如果我們可以使用人工智能來解開生命中最大的謎團之一——蛋白質折疊,會怎樣? 幾十年來,科學家們一直致力於此。
機器現在可以使用深度學習模型以驚人的精度預測蛋白質結構,改變藥物開發、生物技術和我們對基本生物過程的了解。
和我一起探索 AI 蛋白質折疊的有趣領域,尖端技術與生命本身的複雜性發生碰撞。
揭開蛋白質折疊之謎
蛋白質在我們體內像小型機器一樣工作,執行分解食物或輸送氧氣等重要任務。 它們必須正確折疊才能有效發揮作用,就像必須正確切割鑰匙才能插入鎖一樣。 一旦蛋白質被創造出來,一個非常複雜的折疊過程就開始了。
蛋白質折疊是長鏈氨基酸(蛋白質的組成部分)折疊成決定蛋白質功能的三維結構的過程。
考慮一串很長的珠子,必須以精確的形式排列; 這就是蛋白質折疊時發生的情況。 然而,與珠子不同,氨基酸具有獨特的特性並以各種方式相互作用,使蛋白質折疊成為一個複雜而敏感的過程。
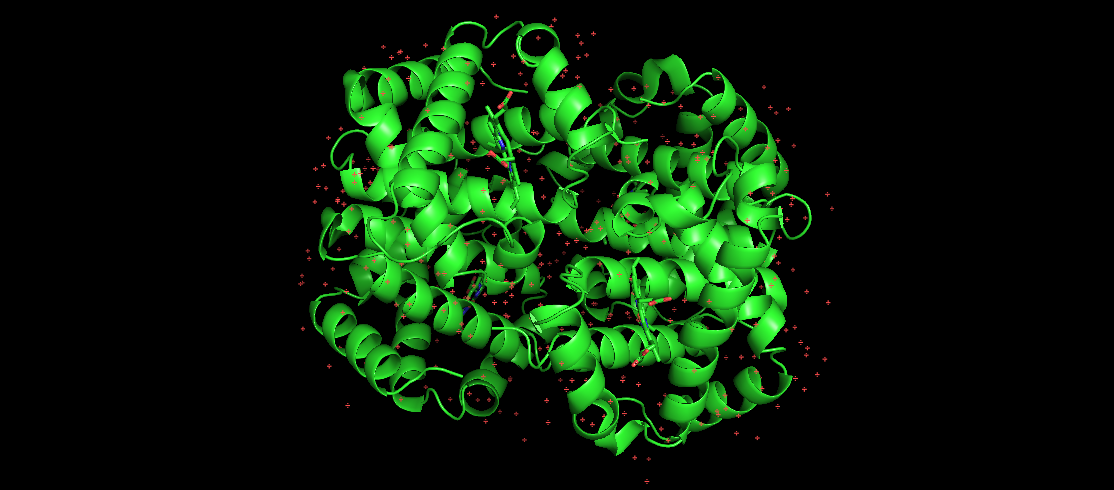
此處的圖片代表人類血紅蛋白,這是一種眾所周知的折疊蛋白
蛋白質必須快速而精確地折疊,否則它們將被錯誤折疊並產生缺陷。 這可能導致阿爾茨海默氏症和帕金森氏症等疾病。 溫度、壓力和細胞中其他分子的存在都會對折疊過程產生影響。
經過數十年的研究,科學家們仍在努力弄清楚蛋白質是如何折疊的。
值得慶幸的是,人工智能的進步正在促進該行業的發展。 科學家們可以通過使用比以往任何時候都更準確地預測蛋白質的結構 機器學習算法 檢查海量數據。
這有可能改變藥物開發並增加我們對疾病的分子知識。
機器能表現得更好嗎?
傳統的蛋白質折疊技術有局限性
幾十年來,科學家們一直試圖弄清楚蛋白質折疊,但這個過程的複雜性使它成為一個具有挑戰性的課題。
傳統的蛋白質結構預測方法結合使用實驗方法和計算機建模,但是,這些方法都有缺點。
X 射線晶體學和核磁共振 (NMR) 等實驗技術既費時又費錢。 而且,計算機模型有時依賴於簡單的假設,這可能會導致錯誤的預測。
人工智能可以克服這些障礙
幸運的是, 人工智能 為更準確和有效的蛋白質結構預測提供了新的希望。 機器學習算法可以檢查大量數據。 而且,他們發現了人們會錯過的模式。
這導致了能夠以無與倫比的精度預測蛋白質結構的新軟件工具和平台的創建。
最有前途的蛋白質結構預測機器學習算法
Google 打造的 AlphaFold 系統 DeepMind 團隊是該領域最有前途的進步之一。 近年來通過使用取得了長足的進步 深度學習算法 根據氨基酸序列預測蛋白質的結構。
神經網絡、支持向量機和隨機森林等機器學習方法有望預測蛋白質結構。
這些算法可以從龐大的數據集中學習。 而且,他們可以預測不同氨基酸之間的相關性。 那麼,讓我們看看它是如何工作的。

協同進化分析和第一代 AlphaFold
成功 折疊 建立在利用協同進化分析開發的深度神經網絡模型之上。 共同進化的概念指出,如果蛋白質中的兩個氨基酸相互作用,它們將一起發育以保持其功能聯繫。
研究人員可以通過比較眾多相似蛋白質的氨基酸序列來檢測哪些氨基酸對可能在 3D 結構中相互聯繫。
這些數據是 AlphaFold 第一次迭代的基礎。 它預測氨基酸對之間的長度以及連接它們的肽鍵的角度。 這種方法優於所有先前的從序列預測蛋白質結構的方法,儘管對於沒有明顯模板的蛋白質,準確性仍然受到限制。

AlphaFold 2:一種全新的方法論
AlphaFold2 是由 DeepMind 創建的計算機軟件,它使用蛋白質的氨基酸序列來預測蛋白質的 3D 結構。
這很重要,因為蛋白質的結構決定了它的功能,了解它的功能可以幫助科學家開發針對蛋白質的藥物。
AlphaFold2 神經網絡接收蛋白質的氨基酸序列以及有關該序列如何與數據庫中其他序列進行比較的詳細信息(這稱為“序列比對”)作為輸入。
神經網絡根據此輸入預測蛋白質的 3D 結構。
它與 AlphaFold2 有何不同?
與其他方法相比,AlphaFold2 預測蛋白質的真實 3D 結構,而不僅僅是氨基酸對之間的分離或連接它們的鍵之間的角度(如先前的算法所做的那樣)。
為了讓神經網絡立即預測完整結構,結構被端到端編碼。
AlphaFold2 的另一個關鍵特徵是它提供了對其預測的信心程度的估計。 這在預期結構上顯示為顏色編碼,紅色表示高置信度,藍色表示低置信度。
這很有用,因為它可以讓科學家了解預測的穩定性。
預測多個序列的組合結構
Alphafold2 的最新擴展,稱為 Alphafold Multimer,可預測多個序列的組合結構。 即使它比早期的技術表現得更好,它仍然有很高的錯誤率。 25 種蛋白質複合物中只有 %4500 被成功預測。
70% 的接觸形成的粗略區域被正確預測,但兩種蛋白質的相對方向不正確。 當中值比對深度小於大約 30 個序列時,Alphafold 多聚體預測的準確性會顯著下降。
如何使用 Alphafold 預測
AlphaFold 的預測模型以相同的文件格式提供,並且可以以與實驗結構相同的方式使用。 為了防止誤解,考慮模型提供的準確度估計至關重要。
它對於復雜的結構特別有用,例如交織的同聚體或僅在存在折疊的情況下折疊的蛋白質。
未知的配體。
一些挑戰
使用預測結構的主要問題是在沒有獲得蛋白質和生物物理數據的情況下理解動力學、配體選擇性、控制、變構、翻譯後變化和結合動力學。
機器學習 可以利用基於物理學的分子動力學研究來克服這個問題。
這些調查可能受益於專業高效的計算機體系結構。 雖然 AlphaFold 在預測蛋白質結構方面取得了巨大進步,但在結構生物學領域還有很多東西需要學習,而 AlphaFold 預測只是未來研究的起點。
其他卓越的工具是什麼?
玫瑰TTA折疊
由華盛頓大學研究人員創建的 RoseTTAFold 同樣採用深度學習算法來預測蛋白質結構,但它還集成了一種稱為“扭轉角動力學模擬”的新方法來改進預測結構。
這種方法取得了令人鼓舞的結果,可能有助於克服現有 AI 蛋白質折疊工具的局限性。
羅塞塔
另一個工具 trRosetta 通過使用 神經網絡 訓練了數百萬個蛋白質序列和結構。
它還使用“基於模板的建模”技術通過將目標蛋白質與可比較的已知結構進行比較來創建更精確的預測。
已經證明 trRosetta 能夠預測微小蛋白質和蛋白質複合物的結構。
深元PSICOV
DeepMetaPSICOV 是另一個專注於預測蛋白質接觸圖的工具。 這些被用作預測蛋白質折疊的指南。 它用 深入學習 預測蛋白質內部殘基相互作用可能性的方法。
這些隨後用於預測整體聯繫地圖。 DeepMetaPSICOV 已顯示出非常準確地預測蛋白質結構的潛力,即使以前的方法都失敗了。
未來該何去何從?
AI 蛋白質折疊的未來是光明的。 基於深度學習的算法,尤其是 AlphaFold2,最近在可靠地預測蛋白質結構方面取得了很大進展。
這一發現有可能通過讓科學家更好地了解蛋白質的結構和功能來改變藥物開發,而蛋白質是常見的治療靶點。
儘管如此,預測蛋白質複合物和檢測預期結構的真實功能狀態等問題仍然存在。 需要更多的研究來解決這些問題並提高 AI 蛋白質折疊算法的準確性和可靠性。
然而,這項技術的潛在好處是巨大的,它有可能導致生產更有效和更精確的藥物。





發表評論