大型文本到图像模型通过从给定的文本提示生成高质量和多样化的图片合成,在人工智能的发展中取得了重大进展。
这些模型无法在各种设置中合成对象的独特表示或复制给定参考集中对象的外观。
新发布的技术,如 OpenAI 的 DALL.E2 或 StabilityAI 的 稳定扩散 和 Midjourney 已经风靡互联网。 现在是自定义结果的时候了。 然而如何?
Google DreamBooth AI 已经到来。
DreamBooth 能够识别图片的主题,将其从原始上下文中解构,然后将其精确地合成到所需的新上下文中。 此外,它还可以与当前的 AI 图片生成器一起使用。
在本文中,我们将深入了解 DreamBooth、它的使用、它的教程、它的限制等等。
什么是 Dreambooth?
梦想展位,一种全新的文本到图像的扩散模型,由谷歌提出。 Google DreamBooth AI 可以将书面提示用作指导,以在不同设置下生成用户所选主题的各种照片。
波士顿大学和谷歌的一个研究小组开发了 DreamBooth,这是一种用于改变经过大量预训练的文本到图像模型的尖端技术。
总体概念相当简单:他们希望增加语言视觉词典,以便不常见的令牌 ID 与用户可以定义的自定义主题相关联。
该模型的主要目标是将用户连接到 文本到图像的扩散模型 通过为他们提供所需的资源,以生成他们所选主题实例的照片级真实感表示。
因此,这种技术似乎可以很好地总结各种情况下的挑战。
谷歌的 DreamBooth 与之前的文本到图像工具不同,例如 达尔-E 2, 稳定扩散及 中途,因为它让用户在使用基于文本的输入操作扩散模型之前,可以更好地控制主题图像。
特征
- DreamBooth AI 可能会改进具有 3-5 个图像的文本到图像模型。
- 可以使用 DreamBooth AI 创建逼真的原始照片。
- 此外,DreamBooth AI 可以从多个角度创建主题照片。
应用领域
艺术演绎
此任务与样式迁移特别不同,样式迁移保留源场景的语义,同时将另一张图像的样式合并到原始场景中。

基于创造性的方法,人工智能可以在保持识别和主题实例细节的同时完成重大的场景改变。
属性修改
DreamBooth AI 可以修改主题实例的特征。

配饰
生成模型之前的强大构图使 DreamBooth AI 装饰物体的能力如此有趣。

重新语境化
DreamBooth AI 可以通过为经过训练的模型提供一个包含唯一标识符和类名词的句子来为某个主题实例生成独特的图像。

它可以以独特的、以前闻所未闻的姿势、关节和场景结构生成主题,而不是改变周围环境。 逼真的反射和阴影,以及主体与周围物体之间的相互作用。
Dreambooth 教程
在本教程中,我们将按照 谷歌协作笔记本,我将引导您完成它,这将使您理解并自己使用它。
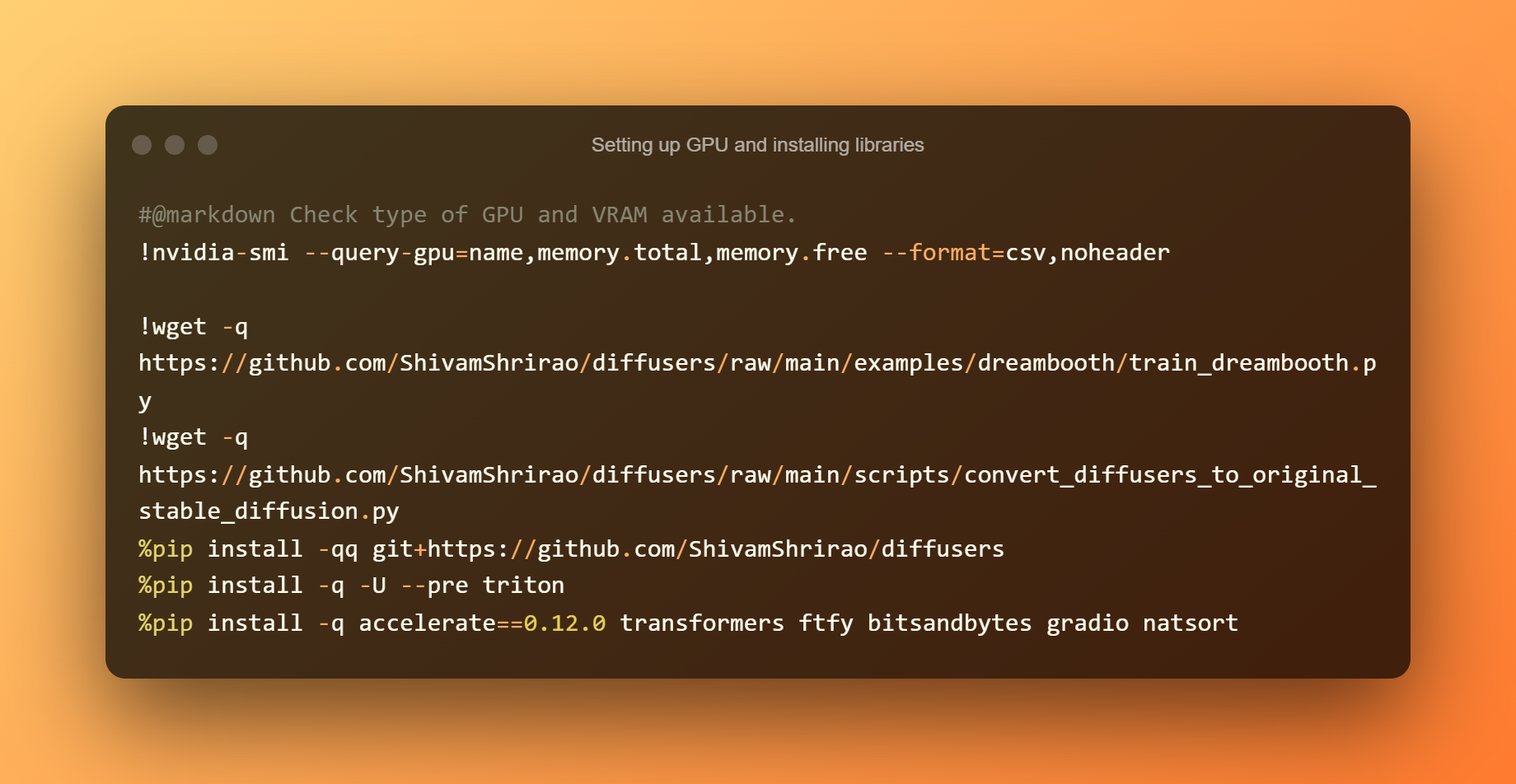
设置 GPU 和安装库
第一步是找出可用的 GPU 和 VRAM 类型。 安装一些需求和依赖项也是必要的。 只需按下播放按钮,然后等待它完成。
在 Huggingface 上创建一个帐户并生成一个令牌
下一步是注册 Huggingface 帐户。 完成后,点击右上角的设置。 您将到达下一页。
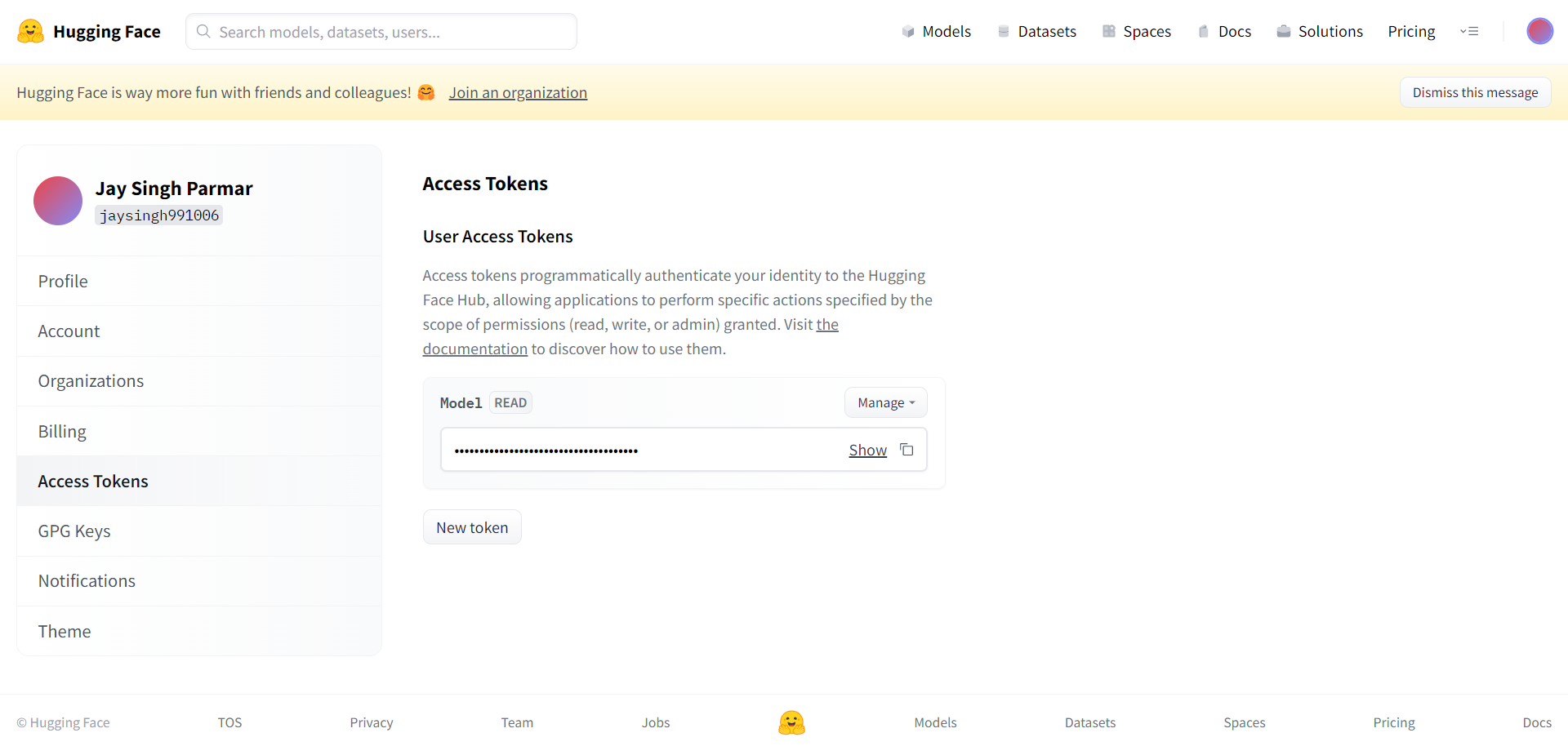
根据此处的请求创建令牌和名称。 应将令牌复制并粘贴到下方单元格中的 Google 协作中。

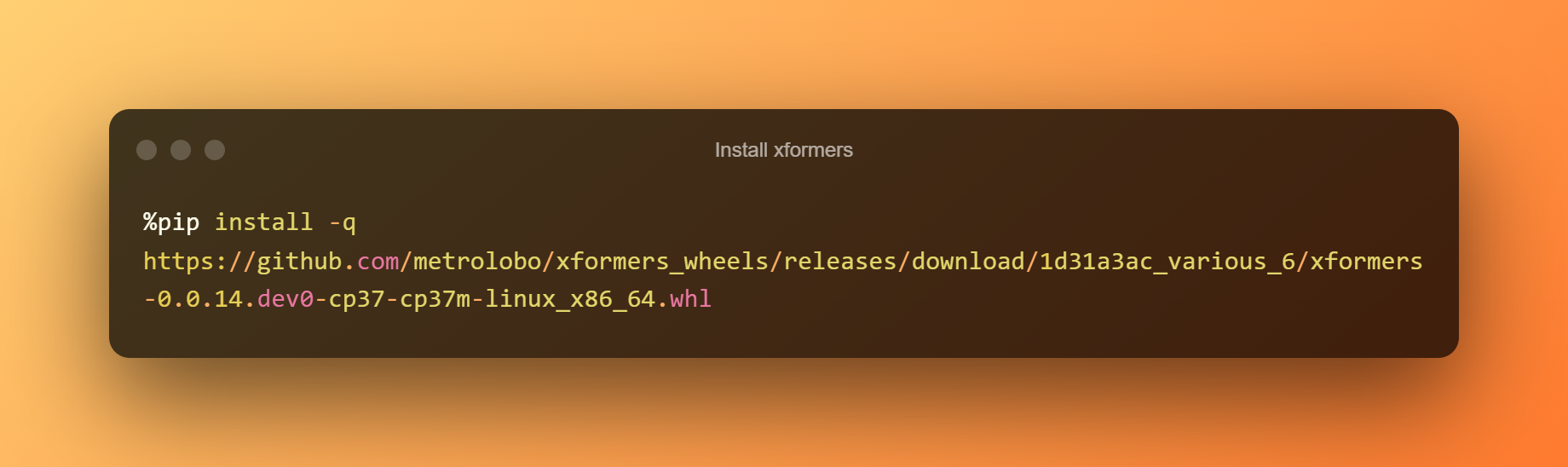
安装 xformers
在这个阶段,您可以通过单击运行时简单地按下播放按钮来安装 xformers。
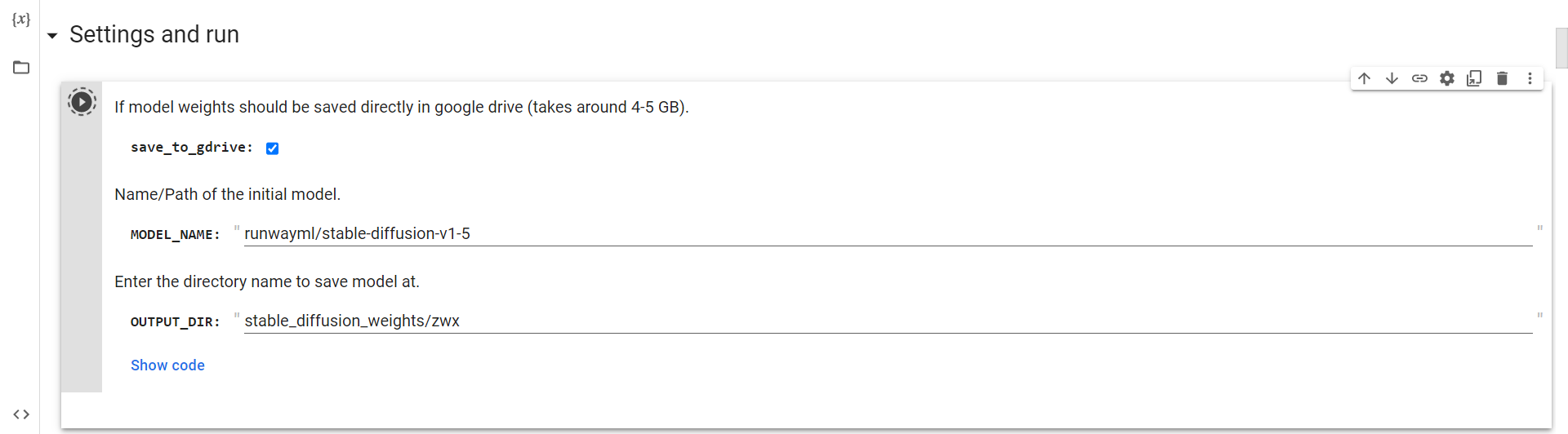
连接到云端硬盘
现在,你只需要运行这个单元来连接到谷歌驱动器。
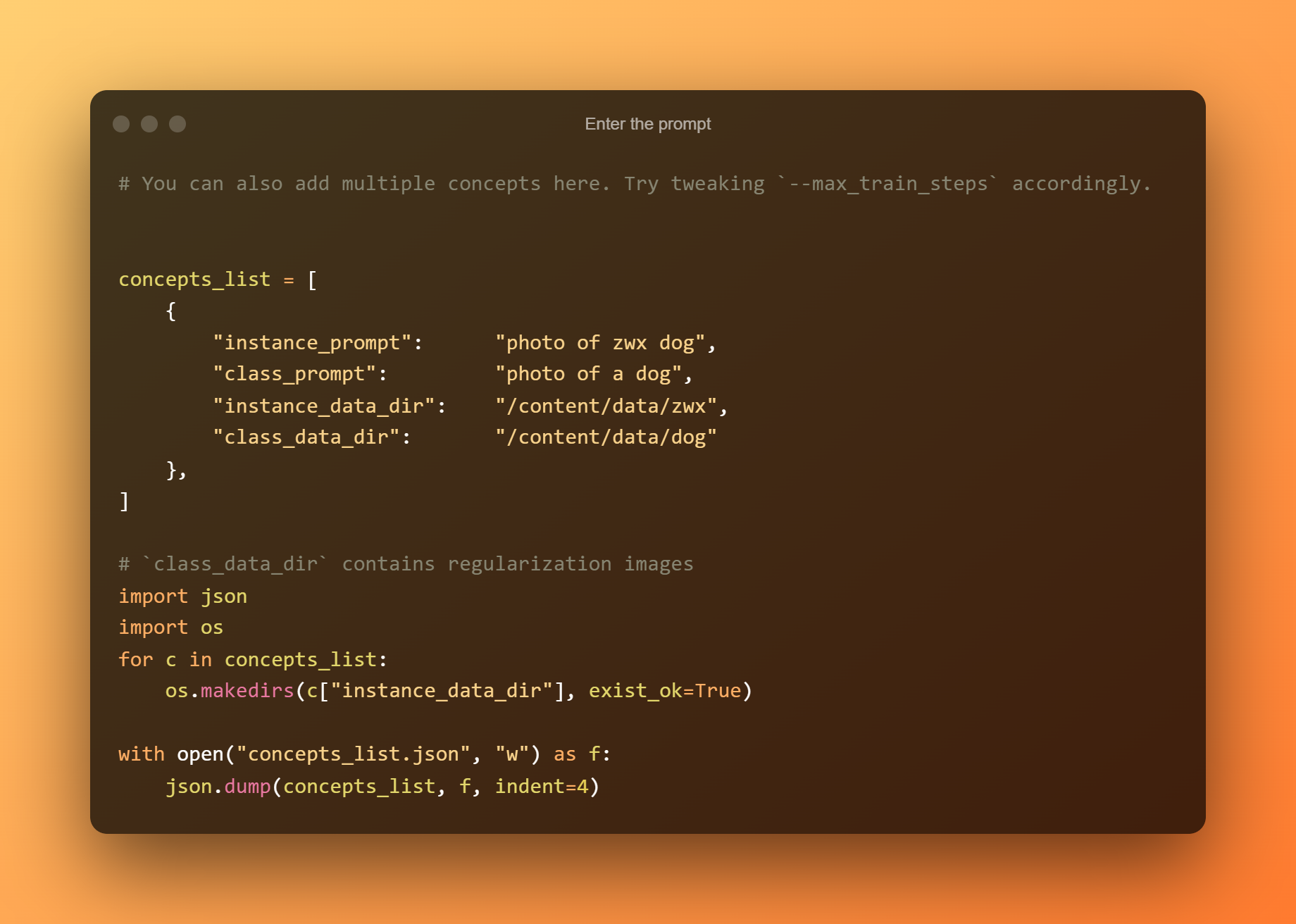
输入提示
在以下单元格中,您只需输入提示。
上传图片
在这一步中,您只需上传您想要训练的图片。

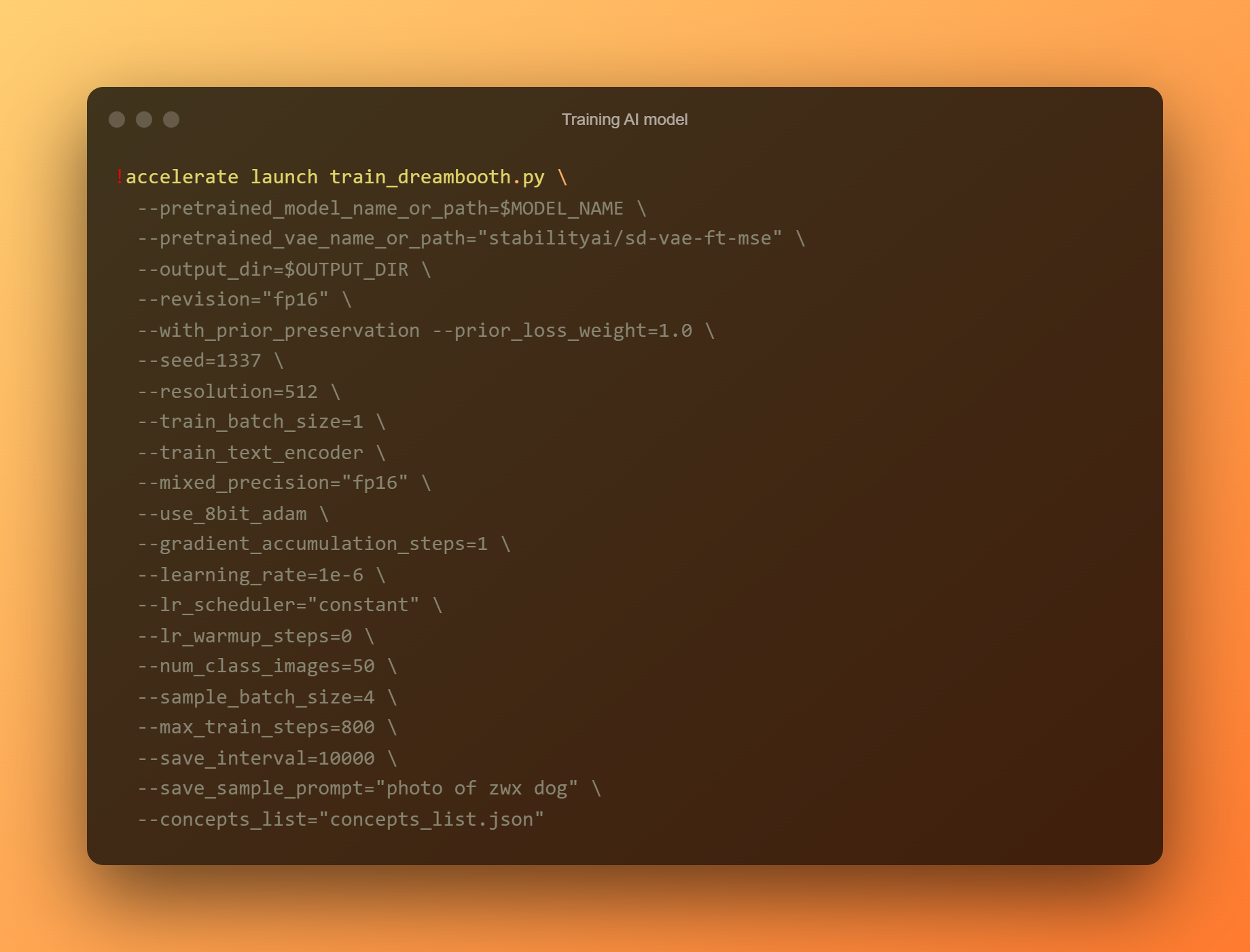
训练 AI 模型
这是最重要的阶段,因为您将使用 DreamBooth 根据您提交的所有参考照片训练一个新的 AI 模型。 您必须将注意力限制在两个输入字段上。 “——实例提示”是第一个参数。 您必须在此处提供一个高度不同的名称。
'–concept list' 参数是第二个关键输入字段。 它必须重命名以匹配“更改提示”部分中使用的名称。
生成 AI 图像
AI图片将在此阶段创建,您可以在其中输入文字说明。

Dreambooth 限制
- 命令提示符成为在具有高度细节的主题中进行迭代的障碍。 DreamBooth 可以更改主题的上下文,但如果模型希望更改主题本身,则框架存在问题。
- 另一个问题是将输出图片过度拟合到输入图像。 如果没有提供足够的图片,则可能不会考虑该主题,或者可能会与提交的图像的上下文混合。 当询问奇数代的上下文时,会发生同样的事情。
结论
为了从单个文本输入生成输出,大量文本到图像模型需要数百万个参数和库。
DreamBooth 只需输入三到五张主题照片和文字背景,即可为消费者简化内容获取和使用。





发表评论