Det er en afgørende og ønskværdig opgave inden for computervision og grafik at producere kreative portrætfilm af højeste kaliber.
Selvom der er blevet foreslået flere effektive modeller til portrætbilleder baseret på den potente StyleGAN, har disse billedorienterede teknikker klare ulemper, når de bruges sammen med videoer, såsom den faste billedstørrelse, kravet om ansigtsjustering, fraværet af ikke-ansigtsdetaljer og tidsmæssig inkonsistens.
En revolutionerende VToonify-ramme bruges til at tackle den vanskelige kontrollerede højopløselige portrætvideostiloverførsel.
Vi vil undersøge den seneste undersøgelse om VToonify i denne artikel, herunder dens funktionalitet, ulemper og andre faktorer.
Hvad er Vtoonify?
VToonify-rammen giver mulighed for brugerdefinerbar højopløsnings portrætvideostiltransmission.
VToonify bruger StyleGANs mellem- og højopløsningslag til at skabe kunstneriske portrætter af høj kvalitet baseret på multi-skala indholdskarakteristika hentet af en encoder for at bevare rammedetaljer.
Den resulterende fuldt foldede arkitektur tager ikke-justerede ansigter i film i variabel størrelse som input, hvilket resulterer i hele ansigtsområder med realistiske bevægelser i outputtet.

Denne ramme er kompatibel med nuværende StyleGAN-baserede billedvisningsmodeller, hvilket giver dem mulighed for at blive udvidet til videovisning og arver attraktive egenskaber såsom justerbar farve- og intensitetstilpasning.
Denne studere introducerer to eksemplarer af VToonify baseret på Toonify og DualStyleGAN til henholdsvis samlingsbaseret og eksemplarbaseret portrætvideostiloverførsel.
Omfattende eksperimentelle resultater viser, at den foreslåede VToonify-ramme overgår eksisterende tilgange til at lave højkvalitets, tidsmæssigt sammenhængende kunstneriske portrætfilm med variable stilparametre.
Forskere leverer Google Colab notesbog, så du kan få dine hænder snavsede på den.
Hvordan virker det?
For at opnå justerbar højopløsnings portrætvideostiloverførsel kombinerer VToonify fordelene ved billedoversættelsesrammen med den StyleGAN-baserede ramme.
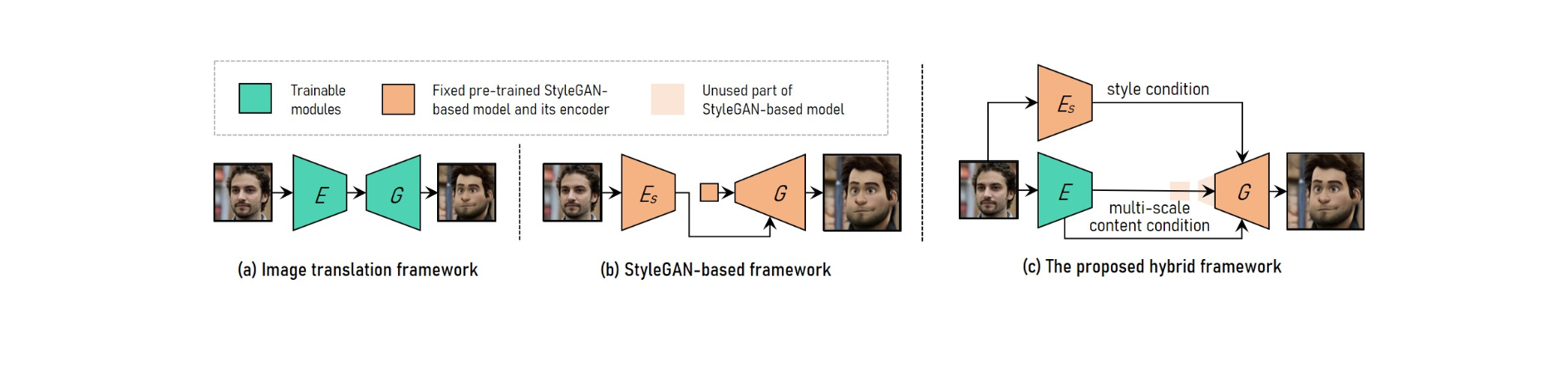
For at imødekomme varierende inputstørrelser anvender billedoversættelsessystemet fuldt foldede netværk. Træning fra bunden gør derimod høj opløsning og kontrolleret stiltransmission umulig.
Den fortrænede StyleGAN-model bruges i den StyleGAN-baserede ramme til høj opløsning og kontrolleret stiloverførsel, selvom den er begrænset til fast billedstørrelse og detaljetab.
StyleGAN er modificeret i hybrid-frameworket ved at slette dens input-funktion med fast størrelse og lav-opløsningslag, hvilket resulterer i en fuldt konvolutionerende encoder-generator-arkitektur svarende til billedoversættelsesrammerne.
For at vedligeholde framedetaljer skal du træne en koder til at udtrække multi-skala indholdskarakteristika for inputframen som et yderligere indholdskrav til generatoren. Vtoonify arver StyleGAN-modellens stilkontrolfleksibilitet ved at sætte den ind i generatoren for at destillere både dens data og model.
Begrænsninger af StyleGAN & Proposed Vtoonify
Kunstneriske portrætter er almindelige i vores daglige liv såvel som i kreative virksomheder såsom kunst, sociale medier avatarer, film, underholdningsreklamer og så videre.
Med udviklingen af dyb læring teknologi, er det nu muligt at skabe kunstneriske portrætter af høj kvalitet fra virkelige ansigtsbilleder ved hjælp af automatiseret overførsel af portrætstil.
Der er en række vellykkede måder skabt til billedbaseret stiloverførsel, hvoraf mange er let tilgængelige for begynderbrugere i form af mobile applikationer. Videomateriale er hurtigt blevet en grundpille i vores sociale medier feeds i løbet af de sidste mange år.
Fremkomsten af sociale medier og flygtige film har øget efterspørgslen efter innovativ videoredigering, såsom overførsel af portrætvideostil, for at generere succesrige og interessante videoer.
Eksisterende billedorienterede teknikker har betydelige ulemper, når de anvendes på film, hvilket begrænser deres anvendelighed i automatiseret portrætvideostilisering.
StyleGAN er en fælles rygrad for udvikling af en portrætbilledstiloverførselsmodel på grund af dens evne til at skabe ansigter af høj kvalitet med justerbar stilstyring.
Et StyleGAN-baseret system (også kendt som billedvisning) koder et rigtigt ansigt ind i StyleGAN's latente rum og anvender derefter den resulterende stilkode til en anden StyleGAN finjusteret på det kunstneriske portrætdatasæt for at skabe en stiliseret version.
StyleGAN skaber billeder med tilpassede ansigter og i en fast størrelse, som ikke favoriserer dynamiske ansigter i optagelser fra den virkelige verden. Ansigtsbeskæring og justering i videoen resulterer nogle gange i et delvist ansigt og akavede bevægelser. Forskere kalder dette problem for StyleGANs 'begrænsning af faste afgrøder.'
Til ujusterede ansigter er StyleGAN3 blevet foreslået; den understøtter dog kun en indstillet billedstørrelse.
Desuden har en nylig undersøgelse opdaget, at kodning af ikke-justerede ansigter er mere udfordrende end justerede ansigter. Forkert ansigtskodning er skadelig for overførsel af portrætstil, hvilket resulterer i problemer som identitetsændring og manglende komponenter i de rekonstruerede og stylede rammer.
Som diskuteret skal en effektiv teknik til overførsel af portrætvideostil håndtere følgende problemer:
- For at bevare realistiske bevægelser skal tilgangen være i stand til at håndtere ujusterede ansigter og varierede videostørrelser. En stor videostørrelse eller en bred synsvinkel kan fange flere oplysninger og samtidig forhindre ansigtet i at bevæge sig ud af billedet.
- For at konkurrere med nutidens almindeligt anvendte HD-gadgets er video i høj opløsning nødvendig.
- Fleksibel stilkontrol bør tilbydes, så brugerne kan ændre og vælge deres valg, når de udvikler et realistisk brugerinteraktionssystem.
Til det formål foreslår forskere VToonify, en ny hybrid ramme til video-toonificering. For at overvinde den faste afgrødebegrænsning studerer forskere først oversættelsesækvivarians i StyleGAN.
VToonify kombinerer fordelene ved den StyleGAN-baserede arkitektur og billedoversættelsesrammerne for at opnå justerbar højopløsnings portrætvideostiloverførsel.
Følgende er de vigtigste bidrag:
- Forskere undersøger StyleGANs faste afgrødebegrænsning og foreslår en løsning baseret på oversættelsesækvivarians.
- Forskere præsenterer et unikt fuldt foldet VToonify-rammeværk til kontrolleret højopløsnings portrætvideostiloverførsel, der understøtter ujusterede ansigter og forskellige videostørrelser.
- Forskere konstruerer VToonify på rygraden af Toonify og DualStyleGAN og kondenserer rygraden med hensyn til både data og model for at muliggøre samlingsbaseret og eksemplarbaseret portrætvideostiloverførsel.
Sammenligning af Vtoonify med andre state-of-the-art modeller
Toonify
Det tjener som grundlaget for samlingsbaseret stiloverførsel på afstemte ansigter ved hjælp af StyleGAN. For at hente stilkoderne skal forskere justere ansigter og beskære 256256 fotos til PSP. Toonify bruges til at generere et stiliseret resultat med 1024*1024 stilkoder.
Til sidst justerer de resultatet i videoen til dets oprindelige placering. Det ikke-stiliserede område er sat til sort.

DualStyleGAN
Det er en rygrad for eksemplarbaseret stiloverførsel baseret på StyleGAN. De bruger de samme data før- og efterbehandlingsteknikker som Toonify.
Pix2pixHD
Det er en billed-til-billede-oversættelsesmodel, der almindeligvis bruges til at kondensere forudtrænede modeller til højopløsningsredigering. Det trænes ved hjælp af parrede data.
Forskere bruger pix2pixHD som dens ekstra instanskortinput, da den bruger udvundet parsingkort.
Første ordens bevægelse
FOM er en typisk billedanimationsmodel. Den blev trænet på 256256 billeder og klarer sig dårligt med andre billedstørrelser. Som en konsekvens skalerer forskere først videoframes til 256*256 for FOM til animation og ændrer derefter resultaterne til deres oprindelige størrelse.
For en retfærdig sammenligning anvender FOM den første stiliserede ramme af sin tilgang som sit referencestilbillede.
DaGAN
Det er en 3D-ansigtsanimationsmodel. De bruger de samme dataforberedelse og efterbehandlingsmetoder som FOM.

Fordele
- Det kan bruges i kunsten, avatarer på sociale medier, film, underholdningsreklamer og så videre.
- Vtoonify kan også bruges i metaverset.
Begrænsninger
- Denne metodologi udtrækker både dataene og modellen fra de StyleGAN-baserede backbones, hvilket resulterer i data- og modelbias.
- Artefakterne er hovedsagelig forårsaget af størrelsesforskelle mellem det stiliserede ansigtsområde og de andre sektioner.
- Denne strategi er mindre vellykket, når man beskæftiger sig med ting i ansigtsregionen.
Konklusion
Endelig er VToonify en ramme til stilstyret video-tonification i høj opløsning.
Denne ramme opnår stor ydeevne i håndtering af videoer og muliggør bred kontrol over den strukturelle stil, farvestil og stilgrad ved at kondensere StyleGAN-baserede billedtoneringsmodeller med hensyn til både deres syntetiske data og netværksstrukturer.





Giv en kommentar