在當今數據驅動的社會中,網絡抓取已成為從互聯網平台獲取有見地數據的重要方法。
作為一個極受歡迎的社交媒體網站,Instagram 提供了大量用戶生成的素材。 而且,這些生成的數據可用於營銷、研究和其他原因。
得益於 Bright Data 功能豐富的 Instagram 抓取工具,用戶可以輕鬆有效地從 Instagram 提取數據 網頁抓取 工具。 在這篇文章中,我們將對 Instagram 抓取過程進行全面、逐步的演練。
那麼,讓我們看看如何從 Instagram 抓取數據的步驟。
從 Bright Data 了解 Instagram 爬蟲
在兩個通用網絡抓取工具和一個預編譯數據集的幫助下,Bright Data 提供了各種 Instagram 抓取服務。 這些技術提供了數據提取的多功能性並適應各種需求。
讓我們更詳細地檢查這些選擇中的每一個:
a. 抓取瀏覽器
被稱為 Scraping Browser 的創新技術是為了滿足數據抓取項目的需求而創建的。 它提供了在單個瀏覽器內大規模抓取所需的一切。 由於其集成的網站解鎖自動化,它脫穎而出,這使其成為全球同類瀏覽器中唯一的。
Scraping Browser 使用戶能夠訪問超越自動化和無頭瀏覽器的強大功能,使他們能夠超越最困難的腳本和網站機器人檢測障礙。
數據抓取更有效、更省心,因為它具有自動調整功能,可以輕鬆管理新鮮塊、驗證碼解決方案、指紋和重試,並顯示為真實用戶。
使用 AI 戰勝機器人檢測系統
通過利用尖端的 AI 技術,Scraping Browser 可以智取機器人檢測系統並不斷調整以適應其不斷變化的策略。 為了更好地解鎖網頁,抓取瀏覽器從這些系統的嘗試中學習,以檢測和阻止抓取嘗試並適當地修改其行為。
通過模仿真實用戶使用的瀏覽器的行為,它優於傳統代理的效率。 因此,客戶可以專注於他們的數據抓取目標,而不必處理正在進行的機器人檢測程序的困難和費用。
b. Web 抓取工具 IDE
Web Scraper IDE 是為開發人員創建的強大的網絡抓取工具,可以處理複雜的抓取任務。 由於其完全託管的解決方案和預構建的抓取功能,它大大縮短了開發時間,同時提供了無限的可擴展性。 該應用程序通過提供來自流行網站的代碼模板和現成的 JavaScript 函數,可以快速和可擴展地構建在線抓取工具。
Web Scraper IDE 提供了成功進行網絡抓取所需的一切。 它是在線數據提取的完整解決方案,因為集成選項使客戶能夠計劃爬網或通過 API 啟動它們並與主存儲系統鏈接。
如何使用它? - 教程
首先,導航到網站上的用戶儀表板。

讓我們從抓取 Instagram 的步驟開始。
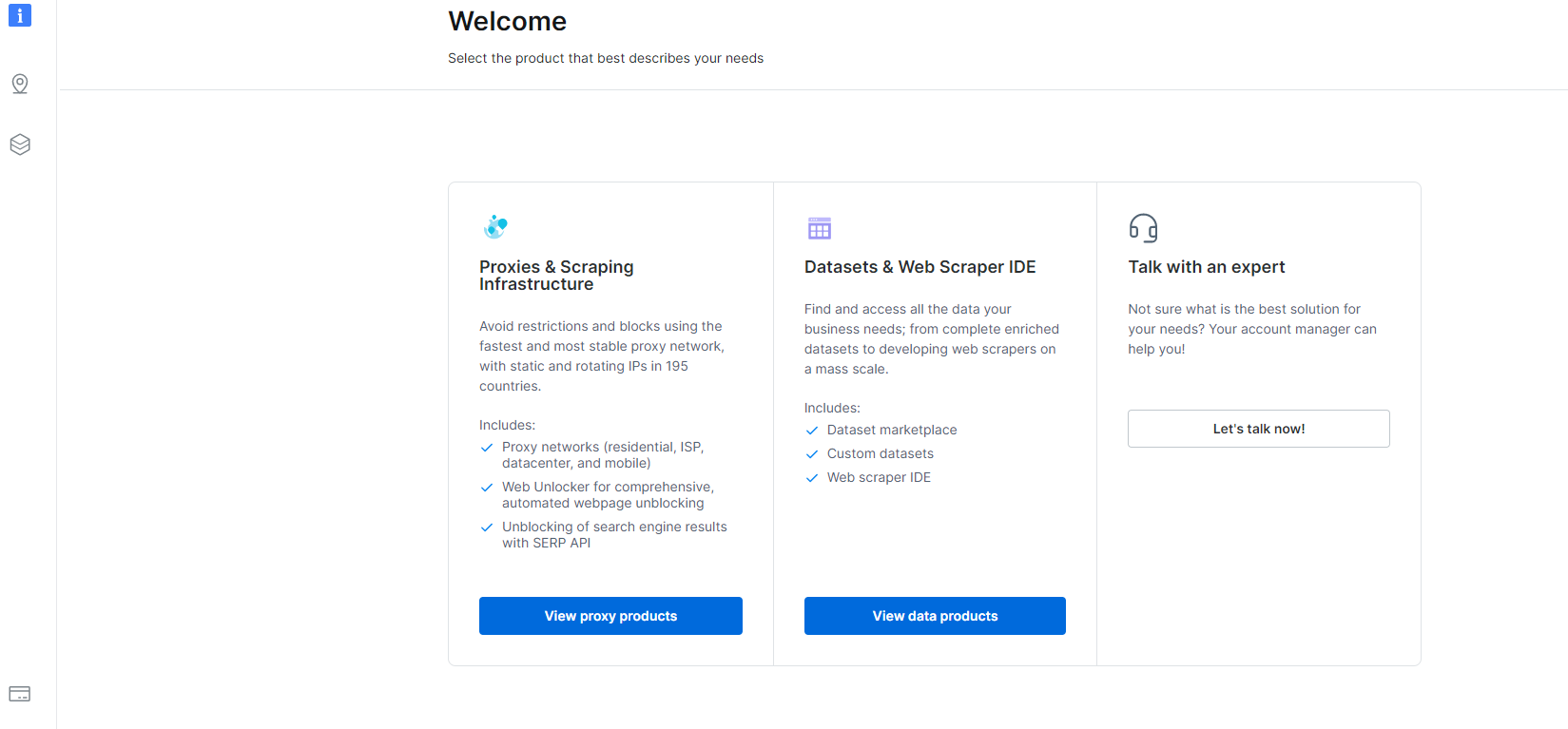
1- 導航到 我的帳戶 然後單擊數據集和 Web Scraper IDE 部分。
2- 到達那里後,單擊“我的刮板”。
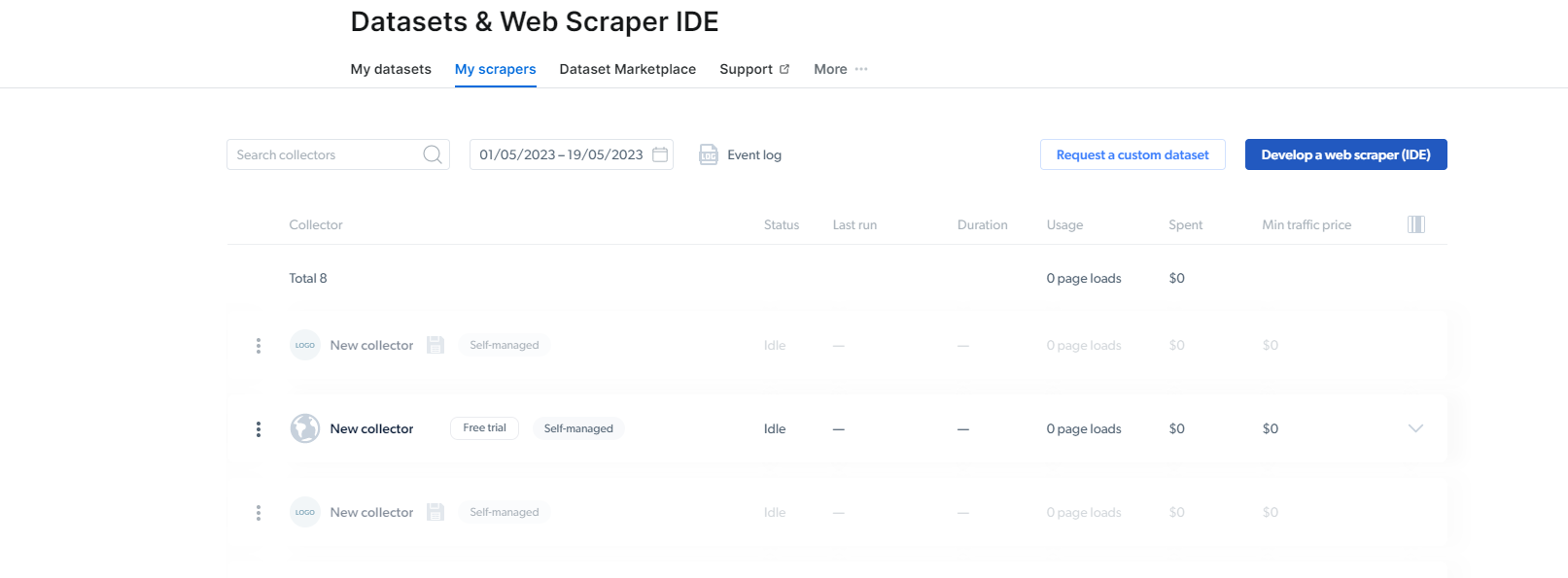
在這裡,您需要點擊“開發網絡抓取工具(IDE)”。 在這裡,我們將為 Instagram 創建我們的抓取工具。
3-現在,我們需要開發一個新的網絡抓取工具。 就此示例而言,我選擇抓取“NASA”帳戶。 這只是為了這個例子。
所以,我的代碼將如下所示:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
您需要單擊右上角的“播放”按鈕才能運行此代碼。
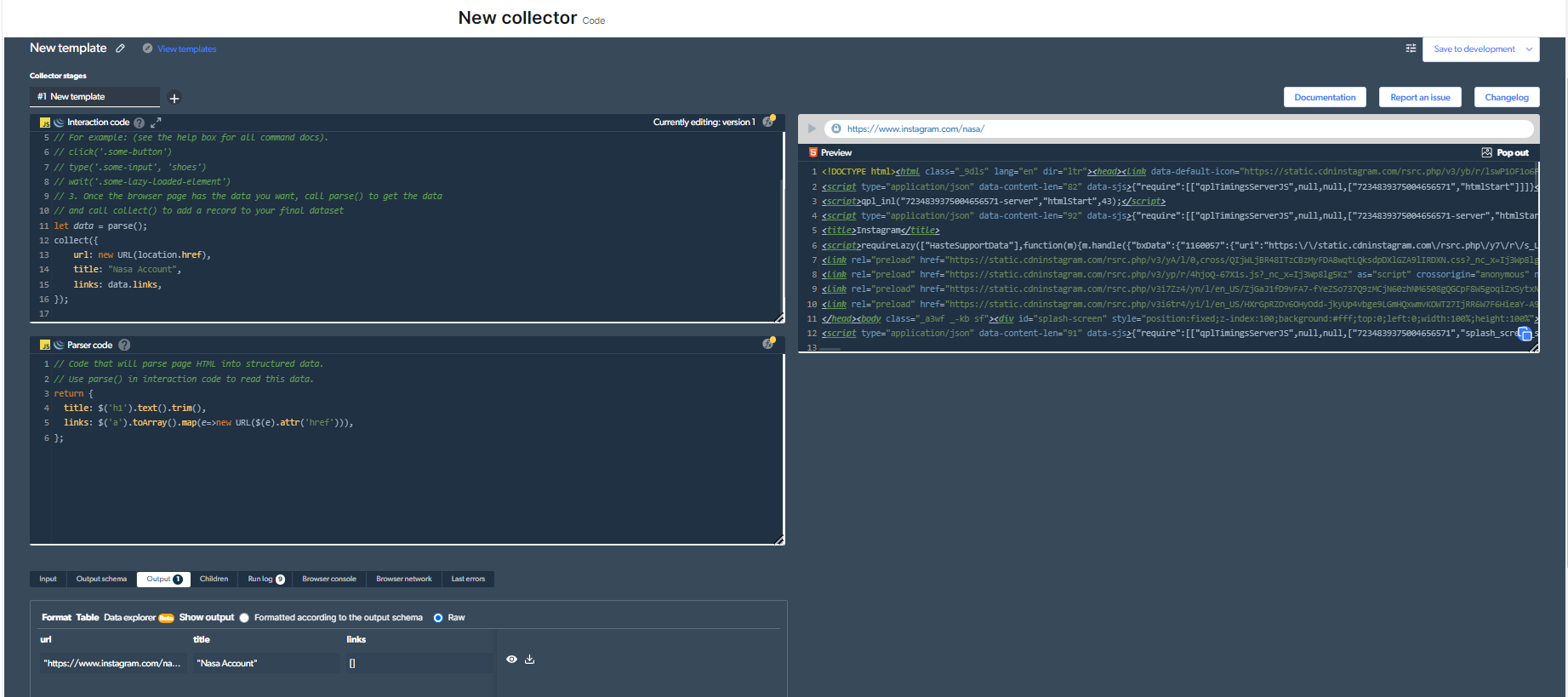
4- 現在,我們將有一個輸出。
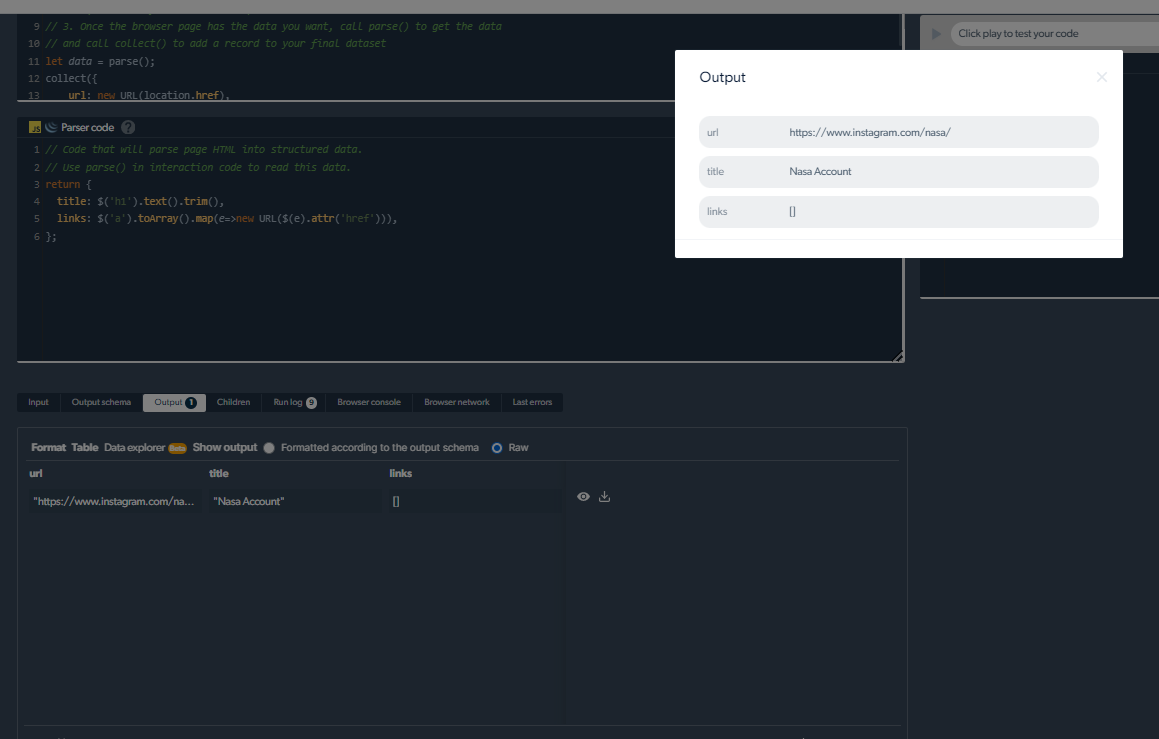
管理抓取問題
帶有“顯示更多按鈕”的 Instagram 帖子可能很難被抓取。 然而,來自 Bright Data 的 Instagram 抓取工具就是為成功處理這種複雜性而設計的。 這些爬蟲具有尖端的技能來遍歷分頁和加載額外的按鈕。
Bright Data 的 Instagram 抓取工具有效地解決了這些困難,以實現徹底的數據提取,使您能夠收集分析或研究所需的全部信息。
通過使用這些抓取工具,您可以解決 Instagram 帖子的動態特性帶來的挑戰。
c. 預先收集的數據集
Bright Data 明白並不是每個人都想運行他們的爬蟲。 他們為 Instagram 提供預先收集的數據集以吸引此類消費者。
該數據集提供了大量有用的信息,例如關注者、個人資料、帖子等。
Bright Data 提供了自定義選項來根據您的需要對數據集進行個性化設置,無論您需要整個數據集還是專業數據的子集。 這種方法避免了構建和管理爬蟲,為您提供隨時可用的數據以供分析和洞察。
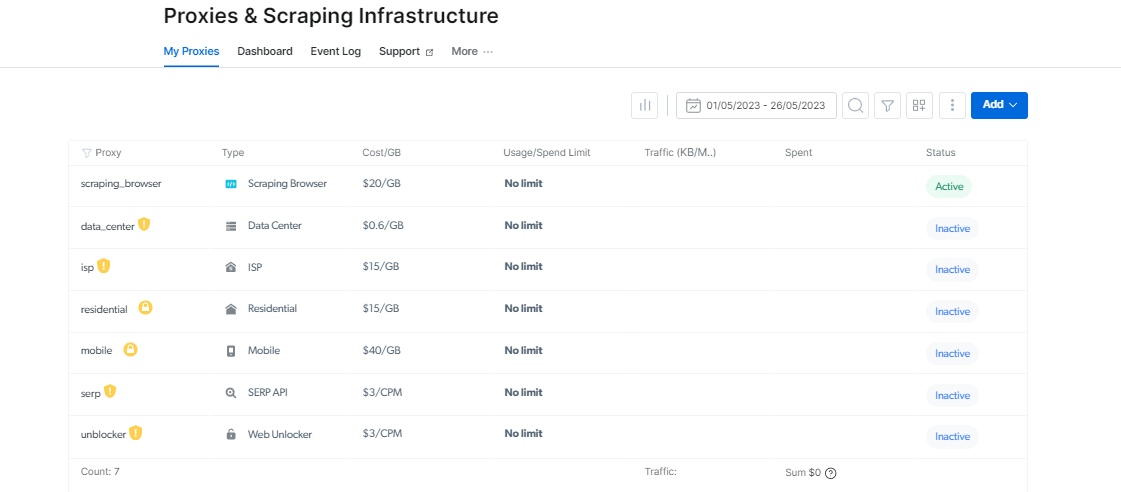
現在,讓我們檢查使這些工具如此有效的基礎架構:代理基礎架構和 Web Unlocker。
釋放代理的力量
運用 代理 在網絡抓取期間至關重要,以確保您的行為不被注意。
Bright Data 提供了廣泛的選擇 代理服務 是根據您的要求定制的。 你可以選擇 住宅代理,提供超過 72 萬個 IP,這些 IP 從 195 個國家/地區的真實對等設備輪換而來。
可選擇ISP Proxies,提供全球700,000+真實家庭IP供長期使用; 數據中心代理,擁有來自任何地理位置的 770,000 多個共享 IP; 和移動代理,它們構成了擁有 3 多個 IP 的最大的真實對等 4G/7,000,000G 移動網絡。
通過使用這些代理,可以在許多地方冒充授權用戶輕鬆收集數據。

Proxy Manager:讓代理管理更簡單
管理多個代理可能很困難,但代理管理器使它變得容易。
這個開源界面使您能夠從一個平台管理所有代理。 告別手動設置和切換代理。 Proxy Manager 簡化了程序並節省了您的時間和精力。
代理瀏覽器擴展:輕鬆更改您的位置
您需要從多個地區收集網絡數據嗎? 我們的代理瀏覽器擴展涵蓋了您。 您只需單擊一下即可更改瀏覽位置,以獲取特定區域的信息。
利用從多個區域收集數據的靈活性和簡單性,無需任何技術複雜性。
它是如何工作的? - 教程
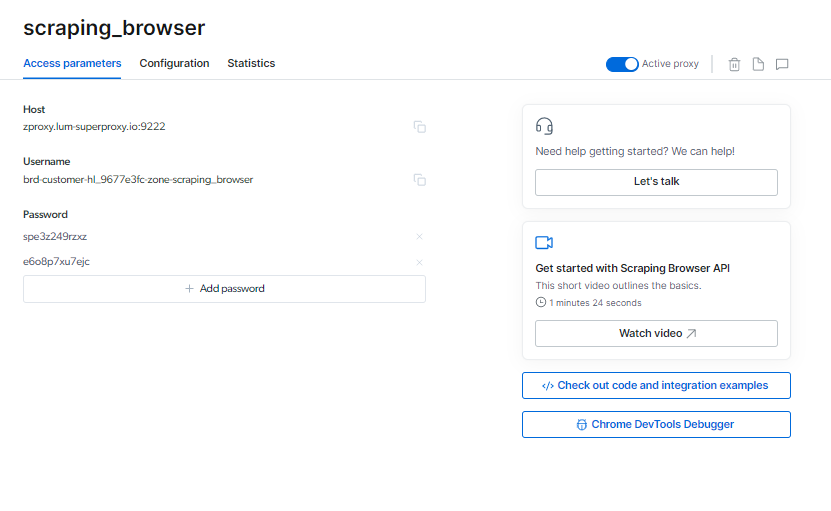
您可以找到您的 抓取瀏覽器 訪問參數頁面上的登錄信息,將在您啟動新的瀏覽器會話時使用。
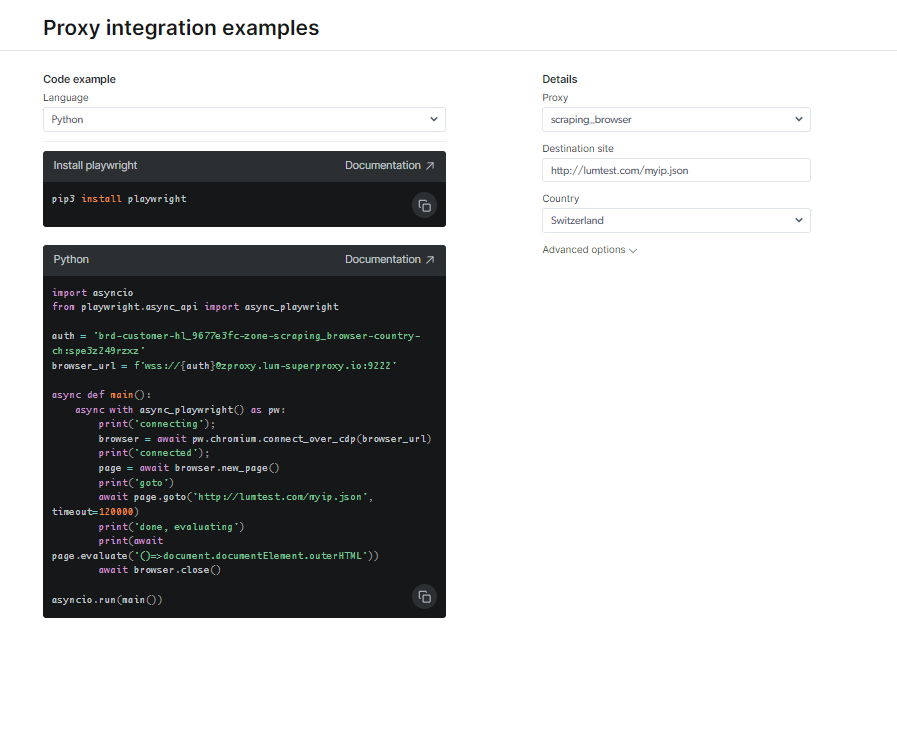
查看文檔和代碼示例,包括隨時可用的全功能示例腳本,或觀看簡短的入門說明視頻。 例如; 這裡有一個 Python代碼 集成示例:
需要幫助嗎? 要與其中一位專家對話,您可以單擊聊天圖標。
請記住,在使用 Scraping Browser 時,您可以完全控制瀏覽器會話,並且可以執行 Puppeteer、Playwright 或直接使用 Chrome DevTools 協議支持的任何操作。
無障礙網站解鎖
Scraping Browser 可以根據需要大規模運行。 您無需擔心被禁止; 您可以根據需要啟動任意數量的瀏覽器會話。
這種能力與代理的力量相結合,保證了持續的數據收集,使您能夠有效地獲取所需的數據。
抓取瀏覽器內置的解鎖技巧和強大的代理網絡可幫助您節省時間、提高生產力並發現新機會。
您還可以直接從同一頁面查看統計信息。
抓取瀏覽器定價
Bright Data 提供可定制的定價選擇以滿足各種目的。 您可以選擇每月或每年的計費周期。
Pay as You Go 選項允許您只為使用的內容付費,無需承諾,起價為 20.00 美元/GB 和 0.1 美元/小時。
500 美元的增長計劃適合成長型企業,折扣費用為 15.30 美元/GB 和 0.1 美元/小時。
商務包, 價格為 1000 美元,是最受歡迎的選項,Scraping Browser API 的價格為 13.50 美元/GB 和 0.1 美元/小時。
通過直接聯繫 Bright Data 團隊,企業用戶可以享受無限擴展和個性化定價。 立即開始免費試用,發現 Bright Data 的 Scraping Browser 的潛力並改變您的在線數據採集工作。
網站解鎖器
Web Unlocker 是一種強大的工具,旨在超越網站限制並提供輕鬆的數據收集。 它通過利用自動化程序克服了多項挑戰,包括 cookie、特定於站點的瀏覽器用戶代理和驗證碼解決方案。
通過使用自動 IP 地址輪換,Web Unlocker 的用戶可以不斷抓取目標網站,確保對重要數據的持續訪問。
增強開發人員請求之旅
多項功能使 Web Unlocker 在開發人員中很受歡迎。 該程序通過自動識別每個網站所需的用戶代理來簡化數據收集過程,從而節省寶貴的時間和資源。
Web Unlocker 實時調整以避免檢測,以響應阻止機器人使用的不斷變化的策略,確保持續訪問感興趣的網站。 該平台的機器學習算法可以快速解決驗證碼,這是數據收集計劃的常見障礙。

Web Unlocker 的定價
Web Unlocker 起價約為每千次請求 2.03 美元 (CPM),提供多種價格選擇以滿足各種需求。 用戶可以享受 7 天的免費試用,讓他們開始使用並讓他們在提交之前測試 Web Unlocker 的功能。
Web Unlocker 具有支持各種使用模式的適應性,無論消費者是想要現收現付的方法還是需要適合其特定需求的定制計劃。 此外,那些選擇長期價格計劃的人可以節省 32%。
Web Unlocker 與自我管理代理的比較
Web Unlocker 比自我管理的代理提供了許多即時的好處。 為了順利實施,它提供了一種廣泛的集成技術,結合了超級代理和代理管理器功能。 用戶可以通過無限數量的並發連接有效地擴展他們的數據收集操作。
Web Unlocker 提供自動解鎖、解決驗證碼並成功管理目標網站上的標記修改。
該平台通過實施自動重試系統並對某些域進行異步調用來保證連續可靠的數據提取。 此外,Online Unlocker 不斷增加的 HTTP 標頭請求、特定於站點的瀏覽器 cookie 和模擬小工具的集合使用戶能夠保持不被發現,同時使他們能夠實時獲取在線數據。
最後的想法和要記住的重要事情
最後,在使用 Bright Data 進行 Instagram 抓取時,牢記幾個要點至關重要。
請注意,根據道德規範,他們的抓取能力僅限於公開可用的數據。
您應該始終遵守 Instagram 的服務條款和隱私政策。 數據採集應該以合乎道德和負責任的方式進行,不得侵犯用戶的權利或違反任何法律。
其次,定期更新和微調您的抓取參數,以確保檢索數據的準確性和相關性。 Instagram 的平台和算法可能會發生變化,因此您必須相應地改變您的抓取策略。
最後,使用 Bright Data 平台的幫助和資源來優化您的 Instagram 抓取工作的成功。 參與他們的文檔、教程和客戶服務,以提高您對他們的抓取工具的了解。
通過遵循這些最佳實踐並利用 Bright Data 的 Instagram 抓取功能的優勢,您可以獲得有用的見解,影響明智的決策,並在 Instagram 平台上成功實施數據驅動的計劃。





發表評論