Vivim temps emocionants, amb anuncis sobre tecnologia d'avantguarda cada setmana. OpenAI acaba de llançar el model d'avantguarda de text a imatge DALLE 2.
Només unes poques persones van tenir accés anticipat a un nou sistema d'IA que pot generar gràfics realistes a partir de descripcions en llenguatge natural. Encara està tancat al públic.
L'estabilitat AI va llançar llavors Difusió estable model, una variant de codi obert de DALLE2. Aquest llançament ho ha alterat tot. La gent de tot Internet publicava resultats ràpids i estava sorprès per l'art realista.
Què és la difusió estable?
Difusió estable és un model d'aprenentatge automàtic capaç de crear imatges a partir de text, canviar imatges en funció del text i omplir detalls en imatges de baixa resolució o detalls.
Es va entrenar amb milers de milions de fotos i pot oferir resultats equivalents a DALL-E2 i Mitjan viatge. IA d'estabilitat el va inventar i es va fer públic el 22 d'agost de 2022.
Però amb recursos computacionals locals limitats, el model de difusió estable triga molt de temps a crear imatges d'alta qualitat. L'execució del model en línia mitjançant un proveïdor de núvol ens proporciona recursos computacionals gairebé infinits i ens permet adquirir excel·lents resultats molt més ràpidament.
L'allotjament del model com a microservei també permet que altres aplicacions creatives explotin més fàcilment el potencial del model sense haver de fer front a les complexitats d'executar models de ML en línia.
En aquesta publicació, intentarem demostrar com desenvolupar un model de difusió estable i desplegar-lo a AWS.
Construir i desplegar una difusió estable
BentoML i Amazon Web Services EC2 són dues opcions per allotjar el model Stable Diffusion en línia. BentoML és un marc de codi obert per escalar màquina d'aprenentatge serveis. Amb BentoML, construirem un servei de dispersió fiable i el desplegarem a AWS EC2.
Preparació de l'entorn i descàrrega del model de difusió estable
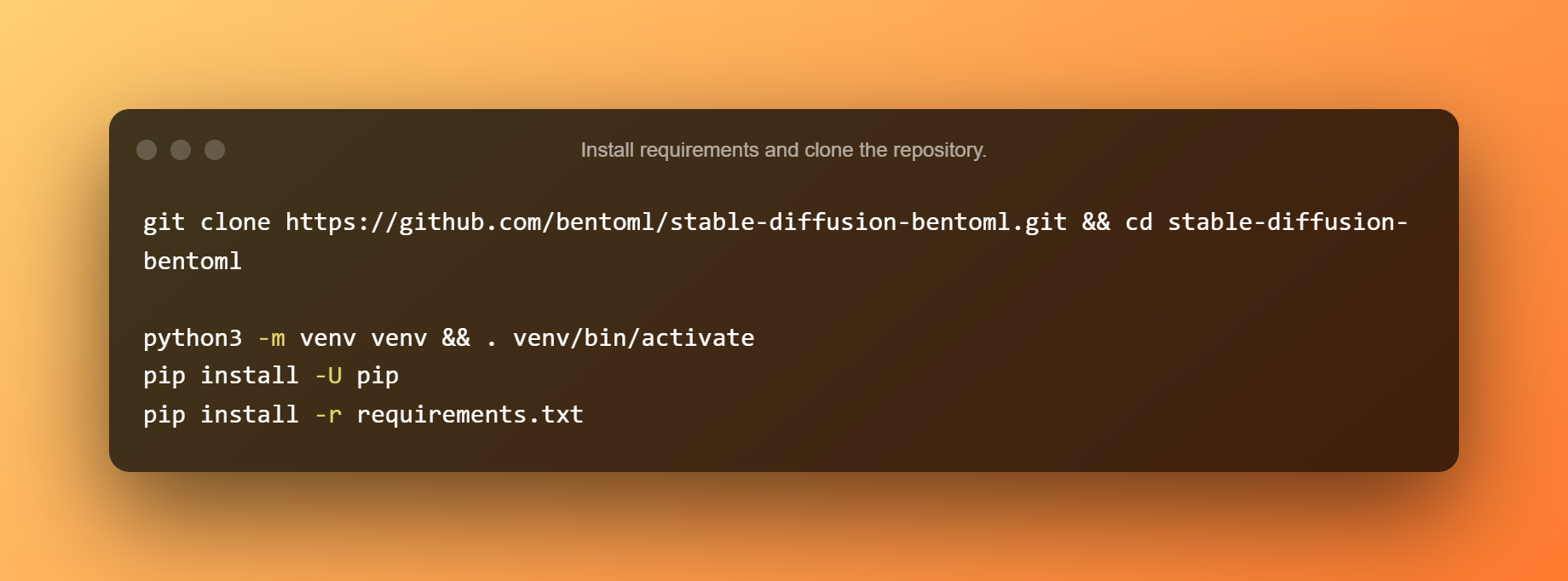
Instal·leu els requisits i cloneu el repositori.
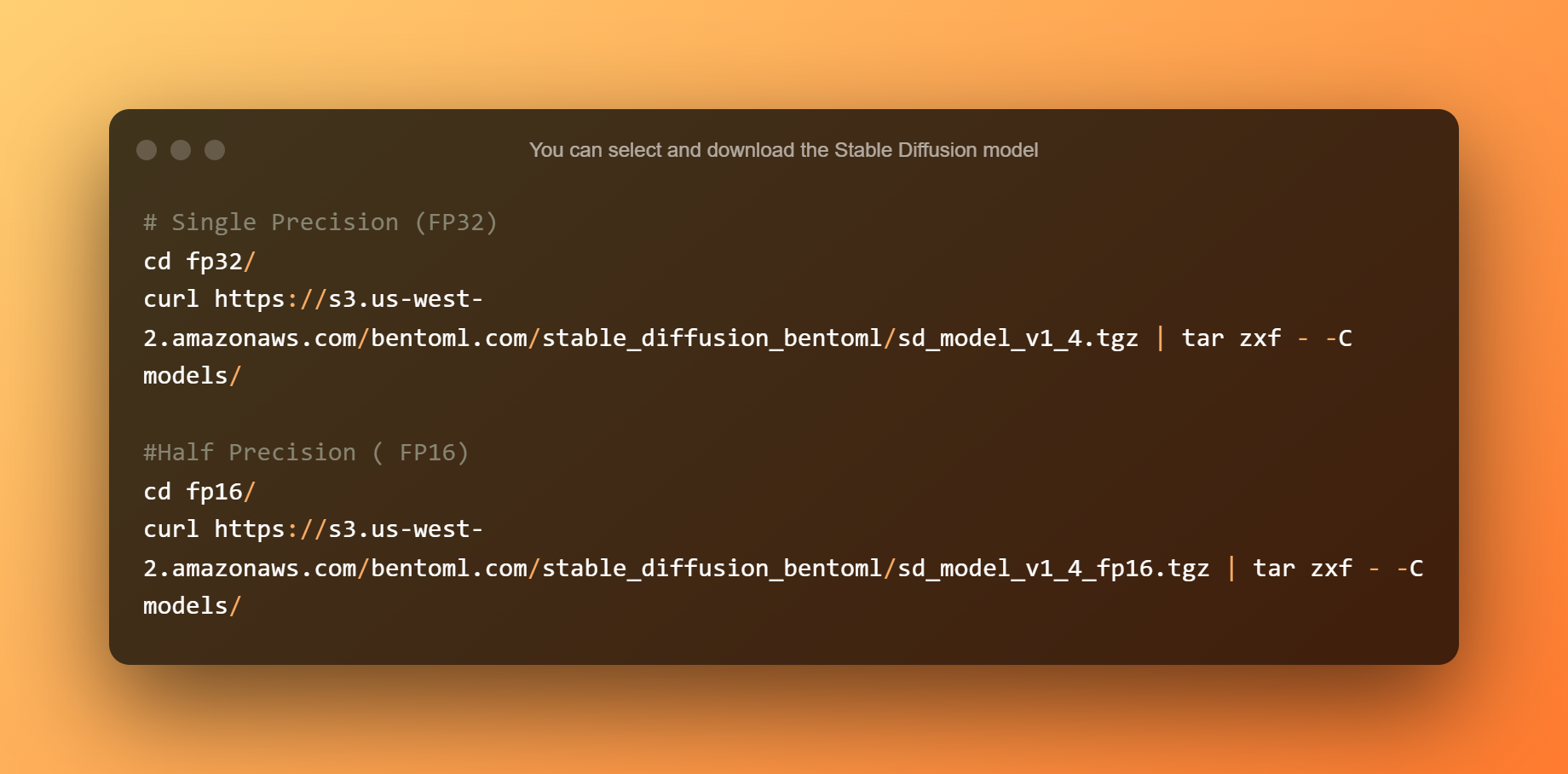
Podeu seleccionar i descarregar el model de difusió estable. La precisió única és adequada per a CPU o GPU amb més de 10 GB de VRAM. La mitja precisió és ideal per a GPU amb menys de 10 GB de VRAM.
Construcció de difusió estable
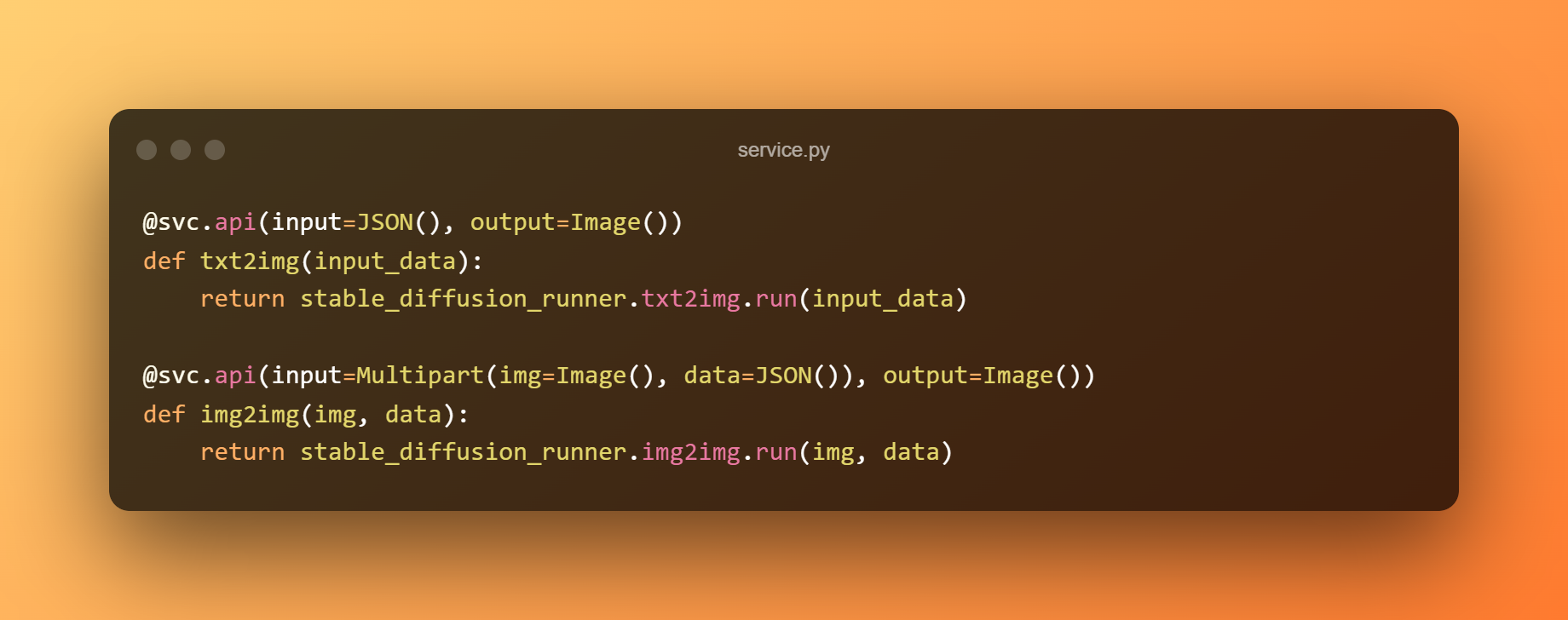
Construirem un servei BentoML per servir el model darrere d'un API RESTful. L'exemple següent utilitza el model de precisió única per a la predicció i el mòdul service.py per connectar el servei a la lògica empresarial. Podem exposar les funcions com a API etiquetant-les amb @svc.api.
A més, podem definir els tipus d'entrada i sortida de les API als paràmetres. El punt final txt2img, per exemple, rep una entrada JSON i produeix una sortida d'Imatge, mentre que el punt final img2img accepta una entrada d'Imatge i una entrada JSON i retorna una sortida d'Imatge.
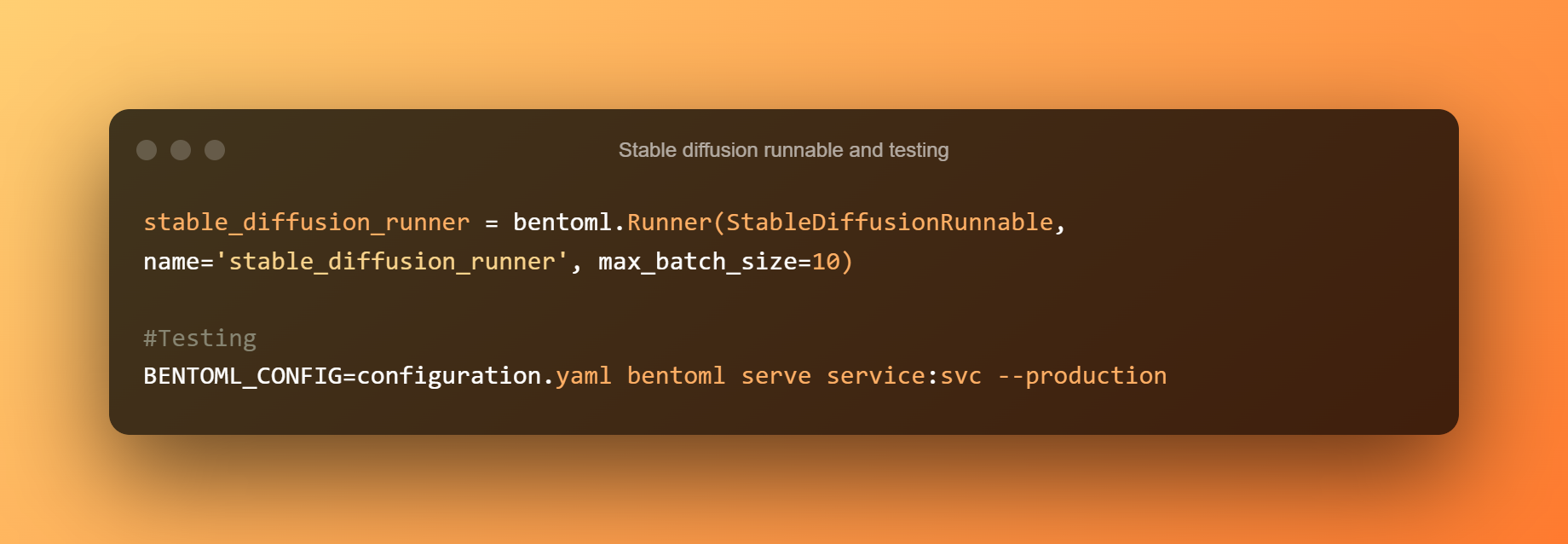
Un StableDiffusionRunnable defineix la lògica d'inferència essencial. L'executable s'encarrega d'executar els mètodes de canalització txt2img del model i d'enviar les entrades pertinents. Per executar la lògica d'inferència del model a les API, es construeix un Runner personalitzat a partir de StableDiffusionRunnable.
A continuació, utilitzeu l'ordre següent per iniciar un servei BentoML per provar-lo. Execució local del Model de difusió estable La inferència sobre les CPU és bastant lenta. Cada sol·licitud trigarà uns 5 minuts a processar-se.
Text a imatge
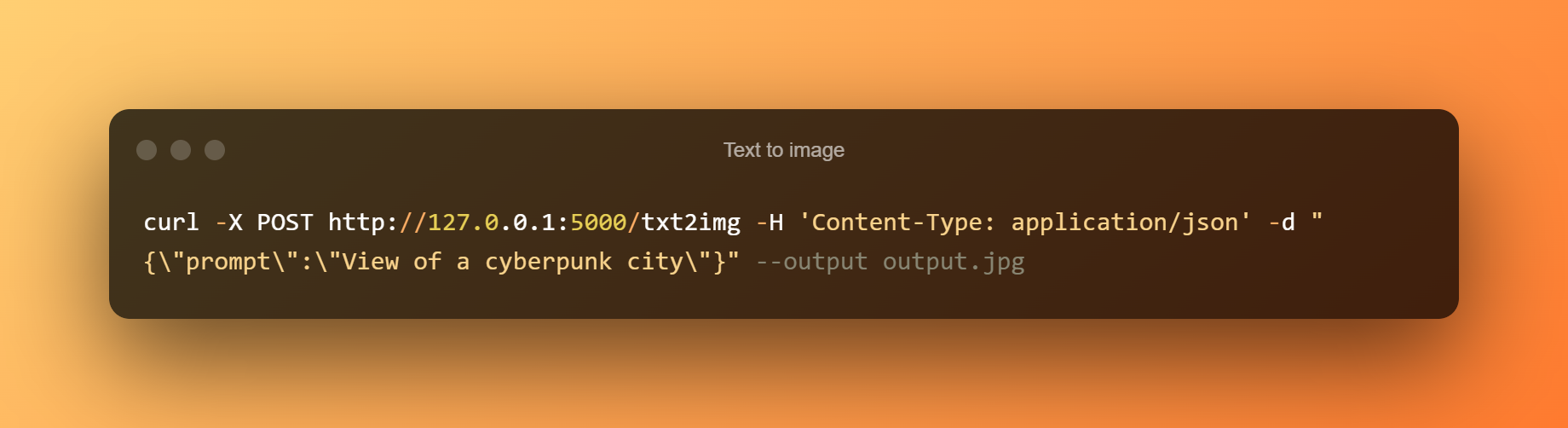
Sortida de text a imatge

El fitxer bentofile.yaml defineix els fitxers i dependències necessaris.
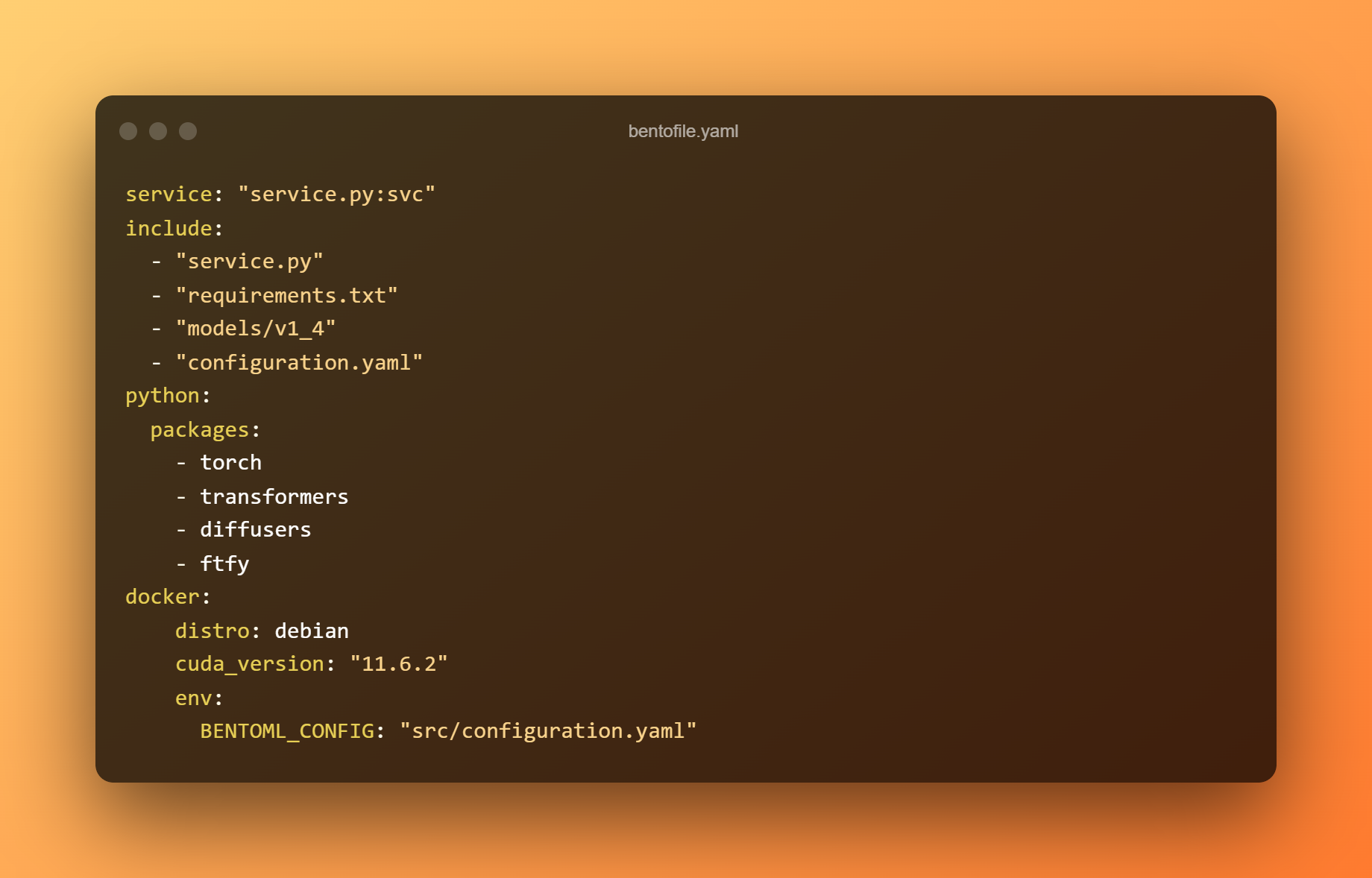
Utilitzeu l'ordre següent per crear un bento. Un Bento és el format de distribució d'un servei BentoML. És un arxiu autònom que conté totes les dades i configuracions necessàries per iniciar el servei.

S'ha acabat el bento de difusió estable. Si no heu pogut generar correctament el bento, no us espanteu; podeu descarregar el model preconstruït mitjançant les ordres que es mostren a la secció següent.
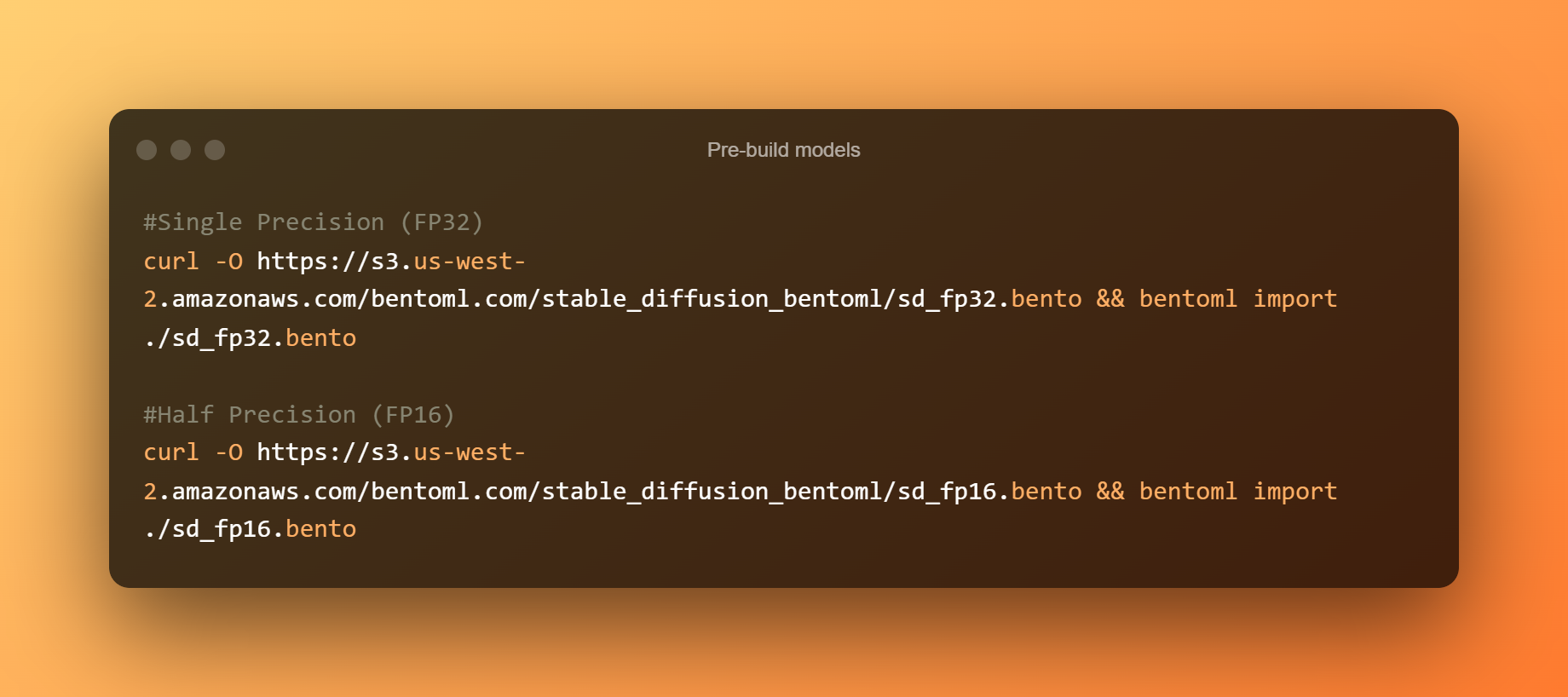
Models previs a la construcció
A continuació es mostren els models previs a la construcció:
Desplegueu el model de difusió estable a EC2
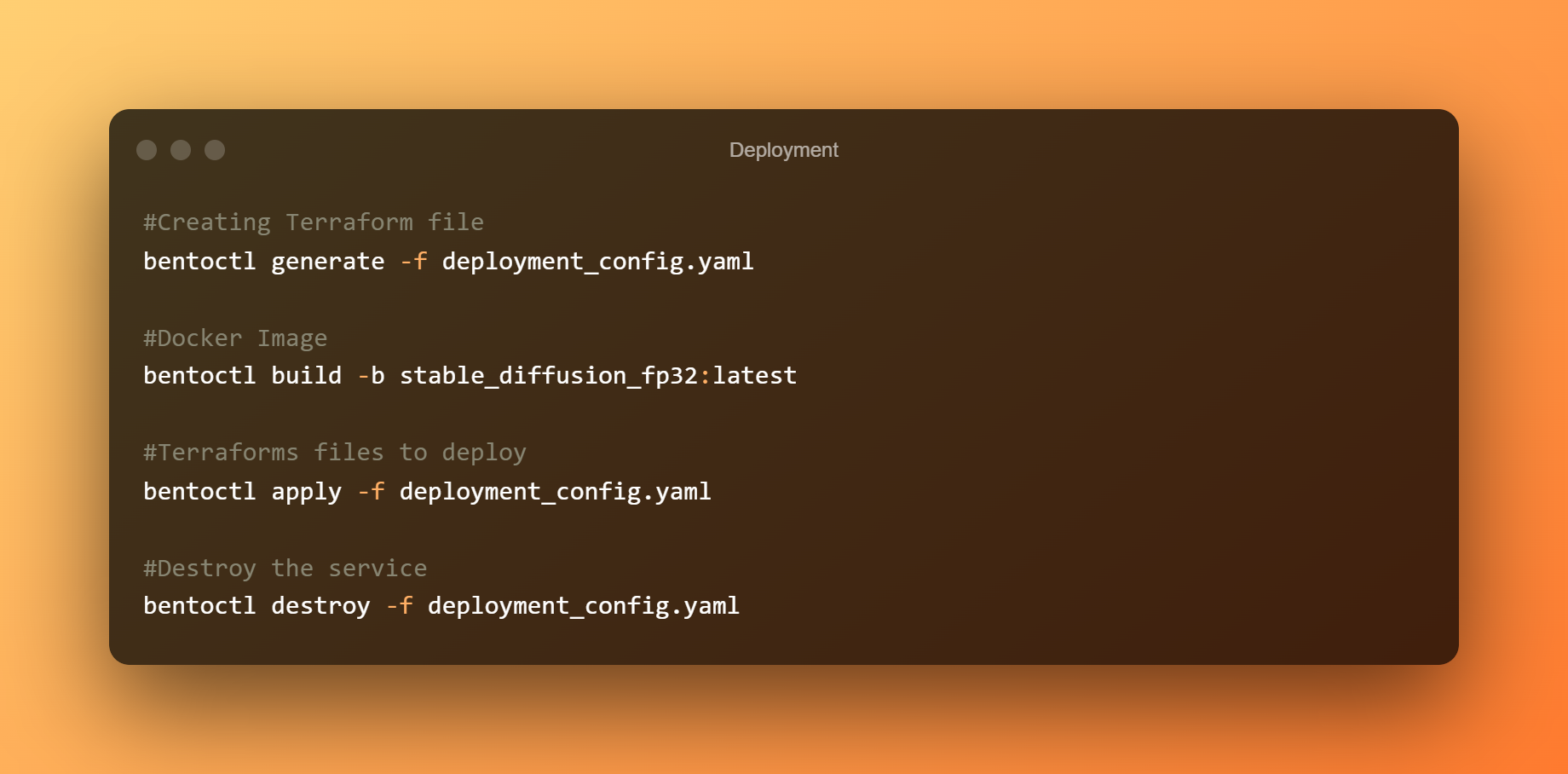
Per desplegar el bento a EC2, utilitzarem bentoctl. bentoctl us permet desplegar els vostres bentos a qualsevol plataforma núvol utilitzant Terraform. Per crear i aplicar fitxers Terraform, instal·leu l'operador AWS EC2.

Al fitxer config.yaml de desplegament, el desplegament ja s'ha configurat. Si us plau, no dubteu a editar segons els vostres requisits. El Bento es desplega de manera predeterminada en un amfitrió g4dn.xlarge amb el Aprenentatge profund AMI GPU PyTorch 1.12.0 (Ubuntu 20.04) AMI a la regió us-west-1.
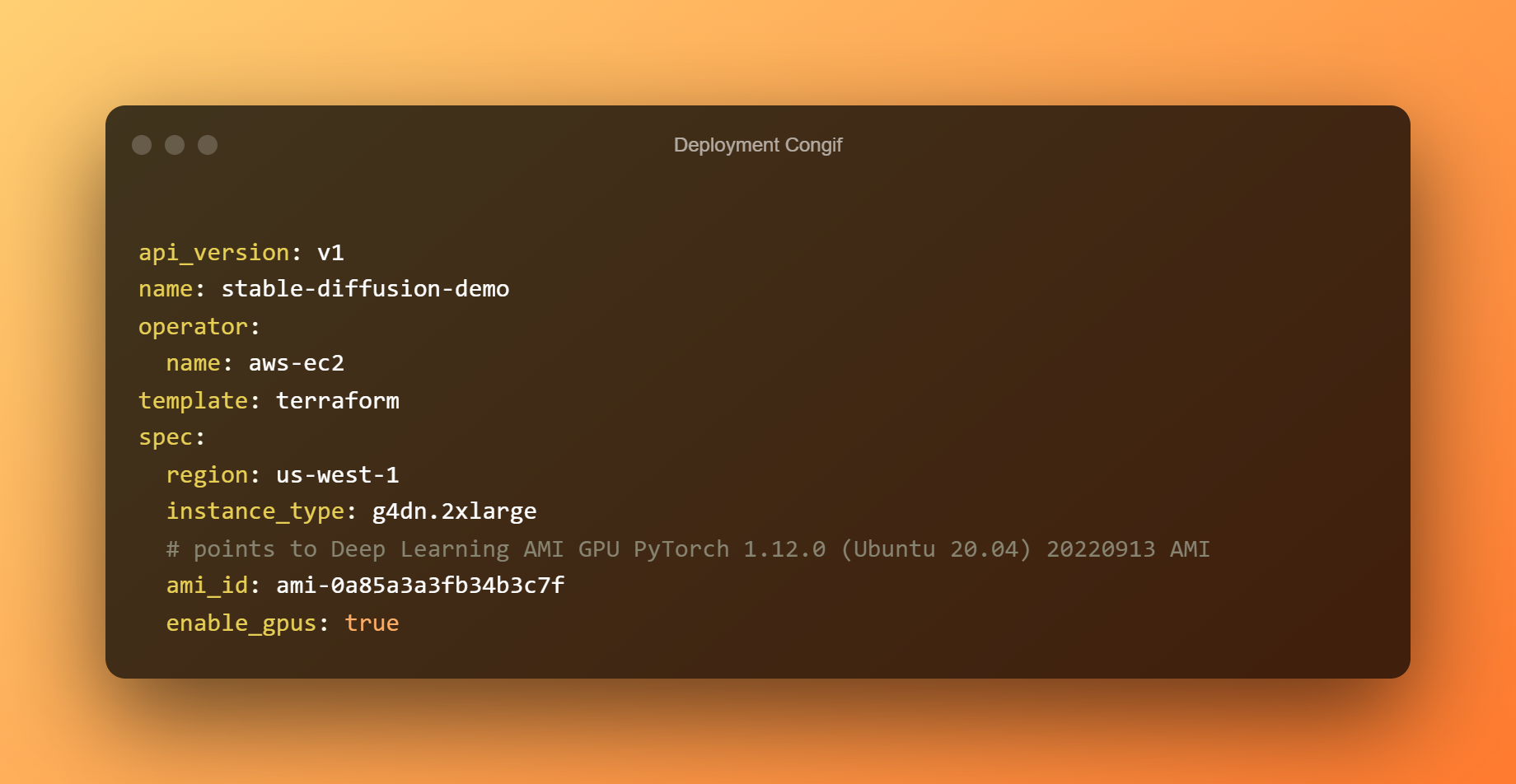
Creeu els fitxers Terraform ara. Creeu la imatge de Docker i pengeu-la a AWS ECR. Depenent de l'amplada de banda, la càrrega d'imatges pot trigar molt de temps. En desplegar el bento a AWS EC2, utilitzeu els fitxers Terraform.
Per accedir a la interfície d'usuari de Swagger, connecteu-vos a la consola EC2 i obriu l'adreça IP pública en un navegador. Finalment, si el servei Stable Diffusion BentoML ja no és necessari, elimineu el desplegament.
Conclusió
Hauríeu de poder veure com són de fascinants i potents SD i els seus models acompanyants. El temps dirà si seguirem el concepte o passarem a enfocaments més sofisticats.
Tanmateix, actualment hi ha iniciatives en marxa per formar models més grans amb ajustos per comprendre millor l'entorn i les instruccions. Vam intentar desenvolupar el servei Stable Diffusion utilitzant BentoML i el vam implementar a AWS EC2.
Hem pogut executar el model Stable Diffusion amb un maquinari més potent, crear imatges amb una latència baixa i estendre'ns més enllà d'un únic ordinador mitjançant la implementació del servei a AWS EC2.





Deixa un comentari