互聯網自誕生之日起就發生了翻天覆地的變化。 它已成為人際關係的基本組成部分,並繼續從 Internet 中繼聊天 (IRC) 發展到現代社交媒體。 它正在演變為未來全球社區的城鎮廣場。
您很可能聽說過“Web 3.0”這個詞在互聯網上流傳。 您可能已經看到解釋 Web 3.0 如何運作及其令人難以置信的發展的信息圖。 至少,您應該看過一部描述 Web 3.0 將如何永久改變世界面貌的短片。
如果您還沒有完成上述任何操作並且不知道 Web 3.0 是什麼,那麼這裡就是為您準備的文章。 在我們繼續了解我們的未來之前,讓我們先回顧一下互聯網的早期。
網絡的演變
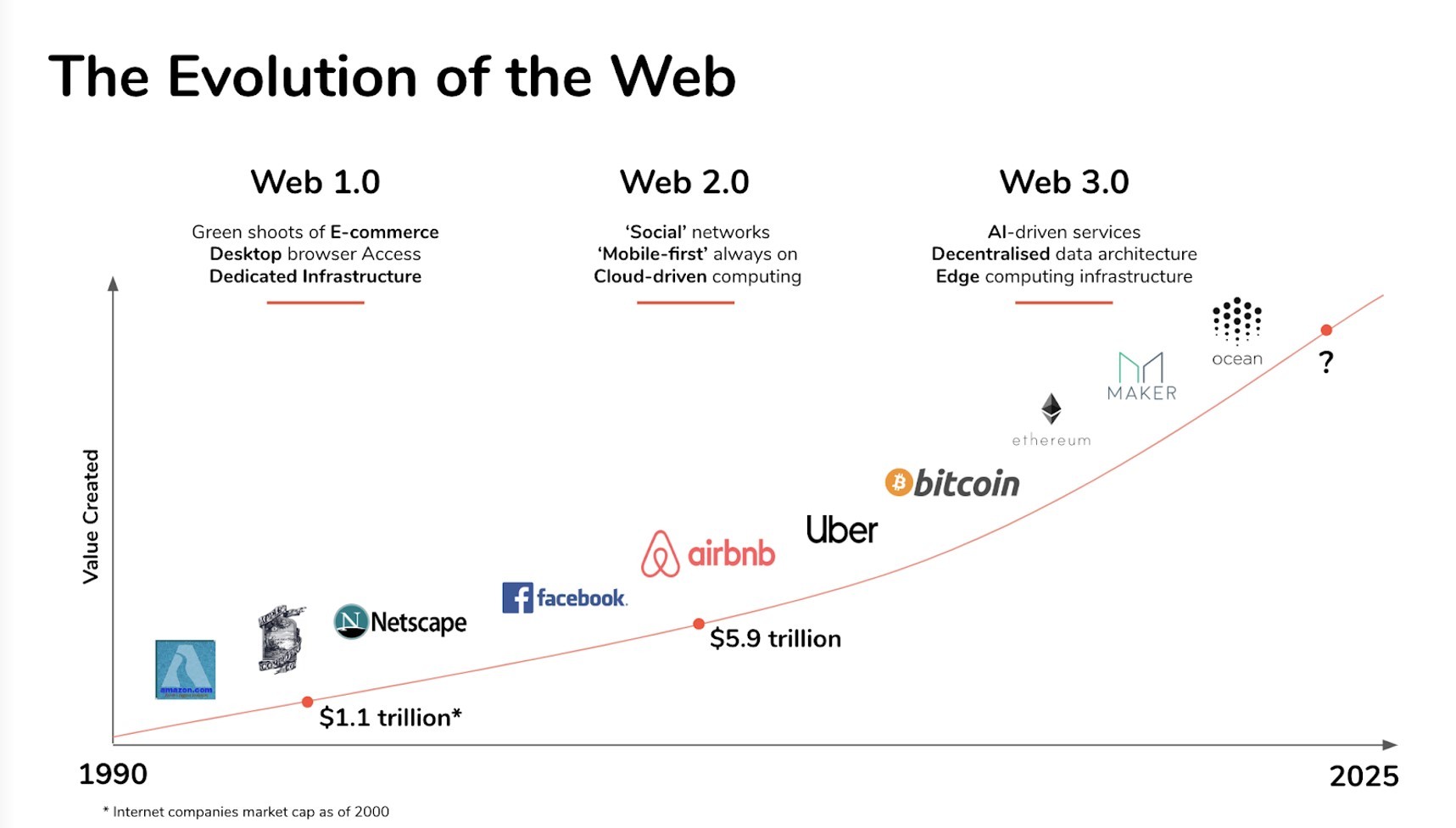
多年來,Web 已顯著增長,其今天的應用程序從最初開始就幾乎無法辨認。 Web 的發展有時分為三個階段:Web 1.0、Web 2.0 和 Web 3.0。
網站1.0
如果沒有 Google、Facebook 或 Instagram Stories,今天的年輕人是不可能想像互聯網的。 然而,從 1990 年代中期到 2000 年代初期,存在一個互聯網的古典時代。 Web 1.0 是互聯網的最初化身。 大多數參與者是內容消費者,而創作者主要是開發人員,他們構建的網站主要以文本或圖片格式提供材料。
Web 1.0 站點提供靜態材料,而不是動態 HTML。 數據和內容是通過靜態文件系統而不是數據庫提供的,網頁缺乏交互性。 視頻流的概念並不存在。 人們會湧入 AOL 聊天室“在線發言”。
下載一首歌曲需要一整天。 通過撥號連接到 Internet 時,您必須移除固定電話。 不,手機不存在。 您必須親自與個人交流,而不使用表情符號。 太可怕了,我告訴你!
網站2.0
互聯網在 2000 年代初期處於其歷史的轉折點。 它可能只是一個單向的、乏味的圖書館,也可能成為一種驚人的創新,將來自世界各地的人們聯繫起來。 幸運的是,它選擇了第二個選項。 您無需成為開發人員即可參與 Web2 世界中的創作過程。 許多應用程序的設計方式使得任何人都可以簡單地成為製造者。
隨著發展 社會化媒體,用戶終於可以在“網絡”上享受身臨其境的體驗。 您現在可以在 YouTube 上發布和廣播視頻內容,Google 成為了任何事情的首選網站。 Web2 非常簡單,正因為如此,全世界越來越多的人正在成為創造者。
Web2 是關於參與而不是觀察。 到 2000 年代中期,大多數網站已經過渡到 Web2(Web 2.0)。 在線遊戲實現了世界各地玩家之間的多人互動。 您可以在 Facebook 上跟踪您的愛人,並在 Instagram 上分享您寵物的有趣照片,但只能通過您的智能手機。
那麼,什麼是 Web 3.0?
Web 3.0 是互聯網發展的下一階段,它將網絡的控制板重新交到消費者手中。 這種區別是由區塊鍊等新興技術創造的,它使互聯網能夠作為點對點 (P2P) 的無信任系統運行。
web2 和 web3 之間有一些本質區別,但去中心化是兩者的核心。 Web3 應用程序或 Dapps 建立在分散的點對點網絡上,例如 乙太坊 和 IPFS. 這些網絡由其用戶而非公司構建、運行和維護。 它們是自組織的,沒有單點故障。
這是網絡發展的第三個階段,通常被稱為讀寫執行階段,它關係到網絡的未來。 人工智能 (AI) 和 機器學習 (ML) 允許計算機以與人類相同的方式理解數據。 Web 3.0 的目標是開放和分散互聯網。
用戶目前必須依靠網絡和蜂窩運營商來跟踪通過其係統的數據。 隨著分佈式賬本技術的出現,用戶將能夠在不久的將來收回對其數據的控制權。 大數據公司和跨國公司不應再共享個人信息或壟斷權力和信息。
為什麼我們需要 Web 3.0?
當我們通過互聯網進行交流時,我們的數據副本會被創建並保存在 Google 或 Facebook 等公司的服務器上,因此我們會失去對數據的控制權。 我們的信息由第三方持有這一事實本質上並不是一件壞事; 然而,當一家公司調解整個過程時,事情可能會出錯。
我們是否需要一個您提供的信息可能因貪婪或惡意而被濫用的社會? 這遠遠超出了隱私。 我們問題的根源是控制之一。 我們定期將 PB 級數據的所有權轉讓給公司和個人,沒有明顯的選擇。
- 安全與隱私 — 利用尖端加密技術構建更好的網絡將確保互聯網用戶可以將個人信息保密,遠離公司或黑客的窺探。
- 分散存儲管理 – 大文件可以分成更小的部分,可以單獨加密並保存在多個地方。 IPFS 網絡和類似協議的結構方式是,破壞它們需要同時入侵世界各地的多台機器,每台機器都有自己的保護。
- 身份和聲譽 — 如果您擔心我們將如何處理在線信任和聲譽,您並不孤單。 實際上,我們已經擁有由社交媒體和其他網站上發布的數據組成的在線數字身份。 主要問題是我們不擁有或管理這些數據,這些數據正在隨著新網絡的變化而變化。
優點
以下是 Web 3.0 的開創性品質的集合,可幫助您了解它將如何運作以及您將如何從中受益!

1。 人工智能
人工智能 (AI) 並不是 Web 3.0 上出現的新概念。 我們已經在 Web 2.0 應用程序中註意到了它。 然而,到了 Web 3.0,人工智能將擁有如此快速的學習機制,以至於很難否認它的存在。 人工智能將迅速區分好數據和差數據、真實的個人和機器人,以及最關鍵的是,區分假新聞和真實報導。
2. 3D 虛擬身份
Web 3.0 將帶來新的通信和虛擬連接途徑。 仍然可以進行聊天、電子郵件和視頻通話。 但是,用戶可以訪問在網絡上代表他們的 3D 身份。 這些虛擬化身,類似於在線遊戲角色,將成為我們在公司交易、工作夥伴關係和約會應用程序中的代表。
3. 不間斷服務
數據將存儲在 Web 3.0 中的多個分散節點上。 這種方法確保始終有足夠的備份節點來供應鏈並防止服務器停止或失敗。 簡單地說,互聯網永遠不會因為災難性的服務器故障而無法使用。
4。 數據所有權
當 Web 3.0 成為現實時,亞馬遜、Facebook 和谷歌等大公司將不再需要工廠大小的服務器來保存客戶的數據。 相反,互聯網用戶將完全控制他們的數據,包括財務信息、登錄信息等。
5.語義元數據
語義元數據是描述數據“意義”的數據。 在任何存在數據的環境中,都有一些價值觀反映了某些想法。 語義元數據將成為 Web 3.0 的關鍵組成部分。 這種方法將允許網絡理解符號、關鍵字和消息的含義。 例如,該網絡將檢測經典的“笑臉”表情符號,該表情符號由兩個點和一個弧線組成。 儘管如此,它仍會認識到它代表了人類的笑容,一種喜悅和接受的姿態。
面臨的挑戰
與任何新技術一樣,Web 3.0 在其當前狀態下很難部署,至少一開始是這樣。 Web 3.0 的問題和缺點包括:
1. 獲取緩慢
最後,Web 3.0 不會對每個人來說都是一擊即中的奇蹟。 經驗豐富的互聯網用戶可能會記得,Web 1.0 花了將近十年的時間才獲得全球關注。 當 Web 2.0 到來時,它帶來了智能技術和社交媒體,但人們仍在弄清楚聊天室和電子郵件是如何運作的。 許多企業將花時間從集中式網絡過渡到去信任鏈。
許多小工具將變得過時,但它們的用戶將無法立即過渡到 Web 3.0。 因此,在可預見的未來,Web 2.0 和 Web 3.0 將共存。
2. 人類的不當行為
Web 3.0 似乎是技術進步中改變遊戲規則的一步。 它的發布很可能代表我們與互聯網互動的“之前和之後”點。 但是,我們不能忘記,那些有不良動機的人將繼續存在。
惡意用戶可能會故意在網絡上充斥虛假或誤導性材料,從而為在線犯罪創造理想環境。 為了減少黑客攻擊、密碼學和 人工智能 學習方法需要快速改進和更新。
結論
互聯網經歷了漫長的演進,未來肯定會繼續演進。 由於無法訪問的數據的大規模擴展,網站和應用程序可能會轉向為全世界越來越多的人提供更好體驗的網絡。 雖然目前還沒有對 Web3(Web 3.0)的明確定義,但它已經受到其他領域技術突破的推動。
隨著我們朝著更加去中心化的互聯網邁進, 增強現實技術 (AR) 和人工智能 (AI) 在定義我們的用例場景中發揮著重要作用,我們可能會預見到全球互聯網革命的新浪潮。
Web 3.0 為開發人員的創造力提供了急需的靈活性。 另一方面,用戶可能會期待改進 數字體驗 以及整體上更加升級和完善的互聯網。 如果做得正確,Web 3.0 有可能節省時間,並以低成本提高生產力。 我們可能期待更智能的互聯網,因為不管你信不信,它會一直存在。





發表評論