大型文本到圖像模型通過從給定的文本提示生成高質量和多樣化的圖片合成,在人工智能的發展中取得了重大進展。
這些模型無法在各種設置中合成對象的獨特表示或複制給定參考集中對象的外觀。
新發布的技術,如 OpenAI 的 DALL.E2 或 StabilityAI 的 穩定擴散 和 Midjourney 已經風靡互聯網。 現在是自定義結果的時候了。 然而如何?
Google DreamBooth AI 已經到來。
DreamBooth 能夠識別圖片的主題,將其從原始上下文中解構,然後將其精確地合成到新的所需上下文中。 此外,它還可以與當前的 AI 圖片生成器一起使用。
在本文中,我們將深入了解 DreamBooth、它的使用、它的教程、它的限制等等。
什麼是 Dreambooth?
夢想展位,一種全新的文本到圖像的擴散模型,由谷歌提出。 Google DreamBooth AI 可以將書面提示用作指導,以在不同設置下生成用戶所選主題的各種照片。
波士頓大學和谷歌的一個研究小組開發了 DreamBooth,這是一種用於改變經過大量預訓練的文本到圖像模型的尖端技術。
總體概念相當簡單:他們希望增加語言視覺詞典,以便不常見的令牌 ID 與用戶可以定義的自定義主題相關聯。
該模型的主要目標是將用戶連接到 文本到圖像的擴散模型 通過為他們提供所需的資源,以生成他們所選主題實例的照片級真實感表示。
因此,這種技術似乎可以很好地總結各種情況下的挑戰。
谷歌的 DreamBooth 與之前的文本到圖像工具不同,例如 達爾-E 2, 穩定擴散和 中途,因為它讓用戶在使用基於文本的輸入操作擴散模型之前,可以更好地控制主題圖像。
功能
- DreamBooth AI 可能會改進具有 3-5 個圖像的文本到圖像模型。
- 可以使用 DreamBooth AI 創建逼真的原始照片。
- 此外,DreamBooth AI 可以從多個角度創建主題照片。
應用
藝術演繹
此任務與樣式遷移特別不同,樣式遷移保留源場景的語義,同時將另一張圖像的樣式合併到原始場景中。

基於創造性的方法,人工智能可以在保持識別和主題實例細節的同時完成重大的場景改變。
屬性修改
DreamBooth AI 可以修改主題實例的特徵。

配飾
生成模型之前的強大構圖使 DreamBooth AI 裝飾物體的能力如此有趣。

重新語境化
DreamBooth AI 可以通過為經過訓練的模型提供一個包含唯一標識符和類名詞的句子來為某個主題實例生成獨特的圖像。

它可以以獨特的、以前聞所未聞的姿勢、關節和場景結構生成主題,而不是改變周圍環境。 逼真的反射和陰影,以及主體與周圍物體之間的相互作用。
Dreambooth 教程
在本教程中,我們將按照 谷歌協作筆記本,我將引導您完成它,這將使您理解並自己使用它。
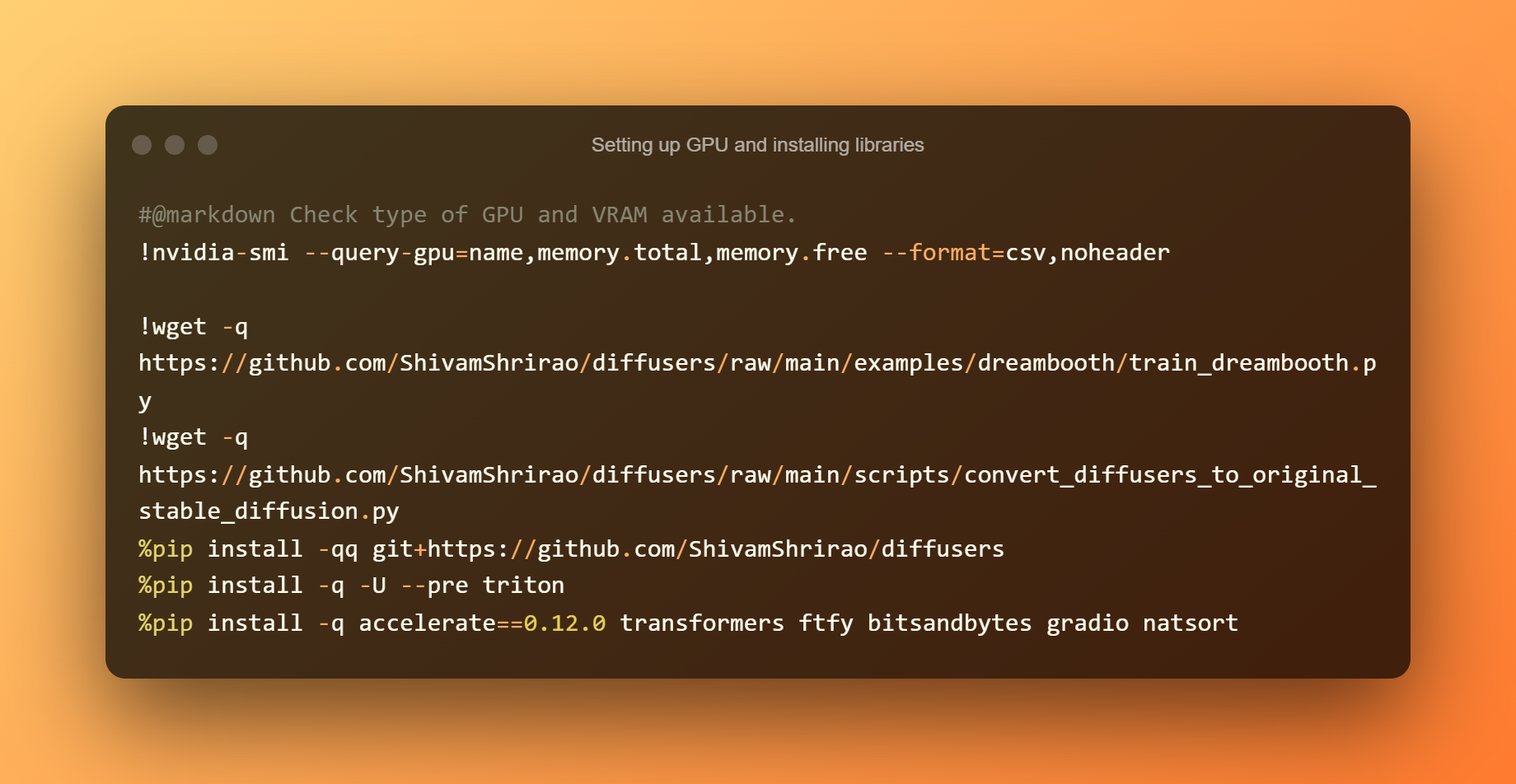
設置 GPU 和安裝庫
第一步是找出可用的 GPU 和 VRAM 類型。 安裝一些需求和依賴項也是必要的。 只需按下播放按鈕,然後等待它完成。
在 Huggingface 上創建一個帳戶並生成一個令牌
下一步是註冊 Huggingface 帳戶。 完成後,點擊右上角的設置。 您將到達下一頁。
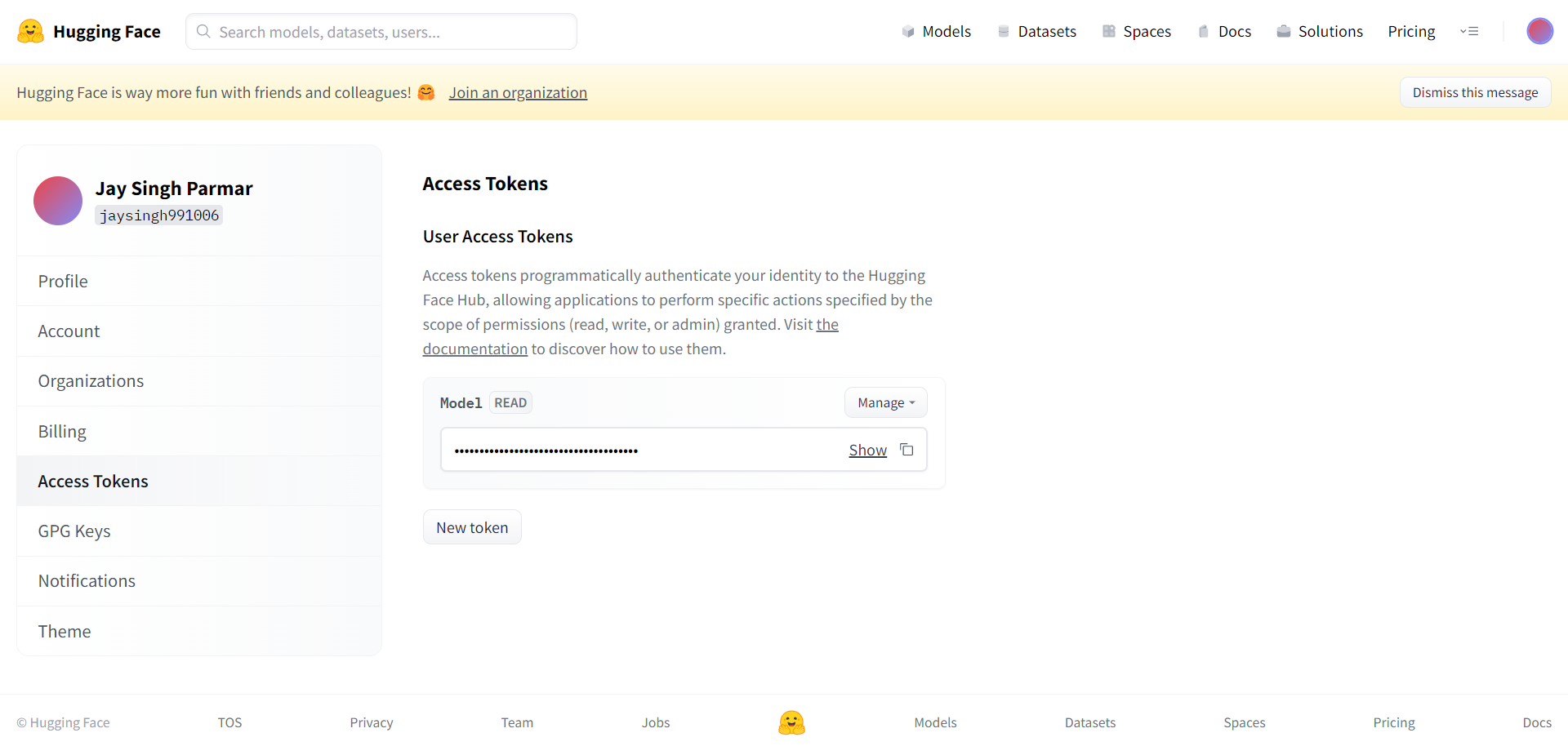
根據此處的請求創建令牌和名稱。 應將令牌複製並粘貼到下方單元格中的 Google 協作中。

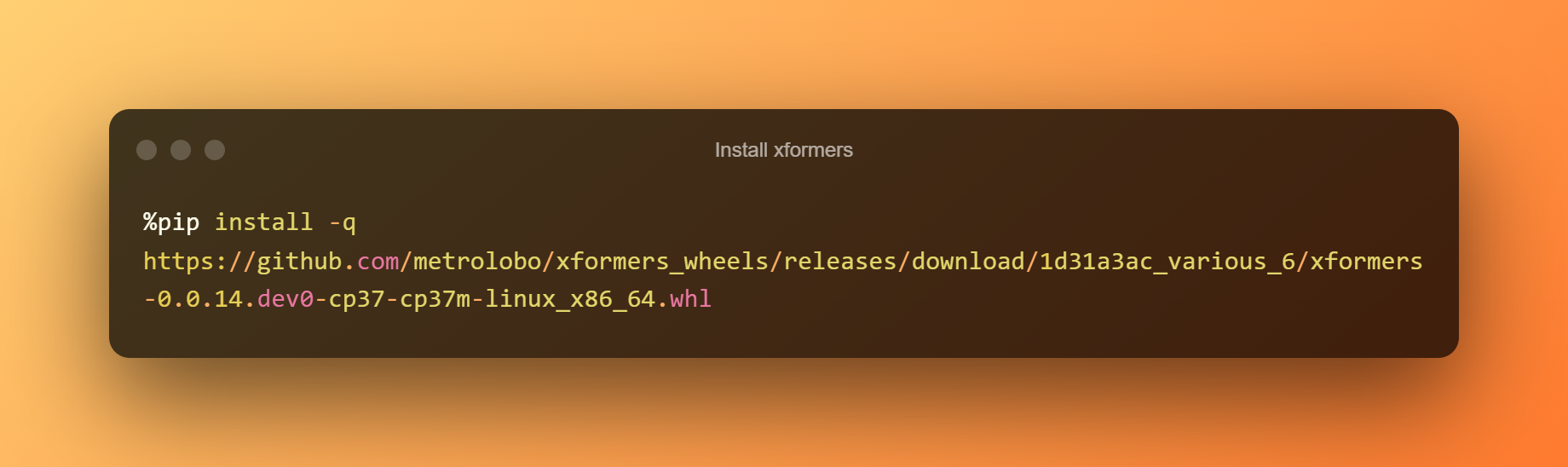
安裝 xformers
在這個階段,您可以通過單擊運行時簡單地按下播放按鈕來安裝 xformers。
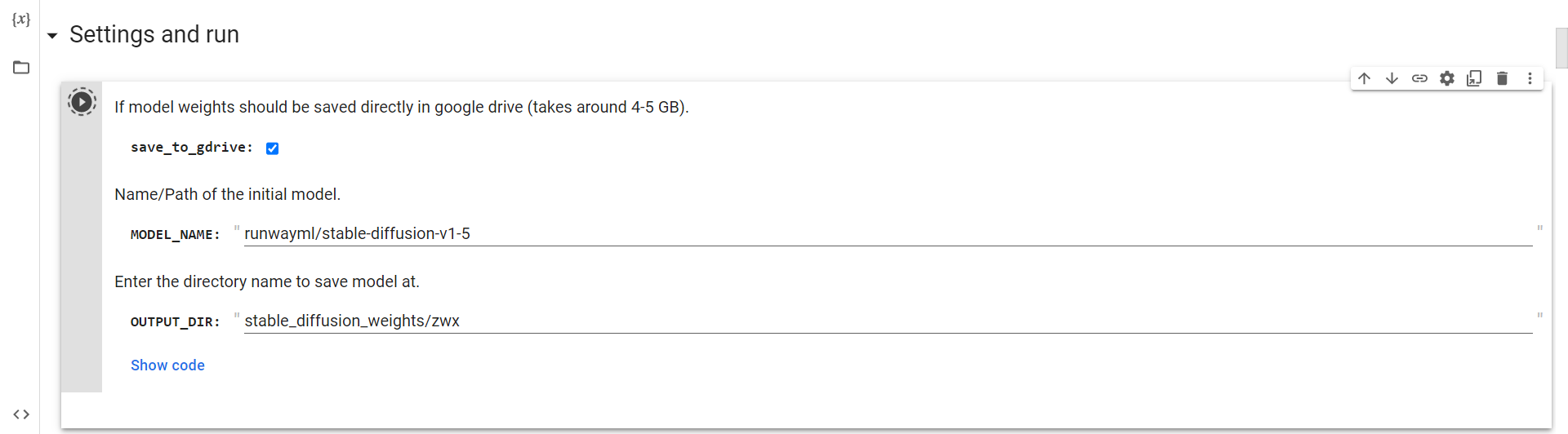
連接到雲端硬盤
現在,你只需要運行這個單元來連接到谷歌驅動器。
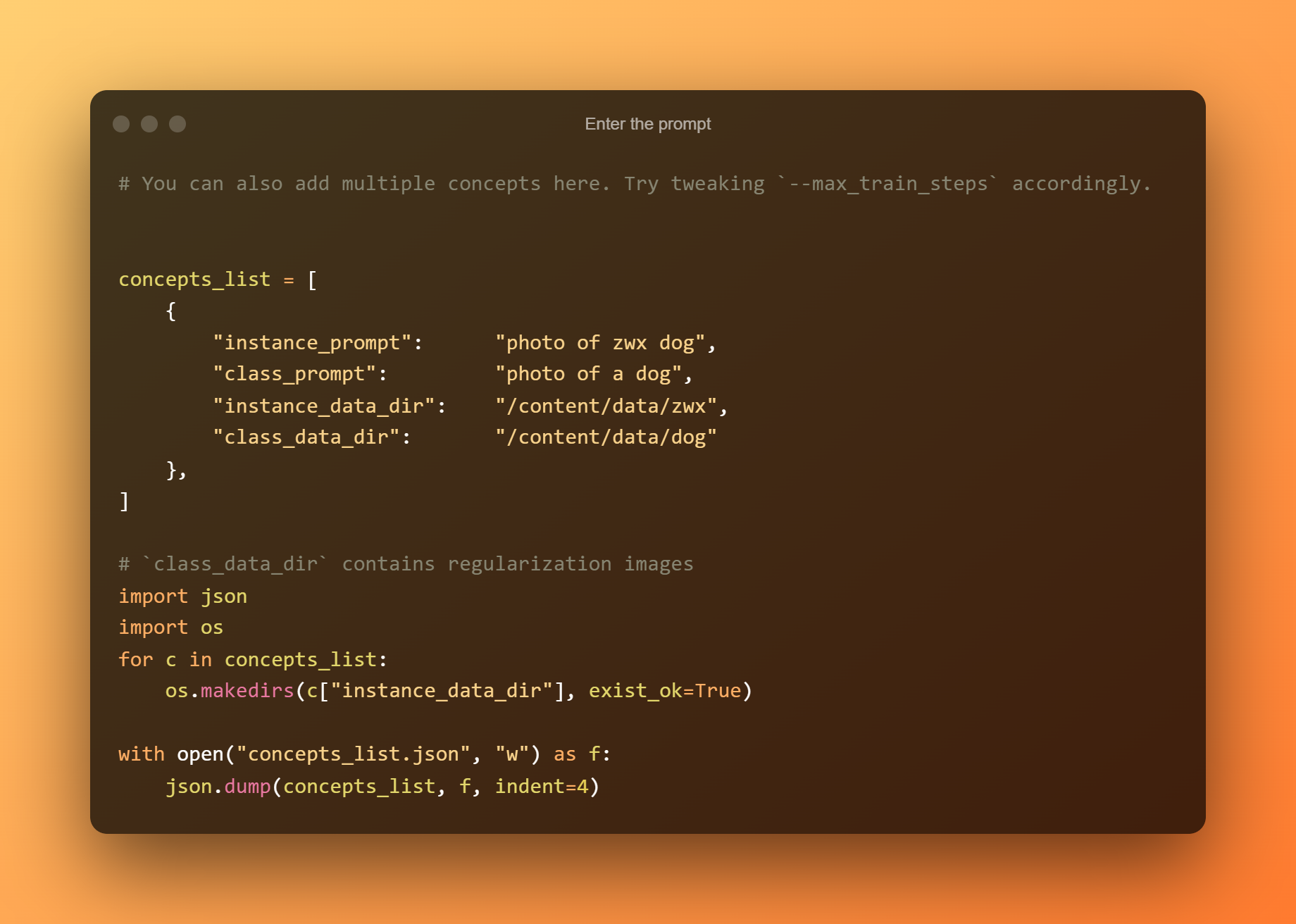
輸入提示
在以下單元格中,您只需輸入提示。
上傳圖片
在這一步中,您只需上傳您想要訓練的圖片。

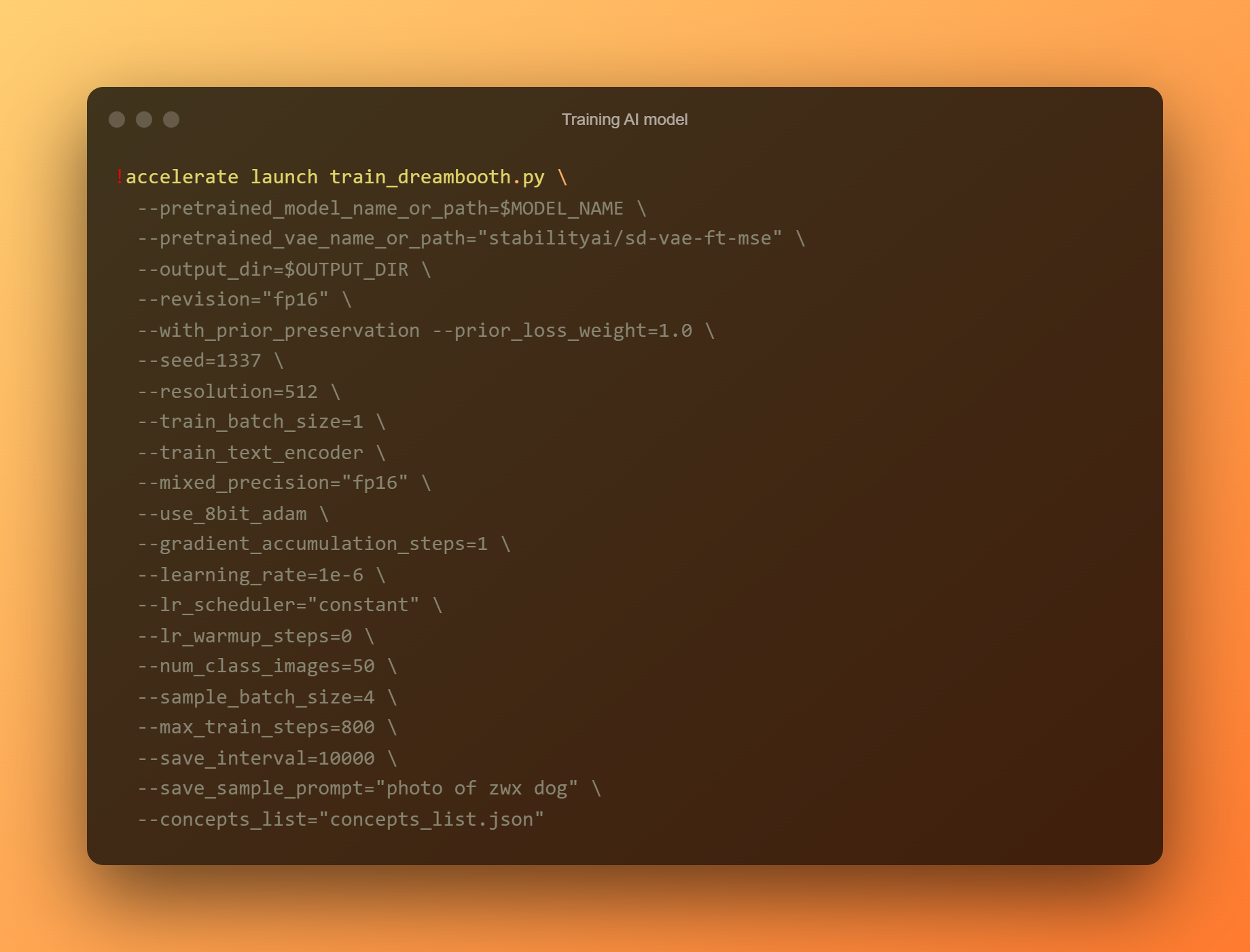
訓練 AI 模型
這是最重要的階段,因為您將使用 DreamBooth 根據您提交的所有參考照片訓練一個新的 AI 模型。 您必須將注意力限制在兩個輸入字段上。 “——實例提示”是第一個參數。 您必須在此處提供一個高度不同的名稱。
'–concept list' 參數是第二個關鍵輸入字段。 它必須重命名以匹配“更改提示”部分中使用的名稱。
生成 AI 圖像
AI圖片將在此階段創建,您可以在其中輸入文字說明。

Dreambooth 限制
- 命令提示符成為在具有高度細節的主題中進行迭代的障礙。 DreamBooth 可以更改主題的上下文,但如果模型希望更改主題本身,則框架存在問題。
- 另一個問題是將輸出圖片過度擬合到輸入圖像。 如果沒有提供足夠的圖片,則可能不會考慮該主題,或者可能會與提交的圖像的上下文混合。 當詢問奇數代的上下文時,會發生同樣的事情。
結論
為了從單個文本輸入生成輸出,大量文本到圖像模型需要數百萬個參數和庫。
DreamBooth 只需輸入三到五張主題照片和文字背景,即可為消費者簡化內容獲取和使用。





發表評論