製作最高水準的創意人像電影是計算機視覺和圖形學中一項至關重要且理想的任務。
儘管已經提出了幾種基於有效 StyleGAN 的人像圖像卡通化的有效模型,但這些面向圖像的技術在與視頻一起使用時具有明顯的缺點,例如固定幀大小、面部對齊的要求、缺乏非面部細節, 和時間不一致。
革命性的 VToonify 框架用於解決難以控制的高分辨率肖像視頻風格傳輸。
我們將在本文中研究 VToonify 的最新研究,包括其功能、缺點和其他因素。
什麼是 Vtoonify?
VToonify 框架允許可定制的高分辨率肖像視頻風格傳輸。
VToonify 使用 StyleGAN 的中高分辨率層,根據編碼器檢索到的多尺度內容特徵來創建高質量的藝術肖像,以保留幀細節。
由此產生的全卷積架構將可變大小電影中未對齊的人臉作為輸入,從而在輸出中產生具有真實運動的全臉區域。

該框架與當前基於 StyleGAN 的圖像卡通化模型兼容,允許它們擴展到視頻卡通化,並繼承了可調節顏色和強度定制等吸引人的特性。
這個 研究 介紹了兩個基於 Toonify 和 DualStyleGAN 的 VToonify 實例,分別用於基於集合和基於樣本的肖像視頻風格遷移。
廣泛的實驗結果表明,所提出的 VToonify 框架在製作具有可變風格參數的高質量、時間連貫的藝術肖像電影方面優於現有方法。
研究人員提供 谷歌 Colab 筆記本,所以你可以弄髒它。
它如何運作?
為了實現可調節的高分辨率人像視頻風格轉換,VToonify 將圖像翻譯框架的優點與基於 StyleGAN 的框架相結合。
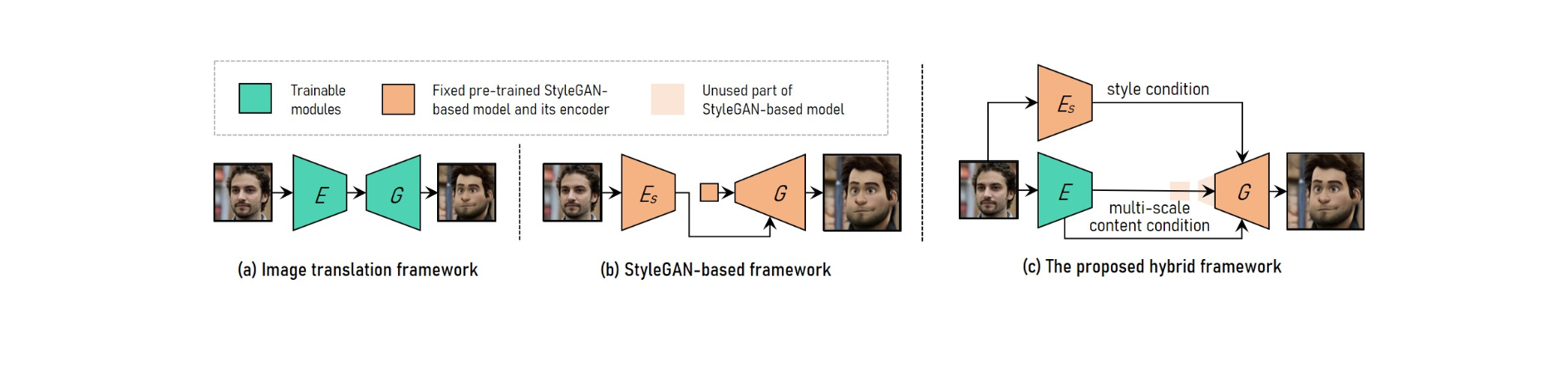
為了適應不同的輸入大小,圖像翻譯系統採用完全卷積網絡。 另一方面,從頭開始訓練使得高分辨率和受控的風格傳輸變得不可能。
預訓練的 StyleGAN 模型用於基於 StyleGAN 的高分辨率和受控風格遷移的框架中,儘管它僅限於固定的圖片尺寸和細節損失。
StyleGAN 在混合框架中進行了修改,刪除了其固定大小的輸入特徵和低分辨率層,從而產生了類似於圖像翻譯框架的全卷積編碼器-生成器架構。
為了保持幀細節,訓練編碼器以提取輸入幀的多尺度內容特徵,作為對生成器的附加內容要求。 Vtoonify 繼承了 StyleGAN 模型的樣式控制靈活性,將其放入生成器以提取其數據和模型。
StyleGAN 和提議的 Vtoonify 的局限性
藝術肖像在我們的日常生活以及藝術等創意行業中很常見, 社會化媒體 頭像、電影、娛樂廣告等等。
隨著發展 深入學習 技術,現在可以使用自動肖像風格轉換從真實的面部照片創建高質量的藝術肖像。
為基於圖像的風格轉移創建了多種成功的方法,其中許多方法很容易以移動應用程序的形式被初級用戶訪問。 在過去的幾年裡,視頻材料迅速成為我們社交媒體源的支柱。
社交媒體和短片的興起增加了對創新視頻編輯的需求,例如肖像視頻風格轉換,以生成成功且有趣的視頻。
現有的面向圖像的技術在應用於電影時具有明顯的缺點,限制了它們在自動肖像視頻風格化中的有用性。
StyleGAN 是開發肖像圖片風格轉移模型的常用主幹,因為它能夠創建具有可調節風格管理的高質量人臉。
基於 StyleGAN 的系統(也稱為圖片卡通化)將真實面孔編碼到 StyleGAN 潛在空間中,然後將生成的樣式代碼應用於另一個在藝術肖像數據集上微調的 StyleGAN,以創建風格化版本。
StyleGAN 創建具有對齊面孔和固定大小的圖片,這不利於現實世界鏡頭中的動態面孔。 視頻中的面部裁剪和對齊有時會導致部分面部和尷尬的手勢。 研究人員將此問題稱為 StyleGAN 的“固定作物限制”。
對於未對齊的人臉,已經提出了StyleGAN3; 但是,它只支持設置的圖片尺寸。
此外,最近的一項研究發現,編碼未對齊的人臉比對齊的人臉更具挑戰性。 不正確的人臉編碼不利於人像風格的遷移,從而導致身份改變和重構和風格化幀中的組件丟失等問題。
如前所述,肖像視頻風格轉換的有效技術必須處理以下問題:
- 為了保持逼真的運動,該方法必須能夠處理未對齊的面部和不同的視頻大小。 較大的視頻尺寸或寬視角可以捕捉更多信息,同時防止面部移出畫面。
- 為了與當今常用的高清設備競爭,高分辨率視頻是必要的。
- 在開發逼真的用戶交互系統時,應該為用戶提供靈活的樣式控制來改變和選擇他們的選擇。
為此,研究人員建議使用 VToonify,這是一種用於視頻卡通化的新型混合框架。 為了克服固定裁剪約束,研究人員首先研究 StyleGAN 中的翻譯等方差。
VToonify 結合了基於 StyleGAN 的架構和圖像翻譯框架的優點,實現了可調節的高分辨率人像視頻風格轉換。
以下是主要貢獻:
- 研究人員研究了 StyleGAN 的固定裁剪約束,並提出了一種基於平移等效性的解決方案。
- 研究人員提出了一個獨特的全卷積 VToonify 框架,用於受控的高分辨率肖像視頻風格傳輸,支持未對齊的面部和不同的視頻大小。
- 研究人員在 Toonify 和 DualStyleGAN 的主幹上構建了 VToonify,並在數據和模型方面對主幹進行了濃縮,以實現基於集合和基於樣本的肖像視頻風格遷移。
將 Vtoonify 與其他最先進的模型進行比較
美化
它是使用 StyleGAN 在對齊面上進行基於集合的樣式遷移的基礎。 要檢索樣式代碼,研究人員必須對齊人臉並為 PSP 裁剪 256256 張照片。 Toonify 用於生成具有 1024*1024 樣式代碼的風格化結果。
最後,他們將視頻中的結果重新對齊到其原始位置。 未風格化的區域已設置為黑色。

雙風格GAN
它是基於 StyleGAN 的基於樣本的風格遷移的骨幹。 他們使用與 Toonify 相同的數據預處理和後處理技術。
像素2像素高清
它是一種圖像到圖像的轉換模型,通常用於壓縮預訓練模型以進行高分辨率編輯。 它使用配對數據進行訓練。
研究人員利用 pix2pixHD 作為其額外的實例圖輸入,因為它使用提取的解析圖。
一階運動
FOM 是一種典型的圖像動畫模型。 它在 256256 張圖片上進行了訓練,在其他尺寸的圖片上表現不佳。 因此,研究人員首先將視頻幀縮放到 256*256 以將 FOM 轉換為動畫,然後將結果調整為原始大小。
為了公平比較,FOM 採用其方法的第一個風格化框架作為其參考風格圖像。
大干
這是一個3D人臉動畫模型。 他們使用與 FOM 相同的數據準備和後處理方法。

優點
- 它可以用於藝術、社交媒體化身、電影、娛樂廣告等。
- Vtoonify 也可以在元節中使用。
限制
- 該方法從基於 StyleGAN 的主幹中提取數據和模型,從而導致數據和模型偏差。
- 偽影主要是由程式化的面部區域與其他部分之間的大小差異引起的。
- 這種策略在處理面部區域的事情時不太成功。
結論
最後,VToonify 是一個風格控制的高分辨率視頻卡通化框架。
該框架在處理視頻方面取得了出色的表現,並通過在兩個方面對基於 StyleGAN 的圖像卡通化模型進行了濃縮,從而可以對結構風格、顏色風格和風格程度進行廣泛的控制。 綜合數據 和網絡結構。





發表評論