Indholdsfortegnelse[Skjule][At vise]
Det er ikke nyt at have falske billeder og videoer. Siden den udbredte brug af internettet har enkeltpersoner skabt forfalskninger beregnet til at narre eller underholde, lige siden der har været billeder og film.
Der er dog en ny type maskinproducerede forfalskninger, der en dag kan gøre det svært for os at skelne virkelighed fra fiktion.
Disse forfalskninger adskiller sig fra de simple billedmanipulationer, der genereres af redigeringssoftware som Photoshop eller fortidens klogt manipulerede film.
Deepfakes er det mest kendte eksempel på "syntetiske medier" - billeder, lyde og videoer, der ser ud til at være produceret ved hjælp af konventionelle metoder, men som virkelig er lavet ved hjælp af sofistikeret software.
Deepfakes har eksisteret i et stykke tid, og selvom deres mest populære applikation til dato har været at sætte hovedet på kendte personer på kroppen af skuespillere i pornografiske film, har de evnen til at producere overbevisende optagelser af enhver, der gør hvad som helst, hvor som helst.
I dette indlæg vil vi se på Deepfakes, hvordan det virker, hvordan du kan generere dem på egen hånd og meget mere.
Så hvad er DeepFake?
En deepfake - en kombination af sætningerne deep learning og fake - er et stykke af syntetiske medier hvor en anden persons lighed bruges til at erstatte en persons lighed i et allerede eksisterende fotografi eller video.
Deepfakes anvender sofistikeret maskinlæring og kunstig intelligens-teknikker til at ændre og skabe visuel og lydinformation, der har et stort potentiale for bedrag.
Dyb læringsmetoder som autoencodere og generative modstridende netværk er den primære mekanisme for deepfake-produktion (GAN).
Disse modeller bruges til at analysere en persons ansigtsfølelser og bevægelser og syntetisere ansigtsbilleder af andre mennesker, der udviser sammenlignelige udtryk og bevægelser.
Brugen af deepfakes i berømthedspornografiske videoer, falske nyheder, fup og økonomisk bedrageri har tiltrukket sig betydelig opmærksomhed. Både industrien og regeringen har reageret ved at forsøge at finde dem og begrænse deres brug.
Første ordens bevægelsesmodel
Når vi forsøgte at udvikle dybe forfalskninger i fortiden, var problemet, at vi har brug for en form for ekstra viden, eller forudsætninger, for at disse tilgange kan fungere.
Som en illustration kræves ansigtsmarkører, hvis vi ønsker at spore hovedbevægelser. Pose-estimering var nødvendig, hvis vi ønskede at kortlægge hele kroppens bevægelse.
Det ændrede sig på NeurIPS-konferencen sidste år, da forskerholdet fra University of Toronto præsenterede deres arbejde, "First Order Motion Model til billedanimation".
Ingen yderligere viden om animation er nødvendig for denne tilgang. Derudover, efter at denne model er blevet trænet, kan den bruges til overførselslæring og anvendes på ethvert emne, der falder ind under samme kategori.
Lad os se på denne metodes drift lidt længere. Motion Extraction and Generation udgør den første halvdel af hele processen. Kørevideoen og kildebillederne bruges som input.
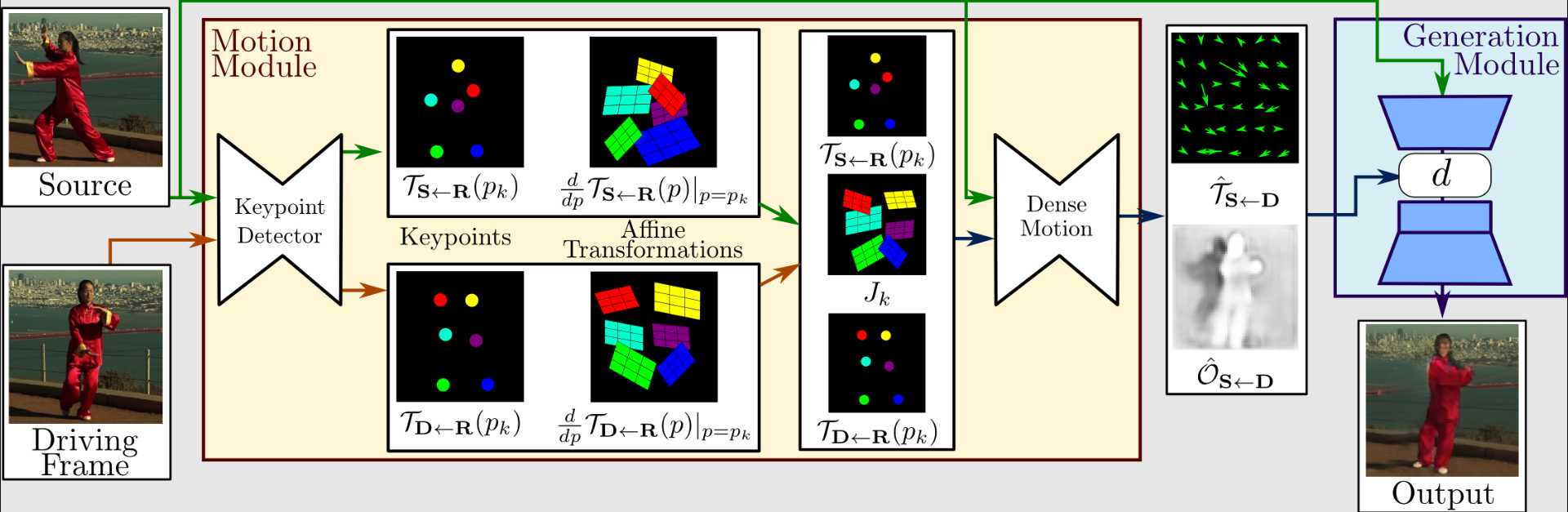
For at udtrække første-ordens bevægelsesrepræsentation, som består af sparsomme nøglepunkter og lokale affine transformationer, bruger en bevægelsesudtrækker en autoencoder til at identificere nøglepunkter.
For at skabe et tæt optisk flow og okklusionskort med det tætte bevægelsesnetværk anvendes de sammen med drivende video. Generatoren gengiver derefter målbilledet ved hjælp af output fra det tætte bevægelsesnetværk og kildebilledet.
Overordnet set præsterer dette arbejde bedre end det nyeste. Den indeholder også funktioner, som andre modeller bare ikke har. Det virker på flere billedtyper, så du kan anvende det på billeder af ansigt, krop, tegnefilm osv., hvilket er ekstremt fantastisk.
Det skabes mange nye muligheder. Et andet banebrydende aspekt af vores strategi er, at den nu giver dig mulighed for at producere højkvalitets Deepfakes ved hjælp af kun ét billede af målobjektet, svarende til hvordan vi gør med YOLO for objekt anerkendelse.
Processen med at skabe Deepfake-model
Tre processer er nødvendige for deepfake-generering: udvinding, træning og skabelse. Hovedpunkterne i hver af disse stadier og hvordan de relaterer til den overordnede proces vil blive dækket i dette afsnit.
Ekstraktion
Deepfakes bruger dybe neurale netværk til at ændre ansigter og har brug for en masse data (billeder) for at fungere korrekt og overbevisende. Udtrækningsprocessen er det stadie, hvor alle frames fra videoklip udtrækkes, ansigterne genkendes, og ansigterne derefter justeres for at maksimere ydeevnen.
Kurser
I træningsfasen er neurale netværk kan ændre et ansigt til et andet. Afhængig af størrelsen på træningssættet og træningsgadgetten kan træningen tage flere timer eller endda dage.
Uddannelsen skal blot afsluttes én gang, ligesom de fleste andre neurale netværkstræninger. Efter træning vil modellen være i stand til at ændre et ansigt fra person A til person B.
Creation
Efter at modellen er blevet trænet, kan der blive produceret en deepfake. Frames tages fra en video og justeres derefter til alle ansigter. Det trænede neurale netværk bruges derefter til at transformere hver frame.
Det transformerede ansigt skal flettes sammen med den originale ramme som sidste trin.
Opbygning af Deepfake Detection Model
Montering og kloning af GitHub Repo
Det er en fordel at kunne bruge Googles GPU'er gratis, mens du arbejder hos Colab dyb læring. En yderligere fordel er muligheden for at montere et Google Drev på en virtuel cloud-maskine (VM).
Med nem adgang til alle sine ting er brugeren aktiveret. Det nødvendige program for at montere Google Drev til den virtuelle maskine i skyen findes i dette afsnit.


Import af moduler
Nu vil vi importere alle de nødvendige moduler.
Udførelse af modellen
Vi vil bruge et eksempel, der kombinerer et stillbillede af Putin (kildebillede) med en video af Obama. Resultatet er en video af Putin, der taler og gestikulerer med nøjagtig de samme ansigtsudtryk, som Obama brugte, mens han kørte.
Inden resultatet af modellen vises, vil mediet blive indlæst, og funktionerne vil blive erklæret. Checkpoints vil derefter blive læsset og modellen vil blive konstrueret. Efter oprettelse af den dybe falske vil to forskellige stilarter af animation blive vist.
Putin er animeret af Obamas bevægelser ved at bruge relativ nøglepunktsforskydning. Den måde, Obamas ansigtsfølelser og kropssprog afbildes smukt og klart for Putin under hans videoer, er forbløffende.
Der er et par mikroskopiske fejl, især når Obama løfter øjenbrynene og blinker med øjnene. Disse udtryk er ikke ligefrem replikeret i Putins rammer.
Uden den dybe falske baggrund ville Putin-filmen virke ret troværdig og autentisk, hvis den skulle ses på tv eller sociale medier.
Modelskabelse
Nu vil vi bruge de fortrænede kontrolpunkter til at skabe en komplet model.
Deepfake detektion
Relativ nøglepunktsforskydning bruges til at animere elementerne i cellen nedenfor. Den næste celle bruger absolutte koordinater i stedet, men alle emneproportioner vil blive taget fra kørevideoen på denne måde.
Forbedring af output ved hjælp af absolutte koordinater

Du vil være i stand til at udvikle en deepfake-detektion på denne måde.
Hvad er risikoen ved Deepfake-teknologi?
Deepfake-videoer er nu engagerende og underholdende at se på grund af deres nyhed. Der er dog en risiko, der kan gå ud af kontrol, når du ligger under overfladen af denne tilsyneladende sjove teknologi.
Det vil helt sikkert være udfordrende at skelne mellem falske og rigtige videoer som deepfake-teknologi fortsætter fremad. Især for fremtrædende personligheder og berømtheder kan dette have alvorlige konsekvenser. Deepfakes, der er bevidst ondsindede, har potentialet til fuldstændig at skade karrierer og liv.
Disse kan blive brugt af en person med ondsindet hensigt til at gå for andre og drage fordel af deres venner, slægtninge og kolleger. De er også i stand til at udløse verdensomspændende kontroverser og endda krige ved at bruge falske film af udenlandske ledere.
Konklusion
Sammenfattende er vi i en mærkelig periode og usædvanlige omgivelser. Mere end nogensinde før er det nemt at producere falske nyheder og film og sprede dem. At forstå, hvad der er sandt, og hvad der ikke er, bliver stadig mere udfordrende.
I dag, viser det sig, kan vi ikke længere stole på vores egne sanser.
På trods af at der er udviklet falske videodetektorer, er det kun et spørgsmål om tid, før informationskløften er så lille, at selv de fineste falske detektorer ikke vil være i stand til at afgøre, om videoen er ægte eller ej.





Giv en kommentar