విషయ సూచిక[దాచు][చూపండి]
మీ చుట్టూ ఉన్న ప్రతిచోటా డేటా ఉంటుంది. నిజమైన కోణంలో, ఇది మీ వ్యాపారంలోని ప్రతి అంశాన్ని ప్రభావితం చేస్తుంది. మీరు మీ డేటాను ఎలా నిర్వహించాలనే దానిపై నిర్ణయాలతో నిమగ్నమై ఉన్నప్పుడు మీ వ్యాపారానికి ఎంతమేరకు సేవలందిస్తున్నారనే దాని ప్రత్యేకతలను పరిశీలించడానికి తగినంత సమయం లేనట్లు అనిపించవచ్చు.
ఇది గమనించండి. మీ సంస్థ రోజులో 24 గంటలు డేటాను ఉపయోగిస్తోంది. కాబట్టి అది ఎక్కడ నుండి వచ్చింది, అది ఎలా వచ్చింది మరియు కంపెనీ ద్వారా ఎలా కదులుతుందో అర్థం చేసుకోవడం దాని విలువను అర్థం చేసుకోవడంలో కీలకం.
ఈ పరిస్థితిలో డేటా వంశం ముఖ్యమైనది. డేటా యొక్క మూలాలు, వలసలు మరియు మార్పులను ట్రాక్ చేయగలిగినప్పుడు డేటా ఎలా ఏర్పడింది, అది ఎక్కడ నుండి వచ్చింది మరియు అది ఎక్కడికి వెళుతుందో అర్థం చేసుకోవడం సులభం.
ఈ పోస్ట్లో, మేము డేటా లినేజ్, ఇది ఎలా పని చేస్తుంది, దాని వినియోగ సందర్భాలు, పద్ధతులు మరియు మరిన్నింటిని నిశితంగా పరిశీలిస్తాము.
డేటా లినేజ్ అంటే ఏమిటి?
డేటా వంశం ఒక రకమైన డిజిటల్ పాస్పోర్ట్గా పనిచేస్తుంది. ఇది డేటా ట్రిప్ యొక్క అత్యంత సమగ్రమైన ఖాతా, దాని మూలం నుండి దాని చివరి గమ్యస్థానానికి దాని స్టాప్లు, డొంకలు మరియు మార్పులను వివరిస్తుంది.
In సారాంశం, డేటా వంశం అనేక సిస్టమ్లు మరియు ప్లాట్ఫారమ్లలో డేటా యొక్క మూలం, మార్పు మరియు వినియోగాన్ని వివరిస్తుంది. డేటా ఎలా ఉత్పత్తి చేయబడింది, అది ఎక్కడ నుండి వచ్చింది మరియు ఎలా ఉపయోగించబడింది అనే దాని గురించి వినియోగదారులకు సమాచారాన్ని అందించడం ద్వారా ఇది డిటెక్టివ్ సాధనంగా పనిచేస్తుంది. ఈ సమాచారం ఏవైనా సంభావ్య సమస్యలను గుర్తించి, పరిష్కరించేందుకు వినియోగదారులను అనుమతిస్తుంది.
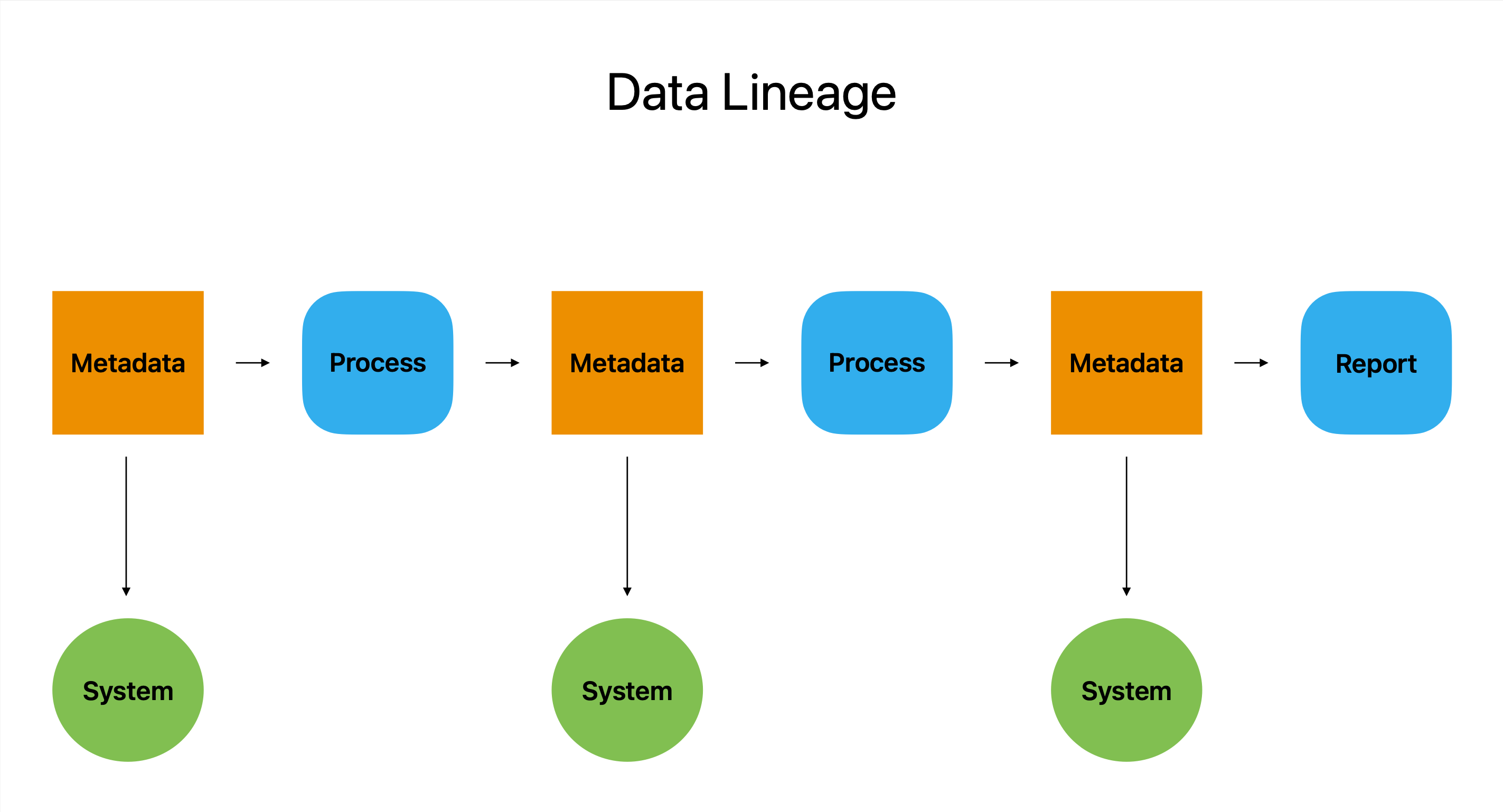
డేటా వంశం అనేది తమ కార్యకలాపాలను అమలు చేయడానికి డేటాపై ఆధారపడే కంపెనీలకు అమూల్యమైన వనరు, ఎందుకంటే ఇది ఎవరు, ఏది, ఎప్పుడు మరియు ఎక్కడ వంటి కీలకమైన ప్రశ్నలకు ప్రతిస్పందించడానికి వినియోగదారులను అనుమతిస్తుంది.
డేటా వంశం అనేది సరళంగా చెప్పాలంటే, డేటా యొక్క పూర్తి మార్గం యొక్క స్పష్టమైన మరియు క్లుప్తమైన దృక్పథాన్ని అందిస్తూ డేటా ఖచ్చితత్వం, పరిపూర్ణత మరియు స్థిరత్వానికి హామీ ఇచ్చే అంతిమ డేటా ట్రయల్.
డేటా లినేజ్ ఎలా పని చేస్తుంది?
డేటా వంశం అనేది డేటా యొక్క భాగాన్ని దాని ప్రారంభ స్థానం నుండి దాని ముగింపు బిందువు వరకు అనుసరించడానికి వీలు కల్పించే రోడ్ మ్యాప్. డేటా పాయింట్ని ప్రయాణికుడుగా పరిగణించండి మరియు అది ఎలా పనిచేస్తుందో బాగా అర్థం చేసుకోవడానికి దాని పాస్పోర్ట్ దాని డేటా వంశంగా పరిగణించండి.
డేటా సోర్స్లు, డేటా ట్రాన్స్ఫర్మేషన్, డేటా స్టోరేజ్ మరియు డేటా అవుట్పుట్ పాస్పోర్ట్ యొక్క నాలుగు ప్రాథమిక భాగాలను తయారు చేస్తాయి.
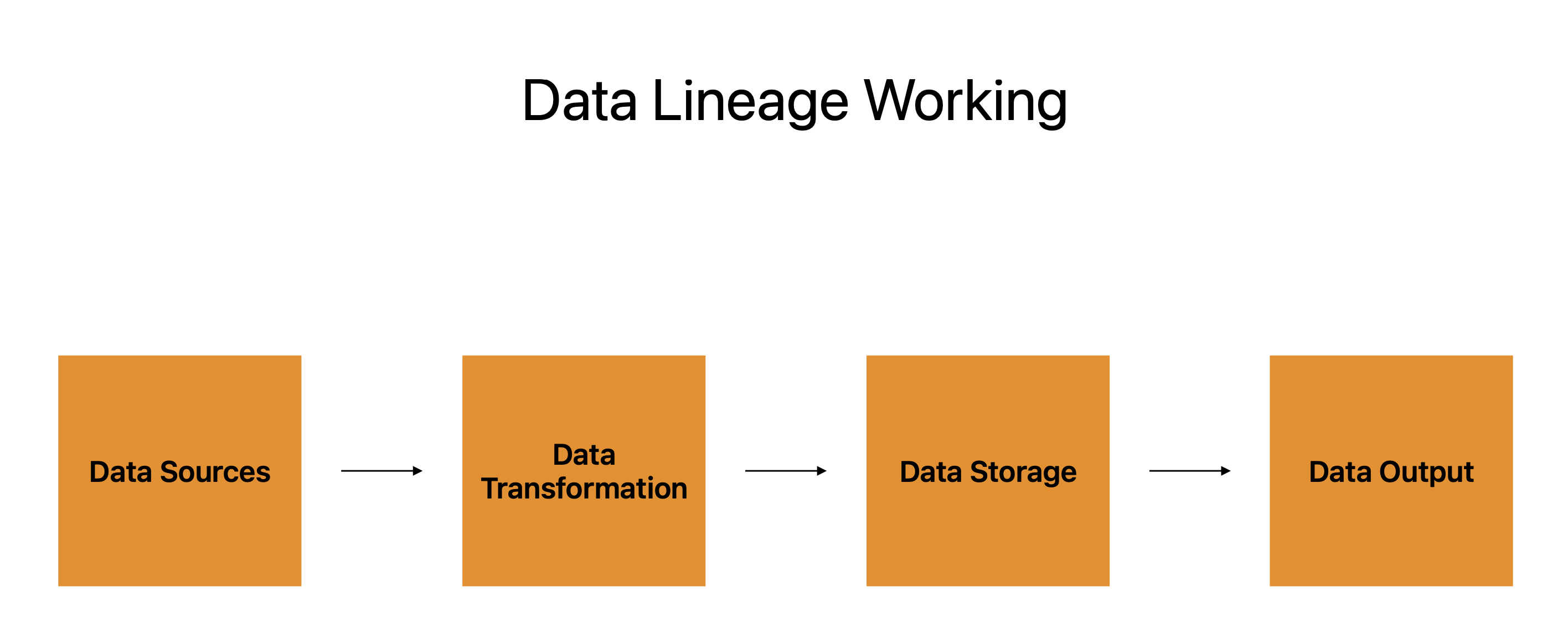
డేటా పుట్టుకొచ్చిన అనేక సిస్టమ్లు, అప్లికేషన్లు మరియు ప్లాట్ఫారమ్లు డేటా మూలాలచే సూచించబడతాయి, ఇవి డేటా ప్రయాణానికి ప్రారంభ బిందువులుగా పనిచేస్తాయి. డేటా పరివర్తన అనేది తదుపరి దశ, మరియు డేటా వంశం ఈ మూలాల నుండి డేటా యొక్క పురోగతిని చార్ట్ చేస్తుంది.
డేటా ట్రాన్స్ఫర్మేషన్ అనేది వినియోగదారు అవసరాలకు అనుగుణంగా డేటాను రూపొందించడం, సవరించడం మరియు మార్చడాన్ని సూచిస్తుంది. ఇది డేటా ట్రిప్ సమయంలో విశ్రాంతి స్టాప్గా పని చేస్తుంది, తదుపరి దశకు దాన్ని సిద్ధం చేస్తుంది.
డేటా దాని చివరి స్థానానికి వెళ్లే ముందు నిల్వ చేయబడుతుంది. ఇది క్లౌడ్ సర్వర్లు, డేటాబేస్లు లేదా ఇతర రకాల నిల్వ పరికరంలో ఉంచబడుతుంది. డేటా ఎక్కడ నిల్వ చేయబడిందో, అలాగే అది ఎలా రక్షించబడుతుందో, బ్యాకప్ చేయబడిందో మరియు పునరుద్ధరించబడుతుందో డేటా వంశం ట్రాక్ చేస్తుంది.
చివరి దశ డేటా అవుట్పుట్, ఇక్కడే డేటాను ఉపయోగించడానికి పంపబడుతుంది. నివేదికలు, ఇన్ఫోగ్రాఫిక్స్ లేదా ఏదైనా ఇతర రకమైన డేటా ఉత్పత్తిని ప్రదర్శించడానికి ఉపయోగించవచ్చు. డేటా వంశం అవుట్పుట్ను ట్రాక్ చేస్తుంది మరియు డేటా యొక్క స్థిరత్వం, ఖచ్చితత్వం మరియు సంపూర్ణతకు హామీ ఇస్తుంది.
డేటా వంశం ప్రాథమికంగా డేటా యొక్క ప్రయాణం యొక్క ప్రతి దశను, దాని ప్రారంభం నుండి దాని అవుట్పుట్ వరకు రికార్డ్ చేయడం ద్వారా పనిచేస్తుంది మరియు ఇది విశ్వసనీయంగా, స్థిరంగా మరియు అన్ని విధాలుగా సరైనదని నిర్ధారించుకోవడం ద్వారా పనిచేస్తుంది. డేటా యొక్క ఉనికి గురించి పూర్తి వీక్షణను అందించడం ద్వారా విద్యావంతులైన నిర్ణయాలు తీసుకోవడానికి, సమస్యలను పరిష్కరించడానికి మరియు చట్టపరమైన బాధ్యతలకు కట్టుబడి ఉండటానికి డేటా వంశం సంస్థలకు సహాయపడుతుంది.
డేటా ఆస్తులు మరియు అవి డేటా పైప్లైన్ ద్వారా ఎలా కదులుతాయో అర్థం చేసుకోవడానికి, డేటా వంశ ప్రక్రియలో మెటాడేటా కీలకమైన భాగం.
డేటా లీనేజ్ సాధనాలను ఉపయోగించి సంస్థలో డేటా ఎలా మార్చబడుతుందో మరియు ఉపయోగించబడుతుందో మీరు చూడవచ్చు, ఇది డేటా ఫ్లో యొక్క దృశ్యమాన వర్ణనను అందించడానికి మెటాడేటాను ప్రభావితం చేస్తుంది. ఇది డేటా సామర్థ్యాన్ని అంచనా వేయడానికి వినియోగదారులను అనుమతిస్తుంది, వారికి మెరుగైన సమాచారంతో నిర్ణయాలు తీసుకోవడంలో సహాయపడుతుంది.
డేటా లినేజ్ రకాలు
డేటా వంశానికి మూడు ప్రాథమిక రూపాలు ఉన్నాయి: ఫార్వర్డ్ డేటా వంశం, వెనుకబడిన డేటా వంశం మరియు ద్వి-దిశాత్మక డేటా వంశం.
ఫార్వర్డ్ డేటా లినేజ్
వన్-వే స్ట్రీట్ మాదిరిగా, ఫార్వర్డ్ డేటా వంశం అనేది డేటా యొక్క భాగాన్ని దాని ప్రారంభ స్థానం నుండి దాని ముగింపు స్థానం వరకు ట్రాక్ చేయడం. డేటా మూలం నుండి ప్రారంభించి, దాని అవుట్పుట్ను చేరుకోవడానికి అనేక పరివర్తనలు మరియు నిల్వ వ్యవస్థల ద్వారా డేటాను అనుసరిస్తుంది.
డేటా యొక్క ప్రాసెసింగ్ మరియు పరివర్తనను అర్థం చేసుకోవడం అలాగే మార్గంలో తలెత్తే ఏవైనా సమస్యలు ఈ రకమైన డేటా వంశాన్ని కలిగి ఉండటం ద్వారా సులభతరం చేయబడతాయి. ప్రతి అడుగు తదుపరి దశకు దారితీస్తుంది; ఇది బ్రెడ్క్రంబ్స్ను అనుసరించడం లాంటిది.
బ్యాక్వర్డ్ డేటా లినేజ్
బ్యాక్వర్డ్ డేటా వంశం అనేది రివర్స్లో ఒక ప్రయాణాన్ని పోలి ఉంటుంది, ఇక్కడ మేము డేటా అవుట్పుట్ను దాని మూలానికి తిరిగి ట్రాక్ చేస్తాము. ప్రక్రియ డేటా యొక్క చివరి స్థానంలో ప్రారంభమవుతుంది మరియు డేటా మూలానికి చేరుకునే వరకు వివిధ నిల్వ మరియు పరివర్తన పద్ధతుల ద్వారా వెనుకకు కదులుతుంది.
డేటా యొక్క అసలైన మూలాన్ని గుర్తించడం, దాని రూపాంతరం యొక్క గ్రహణశక్తి మరియు దాని ఖచ్చితత్వం మరియు సంపూర్ణత యొక్క ధృవీకరణ ఈ రకమైన డేటా వంశం సహాయంతో సాధ్యమవుతుంది. ఇది డిటెక్టివ్ టూల్ లాగా పని చేస్తుంది, డేటా బ్యాక్వర్డ్ మార్గాన్ని అనుసరించడానికి మమ్మల్ని అనుమతిస్తుంది.
ద్వి-దిశాత్మక డేటా లినేజ్
రెండు-మార్గం వీధి, ద్వి-దిశాత్మక డేటా వంశం ఫార్వర్డ్ మరియు బ్యాక్వర్డ్ డేటా వంశం యొక్క ప్రయోజనాలను మిళితం చేస్తుంది. ఇది దాని మూలం నుండి దాని గమ్యస్థానానికి అలాగే ఆ స్థానం నుండి దాని ప్రారంభ స్థానం వరకు ట్రాక్ చేయడం ద్వారా డేటా యొక్క మార్గం యొక్క సమగ్ర వీక్షణను అందిస్తుంది.
డేటా యొక్క అసలు మూలాన్ని గుర్తించడానికి, అది ఎలా మార్చబడిందో అర్థం చేసుకోవడానికి మరియు దాని నాణ్యత, స్థిరత్వం మరియు సంపూర్ణతకు హామీ ఇవ్వడానికి, డేటా యొక్క వంశాన్ని ట్రాక్ చేయడం సహాయపడుతుంది. దాని స్థానం మరియు స్థితిపై నిజ-సమయ సమాచారంతో, ఇది డేటా కోసం GPS ట్రాకర్ను కలిగి ఉంటుంది.
డేటా లినేజ్ అమలు
సంస్థలో డేటా వంశాన్ని అమలు చేయడం తరచుగా క్రింది దశలను కలిగి ఉంటుంది.
డేటా మూలాలను నిర్వచించండి
మీరు ట్రాక్ చేయాలనుకుంటున్న డేటాను కలిగి ఉన్న సిస్టమ్లు మరియు డేటాబేస్లు అన్నీ గుర్తించబడాలి. దీన్ని చేయడానికి, మీరు మొదట ఫైల్లు, APIలు మరియు క్లౌడ్ సేవలతో సహా వివిధ డేటా మూలాలను గుర్తించాలి.
మెటాడేటాను సేకరించండి
తదుపరి దశ దాని స్థానం, ఫార్మాట్ మరియు సంస్థతో సహా డేటా గురించి వివరాలను పొందడం. డేటా యొక్క లక్షణాలను మరియు అది ఎలా ఉపయోగించబడుతుందో అర్థం చేసుకోవడం ఈ మెటాడేటా ద్వారా సాధ్యమవుతుంది.
డేటా లోపాలను గుర్తించండి
మార్గంలో జరిగే ఏవైనా పరివర్తనలు లేదా ప్రాసెసింగ్తో సహా డేటా యొక్క ప్రవాహం దాని మూలం నుండి దాని గమ్యస్థానానికి మ్యాప్ చేయబడితే, సంస్థలో డేటా ఎలా నవీకరించబడుతుందో మరియు ఉపయోగించబడుతుందో అర్థం చేసుకోవడం సులభం.
డేటా యాక్సెస్ని ట్రాక్ చేయండి
డేటా భద్రత మరియు సమ్మతిని నిర్వహించడానికి, డేటాను ఎవరు యాక్సెస్ చేస్తారో ట్రాక్ చేయండి మరియు రికార్డ్ చేయండి.
వంశాన్ని నిల్వ చేయండి మరియు దృశ్యమానం చేయండి
సాధారణ గ్రహణశక్తి మరియు విశ్లేషణ కోసం వంశాన్ని ప్రదర్శించడానికి విజువలైజేషన్ సాధనాలను ఉపయోగించండి. సేకరించిన మెటాడేటా మరియు డేటా ఫ్లో సమాచారాన్ని ఒకే రిపోజిటరీలో నిల్వ చేయండి.
స్వయంచాలక పరిష్కారాన్ని అమలు చేయండి
ఆటోమేషన్ ద్వారా డేటా వంశం సేకరించబడుతుందని మరియు పర్యవేక్షించబడుతుందని మీరు ధృవీకరించవచ్చు, ఇది తప్పులను తగ్గించడానికి మరియు ఉత్పాదకతను పెంచడానికి కూడా సహాయపడుతుంది.
సమీక్ష & నవీకరణ
వంశపారంపర్య రికార్డులు సరియైనవి మరియు క్రమ పద్ధతిలో ప్రస్తుతము ఉండేలా చేయండి మరియు తగిన విధంగా అప్డేట్ చేయండి.
ప్రతి సంస్థ యొక్క ప్రత్యేక అవసరాలు మరియు పరిమితుల ఆధారంగా అమలు ప్రక్రియను సవరించడం లేదా దశలకు జోడించడం అవసరం కావచ్చు.
డేటా లినేజ్ టెక్నిక్స్
నమూనా ఆధారిత వంశం
ఈ పద్ధతితో, డేటాను రూపొందించిన లేదా రూపాంతరం చేసిన ప్రోగ్రామింగ్తో పరస్పర చర్య చేయకుండా వంశపారంపర్యం నిర్వహించబడుతుంది. పట్టికలు, నిలువు వరుసలు మరియు వ్యాపార నివేదికల కోసం మెటాడేటా మూల్యాంకనం ఇందులో భాగం. ఇది ఈ మెటాడేటాను ఉపయోగించి ట్రెండ్ల కోసం వెతకడం ద్వారా వంశాన్ని అన్వేషిస్తుంది.
ఉదాహరణకు, ఒకే పేరు మరియు ఒకే డేటా విలువలతో రెండు డేటాసెట్లలోని నిలువు వరుస దాని ఉనికి యొక్క వివిధ దశలలో ఒకే డేటాను సూచించే అవకాశం ఉంది. ఆ రెండు నిలువు వరుసలను కనెక్ట్ చేయడానికి డేటా లీనేజ్ చార్ట్ ఉపయోగించబడుతుంది.
నమూనా-ఆధారిత వంశం సాంకేతికత స్వతంత్రంగా ఉండటం యొక్క ముఖ్యమైన ప్రయోజనాన్ని కలిగి ఉంది ఎందుకంటే ఇది డేటాను తనిఖీ చేస్తుంది, డేటా ప్రాసెసింగ్ పద్ధతులను కాదు. Oracle, MySQL మరియు Sparkతో సహా ఏదైనా డేటాబేస్ సాంకేతికత కూడా దీన్ని అదే విధంగా అమలు చేయగలదు. ప్రతికూలత ఏమిటంటే ఈ విధానం ఎల్లప్పుడూ ఖచ్చితమైనది కాదు.
డేటా ప్రాసెసింగ్ లాజిక్ కంప్యూటర్ కోడ్లో దాగి ఉండి, మానవులు చదవగలిగే మెటాడేటాలో స్పష్టంగా కనిపించనప్పుడు, అది అప్పుడప్పుడు డేటాసెట్ల మధ్య సంబంధాలను విస్మరిస్తుంది.
డేటా ట్యాగింగ్ ద్వారా వంశం
ట్రాన్స్ఫర్మేషన్ ఇంజిన్ డేటాను ట్యాగ్ చేస్తుంది లేదా మార్కర్ చేస్తుంది అనే భావనపై ఈ పద్ధతి సూచించబడుతుంది. ఇది వంశాన్ని కనుగొనడానికి ట్యాగ్ను మొదటి నుండి చివరి వరకు ట్రేస్ చేస్తుంది. మీరు మొత్తం డేటా బదిలీని నిర్వహించే విశ్వసనీయ పరివర్తన సాధనాన్ని కలిగి ఉంటే మరియు సాధనం ఉపయోగించే ట్యాగింగ్ నిర్మాణం గురించి మీకు తెలిసి ఉంటే మాత్రమే ఈ విధానం విజయవంతమవుతుంది.
అటువంటి సాధనం ఉనికిలో ఉన్నప్పటికీ, అది లేకుండా సృష్టించబడిన లేదా మార్చబడిన ఏ డేటా డేటా ట్యాగింగ్ ద్వారా వంశానికి లోబడి ఉండదు. క్లోజ్డ్ డేటా సిస్టమ్స్లో డేటా వంశాన్ని నిర్వహించడానికి ఈ విషయంలో ఇది పరిమితం చేయబడింది.
స్వీయ-నియంత్రణ వంశం
కొన్ని వ్యాపారాలు మెటాడేటా నిల్వ, ప్రాసెసింగ్ లాజిక్ మరియు మాస్టర్ డేటా మేనేజ్మెంట్ (MDM) వంటి డేటా వాతావరణాన్ని కలిగి ఉంటాయి. ఈ సెట్టింగ్లు తరచుగా a డేటా సరస్సు ఇక్కడ మొత్తం డేటా మొత్తం జీవితకాలం మొత్తం ఉంచబడుతుంది.
అదనపు వనరుల అవసరం లేకుండా ఈ రకమైన స్వీయ-నియంత్రణ వ్యవస్థ ద్వారా వంశాన్ని సహజంగా అందించవచ్చు. అయితే, డేటా ట్యాగింగ్ పద్ధతిలో వలె, ఈ నియంత్రిత వాతావరణంలో వెలుపల జరిగే ఏదైనా వంశానికి తెలియదు.
పార్సింగ్ ద్వారా డేటా వంశం
డేటా-ప్రాసెసింగ్ లాజిక్ను స్వయంచాలకంగా చదివే అత్యంత అధునాతనమైన వంశం. క్షుణ్ణంగా, ఎండ్-టు-ఎండ్ ట్రేసింగ్ కోసం, ఈ పద్ధతి డేటా ట్రాన్స్ఫర్మేషన్ లాజిక్ను రివర్స్ ఇంజనీర్ చేస్తుంది.
ఈ పరిష్కారం అన్నింటినీ అర్థం చేసుకోవాలి కాబట్టి ప్రోగ్రామింగ్ భాషలు మరియు డేటాను మార్చడానికి మరియు రవాణా చేయడానికి ఉపయోగించే సాధనాలు, దాని విస్తరణ సంక్లిష్టంగా ఉంటుంది. ఇది ఎక్స్ట్రాక్ట్-ట్రాన్స్ఫార్మ్-లోడ్ (ETL) లాజిక్, SQL- మరియు జావా-ఆధారిత సొల్యూషన్లు, పాత డేటా ఫార్మాట్లు, XML-ఆధారిత పరిష్కారాలు మరియు ఇతర సాంకేతికతలను ఉపయోగించవచ్చు.
డేటా వంశ వినియోగ కేసులు
డేటా మోడలింగ్
కంపెనీ లోపల అనేక డేటా అంశాలను మరియు వాటి మధ్య కనెక్షన్లను దృశ్యమానం చేయడానికి కంపెనీలు వాటికి మద్దతు ఇచ్చే అంతర్లీన డేటా నిర్మాణాలను తప్పనిసరిగా ఏర్పాటు చేయాలి. ఈ కనెక్షన్లు డేటా వంశాన్ని ఉపయోగించి రూపొందించబడ్డాయి, ఇది డేటా పర్యావరణ వ్యవస్థలో ఉన్న అనేక డిపెండెన్సీలను కూడా చూపుతుంది.
డేటా కాలానుగుణంగా మారుతూ ఉంటుంది కాబట్టి, కొత్త డేటా మూలాధారాలు నిరంతరం కనిపిస్తాయి, కొత్త డేటా ఇంటిగ్రేషన్లు అవసరం మొదలైనవి. దీని కారణంగా, వారి డేటాను నిర్వహించడానికి సంస్థల సాధారణ డేటా నమూనాలు పర్యావరణాన్ని ప్రతిబింబించేలా మారాలి.
వర్తింపు
డేటా లీనేజ్ అనేది ఆడిటింగ్, రిస్క్ మేనేజ్మెంట్ని మెరుగుపరచడం మరియు డేటా గవర్నెన్స్ విధానాలు మరియు చట్టాలకు అనుగుణంగా డేటా ఉంచబడిందని మరియు హ్యాండిల్ చేయబడిందని నిర్ధారించుకోవడానికి సమ్మతి పద్ధతిని అందిస్తుంది.
ప్రభావ విశ్లేషణ
ఏదైనా దిగువ రిపోర్టింగ్ వంటి నిర్దిష్ట వ్యాపార మార్పుల ప్రభావాలను డేటా వంశ సాధనాలను ఉపయోగించి చూడవచ్చు. ఉదాహరణకు, డేటా వంశం, పేరు మార్పు ఎన్ని డాష్బోర్డ్లను ప్రభావితం చేస్తుందో నిర్ణయించడంలో ఎగ్జిక్యూటివ్లకు సహాయపడవచ్చు మరియు తత్ఫలితంగా, ఆ రిపోర్టింగ్ను ఎంత మంది వ్యక్తులు యాక్సెస్ చేస్తారు.
డేటా మైగ్రేషన్
డేటా ఎక్కడ ఉంది మరియు దానిని కొత్త స్టోరేజ్ సిస్టమ్కి మార్చడానికి లేదా కొత్త సాఫ్ట్వేర్ను అమలు చేయడానికి ముందు అది ఎంతకాలం ఉందో అర్థం చేసుకోవడానికి సంస్థలు డేటా మైగ్రేషన్ను ఉపయోగిస్తాయి.
సంస్థ అంతటా డేటా ఎలా తరలించబడిందనే దాని గురించి స్థూలదృష్టిని అందించడం ద్వారా సిస్టమ్ అప్గ్రేడ్లు లేదా మైగ్రేషన్ల కోసం సిద్ధం చేయడానికి డేటా వంశం బృందాలకు సహాయపడుతుంది. ఇది మొత్తంగా కొత్త నిల్వ వాతావరణానికి బదిలీని వేగవంతం చేస్తుంది.
అదనంగా, ఇది పాత లేదా పనికిరాని డేటాను ఆర్కైవ్ చేయడం లేదా తొలగించడం ద్వారా డేటా సిస్టమ్ను నిర్వీర్యం చేసే అవకాశాన్ని అందిస్తుంది. అలా చేయడం ద్వారా, డేటా సిస్టమ్ మొత్తం మెరుగ్గా పని చేస్తుంది మరియు తక్కువ డేటా నిర్వహణ అవసరం.
డేటా శ్రేణిని అమలు చేయడంలో సవాళ్లు
- డేటా భద్రత: డేటా వంశాన్ని నిర్మించేటప్పుడు డేటా భద్రత అనేది ప్రాథమిక ఆందోళన. డేటా ప్రయాణాన్ని దాని ప్రారంభ స్థానం నుండి దాని చివరి గమ్యస్థానానికి అనుసరించడానికి, సున్నితమైన డేటాకు ప్రాప్యత తప్పనిసరిగా మంజూరు చేయబడాలి మరియు ఈ డేటా తప్పనిసరిగా అనధికారిక యాక్సెస్ మరియు ఉల్లంఘనల నుండి రక్షించబడాలి.
- ప్రమాణీకరణ లేకపోవడం: డేటా వంశాన్ని స్వీకరించడానికి ప్రాథమిక అవరోధాలలో ఒకటి ప్రమాణాలు లేకపోవడం. అనేక ప్లాట్ఫారమ్లు, యాప్లు మరియు సిస్టమ్లు డేటా ప్రావిన్స్ని ట్రాక్ చేయడానికి మరియు రికార్డింగ్ చేయడానికి ప్రత్యేకమైన పద్ధతులను ఉపయోగిస్తాయి కాబట్టి, డేటా జర్నీ యొక్క బంధన చిత్రాన్ని కలపడం కష్టం.
- డేటా సిలోస్: డేటా సిలోస్ అనేది డేటా వంశాన్ని అమలు చేస్తున్నప్పుడు తలెత్తే మరో సమస్య. డేటా అనేక అప్లికేషన్లు మరియు సిస్టమ్లలో విస్తరించినప్పుడు, దాని ప్రయాణాన్ని ఒకదాని నుండి మరొకదానికి ట్రాక్ చేయడం సవాలుగా ఉంటుంది. ఇది సరికాని లేదా అసంపూర్ణ డేటా వంశానికి దారితీయవచ్చు.
ముగింపు
ముగింపులో, ప్రతి డేటా-ఆధారిత సంస్థలో డేటా వంశం ఒక ముఖ్యమైన భాగం. ఇది డేటా యొక్క ప్రారంభ స్థానం నుండి ముగింపు బిందువు వరకు సమగ్ర దృక్పథాన్ని అందిస్తుంది, దాని ఖచ్చితత్వం, సంపూర్ణత మరియు స్థిరత్వానికి హామీ ఇస్తుంది.
భవిష్యత్ డేటా లినేజ్ ఆటోమేషన్ మరియు స్టాండర్డైజేషన్ పెరుగుతాయని అంచనా వేయబడింది, ఇది సంస్థలకు అమలు మరియు నిర్వహణను సులభతరం చేస్తుంది. చివరికి, డేటా వంశం యొక్క ప్రాముఖ్యతను నొక్కి చెప్పలేము.
ఇది కంపెనీలకు తెలివైన ఎంపికలు చేయడానికి, వారి కార్యకలాపాలను మరింత సమర్థవంతంగా అమలు చేయడానికి మరియు విజయాన్ని సాధించడానికి అవసరమైన సాధనాలను అందిస్తుంది.





సమాధానం ఇవ్వూ