У сучасному суспільстві, що керується даними, веб-скрейпінг став ключовим методом отримання глибоких даних з інтернет-платформ.
Будучи надзвичайно популярним сайтом соціальних мереж, Instagram надає багато матеріалів, створених користувачами. І ці згенеровані дані можна використовувати для маркетингу, досліджень та інших цілей.
Користувачі можуть легко та ефективно витягувати дані з Instagram завдяки багатофункціональним інструментам Instagram від Bright Data, провідним веб-вискоблювання інструмент. У цій публікації ми докладно, покроково розповімо про процес копіювання Instagram.
Отже, давайте подивимося кроки, як ми можемо очищати дані з Instagram.
Розуміння Instagram скребків з Bright Data
За допомогою двох універсальних веб-скребків і попередньо скомпільованого набору даних Bright Data надає різноманітні сервіси для збирання даних в Instagram. Ці технології пропонують універсальність у вилученні даних і адаптуються до різних вимог.
Розглянемо кожен із цих варіантів докладніше:
a. Браузер для сканування
Інноваційна технологія, відома як Scraping Browser, була створена для задоволення вимог проектів зі збирання даних. Він пропонує все необхідне для сканування в масштабі в одному браузері. Він виділяється завдяки інтегрованій автоматизації розблокування веб-сайтів, що робить його єдиним браузером такого роду в усьому світі.
Scraping Browser надає користувачам доступ до надійних функцій, які виходять за межі автоматизованих і безголових браузерів, дозволяючи їм вийти за межі навіть найскладніших сценаріїв і веб-сайтів, які перешкоджають виявленню ботів.
Збирання даних є більш ефективним і безпроблемним завдяки функціям автоматичного налаштування, які легко керують новими блоками, рішеннями CAPTCHA, відбитками пальців і повторними спробами, а також відображаються як справжній користувач.
Використання ШІ, щоб перехитрити системи виявлення ботів
Використовуючи передову технологію штучного інтелекту, Scraping Browser може перехитрити системи виявлення ботів і постійно адаптуватися до їхніх змінних стратегій. Для кращого розблокування веб-сторінок Scraping Browser вчиться на спробах цих систем виявляти та блокувати спроби сканування та відповідним чином змінює свою поведінку.
Він перевершує ефективність звичайних проксі-серверів, імітуючи поведінку браузера, який використовує реальний користувач. Як наслідок, клієнти можуть зосередитися на своїх цілях щодо збирання даних, не стикаючись із труднощами та витратами на поточні процедури виявлення ботів.
b. Web Scraper IDE
Надійний інструмент веб-скрапінгу, створений для розробників, Web Scraper IDE може виконувати складні завдання скрапінгу. Це значно скорочує час розробки, забезпечуючи необмежену масштабованість завдяки повністю розміщеному рішенню та попередньо вбудованим функціям копіювання. Програма дає змогу швидко та масштабовано створювати онлайн-скребки, надаючи шаблони коду та готові функції JavaScript із популярних веб-сайтів.
Все необхідне для успішного веб-збирання надає IDE Web Scraper. Це комплексне рішення для вилучення даних в Інтернеті, оскільки параметри інтеграції дозволяють клієнтам планувати сканування або запускати їх через API та зв’язувати з основними системами зберігання.
Як ним користуватися? – Підручник
Спочатку перейдіть на інформаційну панель користувача на веб-сайті.

Давайте почнемо з наших кроків, щоб очистити Instagram.
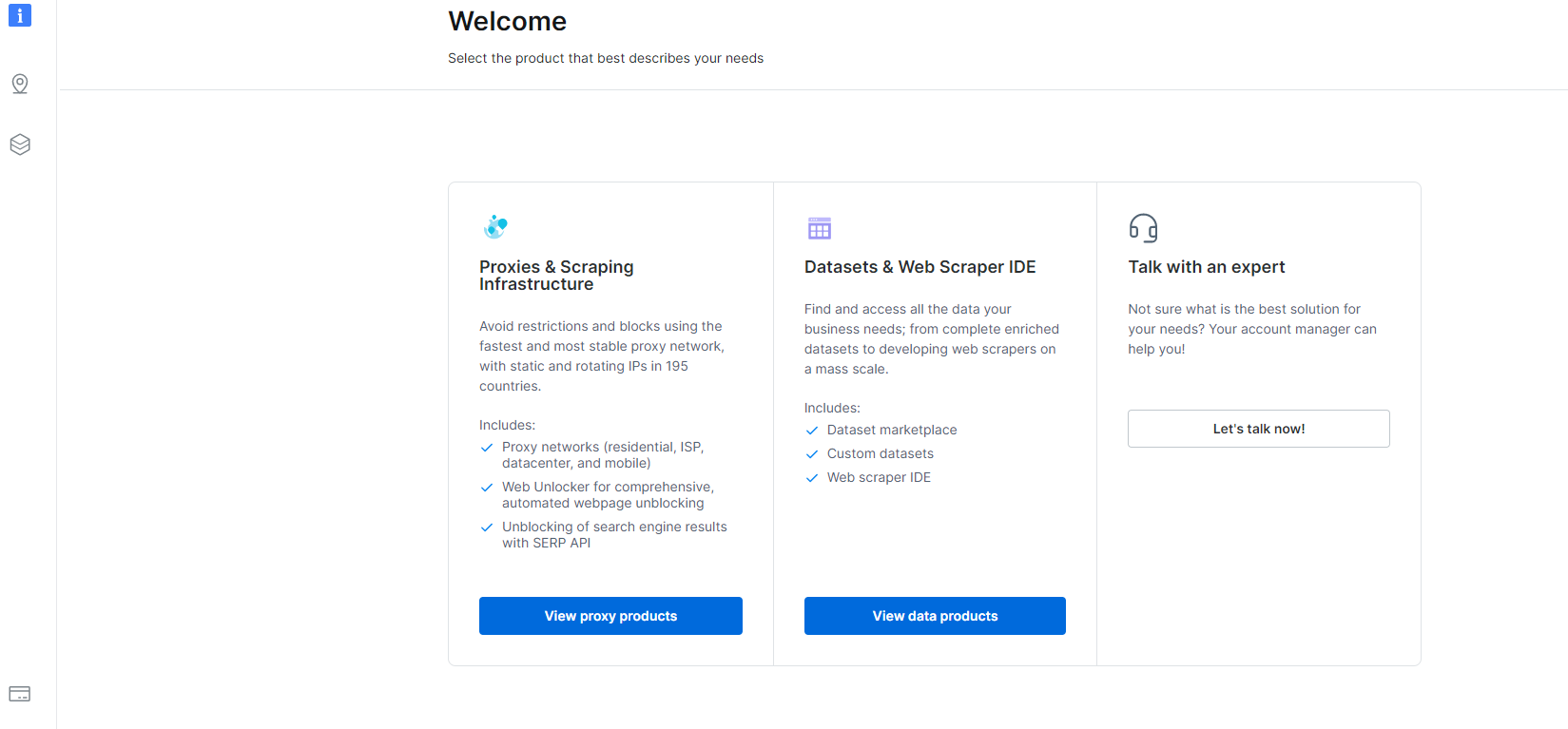
1- Перейдіть до Інформаційна панель і натисніть розділ Datasets & Web Scraper IDE.
2- Коли ви там, натисніть «Мої скребки».
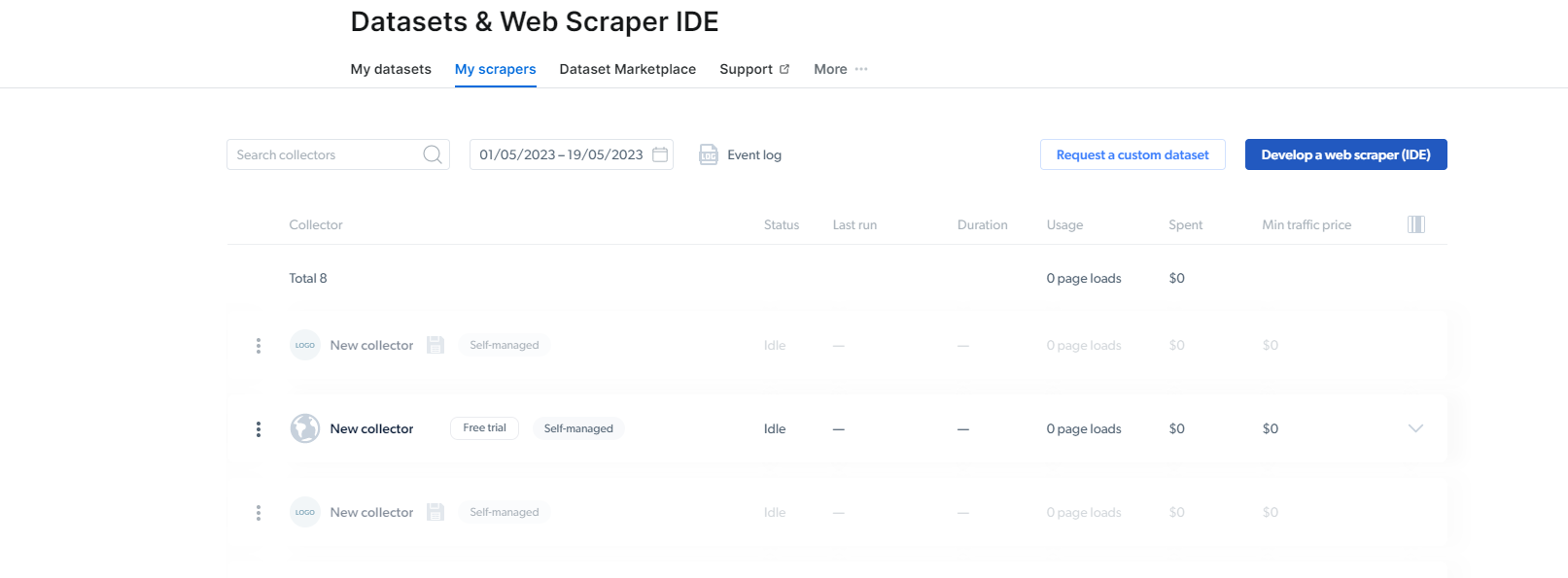
Тут вам потрібно натиснути «Розробити веб-скребок (IDE)». Тут ми створимо наш скребок для Instagram.
3-Тепер нам потрібно розробити новий веб-скребок. Лише для цього прикладу я вирішив скинути обліковий запис «NASA». Це лише для прикладу.
Отже, мій код виглядатиме так:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Вам потрібно натиснути кнопку «відтворити» у верхньому правому куті, щоб запустити цей код.
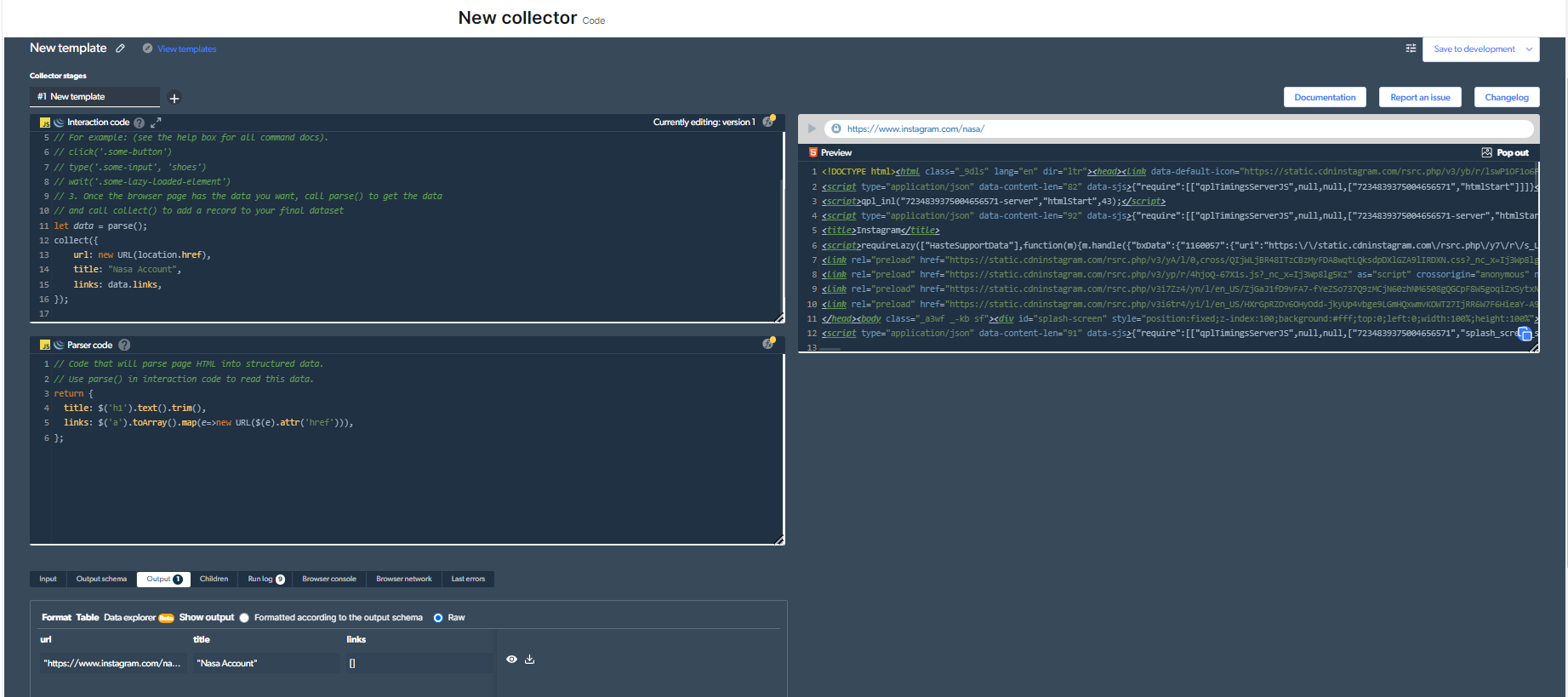
4- Тепер у нас буде результат.
Управління проблемами зіскрібання
Публікації в Instagram із кнопкою «показати більше» може бути складно зафіксувати скребками. Однак скребки Instagram від Bright Data створені, щоб успішно справлятися з такою складністю. Ці скребки володіють передовими навичками проходження сторінок і завантаження додаткових кнопок.
Інстаграм-скребки Bright Data ефективно справляються з цими труднощами, щоб забезпечити ретельний витяг даних, дозволяючи вам зібрати всю колекцію інформації, необхідної для аналізу чи дослідження.
Ви можете обійти проблеми, пов’язані з динамічною природою публікацій в Instagram, використовуючи ці інструменти копіювання.
c. Попередньо зібраний набір даних
Bright Data розуміє, що не кожен хоче запускати свій скрепер. Вони надають попередньо зібраний набір даних для Instagram, щоб звернути увагу на таких споживачів.
Цей набір даних пропонує велику кількість корисної інформації, такої як підписники, профілі, публікації тощо.
Bright Data пропонує параметри налаштування, щоб персоналізувати набір даних відповідно до ваших потреб, незалежно від того, чи потрібен вам цілий набір даних чи піднабір спеціалізованих даних. Цей підхід уникає створення та керування скребком, надаючи вам готові до використання дані для аналізу та розуміння.
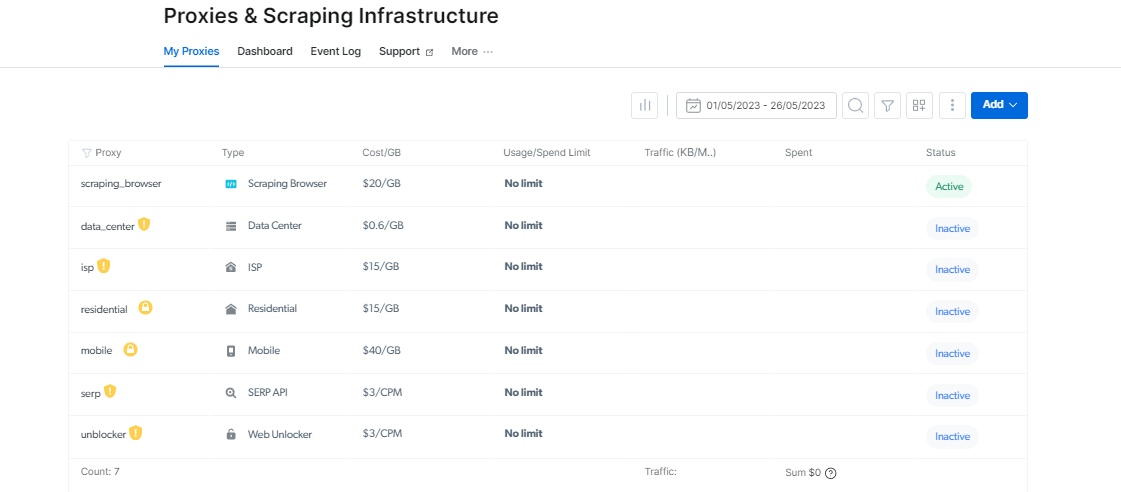
Тепер давайте перевіримо інфраструктуру, яка робить ці інструменти такими ефективними: інфраструктуру проксі та Web Unlocker.
Розкрийте силу проксі-серверів
використання проксі має вирішальне значення під час веб-збирання, щоб гарантувати, що ваші дії залишаться непоміченими.
Bright Data пропонує широкий вибір послуги проксі які налаштовані відповідно до ваших вимог. Ви можете вибрати з Житлові довіреності, які пропонують понад 72 мільйони IP-адрес, що обертаються з реальних однорангових пристроїв у 195 країнах.
Ви можете вибрати проксі-сервери ISP, які пропонують 700,000 770,000+ справжніх домашніх IP-адрес у всьому світі для довгострокового використання; Проксі центрів обробки даних, які мають 3 4+ спільних IP-адрес із будь-якого геолокації; і мобільні проксі-сервери, які утворюють найбільшу реальну однорангову мобільну мережу 7,000,000G/XNUMXG із XNUMX XNUMX XNUMX+ IP-адресами.
За допомогою цих проксі-серверів можна легко збирати дані, видаючи себе за авторизованого користувача в багатьох місцях.

Проксі-менеджер: спростіть керування проксі-сервером
Керувати декількома проксі-серверами може бути важко, але Proxy Manager полегшує це.
Цей інтерфейс із відкритим кодом дає змогу керувати всіма вашими проксі-серверами з однієї платформи. Попрощайтеся з ручним налаштуванням і перемиканням проксі-серверів. Проксі-менеджер спрощує процедуру та економить ваш час і зусилля.
Розширення проксі-браузера: легко змінюйте своє місцезнаходження
Вам потрібно збирати веб-дані з кількох регіонів? Ви охоплені нашим розширенням проксі-браузера. Ви можете змінити місце перегляду одним клацанням миші, щоб отримати інформацію про певний регіон.
Скористайтеся перевагами гнучкості та простоти збору даних із кількох регіонів без жодних технологічних ускладнень.
Як це працює? – Підручник
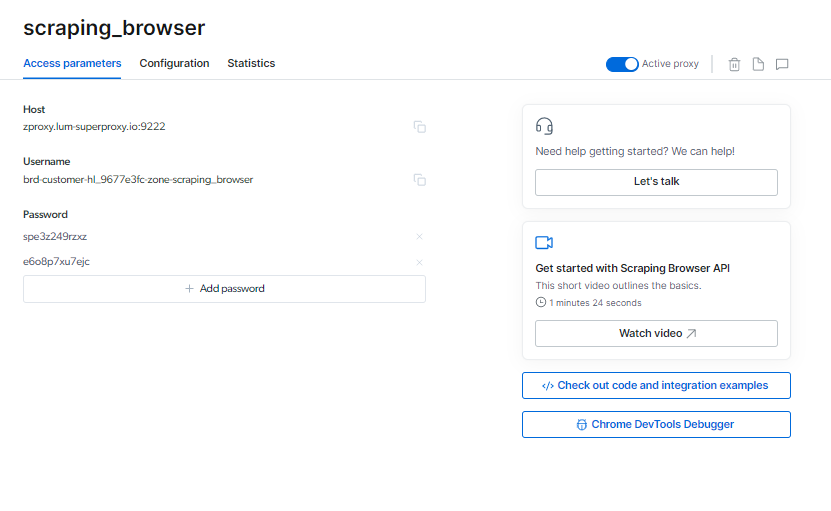
Ви можете знайти своє Браузер для сканування дані для входу на сторінці параметрів доступу, які використовуватимуться під час запуску нового сеансу браузера.
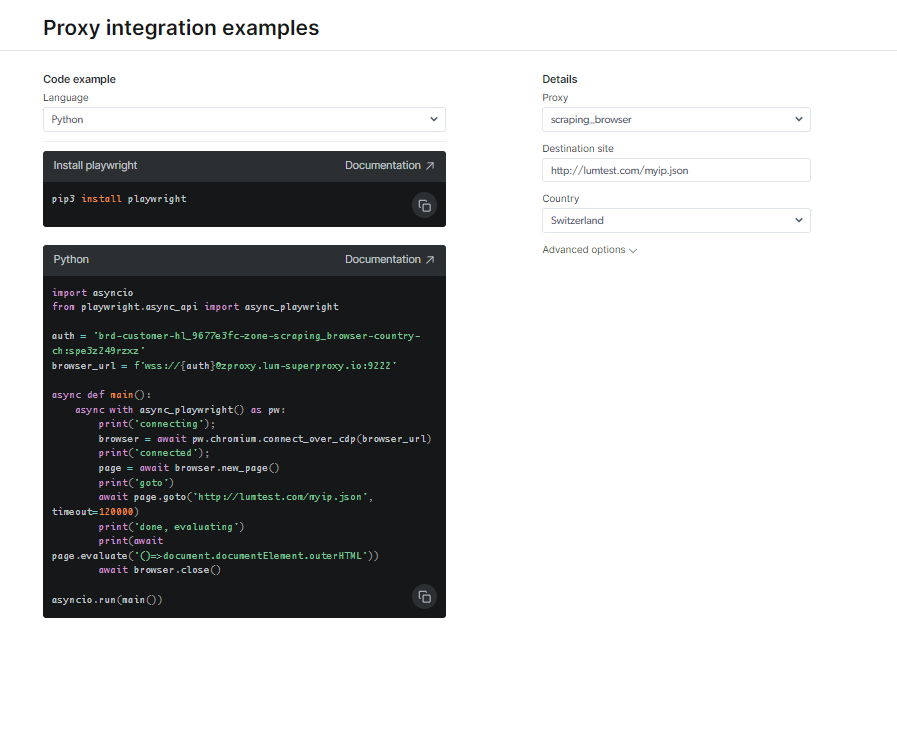
Ознайомтеся з документацією та зразками коду, включаючи повнофункціональний приклад сценарію, який готовий до використання, або подивіться коротке відео з інструкціями щодо початку роботи. Наприклад; ось а Код Python приклад інтеграції:
Потрібна допомога? Для розмови з одним із спеціалістів ви можете натиснути на значок чату.
Майте на увазі, що ви маєте повний контроль над сеансами браузера під час використання Scraping Browser і можете виконувати будь-які операції, які підтримуються Puppeteer, Playwright або прямим використанням протоколу Chrome DevTools.
Розблокування сайту без блокування
Браузер Scraping створено для роботи в масштабі та за потреби. Вам не потрібно турбуватися про те, що вас забанять; Ви можете запустити скільки завгодно сеансів браузера.
Ця потужність у поєднанні з потужністю проксі-серверів гарантує безперервний збір даних, що дозволяє ефективно отримувати потрібні дані.
Вбудовані навички розблокування Scraping Browser і надійна проксі-мережа допоможуть вам заощадити час, підвищити продуктивність і відкрити нові можливості.
Ви також можете перевірити статистику безпосередньо на тій же сторінці.
Ціни браузера Scraping
Bright Data пропонує настроювані ціни для різноманітних цілей. Ви можете вибрати місячний або річний розрахунковий період.
Опція Pay as You Go дозволяє платити лише за те, що ви використовуєте, без жодних зобов’язань, починаючи від 20.00 $/Гб і 0.1 $/год.
План зростання на суму 500 доларів США підходить для компаній, що розвиваються, зі зниженою оплатою 15.30 доларів США за ГБ і 0.1 долара США за годину.
Команда Бізнес пакет, який коштує 1000 доларів США, є найпопулярнішим варіантом, а Scraping Browser API коштує 13.50 доларів США за ГБ і 0.1 доларів США за годину.
Звернувшись безпосередньо до команди Bright Data, корпоративні користувачі можуть насолоджуватися безмежним масштабуванням і персоналізованим ціноутворенням. Розпочніть безкоштовну пробну версію сьогодні, щоб відкрити потенціал браузера сканування Bright Data і змінити свої зусилля онлайн-скрапування.
Розблокувальник веб-сайтів
Web Unlocker — це потужний інструмент, створений, щоб вийти за межі обмежень веб-сайту та забезпечити легкий збір даних. Він долає кілька проблем, включаючи файли cookie, агенти користувача веб-переглядача для певного сайту та рішення captcha, використовуючи автоматизовані процедури.
Використовуючи автоматичну ротацію IP-адрес, користувачі Web Unlocker можуть постійно сканувати цільові веб-сайти, забезпечуючи постійний доступ до важливих даних.
Покращення маршрутів запитів розробників
Кілька функцій роблять Web Unlocker популярним серед розробників. Програма спрощує процес збору даних шляхом автоматичного визначення агентів користувачів, необхідних для кожного веб-сайту, заощаджуючи дорогоцінний час і ресурси.
Web Unlocker адаптується в режимі реального часу, щоб уникнути виявлення у відповідь на постійні зміни стратегій, що використовуються блокуючими ботами, забезпечуючи безперервний доступ до цікавих веб-сайтів. Алгоритми машинного навчання платформи можуть швидко розпізнавати капчі, що є частою перешкодою для ініціатив зі збору даних.

Ціни на Web Unlocker
Починаючи з приблизно 2.03 доларів США за тисячу запитів (CPM), Web Unlocker пропонує різні варіанти цін для задоволення різноманітних вимог. Користувачам доступна 7-денна безкоштовна пробна версія, яка допоможе їм почати роботу та випробувати функції Web Unlocker перед тим, як почати.
Web Unlocker має можливість адаптації для підтримки різних шаблонів використання, незалежно від того, чи хочуть споживачі підхід із оплатою за використання, чи потрібен індивідуальний план, який відповідає їхнім конкретним вимогам. Крім того, ті, хто обирає довгострокові тарифні плани, можуть заощадити 32%.
Порівняння Web Unlocker із самокерованими проксі-серверами
Web Unlocker пропонує численні миттєві переваги в порівнянні з самокерованими проксі-серверами. Для плавної реалізації він пропонує розширену техніку інтеграції, яка поєднує функції суперпроксі та менеджера проксі. Користувачі можуть ефективно розширювати свої операції зі збору даних за допомогою нескінченної кількості одночасних підключень.
Web Unlocker забезпечує автоматичне розблокування, перевіряє CAPTCHA та успішно керує змінами розмітки на цільових веб-сайтах.
Платформа гарантує безперервне та надійне вилучення даних шляхом впровадження системи автоматичного повторення та здійснення асинхронних викликів для певних доменів. Крім того, зростаюча колекція запитів HTTP-заголовків, специфічних для веб-переглядача файлів cookie та імітованих гаджетів онлайнового Unlocker дозволяє користувачам залишатися непоміченими, надаючи їм змогу отримувати онлайн-дані в режимі реального часу.
Останні думки та важливі речі, які слід пам’ятати
Нарешті, використовуючи Bright Data для аналізу Instagram, дуже важливо мати на увазі кілька важливих моментів.
Зверніть увагу, що їхні можливості збирання обмежені загальнодоступними даними відповідно до етичних правил.
Ви завжди повинні дотримуватися умов обслуговування та політики конфіденційності Instagram. Збирання має здійснюватися етично та відповідально, не втручаючись у права користувачів і не порушуючи жодних законів.
По-друге, регулярно оновлюйте та налаштовуйте параметри збирання, щоб забезпечити точність і релевантність отриманих даних. Платформа та алгоритми Instagram можуть змінюватися, тому ви повинні відповідно змінити свої стратегії копіювання.
Нарешті, скористайтеся довідкою та ресурсами платформи Bright Data, щоб оптимізувати успіх своїх зусиль зі збирання Instagram. Скористайтеся їхньою документацією, навчальними посібниками та службою підтримки клієнтів, щоб покращити свої знання про їхні інструменти для збирання.
Ви можете отримати корисну інформацію, вплинути на прийняття мудрих рішень і досягти успіху в своїх ініціативах, що керуються даними, на платформі Instagram, дотримуючись цих найкращих практик і використовуючи переваги можливостей копіювання Instagram Bright Data.





залишити коментар