Taula de continguts[Amaga][Espectacle]
Els grans models de text a imatge van fer un avenç significatiu en el desenvolupament de la IA en produir una síntesi d'imatges diversificada i d'alta qualitat a partir d'un missatge de text determinat.
Aquests models són incapaços de sintetitzar representacions úniques de subjectes en diversos entorns o de replicar l'aparença dels subjectes en un conjunt de referència determinat.
Tecnologies recentment llançades com DALL.E2 d'OpenAI o StabilityAI Difusió estable i Midjourney ja estan agafant Internet per asalto. Ara és el moment de personalitzar els resultats. Però com?
Google DreamBooth AI ha arribat.
DreamBooth té la capacitat de reconèixer el tema d'una imatge, desconstruir-la del seu context original i després sintetitzar-la amb precisió en un nou context desitjat. A més, es pot utilitzar amb els generadors d'imatges AI actuals.
En aquest article, farem una ullada a fons a DreamBooth, el seu ús, el seu tutorial, les seves limitacions i molt més.
Què és Dreambooth?
DreamBooth, un model de difusió de text a imatge totalment nou, va ser presentat per Google. Google DreamBooth AI pot utilitzar una indicació escrita com a guia per generar una àmplia gamma de fotos del tema seleccionat per l'usuari en diferents configuracions.
Un grup d'investigació de la Universitat de Boston i Google va desenvolupar DreamBooth, una tècnica d'avantguarda per alterar models de text a imatge que han estat sotmesos a un ampli entrenament previ.
El concepte general és bastant senzill: volen augmentar el diccionari de visió del llenguatge de manera que els identificadors de testimoni poc comuns s'associïn a temes personalitzats que els usuaris puguin definir.
L'objectiu principal del model és connectar els usuaris a model de difusió text a imatge donant-los els recursos necessaris per produir representacions fotorealistes de les instàncies de la matèria seleccionada.
Com a conseqüència, aquesta tècnica sembla funcionar bé per resumir els reptes en una sèrie de situacions.
DreamBooth de Google difereix de les eines anteriors de text a imatge, com ara DALL-E2, Difusió establei A mig camí, ja que ofereix als usuaris més control sobre la imatge del tema abans de deixar-los manipular el model de difusió mitjançant entrades basades en text.
Característiques
- DreamBooth AI podria millorar un model de text a imatge amb 3-5 imatges.
- Es poden crear fotos fotorealistes originals amb DreamBooth AI.
- A més, la DreamBooth AI pot crear fotos d'un tema des de múltiples angles.
Sol·licitud
Representacions d'art
Aquesta tasca difereix específicament de la transferència d'estil, que manté la semàntica de l'escena font alhora que incorpora l'estil d'una altra imatge a l'escena original.

Basant-se en l'enfocament creatiu, l'IA pot aconseguir alteracions significatives de l'escena mentre manté la identificació i les especificitats de la instància del tema.
Modificació de la propietat
Les característiques de la instància subjecta es poden modificar mitjançant DreamBooth AI.

Accessoris
La forta composició anterior al model de generació és el que fa que la capacitat de DreamBooth AI per adornar objectes sigui tan interessant.

Recontextualització
DreamBooth AI pot produir imatges distintives per a una instància determinada del subjecte donant a un model entrenat una frase que inclogui l'identificador únic i el substantiu de classe.

Pot generar el subjecte en postures, articulacions i estructura d'escena úniques i inèdites abans en lloc de canviar l'entorn. Reflexions i ombres realistes, així com interaccions entre el subjecte i els objectes que l'envolten.
Tutorial de Dreambooth
En aquest tutorial, seguirem el Quadern de Google Collab, i us guiaré a través d'ell, que us farà entendre i utilitzar-lo pel vostre compte.
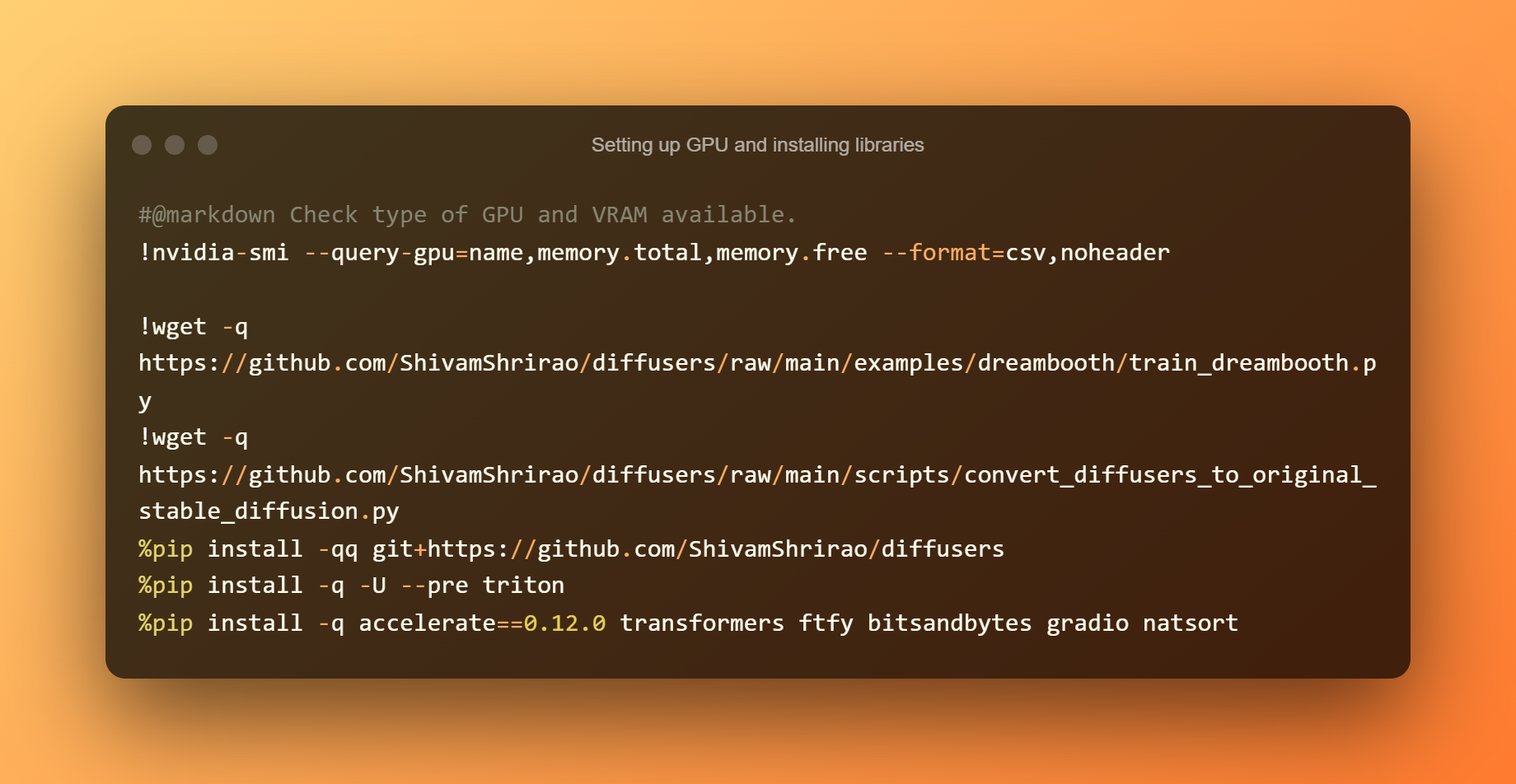
Configuració de la GPU i instal·lació de biblioteques
Esbrinar quins tipus de GPU i VRAM hi ha disponibles és el primer pas. També cal instal·lar alguns requisits i dependències. Només cal que premeu el botó de reproducció i, a continuació, espereu que acabi.
Creeu un compte a Huggingface i genereu un testimoni
El següent pas és registrar-se per obtenir un compte Huggingface. Quan hàgiu acabat, feu clic a Configuració a l'extrem superior dret. Arribareu a la pàgina següent.
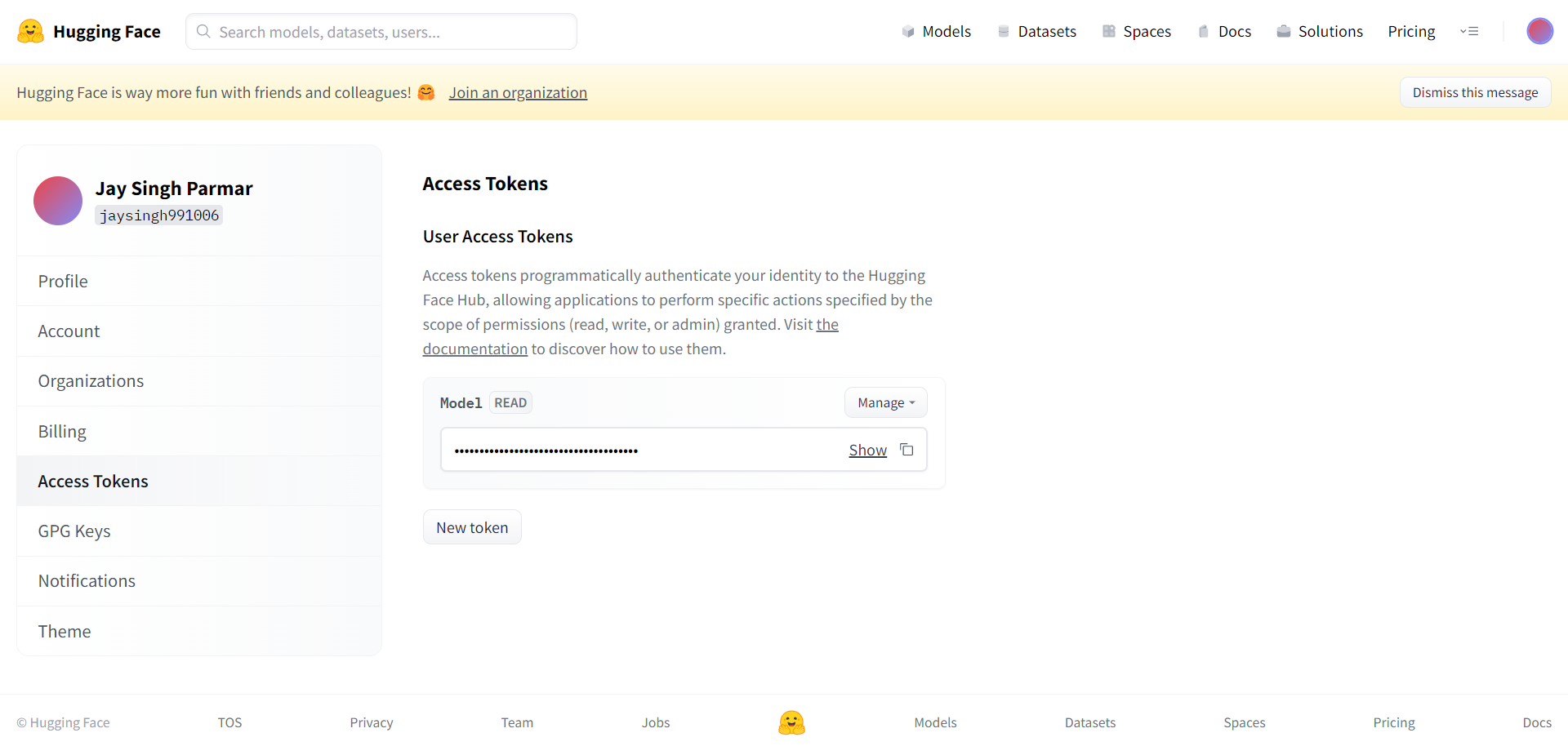
Creeu el testimoni i el nom tal com se sol·licita des d'aquí. El testimoni s'ha de copiar i enganxar a la col·laboració de Google a la cel·la següent.

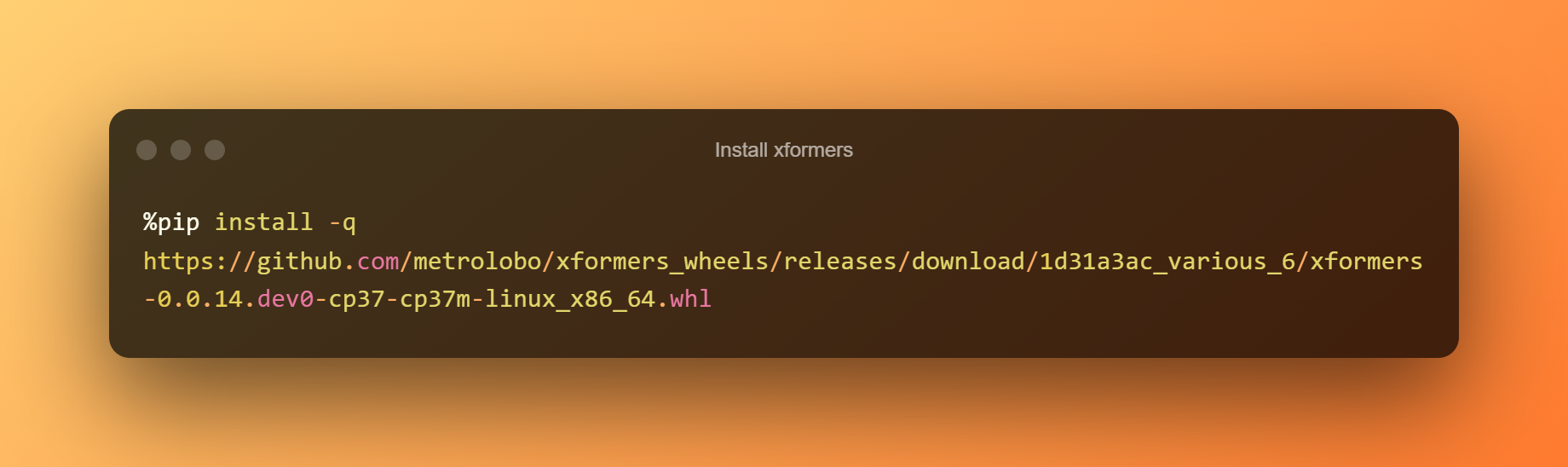
Instal·leu xformers
En aquesta etapa, només podeu prémer el botó de reproducció per instal·lar xformers fent clic al temps d'execució.
Connecta't a Drive
Ara, només heu d'executar aquesta cel·la per connectar-vos a Google Drive.
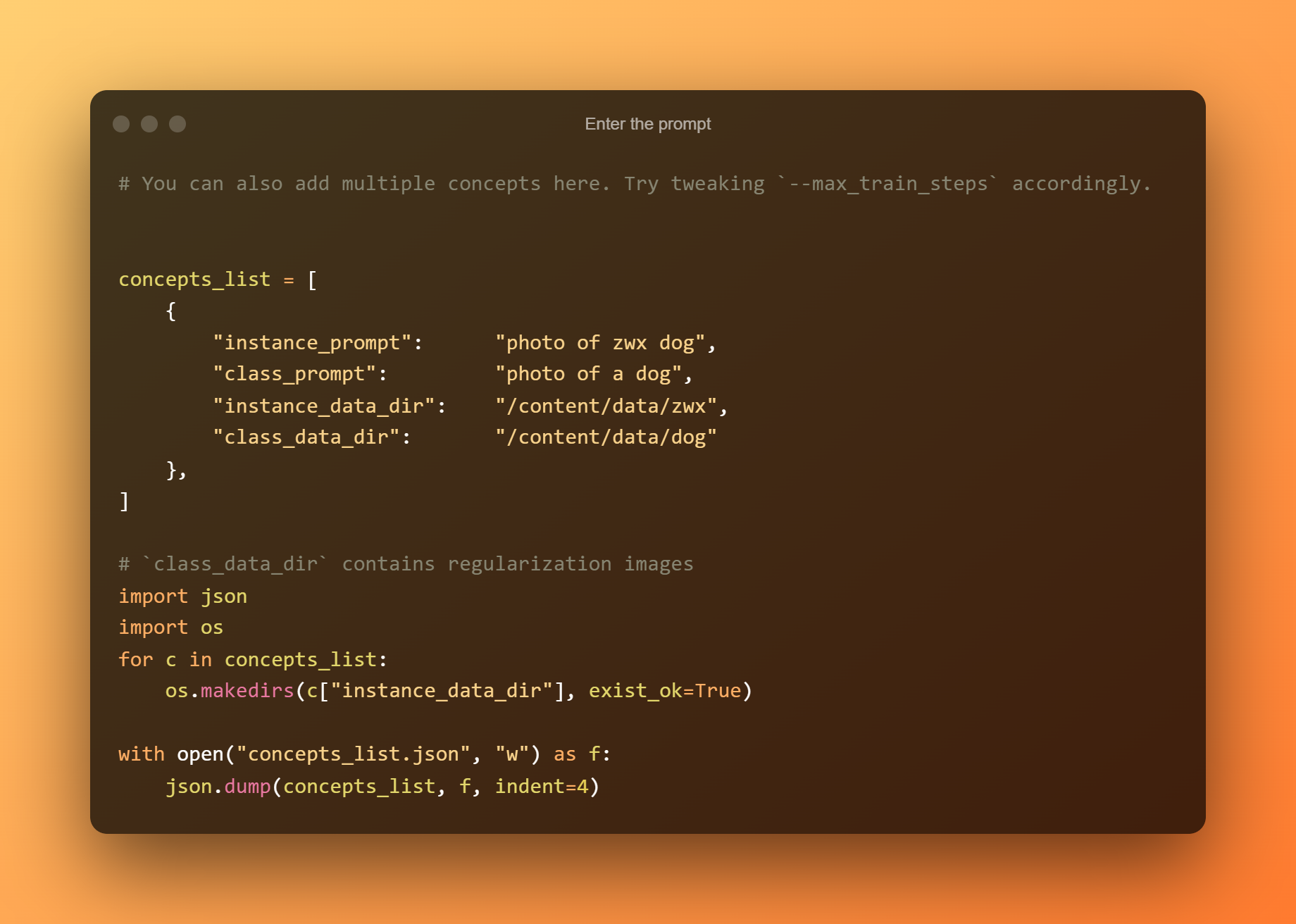
Introduïu la sol·licitud
A la cel·la següent, només heu d'introduir la sol·licitud.
Penjant imatges
En aquest pas, només has de pujar les imatges que vols entrenar.

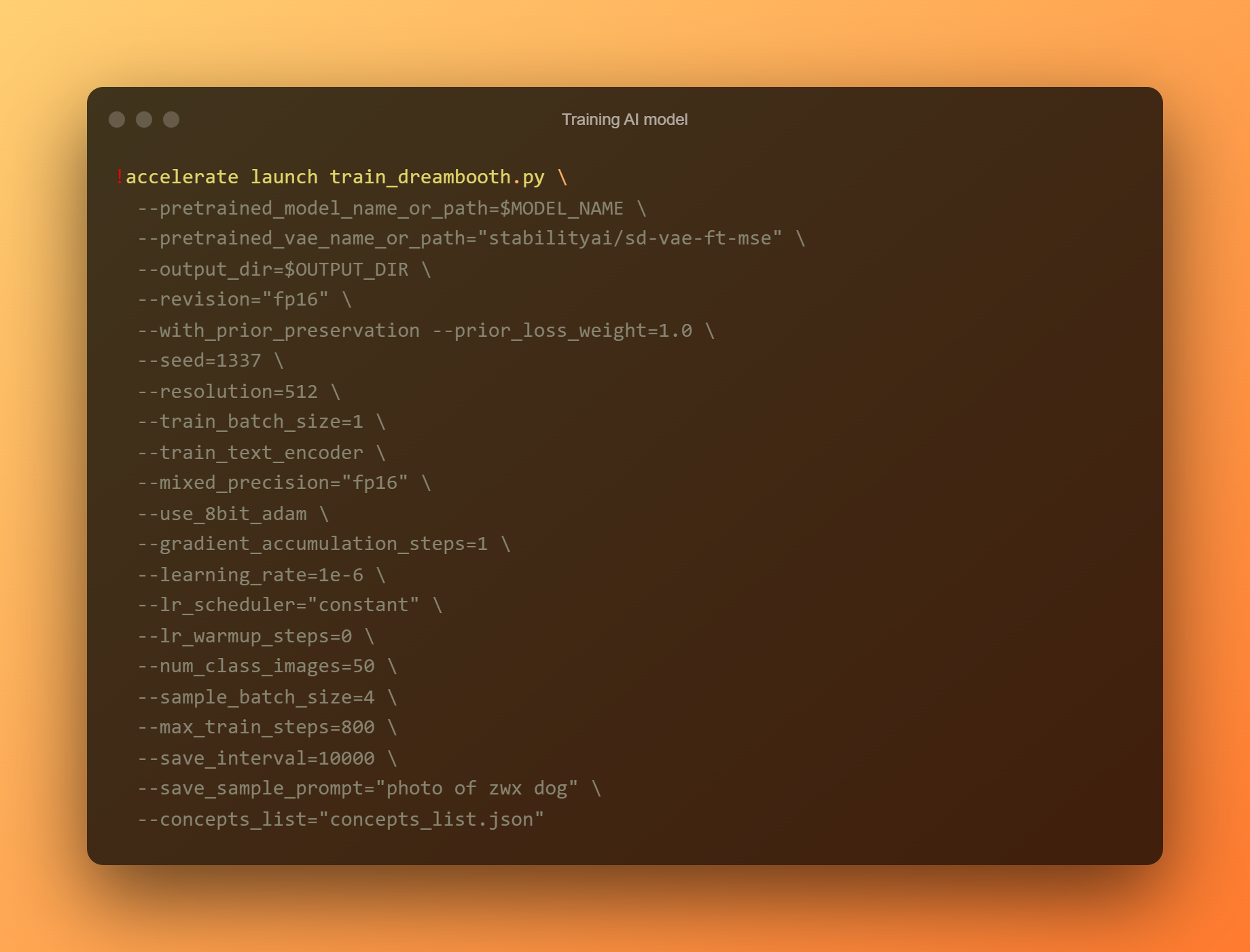
Model de tren d'IA
Aquesta és la fase més important, ja que utilitzareu DreamBooth per entrenar un nou model d'IA basat en totes les vostres fotografies de referència enviades. Heu de limitar la vostra atenció a dos camps d'entrada. "—instance prompt" és el primer paràmetre. Heu de proporcionar un nom molt diferent aquí.
L'argument '–llista de conceptes' és el segon camp d'entrada crític. S'ha de canviar el nom perquè coincideixi amb el que s'utilitza a la secció "Canvia el missatge".
Genera imatges d'IA
Les imatges AI es crearan en aquesta etapa, on podeu introduir les instruccions de text.

Limitacions de Dreambooth
- L'indicador d'ordres es converteix en una barrera per fer iteracions del tema amb alts graus de detall. DreamBooth pot canviar el context del subjecte, però si el model vol canviar el mateix tema, hi ha problemes amb el marc.
- Un altre problema és sobreajustar la imatge de sortida a la imatge d'entrada. Si no hi ha prou imatges subministrades, és possible que el tema no es consideri o es pot combinar amb el context de les imatges enviades. Quan es demana un context per a una generació estranya, passa el mateix.
Conclusió
Per produir sortides a partir d'una única entrada de text, la majoria dels models de text a imatge requereixen milions de paràmetres i biblioteques.
DreamBooth simplifica l'adquisició i l'ús de contingut per als consumidors ja que només requereix l'entrada de tres a cinc fotografies temàtiques juntament amb un fons textual.





Deixa un comentari