神经渲染是深度学习中的一项新兴技术,旨在通过神经网络增强计算机图形学的经典管道。
神经渲染算法需要一组代表同一场景不同角度的图像。 然后,这些图像将被输入神经网络,以创建一个模型,该模型可以输出同一场景的新角度。
神经渲染背后的卓越之处在于它如何能够准确地重建详细的逼真场景,而不必依赖可能对计算要求更高的经典方法。
在深入了解神经渲染的工作原理之前,让我们先回顾一下经典渲染的基础知识。
什么是经典渲染?
我们先了解一下经典渲染中使用的典型方法。
经典渲染是指用于创建三维场景的二维图像的一组技术。 也称为图像合成,经典渲染使用各种算法来模拟光如何与不同类型的对象交互。
例如,渲染一块实心砖需要一组特定的算法来确定阴影的位置或墙壁两侧的光照情况。 同样,反射或折射光线的物体,如镜子、闪亮的物体或水体,也需要自己的技术。

在经典渲染中,每个资产都用多边形网格表示。 然后着色器程序将使用多边形作为输入来确定对象在给定指定光照和角度的情况下的外观。
逼真的渲染将需要更多的计算能力,因为我们的资产最终有数百万个多边形用作输入。 好莱坞大片中常见的计算机生成输出通常需要数周甚至数月的渲染时间,并且可能耗资数百万美元。
光线追踪方法的成本特别高,因为最终图像中的每个像素都需要计算光从光源到物体再到相机的路径。

硬件的进步使用户更容易进行图形渲染。 例如,许多最新的 视频游戏 允许光线追踪效果,例如照片般逼真的反射和阴影,只要它们的硬件能够胜任任务。
最新的 GPU(图形处理单元)专门用于帮助 CPU 处理渲染逼真图形所需的高度复杂的计算。
神经渲染的兴起
神经渲染试图以不同的方式解决渲染问题。 如果我们不使用算法来模拟光如何与物体相互作用,而是创建一个模型来学习场景从某个角度应该如何看会怎样?
您可以将其视为创建逼真的场景的捷径。 使用神经渲染,我们不需要计算光如何与物体相互作用,我们只需要足够的训练数据。
这种方法允许研究人员创建复杂场景的高质量渲染,而无需执行
什么是神经场?
如前所述,大多数 3D 渲染使用多边形网格来存储有关每个对象的形状和纹理的数据。
然而,神经场作为表示三维对象的替代方法越来越受欢迎。 与多边形网格不同,神经场是可微且连续的。
当我们说神经场是可微的时,我们是什么意思?
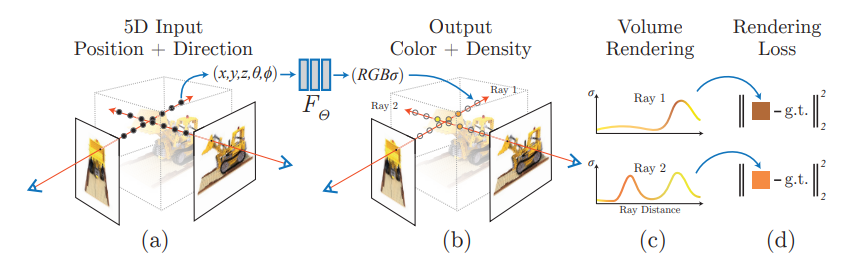
现在可以通过简单地调整神经网络的权重来训练来自神经场的 2D 输出,使其变得逼真。
使用神经场,我们不再需要模拟光的物理特性来渲染场景。 关于最终渲染将如何点亮的知识现在隐式存储在我们的权重中 神经网络.
这使我们能够从少量照片或视频片段中相对快速地创建新颖的图像和视频。
如何训练神经场?
现在我们了解了神经场如何工作的基础知识,让我们来看看研究人员如何能够训练神经辐射场或 神经RF.
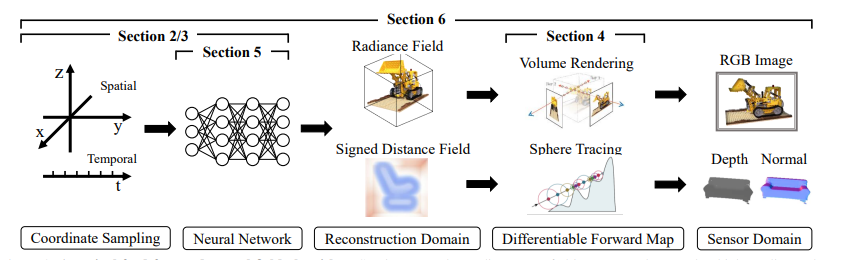
首先,我们需要对场景的随机坐标进行采样并将它们输入神经网络。 然后该网络将能够产生现场数量。
产生的场量被认为是来自我们要创建的场景的所需重建域的样本。
然后我们需要将重建映射到实际的 2D 图像。 然后算法将计算重建误差。 该错误将引导神经网络优化其重建场景的能力。
神经渲染的应用
新颖的视图合成
新颖的视图合成是指使用来自有限数量的视角的数据从新角度创建相机视角的任务。
神经渲染技术尝试为数据集中的每个图像猜测相机的相对位置,并将该数据输入神经网络。
然后神经网络将创建场景的 3D 表示,其中 3D 空间中的每个点都有关联的颜色和密度。

NeRFs 的新实现 谷歌街景 使用新颖的视图合成,让用户可以探索真实世界的位置,就像他们正在控制拍摄视频的相机一样。 这允许游客在决定前往特定地点之前以身临其境的方式探索目的地。
逼真的头像
神经渲染中的先进技术也可以为更逼真的数字化身铺平道路。 然后,这些化身可以用于各种角色,例如虚拟助理或客户服务,或者作为用户将自己的肖像插入到 视频游戏 或模拟渲染。
![]()
例如,一个 纸 发表于 2023 年 XNUMX 月的论文建议使用神经渲染技术在几分钟的视频片段后创建逼真的头像。
结论
神经渲染是一个令人兴奋的研究领域,有可能改变整个计算机图形行业。
该技术可以降低创建 3D 资产的准入门槛。 视觉效果团队可能不再需要等待数天才能渲染几分钟的逼真图形。
将该技术与现有的 VR 和 AR 应用相结合还可以让开发人员创造出更加身临其境的体验。
您认为神经渲染的真正潜力是什么?





发表评论