Premještanje i skladištenje podataka su dobili na značaju kao rezultat stalne ekspanzije IT industrije i miliona podataka koji se proizvode svake sekunde.
Osim toga, ovi podaci moraju biti jasni i jednostavni za razumijevanje kako bi se podržalo precizno donošenje odluka.
Da bi održala konkurentnost i postigla dugoročni uspjeh, vaša kompanija mora skladištiti i premještati podatke koristeći najefikasnija dostupna rješenja.
Zbog toga, sve više preduzeća koristi tkanje podataka. Jedan od najvećih načina da uštedite svoje vrijeme, novac i resurse je korištenje strukture podataka za obradu podataka i omogućavanje AI mašinskog učenja.
U ovom članku ćemo detaljno pogledati Data Fabric, uključujući njegovu upotrebu, glavne komponente, prednosti i druge vitalne detalje.
Dakle, šta je Data Fabric?
Bez obzira na to gdje se nalaze, upravljajte svojim podacima i aplikacijama i pazite na njih. U svojoj srži, mreža podataka je integrisana arhitektura podataka koja je sigurna, raznovrsna i prilagodljiva.
Mreža podataka, koja kombinuje najbolje od oblaka, jezgre i ruba, na mnogo je načina novi strateški pristup vašem poslovanju skladištenja podataka.
Iako je centralno kontroliran, može doseći svuda, uključujući lokalne, javne i privatne oblake, kao i rubne i IoT uređaje.
Silosi podataka veličine nebodera i raznolike nepovezane infrastrukture stvar su prošlosti. Mreža podataka je zasnovana na sveobuhvatnoj kolekciji alata za upravljanje podacima koji garantuju konzistentnost u svim vašim povezanim okruženjima.
Kroz automatizaciju, pojednostavljuje upravljanje koje oduzima mnogo vremena, ubrzava razvoj, testiranje i implementaciju i štiti vašu imovinu XNUMX sata dnevno.
Bez obzira gdje se nalaze vaši podaci i aplikacije, možete pratiti troškove skladištenja, performanse i efikasnost sa jedne platforme.
Možete brzo (i, u nekim slučajevima, automatski) izvršiti promjene u svojoj infrastrukturi hibridnog oblaka kada steknete znanje o njoj, kao što je ispravljanje grešaka, rješavanje problema sigurnosti i usklađenosti, te povećanje i smanjenje računarstva.
Ukratko, Data Fabric poboljšava implementaciju infrastrukture i efikasnost održavanja, smanjuje troškove i povećava performanse.
Zašto biste trebali koristiti Data Fabric?
Svakoj firmi orijentisanoj na podatke potrebna je sveobuhvatna strategija koja prevazilazi prepreke poput vremena, prostora, raznih vrsta softvera i lokacija podataka. Podaci ne bi trebali biti skriveni iza zaštitnih zidova ili raspršeni na nekoliko mjesta, već bi trebali biti dostupni ljudima kojima su potrebni.
Da bi uspjeli, preduzećima je potrebno rješenje za podatke koje je otporno na budućnost i sigurno, efikasno, ujedinjeno okruženje. Ovo se može uraditi pomoću strukture podataka.
Potrebe modernih preduzeća za povezivanjem u realnom vremenu, samoposluživanjem, automatizacijom i univerzalnim promjenama ne mogu se zadovoljiti tradicionalnom integracijom podataka.
Iako prikupljanje podataka iz mnogih izvora često nije problem, mnoga preduzeća se bore da integrišu, obrađuju, kuriraju i transformišu podatke sa podacima iz drugih izvora.
Da bi se pružilo dubinsko razumijevanje potrošača, partnera i robe, ovaj kritični korak u procesu upravljanja podacima mora se dogoditi. Zbog njihove sposobnosti da nadograde svoje sisteme, bolje služe kupcima i iskoriste ih cloud computing, firme kao rezultat dobijaju konkurentsku prednost.
Gdje god da se nalaze korisnici organizacije, tkanje podataka može se zamisliti kao tkanina koja se širi širom svijeta. Na ovoj mreži, korisnik može biti na bilo kojoj lokaciji i dalje imati neograničen pristup podacima u realnom vremenu na bilo kojoj drugoj lokaciji.
Osnovne komponente Data Fabric-a
Osnovne komponente koje čine strukturu podataka mogu se birati i prikupljati na različite načine. Tvornica podataka se stoga može implementirati na različite načine. Pogledajmo primarne elemente strukture podataka.
- Prošireni katalog podataka
- Perzistentni sloj
- znanje Grafikon
- Insights and Recommendations Engine
- Sloj za pripremu i isporuku podataka
- Orchestration and Data Ops
Možete pogledati ključne stubove arhitekture Data Fabric prema Gartner.
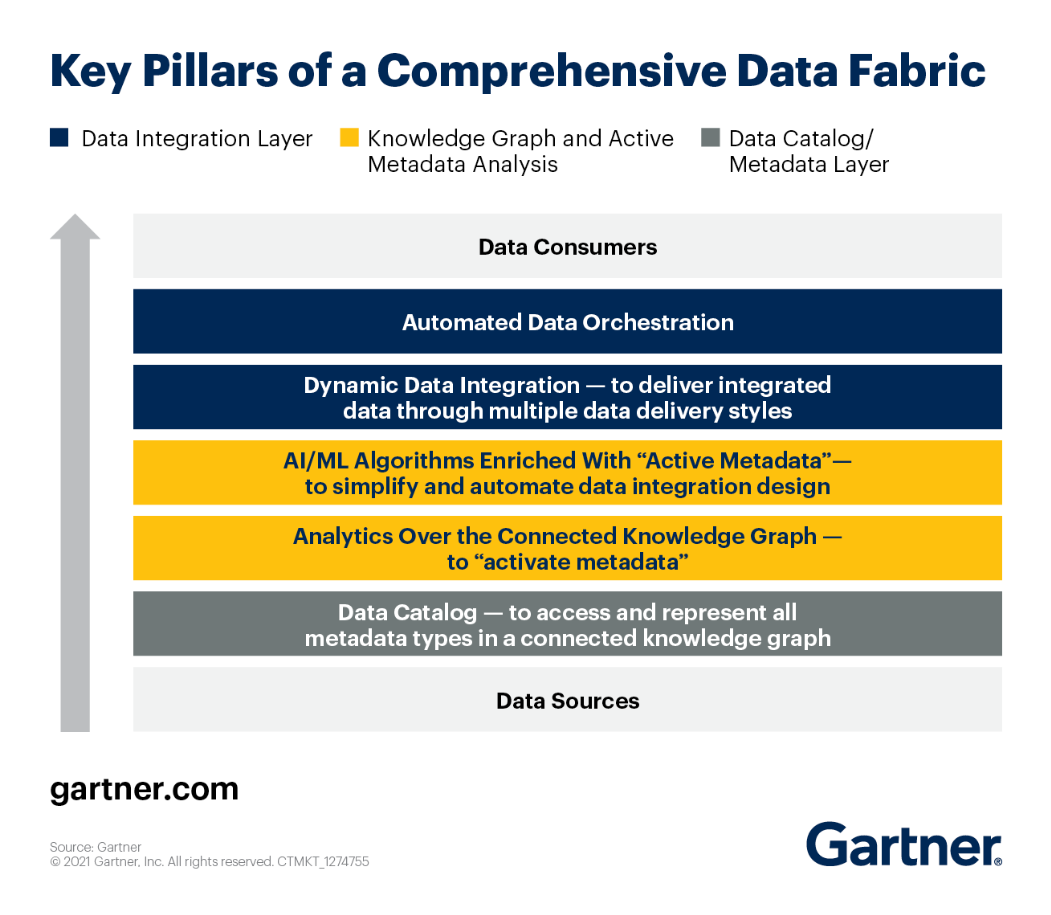
Pogledajmo svaki od njih izbliza.
- Katalog proširenih podataka – daje korisnicima pristup svim vrstama metapodataka kroz snažan graf znanja. Osim toga, razvija karakteristične asocijacije između postojećih informacija i vizualno ih prikazuje na razumljiv način. Korišćenjem mašinsko učenje za povezivanje sredstava podataka sa terminologijom organizacije, poboljšani katalozi podataka kreiraju poslovni semantički sloj za strukturu podataka.
- Perzistentni sloj – Ovisno o slučaju upotrebe, za dinamičko pohranjivanje podataka mogu se koristiti različiti relacijski i nerelacijski modeli.
- Aktivni metapodaci – karakteristični dio strukture podataka. daje strukturi podataka mogućnost prikupljanja, dijeljenja i analize mnogih vrsta metapodataka. Za razliku od pasivnih metapodataka, aktivni metapodaci prate tekuću upotrebu podataka od strane sistema i ljudi (metapodaci zasnovani na dizajnu i u toku rada).
- znanje Grafikon – Još jedna osnovna jedinica za tkanje podataka. Oni koriste standardne ID-ove, prilagodljive šeme, itd. za prikaz povezanog okruženja podataka. Grafovi znanja čine strukturu podataka pretraživom i pomažu u njenom razumijevanju.
- Insights and Recommendation Engine – gradi pouzdane, snažne cevovode podataka za operativne i analitičke slučajeve upotrebe.
- Sloj za pripremu i isporuku podataka – Podaci se mogu preuzeti iz bilo kojeg izvora i poslati na bilo koji cilj koristeći bilo koji mehanizam, uključujući ETL (bulk), razmjenu poruka, CDC, virtualizaciju i API.
- Orchestration and Data Ops – Ova komponenta koristi podatke za koordinaciju svih zadataka u svakoj fazi toka posla od kraja do kraja. Omogućuje vam da odaberete kada i koliko često ćete pokretati cjevovode, kao i kako upravljati podacima koje ti cjevovodi proizvode.
prednosti
Zdravi podaci u distribuiranom kontekstu su dostupni, učitani, integrisani i dijeljeni preko mreže podataka. Radeći to, preduzeća mogu ubrzati digitalnu tranziciju i maksimizirati vrijednost svojih podataka.
U nastavku su navedene ključne prednosti modela strukture podataka.
Efikasnost:
Tkanina podataka može kompajlirati rezultate iz ranijih upita, omogućavajući sistemu da skenira agregiranu tabelu, a ne sirove podatke u pozadini.
Zbog bržeg vremena odgovora na pojedinačne zahtjeve, dopuštanje zahtjevima da pristupe manjim skupovima podataka umjesto skeniranja sirovih podataka cijele trgovine također rješava problem nekoliko istovremenih zahtjeva.
Preduzeća mogu brzo odgovoriti na hitne upite zbog sposobnosti strukture podataka da značajno skrati vrijeme odgovora na upite.
Pametna integracija
Za integraciju podataka u različite vrste podataka i krajnjih tačaka, strukture podataka koriste semantičke grafove znanja, upravljanje metapodacima i mašinsko učenje.
Ovo pomaže timovima za upravljanje podacima da grupišu relevantne skupove podataka zajedno i ugrade potpuno nove izvore podataka u ekosistem podataka kompanije.
Ova funkcija automatizira dijelove upravljanja zadacima podataka, što rezultira gore navedenim uštedama produktivnosti, ali također pomaže u razbijanju silosa sistema podataka, centraliziranju procedura upravljanja podacima i poboljšanju ukupnog kvaliteta podataka.
Efikasnija sigurnost podataka
To također ne podrazumijeva žrtvovanje sigurnosti podataka i zaštite privatnosti zarad proširenja pristupa podacima.
U stvari, to zahtijeva pooštravanje zaštitnih ograda za kontrolu pristupa i implementaciju više mjera upravljanja podacima kako bi se garantovalo da su određene uloge jedine koje imaju pristup datom skupu podataka.
Dodatno, arhitekture strukture podataka omogućavaju tehničke i sigurnosni timovi za implementaciju maskiranja podataka i šifriranje oko povjerljivih i osjetljivih informacija, smanjujući vjerovatnoću dijeljenja podataka i hakovanja sistema.
Demokratizacija podataka
Samouslužne aplikacije su olakšane dizajnom strukture podataka, proširujući doseg pristupa podacima izvan više tehničkog osoblja kao što su inženjeri podataka, programeri i timovi za analizu podataka.
Omogućavajući poslovnim korisnicima da donose brže poslovne odluke i puštanjem tehničkih korisnika da daju prioritet aktivnostima koje najbolje koriste njihove skupove vještina, eliminacija uskih grla u podacima dovodi do povećanja produktivnosti.
Koristite slučajeve
Arhitektura strukture podataka ima za cilj da ponudi sveobuhvatnu strukturu za rukovanje svim oblicima pohranjenih informacija tako da se mogu učiniti upotrebljivim kada je to potrebno.
Ove vrste podataka mogu se koristiti za bilo šta, od predviđanja prodaje do izvještaja o stanju IT infrastrukture organizacije ili krajnjih tačaka korisnika.
Slučajevi upotrebe arhitekture strukture podataka su identični slučajevima upotrebe za bilo koju drugu vrstu podataka u poslovanju, uključujući prodaju, marketing, IT, sajber sigurnost i još mnogo toga.
Međutim, podaci u organizaciji su često organizirani, polustrukturirani ili nestrukturirani u gotovo svim slučajevima upotrebe. Relaciona baza podataka može pohraniti strukturirane podatke i odmah se koristiti, kao što su zapisi baze podataka.
Podaci koji nisu očišćeni ili kategorizirani nazivaju se nestrukturiranim podacima i moraju se pripremiti za korištenje kada je to potrebno.
Nekoliko oblika nestrukturiranih podataka koje mnoge firme mogu nabaviti i pohraniti za buduću upotrebu uključuju mašinsko učenje, analitiku, podatke senzora, računalstvo u oblaku i aplikacije za produktivnost.
U polustrukturiranim podacima, koji uključuju podatke prepoznate vrste sačuvane s nestrukturiranim podacima (kao što su zip datoteke, web stranice i e-poruke), oba aspekta su prisutna.
Brojni mogući slučajevi upotrebe zasnovani na kapacitetu strukture podataka da pomogne kompanijama da brže i efikasnije pristupe i koriste svoje podatke mogu se pronaći istraživanjem njihove upotrebe.
Tipični primjeri uključuju:
- Otkrivanje prijevara
- IoT analitika
- Logistika lanca snabdevanja
- Analitika podataka u realnom vremenu
- Inteligencija kupaca
- Povećava operativnu efikasnost
- Analiza preventivnog održavanja
- Pored toga, modeli rizika povratka na posao
- Osiguranje transakcija kreditnim karticama
- Predviđanje odljeva, otkrivanje prijevara i kreditno ocjenjivanje
zaključak
U zaključku, silosi podataka moraju progresivno da se raspadaju kako se nivoi naše upotrebe podataka povećavaju kako bi se napravio prostor za povezane kompanije.
Primena strukture podataka predstavlja značajan napredak na ovom putu, rangirajući se među najrevolucionarnijim otkrićima od razvoja relacionih baza podataka 1970-ih.
To je zato što je struktura podataka više od tehnologije ili jedne stavke.
Podaci i poslovne operacije zamršeno su isprepleteni kroz dizajn arhitekture, sistematske procedure i promjenu mentaliteta.
Data Fabric smanjuje troškove, povećava performanse i olakšava efikasnije postavljanje i održavanje infrastrukture. To bi mogla biti ključna komponenta za osiguravanje da svaki proces, aplikacija i poslovna odluka budu vođeni podacima.





Ostavite odgovor