Indholdsfortegnelse[Skjule][At vise]
Vi kan nu beregne rummets vidde og de små forviklinger af subatomære partikler takket være computere.
Computere slår mennesker, når det kommer til at tælle og regne, såvel som at følge logiske ja/nej-processer, takket være elektroner, der rejser med lysets hastighed via dets kredsløb.
Men vi ser dem ikke ofte som "intelligente", da computere tidligere ikke kunne udføre noget uden at blive undervist (programmeret) af mennesker.
Machine learning, herunder deep learning og kunstig intelligens, er blevet et buzzword i videnskabelige og teknologiske overskrifter.
Maskinlæring ser ud til at være allestedsnærværende, men mange mennesker, der bruger ordet, ville kæmpe for at definere, hvad det er, hvad det gør, og hvad det bedst bruges til.
Denne artikel søger at tydeliggøre maskinlæring og samtidig give konkrete eksempler fra den virkelige verden på, hvordan teknologien fungerer for at illustrere, hvorfor den er så gavnlig.
Derefter vil vi se på de forskellige maskinlæringsmetoder og se, hvordan de bliver brugt til at løse forretningsmæssige udfordringer.
Til sidst vil vi konsultere vores krystalkugle for nogle hurtige forudsigelser om fremtiden for maskinlæring.
Hvad er maskinlæring?
Maskinlæring er en disciplin inden for datalogi, der gør det muligt for computere at udlede mønstre fra data uden at blive undervist i, hvad disse mønstre er.
Disse konklusioner er ofte baseret på brug af algoritmer til automatisk at vurdere de statistiske træk ved dataene og udvikling af matematiske modeller til at skildre forholdet mellem forskellige værdier.
Sammenlign dette med klassisk databehandling, som er baseret på deterministiske systemer, hvor vi eksplicit giver computeren et sæt regler, som den skal følge for at udføre en bestemt opgave.
Denne måde at programmere computere på er kendt som regelbaseret programmering. Maskinlæring adskiller sig fra og overgår regelbaseret programmering ved, at den kan udlede disse regler på egen hånd.
Antag, at du er en bankdirektør, der ønsker at afgøre, om en låneansøgning vil mislykkes på deres lån.
I en regelbaseret metode vil bankdirektøren (eller andre specialister) udtrykkeligt informere computeren om, at hvis ansøgerens kreditscore er under et vist niveau, skal ansøgningen afvises.
Et maskinlæringsprogram vil imidlertid blot analysere tidligere data om kundernes kreditvurderinger og låneresultater og bestemme, hvad denne tærskel skal være alene.
Maskinen lærer af tidligere data og opretter sine egne regler på denne måde. Dette er selvfølgelig kun en primer om maskinlæring; virkelige maskinlæringsmodeller er væsentligt mere komplicerede end en grundlæggende tærskel.
Ikke desto mindre er det en fremragende demonstration af potentialet ved maskinlæring.
Hvordan fungerer en maskine lære?
For at gøre tingene enkle, "lærer" maskiner ved at detektere mønstre i sammenlignelige data. Betragt data som information, som du indsamler fra omverdenen. Jo mere data en maskine tilføres, jo "smartere" bliver den.
Men ikke alle data er ens. Antag, at du er en pirat med et livsformål at afdække de begravede rigdomme på øen. Du vil have en betydelig mængde viden for at finde præmien.
Denne viden kan ligesom data enten tage dig på den rigtige eller forkerte måde.
Jo større information/data indsamlet, jo mindre uklarhed er der, og omvendt. Som følge heraf er det afgørende at overveje, hvilken slags data du fodrer din maskine for at lære af.
Men når en væsentlig mængde data er leveret, kan computeren foretage forudsigelser. Maskiner kan forudse fremtiden, så længe den ikke afviger meget fra fortiden.
Maskiner "lærer" ved at analysere historiske data for at bestemme, hvad der sandsynligvis vil ske.
Hvis de gamle data ligner de nye data, så vil de ting, du kan sige om de tidligere data, sandsynligvis gælde for de nye data. Det er, som om du ser tilbage for at se fremad.
Hvilke typer maskinlæring er der?
Algoritmer til maskinlæring klassificeres ofte i tre brede typer (selvom andre klassifikationsskemaer også bruges):
- Overvåget læring
- Uovervåget læring
- Forstærkning læring
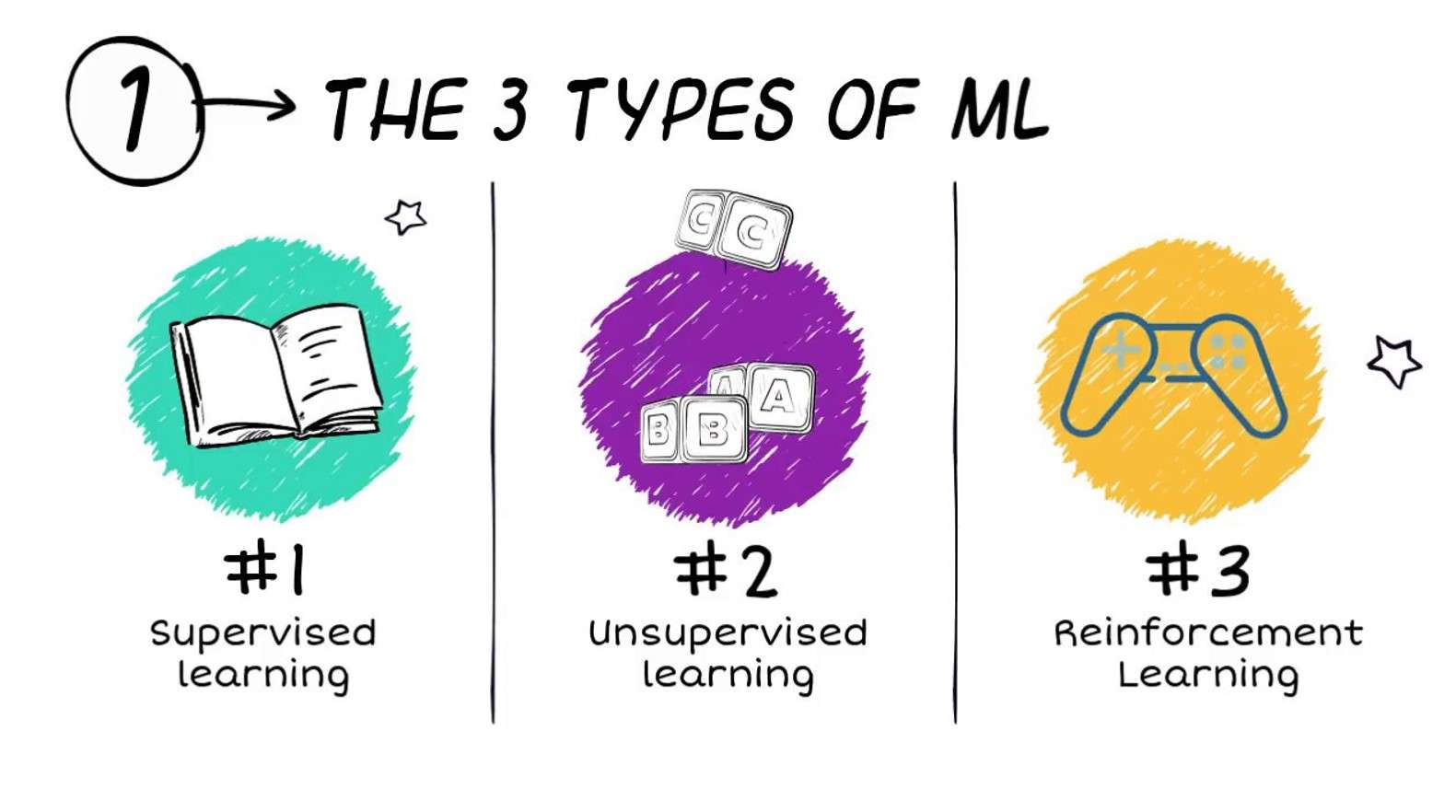
Overvåget læring
Overvåget maskinlæring refererer til teknikker, hvor maskinlæringsmodellen får en samling af data med eksplicitte etiketter for mængden af interesse (denne mængde omtales ofte som responsen eller målet).
For at træne AI-modeller anvender semi-overvåget læring en blanding af mærkede og umærkede data.
Hvis du arbejder med umærkede data, skal du foretage nogle datamærkninger.
Mærkning er processen med at mærke prøver for at hjælpe med træne en maskinlæring model. Mærkning udføres primært af mennesker, hvilket kan være dyrt og tidskrævende. Der er dog teknikker til at automatisere mærkningsprocessen.
Den låneansøgningssituation, vi diskuterede før, er en glimrende illustration af superviseret læring. Vi havde historiske data vedrørende tidligere låneansøgeres kreditvurderinger (og måske indkomstniveauer, alder og så videre) samt specifikke etiketter, der fortalte os, om den pågældende person misligholdt deres lån eller ej.
Regression og klassificering er to undergrupper af overvågede læringsteknikker.
- Klassifikation – Det gør brug af en algoritme til at kategorisere data korrekt. Spamfiltre er et eksempel. "Spam" kan være en subjektiv kategori - grænsen mellem spam og ikke-spam kommunikation er sløret - og spamfilteralgoritmen forfiner sig konstant afhængigt af din feedback (hvilket betyder e-mail, som mennesker markerer som spam).
- Regression – Det er nyttigt til at forstå sammenhængen mellem afhængige og uafhængige variable. Regressionsmodeller kan forudsige numeriske værdier baseret på flere datakilder, såsom salgsindtægtsestimater for en bestemt virksomhed. Lineær regression, logistisk regression og polynomiel regression er nogle fremtrædende regressionsteknikker.
Uovervåget læring
I uovervåget læring får vi umærkede data og leder bare efter mønstre. Lad os lade som om, du er Amazon. Kan vi finde nogen klynger (grupper af lignende forbrugere) baseret på kundens købshistorik?
Selvom vi ikke har eksplicitte, afgørende data om en persons præferencer, i dette tilfælde, ved blot at vide, at et bestemt sæt af forbrugere køber sammenlignelige varer, kan vi komme med købsforslag baseret på, hvad andre personer i klyngen også har købt.
Amazons "du kan også være interesseret i"-karrusel er drevet af lignende teknologier.
Uovervåget læring kan gruppere data gennem clustering eller association, afhængigt af hvad du vil gruppere sammen.
- klyngedannelse – Uovervåget læring forsøger at overvinde denne udfordring ved at søge efter mønstre i dataene. Hvis der er en lignende klynge eller gruppe, vil algoritmen kategorisere dem på en bestemt måde. At forsøge at kategorisere kunder baseret på tidligere købshistorik er et eksempel på dette.
- Association – Uovervåget læring forsøger at tackle denne udfordring ved at forsøge at forstå de regler og betydninger, der ligger til grund for forskellige grupper. Et hyppigt eksempel på et associeringsproblem er at fastslå en sammenhæng mellem kundekøb. Butikker kan være interesserede i at vide, hvilke varer der blev købt sammen, og kan bruge disse oplysninger til at arrangere placeringen af disse produkter for nem adgang.
Forstærkningslæring
Forstærkende læring er en teknik til at undervise i maskinlæringsmodeller til at træffe en række målorienterede beslutninger i interaktive omgivelser. De ovennævnte spilbrugstilfælde er fremragende illustrationer af dette.
Du behøver ikke indtaste AlphaZero tusindvis af tidligere skakspil, hver med et "godt" eller "dårligt" træk mærket. Du skal blot lære det spillets regler og målet, og lad det derefter prøve tilfældige handlinger.
Positiv forstærkning gives til aktiviteter, der bringer programmet tættere på målet (såsom at udvikle en solid bondeposition). Når handlinger har den modsatte effekt (såsom at skifte kongen for tidligt), får de negativ forstærkning.
Softwaren kan i sidste ende mestre spillet ved hjælp af denne metode.
Forstærkning læring bruges i vid udstrækning inden for robotteknologi til at lære robotter til komplicerede og svære at konstruere handlinger. Det bruges nogle gange i forbindelse med vejinfrastruktur, såsom trafiksignaler, for at forbedre trafikstrømmen.
Hvad kan man gøre med maskinlæring?
Brugen af maskinlæring i samfundet og industrien resulterer i fremskridt inden for en bred vifte af menneskelige bestræbelser.
I vores daglige liv styrer maskinlæring nu Googles søge- og billedalgoritmer, hvilket giver os mulighed for at blive mere præcist matchet med den information, vi har brug for, når vi har brug for dem.
Inden for medicin anvendes maskinlæring for eksempel på genetiske data for at hjælpe læger med at forstå og forudsige, hvordan kræft spredes, hvilket giver mulighed for at udvikle mere effektive terapier.
Data fra det dybe rum bliver indsamlet her på Jorden via massive radioteleskoper - og efter at være blevet analyseret med maskinlæring hjælper det os med at opklare mysterierne om sorte huller.
Maskinlæring i detailhandlen forbinder købere med ting, de ønsker at købe online, og hjælper også butiksmedarbejdere med at skræddersy den service, de leverer til deres kunder i den fysiske verden.
Maskinlæring bruges i kampen mod terror og ekstremisme for at forudse adfærden hos dem, der ønsker at såre de uskyldige.
Naturlig sprogbehandling (NLP) refererer til processen med at tillade computere at forstå og kommunikere med os på menneskeligt sprog gennem maskinlæring, og det har resulteret i gennembrud inden for oversættelsesteknologi såvel som de stemmestyrede enheder, vi i stigende grad bruger hver dag, som f.eks. Alexa, Google dot, Siri og Google Assistant.
Uden tvivl viser maskinlæring, at det er en transformationsteknologi.
Robotter, der er i stand til at arbejde sammen med os og booste vores egen originalitet og fantasi med deres fejlfri logik og overmenneskelige hastighed, er ikke længere en science fiction-fantasi – de er ved at blive en realitet i mange sektorer.
Machine Learning-brugstilfælde
1. Cybersecurity
Efterhånden som netværk er blevet mere komplicerede, har cybersikkerhedsspecialister arbejdet utrætteligt på at tilpasse sig det stadigt voksende udvalg af sikkerhedstrusler.
At imødegå hastigt udviklende malware og hacking-taktik er udfordrende nok, men udbredelsen af Internet of Things (IoT)-enheder har fundamentalt transformeret cybersikkerhedsmiljøet.
Angreb kan forekomme når som helst og hvor som helst.
Heldigvis har maskinlæringsalgoritmer gjort det muligt for cybersikkerhedsoperationer at følge med i denne hurtige udvikling.
Forudsigelig analyse muliggør hurtigere registrering og afbødning af angreb, mens maskinlæring kan analysere din aktivitet inde i et netværk for at opdage abnormiteter og svagheder i eksisterende sikkerhedsmekanismer.
2. Automatisering af kundeservice
Håndtering af et stigende antal onlinekundekontakter har belastet meget organisation.
De har simpelthen ikke nok kundeservicepersonale til at håndtere mængden af forespørgsler, de modtager, og den traditionelle tilgang med at outsource spørgsmål til en kontaktcenter er bare uacceptabelt for mange af nutidens kunder.
Chatbots og andre automatiserede systemer kan nu imødekomme disse krav takket være fremskridt inden for maskinlæringsteknikker. Virksomheder kan frigøre personale til at udføre mere kundesupport på højt niveau ved at automatisere hverdagsagtige og lavt prioriterede aktiviteter.
Når det bruges korrekt, kan maskinlæring i erhvervslivet hjælpe med at strømline problemløsning og give forbrugerne den form for hjælpsom support, der gør dem til engagerede brandmestre.
3. kommunikation
At undgå fejl og misforståelser er afgørende i enhver form for kommunikation, men mere i nutidens virksomhedskommunikation.
Simple grammatiske fejl, forkert tone eller fejlagtige oversættelser kan forårsage en række vanskeligheder i forbindelse med e-mail-kontakt, kundeevalueringer, videokonference, eller tekstbaseret dokumentation i mange former.
Maskinlæringssystemer har avanceret kommunikation langt ud over Microsofts Clippys berusende dage.
Disse maskinlæringseksempler har hjulpet enkeltpersoner med at kommunikere enkelt og præcist ved at bruge naturlig sprogbehandling, sprogoversættelse i realtid og talegenkendelse.
Mens mange enkeltpersoner ikke kan lide autokorrektionsfunktioner, værdsætter de også at blive beskyttet mod pinlige fejl og ukorrekt tone.
4. Objektgenkendelse
Mens teknologien til at indsamle og fortolke data har eksisteret i et stykke tid, har det vist sig at være en vildledende vanskelig opgave at lære computersystemer at forstå, hvad de ser på.
Objektgenkendelsesfunktioner føjes til et stigende antal enheder på grund af maskinlæringsapplikationer.
En selvkørende bil genkender f.eks. en anden bil, når den ser en, selvom programmører ikke gav den et nøjagtigt eksempel på den bil, der skal bruges som reference.
Denne teknologi bliver nu brugt i detailvirksomheder for at hjælpe med at fremskynde betalingsprocessen. Kameraer identificerer produkterne i forbrugernes vogne og kan automatisk fakturere deres konti, når de forlader butikken.
5. Digital markedsføring
Meget af nutidens markedsføring foregår online ved hjælp af en række digitale platforme og softwareprogrammer.
Efterhånden som virksomheder indsamler oplysninger om deres forbrugere og deres købsadfærd, kan marketingteams bruge disse oplysninger til at opbygge et detaljeret billede af deres målgruppe og opdage, hvilke personer der er mere tilbøjelige til at opsøge deres produkter og tjenester.
Maskinlæringsalgoritmer hjælper marketingfolk med at give mening ud af alle disse data ved at opdage væsentlige mønstre og egenskaber, der giver dem mulighed for nøje at kategorisere muligheder.
Den samme teknologi muliggør stor digital marketingautomatisering. Annoncesystemer kan konfigureres til at opdage nye potentielle forbrugere dynamisk og levere relevant marketingindhold til dem på det rigtige tidspunkt og sted.
Fremtiden for maskinlæring
Maskinlæring vinder helt sikkert popularitet, efterhånden som flere virksomheder og store organisationer bruger teknologien til at tackle specifikke udfordringer eller sætte gang i innovation.
Denne fortsatte investering demonstrerer en forståelse af, at maskinlæring producerer ROI, især gennem nogle af de ovennævnte etablerede og reproducerbare use cases.
Når alt kommer til alt, hvis teknologien er god nok til Netflix, Facebook, Amazon, Google Maps og så videre, er chancerne for, at den også kan hjælpe din virksomhed med at få mest muligt ud af sine data.
Som nyt machine learning modeller udvikles og lanceres, vil vi opleve en stigning i antallet af applikationer, der vil blive brugt på tværs af brancher.
Dette sker allerede med ansigtsgenkendelse, som engang var en ny funktion på din iPhone, men som nu implementeres i en lang række programmer og applikationer, især dem, der er relateret til offentlig sikkerhed.
Nøglen for de fleste organisationer, der prøver at komme i gang med maskinlæring, er at se forbi de lyse futuristiske visioner og opdage de reelle forretningsmæssige udfordringer, som teknologien kan hjælpe dig med.
Konklusion
I den post-industrialiserede tidsalder har videnskabsmænd og fagfolk forsøgt at skabe en computer, der opfører sig mere som mennesker.
Tænkemaskinen er AI's mest betydningsfulde bidrag til menneskeheden; den fænomenale ankomst af denne selvkørende maskine har hurtigt ændret virksomhedens driftsregler.
Selvkørende køretøjer, automatiserede assistenter, selvstændige produktionsmedarbejdere og smarte byer har på det seneste demonstreret levedygtigheden af smarte maskiner. Maskinlæringsrevolutionen og fremtiden for maskinlæring vil være med os i lang tid.





Giv en kommentar