És una tasca crucial i desitjable en visió per ordinador i gràfics produir pel·lícules creatives de retrats del més alt calibre.
Tot i que s'han proposat diversos models efectius per a la tonificació d'imatges de retrat basats en el potent StyleGAN, aquestes tècniques orientades a la imatge tenen clars inconvenients quan s'utilitzen amb vídeos, com ara la mida fixa del fotograma, el requisit d'alineació de la cara, l'absència de detalls no facials. , i incoherència temporal.
S'utilitza un marc revolucionari VToonify per fer front a la difícil transferència d'estil de vídeo retrat d'alta resolució controlada.
Examinarem l'estudi més recent sobre VToonify en aquest article, incloent la seva funcionalitat, inconvenients i altres factors.
Què és Vtoonify?
El marc de VToonify permet una transmissió personalitzable d'estil de vídeo retrat d'alta resolució.
VToonify utilitza les capes de resolució mitjana i alta de StyleGAN per crear retrats artístics d'alta qualitat basats en característiques de contingut multiescala recuperades per un codificador per retenir els detalls del marc.
L'arquitectura totalment convolucional resultant pren com a entrada cares no alineades en pel·lícules de mida variable, donant lloc a regions de cara sencera amb moviments realistes a la sortida.

Aquest marc és compatible amb els models actuals de tonificació d'imatges basats en StyleGAN, la qual cosa permet estendre'ls a la tonificació de vídeo i hereta característiques atractives com ara la personalització ajustable del color i la intensitat.
aquest estudiar introdueix dues instàncies de VToonify basades en Toonify i DualStyleGAN per a la transferència d'estil de vídeo de retrat basada en col·leccions i exemplars, respectivament.
Les troballes experimentals extenses mostren que el marc VToonify proposat supera els enfocaments existents per fer pel·lícules de retrats artístics d'alta qualitat i coherents temporalment amb paràmetres d'estil variables.
Els investigadors proporcionen el Llibreta de Google Colab, perquè us pugueu embrutar les mans.
Com funciona?
Per aconseguir una transferència d'estil de vídeo de retrat d'alta resolució ajustable, VToonify combina els avantatges del marc de traducció d'imatges amb el marc basat en StyleGAN.
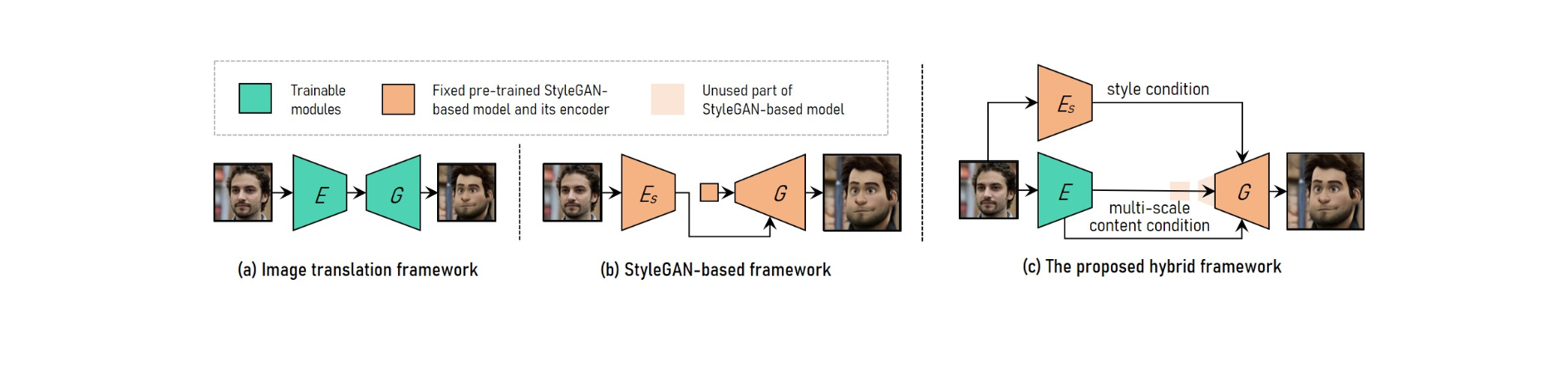
Per adaptar-se a diferents mides d'entrada, el sistema de traducció d'imatges utilitza xarxes totalment convolucionals. L'entrenament des de zero, d'altra banda, fa impossible la transmissió d'estil controlada i d'alta resolució.
El model StyleGAN pre-entrenat s'utilitza al marc basat en StyleGAN per a una transferència d'estil controlada i d'alta resolució, tot i que es limita a la mida de la imatge fixa i pèrdues de detalls.
StyleGAN es modifica al marc híbrid eliminant la seva característica d'entrada de mida fixa i les capes de baixa resolució, donant lloc a una arquitectura de generador de codificadors totalment convolucionals similar a la del marc de traducció d'imatges.
Per mantenir els detalls del fotograma, entreneu un codificador per extreure les característiques de contingut multiescala del fotograma d'entrada com a requisit de contingut addicional per al generador. Vtoonify hereta la flexibilitat de control d'estil del model StyleGAN posant-lo al generador per destil·lar tant les seves dades com el model.
Limitacions de StyleGAN i Vtoonify proposat
Els retrats artístics són habituals en la nostra vida quotidiana, així com en empreses creatives com l'art, mitjans de comunicació social avatars, pel·lícules, publicitat d'entreteniment, etc.
Amb el desenvolupament de aprenentatge profund tecnologia, ara és possible crear retrats artístics d'alta qualitat a partir de fotografies de cares de la vida real mitjançant la transferència automàtica d'estil de retrat.
Hi ha una varietat de maneres d'èxit creades per a la transferència d'estil basada en imatges, moltes de les quals són fàcilment accessibles per als usuaris principiants en forma d'aplicacions mòbils. El material de vídeo s'ha convertit ràpidament en un pilar de les nostres xarxes socials durant els darrers anys.
L'auge de les xarxes socials i les pel·lícules efímeres ha augmentat la demanda d'edició de vídeo innovadora, com ara la transferència d'estil de vídeo de retrat, per generar vídeos d'èxit i interessants.
Les tècniques existents orientades a la imatge tenen desavantatges importants quan s'apliquen a les pel·lícules, la qual cosa limita la seva utilitat en l'estilització automàtica de vídeos de retrats.
StyleGAN és una columna vertebral habitual per desenvolupar un model de transferència d'estil d'imatge retrat a causa de la seva capacitat per crear cares d'alta qualitat amb una gestió d'estil ajustable.
Un sistema basat en StyleGAN (també conegut com a toonificació d'imatges) codifica una cara real a l'espai latent de StyleGAN i després aplica el codi d'estil resultant a un altre StyleGAN afinat al conjunt de dades de retrat artístic per crear una versió estilitzada.
StyleGAN crea imatges amb cares alineades i amb una mida fixa, cosa que no afavoreix les cares dinàmiques en imatges del món real. El retall i l'alineació de la cara al vídeo de vegades donen lloc a una cara parcial i gestos incòmodes. Els investigadors anomenen aquest problema la "restricció de cultiu fix" de StyleGAN.
Per a cares no alineades, s'ha proposat StyleGAN3; tanmateix, només admet una mida d'imatge determinada.
A més, un estudi recent va descobrir que la codificació de cares no alineades és més difícil que les cares alineades. La codificació incorrecta de les cares és perjudicial per a la transferència d'estil de retrat, i provoca problemes com ara l'alteració de la identitat i la manca de components als marcs reconstruïts i estilitzats.
Com s'ha comentat, una tècnica eficient per a la transferència d'estil de vídeo retrat ha de gestionar els problemes següents:
- Per preservar moviments realistes, l'enfocament ha de ser capaç de fer front a cares no alineades i mides de vídeo variades. Una mida de vídeo gran, o un gran angle de visió, poden capturar més informació alhora que evita que la cara es mogui fora del marc.
- Per competir amb els aparells d'alta definició que s'utilitzen habitualment, és necessari un vídeo d'alta resolució.
- S'ha d'oferir un control d'estil flexible perquè els usuaris puguin modificar i triar la seva elecció quan desenvolupin un sistema d'interacció realista amb l'usuari.
Amb aquesta finalitat, els investigadors suggereixen VToonify, un nou marc híbrid per a la tonificació de vídeo. Per superar la restricció fixa del cultiu, els investigadors primer estudien l'equivariància de traducció a StyleGAN.
VToonify combina els avantatges de l'arquitectura basada en StyleGAN i el marc de traducció d'imatges per aconseguir una transferència d'estil de vídeo de retrat d'alta resolució ajustable.
Aquestes són les principals aportacions:
- Els investigadors investiguen la restricció de cultiu fix de StyleGAN i proposen una solució basada en l'equivariància de traducció.
- Els investigadors presenten un marc únic de VToonify totalment convolucional per a la transferència controlada d'estil de vídeo retrat d'alta resolució que admet cares no alineades i diferents mides de vídeo.
- Els investigadors construeixen VToonify sobre els eixos vertebradors de Toonify i DualStyleGAN i condensen els eixos vertebradors tant en termes de dades com de model per permetre la transferència d'estil de vídeo de retrat basada en col·leccions i exemplars.
Comparant Vtoonify amb altres models d'última generació
Toonificar
Serveix com a base per a la transferència d'estil basada en col·leccions a cares alineades mitjançant StyleGAN. Per recuperar els codis d'estil, els investigadors han d'alinear les cares i retallar 256256 fotos per a PSP. Toonify s'utilitza per generar un resultat estilitzat amb codis d'estil 1024*1024.
Finalment, tornen a alinear el resultat del vídeo a la seva ubicació original. L'àrea no estilitzada s'ha configurat en negre.

DualStyleGAN
És una columna vertebral per a la transferència d'estil basada en exemplars basada en StyleGAN. Utilitzen les mateixes tècniques de pre i postprocessament de dades que Toonify.
Pix2pixHD
És un model de traducció d'imatge a imatge que s'utilitza habitualment per condensar models prèviament entrenats per a l'edició d'alta resolució. S'entrena utilitzant dades aparellades.
Els investigadors utilitzen pix2pixHD com a entrades addicionals de mapa d'instàncies, ja que utilitza un mapa d'anàlisi extret.
Moció de primer ordre
FOM és un model típic d'animació d'imatges. S'ha entrenat amb 256256 imatges i té un mal rendiment amb altres mides d'imatge. Com a conseqüència, els investigadors primer escalen els fotogrames de vídeo a 256 * 256 per FOM a l'animació i després canvien la mida dels resultats a la seva mida original.
Per a una comparació justa, FOM utilitza el primer marc estilitzat del seu enfocament com a imatge d'estil de referència.
DaGAN
És un model d'animació facial en 3D. Utilitzen els mateixos mètodes de preparació i postprocessament de dades que FOM.

avantatges
- Es pot utilitzar en arts, avatars de xarxes socials, pel·lícules, publicitat d'entreteniment, etc.
- Vtoonify també es pot utilitzar al metavers.
Limitacions
- Aquesta metodologia extreu tant les dades com el model dels troncs basats en StyleGAN, donant lloc a un biaix de dades i de model.
- Els artefactes són causats principalment per diferències de mida entre la regió de la cara estilitzada i les altres seccions.
- Aquesta estratègia té menys èxit quan es tracta de coses a la regió de la cara.
Conclusió
Finalment, VToonify és un marc per a la tonificació de vídeo d'alta resolució controlada per estil.
Aquest marc aconsegueix un gran rendiment en el maneig de vídeos i permet un control ampli sobre l'estil estructural, l'estil de color i el grau d'estil condensant els models de tonificació d'imatges basats en StyleGAN tant pel que fa als seus dades sintètiques i estructures de xarxa.





Deixa un comentari