Els models de difusió han arrasat el món per tempesta amb el llançament de Dall-E 2, Imatge de Google, Difusió establei A mig camí, provocant la innovació i estirant els límits de l'aprenentatge automàtic.
Aquests models poden produir un nombre gairebé il·limitat d'imatges a partir d'indicacions de paraules, incloses imatges fotorealistes, màgiques, futuristes i, per descomptat, boniques.
Aquestes capacitats reinventen el que significa per als humans interactuar amb el silici, donant-nos la possibilitat de fer pràcticament qualsevol imatge que puguem imaginar.
A mesura que aquests models es desenvolupin o el proper paradigma generatiu es faci càrrec, els humans seran capaços de produir imatges, pel·lícules i altres experiències immersives amb només un pensament.
En aquest post, parlarem de model de difusió, difusió estable, com funciona i un tutorial de model de difusió en pintura, entre altres coses.
Què és el model de difusió?
Els models d'aprenentatge automàtic que poden crear dades noves a partir de dades d'entrenament s'anomenen models generatius. Altres models generatius inclouen models basats en flux, codificadors automàtics variacionals i xarxes adversaries generatives (GAN).
Cadascun pot generar imatges d'excel·lent qualitat. Els models de difusió aprenen a recuperar les dades invertint aquest procés d'addició de soroll després de danyar les dades d'entrenament afegint soroll. Per dir-ho d'una altra manera, els models de difusió són capaços de crear imatges coherents a partir del soroll.
Els models de difusió aprenen introduint soroll a les imatges, que després el model domina l'eliminació. Per tal de produir imatges realistes, el model aplica aquesta tècnica de reducció de soroll a llavors aleatòries.
En condicionar el procés de producció d'imatges, aquests models es poden utilitzar juntament amb la guia de text a imatge per generar un nombre gairebé il·limitat d'imatges només a partir del text. Les llavors es poden dirigir mitjançant entrades d'incrustacions com CLIP per oferir fortes capacitats de text a imatge.
Els models de difusió poden dur a terme una varietat de tasques, com ara la creació d'imatges, la eliminació de sorolls d'imatges, la pintura interna, la pintura exterior i la difusió de bits.
Ara bé, què és la difusió estable?
Stable Diffusion és un model d'aprenentatge automàtic per a la creació d'imatges basades en text que ofereix Estabilitat.AI. És capaç de generar imatges a partir de text.
Components de difusió estable
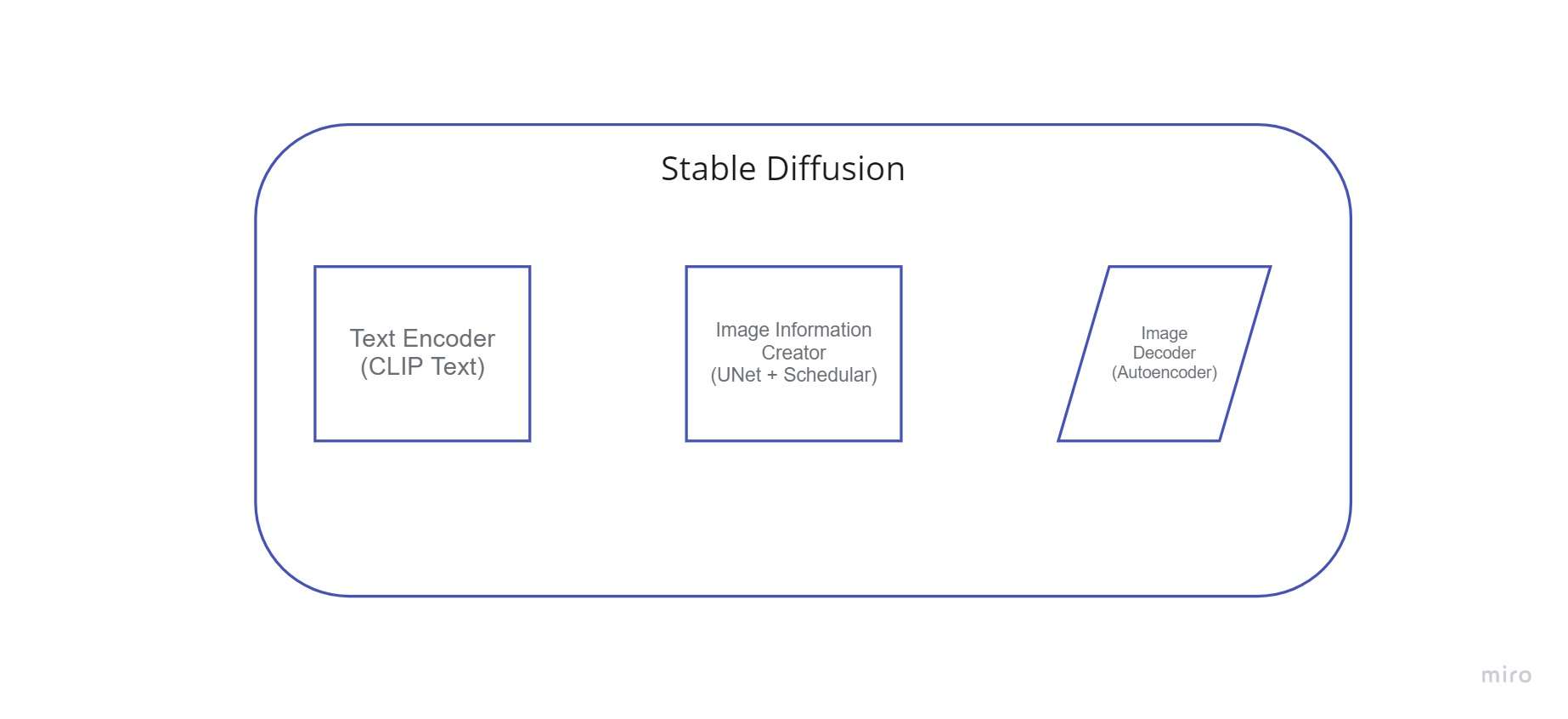
Difusió estable és un sistema format per diversos components i conceptes. No és un únic model. Quan comprovem darrere del capó, el primer que veiem és que hi ha un component de comprensió del text que converteix la informació del text en una representació numèrica que recull els conceptes del text.
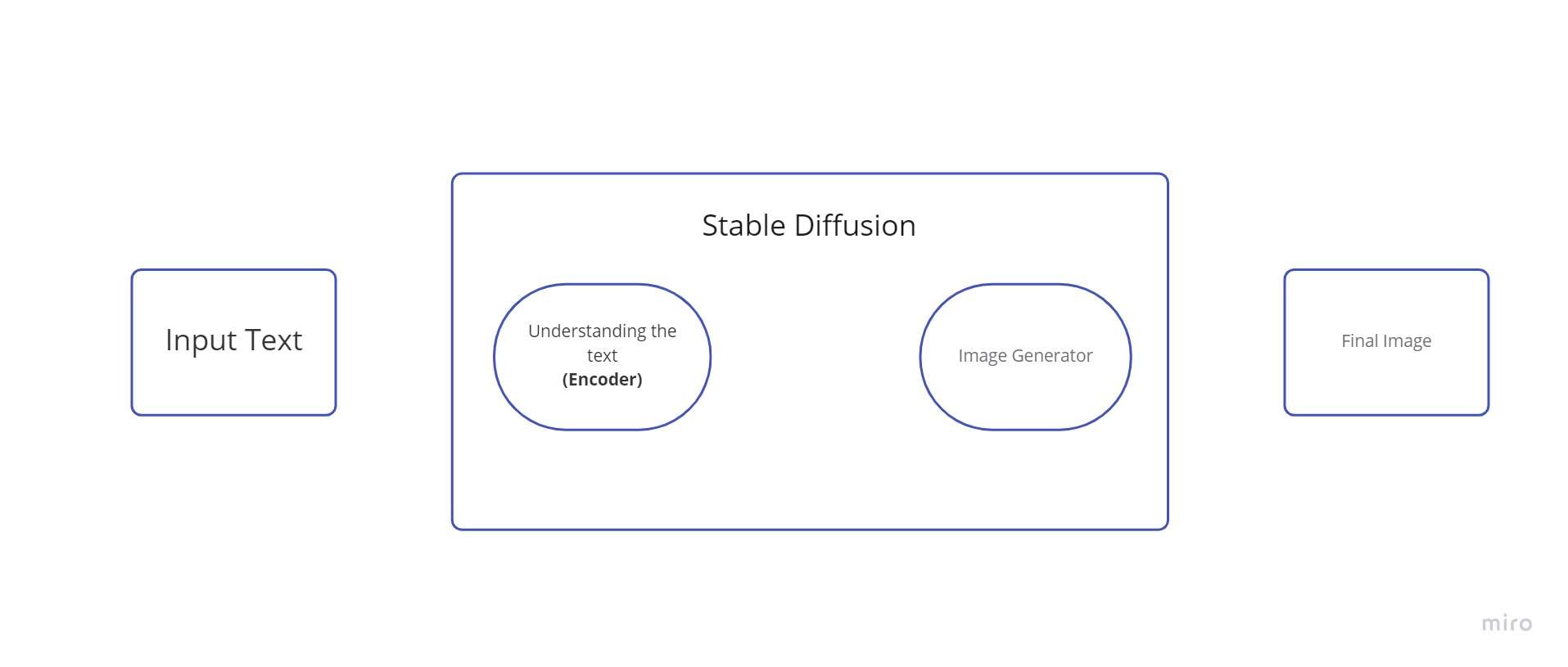
Podem anomenar a aquest codificador de text un transformador model lingüístic (tècnicament: el codificador de text d'un model CLIP). Pren el text d'entrada i genera una llista de nombres enters (un vector) per a cada paraula/token del text. A continuació, aquestes dades es subministren al generador d'imatges, que està format per diversos components.
Hi ha dos passos en el generador d'imatges:
1. Creador d'informació d'imatge
El component principal de la difusió estable és aquest element. És on es fa la major part de la millora del rendiment respecte a les versions anteriors.
Aquest component passa per diverses etapes per proporcionar dades d'imatge. El creador de la informació de la imatge només opera dins de l'espai d'informació de la imatge (o espai latent).
És més ràpid que els models de difusió anteriors que funcionaven a l'espai de píxels a causa d'aquesta característica. Tècnicament parlant, aquest component està format per un algorisme de programació i una UNet xarxa neural.
El procés que té lloc en aquest component s'anomena "difusió". En última instància, es produeix una imatge d'alta qualitat com a resultat de la informació que es processa per passos (pel següent component, el descodificador d'imatge).
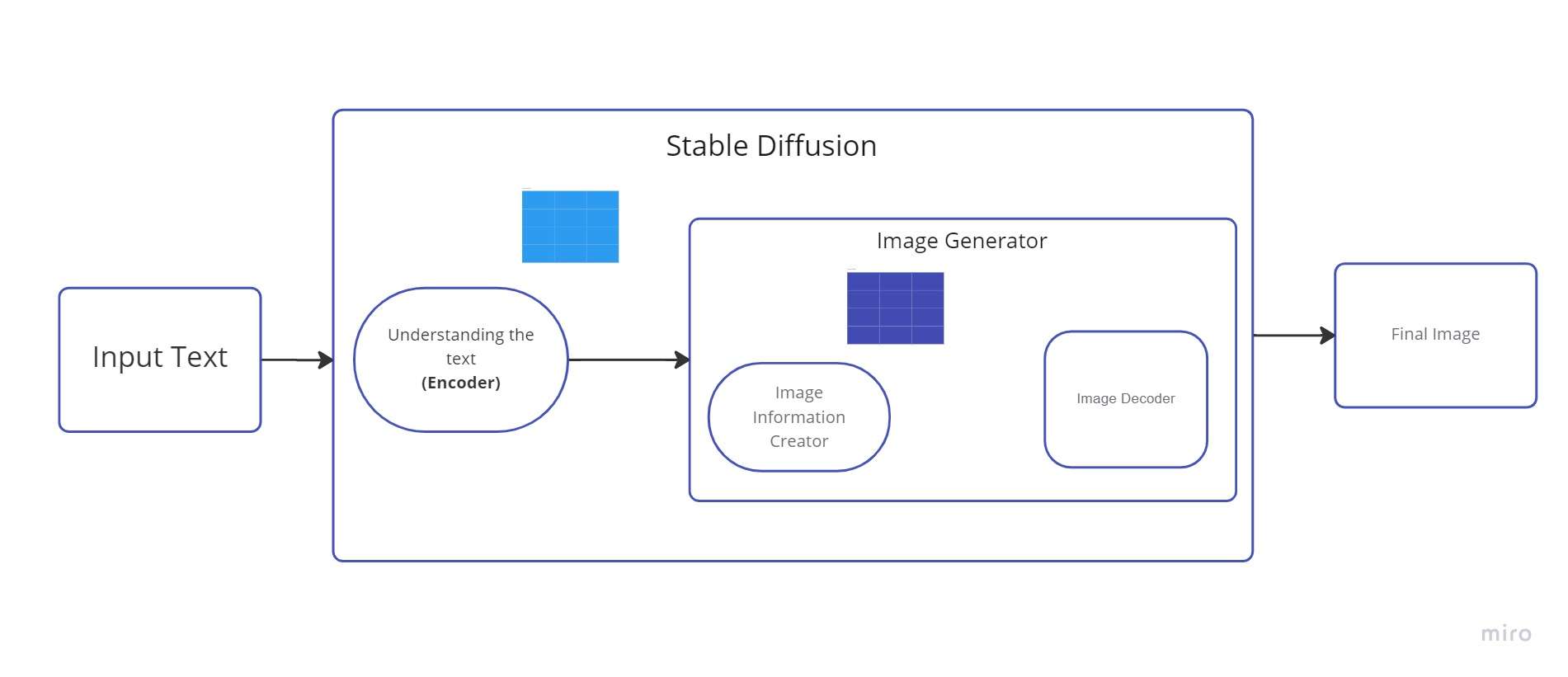
2. Descodificador d'imatges
Utilitzant les dades que va rebre del productor d'informació, el descodificador d'imatges crea una imatge. Només s'executa una vegada per crear la imatge de píxel acabada al final de l'operació.
Tutorial de Stable Diffusion Impainting
La pintura d'imatge de difusió estable és la tècnica d'omplir les zones que falten o danyades d'una imatge. El propòsit de la pintura en quadres és ocultar el fet que la imatge ha estat restaurada.
Aquesta tècnica s'utilitza sovint per eliminar coses no desitjades d'una imatge o per restaurar àrees danyades de fotografies històriques. Stable Diffusion Inpainting és una forma relativament recent d'inpainting que està donant efectes prometedors.
Seguint les instruccions següents us permetrà començar a explorar inpainting i modificar les fotos existents si voleu provar inpainting amb una difusió estable:
- Vés a Huggingface Impinting de difusió estable
- Puja la teva pròpia imatge
- Esborra la part de la imatge que cal substituir.
- Introduïu la vostra sol·licitud aquí (el que voleu afegir en lloc del que esteu eliminant)
- Seleccioneu "executar"
Al vídeo de dalt, pengem una imatge amb tres llimones i les canviem per pomes. Personalment us recomano que ho proveu amb les vostres pròpies fotografies i instruccions.
Conclusió
En general, la pintura de difusió constant és un mètode excel·lent per produir imatges o vídeos falsos que semblen extremadament reals. A mesura que avancem cap als nous avenços tecnològics, cada cop serà més difícil distingir entre autèntics i fraudulents a mesura que avanci la tecnologia.





La primera part no té cap relació amb la segona. Hauria estat genial si l'autor hagués explicat com funciona inpaint en el marc del model que va explicar anteriorment, hagués pogut donar una idea. Però no! Això hauria requerit una comprensió real, en lloc de recollir i processar un text aleatori.