Obsah[Skrýt][Ukázat]
- 1. Co je skriptování v Pythonu a jak se liší od programování v Pythonu?
- 2. Jak funguje sběr odpadu v Pythonu?
- 3. Vysvětlete rozdíl mezi seznamem a n-ticí
- 4. Co jsou to seznamy a uveďte příklad jejich použití?
- 5. Popište rozdíl mezi deepcopy a copy?
- 6. Jak je dosaženo multithreadingu v Pythonu a jak se liší od multiprocessingu?
- 7. Co jsou dekorátory a jak se používají v Pythonu?
- 8. Vysvětlete rozdíly mezi *args a **kwargs?
- 9. Jak byste zajistili, že funkci lze pomocí dekorátorů volat pouze jednou?
- 10. Jak funguje dědičnost v Pythonu?
- 11. Co je přetěžování a přepisování metody?
- 12. Popište pojem polymorfismus na příkladu.
- 13. Vysvětlete rozdíl mezi instančními, třídními a statickými metodami.
- 14. Popište, jak pythonská sada interně funguje.
- 15. Jak je slovník implementován v Pythonu?
- 16. Vysvětlete výhody používání pojmenovaných n-tic.
- 17. Jak funguje blok try-except?
- 18. Jaký je rozdíl mezi tvrzeními o zvýšení a tvrzení?
- 19. Jak čtete a zapisujete data z binárního souboru v Pythonu?
- 20. Vysvětlete příkaz with a jeho výhody při práci se souborovými I/O.
- 21. Jak byste vytvořili singleton modul v Pythonu?
- 22. Uveďte několik způsobů, jak optimalizovat využití paměti ve skriptu Python.
- 23. Jak byste extrahovali všechny e-mailové adresy z daného řetězce pomocí regulárního výrazu?
- 24. Vysvětlete návrhový vzor Factory a jeho aplikaci v Pythonu
- 25. Jaký je rozdíl mezi iterátorem a generátorem?
- 26. Jak funguje dekorátor @property?
- 27. Jak byste vytvořili základní REST API v Pythonu?
- 28. Popište, jak používat knihovnu požadavků k vytvoření požadavku HTTP POST.
- 29. Jak byste se připojili k databázi PostgreSQL pomocí Pythonu?
- 30. Jaká je role ORM v Pythonu a jmenujte populární?
- 31. Jak byste profilovali skript Python?
- 32. Vysvětlete GIL (Global Interpreter Lock) v CPythonu
- 33. Vysvětlete async/wait Pythonu. Jak se liší od tradičního navlékání?
- 34. Popište, jak byste použili Pythonův concurrent.futures.
- 35. Porovnejte Django a Flask z hlediska případu použití a škálovatelnosti.
- Proč investovat do čističky vzduchu?
V době, kdy technologie existuje v každém aspektu našeho života, PYTHON skriptování se ukazuje jako klíčová složka obrovské a složité IT infrastruktury, která otevírá paradigma snadného použití a užitečnosti.
Síla Pythonu nespočívá pouze v jeho syntaktické jednoduchosti a čitelnosti, ale také v jeho přizpůsobivosti, která mu umožňuje snadno překlenout propast mezi nízkorizikovým skriptováním pro začátečníky a vysokými sázkami, vývojem softwaru na podnikové úrovni.
Široké knihovny a rámce Pythonu dláždí cestu pro plynulé, nápadité technické dobrodružství, ať už jde o oblasti analýzy dat, vývoje webu, umělé inteligence nebo síťových serverů.
Kromě toho, že je Python nástrojem pro řešení problémů, také podporuje atmosféru, kde jsou inovace nejen přijímány, ale také přirozeně začleňovány díky svým obrovským knihovnám a rámcům, jako je Django pro vývoj webu nebo Pandas pro analýzu dat.
Ve světě, kde jsou data králem, poskytuje Python výkonné nástroje pro manipulaci, analýzu a vizualizace dat, což vede k použitelným poznatkům a vodítkům při strategických rozhodnutích.
Python není jen programovací jazyk; je to také prosperující komunita, centrum, kde se setkávají vývojáři, datoví vědci a tech nadšenci, aby vynalezli, vytvořili a posunuli IT průmysl na další úroveň.
Vývojáři v jazyce Python jsou vyhledávaní podniky všech velikostí, od začínajících startupů až po dobře zavedené organizace, jako katalyzátory inovací, zlepšování procesů a zlepšených služeb zákazníkům.
Navíc jeho open source povaha podporuje kulturu sdíleného učení a kolaborativního růstu, což zaručuje, že se bude i nadále vyvíjet v rychle se měnícím technologickém světě.
Učení Pythonu v roce 2023 je investicí do jazyka, který slibuje, že zůstane aktuální, flexibilní a nezbytný pro řízení přílivu a toku technologií.
Umožňuje přístup k polím strojové učení, analytika dat, kybernetická bezpečnost a další, které jsou klíčové pro utváření digitální éry.
Proto jsme pro vás sestavili seznam nejlepších otázek pro pohovory v Pythonu, které vám umožní zazářit jako vývojář a být esem na pohovoru.
1. Co je skriptování v Pythonu a jak se liší od programování v Pythonu?
Python je známý svou přizpůsobivostí a poskytuje jak skriptovací, tak programovací dovednosti, z nichž každá je vhodná pro konkrétní práci a cíle.
Skriptování v Pythonu je v podstatě proces psaní kratších, efektivnějších skriptů, které jsou určeny ke správě souborů, automatizaci opakujících se procesů nebo rychlému prototypování nápadů.
Tyto skripty, které jsou často samostatné, efektivně provádějí seznam akcí v pořadí.
Na druhé straně programování v Pythonu jde dále a klade důraz na vytváření větších, složitějších programů se strukturovaným kódem pomocí knihoven, rámců a osvědčených postupů.
Zatímco oba pocházejí ze stejného jazyka, skriptování zjednodušuje a automatizuje, zatímco programování vytváří a vynalézá. Tento rozdíl je vidět v rozsahu a cílech jednotlivých disciplín.
2. Jak funguje sběr odpadu v Pythonu?
Klíčovým prvkem pro zajištění efektivní správy paměti je Pythonův systém pro sběr odpadu.
Neúnavně pracuje na pozadí, aby chránil systémové prostředky před přetížením úniky paměti. Tento automatizovaný přístup je založen především na metodě počítání referencí, kdy každý objekt sleduje, kolik dalších objektů na něj odkazuje.
Tento objekt se stane kandidátem na rekultivaci paměti, když tento počet klesne na 0, což znamená, že položka již není vyžadována.
Kromě toho Python používá cyklický garbage collector, který by jednoduchý přístup počítání referencí mohl minout, k nalezení a vyčištění referenčních cyklů.
Dvouvrstvá strategie počítání referencí a cyklického shromažďování odpadu tedy poskytuje pečlivé a efektivní využití paměti a posiluje výkon Pythonu, zejména v aplikacích náročných na paměť.
Jednoduchá ukázka kódu ukazující, jak se propojit se systémem sběru odpadků Pythonu, je uvedena níže:
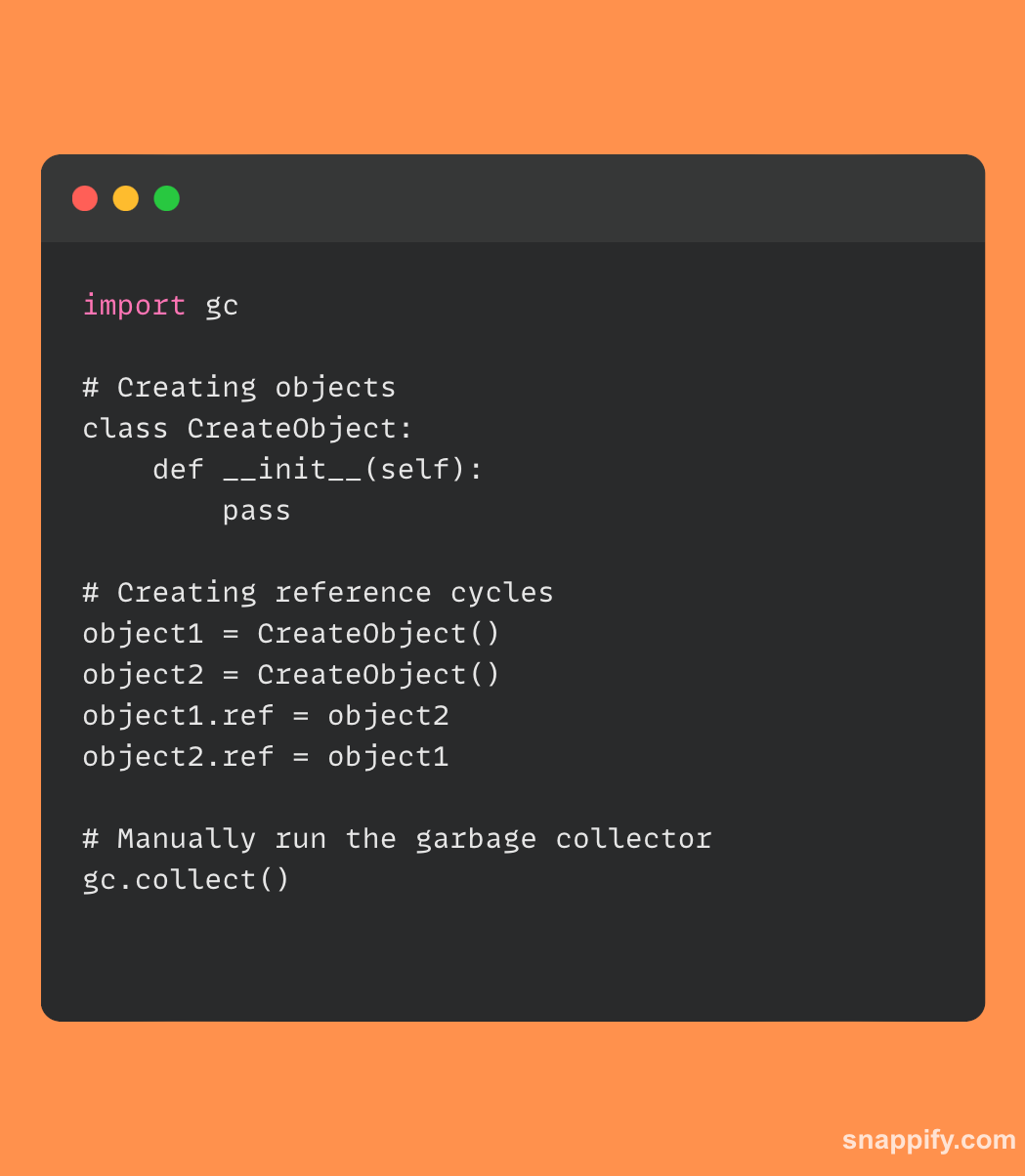
V tomto úryvku jsou generovány dva objekty, na které se odkazuje za účelem vytvoření cyklu. Kolektor odpadu je pak ručně spuštěn pomocí gc.collect(), což ukazuje, jak se programátoři mohou podle potřeby zapojit do mechanismu správy paměti Pythonu.
3. Vysvětlete rozdíl mezi seznamem a n-ticí
Seznamy a n-tice jsou efektivní kontejnery pro data ve světě Pythonu, ale mají různé vlastnosti, které splňují různé programovací účely.
Seznam, označený hranatými závorkami, umožňuje flexibilitu tím, že umožňuje měnit a dynamicky měnit velikost jeho součástí.
Naproti tomu n-tice uzavřená v závorkách je neměnná a během provádění funkce si zachovává svůj počáteční stav.
N-tice poskytují pevnou, neměnnou posloupnost, zatímco seznamy nabízejí flexibilitu, která umožňuje různá použití při zpracování a úpravě dat.
Tady je něco málo Pythonův kód ukázka ukazující, jak používat seznamy i n-tice:

4. Co jsou to seznamy a uveďte příklad jejich použití?
Porozumění seznamu je účinný a expresivní způsob, jak vytvářet seznamy v Pythonu, které kombinují sílu podmíněné logiky a smyček do jediného, srozumitelného řádku kódu.
Poskytují zjednodušenou syntaxi pro převod našich záměrů na seznam, kombinující iteraci a podmíněnost do jediné, rafinované struktury.
Porozumění seznamu v podstatě dává programátorům možnost vytvářet seznamy prováděním operací na každém členu a možná je filtrovat v závislosti na určitých kritériích, to vše při zachování pořádkové kódové základny.
Tato výrazná funkce kombinuje efektivitu s přehledností v programování v Pythonu tím, že zlepšuje čitelnost a zároveň může za určitých okolností poskytovat výpočetní zisky.
Ukázka porozumění seznamu v Pythonu je uvedena níže:
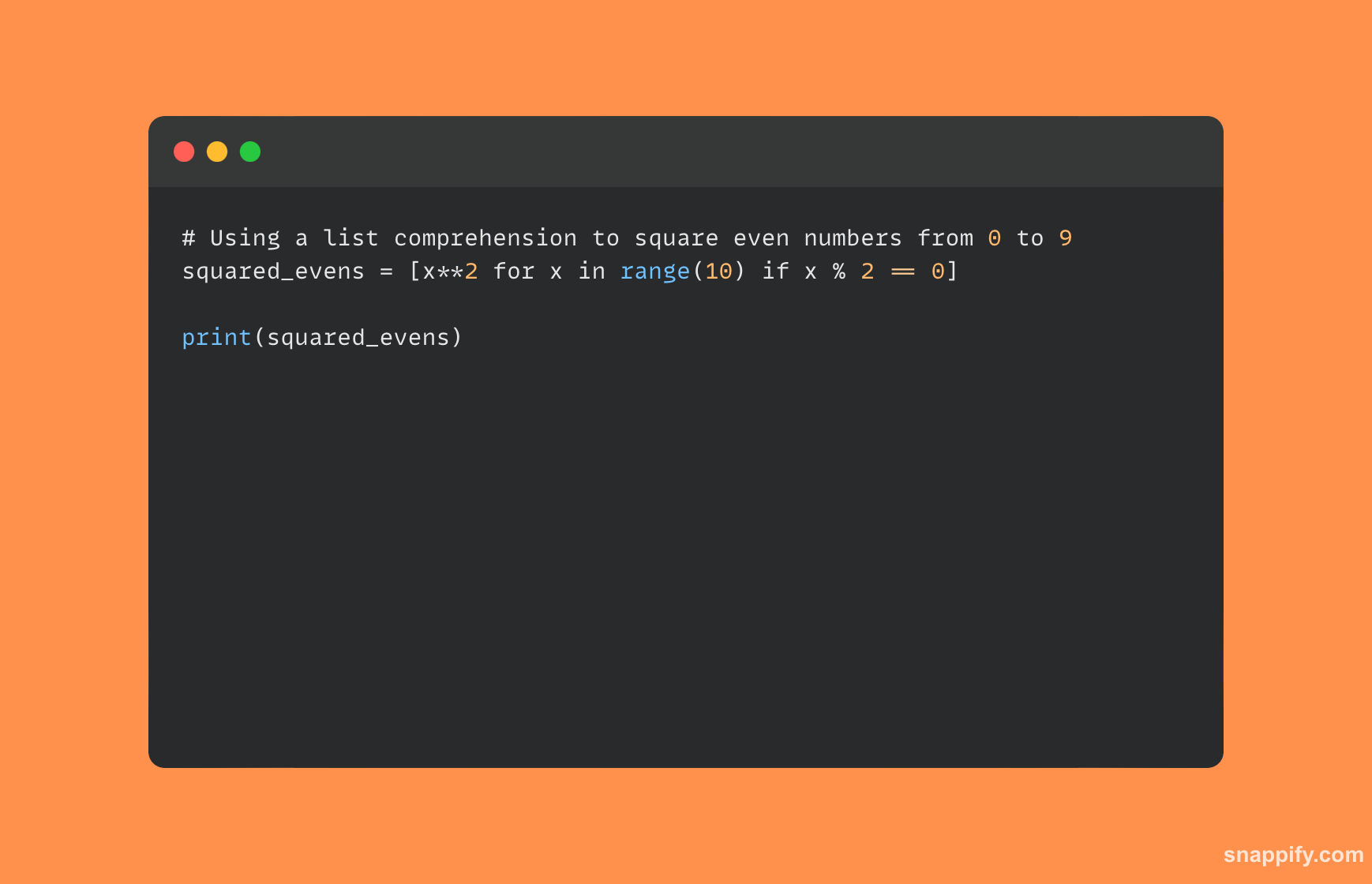
5. Popište rozdíl mezi deepcopy a copy?
Hloubka a integrita duplikovaných objektů určují rozdíl mezi nimi deepcopy a copy v Pythonu.
Vytvořením nové položky při zachování odkazů na původní vnořené objekty, a copy vytváří mělkou repliku, která spojuje jejich osudy dohromady v síti vzájemné závislosti.
Deepcopy vytváří zcela autonomní klon rekurzivním kopírováním původního objektu a všech jeho hierarchických komponent, přerušením všech spojení a zachováním autonomie při změnách.
Proto v závislosti na požadované úrovni nezávislosti na objektu deepcopy zajišťuje komplexní reprodukci, zatímco kopie poskytuje pouze povrchovou duplikaci.
Zde je nějaký kód, který ukazuje, jak na to copy a deepcopy se od sebe liší:
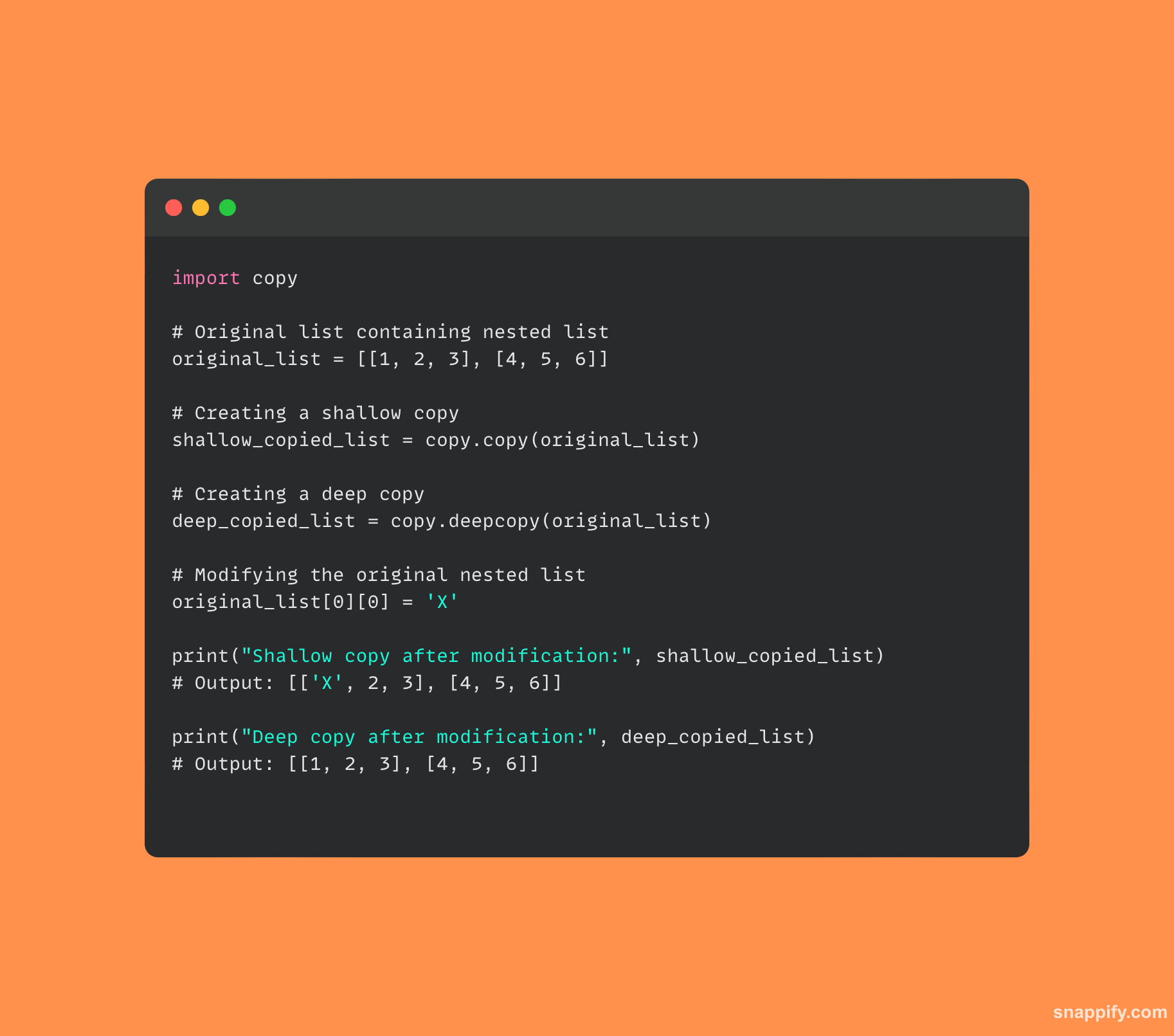
6. Jak je dosaženo multithreadingu v Pythonu a jak se liší od multiprocessingu?
Pythonův multiprocessing a multithreading řeší souběžné provádění, ale používají různá paradigmata.
Použití mnoha vláken uvnitř jednoho procesu umožňuje multithreading souběžné provádění úloh ve sdíleném paměťovém prostoru.
Skutečné spuštění paralelního vlákna však může být obtížné dosáhnout kvůli Pythonu Global Interpreter Lock (GIL).
Na druhou stranu multiprocesing využívá několik procesů, každý se samostatným interpretem Pythonu a paměťovým prostorem, což zajišťuje skutečný paralelismus.
Pro I/O aktivity je multithreading lehčí a praktičtější, ale multiprocessing vyniká v situacích vázaných na CPU, kde je rozhodující skutečné paralelní provádění.
Zde je krátká ukázka kódu, která porovnává multiprocesing a multithreading:
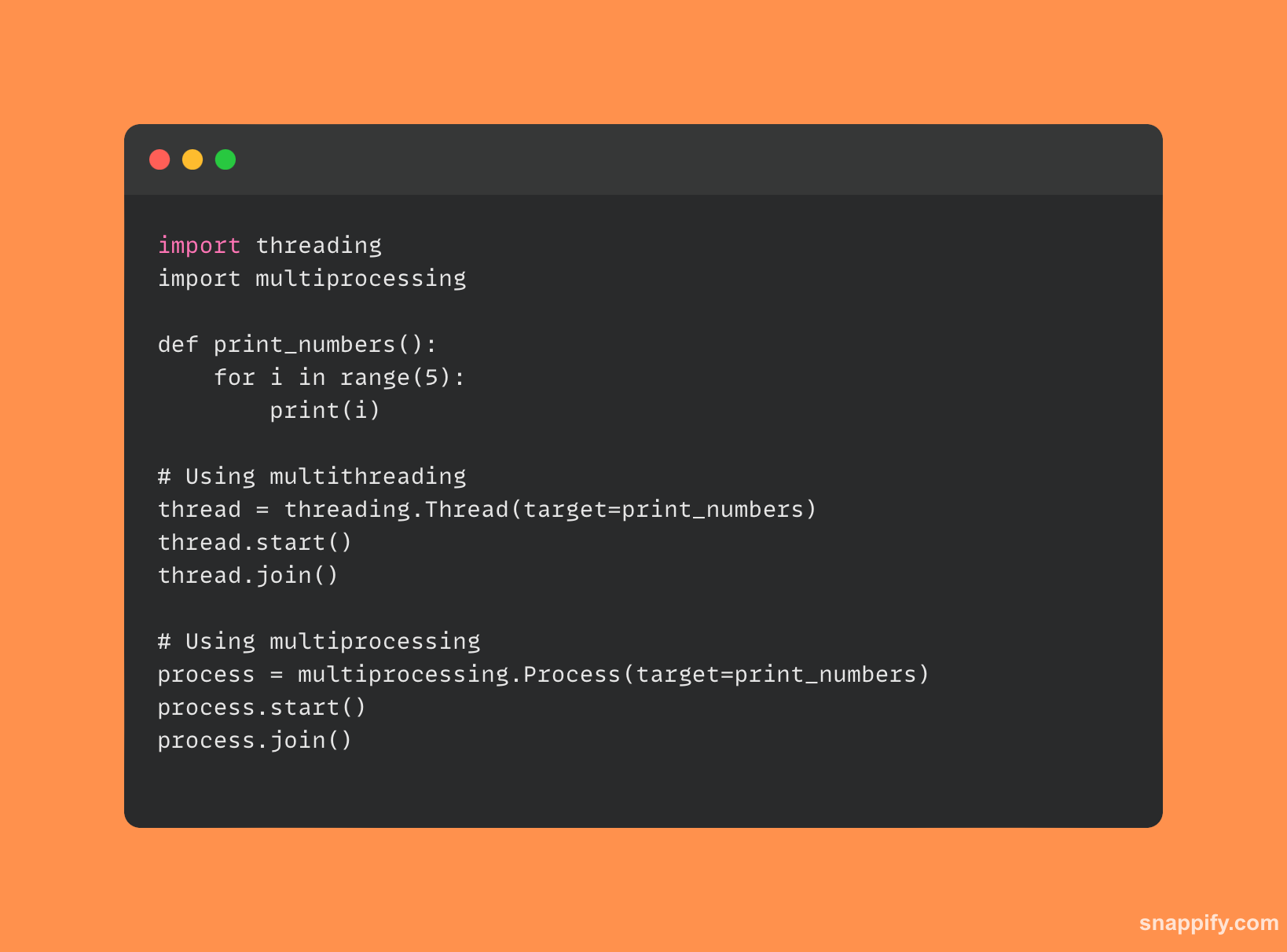
7. Co jsou dekorátory a jak se používají v Pythonu?
V Pythonu dekorátoři elegantně kombinují užitečnost a jednoduchost a zároveň jemně rozšiřují nebo mění funkce.
Představte si dekoratéry jako závoj, který nádherně zahaluje funkci a přidává její schopnosti, aniž by měnil její základní povahu.
Tyto entity, označené symbolem @, přijmout funkci jako vstup a na výstupu zcela novou funkci, která nabízí bezproblémový způsob úpravy chování funkce.
Dekorátoři poskytují širokou škálu funkcí, od protokolování po řízení přístupu, vylepšují kód o nové vrstvy při zachování jasné a srozumitelné syntaxe.
Zde je jednoduchý příklad kódu Python, který ukazuje, jak se dekorátory používají:
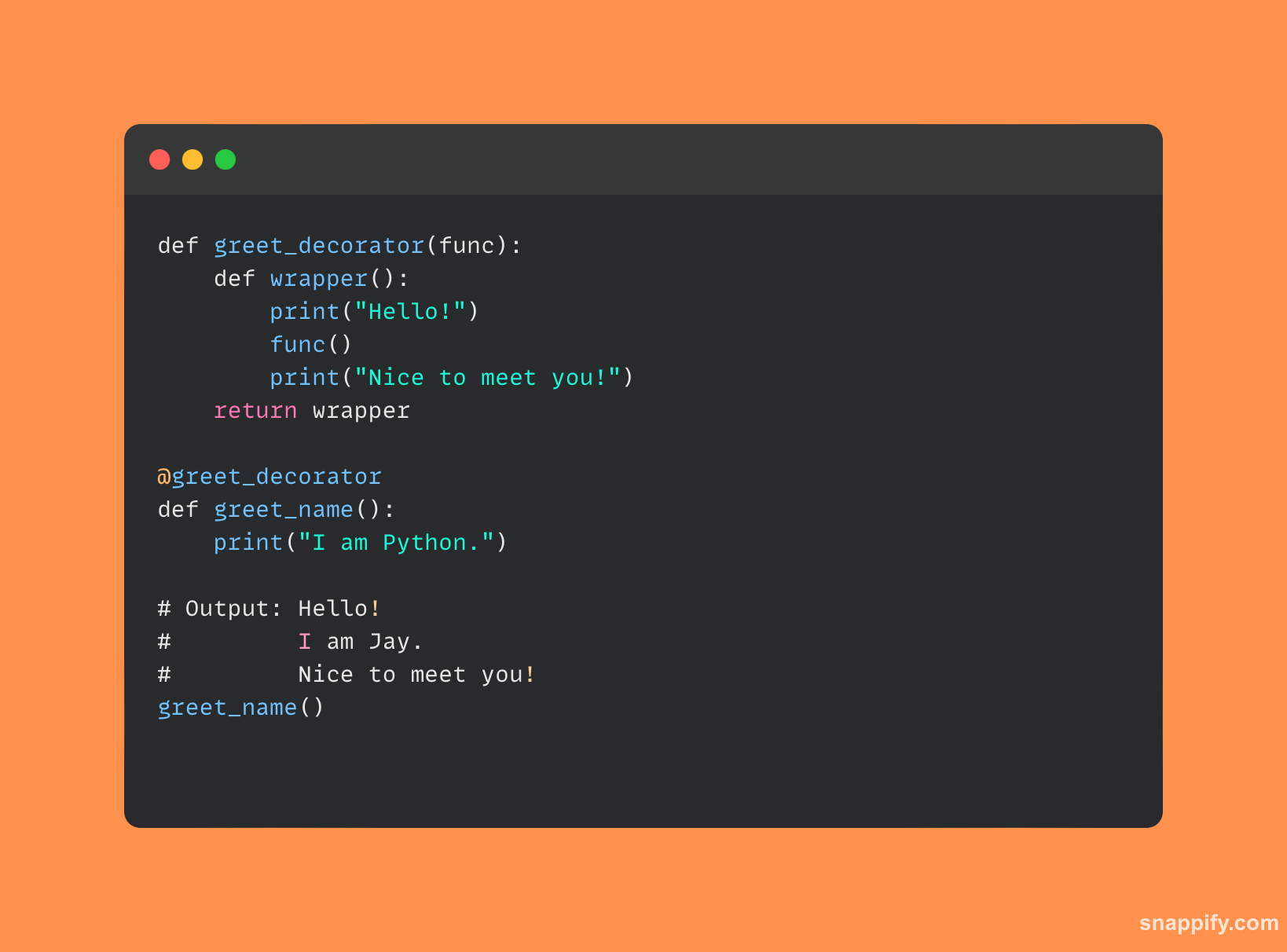
8. Vysvětlete rozdíly mezi *args a **kwargs?
Flexibilní parametry Pythonu *args a **kwargs umožňují funkcím správně převzít řadu argumentů.
Funkce může přijmout libovolný počet pozičních argumentů pomocí *args parametr, který je seskupuje do n-tice.
Naproti tomu funkce může přijmout libovolný počet argumentů klíčových slov pomocí **kwargs parametr, který je seskupuje do slovníku.
Oba fungují jako kanály pro dynamiku a flexibilitu při konstrukci funkcí a volání, **kwargs nabízí strukturovanou metodu pro zpracování libovolného množství vstupů klíčových slov *args elegantně zpracovává nedefinované poziční vstupy.
Společně zlepšují flexibilitu a trvanlivost funkcí Pythonu obratným a jasným zpracováním široké škály aplikačních scénářů.
Příklad kódu Pythonu, který používá *args a **kwargs je uveden níže:
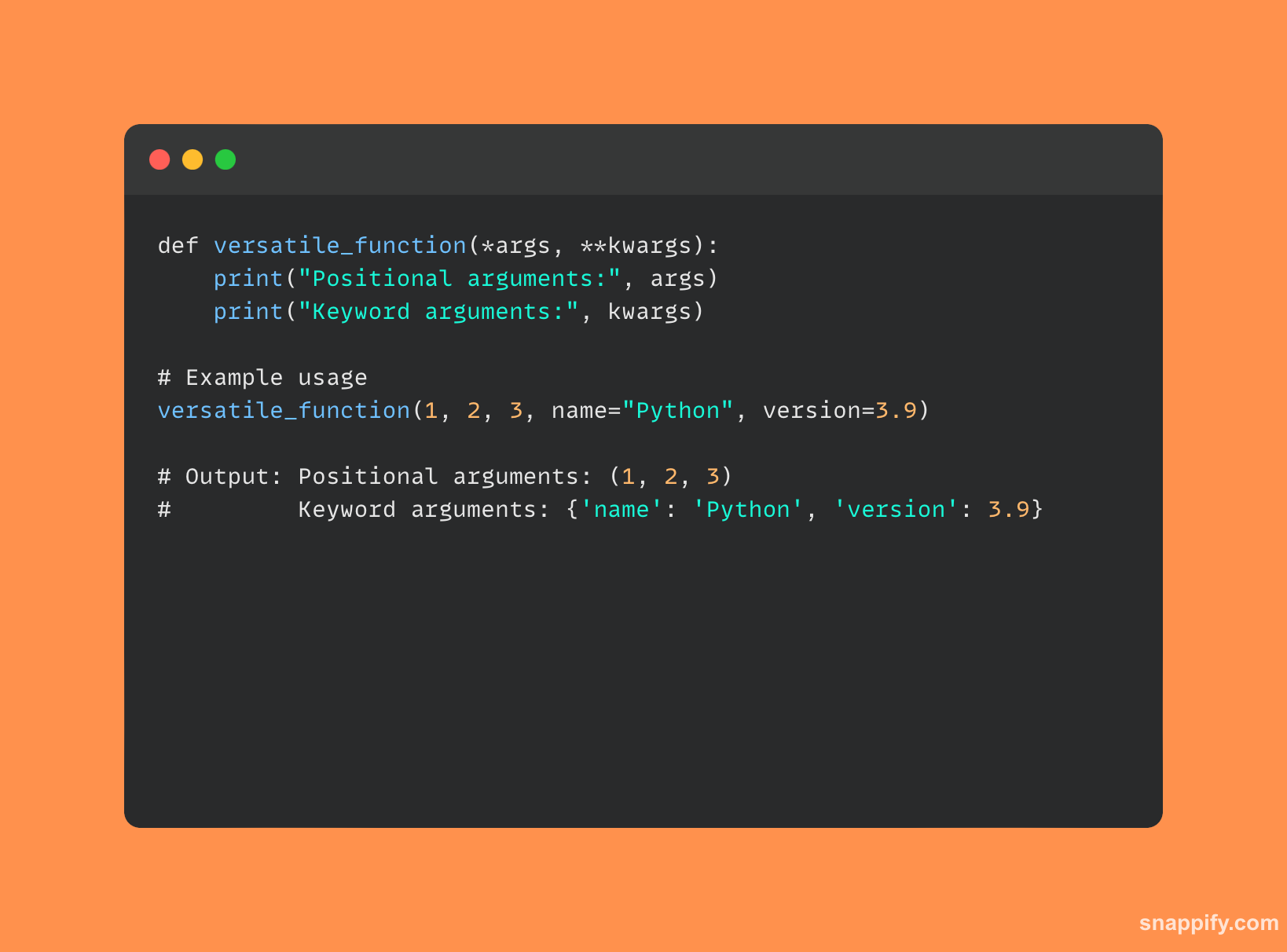
9. Jak byste zajistili, že funkci lze pomocí dekorátorů volat pouze jednou?
Dekorátoři Python jsou zběhlí v kombinování užitečnosti s elegancí, která je potřebná k zajištění jedinečnosti funkce při provádění.
Je možné navrhnout dekorátor tak, aby obsahoval funkci a uchovával tyto informace uvnitř udržováním vnitřního stavu.
Zapouzdřená funkce se zavolá jednou a provede se a dekorátor volání zaznamená. Následná volání jsou blokována, čímž je funkce chráněna před opakovaným prováděním tím, že není rušena.
Pomocí této aplikace dekoratérů lze ovládat volání funkcí jemným, ale účinným způsobem, což zaručuje jedinečnost způsobem, který je krásný a nenápadný.
Zde je ukázka kódu, která ukazuje, jak lze dekorátory použít k omezení počtu volání funkce:

10. Jak funguje dědičnost v Pythonu?
Dědičný systém Pythonu vytváří síť hierarchických vazeb mezi třídami, což umožňuje sdílení charakteristik a funkcí z rodičovské třídy s jejími potomky.
Spravuje linii, která umožňuje odvozeným (podřízeným) třídám dědit, nahrazovat nebo přidávat funkce z jejich základních (nadřazených) tříd, čímž podporuje opětovné použití kódu a logický, hierarchický design.
Podřízená třída může kromě toho, že absorbuje schopnosti od svého rodiče, představit své jedinečné vlastnosti a chování a vytvořit tak silný, vícevrstvý objektový model.
V tomto přístupu dědičnost dovedně distribuuje funkčnost po tepnách hierarchie tříd a vytváří jednotnou, dobře organizovanou objektově orientovanou architekturu.
Následující zjednodušený kód Pythonu demonstruje dědičnost:

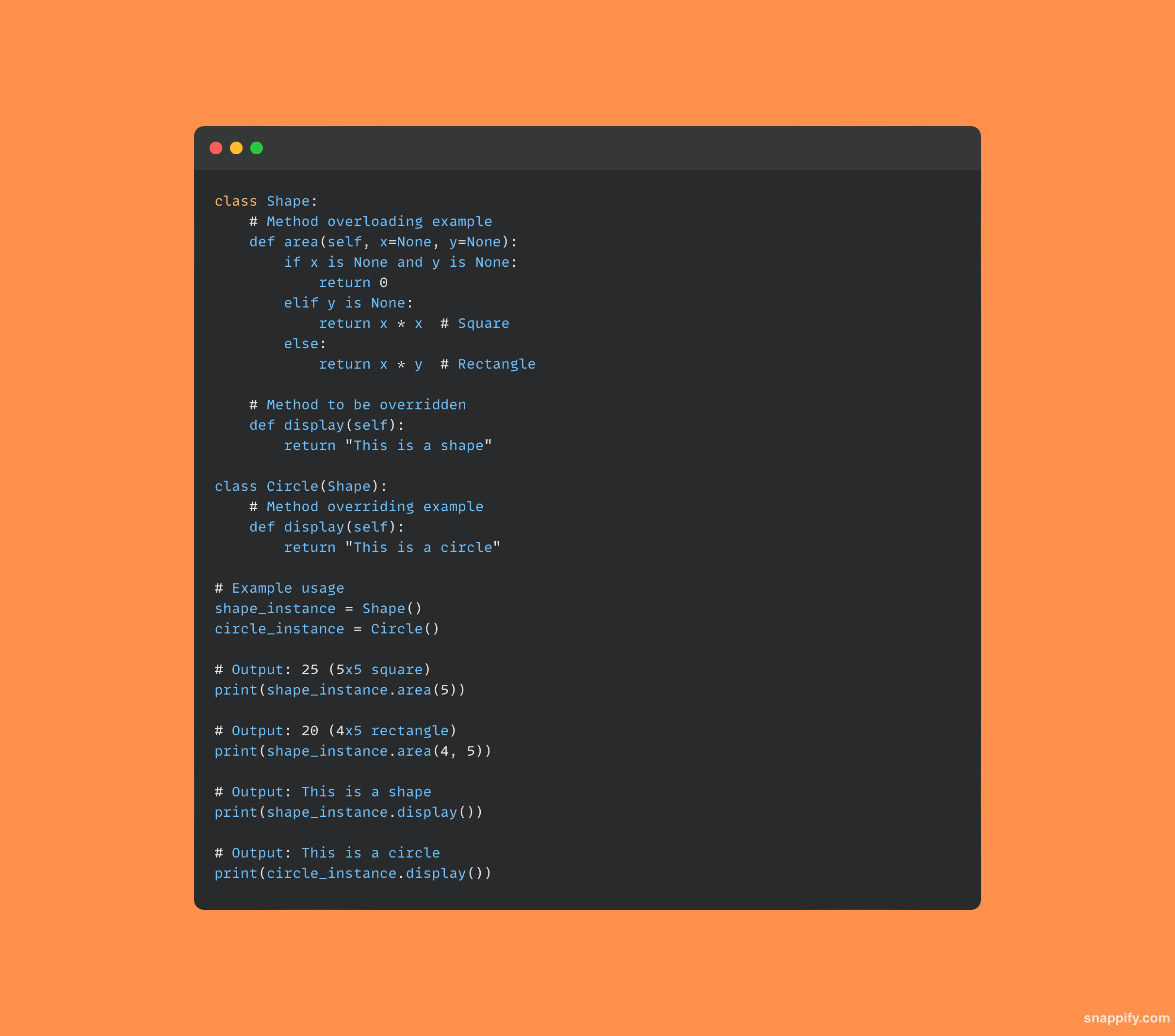
11. Co je přetěžování a přepisování metody?
Dva základní kameny objektově orientované programování, přetěžování metod a přepisování metod, umožňují vývojářům používat stejný název metody pro několik účelů.
Jediná metoda může pojmout různé typy dat a počet argumentů tím, že má mnoho podpisů díky přetížení metody.
Na druhou stranu přepis metody umožňuje podtřídě přidat vlastní speciální implementaci k metodě, která je již definována v její rodičovské třídě, což zaručuje, že bude volána verze potomka.
Společně tyto strategie zlepšují přizpůsobivost tím, že umožňují chování metod, které závisí na kontextu a konkrétních požadavcích aplikace.
Zde je ukázka kódu, který ilustruje oba koncepty:
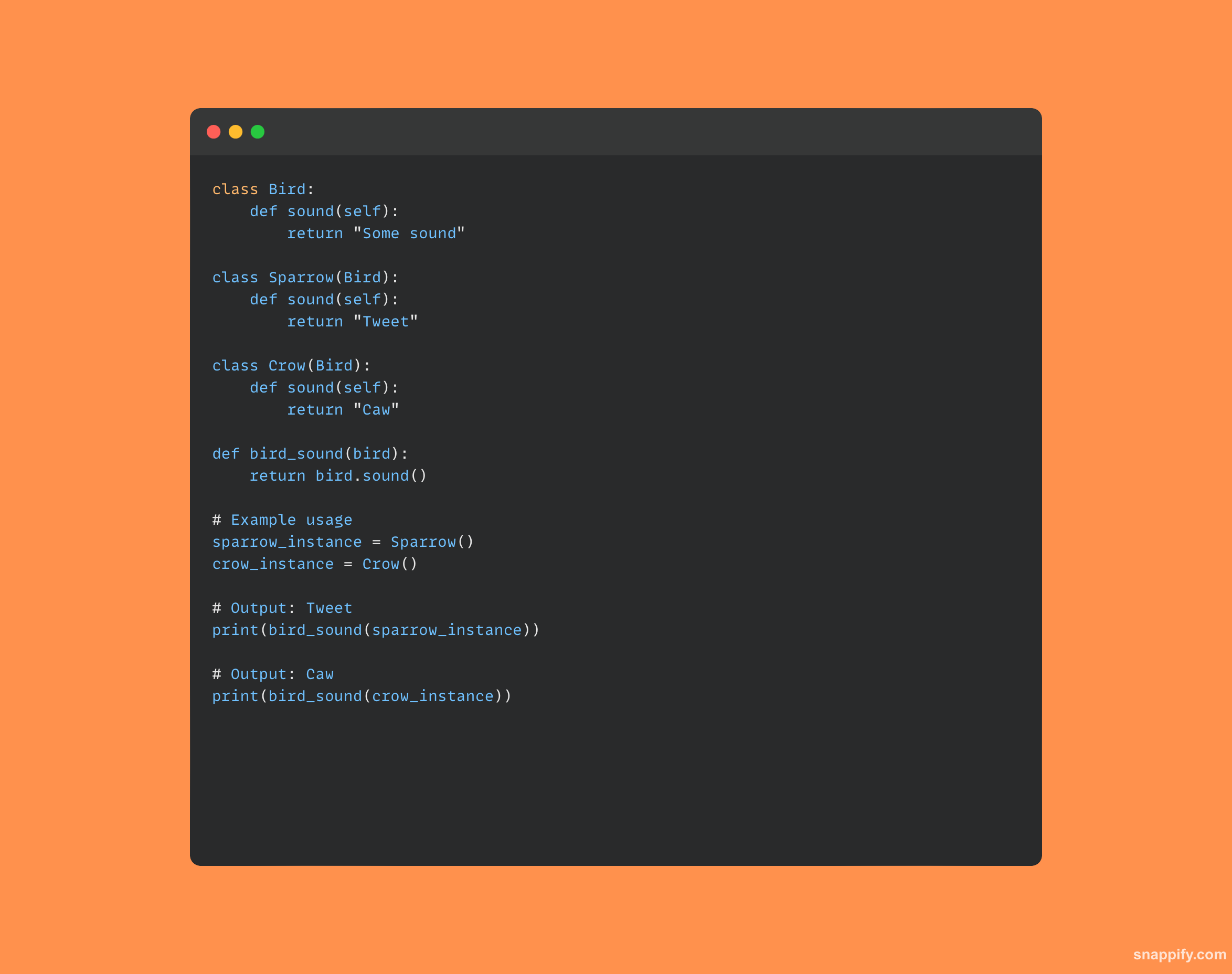
12. Popište pojem polymorfismus na příkladu.
Polymorfismus je praxe používání jediného rozhraní pro různé typy dat.
Tato myšlenka zajišťuje přizpůsobivost a škálovatelnost v návrhu tím, že dává metodám svobodu zpracovávat objekty různými způsoby v závislosti na jejich vnitřním typu nebo třídě.
Polymorfismus v podstatě umožňuje jednotné interakce při zachování odlišného chování tím, že umožňuje, aby objekty různých tříd byly považovány za instance stejné třídy prostřednictvím dědičnosti.
Tato dynamická funkce podporuje jednoduchost kódu tím, že umožňuje jediné funkci nebo operátorovi bez problémů komunikovat s různými druhy objektů.
Zde je přehledná ukázka kódu, která demonstruje polymorfismus:
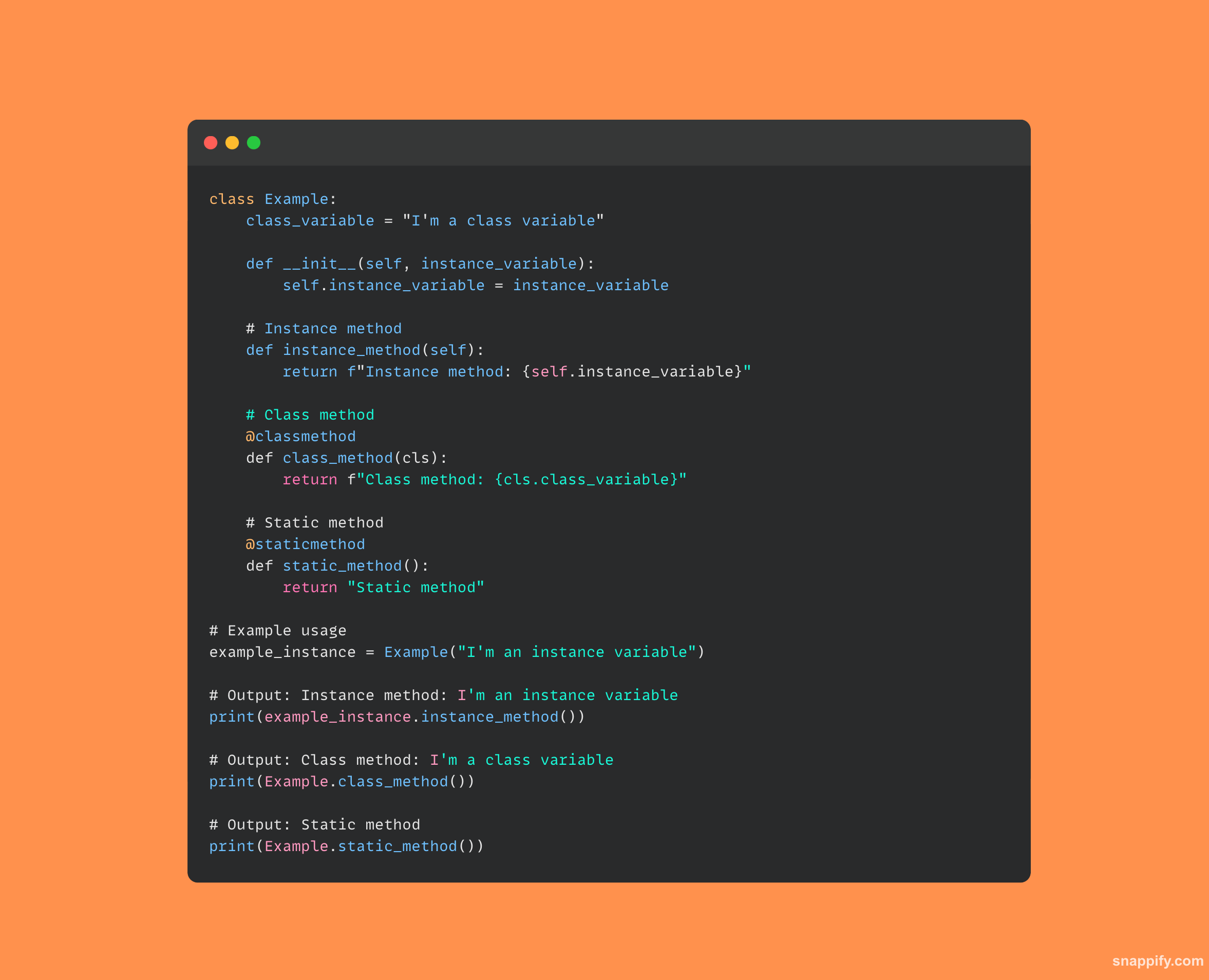
13. Vysvětlete rozdíl mezi instančními, třídními a statickými metodami.
Instance, třídy a statické metody mají všechny své vlastní odlišné způsoby interakce s objektovými a třídními daty v Pythonu.
Nejrozšířenější druh, metody instance, působí na data instance třídy a berou jako vstup instanci třídy, obvykle nazývanou self.
Třída samotná (často označovaná jako cls) je akceptována jako argument metodami třídy, které jsou označeny @classmethod, a manipulují s daty na úrovni třídy.
Statické metody, označené symbolem hash @staticmethod, neovlivňují stav třídy nebo instance, protože se jedná o samostatně stojící funkce obsažené ve třídě a neberou self nebo cls jako první parametr.
Protože každý typ metody poskytuje jiný přístup a užitečnost, jsou objektově orientované architektury flexibilní a přesné.
Jako příklad jednoho z těchto typů metod v kódu:
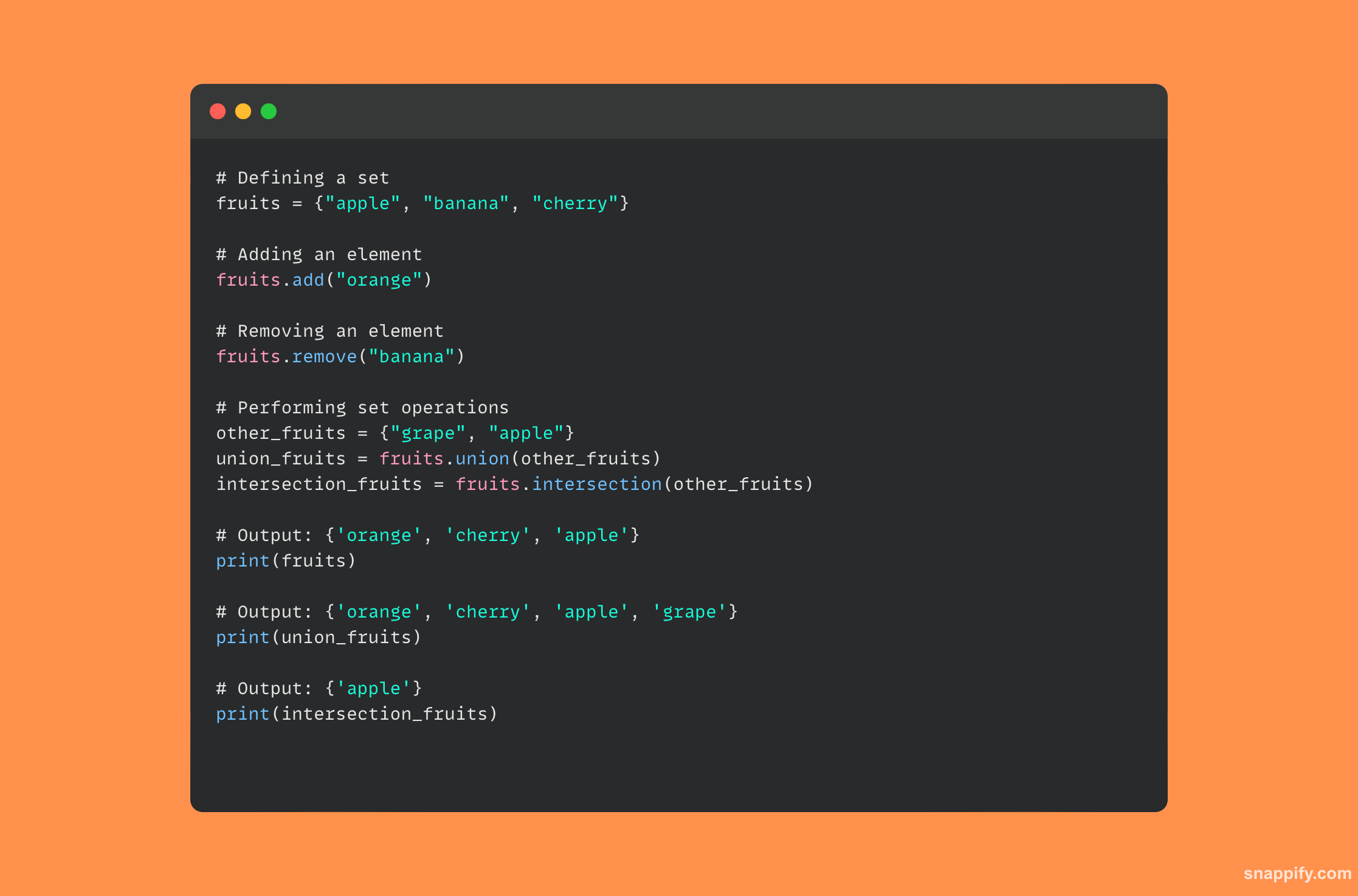
14. Popište, jak pythonská sada interně funguje.
Interní datová struktura nazvaný hashtable se používá v sadě Pythonu, což je neuspořádaná kolekce odlišných komponent, k provádění výkonných a efektivních operací.
Python používá hashovací funkci k rychlé správě a načítání dat, když je prvek přidán do sady, čímž se prvek mění na hodnotu hash, která pak definuje jeho umístění v paměti.
Usnadněním rychlých kontrol členství a odstraněním duplicitních záznamů tato technika zajišťuje, že každý prvek v sadě je jedinečný a snadno dostupný.
Proto inherentní architektura sad má tendenci optimalizovat operace, jako jsou sjednocení, křížení a rozdíly, což vede k malé, efektivní datové struktuře.
Zde je část kódu, která ukazuje, jak jednoduše interagovat se sadou Pythonu:
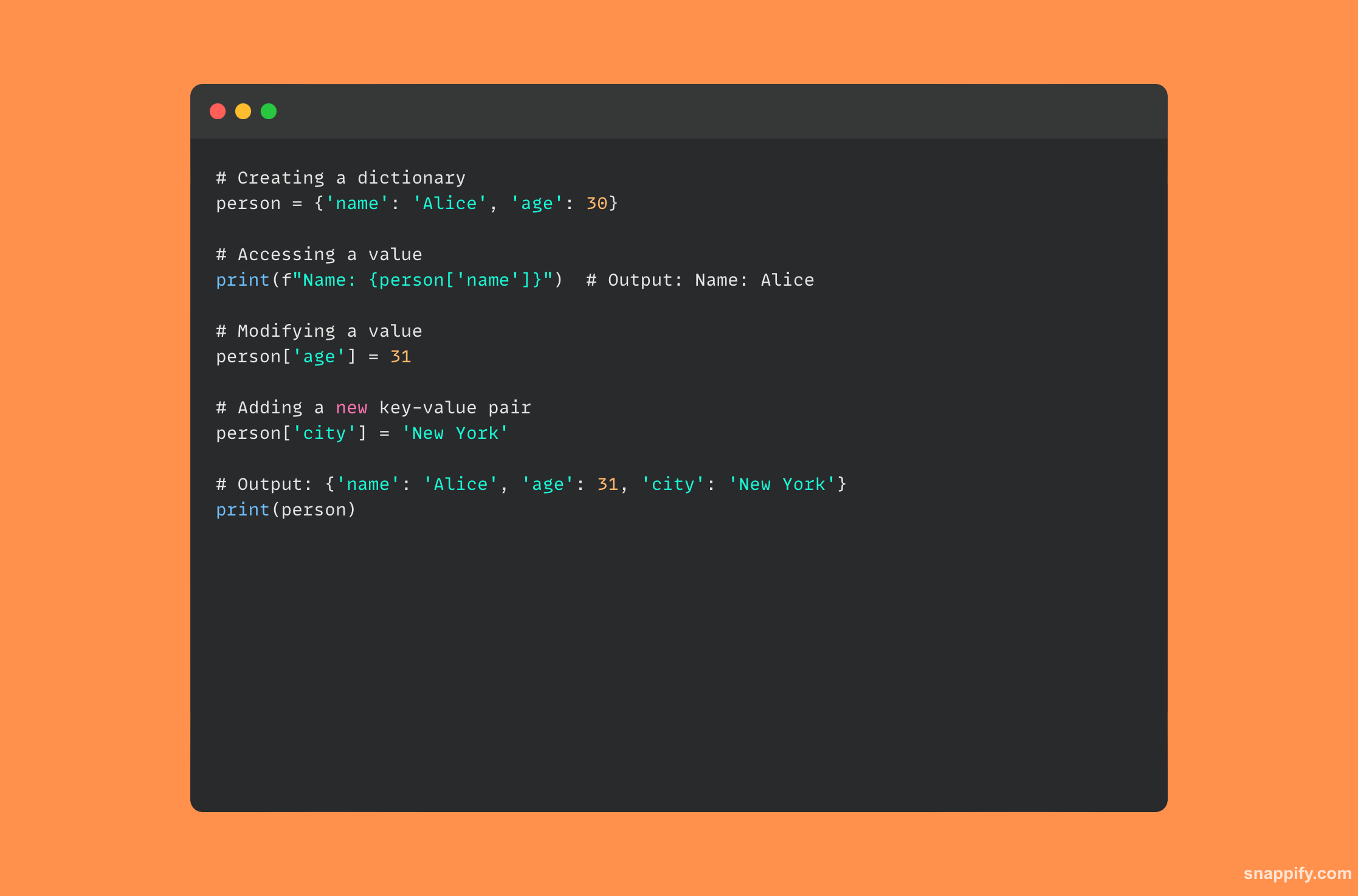
15. Jak je slovník implementován v Pythonu?
Hashtable slouží jako základ slovníku v Pythonu a umožňuje rychlé načítání dat a manipulaci s nimi. Slovníky jsou dynamické, neuspořádané kolekce párů klíč-hodnota.
Python používá hašovací funkci k výpočtu hašování klíče, když je vydán pár klíč-hodnota, a vyhledá umístění adresy úložiště hodnoty v paměti.
Vzhledem k tomu, že hashovací funkce okamžitě nasměruje interpret na adresu paměti, nabízí tento design rychlý přístup k datům na základě klíčů a je úžasně efektivní při operacích vyhledávání, vkládání a mazání.
Vývojáři mohou spravovat data snadno a efektivně díky lákavé kombinaci rychlosti a flexibility, kterou poskytují slovníky Pythonu.
Níže je uvedena ukázka kódu ukazující, jak používat slovník Pythonu:
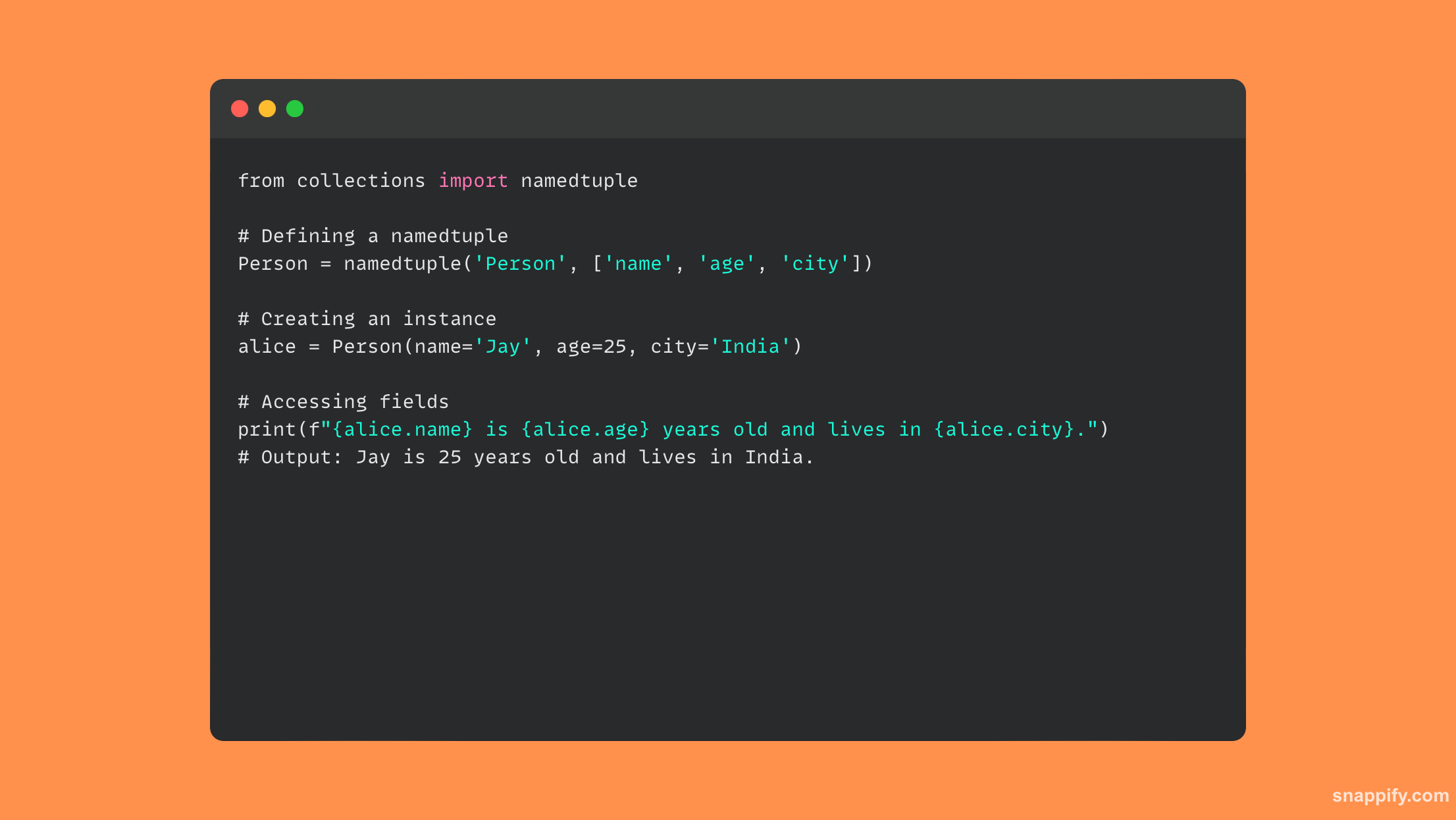
16. Vysvětlete výhody používání pojmenovaných n-tic.
Použití pojmenovaných n-tic v Pythonu dovedně kombinuje expresivitu tříd s jednoduchostí n-tic, což má za následek malou, samovysvětlující datovou strukturu.
Tradiční n-tice je rozšířena o pojmenované n-tice, které zachovávají neměnnost a paměťovou efektivitu n-tic a zároveň přidávají pojmenovaná pole pro zlepšení čitelnosti kódu a vlastního popisu.
Pojmenované n-tice podporují jasný, srozumitelný a výkonný kód vytvářením přímých a lehkých objektů bez jakýchkoliv metod, čímž zlepšují jak vývojářskou zkušenost, tak výpočetní výkon.
Výsledkem je, že se pojmenované n-tice vyvinou v výkonný nástroj, který zlepšuje strukturu dat a čitelnost bez kompromisů v rychlosti.
Ukázka kódu ilustrující použití pojmenovaných n-tic je uvedena níže:
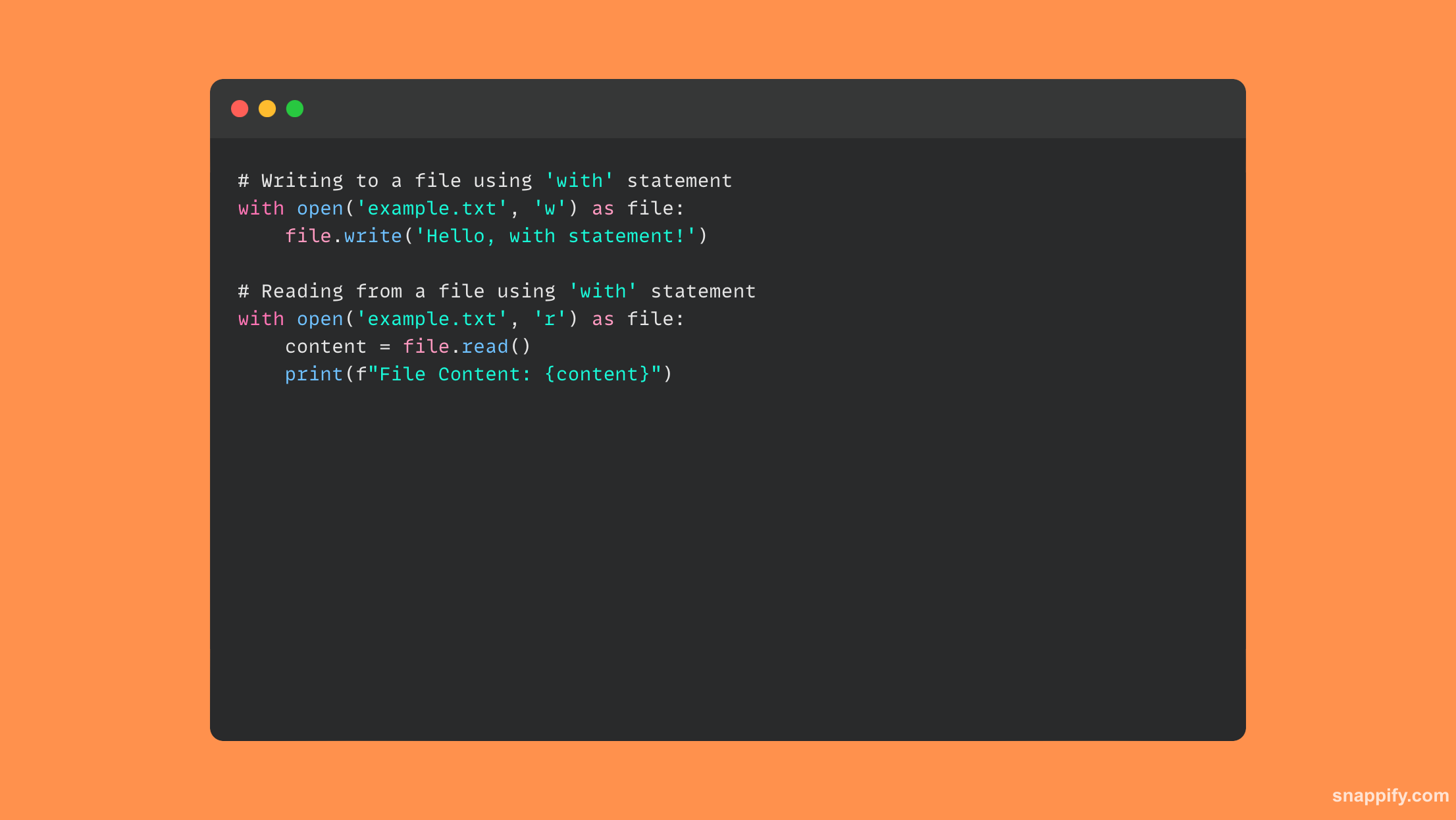
17. Jak funguje blok try-except?
Blok try-except funguje jako hlídač v expresivní syntaxi Pythonu, bedlivě chrání před nepravidelnostmi běhu a udržuje hladký průběh provádění navzdory potenciálním problémům.
Když blok try narazí na chybu, ovládací prvek se automaticky přenese do příslušného bloku kromě, kde je problém vyřešen nahlášením, opravou nebo možná opětovným vyvoláním výjimky.
Účelným a kontrolovaným zpracováním výjimek tento systém nejen chrání před rušivými pády, ale také zlepšuje uživatelská zkušenost a integritu dat.
Výsledkem je, že blok try-except dovedně kombinuje správu chyb s prováděním programu, což zaručuje robustnost a stabilitu aplikace.
Zde je malá ukázka kódu, který používá blok try-except:
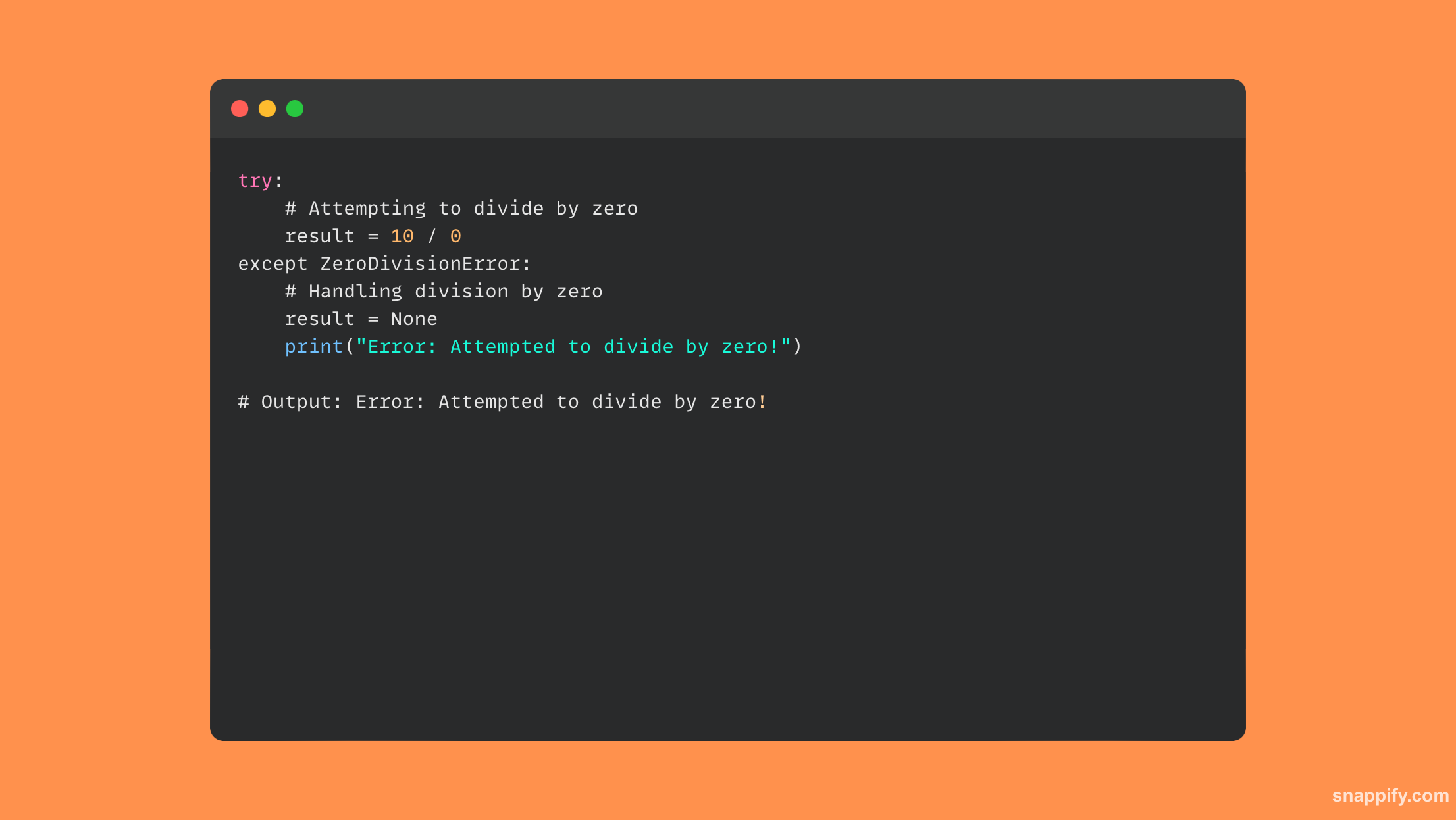
18. Jaký je rozdíl mezi tvrzeními o zvýšení a tvrzení?
Příkazy raise a statement v Pythonu pro zpracování chyb představují dva samostatné, ale související výrazy správy výjimek.
Projekt raise poskytuje programátorovi explicitní kontrolu nad chybovými zprávami a tokem tím, že jim umožňuje explicitně způsobovat specifikované výjimky.
Assertna druhé straně funguje jako ladicí nástroj automatickým generováním souboru AssertionError pokud není splněna jeho odpovídající podmínka, zaručující, že program během vývoje funguje tak, jak bylo zamýšleno.
Assert jednoduše kontroluje podmínky, zlepšuje ladění a ověřování, zatímco raise umožňuje širší a explicitnější kontrolu. Jak zvýšit, tak prosadit, povolují řízenou produkci výjimek.
Zde je ukázkový kód ukazující, jak používat raise a assert:
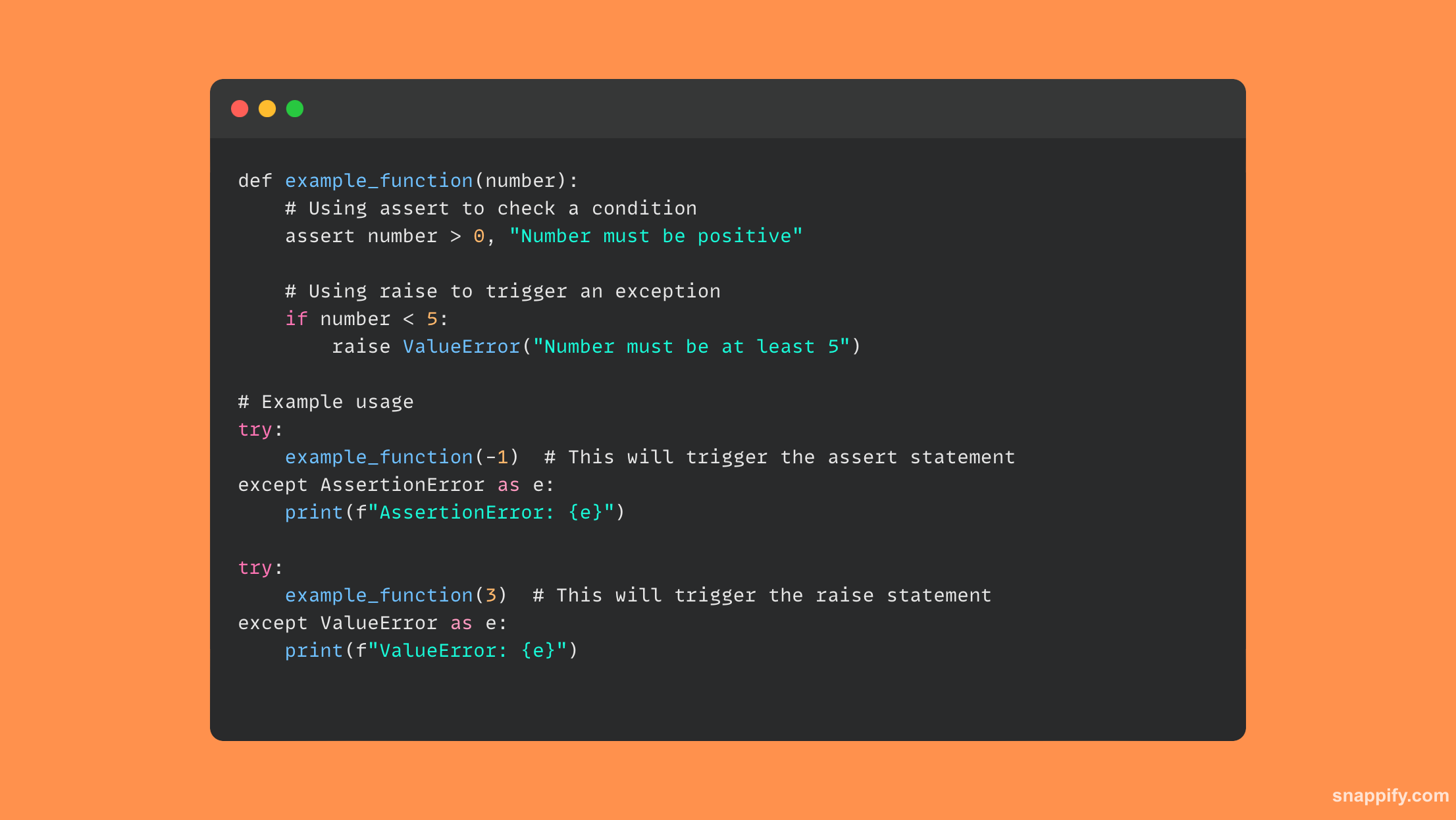
19. Jak čtete a zapisujete data z binárního souboru v Pythonu?
Pomocí vestavěné otevřené funkce se specifikátorem binárního režimu přináší propojení s binárními soubory v Pythonu rovnováhu mezi přesností a jednoduchostí.
Za použití rb or wb režimy při otevírání binárního souboru zajistí, že data budou při čtení nebo zápisu binárních dat zpracována v jejich nekódované, nezpracované podobě.
Použitím těchto režimů Python zjednodušuje správu netextových dat, jako jsou obrázky nebo spustitelné soubory, což umožňuje programátorům zpracovávat a analyzovat binární data přesně a snadno.
Proto operace s binárními soubory v Pythonu otevírají dveře široké škále aplikací, včetně serializace dat, zpracování obrazu a binární analýzy, abychom zmínili alespoň některé.
Pomocí binárního souboru tento příklad kódu ukazuje, jak číst a zapisovat data:
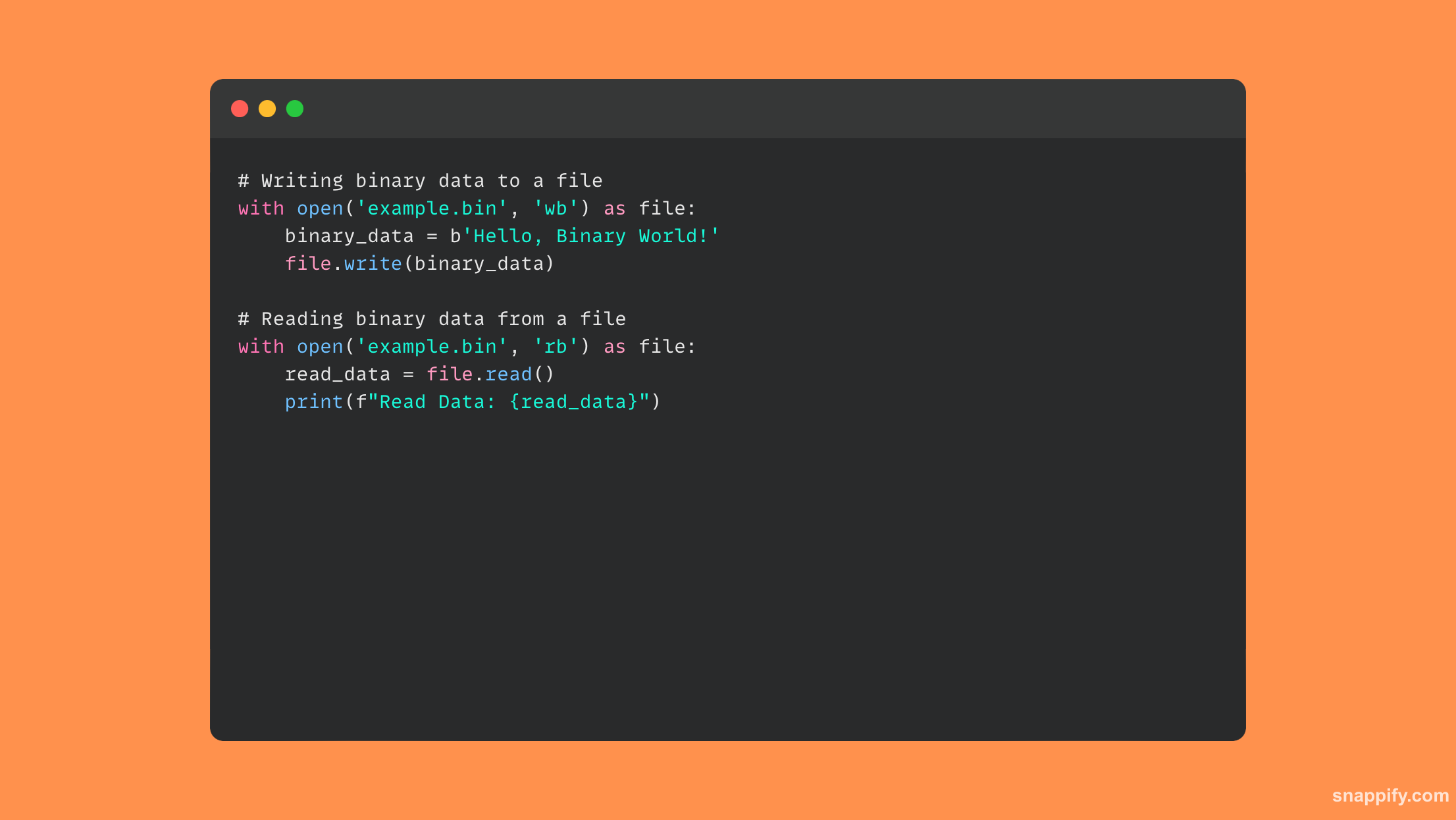
20. Vysvětlete with a jeho výhody při práci se souborovými I/O.
Příkaz Python's with, který se často používá se souborovými I/O, elegantně zajišťuje efektivní zacházení se zdroji díky myšlence správy kontextu.
Při práci se soubory, withpříkaz okamžitě zavře soubor po použití, i když během provádění akce dojde k výjimce, chrání před únikem prostředků a zaručuje čisté ukončení.
Odstraněním standardního kódu tento syntaktický cukr zlepšuje čitelnost kódu. Zvyšuje také spolehlivost a jednoduchost díky integraci správy zdrojů a zpracování výjimek.
V důsledku toho se příkaz with stává nezbytným pro zajištění spolehlivosti a čistoty operací se soubory, ochrany před nepředvídanými problémy a zlepšení srozumitelnosti kódu.
Zde je příklad kódu, který používá with příkaz v operacích se soubory:
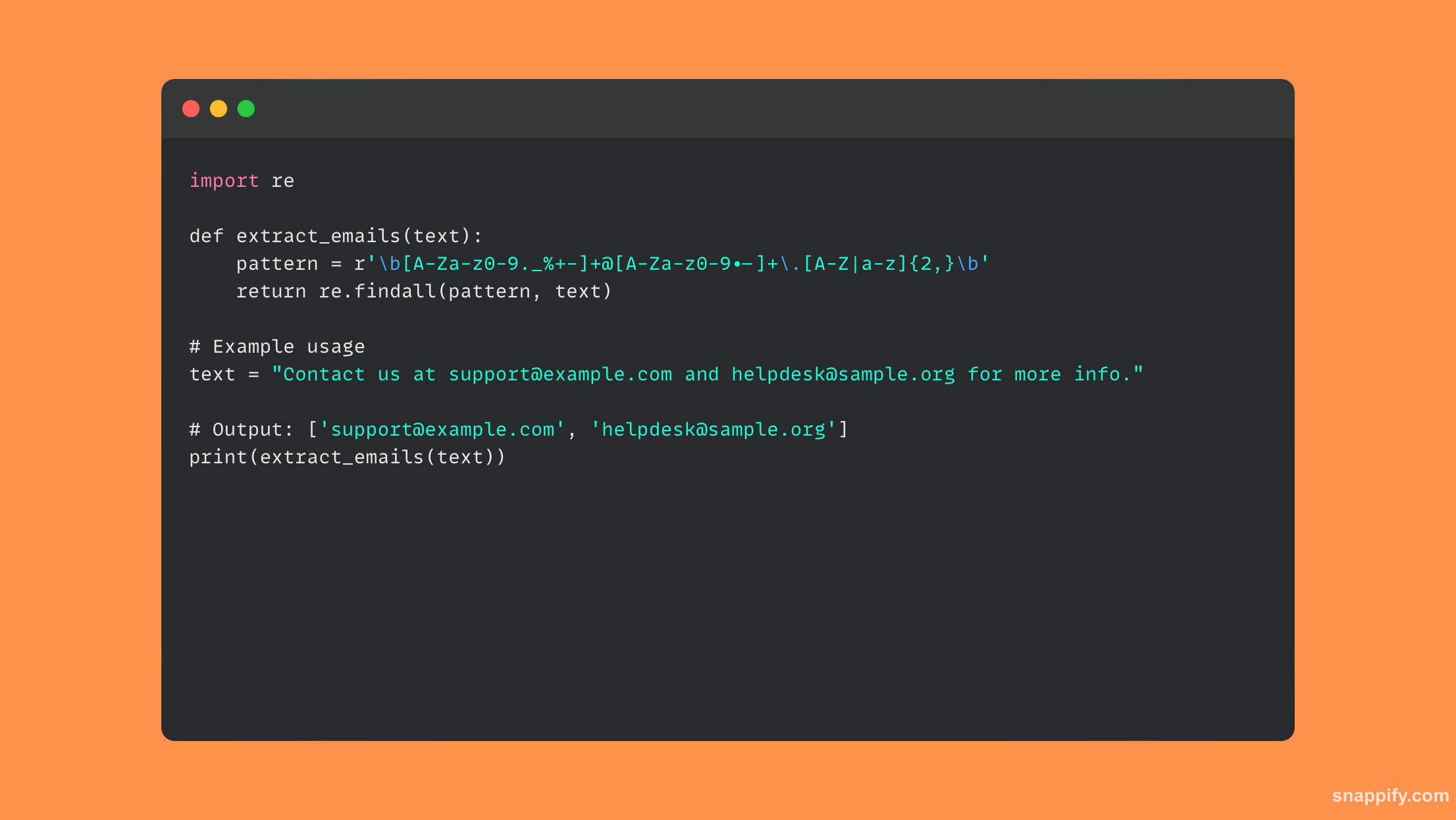
21. Jak byste vytvořili singleton modul v Pythonu?
Kombinace metod třídy a interních kontrol se používá k vytvoření modulu singleton v Pythonu, což je návrhový vzor, který umožňuje vytvoření pouze jedné instance třídy.
Tím, že třída udržuje sledování své vlastní instance a poskytuje metodu pro její generování nebo vracení, následuje tento vzor, aby zajistila, že následující instance replikují první instanci.
Díky jedinému bodu kontroly, jednotnému přístupu ke zdrojům a ochraně proti konkurenčním manipulacím zajišťuje singleton jeden bod kontroly.
Výsledkem je, že se vyvíjí v účinný nástroj pro zapouzdření sdílených zdrojů, který zaručuje konzistentní přístup a úpravy v rámci programu.
Zde je malá ukázka kódu Python demonstrující třídu singleton:
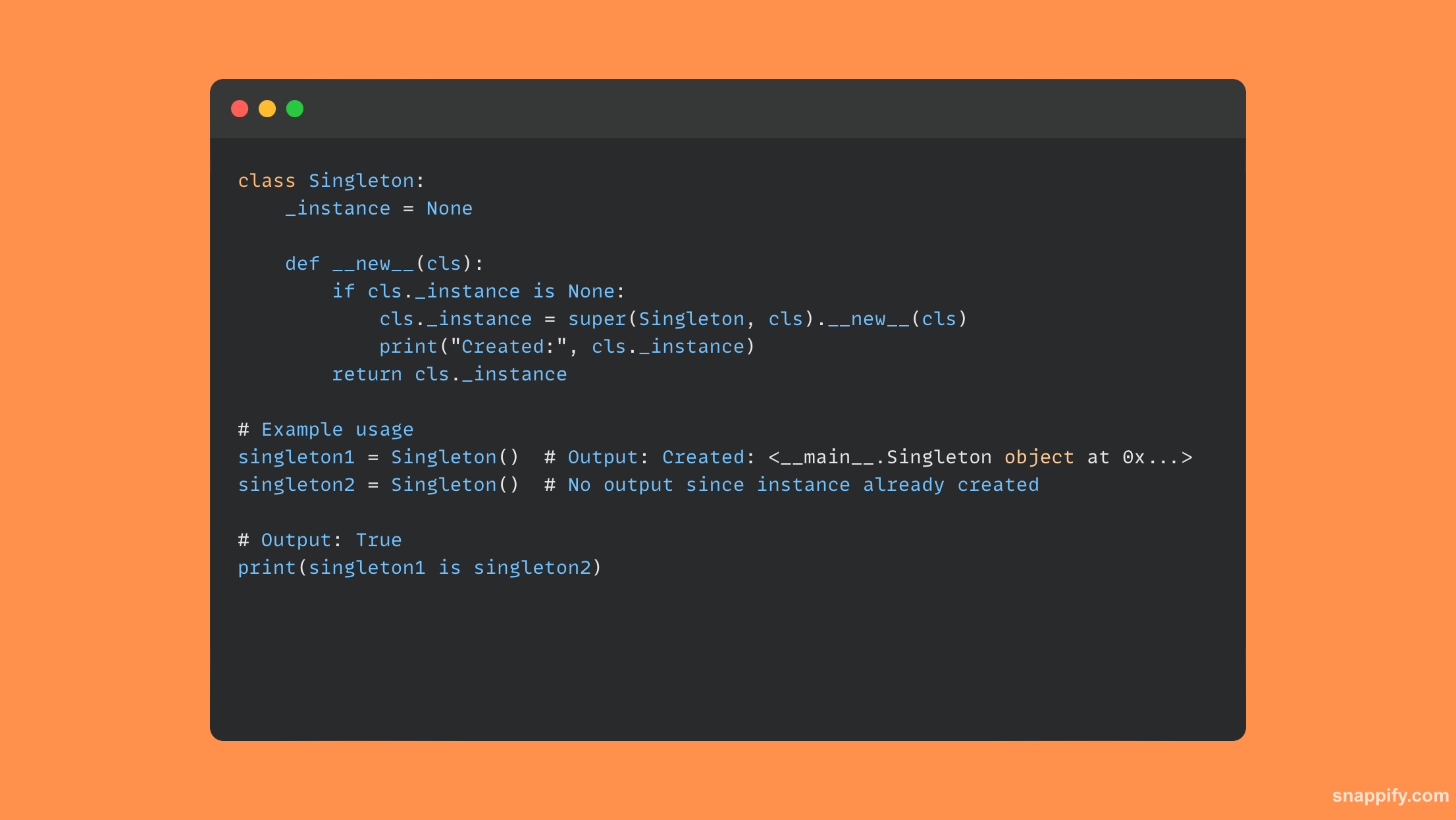
22. Uveďte několik způsobů, jak optimalizovat využití paměti ve skriptu Python.
Optimalizace spotřeby paměti skriptu Python často vyžaduje pečlivé vyvažování mezi výběrem datové struktury, vylepšením algoritmu a správou zdrojů.
Při práci s obrovskými datovými sadami může například použití generátorů namísto seznamů výrazně minimalizovat využití paměti tím, že bude líné vyhodnocovat položky za běhu, místo aby je uchovávali v paměti.
Další snížení využití paměti je možné nakládáním s numerickými daty s datovými strukturami pole spíše než se seznamy a šetrným používáním __slots__ in-class deklarace pro řízení tvorby dynamických atributů.
Vyvážením výkonu a využití zdrojů tedy můžete zajistit, že programy Pythonu budou nejen efektivní, ale také promyšlené v tom, kolik paměti používají.
Zde je krátký příklad kódu, který používá generátor ke snížení množství použité paměti:
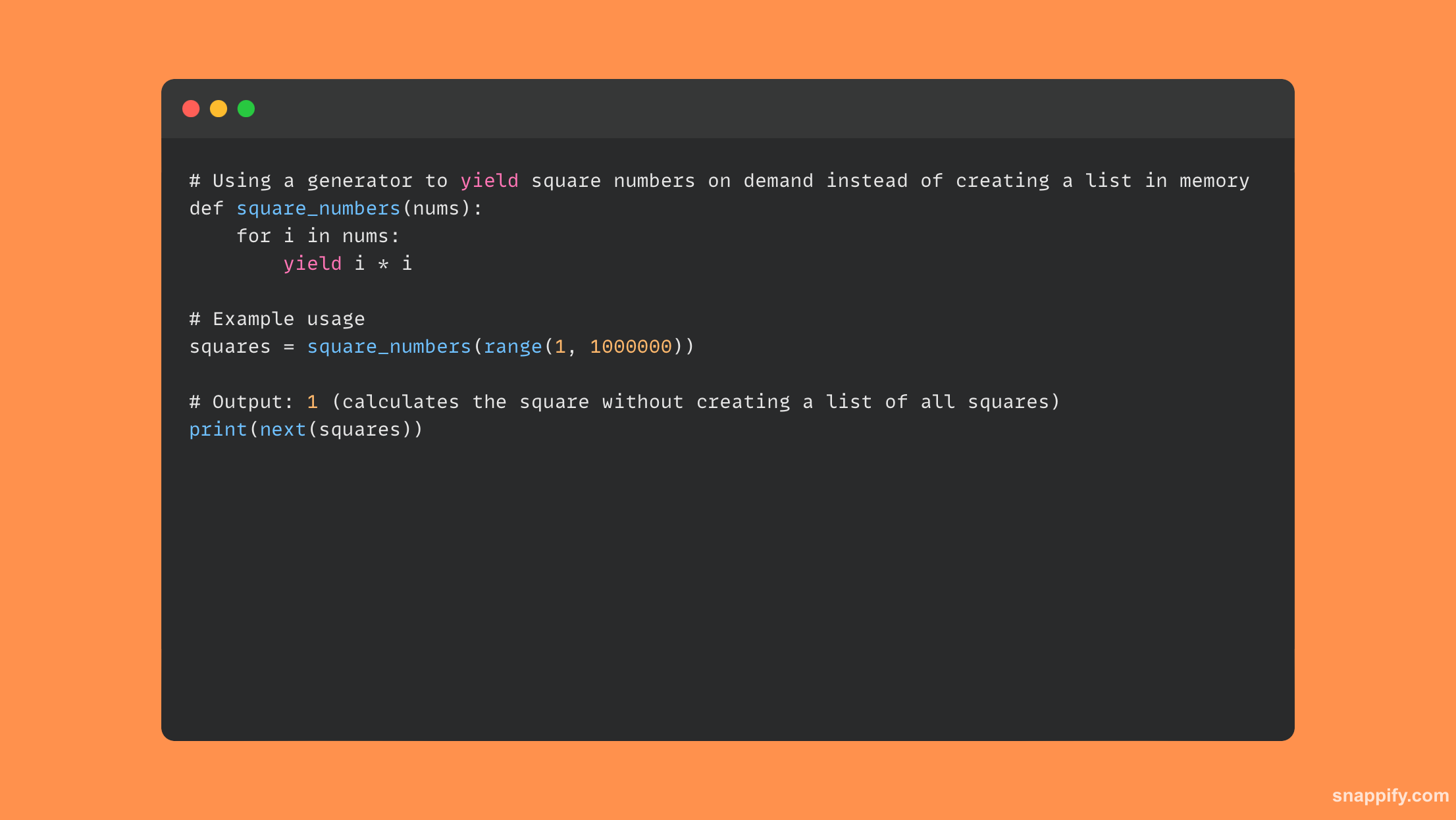
23. Jak byste extrahovali všechny e-mailové adresy z daného řetězce pomocí regulárního výrazu?
Regulární výrazy (regex) v Pythonu kombinují přesnost a všestrannost k extrahování e-mailových adres z řetězce, což umožňuje vývojáři obratně filtrovat textový materiál a identifikovat žádoucí vzory.
Chcete-li vytvořit strukturu e-mailové adresy, vytvořte vzor regulárního výrazu pomocí re-modulu. Pak můžete použít findall získat všechny výskyty z cílového řetězce.
Tato metoda odborně prochází textovým bludištěm, aby získala všechny skryté e-mailové adresy, což nejen urychluje proces extrakce, ale také zajišťuje správnost.
Regex lze dovedně použít k efektivnímu extrahování určitých dat z řetězců, což zvyšuje zpracování dat a analýzu skriptů Python.
Zde je část kódu, který používá regex k extrahování e-mailů:
24. Vysvětlete návrhový vzor Factory a jeho aplikaci v Pythonu
Základní princip objektově orientovaného programování, tovární návrhový vzor, je vytváření objektů bez identifikace přesné třídy objektů, které mají být generovány.
Vzor Factory lze elegantně implementovat v Pythonu vytvořením metody, která vrací instance několika tříd v závislosti na vstupech nebo konfiguracích metody.
Tato procedura, která je někdy označována jako „továrna“, funguje jako rozbočovač pro splétání několika instancí tříd a zaručuje, že objekty budou vytvořeny, aniž by volající musel ručně vytvářet instance tříd.
Vzor Factory si tedy zachovává oddělenou, škálovatelnou architekturu a zároveň zlepšuje modularitu a soudržnost kódu. Nabízí také zjednodušenou techniku stavby objektů.
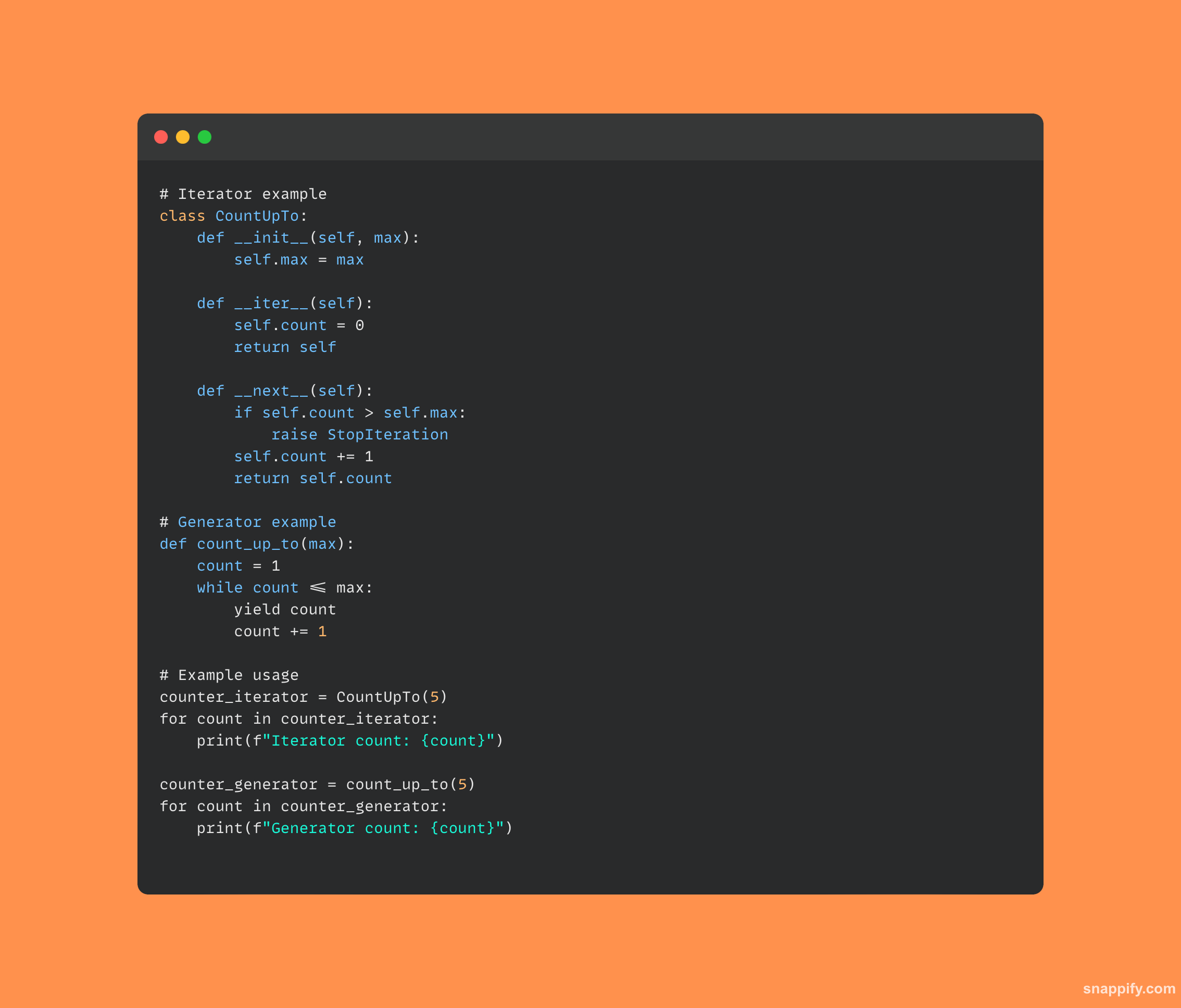
25. Jaký je rozdíl mezi iterátorem a generátorem?
Z iterátorů a generátorů Pythonu je zřejmé, že obě konstrukce umožňují procházet hodnoty, nicméně existují jemné rozdíly v tom, jak jsou implementovány a používány.
Generátor, který je často identifikován použitím výnosu, automaticky udržuje svůj stav a je implementován pomocí funkce, která poskytuje stručný a paměťově efektivní způsob vytváření hodnot za chodu.
Iterátor, který je obvykle implementován jako třída, používá metody jako __iter__ a __next__ spravovat svůj iterační stav a vytvářet hodnoty.
Výsledkem je, že každý má své vlastní přednosti založené na konkrétním případu použití, přičemž iterátory nabízejí důkladný, objektově orientovaný způsob procházení dat, zatímco generátory nabízejí lehkou a línou vyhodnocovací techniku.
Obě techniky rozšiřují vývojářský arzenál a umožňují rychle a efektivně zkoumat data v různých situacích.
Zde je část kódu iterátoru a generátoru v Pythonu:
26. Jak funguje @property malířské práce?
Dekorátor '@property' v Pythonu hraje krásnou melodii, která převádí volání metod na přístup podobný atributům, čímž zlepšuje použitelnost a expresivitu objektů.
Metodu lze volat bez použití závorek pomocí @property, což je podobné přístupu k atributu. To vytváří přehlednější a snáze použitelné rozhraní pro interakci s objekty.
Navíc nabízí obratnou rovnováhu mezi funkčností a zapouzdřením, chrání stavy objektů a zároveň poskytuje intuitivní rozhraní, které umožňuje vývojářům snadno specifikovat atributy pomocí metod getter a setter.
Kombinací funkčnosti metody s přístupností atributů, @property dekoratér se ukazuje jako klíčový nástroj a nabízí přímočaré, ale účinné paradigma interakce s objektem.
Příklad Pythonu @property dekoratér je zobrazen níže:
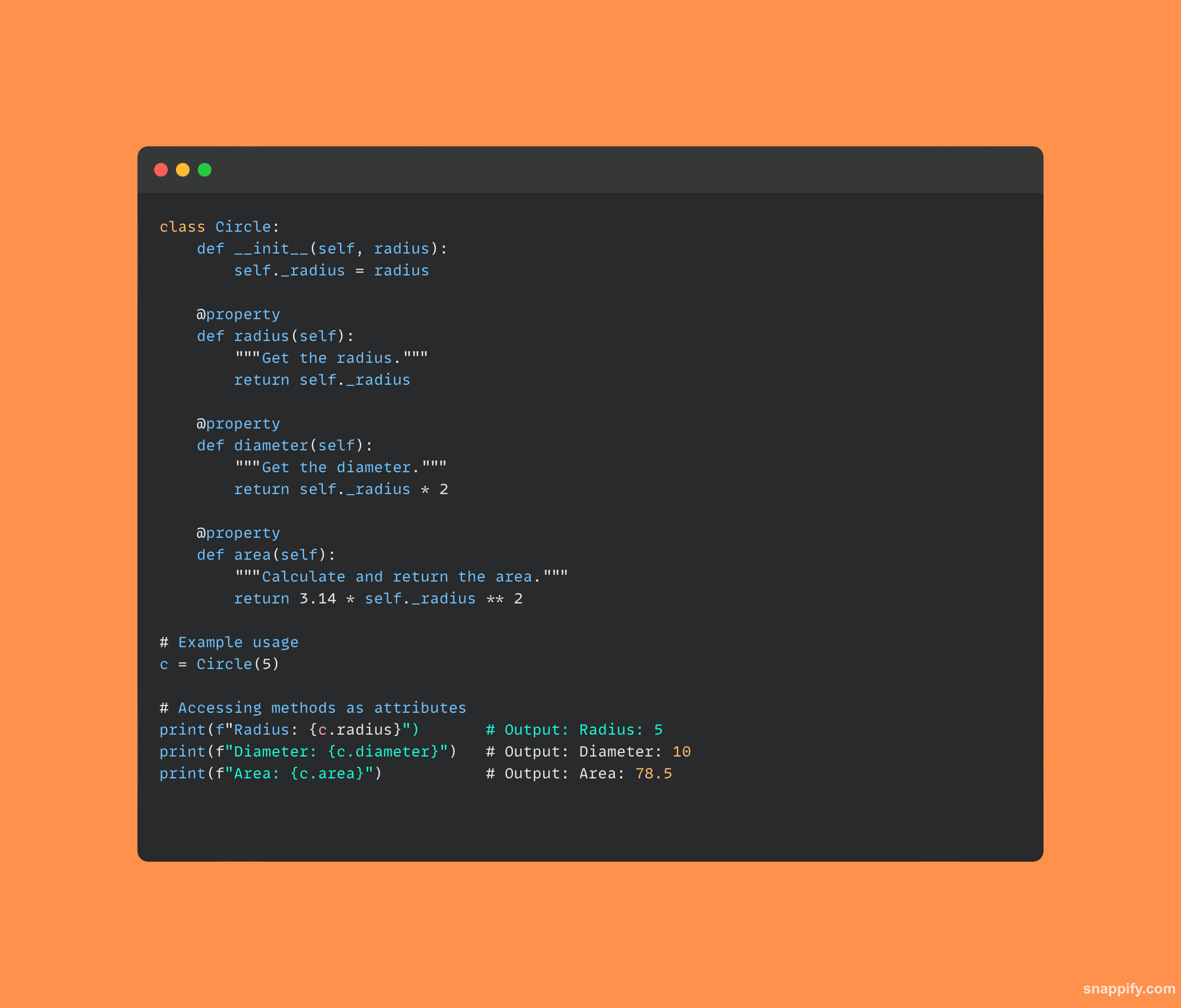
27. Jak byste vytvořili základní REST API v Pythonu?
Aby bylo možné vytvářet webové služby, které interagují prostřednictvím požadavků HTTP, vývojáři často využívají vyjadřovací schopnosti rámců, jako je Flask, při vytváření jednoduchého REST API v Pythonu.
Díky své jednoduché a srozumitelné syntaxi umožňuje Flask vývojářům vytvářet trasy, ke kterým lze přistupovat řadou metod HTTP, včetně GET a POST, pro komunikaci se základní aplikací.
REST API vytvořené pomocí Flask může snadno přijímat požadavky HTTP, zpracovávat obsažená data a poskytovat relevantní informace v reakci tím, že specifikuje jedinečné koncové body spojené s různými funkcemi.
Aby byla zajištěna bezproblémová komunikace mezi různými softwarovými komponentami v síťovém prostředí, mohou vývojáři používat výkonná REST API pomocí kombinace Python a Flask.
Zde je malý kousek kódu, který používá Flask k vytvoření REST API:
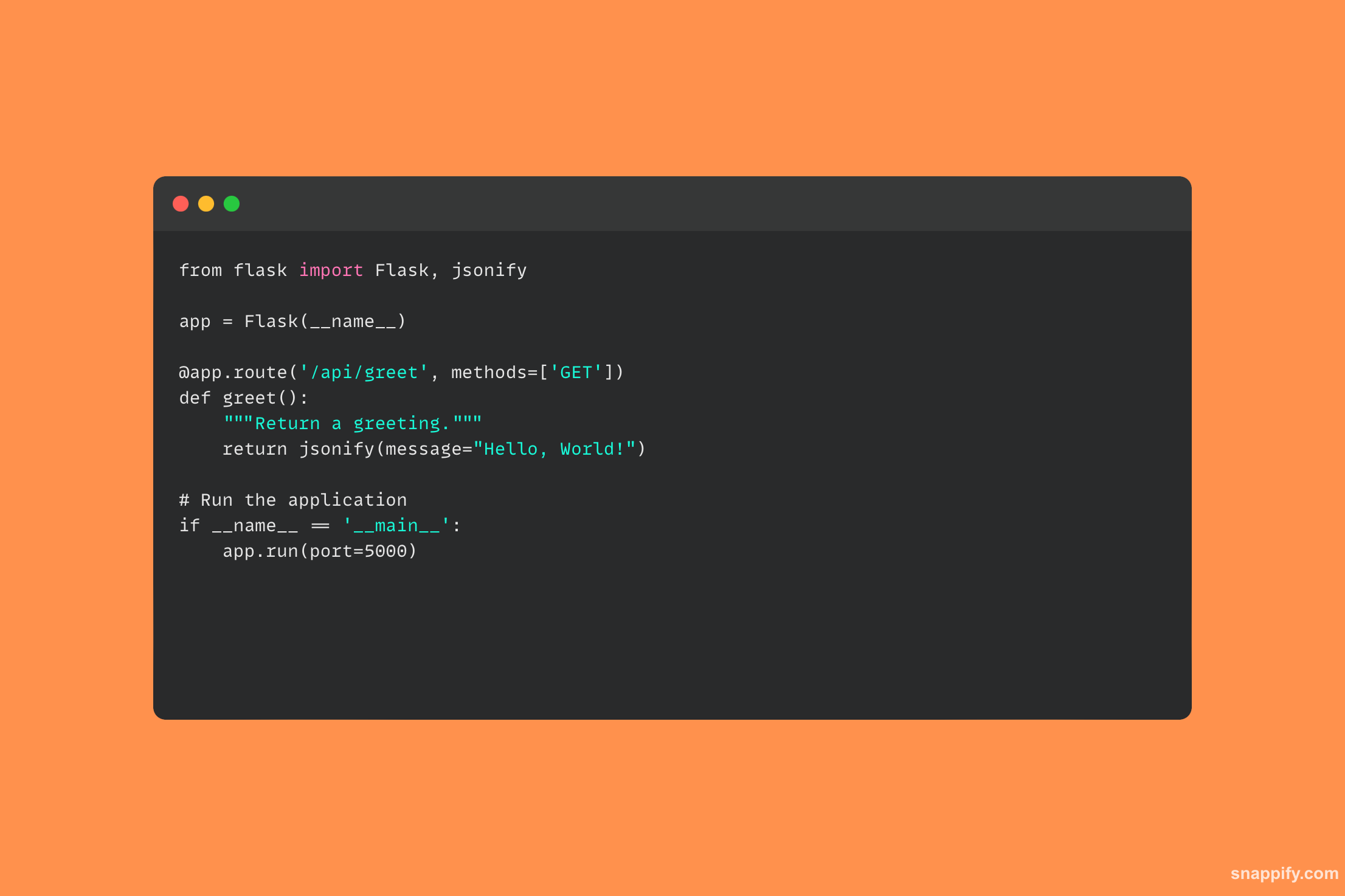
28. Popište, jak používat knihovnu požadavků k vytvoření požadavku HTTP POST.
Knihovna požadavků Pythonu je mocný nástroj, který transformuje potíže s HTTP komunikací na uvítací API a umožňuje jednoduchou a přirozenou interakci s online službami pomocí HTTP POST požadavků.
Požadavek POST se provádí pomocí metody post, zadáním cílové adresy URL a připojením materiálu k odeslání, který může obsahovat data formuláře, JSON, soubory a další.
Knihovna požadavků pak spravuje základní připojení HTTP, odesílá data na určenou adresu URL a shromažďuje odpověď serveru, aby umožnila plynulé webové interakce.
Vývojáři se mohou snadno zapojit do online služeb, odesílat data z formulářů a vytvářet rozhraní s webovými rozhraními API prostřednictvím požadavků, čímž překlenují propast mezi místními aplikacemi a globálním webem.
Pomocí knihovny požadavků následující ukázka kódu ukazuje, jak odeslat požadavek HTTP POST:
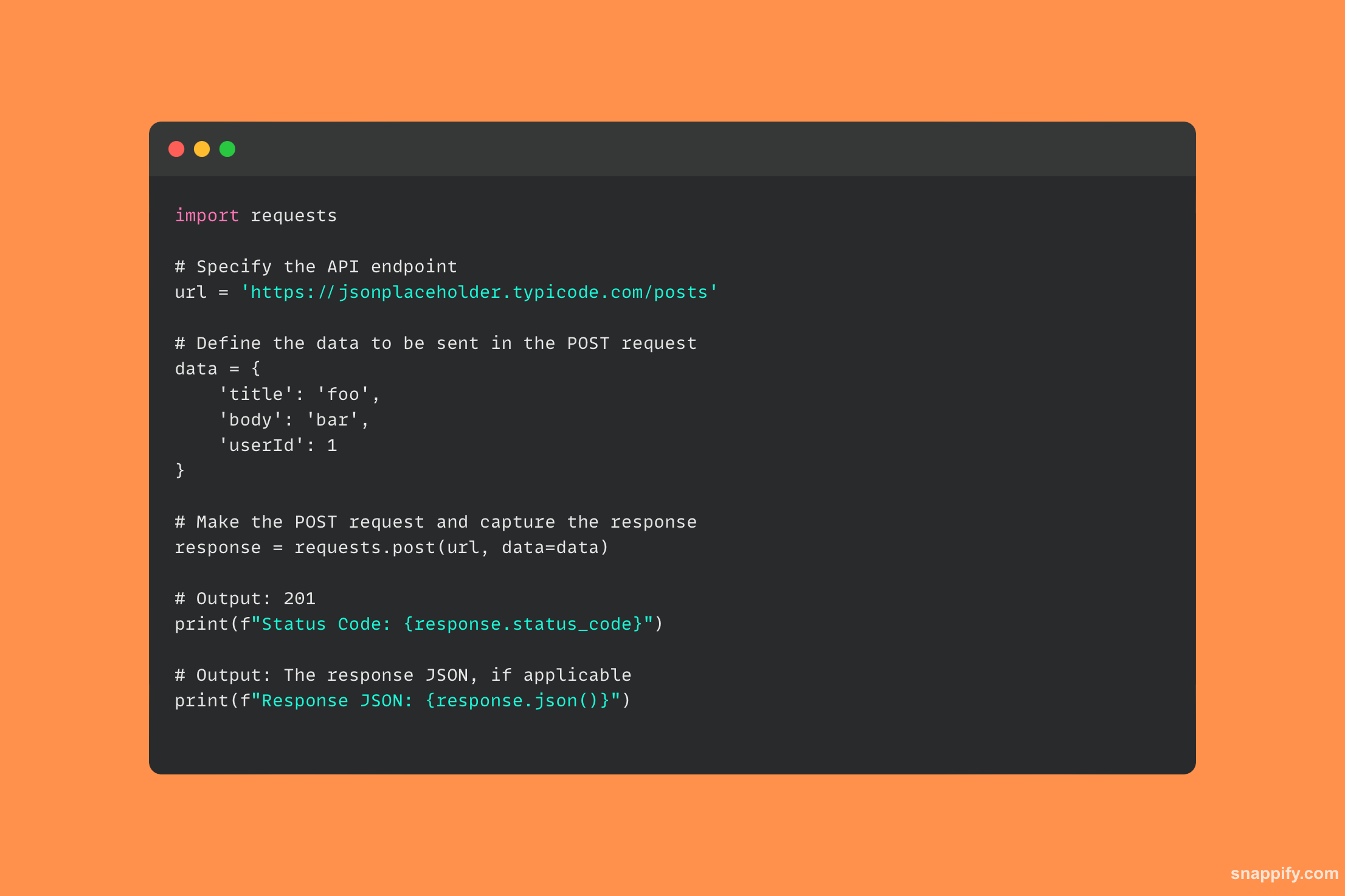
29. Jak byste se připojili k databázi PostgreSQL pomocí Pythonu?
Práce s databází PostgreSQL z prostředí Pythonu je řešena elegantně balíčkem psycopg2, výkonným mostem, který umožňuje bezproblémovou interakci s databází.
Pomocí psycopg2, programátoři mohou snadno vytvářet připojení, spouštět dotazy SQL a získávat výsledky, přímou integrací schopností PostgreSQL do programů Python.
Složité databázové funkce můžete odemknout pouze pomocí několika řádků kódu, což zaručuje, že k datům bude přistupováno, upravovány a ukládány s přesností a účinností.
Tento modul umožňuje vývojářům plně využívat relační databáze ve svých aplikacích tím, že elegantně realizuje synergii mezi Pythonem a PostgreSQL.
Zde je ukázkový kód, který ukazuje, jak používat psycopg2 knihovny pro navázání připojení k databázi PostgreSQL:
30. Jaká je role ORM v Pythonu a jmenujte populární?
Objektově relační mapování (ORM) v Pythonu umožňuje vývojářům propojit se s databázemi pomocí tříd Python a objektových paradigmat.
Funguje jako harmonický prostředník mezi objektově orientovaným programováním a správou relačních databází.
SQLAlchemy, jeden z nejznámějších ORM v prostředí Pythonu, nabízí kompletní sadu nástrojů pro interakci s více databázemi SQL pomocí objektově orientované syntaxe na vysoké úrovni.
S pomocí SQLAlchemy lze databázové entity reprezentovat jako třídy Python, přičemž instance těchto tříd slouží jako řádky v databázových tabulkách.
To umožňuje programátorům pracovat s databázemi, aniž by museli psát nějaké nezpracované SQL dotazy.
Vzhledem ke složitosti SQL a databázové konektivity umožňují ORM, jako je SQLAlchemy, uživatelsky přívětivější, bezpečnější a udržovatelnější databázové interakce.
Zde je jednoduchý příklad ukazující, jak SQLAlchemy funguje:
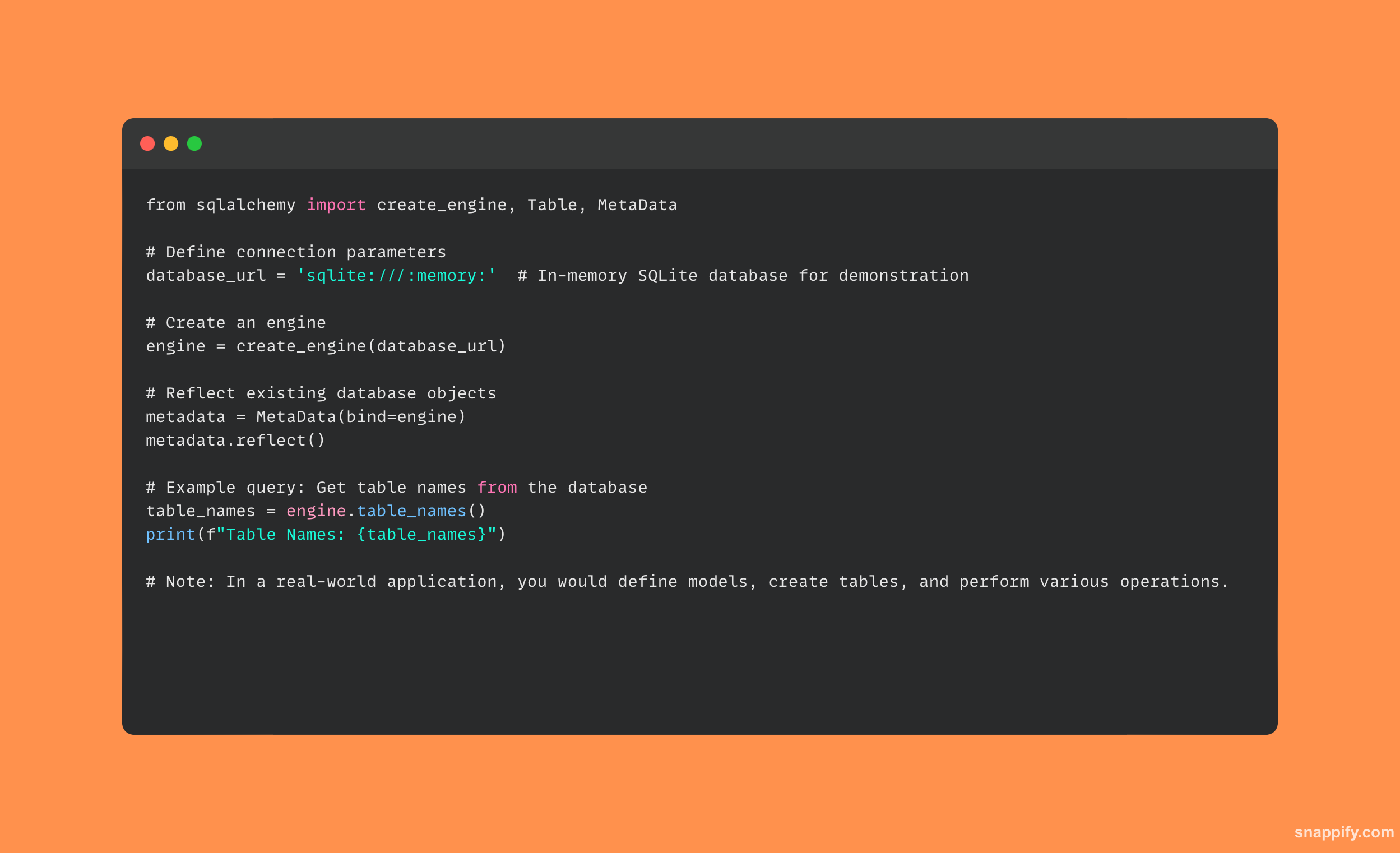
31. Jak byste profilovali skript Python?
Skript v Pythonu je profilován analýzou jeho výpočetní struktury a časových a prostorových podrobností jeho provádění, aby se našly všechny možné překážky výkonu a zlepšila se efektivita.
Vývojáři mohou pečlivě analyzovat chování svého kódu během běhu pomocí vestavěného cProfile modul.
Díky tomu mohou získat důkladná data o volání funkcí, dobách provádění a vztazích volání, což jim umožňuje identifikovat a řešit problémová místa výkonu.
Zahrnutím profilování do životního cyklu vývoje můžete zaručit, že kód bude fungovat nejen správně, ale také efektivně, vyvážením výpočetních zdrojů a zlepšením celkového výkonu aplikace.
Vývojáři proto mohou chránit programy před neefektivitou pečlivým profilováním, které zajistí, že budou spolehlivě vyladěny a výkonné v celé řadě výpočetních požadavků.
Zde je jednoduchý příklad profilování skriptů Python pomocí cProfile modul:
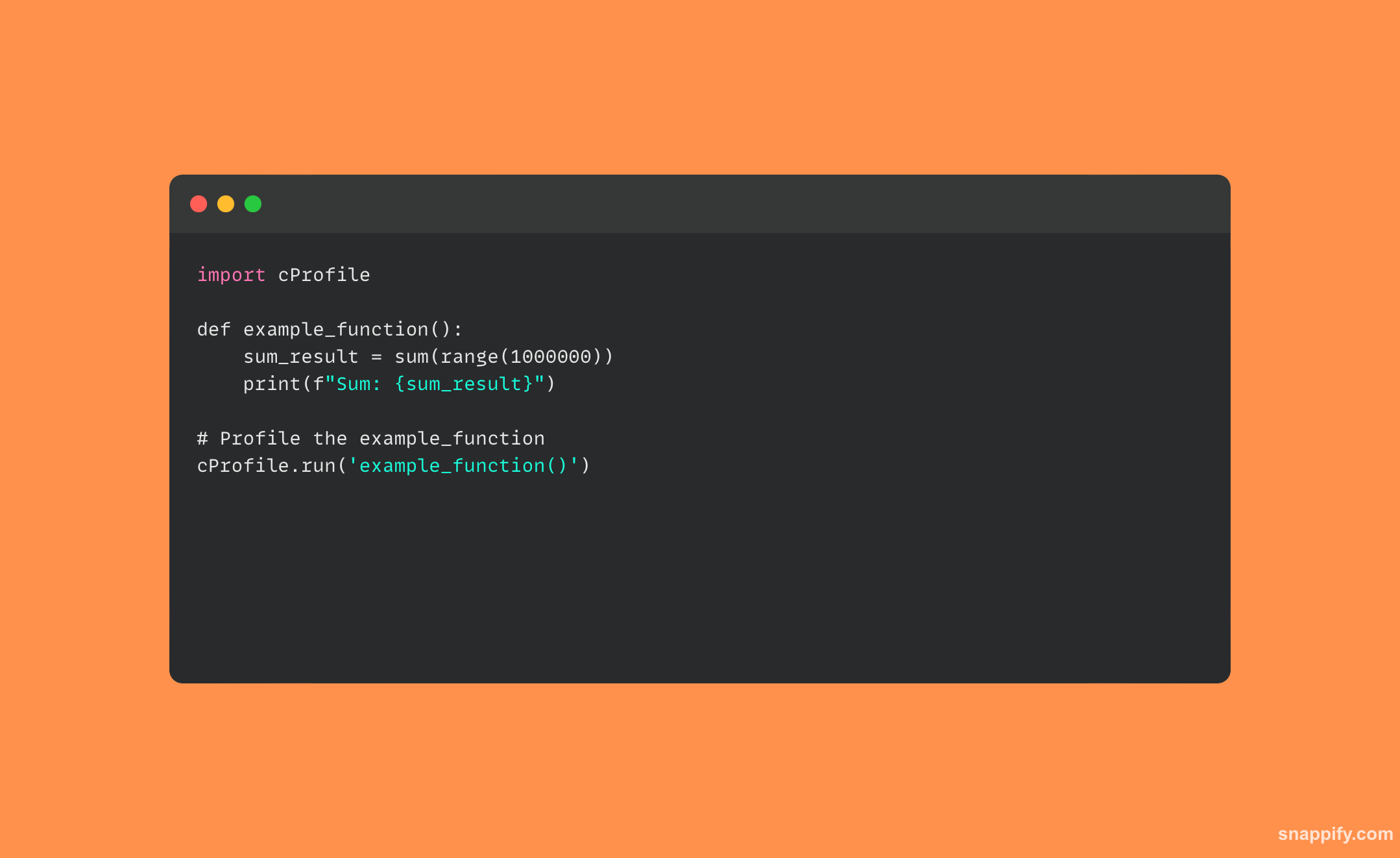
32. Vysvětlete GIL (Global Interpreter Lock) v CPythonu
Global Interpreter Lock (GIL) v CPythonu funguje jako hlídač, který zaručuje, že pouze jedno vlákno spouští bajtový kód Pythonu najednou v jediném procesu, a to i ve vícevláknových aplikacích.
I když se to může zdát jako úzké hrdlo, GIL je zásadní pro ochranu správy paměti a interních datových struktur CPythonu před souběžným přístupem a zachování integrity systému.
Nutnost multithreadingu v I/O-vázaných aktivitách, kde vlákna musí čekat na doručení nebo přijetí dat, je však třeba mít na paměti, protože GIL tuto potřebu neeliminuje.
I když GIL představuje potíže pro činnosti vázané na CPU, pochopení jeho chování a přizpůsobení technik, jako je použití multiprocesingu nebo souběžného programování, umožňuje vývojářům vytvářet efektivní, souběžné programy Pythonu.
Zde je příklad kódu Pythonu, který používá vlákna a ukazuje, jak by GIL mohl mít vliv na úlohy vázané na CPU:
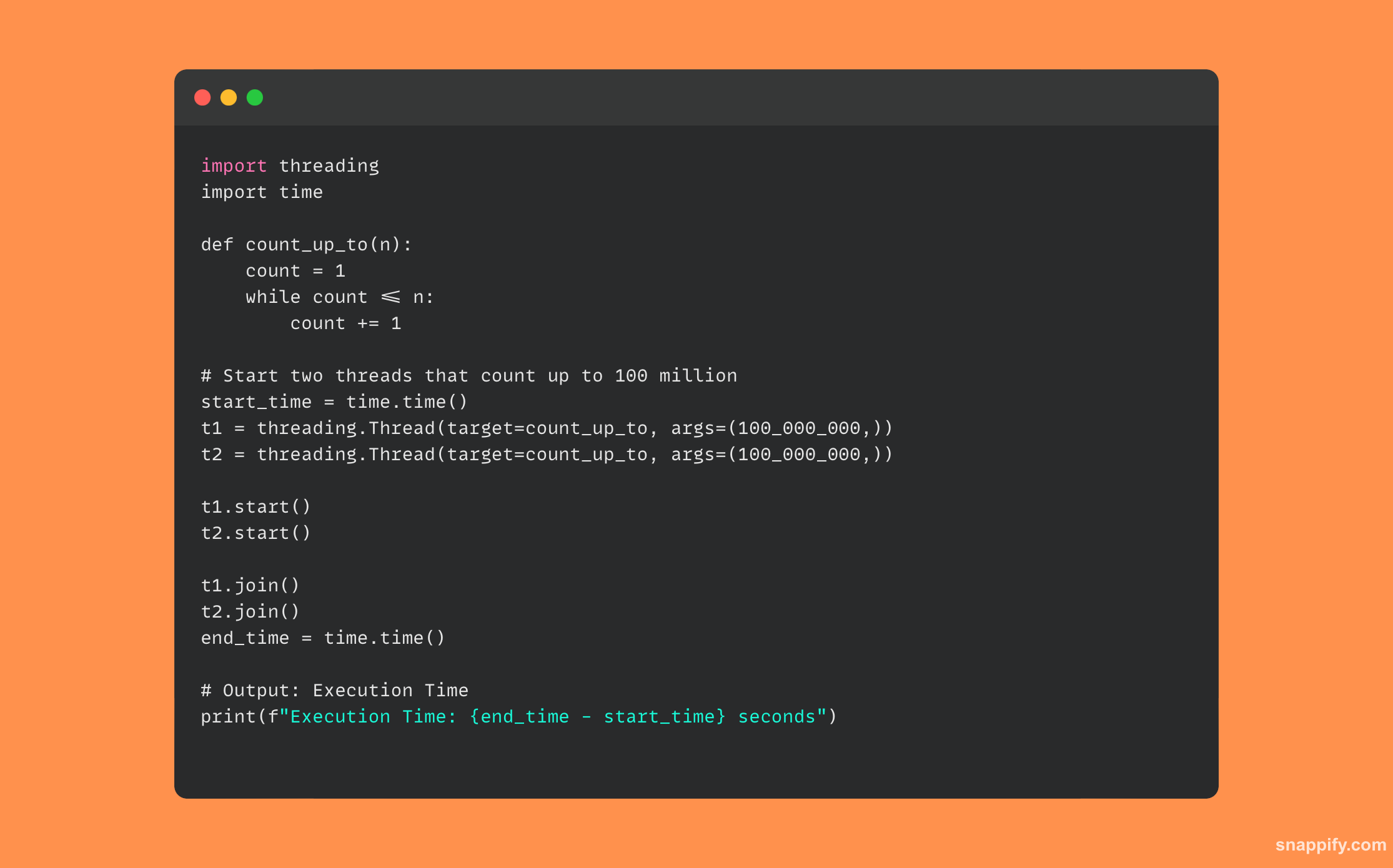
33. Vysvětlete async/wait Pythonu. Jak se liší od tradičního navlékání?
Syntaxe async/await v Pythonu otevírá svět asynchronního programování, což je paradigma, které umožňuje některým funkcím postoupit řízení běhovému prostředí, aby se mezitím mohly provádět jiné činnosti, což zlepšuje efektivitu programu.
Async/await udržuje aktivity v jednom vlákně, ale umožňuje provádění přeskakovat mezi úkoly, což zajišťuje neblokující chování bez složitosti správy vláken.
To je na rozdíl od klasického vlákna, kde vlákna probíhají paralelně a často vyžadují komplikovanou správu a synchronizaci.
Výsledkem je, že vývojáři mohou efektivně zvládat souběžné I/O aktivity s přímočařejším přístupem k řízení souběžnosti.
To podporuje kooperativní multitaskingový model, ve kterém procesy ochotně poskytují kontrolu.
Výsledkem je, že async/await nabízí výrazný, zjednodušený způsob navrhování souběžných aplikací, zejména tam, kde jsou běžné I/O operace, a nalézá rovnováhu mezi výkonem a složitostí.
Níže je uveden příklad kódu Python, který používá async/await:
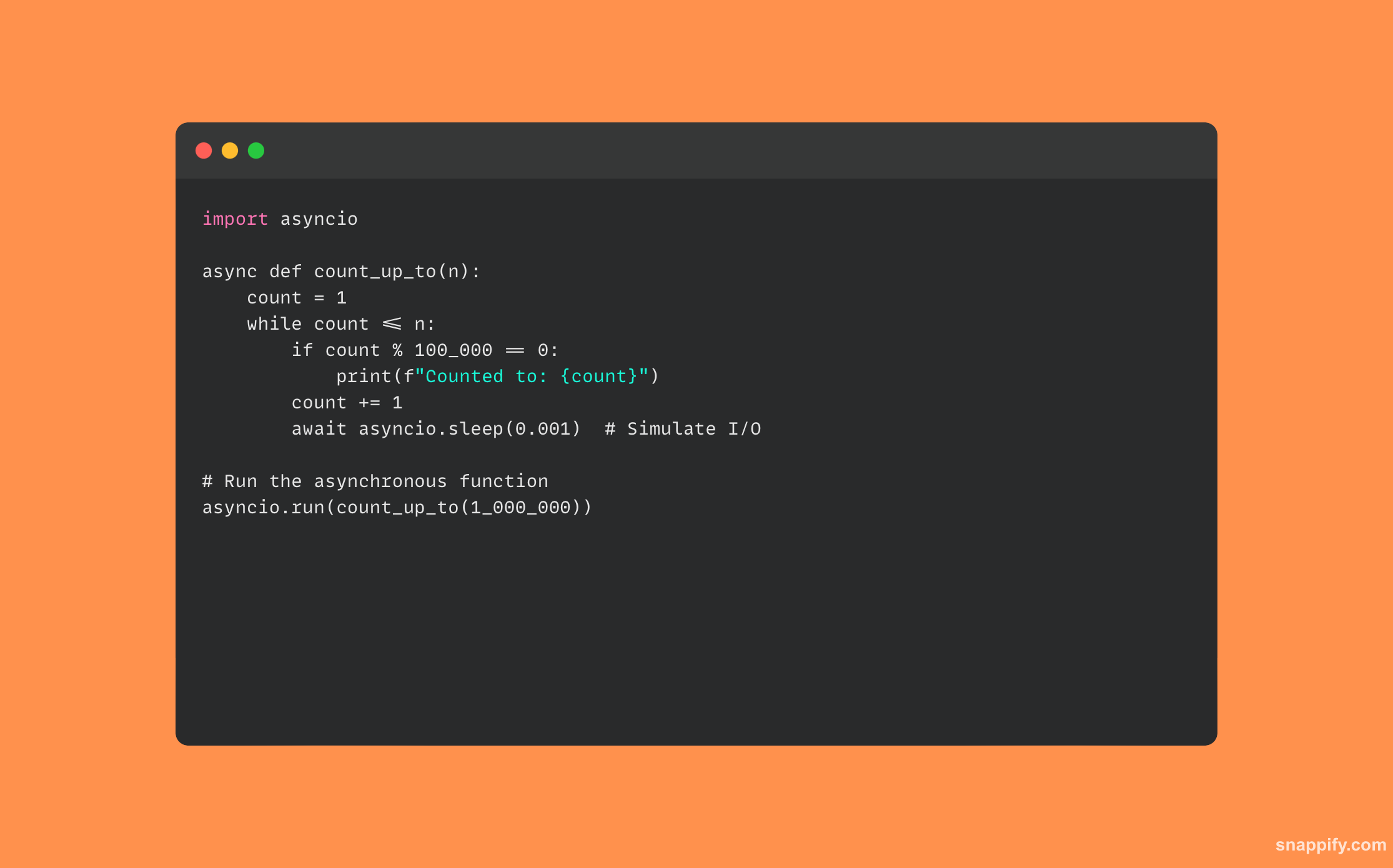
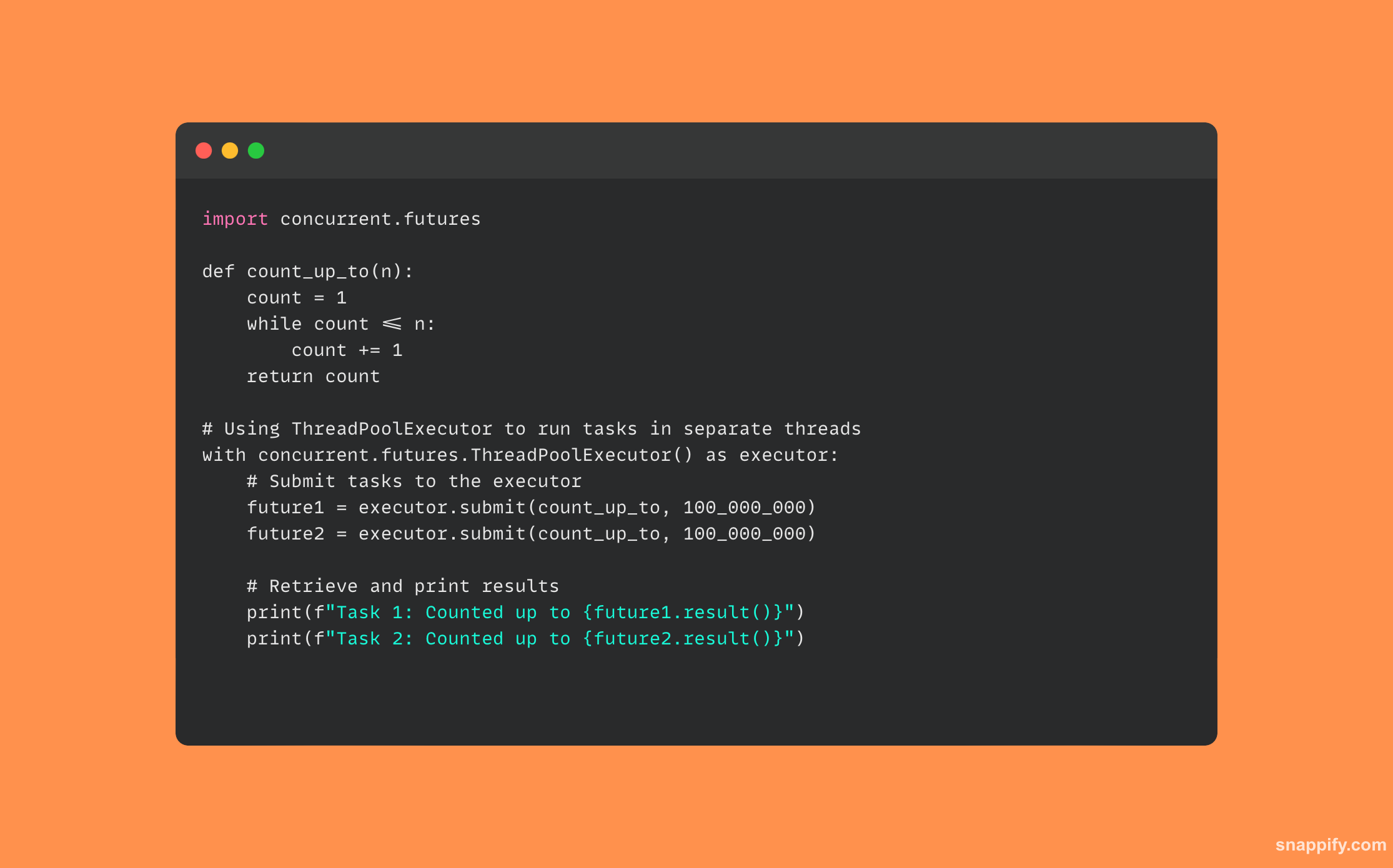
34. Popište, jak byste použili Python concurrent.futures.
rozhraní pro asynchronní provádění callable prostřednictvím vláken nebo procesů mohou vývojáři elegantně spravovat asynchronní a paralelní operace.
Tento modul spravuje alokaci zdrojů a provádění callables a zároveň zapouzdřuje choulostivé aspekty vláken a multiprocesingu prostřednictvím Executorů (ThreadPoolExecutor a ProcessPoolExecutor).
Vývojáři mohou efektivně využívat vícejádrové procesory pro činnosti vázané na CPU a poskytovat neblokující I/O operace odesíláním úloh exekutoru, který je pak může provádět souběžně a dokonce agregovat jejich výsledky.
Aby bylo zajištěno, že aplikace budou responzivní a výkonné, concurrent.futures vytváří prostor, kde se mohou složité výpočty a I/O činnosti hladce sloučit.
Zde je ukázka kódu, který používá concurrent.futures:
35. Porovnejte Django a Flask z hlediska případu použití a škálovatelnosti.
Dvě hvězdy v souhvězdí webových frameworků Pythonu, Django a Flask, každá jasně září a zároveň splňují různé vývojářské požadavky.
Pro programátory vytvářející masivní aplikace založené na databázích je Django nástrojem volby, protože přichází s ORM a vestavěným administrátorským rozhraním.
Jednoduchý a modulární design Flask však dává vývojářům svobodu při výběru vlastních komponent, což z něj dělá perfektní volbu pro menší projekty nebo situace, kde je zásadní lehké a přizpůsobivé řešení.
Oba rámce lze škálovat tak, aby vyhovovaly vyšším požadavkům, pokud jde o škálovatelnost.
Štíhlá povaha Flasku však umožňuje přizpůsobené taktiky škálování, které jsou přizpůsobeny konkrétním potřebám, zatímco vestavěné schopnosti Django mu mohou poskytnout malou výhodu pro rychlý vývoj ve větších a komplikovanějších projektech.
Proč investovat do čističky vzduchu?
Python skriptovací rozhovory vyžadují důkladnou znalost schopností jazyka, složitosti a aplikací.
Důkladná příprava nejen posiluje technickou způsobilost, ale také vzbuzuje důvěru a pomáhá uchazečům rychle a přesně se pohybovat v obtížném bludišti otázek.
Uchazeči se mohou ujistit, že jsou připraveni zvládnout základní i aplikované problémy Pythonu tím, že si prostudují klíčové myšlenky, jako je souběžnost, principy OOP a datové struktury, a také se ponoří do praktických aplikací, jako je webové programování a manipulace s daty.
V důsledku toho se všestranné vzdělání stává nezbytným předpokladem úspěchu a může vést k situacím, kdy něčí schopnosti programování v Pythonu mohou vynikat a být kreativní. Vidět Hašdorkův seriál rozhovorů za pomoc s přípravou na pohovor.





Napsat komentář