Решаваща и желана задача в компютърното зрение и графиката е създаването на творчески портретни филми от най-висок калибър.
Въпреки че са предложени няколко ефективни модела за тонизиране на портретни изображения, базирани на мощния StyleGAN, тези ориентирани към изображения техники имат ясни недостатъци, когато се използват с видеоклипове, като фиксиран размер на рамката, изискване за подравняване на лицето, липса на детайли, различни от лицето и времева непоследователност.
Революционна рамка VToonify се използва за справяне с трудно контролираното прехвърляне на портретен видео стил с висока разделителна способност.
Ще разгледаме най-новото проучване на VToonify в тази статия, включително неговата функционалност, недостатъци и други фактори.
Какво е Vtoonify?
Рамката VToonify позволява персонализирано предаване в портретен стил на видео с висока разделителна способност.
VToonify използва слоевете със средна и висока разделителна способност на StyleGAN, за да създаде висококачествени артистични портрети, базирани на многомащабни характеристики на съдържанието, извлечени от енкодер за запазване на детайлите на рамката.
Получената напълно конволюционна архитектура приема неподравнени лица във филми с променлив размер като вход, което води до области с цели лица с реалистични движения в изхода.

Тази рамка е съвместима с настоящите базирани на StyleGAN модели за тонизиране на изображения, което им позволява да бъдат разширени до видео тонизиране и наследява атрактивни характеристики като регулируем цвят и персонализиране на интензитета.
Това проучване въвежда две инстанции на VToonify, базирани на Toonify и DualStyleGAN за прехвърляне на портретен видео стил, базиран на колекция и екземпляр, съответно.
Обширни експериментални открития показват, че предложената рамка VToonify превъзхожда съществуващите подходи при създаването на висококачествени, съгласувани във времето художествени портретни филми с променливи стилови параметри.
Изследователите предоставят Бележник на Google Colab, за да можете да си изцапате ръцете с него.
Как работи?
За да постигне регулируемо прехвърляне на портретен видео стил с висока разделителна способност, VToonify комбинира предимствата на рамката за превод на изображения с базираната на StyleGAN рамка.
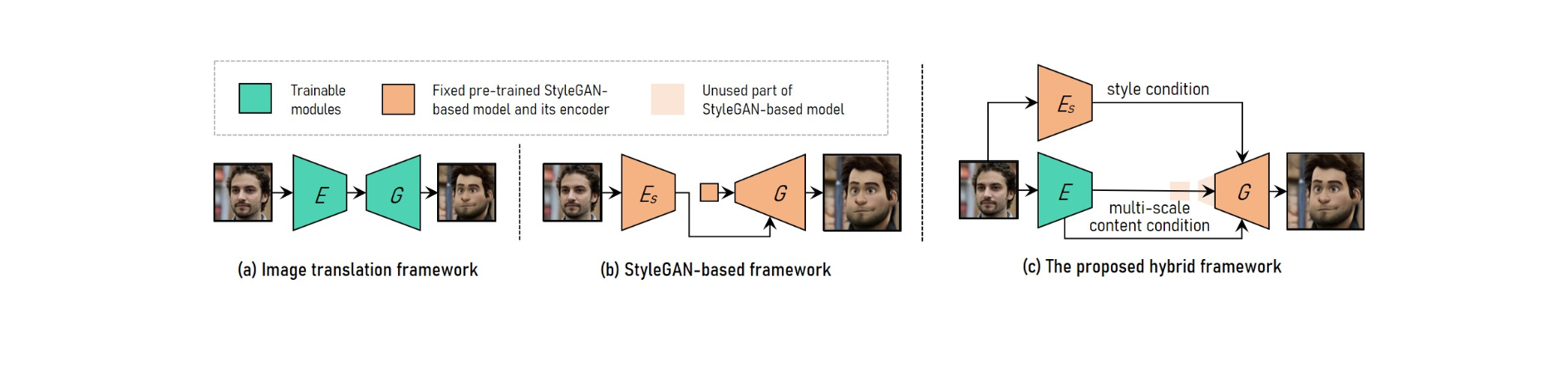
За да поеме различни входни размери, системата за превод на изображения използва напълно конволюционни мрежи. Обучението от нулата, от друга страна, прави предаването с висока разделителна способност и контролиран стил невъзможно.
Предварително обученият модел StyleGAN се използва в базираната на StyleGAN рамка за трансфер с висока разделителна способност и контролиран стил, въпреки че е ограничен до фиксиран размер на картината и загуба на детайли.
StyleGAN е модифициран в хибридната рамка чрез изтриване на функцията за въвеждане с фиксиран размер и слоеве с ниска разделителна способност, което води до напълно конволюционна архитектура на енкодер-генератор, подобна на тази на рамката за превод на изображения.
За да поддържате подробности за рамката, обучете енкодер да извлича многомащабни характеристики на съдържанието на входната рамка като допълнително изискване за съдържание към генератора. Vtoonify наследява гъвкавостта на стиловия контрол на модела StyleGAN, като го поставя в генератора, за да дестилира както неговите данни, така и модела.
Ограничения на StyleGAN & Предложен Vtoonify
Художествените портрети са често срещани в нашето ежедневие, както и в творчески бизнеси като изкуство, социална медия аватари, филми, развлекателни реклами и т.н.
С развитието на дълбоко учене технология, вече е възможно да създавате висококачествени артистични портрети от реални снимки на лица с помощта на автоматизирано прехвърляне на портретен стил.
Има различни успешни начини, създадени за прехвърляне на стил, базиран на изображения, много от които са лесно достъпни за начинаещи потребители под формата на мобилни приложения. През последните няколко години видео материалите бързо се превърнаха в опора на емисиите ни в социалните медии.
Възходът на социалните медии и ефимерните филми увеличи търсенето на иновативно видео редактиране, като прехвърляне на портретен видео стил, за генериране на успешни и интересни видеоклипове.
Съществуващите техники, ориентирани към изображения, имат значителни недостатъци, когато се прилагат към филми, ограничавайки тяхната полезност при автоматизирана стилизация на портретно видео.
StyleGAN е общ гръбнак за разработване на модел за прехвърляне на стил на портретна картина поради способността му да създава висококачествени лица с регулируемо управление на стила.
Базирана на StyleGAN система (известна също като тоонификация на картина) кодира истинско лице в латентното пространство на StyleGAN и след това прилага получения стилов код към друг StyleGAN, фино настроен върху набора от данни за артистичен портрет, за да създаде стилизирана версия.
StyleGAN създава картини с подравнени лица и с фиксиран размер, което не благоприятства динамичните лица в кадри от реалния свят. Изрязването и подравняването на лицето във видеото понякога водят до частично лице и неудобни жестове. Изследователите наричат този проблем "ограничението за фиксирани култури" на StyleGAN.
За неподравнени лица е предложен StyleGAN3; обаче поддържа само зададен размер на картината.
Освен това, скорошно проучване откри, че кодирането на неподравнени лица е по-голямо предизвикателство от подравнените лица. Неправилното кодиране на лицето е вредно за трансфера на портретен стил, което води до проблеми като промяна на самоличността и липсващи компоненти в реконструираните и стилизирани рамки.
Както беше обсъдено, една ефективна техника за прехвърляне на портретен видео стил трябва да се справи със следните проблеми:
- За да се запазят реалистични движения, подходът трябва да може да се справя с неподравнени лица и различни размери на видео. Големият размер на видеото или широкият зрителен ъгъл могат да уловят повече информация, като същевременно предпазват лицето от излизане от рамката.
- За да се конкурира с често използваните днес HD джаджи, е необходимо видео с висока разделителна способност.
- Трябва да се предложи гъвкав контрол на стила, за да могат потребителите да променят и избират своя избор, когато разработват реалистична система за взаимодействие с потребителя.
За тази цел изследователите предлагат VToonify, нова хибридна рамка за видео тонификация. За да преодолеят ограничението за фиксирана култура, изследователите първо изучават еквивариантността на превода в StyleGAN.
VToonify съчетава предимствата на базираната на StyleGAN архитектура и рамката за превод на изображения, за да постигне регулируемо прехвърляне на портретен видео стил с висока разделителна способност.
Следват основните приноси:
- Изследователите проучват ограничението за фиксирана култура на StyleGAN и предлагат решение, базирано на еквивариантността на превода.
- Изследователите представят уникална напълно конволюционна рамка VToonify за контролиран трансфер на портретен видео стил с висока разделителна способност, който поддържа неподравнени лица и различни размери на видео.
- Изследователите изграждат VToonify на базата на Toonify и DualStyleGAN и кондензират опорите по отношение както на данни, така и на модел, за да позволят базиран на колекция и базиран на пример трансфер на портретен видео стил.
Сравняване на Vtoonify с други най-съвременни модели
Тонизирайте
Той служи като основа за трансфер на стил, базиран на колекция, върху подравнени лица с помощта на StyleGAN. За да извлекат стиловите кодове, изследователите трябва да подравнят лицата и да изрежат 256256 снимки за PSP. Toonify се използва за генериране на стилизиран резултат със стилови кодове 1024*1024.
Накрая те подравняват отново резултата във видеото към първоначалното му местоположение. Нестилизираната област е зададена на черно.

DualStyleGAN
Това е гръбнак за прехвърляне на стил, базиран на образци, базиран на StyleGAN. Те използват същите техники за предварителна и последваща обработка на данни като Toonify.
Pix2pixHD
Това е модел за превод от изображение към изображение, който обикновено се използва за уплътняване на предварително обучени модели за редактиране с висока разделителна способност. Обучава се с помощта на сдвоени данни.
Изследователите използват pix2pixHD като допълнителни входове за карта на екземпляри, тъй като използва извлечена карта за анализиране.
Движение от първи ред
FOM е типичен модел за анимация на изображения. Обучен е на 256256 снимки и се представя зле с други размери на изображения. В резултат на това изследователите първо мащабират видео кадрите до 256*256 за FOM към анимация и след това преоразмеряват резултатите до техния оригинален размер.
За справедливо сравнение FOM използва първата стилизирана рамка от своя подход като референтно стилово изображение.
ДаГАН
Това е 3D модел за анимация на лице. Те използват същите методи за подготовка и последваща обработка на данни като FOM.

Предимства
- Може да се използва в изкуствата, аватарите в социалните медии, филмите, развлекателната реклама и т.н.
- Vtoonify може да се използва и в метавселената.
Ограничения
- Тази методология извлича както данните, така и модела от базираните на StyleGAN гръбнаци, което води до отклонение на данните и модела.
- Артефактите са причинени най-вече от разликите в размера между стилизираната област на лицето и другите секции.
- Тази стратегия е по-малко успешна, когато се занимавате с неща в областта на лицето.
Заключение
И накрая, VToonify е рамка за контролирано от стила тонизиране на видео с висока разделителна способност.
Тази рамка постига голяма производителност при обработката на видеоклипове и позволява широк контрол върху структурния стил, цветовия стил и степента на стил чрез кондензиране на базирани на StyleGAN модели за тонизиране на изображения по отношение на техните синтетични данни и мрежови структури.





Оставете коментар