制作最高水准的创意人像电影是计算机视觉和图形学中一项至关重要且理想的任务。
尽管已经提出了几种基于有效 StyleGAN 的人像图像卡通化的有效模型,但这些面向图像的技术在与视频一起使用时具有明显的缺点,例如固定帧大小、面部对齐的要求、缺乏非面部细节, 和时间不一致。
革命性的 VToonify 框架用于解决难以控制的高分辨率肖像视频风格传输。
我们将在本文中研究 VToonify 的最新研究,包括其功能、缺点和其他因素。
什么是 Vtoonify?
VToonify 框架允许可定制的高分辨率肖像视频风格传输。
VToonify 使用 StyleGAN 的中高分辨率层,根据编码器检索到的多尺度内容特征来创建高质量的艺术肖像,以保留帧细节。
由此产生的全卷积架构将可变大小电影中未对齐的人脸作为输入,从而在输出中产生具有真实运动的全脸区域。

该框架与当前基于 StyleGAN 的图像卡通化模型兼容,允许它们扩展到视频卡通化,并继承了可调节颜色和强度定制等吸引人的特性。
本篇 根据一项研究, 介绍了两个基于 Toonify 和 DualStyleGAN 的 VToonify 实例,分别用于基于集合和基于样本的肖像视频风格迁移。
广泛的实验结果表明,所提出的 VToonify 框架在制作具有可变风格参数的高质量、时间连贯的艺术肖像电影方面优于现有方法。
研究人员提供 谷歌 Colab 笔记本,所以你可以弄脏它。
我们如何运作?
为了实现可调节的高分辨率人像视频风格转换,VToonify 将图像翻译框架的优点与基于 StyleGAN 的框架相结合。
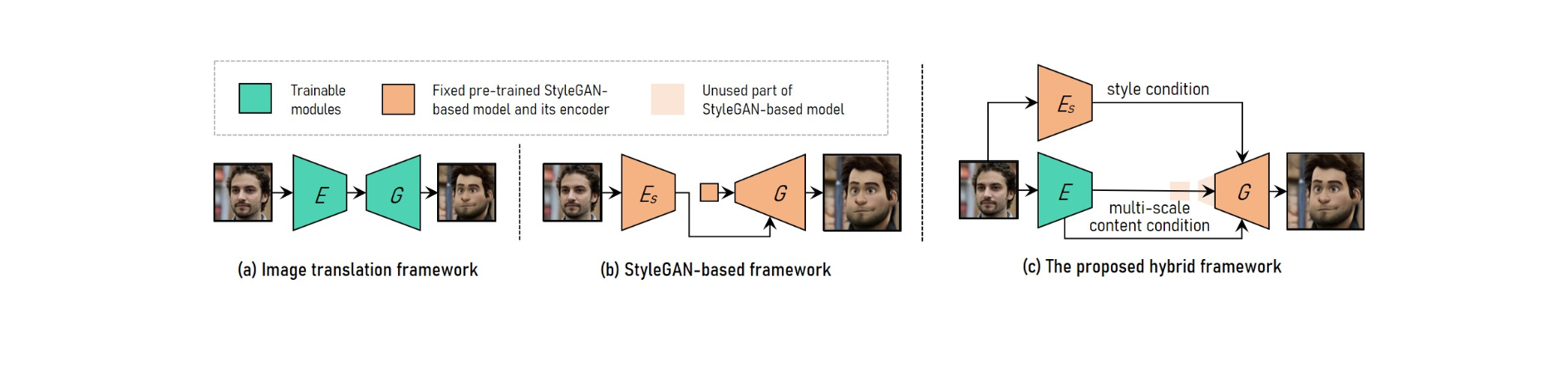
为了适应不同的输入大小,图像翻译系统采用完全卷积网络。 另一方面,从头开始训练使得高分辨率和受控的风格传输变得不可能。
预训练的 StyleGAN 模型用于基于 StyleGAN 的高分辨率和受控风格迁移的框架中,尽管它仅限于固定的图片尺寸和细节损失。
StyleGAN 在混合框架中进行了修改,删除了其固定大小的输入特征和低分辨率层,从而产生了类似于图像翻译框架的全卷积编码器-生成器架构。
为了保持帧细节,训练编码器以提取输入帧的多尺度内容特征,作为对生成器的附加内容要求。 Vtoonify 继承了 StyleGAN 模型的样式控制灵活性,将其放入生成器以提取其数据和模型。
StyleGAN 和提议的 Vtoonify 的局限性
艺术肖像在我们的日常生活以及艺术等创意行业中很常见, 社会化媒体 头像、电影、娱乐广告等等。
随着发展 深入学习 技术,现在可以使用自动肖像风格转换从真实的面部照片创建高质量的艺术肖像。
为基于图像的风格转移创建了多种成功的方法,其中许多方法很容易以移动应用程序的形式被初级用户访问。 在过去的几年里,视频材料迅速成为我们社交媒体源的支柱。
社交媒体和短片的兴起增加了对创新视频编辑的需求,例如肖像视频风格转换,以生成成功且有趣的视频。
现有的面向图像的技术在应用于电影时具有明显的缺点,限制了它们在自动肖像视频风格化中的有用性。
StyleGAN 是开发肖像图片风格转移模型的常用主干,因为它能够创建具有可调节风格管理的高质量人脸。
基于 StyleGAN 的系统(也称为图片卡通化)将真实面孔编码到 StyleGAN 潜在空间中,然后将生成的样式代码应用于另一个在艺术肖像数据集上微调的 StyleGAN,以创建风格化版本。
StyleGAN 创建具有对齐面孔和固定大小的图片,这不利于现实世界镜头中的动态面孔。 视频中的面部裁剪和对齐有时会导致部分面部和尴尬的手势。 研究人员将此问题称为 StyleGAN 的“固定作物限制”。
对于未对齐的人脸,已经提出了StyleGAN3; 但是,它只支持设置的图片尺寸。
此外,最近的一项研究发现,编码未对齐的人脸比对齐的人脸更具挑战性。 不正确的人脸编码不利于人像风格的迁移,从而导致身份改变和重构和风格化帧中的组件丢失等问题。
如前所述,肖像视频风格转换的有效技术必须处理以下问题:
- 为了保持逼真的运动,该方法必须能够处理未对齐的面部和不同的视频大小。 较大的视频尺寸或宽视角可以捕捉更多信息,同时防止面部移出画面。
- 为了与当今常用的高清设备竞争,高分辨率视频是必要的。
- 在开发逼真的用户交互系统时,应该为用户提供灵活的样式控制来改变和选择他们的选择。
为此,研究人员建议使用 VToonify,这是一种用于视频卡通化的新型混合框架。 为了克服固定裁剪约束,研究人员首先研究 StyleGAN 中的翻译等方差。
VToonify 结合了基于 StyleGAN 的架构和图像翻译框架的优点,实现了可调节的高分辨率人像视频风格转换。
以下是主要贡献:
- 研究人员研究了 StyleGAN 的固定裁剪约束,并提出了一种基于平移等效性的解决方案。
- 研究人员提出了一个独特的全卷积 VToonify 框架,用于受控的高分辨率肖像视频风格传输,支持未对齐的面部和不同的视频大小。
- 研究人员在 Toonify 和 DualStyleGAN 的主干上构建了 VToonify,并在数据和模型方面对主干进行了浓缩,以实现基于集合和基于样本的肖像视频风格迁移。
将 Vtoonify 与其他最先进的模型进行比较
美化
它是使用 StyleGAN 在对齐面上进行基于集合的样式迁移的基础。 要检索样式代码,研究人员必须对齐人脸并为 PSP 裁剪 256256 张照片。 Toonify 用于生成具有 1024*1024 样式代码的风格化结果。
最后,他们将视频中的结果重新对齐到其原始位置。 未风格化的区域已设置为黑色。

双风格GAN
它是基于 StyleGAN 的基于样本的风格迁移的骨干。 他们使用与 Toonify 相同的数据预处理和后处理技术。
像素2像素高清
它是一种图像到图像的转换模型,通常用于压缩预训练模型以进行高分辨率编辑。 它使用配对数据进行训练。
研究人员利用 pix2pixHD 作为其额外的实例图输入,因为它使用提取的解析图。
一阶运动
FOM 是一种典型的图像动画模型。 它在 256256 张图片上进行了训练,在其他尺寸的图片上表现不佳。 因此,研究人员首先将视频帧缩放到 256*256 以将 FOM 转换为动画,然后将结果调整为原始大小。
为了公平比较,FOM 采用其方法的第一个风格化框架作为其参考风格图像。
大干
这是一个3D人脸动画模型。 他们使用与 FOM 相同的数据准备和后处理方法。

优势
- 它可以用于艺术、社交媒体化身、电影、娱乐广告等。
- Vtoonify 也可以在元节中使用。
限制
- 该方法从基于 StyleGAN 的主干中提取数据和模型,从而导致数据和模型偏差。
- 伪影主要是由程式化的面部区域与其他部分之间的大小差异引起的。
- 这种策略在处理面部区域的事情时不太成功。
结论
最后,VToonify 是一个风格控制的高分辨率视频卡通化框架。
该框架在处理视频方面取得了出色的表现,并通过在两个方面对基于 StyleGAN 的图像卡通化模型进行了浓缩,从而可以对结构风格、颜色风格和风格程度进行广泛的控制。 综合数据 和网络结构。





发表评论