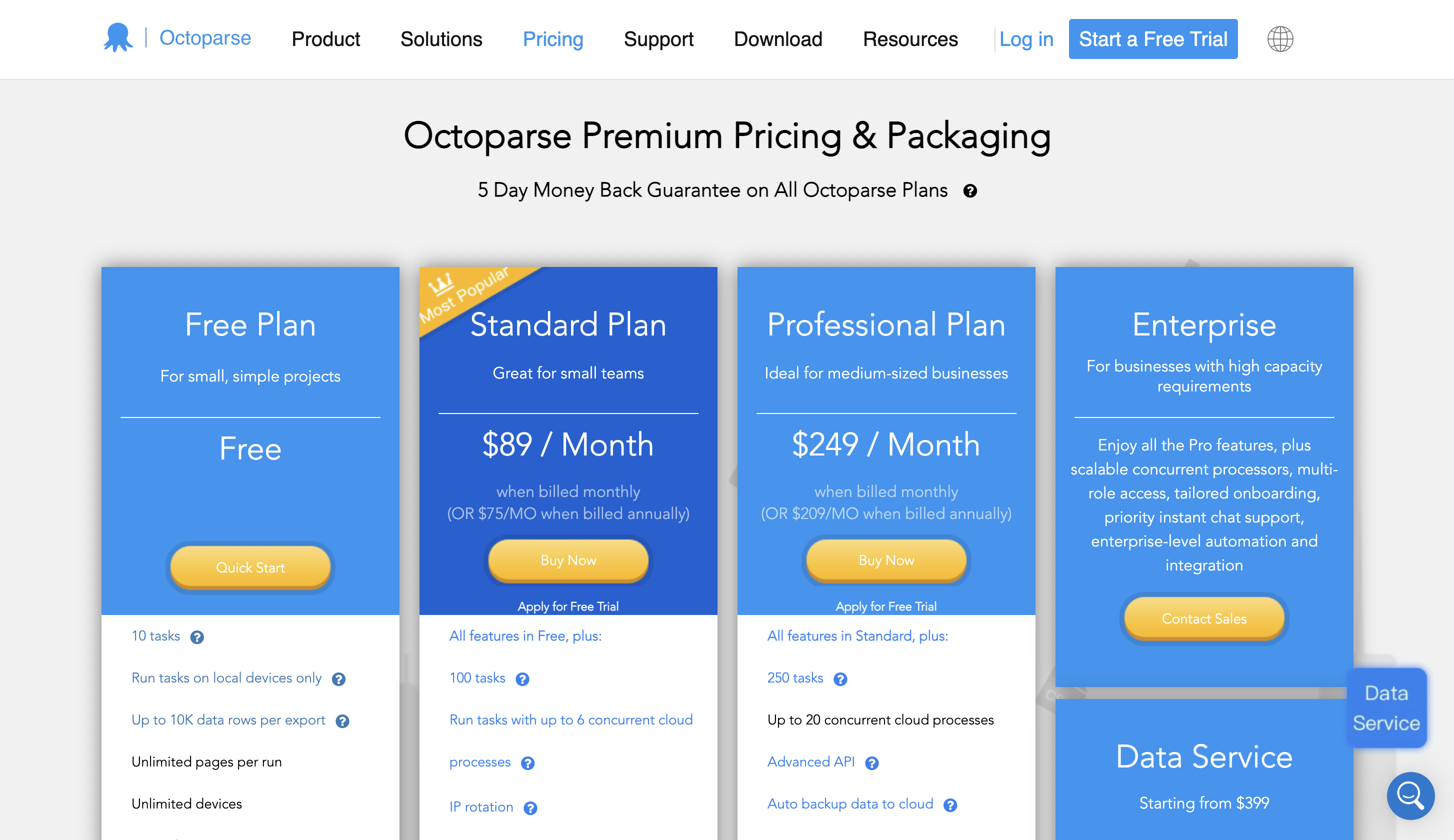
AnzeigenPreise
Sie können es kostenlos nutzen und die Premium-Preise beginnen bei 89 $/Monat.
4. Apify
Apify ist eine All-in-One-Plattform für Web Scraping und Automatisierung, die eine Vielzahl leistungsstarker Funktionen bietet. Es unterstützt sowohl Headless- als auch Headful-Browser und verfügt über eine intuitive Benutzeroberfläche, die es selbst technisch nicht versierten Benutzern leicht macht, Scraping-Aufgaben zu erstellen.
Apifys Fähigkeit, schwierige Scraping-Jobs zu bewältigen, mehrere Sprachen zu unterstützen und zu skalieren, um groß angelegte Scraping-Projekte zu bewältigen, sind einige seiner besten Eigenschaften.
Darüber hinaus bietet Apify Zugang zu einem riesigen Markt an vorgefertigten Schabern, die schnell an Ihre individuellen Anforderungen angepasst werden können.
Mit seiner Unterstützung für Headless-Browser kann Apify durch anspruchsvolle Benutzeroberflächen navigieren und Daten von dynamischen Websites kratzen, während es schnell und effizient Informationen aus riesigen Datenmengen extrahiert.
Apify ist ein nützliches Tool für eine Vielzahl von Online-Scraping-Anwendungen, einschließlich Lead-Generierung, Wettbewerbsanalyse, Marktforschung und Inhaltsaggregation.
Apify steigert die Genauigkeit und Effizienz und spart gleichzeitig Zeit und Mühe durch die Automatisierung des Datenextraktionsprozesses. Aufgrund seiner Funktionalität und seines benutzerfreundlichen Designs ist es sowohl für technische als auch für nicht-technische Benutzer ein starkes Werkzeug.
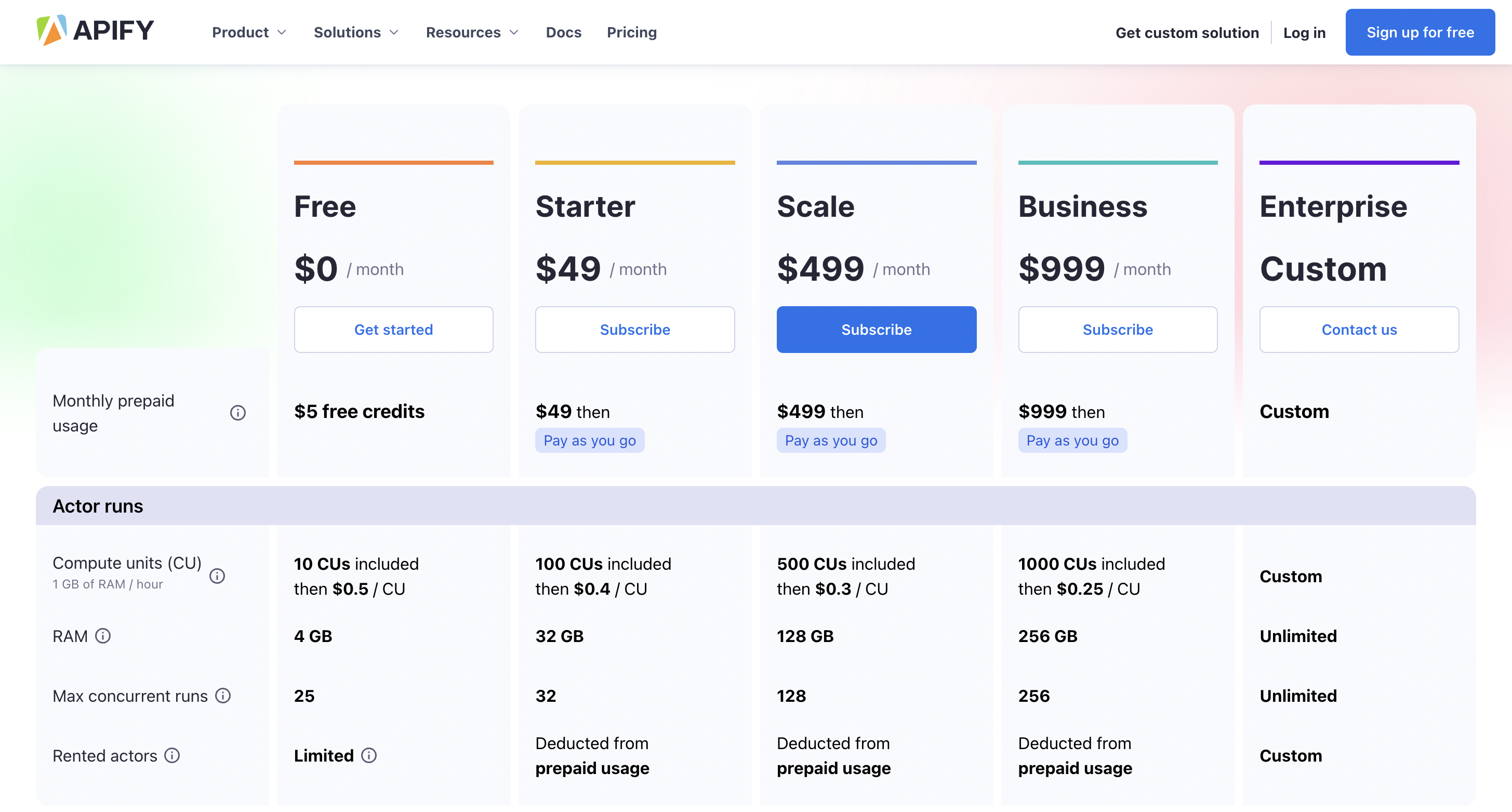
AnzeigenPreise
Sie können es kostenlos nutzen und die Premium-Preise beginnen bei 49 $/Monat.
5. SchabenBiene
Die hervorragende Online-Scraping-Anwendung ScrapingBee macht es einfach, den Datenextraktionsprozess von Websites zu automatisieren.
Seine Fähigkeiten, wie die zur Verarbeitung von JavaScript-Rendering, CAPTCHA-Auflösung und User-Agent-Rotation, ermöglichen es, die Anti-Scraping-Abwehr von Websites zu umgehen. Daher ist es eine großartige Option für Web-Scraping-Aufgaben.
Benutzer haben mit diesem Tool einen großen Freiheitsgrad, da es sowohl mit Headless- als auch mit Headful-Browsern funktioniert. Es ist wichtig darauf hinzuweisen, dass ScrapingBee standardmäßig Headless-Browser verwendet, was perfekt zum automatischen Abrufen enormer Datenmengen ist.
Um mit Websites zu interagieren, die über eine komplexe Benutzeroberfläche verfügen, wechseln Benutzer möglicherweise zu Headful-Browsern. Um eine effektive Datenextraktion zu gewährleisten, unterhält ScrapingBee auch einen Pool von geolokalisierten Proxys, die regelmäßig überprüft und geändert werden.
Benutzer können Zeit und Aufwand beim Web Scraping reduzieren, indem sie ScrapingBee als Headless- oder Headful-Browser verwenden und gleichzeitig die Korrektheit und Vollständigkeit der abgerufenen Daten gewährleisten. Es hat auch viele hilfreiche Funktionen, wie Datenformatierung, Proxy-Rotation und API-Konnektivität, was es zu einem praktischen Tool für Unternehmen und Studenten macht.
AnzeigenPreise
Die Premium-Preise beginnen bei 49 $/Monat.
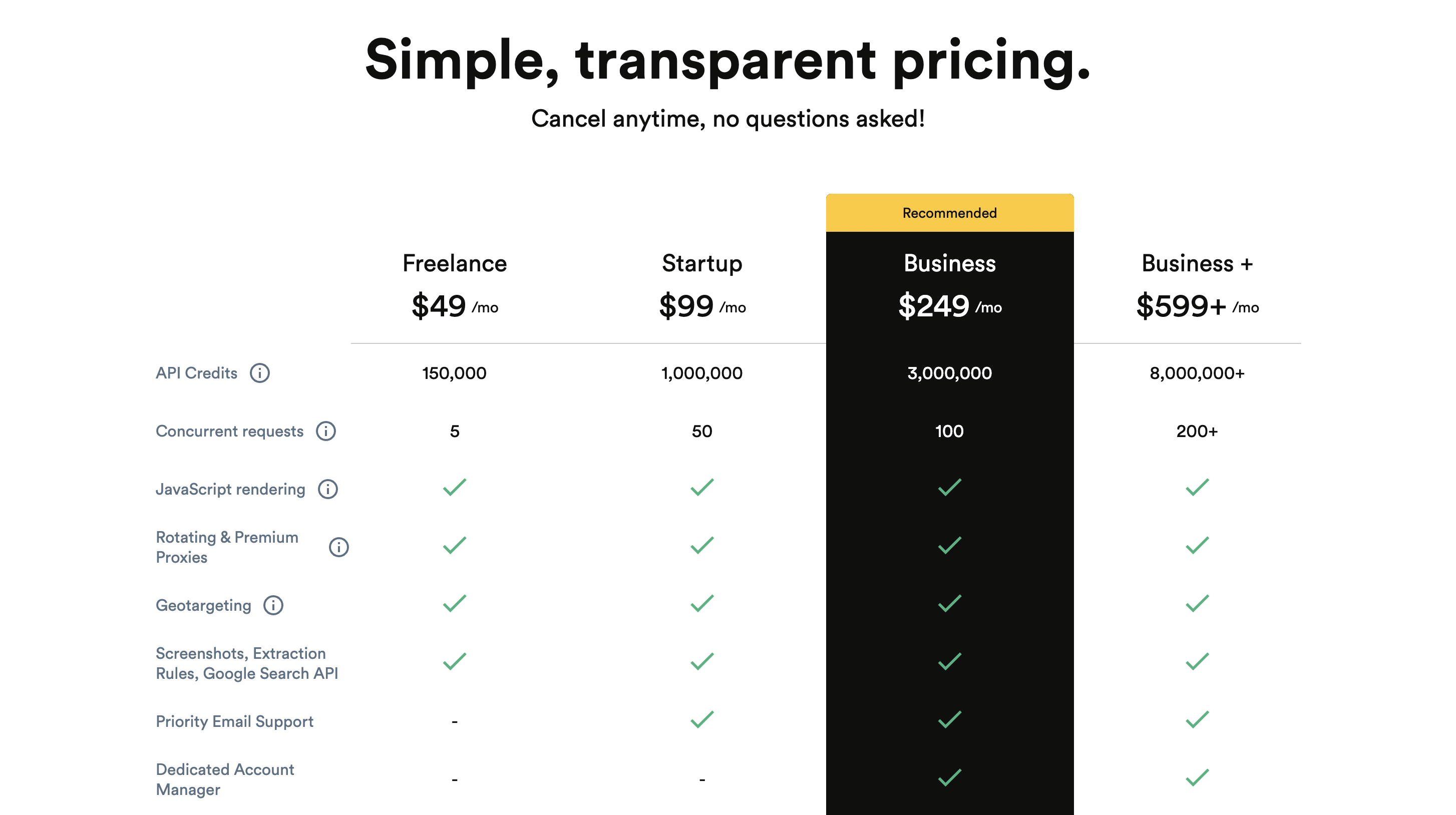
6. ParseHub
Ohne technisches Fachwissen können Benutzer mit der Web-Scraping-Anwendung ParseHub Daten von Websites sammeln. Eines seiner größten Merkmale ist die Benutzerfreundlichkeit; Benutzer können die Daten auswählen, die sie kratzen möchten, indem sie einfach auf die Elemente klicken.
Außerdem hat es die Fähigkeit, Paginierung automatisch zu erkennen, was es Benutzern erleichtert, Informationen von mehreren Seiten zu kratzen. Um Daten von Websites mit einfachen oder komplizierten Benutzeroberflächen zu kratzen, unterstützt ParseHub sowohl Headless- als auch Headful-Browser.
Darüber hinaus bietet es eine automatische IP-Rotation, wodurch es für Websites schwieriger wird, Scraping-Aktivitäten zu identifizieren und zu verbieten. ParseHub garantiert mit Hilfe seiner umfangreichen Datenformatierungsfunktionen, dass Daten auf organisierte Weise extrahiert werden, was die Analyse und Systemintegration vereinfacht.
Darüber hinaus verfügt ParseHub über einen intelligenten Modus, der Informationen von ähnlichen Websites automatisch erkennt und sammelt. ParseHub kann Daten von Websites mit ähnlichen Strukturen, wie z. B. E-Commerce-Websites, erkennen und sammeln künstliche Intelligenz (AI). Diese Funktion steigert die Genauigkeit und Produktivität, indem sie weniger Aufwand erfordert und Zeit spart.
AnzeigenPreise
Sie können es kostenlos nutzen und die Premium-Preise beginnen bei 189 $/Monat.
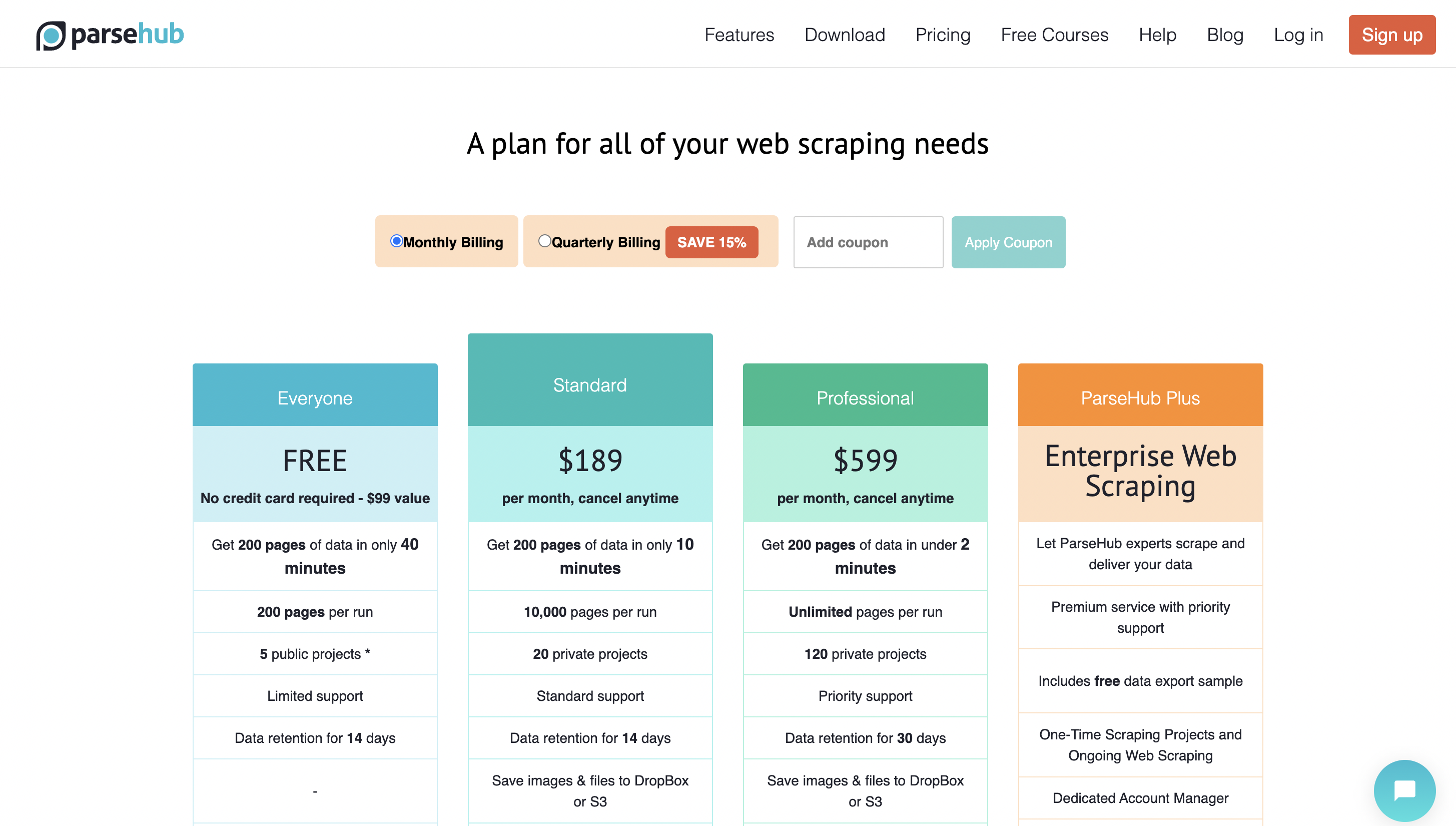
7. WebHarvy
WebHarvy ist ein leistungsstarkes Online-Scraping-Tool, das es Unternehmen ermöglicht, Daten schnell, genau und effizient von Websites zu scrapen. Es wurde entwickelt, um Informationen von vielen Websites, einschließlich Suchmaschinen, sozialen Medien, E-Commerce-Websites und Verzeichnissen, zu kratzen.
Ohne vorherige Programmiererfahrung können Benutzer aufgrund der benutzerfreundlichen Oberfläche mühelos Scraping-Jobs erkunden und erstellen. Eines der größten Merkmale von WebHarvy ist seine Fähigkeit, Daten von Webseiten abzurufen, die mit JavaScript und AJAX betrieben werden, auf die andere Scraping-Tools möglicherweise nicht zugreifen können.
Darüber hinaus bietet es eine Point-and-Click-Oberfläche, die es einfach macht, die Informationen von einer Webseite auszuwählen, die Sie kratzen möchten. WebHarvy verfügt über Headless- und Headful-Browsing-Modi. Für ein schnelleres und effektiveres Data Scraping kann es im Headless-Modus betrieben werden.
Der Headful-Modus ist hilfreich, wenn Sie mit komplizierten Websites arbeiten, die Benutzereingaben erfordern. Es kann auch zwischen zahlreichen Seiten navigieren und Formulare ausfüllen, was beim Extrahieren von Daten von Websites mit mehreren Seiten nützlich ist.
AnzeigenPreise
Die Premium-Preise beginnen bei 129 $ für eine Einzelbenutzerlizenz.

8. Dataflow-Kit
Mit Dataflow Kit, einem robusten Online-Scraping-Tool, können Daten von einer Vielzahl von Websites gesammelt und analysiert werden, darunter Social-Networking Websites, Suchmaschinen, E-Commerce-Websites und Nachrichten-Websites. Eine seiner besten Eigenschaften ist die Fähigkeit, Daten von komplizierten, dynamischen Websites schnell und effizient zu sammeln.
Es ist ideal zum Scrapen von Websites, auf die mit anderen Methoden nur schwer zugegriffen werden kann, da es so einfach zu verwenden ist. Sowohl ein Headless-Browser als auch ein Headful-Browser sind mit Dataflow Kit funktionsfähig. Erweiterte Funktionen wie Proxy- und User-Agent-Rotation, IP-Blockierungsvermeidung und Anti-Bot-Erkennung werden bereitgestellt, um ein effektives Scraping sicherzustellen.
Darüber hinaus bietet es eine benutzerfreundliche Oberfläche, die es Kunden ermöglicht, ihre Scraping-Aktivitäten ohne Programmiererfahrung zu erstellen, zu planen und zu verwalten. Für groß angelegte Web-Scraping-Anwendungen ist seine effektive Scraper-Engine eine fantastische Lösung, da sie für die schnelle und effektive Datenverarbeitung optimiert ist.
Die geschabten Daten können einfach in eine Vielzahl von Formaten exportiert werden, darunter CSV, JSON und XML, sodass Sie sie nach Belieben analysieren und verwenden können. Darüber hinaus bietet Dataflow Kit eine Vielzahl von Schnittstellenoptionen, einschließlich API und Zapier, um Sie bei der Optimierung Ihres Arbeitsablaufs und der Automatisierung Ihres Datenextraktionsprozesses zu unterstützen.
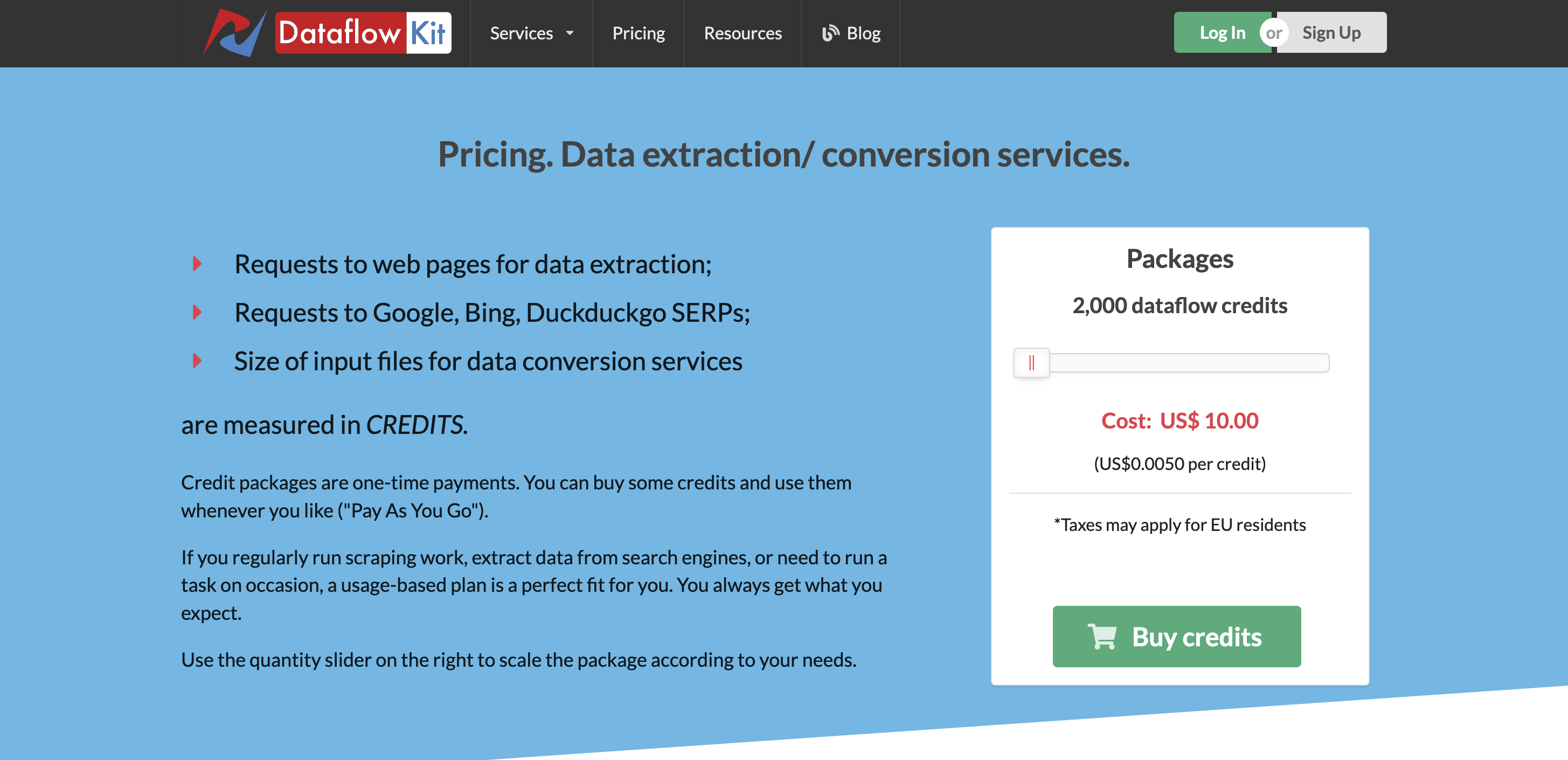
AnzeigenPreise
Die Premium-Preise beginnen bei 10 $ für 2000 Dataflow-Credits, die Sie nach Ihren Bedürfnissen verwenden können.
9. Import.io
Mit Hilfe des cloudbasierten Web-Scraping-Tools Import.io können Nutzer ohne Programmiererfahrung Daten von Websites schaben. Die Einfachheit der Nutzung ist eine der verlockendsten Eigenschaften von Import.io; Alles, was Sie tun müssen, ist zu zeigen und zu klicken, um die Daten zu finden, die Sie auslesen möchten.
Benutzer können extrahierte Daten aufgrund der leistungsstarken Visualisierungsfunktionen in Echtzeit auswerten. Import.io ist ein Headless-Browser, der einen Webbrowser imitiert und eine Verbindung zu Websites auf die gleiche Weise wie eine Person herstellt, jedoch ohne dass eine grafische Benutzeroberfläche erforderlich ist.
Dies verbessert die Web-Scraping-Effizienz und ermöglicht Benutzern das Scrapen von Daten von dynamischen Websites, die eine Benutzerbeteiligung erfordern, um Informationen anzuzeigen. Der KI-gestützte Extractor ermöglicht es Benutzern, Daten mit nur wenigen Klicks zu extrahieren. Der Extractor kann auch Datenmuster erkennen und vergleichbare Daten aus zahlreichen Quellen extrahieren.
Benutzer können ihre Scraping-Bemühungen automatisieren und erhalten mit den umfassenden Planungsfunktionen häufige Updates zu den gewünschten Daten. Import.io macht es einfach, die extrahierten Daten in anderen Apps zu verwenden, indem es Ihnen ermöglicht, mit beliebten Tools wie Google Sheets und Zapier zu verknüpfen.
AnzeigenPreise
Die Preise sind auf der Website nicht aufgeführt, bitte sprechen Sie mit einem Experten darüber.
10 Dexi.io
Die Datenextraktion ist mit Hilfe des robusten Web-Scraping-Tools Dexi.io einfach. Aufgrund der benutzerfreundlichen Oberfläche und der automatisierten Möglichkeiten können Sie mit diesem Tool ohne Programmierkenntnisse Daten von Websites sammeln.
Eine seiner besten Eigenschaften ist seine Fähigkeit, Daten aus vielen Quellen, einschließlich Webseiten, APIs und Datenbanken, zu kratzen und zu kombinieren. Dank der parallelen Verarbeitungsfähigkeit von Dexi.io können Sie schnell und effektiv riesige Datenmengen kratzen.
Dexi.io bietet Ihnen die Wahl, die beste Alternative für Ihre Scraping-Anforderungen auszuwählen, da es sowohl als Headless-Browser als auch als Headful-Browser fungiert. Während die Headful-Browser-Option es Ihnen ermöglicht, die Website so zu sehen und mit ihr zu interagieren, als ob Sie einen typischen Browser verwenden würden, ermöglicht Ihnen die Headless-Browser-Option, Daten zu kratzen, ohne die Seite in einem Browser anzuzeigen.
Dies macht es einfach, Schabeprobleme zu beheben und das Schabeverfahren an Ihre Vorlieben anzupassen. Sie können geschabte Daten aus Dexi.io schnell in einer Vielzahl von Formaten wie CSV, JSON und Excel exportieren, um sie weiter zu analysieren oder mit anderen Anwendungen zu interagieren.
Darüber hinaus bietet es zuverlässiges und sicheres Cloud-Hosting für Ihre gekratzten Daten und garantiert deren Sicherheit und Zugänglichkeit.
AnzeigenPreise
Sie können die Plattform mit ihrem kostenlosen Testplan ausprobieren und das Team für die Preise kontaktieren.
Zusammenfassung
Zusammenfassend lässt sich sagen, dass es mehrere Web-Scraping-Lösungen auf dem Markt gibt, jede mit spezifischen Vorteilen und Fähigkeiten. Es stehen viele Datenalternativen zur Auswahl, die von All-in-One-Lösungen wie Bright Data und ScrapingBee bis hin zu spezialisierteren Tools wie Apify und ParseHub reichen.
Diese Systeme verfügen oft über Funktionen wie Headless Browsing, IP-Rotation, User-Agent-Spoofing und Browser-Fingerprinting, um die Effektivität, Zuverlässigkeit und Geheimhaltung von Online-Scraping zu erhöhen.
Web-Scraping-Tools können Ihnen schnellen und einfachen Zugriff auf eine Fülle von Informationen ermöglichen, egal ob Sie ein Kleinunternehmer sind, der versucht, Ihre Konkurrenten zu untersuchen, ein Forscher, der nach Daten sucht, um Ihre Arbeit zu unterstützen, oder ein Datenanalyst, der nach Einblicken in das Verbraucherverhalten sucht .
Die Möglichkeit von Fehlern und Inkonsistenzen kann verringert werden, während Sie potenziell Zeit und Geld sparen können, indem Sie den Datenerfassungsprozess automatisieren.





Hinterlassen Sie uns einen Kommentar