Indholdsfortegnelse[Skjule][At vise]
Store tekst-til-billede-modeller gjorde et betydeligt fremskridt i udviklingen af AI ved at producere højkvalitets og diversificeret billedsyntese fra en given tekstprompt.
Disse modeller er ude af stand til at syntetisere unikke repræsentationer af emner i forskellige indstillinger eller at replikere udseendet af emner i et givet referencesæt.
Nyudgivne teknologier som OpenAI's DALL.E2 eller StabilityAI's Stabil diffusion og Midjourney tager allerede internettet med storm. Det er nu tid til at tilpasse resultaterne. Men hvordan?
Google DreamBooth AI er ankommet.
DreamBooth har evnen til at genkende emnet for et billede, dekonstruere det fra dets oprindelige kontekst og derefter præcist syntetisere det til en ny ønsket kontekst. Derudover kan den bruges med nuværende AI-billedgeneratorer.
I denne artikel vil vi tage et dybt kig på DreamBooth, dens brug, dens vejledning, dens begrænsninger og meget mere.
Hvad er Dreambooth?
drømmekabine, en helt ny tekst-til-billede spredningsmodel, blev præsenteret af Google. En skriftlig prompt kan bruges som vejledning af Google DreamBooth AI til at generere en bred vifte af billeder af brugerens valgte emne i forskellige indstillinger.
En forskergruppe fra Boston University og Google udviklede DreamBooth, en banebrydende teknik til at ændre tekst-til-billede-modeller, der har gennemgået omfattende fortræning.
Det overordnede koncept er ret ligetil: de ønsker at øge sprog-vision-ordbogen, således at ualmindelige token-id'er er forbundet med brugerdefinerede emner, som brugerne kan definere.
Hovedmålet med modellen er at forbinde brugere med tekst-til-billede spredningsmodel ved at give dem de ressourcer, de har brug for til at producere fotorealistiske repræsentationer af forekomsterne af deres udvalgte emne.
Som en konsekvens ser denne teknik ud til at fungere godt til at opsummere udfordringer i en række situationer.
Googles DreamBooth adskiller sig fra tidligere tekst-til-billede værktøjer, som f.eks DALL-E2, Stabil diffusionog midt på rejsen, idet det giver brugerne mere kontrol over emnebilledet, før de lader dem manipulere diffusionsmodellen ved hjælp af tekstbaserede input.
Funktionalitet
- DreamBooth AI kan muligvis forbedre en tekst-til-billede-model med 3-5 billeder.
- Originale fotorealistiske billeder kan oprettes med DreamBooth AI.
- Derudover kan DreamBooth AI skabe billeder af et emne fra flere vinkler.
Anvendelse
Kunstgengivelser
Denne opgave adskiller sig specifikt fra stiloverførsel, som bevarer semantikken i kildescenen, mens stilen fra et andet billede inkorporeres i den originale scene.

Baseret på den kreative tilgang kan AI'en udføre betydelige sceneændringer, samtidig med at identifikations- og emneforekomstens detaljer bevares.
Ejendomsændring
Emneforekomstens karakteristika kan ændres af DreamBooth AI.

Accessorisering
Det stærke kompositoriske forud for generationsmodellen er det, der gør DreamBooth AI's evne til at pryde objekter så interessant.

Rekontekstualisering
DreamBooth AI kan producere karakteristiske billeder for en bestemt emneforekomst ved at give en trænet model en sætning, der inkluderer den unikke identifikator og klassens navneord.

Det kan generere motivet i unikke, hidtil uhørte stillinger, artikulationer og scenestruktur i stedet for at ændre omgivelserne. Realistiske refleksioner og skygger, samt interaktioner mellem motivet og omgivende objekter.
Dreambooth tutorial
I denne tutorial vil vi følge Google Collab notesbog, og jeg vil lede dig igennem det, hvilket vil få dig til at forstå og bruge det på egen hånd.
Opsætning af GPU og installation af biblioteker
At finde ud af, hvilke GPU- og VRAM-typer der er tilgængelige, er det første skridt. Det er også nødvendigt at installere nogle få krav og afhængigheder. Tryk blot på afspilningsknappen, og vent derefter på, at det er færdigt.
Opret en konto på Huggingface og generer et token
Det næste trin er at tilmelde dig en Huggingface-konto. Når du er færdig, skal du klikke på indstillinger i øverste højre hjørne. Du kommer på næste side.
Opret token og navn som anmodet herfra. Tokenet skal kopieres og indsættes i Google-samarbejdet i cellen nedenfor.

Installer xformers
I denne fase kan du blot trykke på afspilningsknappen for at installere xformers ved at klikke på runtime.
Opret forbindelse til Drev
Nu skal du bare køre denne celle for at oprette forbindelse til Google Drive.
Indtast prompten
I den følgende celle skal du blot indtaste prompten.
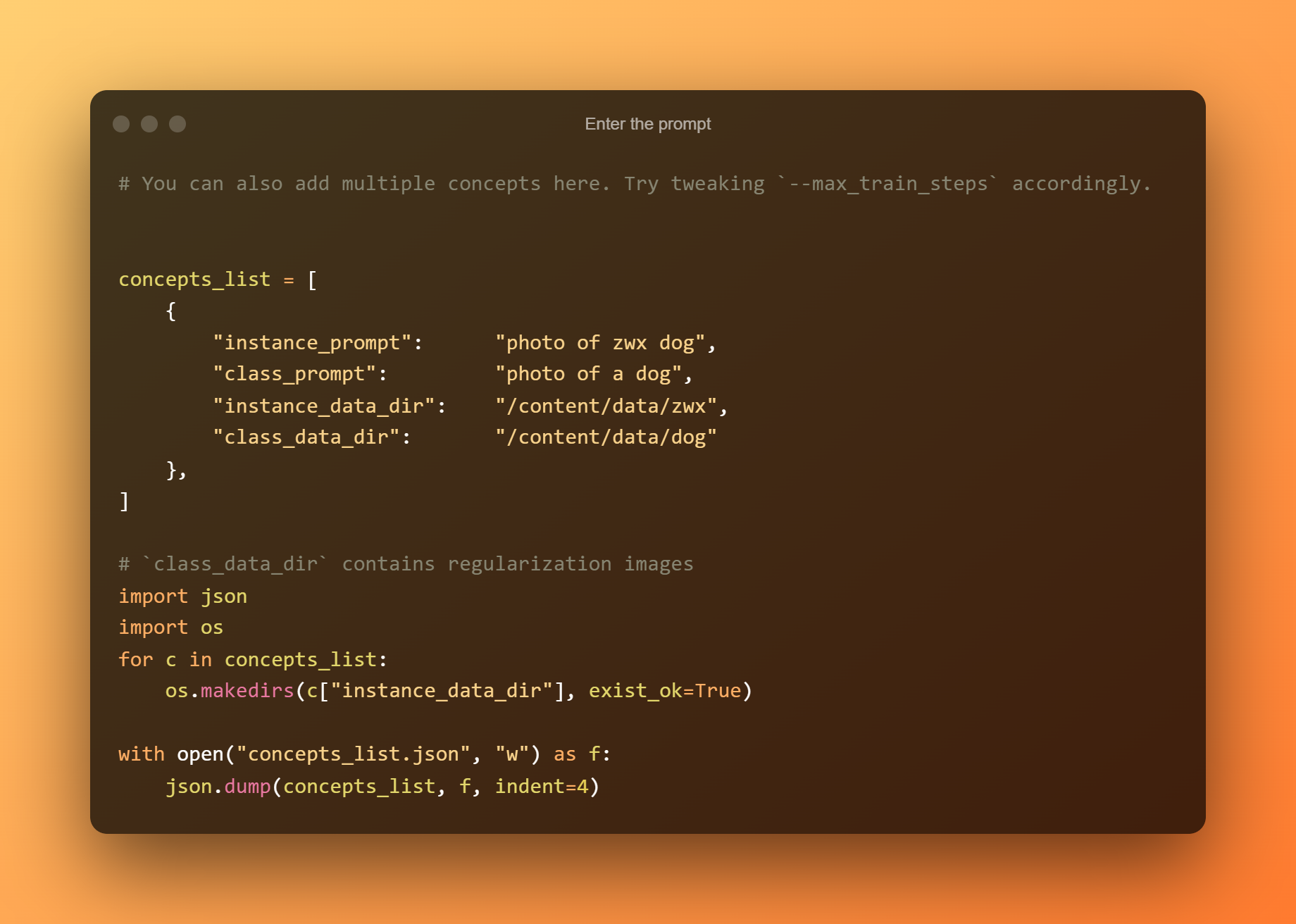
Upload af billeder
I dette trin skal du blot uploade de billeder, du ville træne.

Træn AI-model
Dette er den vigtigste fase, da du vil bruge DreamBooth til at træne en ny AI-model baseret på alle dine indsendte referencebilleder. Du skal begrænse din opmærksomhed til to inputfelter. "—instance prompt" er den første parameter. Du skal angive et meget tydeligt navn her.
Argumentet '–concept list' er det andet kritiske inputfelt. Den skal omdøbes, så den matcher den, der blev brugt i afsnittet 'Skift prompt'.
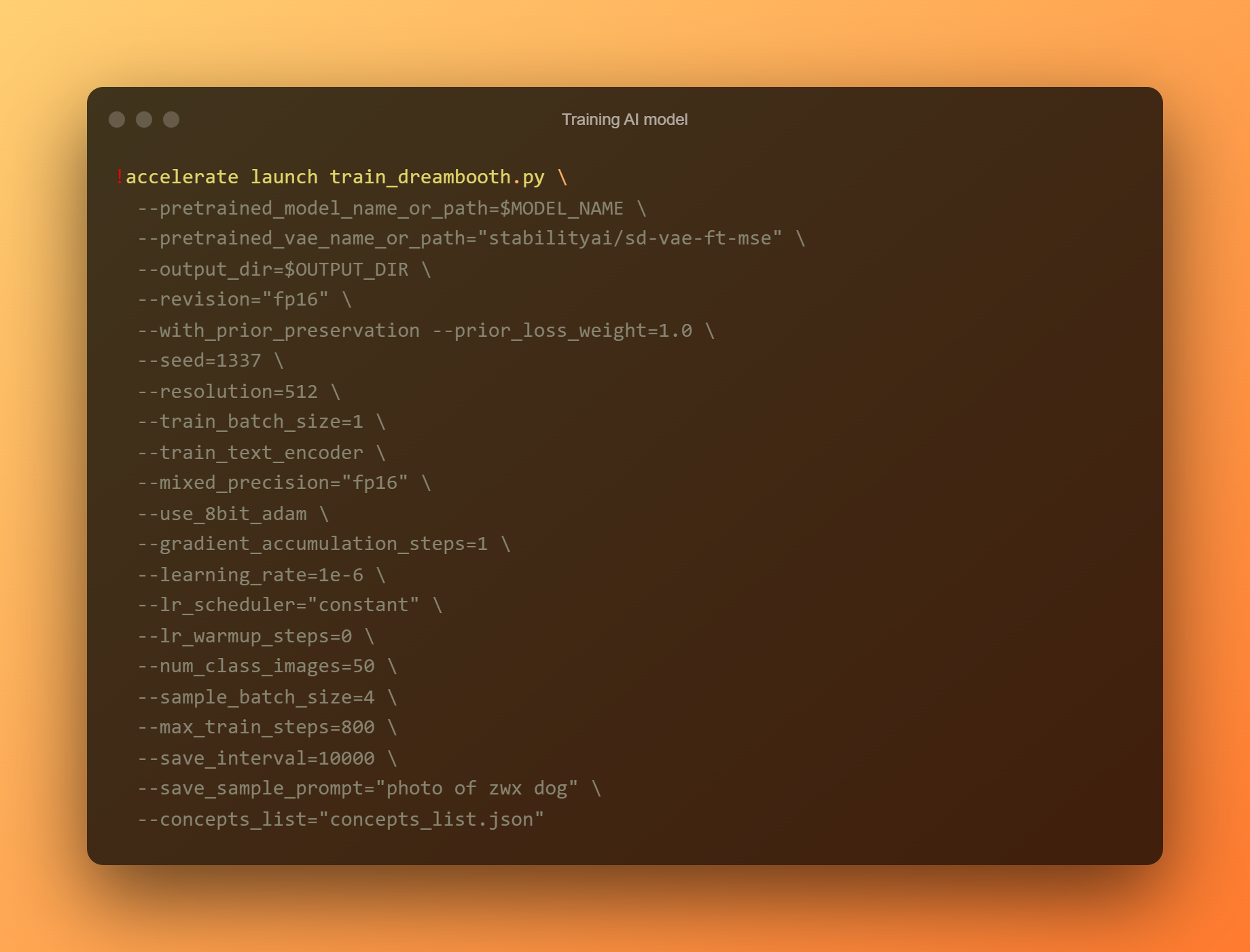
Generer AI-billeder
AI-billederne vil blive oprettet på dette trin, hvor du kan indtaste tekstinstruktionerne.

Dreambooth-begrænsninger
- Kommandoprompten bliver en barriere for at lave gentagelser i emnet med høje detaljeringsgrader. DreamBooth kan ændre emnets kontekst, men hvis modellen ønsker at ændre emnet selv, er der problemer med rammen.
- Et andet problem er overtilpasning af outputbilledet til inputbilledet. Hvis der ikke er nok billeder, kommer emnet muligvis ikke i betragtning eller kan blandes med konteksten af de indsendte billeder. Når der spørges om en kontekst for en ulige generation, sker det samme.
Konklusion
For at producere output fra et enkelt tekstinput kræver hovedparten af tekst-til-billede-modeller millioner af parametre og biblioteker.
DreamBooth forenkler indhentning og brug af indhold for forbrugere ved kun at kræve input fra tre til fem emnefotografier sammen med en tekstmæssig baggrund.





Giv en kommentar