令人欣慰的是,我们已经成功地让机器人具备了通过榜样学习和感知周围环境的与生俱来的能力。 根本的挑战是那些教计算机像人类一样“看”的人需要更多的时间和精力。
但是,当我们考虑到这项技能目前为组织和企业提供的实用价值时,这种努力是值得的。 在本文中,您将了解图像分类、它的工作原理及其实际实现。 让我们开始。
什么是图像分类?
将图像输入到 神经网络 并让它为该图片输出某种形式的标签称为图像识别。 网络的输出标签将对应于预定义的类。
可能有许多类分配给图片,或者只是一个。 当只有一个类时,经常使用“识别”一词,而当有多个类时,则经常使用“分类”一词。
物体检测 是图片分类的一个子集,其中对象的特定实例被检测为属于给定类别,例如动物、车辆或人类。
图像分类是如何工作的?
计算机分析像素形式的图像。 它通过将图片视为矩阵的集合来实现这一点,矩阵的大小由图像分辨率决定。 简单地说,图片分类是从计算机的角度利用算法研究统计数据。
图像分类是在数字图像处理中通过将像素分组到预定的组或“类”来完成的。 该算法将图像划分为一系列值得注意的特征,从而减轻了最终分类器的负担。
这些品质使分类器了解图像的含义和潜在的分类。 因为图片分类的其余过程都依赖于它,所以特征提取方法是最关键的阶段。
提供的数据 该算法在图像分类中也很重要,尤其是监督分类。 与基于类别的数据不平衡以及低图片和注释质量的糟糕数据集相比,优化良好的分类数据集表现出色。
在 python 中使用 Tensorflow 和 Keras 进行图像分类
我们将使用 CIFAR-10 数据集(包括飞机、飞机、鸟类和其他 7 种事物)。
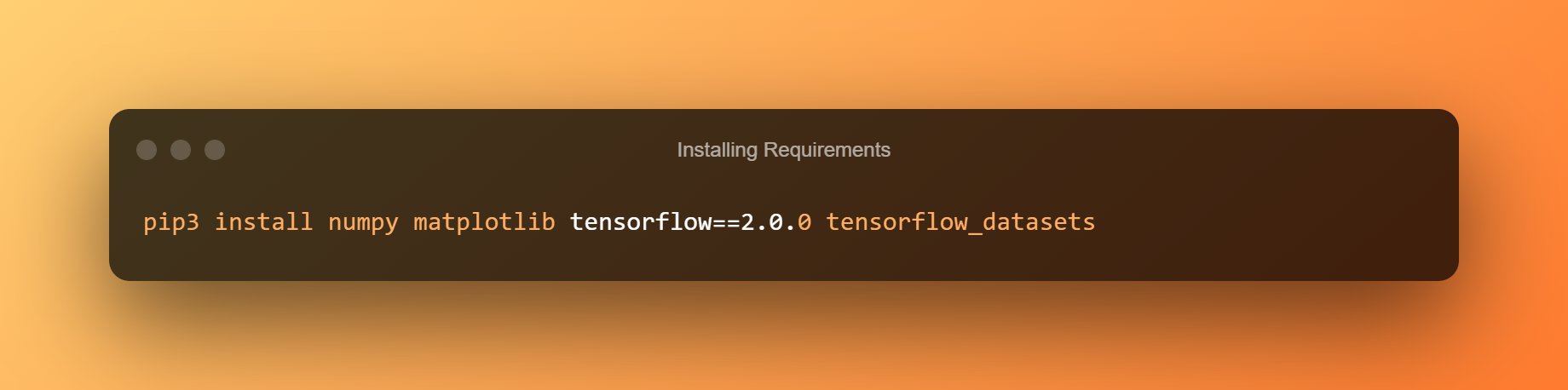
1. 安装要求
下面的代码将安装所有先决条件。
2. 导入依赖
在 Python 中创建一个 train.py 文件。 下面的代码将导入 TensorFlow 和 Keras 依赖项。

3. 初始化参数
CIFAR-10 仅包含 10 个图片类别,因此 num classes 仅指要分类的类别数量。

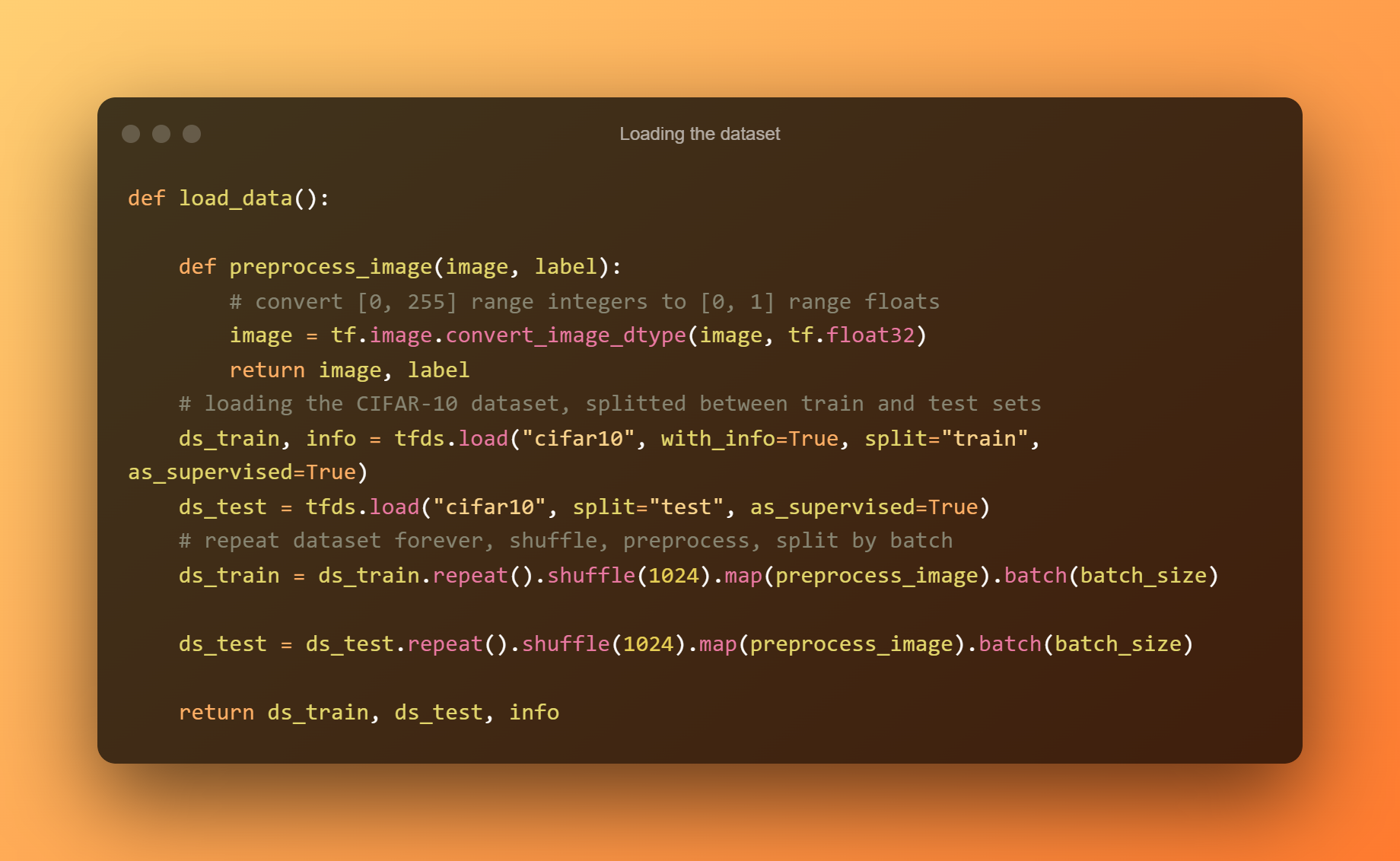
4. 加载数据集
该函数使用 TensorFlow Datasets 模块加载数据集,我们将 with info 设置为 True 以获取有关它的一些信息。 您可以将其打印出来以查看哪些字段及其值,我们将使用该信息来检索训练和测试集中的样本数量。
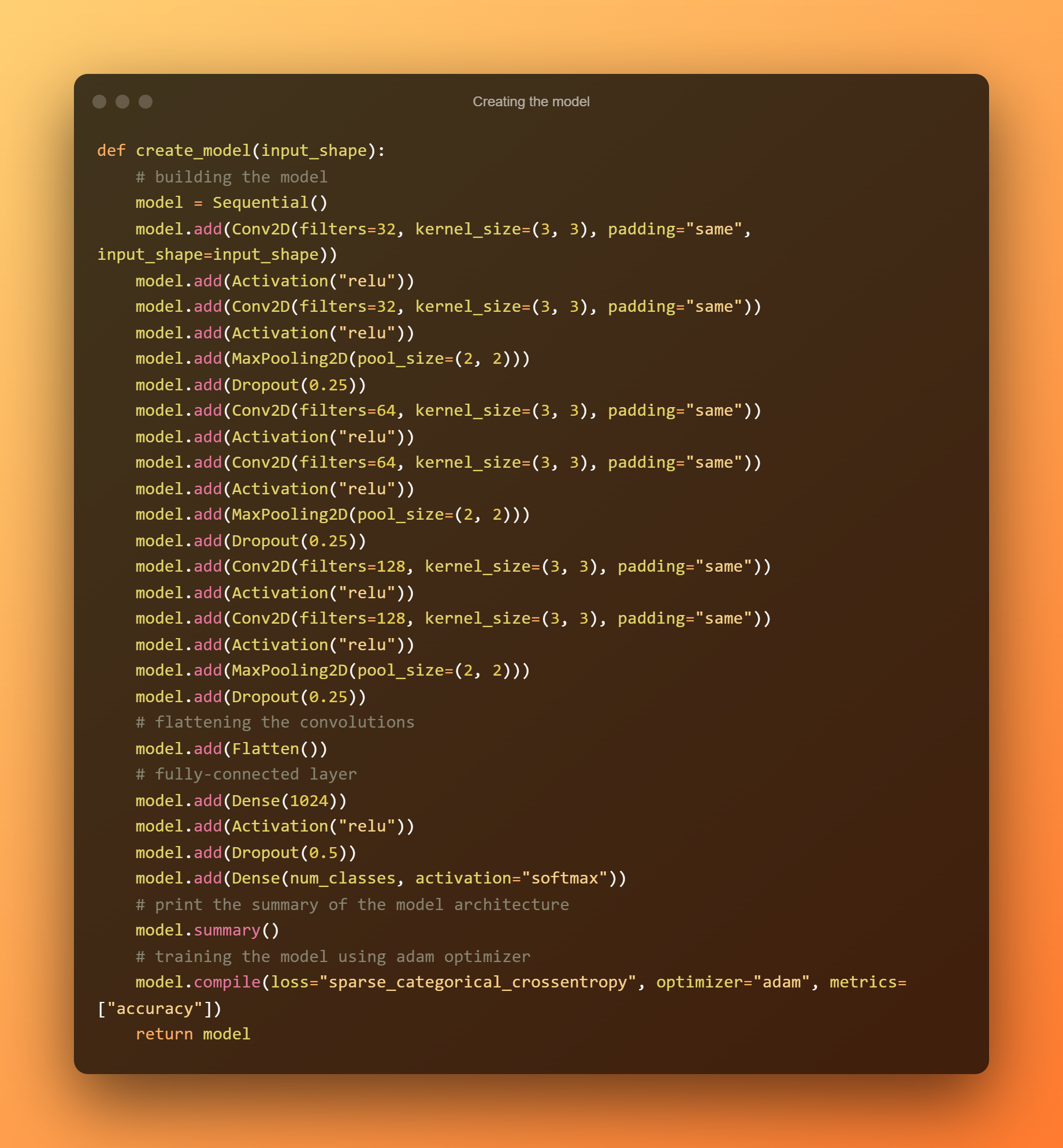
5. 创建模型
现在我们将构建三层,每层由两个具有最大池和 ReLU 激活功能的 ConvNet 组成,然后是一个完全连接的 1024 单元系统。 与最先进的模型 ResNet50 或 Xception 相比,这可能是一个相对较小的模型。
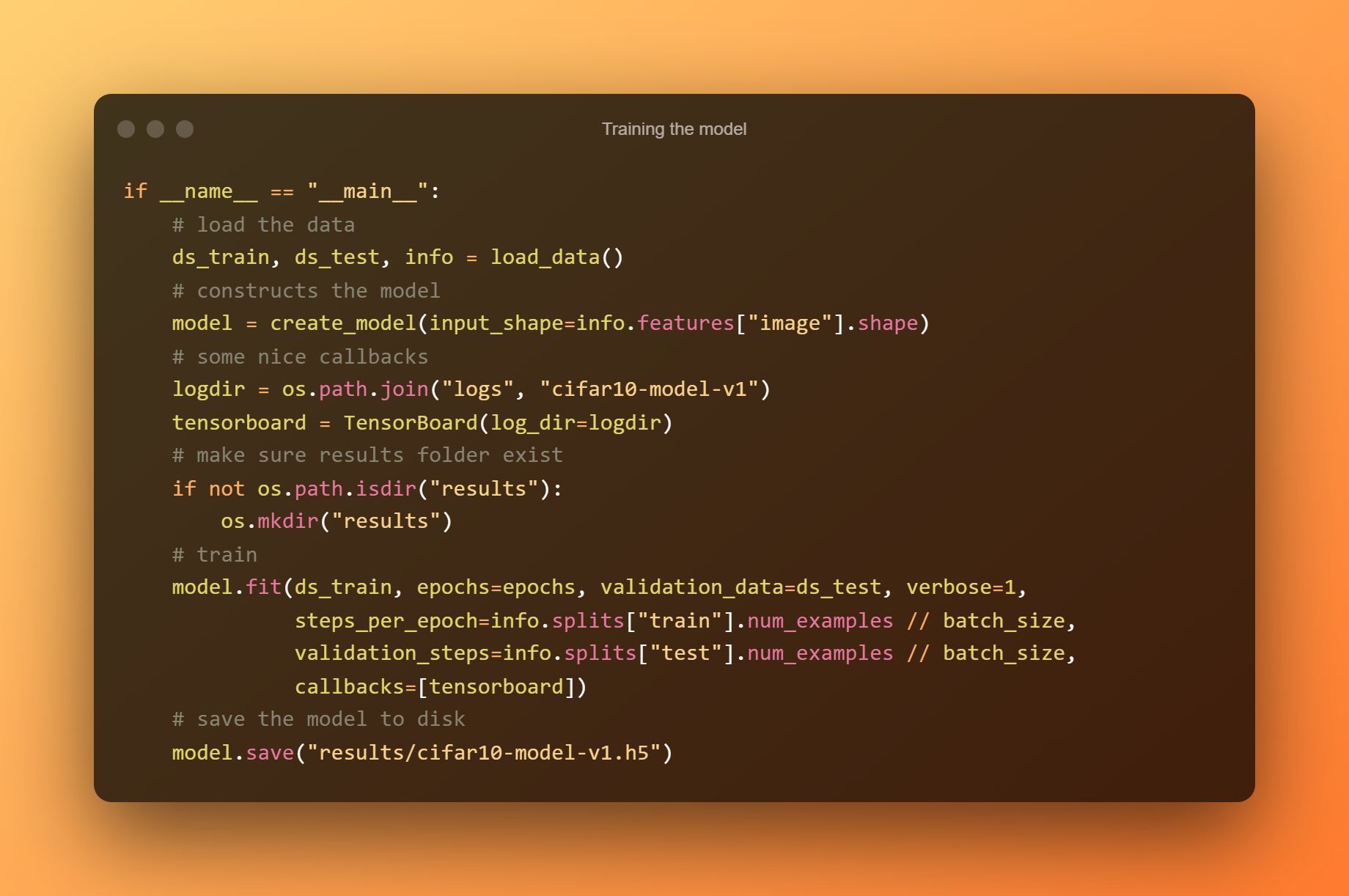
6. 训练模型
我使用 Tensorboard 测量每个 epoch 的准确率和损失,并在导入数据和生成模型后为我们提供漂亮的显示。 运行以下代码; 根据您的 CPU/GPU,训练将需要几分钟时间。
要使用 tensorboard,只需在终端或当前目录的命令提示符下键入以下命令:
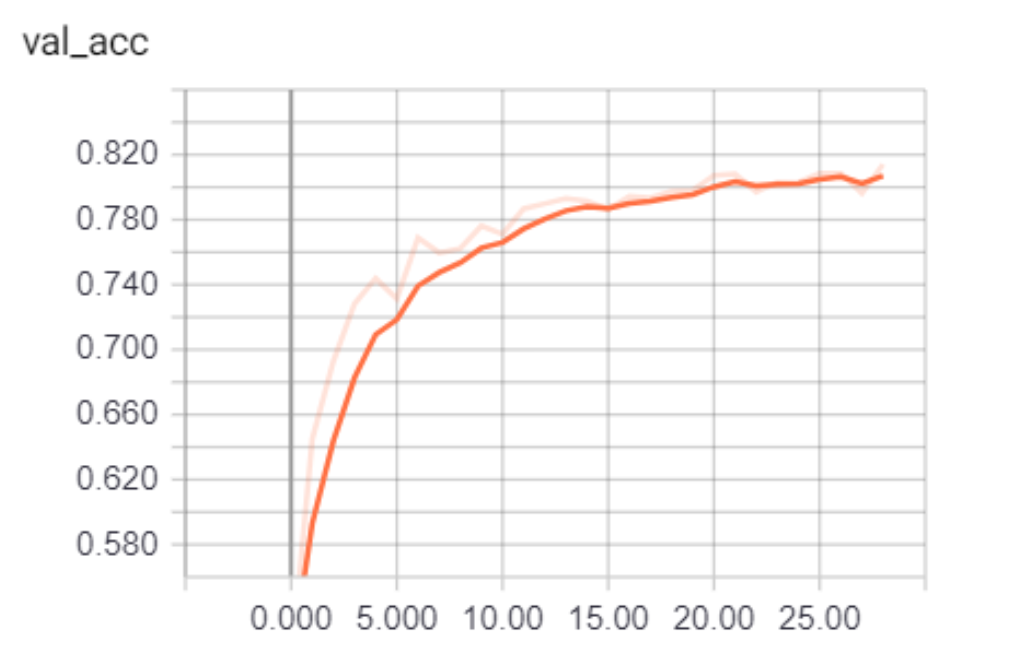
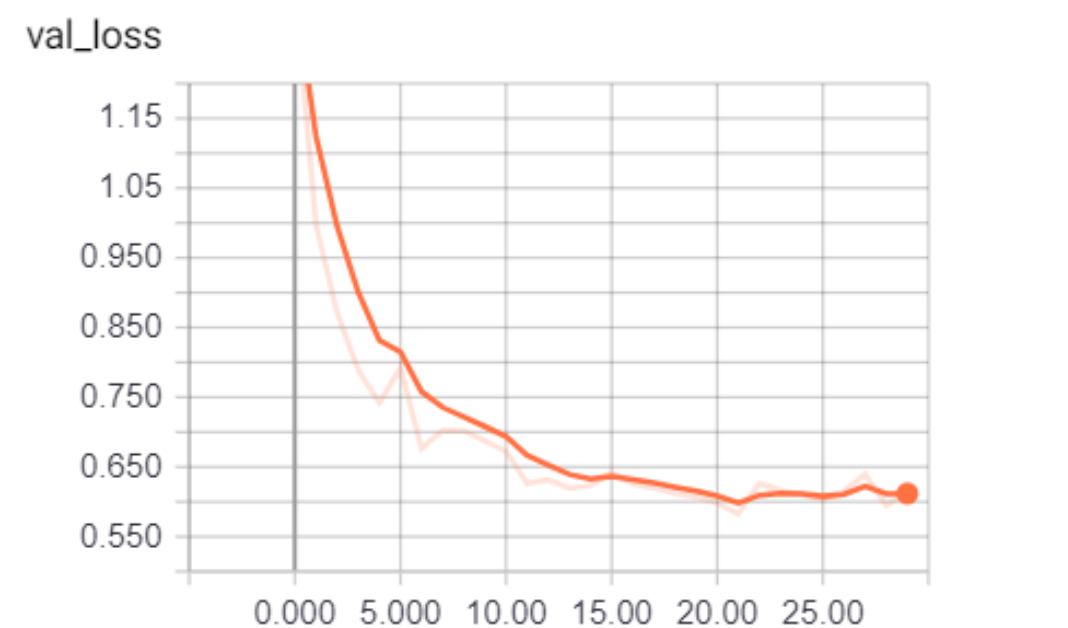
您会看到验证损失正在减少,准确率上升到大约 81%。 这太妙了!
测试模型
训练完成后,最终的模型和权重保存在结果文件夹中,允许我们训练一次并随时进行预测。 遵循名为 test.py 的新 python 文件中的代码。
7. 导入实用程序进行测试

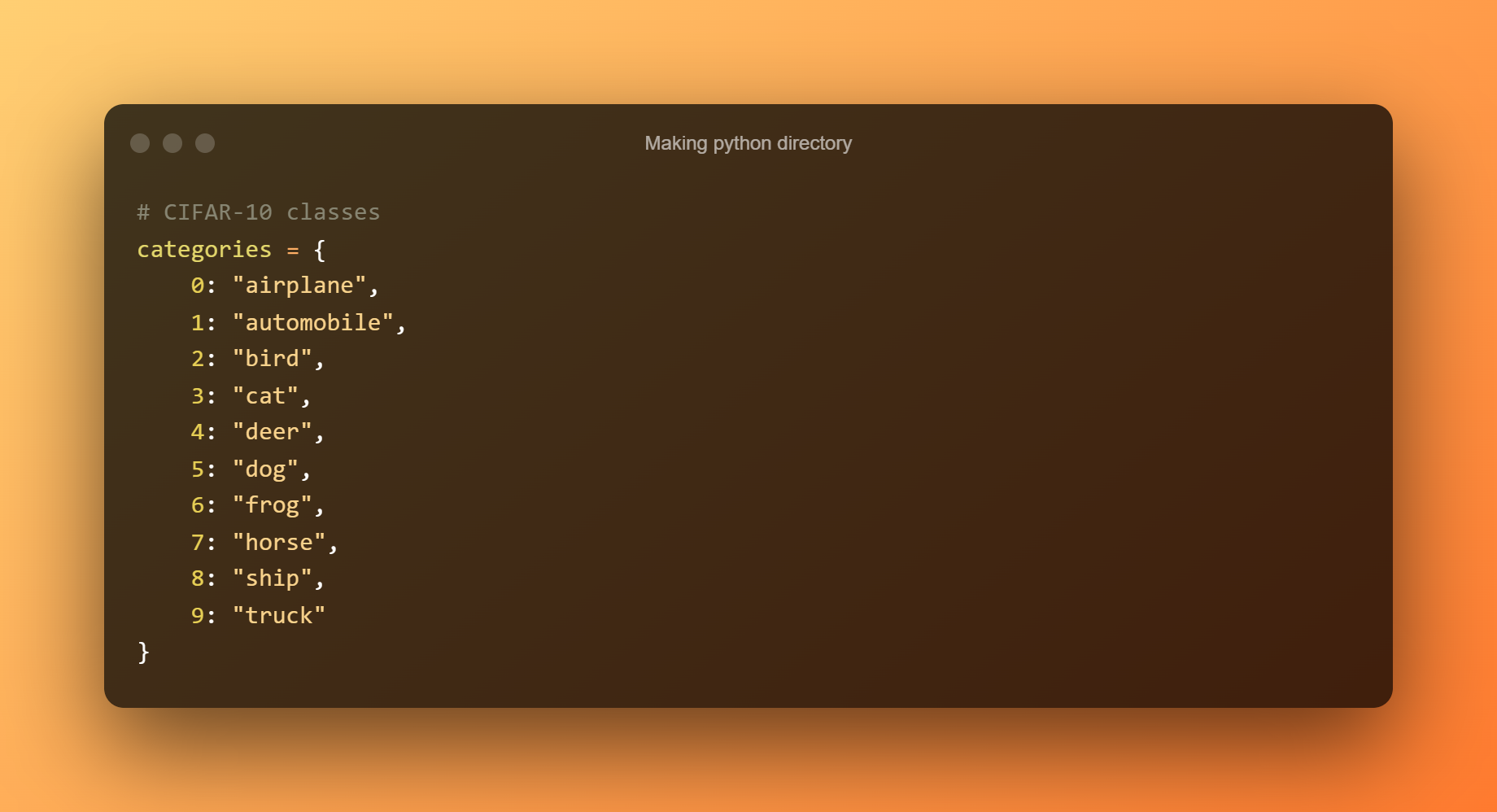
8.制作python目录
制作一个 Python 字典,将每个整数值转换为数据集的相应标签:
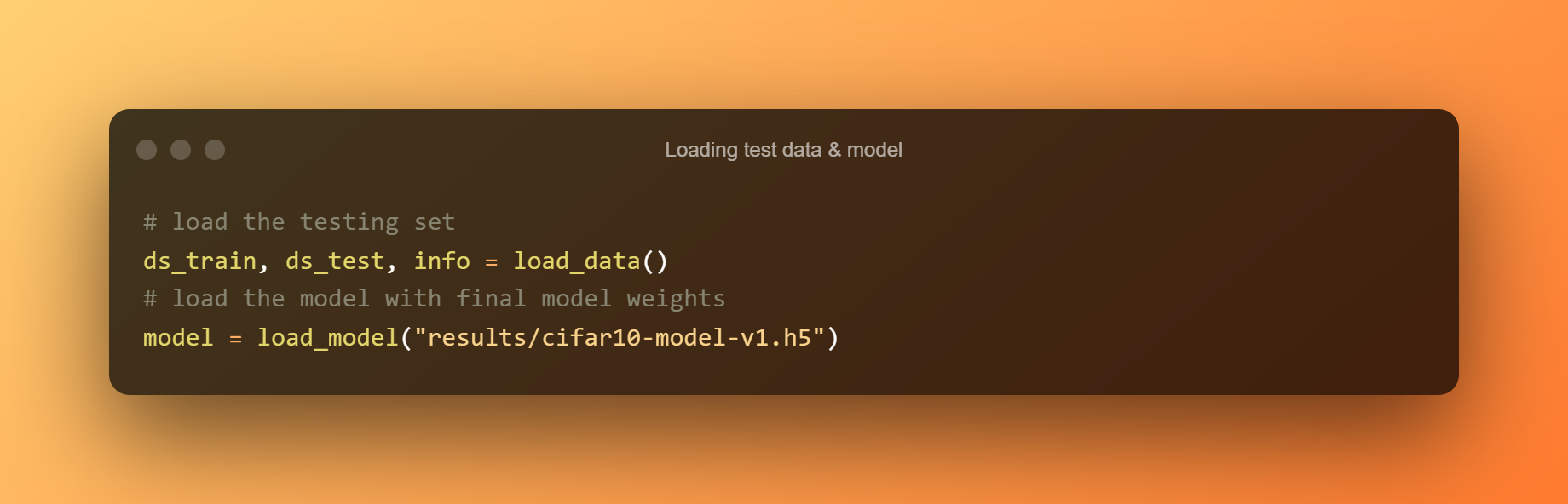
9.加载测试数据和模型
以下代码将加载测试数据和模型。
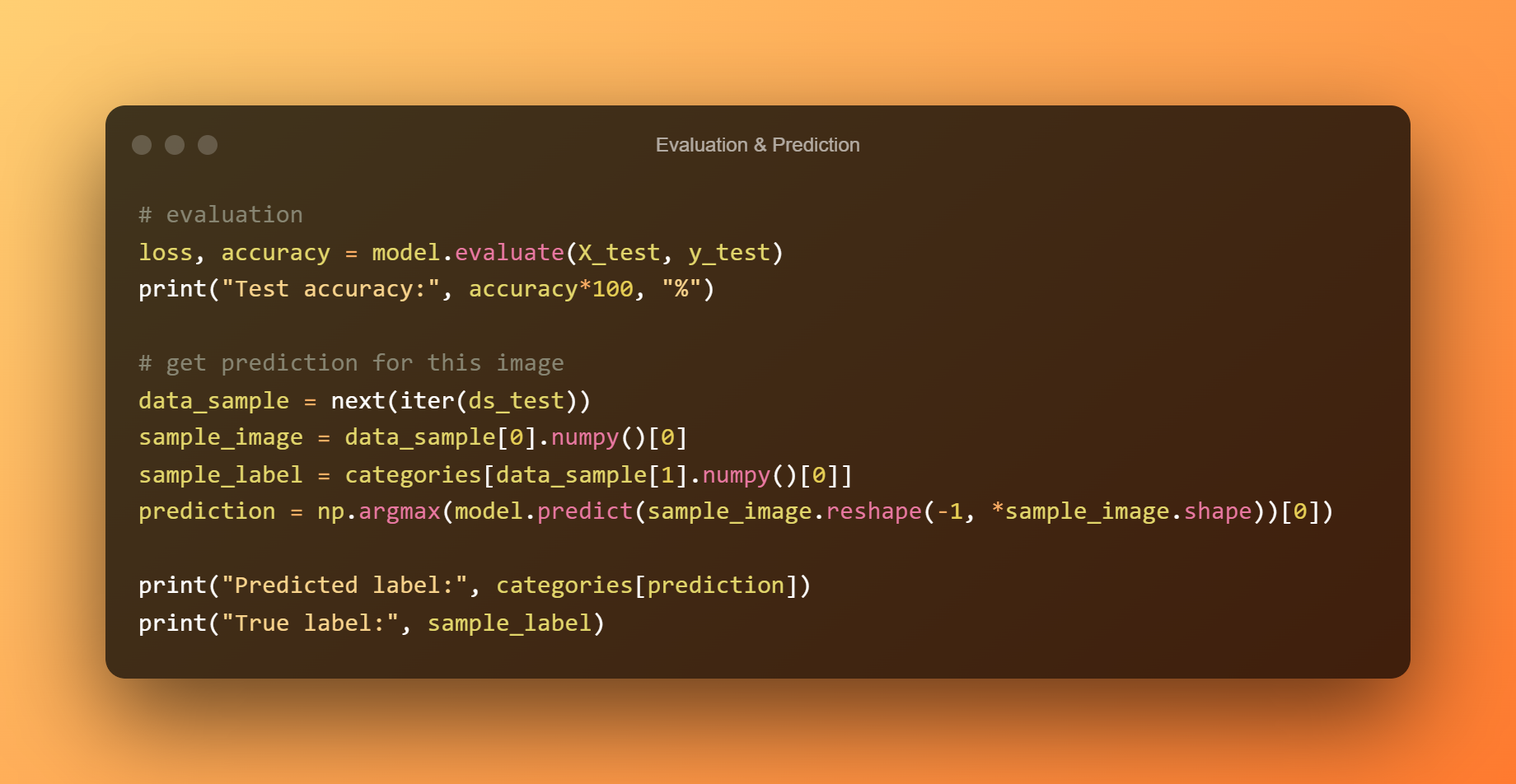
10. 评估与预测
以下代码将对青蛙图像进行评估和预测。
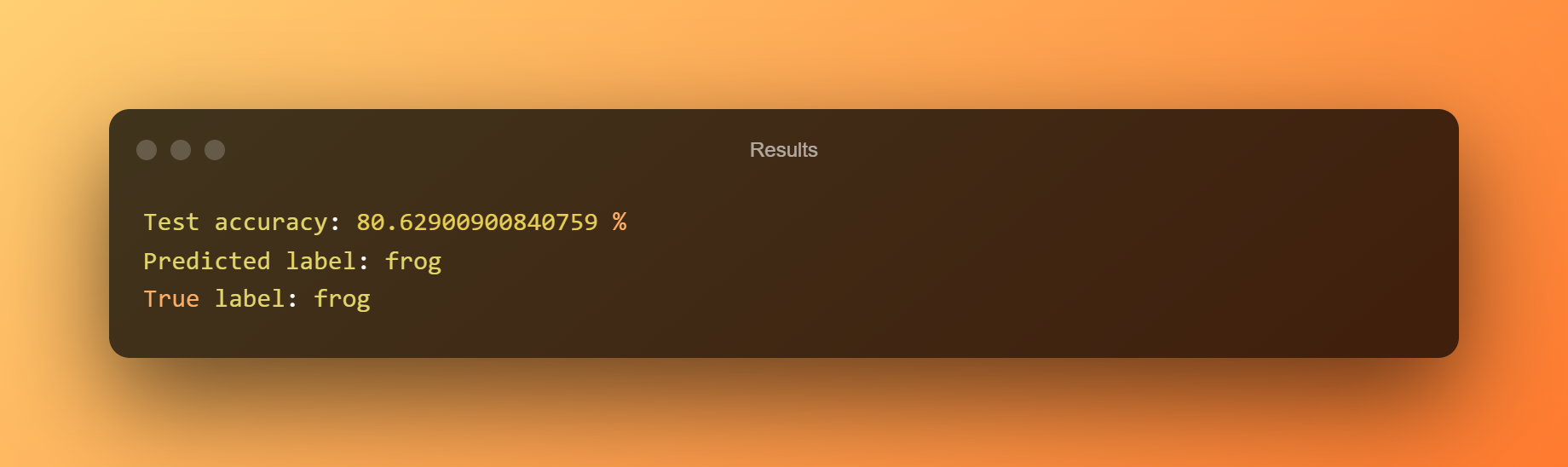
11。 结果
该模型以 80.62% 的准确率预测青蛙。
结论
好的,我们完成了这一课。 虽然 80.62% 对小 CNN 来说并不好,但我强烈建议您更改模型或查看 ResNet50、Xception 或其他尖端模型以获得更好的结果。
现在您已经在 Keras 中构建了您的第一个图像识别网络,您应该对模型进行试验,以了解不同的参数如何影响其性能。





发表评论