Mae cynhyrchu ffilmiau portread creadigol o'r radd flaenaf yn dasg hanfodol a dymunol mewn gweledigaeth gyfrifiadurol a graffeg.
Er bod sawl model effeithiol ar gyfer toneiddiad delwedd portread yn seiliedig ar y StyleGAN grymus wedi'u cynnig, mae gan y technegau delwedd-ganolog hyn anfanteision amlwg pan gânt eu defnyddio gyda fideos, megis maint y ffrâm sefydlog, y gofyniad am aliniad wyneb, absenoldeb manylion nad ydynt yn wyneb. , ac anghysondeb tymmorol.
Defnyddir fframwaith VToonify chwyldroadol i fynd i'r afael â'r trosglwyddiad arddull fideo portread cydraniad uchel anodd dan reolaeth.
Byddwn yn archwilio'r astudiaeth ddiweddaraf ar VToonify yn yr erthygl hon, gan gynnwys ei ymarferoldeb, anfanteision, a ffactorau eraill.
Beth yw Vtoonify?
Mae fframwaith VToonify yn caniatáu trosglwyddiad arddull fideo portread cydraniad uchel y gellir ei addasu.
Mae VToonify yn defnyddio haenau cydraniad canolig ac uchel StyleGAN i greu portreadau artistig o ansawdd uchel yn seiliedig ar nodweddion cynnwys aml-raddfa a adalwyd gan amgodiwr i gadw manylion ffrâm.
Mae'r bensaernïaeth sy'n deillio o hynny'n gwbl drawsnewidiol yn cymryd wynebau heb eu halinio mewn ffilmiau maint amrywiol fel mewnbwn, gan arwain at ranbarthau wyneb cyfan gyda symudiadau realistig yn yr allbwn.

Mae'r fframwaith hwn yn gydnaws â modelau tonification delwedd cyfredol sy'n seiliedig ar StyleGAN, gan ganiatáu iddynt gael eu hymestyn i donification fideo, ac mae'n etifeddu nodweddion deniadol megis addasu lliw a dwyster y gellir eu haddasu.
Mae hyn yn astudio yn cyflwyno dau amrantiad o VToonify yn seiliedig ar Toonify a DualStyleGAN ar gyfer trosglwyddo arddull fideo portread yn seiliedig ar gasgliad ac yn seiliedig ar enghreifftiol, yn y drefn honno.
Mae canfyddiadau arbrofol helaeth yn dangos bod y fframwaith VToonify arfaethedig yn perfformio'n well na'r dulliau presennol o wneud ffilmiau portread artistig o ansawdd uchel, sy'n gydlynol dros dro, gyda pharamedrau arddull amrywiol.
Mae ymchwilwyr yn darparu'r Llyfr nodiadau Google Colab, felly gallwch chi gael eich dwylo'n fudr arno.
Sut mae'n gweithio?
Er mwyn cyflawni trosglwyddiad arddull fideo portread cydraniad uchel y gellir ei addasu, mae VToonify yn cyfuno manteision y fframwaith cyfieithu delwedd â'r fframwaith sy'n seiliedig ar StyleGAN.
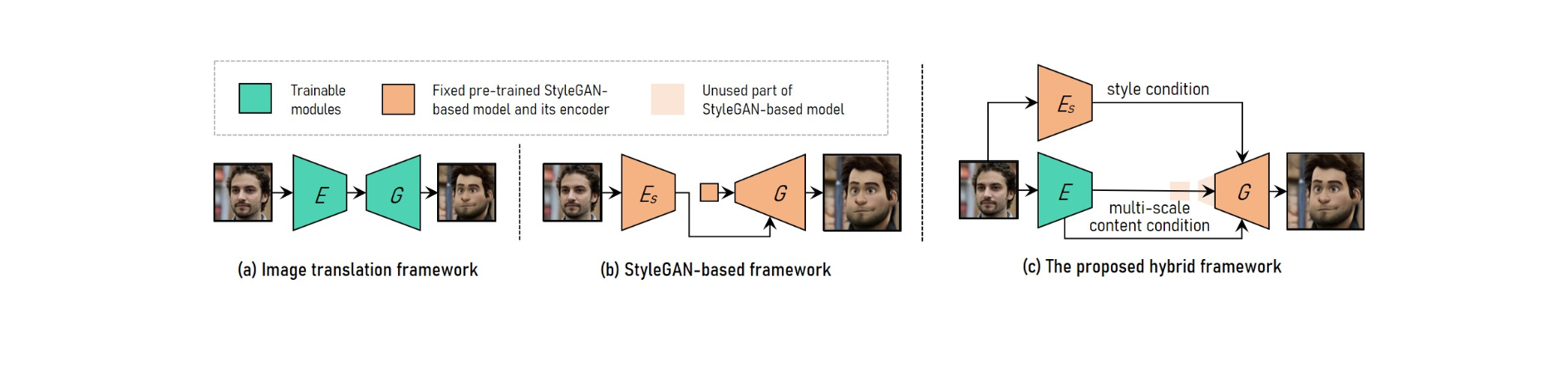
Er mwyn darparu ar gyfer gwahanol feintiau mewnbwn, mae'r system cyfieithu delwedd yn defnyddio rhwydweithiau cwbl fyfyrgar. Mae hyfforddiant o'r dechrau, ar y llaw arall, yn ei gwneud hi'n amhosibl trosglwyddo cydraniad uchel ac arddull rheoledig.
Defnyddir y model StyleGAN sydd wedi'i hyfforddi ymlaen llaw yn y fframwaith sy'n seiliedig ar StyleGAN ar gyfer trosglwyddo arddull cydraniad uchel a rheoledig, er ei fod yn gyfyngedig i golledion maint llun sefydlog a manylion.
Mae StyleGAN yn cael ei addasu yn y fframwaith hybrid trwy ddileu ei nodwedd mewnbwn maint sefydlog a'i haenau cydraniad isel, gan arwain at bensaernïaeth amgodiwr-generadur cwbl wrthdro sy'n debyg i un y fframwaith cyfieithu delwedd.
Er mwyn cynnal manylion y ffrâm, hyfforddwch amgodiwr i dynnu nodweddion cynnwys aml-raddfa'r ffrâm mewnbwn fel gofyniad cynnwys ychwanegol i'r generadur. Mae Vtoonify yn etifeddu hyblygrwydd rheoli arddull model StyleGAN trwy ei roi yn y generadur i ddistyllu ei ddata a'i fodel.
Cyfyngiadau StyleGAN a Vtoonify Arfaethedig
Mae portreadau artistig yn gyffredin yn ein bywydau bob dydd yn ogystal ag mewn busnesau creadigol fel celf, cyfryngau cymdeithasol avatars, ffilmiau, hysbysebu adloniant, ac ati.
Gyda datblygiad dysgu dwfn technoleg, mae bellach yn bosibl creu portreadau artistig o ansawdd uchel o luniau wyneb bywyd go iawn gan ddefnyddio trosglwyddiad arddull portread awtomataidd.
Mae yna amrywiaeth o ffyrdd llwyddiannus wedi'u creu ar gyfer trosglwyddo arddull yn seiliedig ar ddelwedd, ac mae llawer ohonynt yn hawdd eu cyrraedd i ddefnyddwyr cychwynnol ar ffurf cymwysiadau symudol. Mae deunydd fideo wedi dod yn un o brif elfennau ein ffrydiau cyfryngau cymdeithasol yn gyflym dros y blynyddoedd diwethaf.
Mae'r cynnydd yn y cyfryngau cymdeithasol a ffilmiau byrhoedlog wedi cynyddu'r galw am olygu fideo arloesol, megis trosglwyddo arddull fideo portread, i gynhyrchu fideos llwyddiannus a diddorol.
Mae gan dechnegau delwedd-ganolog presennol anfanteision sylweddol o'u cymhwyso i ffilmiau, gan gyfyngu ar eu defnyddioldeb mewn steilio fideo portreadau awtomataidd.
Mae StyleGAN yn asgwrn cefn cyffredin ar gyfer datblygu model trosglwyddo arddull llun portread oherwydd ei allu i greu wynebau o ansawdd uchel gyda rheolaeth arddull addasadwy.
Mae system sy'n seiliedig ar StyleGAN (a elwir hefyd yn donification llun) yn amgodio wyneb go iawn i mewn i ofod cudd StyleGAN ac yna'n cymhwyso'r cod arddull canlyniadol i StyleGAN arall wedi'i fireinio ar y set ddata portreadau artistig i greu fersiwn arddull.
Mae StyleGAN yn creu lluniau gydag wynebau wedi'u halinio ac ar faint sefydlog, nad yw'n ffafrio wynebau deinamig mewn ffilm o'r byd go iawn. Weithiau mae cnydio wynebau ac aliniad yn y fideo yn arwain at wyneb rhannol ac ystumiau lletchwith. Mae ymchwilwyr yn galw'r mater hwn yn 'gyfyngiad cnwd sefydlog.'
Ar gyfer wynebau heb eu halinio, mae StyleGAN3 wedi'i gynnig; fodd bynnag, dim ond maint llun gosodedig y mae'n ei gefnogi.
At hynny, canfu astudiaeth ddiweddar fod amgodio wynebau heb eu halinio yn fwy heriol nag wynebau wedi'u halinio. Mae amgodio wynebau anghywir yn niweidiol i drosglwyddo arddull portread, gan arwain at faterion fel newid hunaniaeth a chydrannau coll yn y fframiau wedi'u hail-greu a'u steilio.
Fel y trafodwyd, rhaid i dechneg effeithlon ar gyfer trosglwyddo arddull fideo portread ymdrin â'r materion canlynol:
- Er mwyn cadw symudiadau realistig, rhaid i'r dull ymdrin â wynebau heb eu halinio a meintiau fideo amrywiol. Gall maint fideo mawr, neu ongl golygfa eang, ddal mwy o wybodaeth wrth gadw'r wyneb rhag symud allan o ffrâm.
- Er mwyn cystadlu â theclynnau HD a ddefnyddir yn gyffredin heddiw, mae angen fideo cydraniad uchel.
- Dylid cynnig rheolaeth arddull hyblyg i ddefnyddwyr newid a dewis eu dewis wrth ddatblygu system ryngweithio defnyddwyr realistig.
I'r diben hwnnw, mae ymchwilwyr yn awgrymu VToonify, fframwaith hybrid newydd ar gyfer toonification fideo. Er mwyn goresgyn y cyfyngiad cnwd sefydlog, mae ymchwilwyr yn astudio cywerthedd cyfieithu yn StyleGAN yn gyntaf.
Mae VToonify yn cyfuno manteision y bensaernïaeth sy'n seiliedig ar StyleGAN a'r fframwaith cyfieithu delwedd i gyflawni trosglwyddiad arddull fideo portread cydraniad uchel y gellir ei addasu.
Dyma’r prif gyfraniadau:
- Mae ymchwilwyr yn ymchwilio i gyfyngiad cnwd sefydlog StyleGAN ac yn cynnig ateb yn seiliedig ar gywerthedd cyfieithu.
- Mae ymchwilwyr yn cyflwyno fframwaith VToonify cwbl ddadleuol unigryw ar gyfer trosglwyddo arddull fideo portread cydraniad uchel dan reolaeth sy'n cefnogi wynebau heb eu halinio a gwahanol feintiau fideo.
- Mae ymchwilwyr yn adeiladu VToonify ar asgwrn cefn Toonify a DualStyleGAN ac yn crynhoi'r asgwrn cefn o ran data a model i alluogi trosglwyddo arddull fideo portread yn seiliedig ar gasgliadau ac yn seiliedig ar esiampl.
Cymharu Vtoonify â modelau eraill o'r radd flaenaf
Toonify
Mae'n gweithredu fel sylfaen ar gyfer trosglwyddo arddull yn seiliedig ar gasgliad ar wynebau wedi'u halinio gan ddefnyddio StyleGAN. Er mwyn adfer y codau arddull, rhaid i ymchwilwyr alinio wynebau a chnydio 256256 o luniau ar gyfer rhaglen cymorth Bugeiliol. Defnyddir Toonify i gynhyrchu canlyniad arddulliedig gyda chodau arddull 1024 * 1024.
Yn olaf, maent yn ail-alinio'r canlyniad yn y fideo i'w leoliad gwreiddiol. Mae'r ardal heb ei steilio wedi'i gosod i ddu.

DdeuolStyleGAN
Mae'n asgwrn cefn ar gyfer trosglwyddo arddull enghreifftiol yn seiliedig ar StyleGAN. Defnyddiant yr un technegau cyn ac ar ôl prosesu data â Toonify.
Pix2pixHD
Mae'n fodel cyfieithu delwedd-i-ddelwedd a ddefnyddir yn gyffredin i gywasgu modelau sydd wedi'u hyfforddi ymlaen llaw ar gyfer golygu cydraniad uchel. Mae'n cael ei hyfforddi gan ddefnyddio data pâr.
Mae ymchwilwyr yn defnyddio pix2pixHD fel ei fewnbynnau map enghreifftiol ychwanegol gan ei fod yn defnyddio map dosrannu a echdynnwyd.
Cynnig Gorchymyn Cyntaf
Mae FOM yn fodel animeiddio delwedd nodweddiadol. Cafodd ei hyfforddi ar 256256 o luniau ac mae'n perfformio'n wael gyda meintiau delwedd eraill. O ganlyniad, mae ymchwilwyr yn graddio'r fframiau fideo i 256 * 256 i FOM i'w hanimeiddio ac yna'n newid maint y canlyniadau i'w maint gwreiddiol.
I gael cymhariaeth deg, mae FOM yn defnyddio ffrâm arddull gyntaf ei ddull gweithredu fel ei ddelwedd arddull cyfeirio.
DaGAN
Mae'n fodel animeiddio wyneb 3D. Maent yn defnyddio'r un dulliau paratoi data ac ôl-brosesu â FOM.

manteision
- Gellir ei ddefnyddio yn y celfyddydau, avatars cyfryngau cymdeithasol, ffilmiau, hysbysebu adloniant, ac ati.
- Gellir defnyddio Vtoonify yn y metaverse hefyd.
Cyfyngiadau
- Mae'r fethodoleg hon yn tynnu'r data a'r model o'r asgwrn cefn sy'n seiliedig ar StyleGAN, gan arwain at ogwydd data a model.
- Achosir yr arteffactau yn bennaf gan wahaniaethau maint rhwng y rhanbarth wyneb arddulliedig a'r adrannau eraill.
- Mae'r strategaeth hon yn llai llwyddiannus wrth ymdrin â phethau yn y rhanbarth wyneb.
Casgliad
Yn olaf, mae VToonify yn fframwaith ar gyfer toneiddiad fideo cydraniad uchel a reolir gan arddull.
Mae'r fframwaith hwn yn cyflawni perfformiad gwych wrth drin fideos ac yn galluogi rheolaeth eang dros yr arddull strwythurol, yr arddull lliw, a'r radd arddull trwy gyddwyso modelau toneiddiad delwedd sy'n seiliedig ar StyleGAN o ran eu cyddwyso. data synthetig a strwythurau rhwydwaith.





Gadael ymateb