جدول المحتويات[يخفي][يعرض]
حسّن الذكاء الاصطناعي الجديد والمحسّن من القدرات والفهم والقدرة على إنتاج صور عالية الدقة. ربما تكون قد صادفت مؤخرًا بعض الصور الغريبة والمسلية التي تطفو على الإنترنت.
يرتدي كلب من نوع شيبا إينو قبعة وياقة مدورة سوداء. وثعالب البحر على طريقة الرسام الهولندي فيرمير "الفتاة ذات القرط اللؤلؤي". وهناك فنجان من الحساء يشبه الوحش الصوفي.
هذه الصور لم يخلقها فنان بشري.
بدلاً من ذلك ، قام نظام DALL-E 2 ، وهو نظام ذكاء اصطناعي جديد يمكنه تحويل الأوصاف النصية إلى صور ، بإنشائها.
ما عليك سوى كتابة ما تريد رؤيته ، وسيقوم الذكاء الاصطناعي بإنشائه لك - بتفاصيل زاهية وجودة رائعة ، وفي بعض الحالات ، ابتكار حقيقي. في هذا المنشور ، سنلقي نظرة عميقة على أحدث دراسة لـ OpenAI ، DALL.E 2 ، بالإضافة إلى كيفية عملها ، وأكثر من ذلك بكثير. هيا بنا نبدأ.
ما هو بالضبط دال.إي 2?
DALL-E 2 هو "نموذج توليدي" ، وهو نوع من خوارزمية التعلم الآلي التي تولد مخرجات معقدة بدلاً من أداء مهام التنبؤ أو التصنيف على بيانات الإدخال.
أنت تزود DALL-E 2 بوصف مكتوب ، ويقوم بإنشاء صورة تتوافق معه. من خلال الجمع بين المفاهيم والصفات والأنماط ، يمكن لـ OpenAI's DALLE 2 إنتاج رسومات وفنون مبتكرة وواقعية من وصف لغوي أساسي.
يُقال إن أحدث إصدار ، DALLE 2 ، أكثر تنوعًا ، وقادرًا على إنشاء صور من التسميات التوضيحية بدقة أعلى وفي نطاق أوسع من الأنماط الإبداعية. على سبيل المثال ، تم إنشاء الصور أدناه (من منشور مدونة DALL-E 2) من خلال الوصف "رائد فضاء يركب حصانًا."
يستنتج أحد الوصف ، "مثل رسم قلم رصاص" ، بينما يستنتج الآخر ، "بطريقة واقعية."

يمكنه أيضًا تغيير الصور الموجودة بدقة مذهلة. لذلك ، يمكنك إضافة عناصر أو حذفها مع الاحتفاظ بالألوان والانعكاسات والظلال ، مع الحفاظ على مظهر الصورة الأصلية.
كيف تعمل؟
يستخدم DALL-E 2 نماذج CLIP ونشر ، وهما نموذجان متطوران التعلم العميق الأساليب التي تم تطويرها في السنوات الأخيرة. ومع ذلك ، فهو يقوم على نفس الفكرة مثل كل الأعمق الأخرى الشبكات العصبية: التعلم التمثيل. يقوم CLIP بتدريب اثنين في وقت واحد الشبكات العصبية على الصور والتعليقات التوضيحية.
تتعلم إحدى الشبكات التمثيلات المرئية في الصورة ، بينما تتعلم الأخرى تمثيلات النص. أثناء التدريب ، تحاول الشبكتان تعديل معلماتهما بحيث تؤدي الصور والأوصاف القابلة للمقارنة إلى عمليات تطريز متشابهة.
"الانتشار" ، وهو نوع من النماذج التوليدية التي تتعلم كيفية صنع الصور عن طريق إصدار ضوضاء تدريجيًا وتقليل التشويش على عينات التدريب ، هو نهج التعلم الآلي الآخر المستخدم في DALL-E 2. نماذج الانتشار تشبه أجهزة التشفير التلقائي من حيث أنها تحول بيانات الإدخال إلى تضمين التمثيل ثم استخدام معلومات التضمين لإعادة إنشاء البيانات الأصلية.
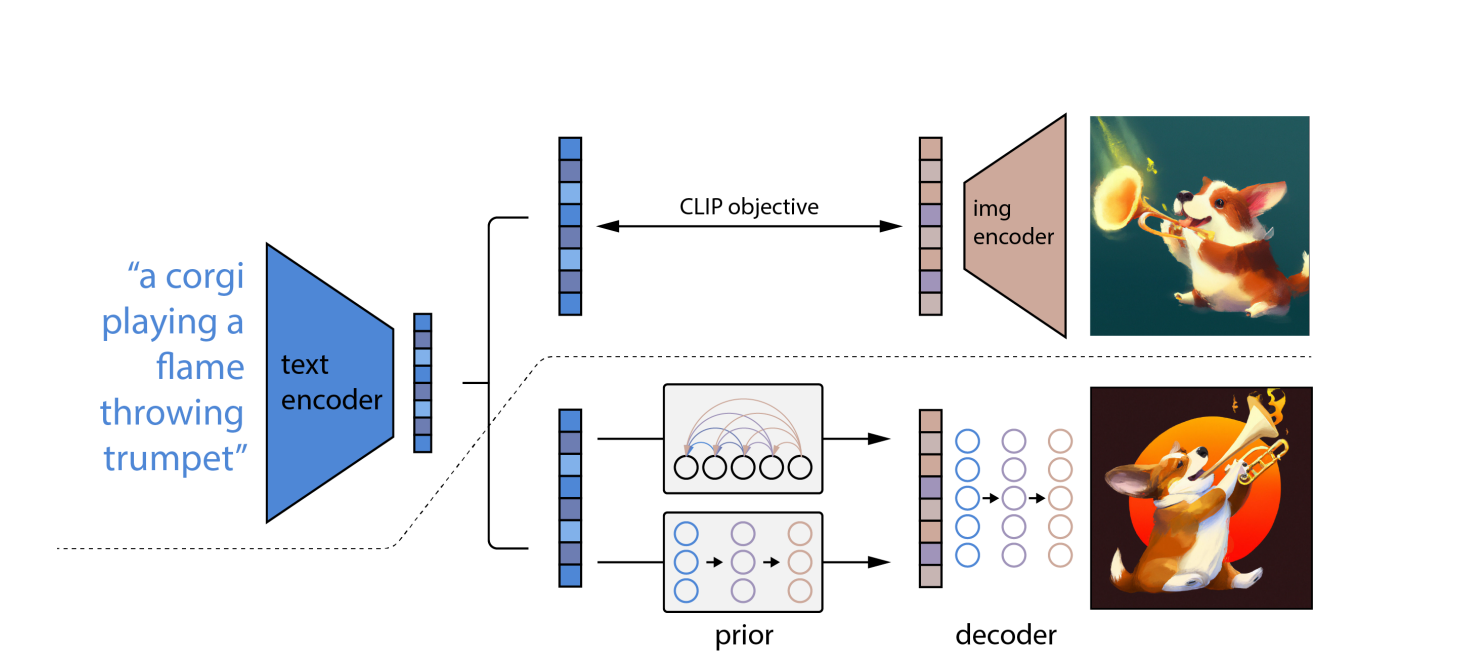
باستخدام OpenAI's نموذج اللغة CLIP ، الذي يمكنه ربط الأوصاف النصية بالصور الفوتوغرافية ، يقوم أولاً بترجمة الموجه المكتوب إلى شكل وسيط يتضمن الخصائص الأساسية التي يجب أن تتطابق معها الصورة (وفقًا لـ CLIP).
ثانيًا ، ينشئ DALL-E 2 ملفًا متوافقًا مع CLIP الصورة باستخدام نموذج الانتشار، وهي شبكة عصبية.
في الصور المشوهة ذات البكسلات العشوائية ، يتم التعرف على نماذج الانتشار. يتعلمون كيفية استعادة الشكل الأصلي للصور. يمكن أن تنتج نماذج الانتشار صورًا تركيبية عالية الجودة ، خاصة عند استخدامها جنبًا إلى جنب مع نهج إرشادي يعطي الأولوية للدقة على التنوع.
نتيجة لذلك ، فإن نموذج الانتشار يأخذ وحدات البكسل العشوائية ويستخدم CLIP لتحويلها إلى صورة جديدة تتطابق مع موجه الكلمات. بسبب مفهوم الانتشار ، يمكن لـ DALL-E 2 إنتاج صور عالية الدقة أسرع من DALL-E.
حالة استخدام DALL.E 2
في العشرين سنة الماضية ، رؤية الكمبيوتر تقدمت التكنولوجيا من مجرد فكرة بسيطة إلى اختراق كبير. على الرغم من هذه التطورات ، لا تزال نماذج التعرف على الصور والأشياء تواجه عقبات كبيرة في الحياة اليومية. يعد عدم وجود مجموعات البيانات أحد أهم عيوب التعرف على الصور ورؤية الكمبيوتر. نظرًا لوجود نقص في البيانات على كلا الطرفين ، فإن تدريب نماذج التعرف على الصور لإعطاء نتائج دقيقة بنسبة 100 بالمائة يكاد يكون صعبًا.
لحسن الحظ ، يمكن لنموذج التعلم الآلي الجديد لـ OpenAI سد الفجوة في التكنولوجيا. DALLE 2 قادر على إنتاج صور مذهلة بناءً على أوصاف النص. يمكن أن يوفر إنتاج الصور المزيفة هذا بيانات لنماذج التعرف على الصور بناءً على متطلباتها. يعد غياب البيانات حجر عثرة كبير في تحديد هوية الكائن والصورة.
في العصر الرقمي ، توجد مجموعات البيانات في كل مكان ، ومع ذلك ما زلنا نبحث عن اختصارات لتغذية نموذج الذكاء الاصطناعي ، حتى يتمكن من تقديم نتائج جيدة. ومع ذلك ، ليس من السهل تدريب نموذج التعرف على الصور. يستلزم عددًا كبيرًا من مجموعات البيانات مع القليل من الاختلافات ، والتي ربما لم نتمكن من استردادها ببساطة.
إذن ، ما هي الإجابة: الإجابة هي DALLE 2. يمكن لمولد الصور OpenAI ، بقدرته على إنتاج الصور من النصوص وتغيير الصور الموجودة ، أن يساعد في سد الفجوة. سيساعد هذا في توليد بيانات تدريب إضافية مع تقليل كمية الملصقات البشرية المطلوبة. على الرغم من الفائدة الكبيرة ، يجب أن تكون على دراية بإنتاج الصور الاحتيالية والصور التي تستبعد التضمين. قد يؤدي هذا إلى طرق الكشف عن الصور التي تنتج نتائج متحيزة.
القيود
وفقًا لـ OpenAI ، قد يكون لـ DALL.E 2 تأثير ضار إذا وقع في الأيدي الخطأ. في عالم اليوم المزيف العميق ، يمكن استخدام النموذج بسهولة لنشر معلومات خاطئة أو صور عنصرية ، ولهذا السبب لا تسمح OpenAI للمطورين باستخدام DALL.2 إلا عن طريق الدعوة. يجب أن يتوافق النموذج مع قيود صارمة على المحتوى لجميع الاقتراحات التي تتلقاها.
لاستبعاد إمكانية إنشاء DALL.E 2 لأي صور معادية أو عنيفة ، تم إنشاء مجموعة البيانات بدون أي أسلحة فتاكة. بينما صرحت شركة OpenAI بأنها تخطط لتحويلها إلى واجهة برمجة تطبيقات في المستقبل ، في حالة DALL.E 2 ، فإنها على استعداد للمضي قدمًا بحذر.
وفي الختام
DALL-E 2 هو اكتشاف بحثي آخر مثير للاهتمام من OpenAI يفتح الباب أمام تطبيقات جديدة.
أحد الأمثلة على ذلك هو إنشاء مجموعات بيانات ضخمة لمواجهة أحد الاختناقات الرئيسية للرؤية الحاسوبية - البيانات. في حين أن الحالة الاقتصادية للعديد من التطبيقات المستندة إلى DALL-E سيتم تحديدها من خلال السعر والسياسات التي تضعها OpenAI لمستخدمي واجهة برمجة التطبيقات الخاصة بها ، فإنها ستعمل بلا شك على تطوير إنتاج الصور.





اترك تعليق