Inhaltsverzeichnis[Ausblenden][Zeigen]
Es ist nichts Neues, gefälschte Fotos und Videos zu haben. Seit der weitverbreiteten Nutzung des Internets stellen Einzelpersonen Fälschungen her, die täuschen oder amüsieren sollen, seit es Bilder und Filme gibt.
Es gibt jedoch eine neue Art von maschinell hergestellten Fälschungen, die es uns eines Tages schwer machen könnten, Realität von Fiktion zu unterscheiden.
Diese Fälschungen unterscheiden sich von den einfachen Bildmanipulationen durch Bearbeitungssoftware wie Photoshop oder den raffiniert manipulierten Filmen der Vergangenheit.
Deepfakes sind das bekannteste Beispiel für „synthetische Medien“ – Bilder, Töne und Videos, die aussehen, als wären sie mit konventionellen Methoden produziert worden, in Wirklichkeit aber mit ausgeklügelter Software erstellt wurden.
Deepfakes gibt es schon seit einiger Zeit, und obwohl ihre beliebteste Anwendung bisher darin bestand, die Köpfe berühmter Persönlichkeiten auf die Körper von Schauspielern in Pornofilmen zu kleben, haben sie die Fähigkeit, überzeugendes Filmmaterial von jedem zu produzieren, der alles und überall tut.
In diesem Beitrag werden wir uns Deepfakes ansehen, wie es funktioniert, wie Sie sie selbst erstellen können und vieles mehr.
Also, was ist DeepFake?
Ein Deepfake – eine Kombination aus den Begriffen „Deep Learning“ und „Fake“ – ist ein Stück synthetische Medien bei dem die Ähnlichkeit einer anderen Person verwendet wird, um die einer Person in einem bereits vorhandenen Foto oder Video zu ersetzen.
Deepfakes verwenden ausgeklügelte Techniken des maschinellen Lernens und der künstlichen Intelligenz, um visuelle und akustische Informationen zu modifizieren und zu erstellen, die ein hohes Täuschungspotenzial aufweisen.
Deep-Learning-Methoden wie Autoencoder und Generative Adversarial Networks sind der primäre Mechanismus für die Deepfake-Produktion (GAN).
Diese Modelle werden verwendet, um die Gesichtsemotionen und -bewegungen einer Person zu analysieren und Gesichtsbilder anderer Personen mit vergleichbaren Ausdrücken und Bewegungen zu synthetisieren.
Die Verwendung von Deepfakes in Pornovideos von Prominenten, gefälschten Nachrichten, Scherzen und Finanzbetrug hat beträchtliche Aufmerksamkeit erregt. Sowohl die Industrie als auch die Regierung haben darauf reagiert, indem sie versuchten, sie zu finden und ihre Verwendung einzuschränken.
Bewegungsmodell erster Ordnung
Bei dem Versuch, Deepfakes in der Vergangenheit zu entwickeln, bestand das Problem darin, dass wir eine Art zusätzliches Wissen oder Vorkenntnisse benötigen, damit diese Ansätze funktionieren.
Zur Veranschaulichung sind Gesichtsmarker erforderlich, wenn wir die Kopfbewegung verfolgen möchten. Die Posenschätzung war notwendig, wenn wir Ganzkörperbewegungen abbilden wollten.
Das änderte sich letztes Jahr auf der NeurIPS-Konferenz, als das Forschungsteam der University of Toronto seine Arbeit vorstellte, “Bewegungsmodell erster Ordnung für Bildanimation"
Für diesen Ansatz sind keine weiteren Animationskenntnisse erforderlich. Nachdem dieses Modell trainiert wurde, kann es außerdem für das Transferlernen verwendet und auf alle Elemente angewendet werden, die unter dieselbe Kategorie fallen.
Sehen wir uns die Funktionsweise dieser Methode etwas genauer an. Bewegungsextraktion und -erzeugung bilden die erste Hälfte des gesamten Prozesses. Das Fahrvideo und die Quellenbilder werden als Eingaben verwendet.
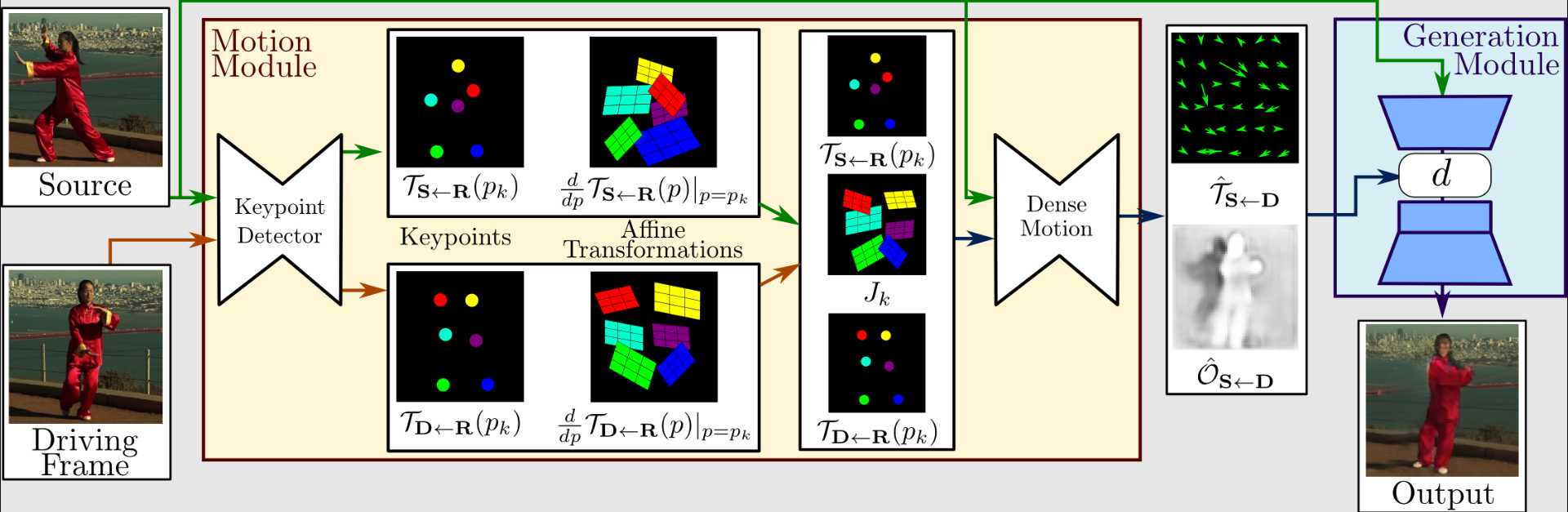
Um eine Bewegungsdarstellung erster Ordnung zu extrahieren, die aus spärlichen Schlüsselpunkten und lokalen affinen Transformationen besteht, verwendet ein Bewegungsextraktor einen Autoencoder, um Schlüsselpunkte zu identifizieren.
Um mit dem dichten Bewegungsnetzwerk einen dichten optischen Fluss und eine Okklusionskarte zu erstellen, werden sie zusammen mit dem Fahrvideo verwendet. Der Generator rendert dann das Zielbild unter Verwendung der Ausgaben aus dem dichten Bewegungsnetzwerk und dem Quellenbild.
Insgesamt schneidet diese Arbeit besser ab als der Stand der Technik. Es enthält auch Funktionen, die andere Modelle einfach nicht haben. Es funktioniert mit mehreren Bildtypen, sodass Sie es auf Bilder von Gesicht, Körper, Cartoons usw. anwenden können, was äußerst großartig ist.
Dadurch ergeben sich viele neue Möglichkeiten. Ein weiterer bahnbrechender Aspekt unserer Strategie ist, dass Sie jetzt mit nur einem Bild des Zielobjekts hochwertige Deepfakes erstellen können, ähnlich wie wir es tun YOLO für Objekt Anerkennung.
Prozess zum Erstellen eines Deepfake-Modells
Für die Generierung von Deepfakes sind drei Prozesse erforderlich: Extrahieren, Trainieren und Erstellen. Die Hauptpunkte jeder dieser Phasen und ihre Beziehung zum Gesamtprozess werden in diesem Abschnitt behandelt.
Extrahierung
Deepfakes verwenden tiefe neuronale Netze, um Gesichter zu ändern, und benötigen viele Daten (Bilder), um korrekt und überzeugend zu funktionieren. Der Extraktionsprozess ist die Phase, in der alle Frames aus Videoclips extrahiert, die Gesichter erkannt und die Gesichter dann ausgerichtet werden, um die Leistung zu maximieren.
Ausbildung
In der Trainingsphase wird die neuronale Netzwerk kann ein Gesicht in ein anderes verwandeln. Je nach Größe des Übungssets und des Trainingsgeräts kann das Training mehrere Stunden oder sogar Tage dauern.
Das Training muss nur einmal abgeschlossen werden, ähnlich wie die meisten anderen neuronalen Netzwerktrainings. Nach dem Training wäre das Model in der Lage, ein Gesicht von Person A zu Person B zu ändern.
von Vorabkalkulationen
Nachdem das Modell trainiert wurde, kann ein Deepfake erstellt werden. Frames werden aus einem Video genommen und dann an allen Gesichtern ausgerichtet. Das trainierte neuronale Netzwerk wird dann verwendet, um jeden Rahmen zu transformieren.
Das transformierte Gesicht muss als letzter Schritt mit dem Originalrahmen zusammengeführt werden.
Erstellen eines Deepfake-Erkennungsmodells
Mounten und Klonen von GitHub Repo
Während der Arbeit bei Colab die GPUs von Google kostenlos nutzen zu können, ist von Vorteil für tiefe Lernen. Ein zusätzlicher Vorteil ist die Möglichkeit, ein Google Drive auf einer virtuellen Cloud-Maschine (VM) bereitzustellen.
Mit einfachem Zugriff auf all seine Sachen wird der Benutzer aktiviert. In diesem Abschnitt finden Sie das Programm, das zum Bereitstellen von Google Drive auf der virtuellen Maschine in der Cloud erforderlich ist.


Module importieren
Jetzt werden wir alle notwendigen Module importieren.
Ausführung des Modells
Wir verwenden ein Beispiel, das ein Standbild von Putin (Quellbild) mit einem Video von Obama kombiniert. Das Ergebnis ist ein Video, in dem Putin mit genau denselben Gesichtsausdrücken spricht und gestikuliert, die Obama beim Autofahren verwendet hat.
Bevor das Ergebnis des Modells angezeigt wird, werden die Medien geladen und die Funktionen deklariert. Checkpoints werden dann geladen und das Modell wird konstruiert. Nach dem Erstellen des Deep Fakes werden zwei verschiedene Animationsstile angezeigt.
Putin wird von Obamas Bewegungen animiert, die relative Keypoint-Verschiebungen nutzen. Die Art und Weise, wie Obamas Gesichtsausdrücke und Körpersprache in seinen Videos schön und klar für Putin dargestellt werden, ist erstaunlich.
Es gibt ein paar mikroskopische Fehler, besonders wenn Obama die Augenbrauen hochzieht und mit den Augen blinzelt. Diese Ausdrücke werden in Putins Rahmen nicht genau repliziert.
Ohne die Deepfake-Kulisse würde der Putin-Film ziemlich glaubwürdig und authentisch erscheinen, wenn er im Fernsehen gesehen würde oder Social Media.
Modellerstellung
Jetzt werden wir die vortrainierten Prüfpunkte verwenden, um ein vollständiges Modell zu erstellen.
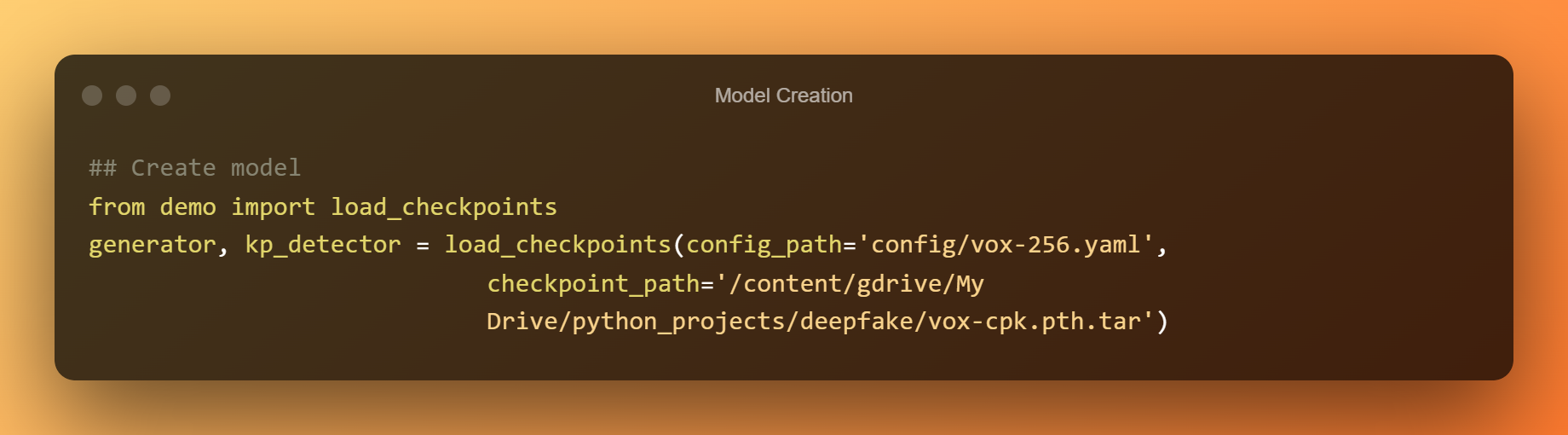
Deepfake-Erkennung
Die relative Eigenpunktverschiebung wird verwendet, um die Elemente in der Zelle darunter zu animieren. Die nächste Zelle verwendet stattdessen absolute Koordinaten, aber alle Objektproportionen werden auf diese Weise aus dem Fahrvideo übernommen.
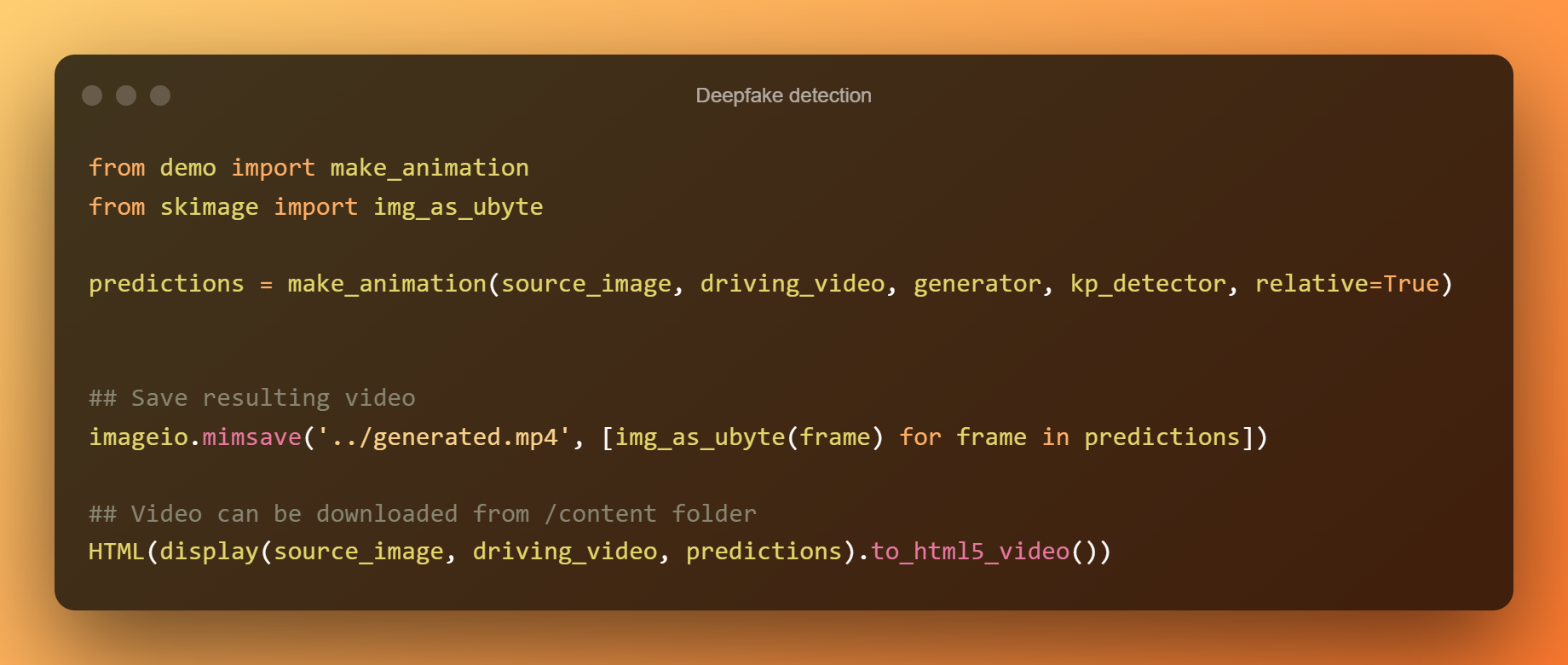
Verbesserung der Ausgabe mit absoluten Koordinaten

Auf diese Weise können Sie eine Deepfake-Erkennung entwickeln.
Was sind die Risiken der Deepfake-Technologie?
Deepfake-Videos sind jetzt aufgrund ihrer Neuheit ansprechend und unterhaltsam anzusehen. Es besteht jedoch ein Risiko, dass unter der Oberfläche dieser scheinbar komischen Technologie außer Kontrolle geraten könnte.
Es wird sicherlich schwierig sein, zwischen gefälschten und echten Videos zu unterscheiden Deepfake-Technologie schreitet weiter voran. Vor allem für prominente Persönlichkeiten und Prominente könnte dies schwerwiegende Folgen haben. Absichtlich böswillige Deepfakes haben das Potenzial, Karrieren und Leben vollständig zu schaden.
Diese könnten von jemandem mit böswilliger Absicht verwendet werden, um für andere auszugeben und ihre Freunde, Verwandten und Kollegen auszunutzen. Sie sind auch in der Lage, weltweite Kontroversen und sogar Kriege auszulösen, indem sie gefälschte Filme ausländischer Führer verwenden.
Zusammenfassung
Zusammenfassend befinden wir uns in einer seltsamen Zeit und einem ungewöhnlichen Umfeld. Mehr denn je ist es einfach, Falschmeldungen und Filme zu produzieren und zu verbreiten. Zu verstehen, was wahr ist und was nicht, wird immer schwieriger.
Heute, so scheint es, können wir uns nicht mehr auf unsere eigenen Sinne verlassen.
Obwohl gefälschte Videodetektoren entwickelt wurden, ist es nur eine Frage der Zeit, bis die Informationslücke so gering ist, dass selbst die besten gefälschten Detektoren nicht feststellen können, ob das Video echt ist oder nicht.





Hinterlassen Sie uns einen Kommentar