Змест[Схаваць][Паказаць]
Фальшывыя фатаграфіі і відэа не з'яўляюцца навінкай. З моманту шырокага распаўсюджвання Інтэрнэту людзі ствараюць падробкі, каб падмануць або пацешыць з тых часоў, як з'явіліся выявы і фільмы.
Тым не менш, ёсць новы тып машынна вырабленых падробак, з-за якіх калі-небудзь нам будзе цяжка адрозніць рэальнасць ад выдумкі.
Гэтыя фальшыўкі адрозніваюцца ад простых маніпуляцый з выявамі, створаных праграмным забеспячэннем для рэдагавання, такім як Photoshop, або спрытна апрацаваных фільмаў мінулага.
Глыбокія падробкі з'яўляюцца найбольш вядомым прыкладам «сінтэтычных носьбітаў» — малюнкаў, гукаў і відэа, якія выглядаюць створанымі з выкарыстаннем звычайных метадаў, але на самой справе былі створаны з дапамогай складанага праграмнага забеспячэння.
Deepfakes існуюць ужо некаторы час, і хаця іх самым папулярным прымяненнем было нанясенне галоў вядомых людзей на целы акцёраў у парнаграфічных фільмах, у іх ёсць магчымасць ствараць пераканаўчыя кадры, на якіх хто заўгодна робіць што заўгодна і дзе заўгодна.
У гэтай публікацыі мы разгледзім Deepfakes, як гэта працуе, як вы можаце стварыць іх самастойна і многае іншае.
Такім чынам, што такое DeepFake?
Deepfake - спалучэнне фраз deep learning і fake - гэта частка сінтэтычныя носьбіты у якім падабенства іншага чалавека выкарыстоўваецца для замены падабенства чалавека на ўжо існуючай фатаграфіі або відэа.
Deepfakes выкарыстоўвае складаныя метады машыннага навучання і штучнага інтэлекту для мадыфікацыі і стварэння візуальнай і аўдыяінфармацыі, якая мае высокі патэнцыял для падману.
Метады глыбокага навучання, такія як аўтакадавальнікі і генератыўныя спаборніцкія сеткі, з'яўляюцца асноўным механізмам стварэння глыбокіх падробак (GAN).
Гэтыя мадэлі выкарыстоўваюцца для аналізу мімічных эмоцый і рухаў чалавека і сінтэзу фатаграфій твараў іншых людзей, якія дэманструюць супастаўныя выразы твару і рухі.
Выкарыстанне дыпфейкаў у парнаграфічных відэароліках са знакамітасцямі, фальшывых навінах, містыфікацыях і фінансавым махлярстве прыцягнула значную ўвагу. І прамысловасць, і ўрад адказалі, спрабуючы знайсці іх і абмежаваць іх выкарыстанне.
Мадэль руху першага парадку
Калі ў мінулым мы спрабавалі распрацаваць глыбокія фэйкі, праблема заключалася ў тым, што нам патрэбны нейкія дадатковыя веды або папярэднія веды, каб гэтыя падыходы спрацавалі.
У якасці ілюстрацыі патрабуюцца маркеры твару, калі мы хочам прасачыць рух галавы. Ацэнка позы была неабходная, калі мы хацелі адлюстраваць рух усяго цела.
Гэта змянілася на канферэнцыі NeurIPS у мінулым годзе, калі даследчая група з Універсітэта Таронта прадставіла сваю працу, "Мадэль руху першага парадку для анімацыі выявы».
Для гэтага падыходу дадатковыя веды анімацыі не патрэбныя. Акрамя таго, пасля навучання гэтай мадэлі яе можна выкарыстоўваць для пераноснага навучання і прымяняць да любога прадмета, які падпадае пад тую ж катэгорыю.
Давайце разгледзім працу гэтага метаду крыху далей. Выманне і генерацыя руху складаюць першую палову ўсяго працэсу. У якасці ўваходных дадзеных выкарыстоўваюцца відэа і зыходныя выявы.
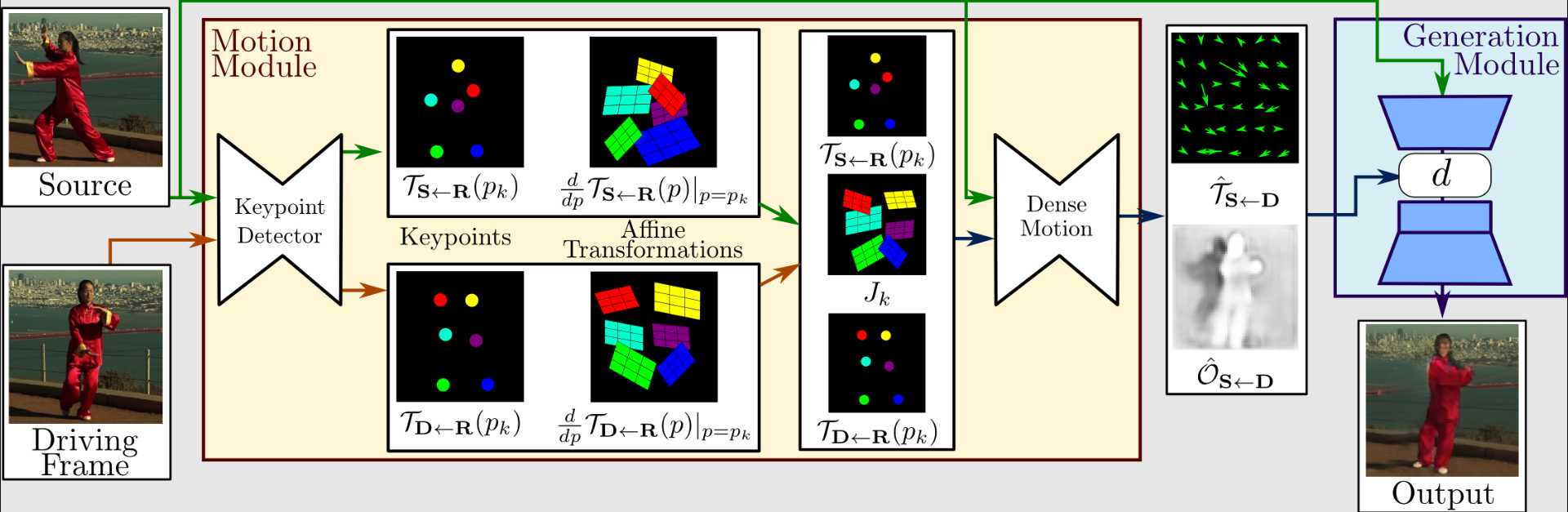
Каб атрымаць прадстаўленне руху першага парадку, якое складаецца з разрэджаных ключавых кропак і лакальных афінных пераўтварэнняў, экстрактар руху выкарыстоўвае аўтакадавальнік для ідэнтыфікацыі ключавых кропак.
Каб стварыць шчыльны аптычны паток і карту аклюзіі з сеткай шчыльнага руху, яны выкарыстоўваюцца разам з кіраваннем відэа. Затым генератар візуалізуе мэтавае малюнак, выкарыстоўваючы выхады з сеткі шчыльнага руху і зыходнага відарыса.
Па ўсіх напрамках гэтая праца працуе лепш, чым сучасныя. Ён таксама змяшчае функцыі, якіх проста няма ў іншых мадэлях. Ён працуе з некалькімі тыпамі малюнкаў, так што вы можаце прымяніць яго да выяваў твару, цела, мультфільмаў і г.д., што надзвычай выдатна.
Гэта стварае шмат новых магчымасцей. Яшчэ адзін наватарскі аспект нашай стратэгіі заключаецца ў тым, што цяпер яна дазваляе ствараць высакаякасныя Deepfakes, выкарыстоўваючы толькі адну выяву мэтавага аб'екта, падобна таму, як мы робім з YOLO для аб'екта прызнанне.
Працэс стварэння мадэлі Deepfake
Для генерацыі глыбокага фейка неабходныя тры працэсы: выманне, навучанне і стварэнне. Асноўныя моманты кожнага з гэтых этапаў і тое, як яны звязаны з агульным працэсам, будуць разгледжаны ў гэтым раздзеле.
Здабыча
Deepfakes выкарыстоўваюць глыбокія нейронавыя сеткі, каб змяняць абліччы, і для карэктнай і пераканаўчай працы ім патрабуецца шмат дадзеных (малюнкаў). Працэс вымання - гэта этап, на якім здабываюцца ўсе кадры з відэакліпаў, распазнаюцца твары, а потым яны выраўноўваюцца для максімальнай прадукцыйнасці.
навучанне
На этапе навучання ст нейронных сеткі можа змяніць адзін твар на іншы. У залежнасці ад памеру трэніровачнага набору і навучальнага гаджэта навучанне можа заняць некалькі гадзін або нават дзён.
Навучанне проста трэба скончыць адзін раз, як і большасць іншых трэніровак нейронных сетак. Пасля навучання мадэль магла б змяніць твар чалавека А на твар Б.
Стварэнне
Пасля навучання мадэлі можа быць выраблены глыбокі фэйк. Кадры бяруцца з відэа, а потым выраўноўваюцца па ўсіх гранях. Затым навучаная нейронавая сетка выкарыстоўваецца для пераўтварэння кожнага кадра.
На апошнім этапе трансфармаваны твар трэба аб'яднаць з зыходнай рамкай.
Пабудова мадэлі выяўлення Deepfake
Мантаж і кланаванне GitHub Repo
Магчымасць бясплатнага выкарыстання графічных працэсараў Google падчас працы ў Colab з'яўляецца перавагай для глыбокае вывучэнне. Дадатковай перавагай з'яўляецца магчымасць мантавання Google Drive на воблачнай віртуальнай машыне (VM).
Маючы лёгкі доступ да ўсіх сваіх рэчаў, карыстальнік уключаны. У гэтым раздзеле можна знайсці праграму, неабходную для падключэння Google Drive да віртуальнай машыны ў воблаку.


Імпарт модуляў
Зараз мы імпартуем усе неабходныя модулі.
Выкананне мадэлі
Мы будзем выкарыстоўваць прыклад, які спалучае нерухомую фатаграфію Пуціна (крыніца выявы) з відэа Абамы. У выніку атрымалася відэа, на якім Пуцін размаўляе і жэстыкулюе з дакладна такой жа мімікай, якую выкарыстоўваў Абама за рулём.
Перад адлюстраваннем выніку мадэлі будзе загружаны носьбіт і аб'яўлены функцыі. Затым будуць загружаны кантрольныя кропкі і пабудавана мадэль. Пасля стварэння глыбокай падробкі будуць паказаны два розныя стылі анімацыі.
Пуціна ажыўляюць рухі Абамы, якія выкарыстоўваюць адноснае зрушэнне ключавых кропак. Тое, як эмоцыі і мова цела Абамы прыгожа і выразна адлюстраваны Пуцінам у яго відэароліках, уражвае.
Ёсць некалькі мікраскапічных памылак, асабліва калі Абама падымае бровы і міргае вачыма. Гэтыя выразы не зусім дакладна тыражуюцца ў кадрах Пуціна.
Без фону з глыбокай падробкай фільм пра Пуціна выглядаў бы дастаткова надзейным і сапраўдным, калі б яго паглядзелі па тэлебачанні ці сацыяльныя медыя.
Стварэнне мадэлі
Цяпер мы будзем выкарыстоўваць папярэдне падрыхтаваныя кантрольныя кропкі для стварэння поўнай мадэлі.
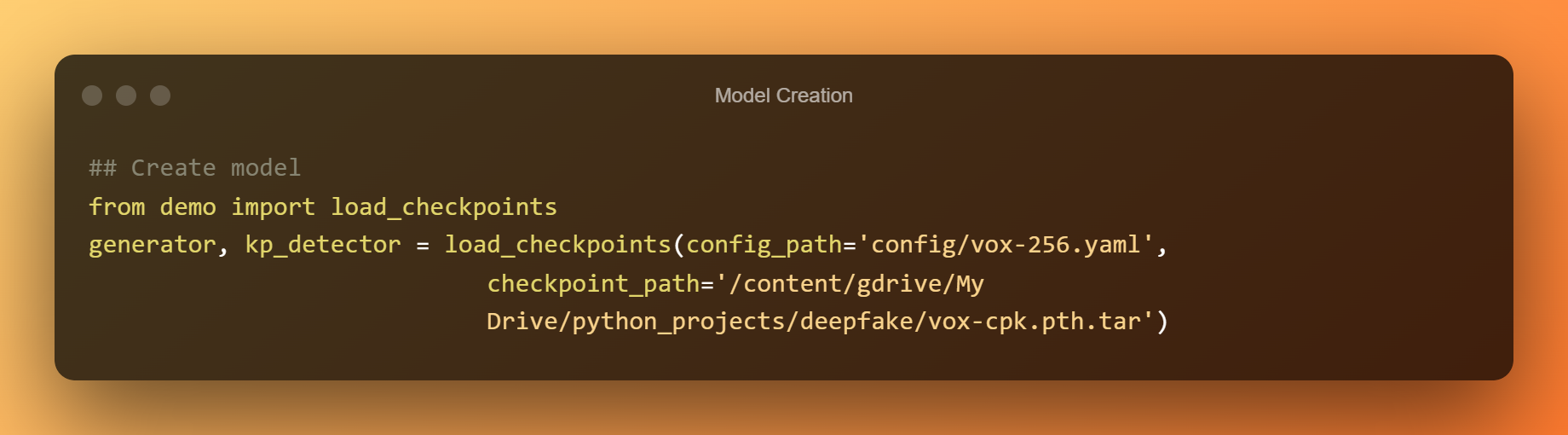
Выяўленне Deepfake
Адноснае зрушэнне ключавых кропак выкарыстоўваецца для анімацыі элементаў у ячэйцы ніжэй. У наступнай ячэйцы замест гэтага выкарыстоўваюцца абсалютныя каардынаты, але прапорцыі ўсіх элементаў такім чынам будуць узяты з відэа ваджэння.
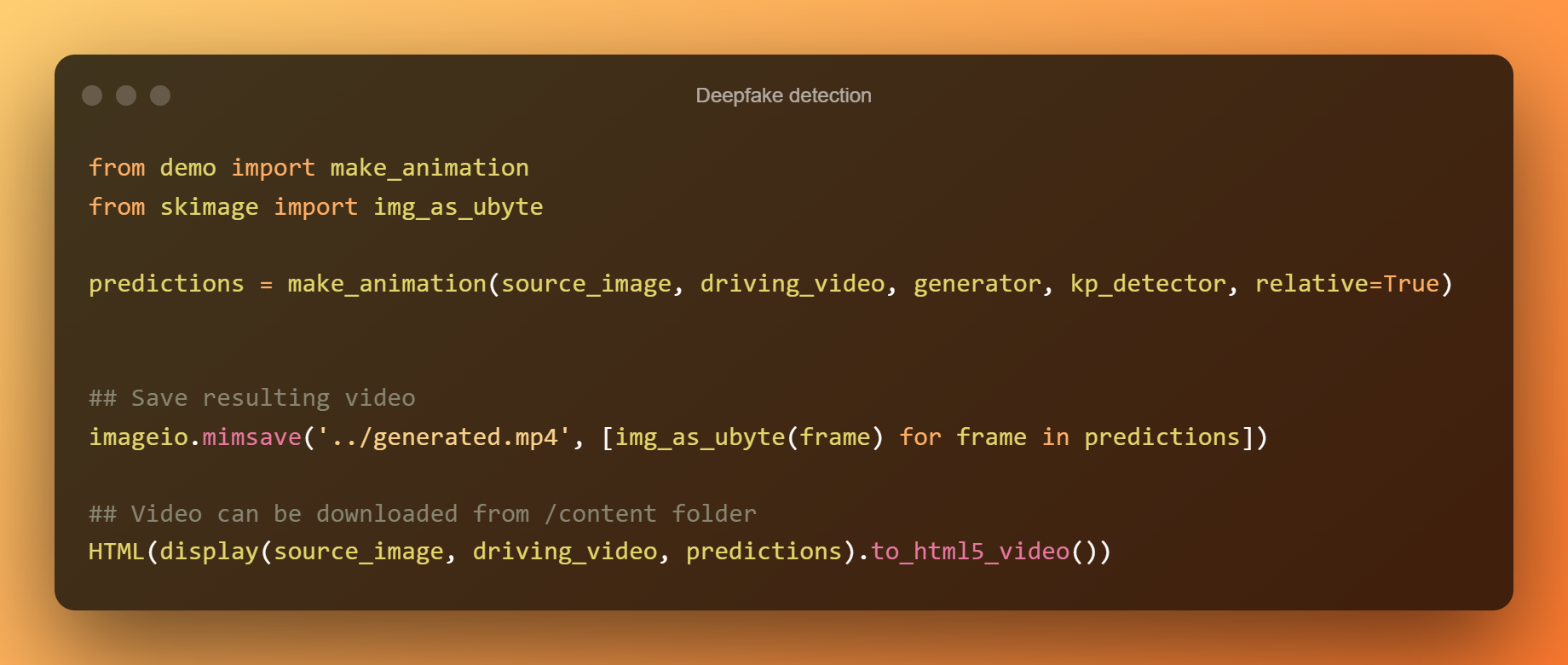
Павышэнне вываду з выкарыстаннем абсалютных каардынат

Вы зможаце распрацаваць выяўленне deepfake такім чынам.
Якія рызыкі тэхналогіі Deepfake?
Відэа Deepfake цяпер прывабныя і забаўляльныя для прагляду дзякуючы сваёй навізне. Аднак існуе рызыка, якая можа выйсці з-пад кантролю, якая ляжыць пад паверхняй гэтай, здавалася б, пацешнай тэхналогіі.
Безумоўна, будзе складана адрозніць падробленыя відэа ад сапраўдных тэхналогія глыбокага падключэння працягвае прасоўвацца. У прыватнасці, для вядомых асоб і знакамітасцяў гэта можа мець сур'ёзныя наступствы. Deepfakes, якія наўмысна злосныя, могуць цалкам пашкодзіць кар'еры і жыццю.
Яны могуць быць выкарыстаны кімсьці са злымі намерамі, каб выдаць за іншых і скарыстацца сваімі сябрамі, сваякамі і калегамі. Яны таксама здольныя распаліць сусветныя спрэчкі і нават войны, выкарыстоўваючы фальшывыя фільмы замежных лідэраў.
заключэнне
Такім чынам, мы знаходзімся ў дзіўным перыядзе і незвычайнай абстаноўцы. Як ніколі проста вырабляць ілжывыя навіны і фільмы і распаўсюджваць іх. Разуменне таго, што праўда, а што не, становіцца ўсё больш складаным.
Сёння, здаецца, мы ўжо не можам спадзявацца на ўласныя пачуцці.
Нягледзячы на тое, што былі распрацаваны ілжывыя дэтэктары відэа, гэта толькі пытанне часу, калі інфармацыйны прабел стане настолькі вузкім, што нават найлепшыя ілжывыя дэтэктары не змогуць вызначыць, сапраўднае відэа ці не.





Пакінуць каментар