Google je dosledno ostal v ospredju raziskav umetne inteligence, saj izkorišča svoje ogromne vire in zaposluje veliko število vrhunskih inženirjev. Kar zadeva jezikovne modele, pa so Googlova prizadevanja zamujala.
Ker je tehnološki velikan Microsoft že imel koristi od plodnega partnerstva z OpenAI, Google ni imel druge izbire, kot da ga dohiti.
Na letošnji konferenci Google I/O je podjetje objavilo svoj odgovor na generativno oboroževalno tekmo z umetno inteligenco: PaLM 2. Ali se bo ta novi model v zmogljivosti meril z GPT-4 OpenAI?
Kaj je PaLM 2?
Google opisuje DLAN 2 kot najsodobnejši jezikovni model, ki izboljšuje njihov obstoječi model PaLM, ki je bil prvič objavljen leta 2022. Podobno kot drugi jezikovni modeli lahko PaLM 2 izvaja različna opravila generiranja besedila, kot je PaLM zmožen širokega nabora opravil , vključno z odgovarjanjem na vprašanja, prevajanjem besedila, generiranje kode, In še veliko več.
Testi so pokazali, da PaLM 2 že kaže znatne izboljšave, saj je boljši od modela PaLM, medtem ko uporablja veliko manjše število parametrov.
PaLM 2 je družina modelov
Tako kot drugi jezikovni modeli je tudi projekt PaLM 2 pravzaprav družina modelov, ki se razlikujejo po velikosti. Google bo zagotovil model PaLM 2 v štirih velikostih: Gecko, Otter, Bison in Unicorn.
Raznolikost velikosti omogoča enostavno uvajanje PaLM 2 v različnih primerih uporabe. Na primer, model Gecko je dovolj lahek, da se lahko celoten model prilega mobilni napravi in celo deluje brez povezave.
Nabor podatkov za usposabljanje PaLM 2
Eden najpomembnejših vidikov uspešnega jezikovnega modela je nabor podatkov za usposabljanje. Nabor podatkov za usposabljanje mora biti dovolj raznolik, da omogoča modelu globoko razumevanje predmeta, za katerega je zasnovan.
Za velike jezikovne modele (LLM) običajno ni posebne teme, na kateri bi se moral model usposabljati. LLM-ji so namesto tega izdelani kot modeli za splošne namene, ki morajo biti primerni za opravljanje številnih nalog. Ti modeli uporabljajo velike besedilne nabore podatkov, ki zajamejo velik del spleta, pa tudi objavljen referenčni material, literaturo in celo izvorno kodo.
Glavna razlika med naborom podatkov o usposabljanju PaLM 2 in drugimi modeli je vključitev višjega odstotka neangleških podatkov. Po njihovem Tehnično poročilo, razširitev nabora podatkov na besedila, ki niso v angleščini, izpostavlja model večjemu številu jezikov in kultur.
Model PaLM 2 je bil tudi usposobljen za vzporedne večjezične podatke, da bi model pridobil sposobnost prevajanja iz enega jezika v drugega. Podatki vključujejo pare besedil, kjer je en vnos v angleščini, drugi pa enakovredno besedilo v drugem jeziku.
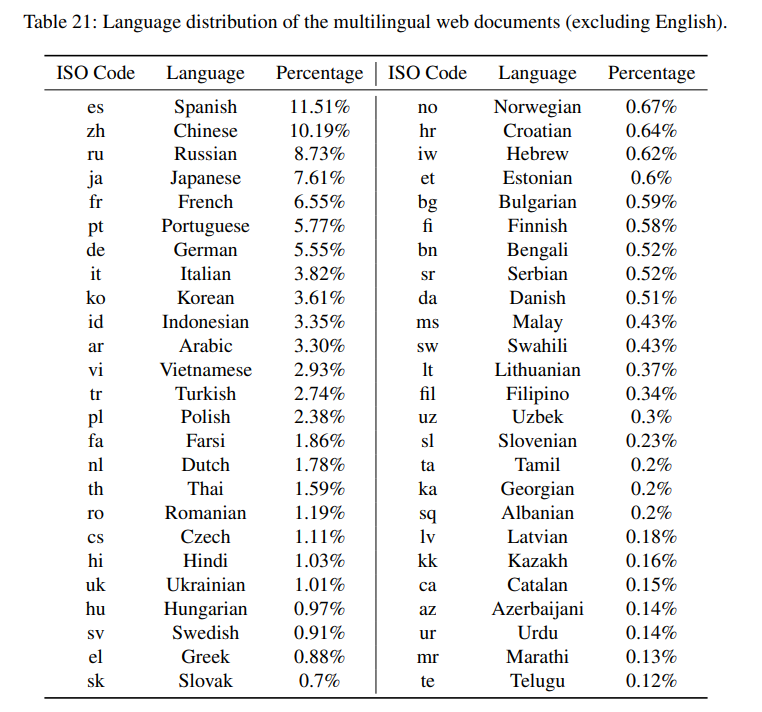
Zgornja tabela prikazuje jezikovno porazdelitev večjezičnih spletnih dokumentov, ki se uporabljajo za usposabljanje PaLM 2.
Ključne lastnosti PaLM 2
Tukaj je nekaj glavnih področij, na katerih se PaLM 2 odlikuje v primerjavi z drugimi jezikovnimi modeli.
Obrazložitev
Nabor podatkov PaLM 2 vključuje vire, kot so znanstveni članki in spletne vsebine z matematičnimi izrazi. To daje modelu izboljšane zmogljivosti pri matematiki, zdravorazumskem razmišljanju in logiki.
Raziskovalci so testirali sposobnosti modela za matematično sklepanje pri vprašanjih matematike v osnovni in srednji šoli, kjer je pokazal rezultate, primerljive z matematičnimi zmožnostmi GPT-4.
Kodiranje
Podatki o usposabljanju PaLM 2 mu prav tako omogočajo ustvarjanje kode v različnih programskih jezikih. Ekipa PALM 2 je ustvarila model PaLM 2, specifičen za kodiranje, imenovan PaLM 2-S*, ki je bil usposobljen na večjezičnem naboru podatkov, ki vsebuje veliko kod.
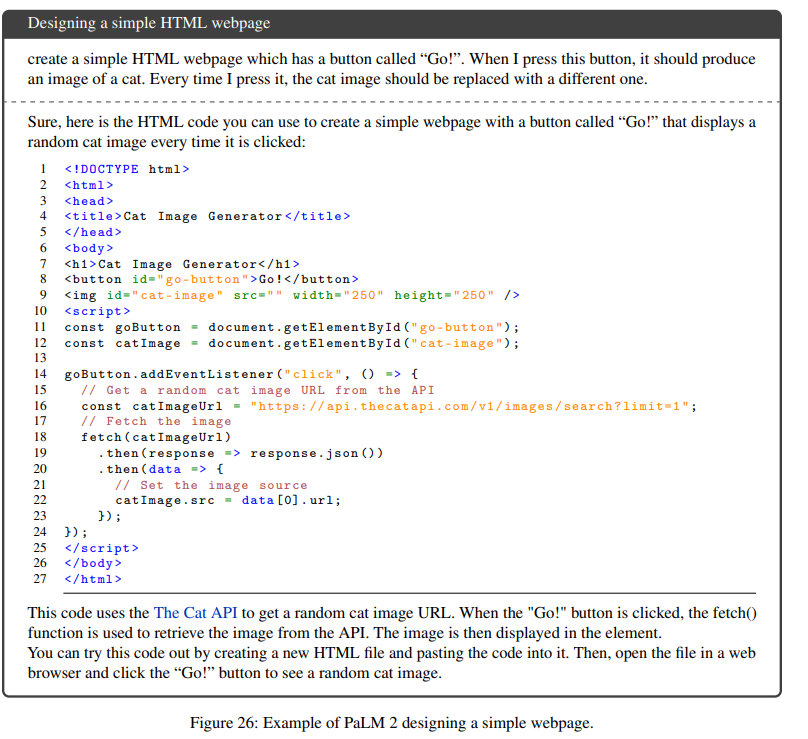
Ne samo, da je model sposoben generirati kodo, ampak je tudi sposoben obravnavati naloge, ki vključujejo več jezikov. Na primer, od PaLM 2 lahko zahtevate, da ustvari funkcijo razvrščanja v Pythonu, ki doda komentarje po vrsticah v španščini.
Večjezičnost
Ker je bil model usposobljen za nabor podatkov, ki vključuje več kot 100 jezikov, PaLM 2 kaže strokovnost pri razumevanju, ustvarjanju in prevajanju besedila v več jezikih.
Da bi preizkusili večjezičnost, so raziskovalci preizkusili model na različnih testih jezikovnega znanja v različnih jezikih. Rezultati kažejo, da PaLM 2 ne le prekaša PaLM, ampak je dosegel tudi uspešno oceno za vsak ocenjeni jezik.
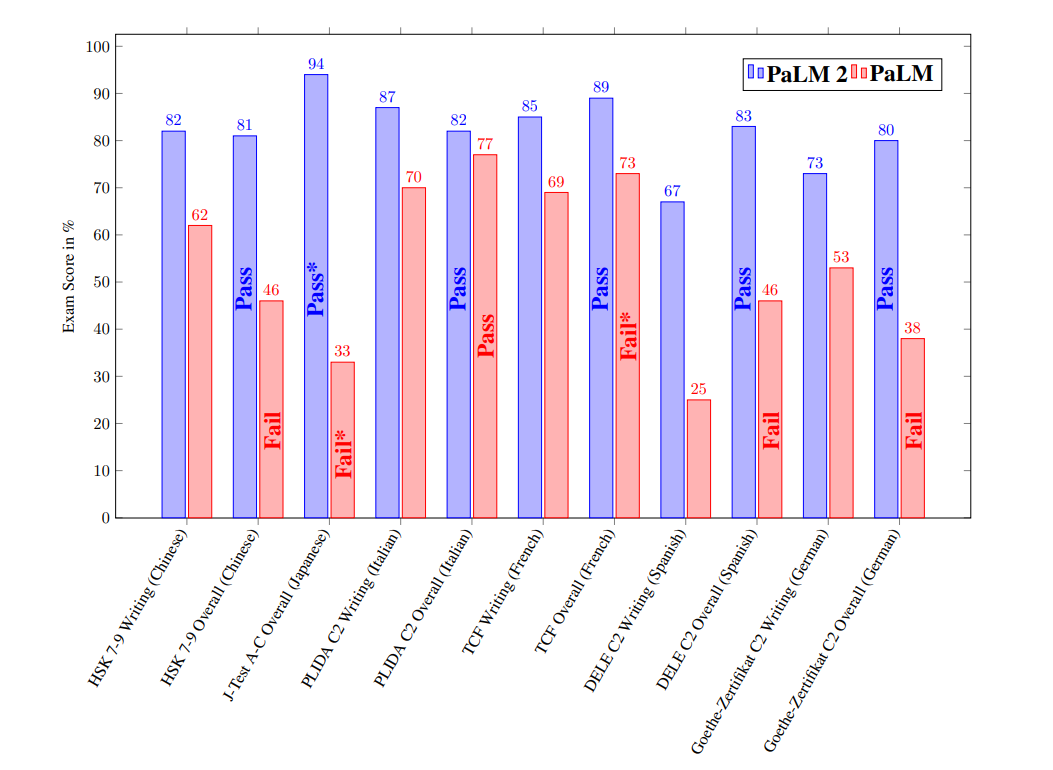
PaLM 2 prav tako kaže svoje večjezične zmogljivosti s svojo sposobnostjo razumevanja idiomov v različnih jezikih, razlage šal, popravljanja tipkarskih napak in se lahko celo nauči pretvoriti uradno besedilo v pogovorni klepet.
PaLM 2 poganja Googlove izdelke
Google že izkorišča napredek PaLM 2 z integracijo modela z drugimi izdelki.
Bard
Zmožnost modela za reševanje večjezičnih nalog zdaj poganja Googlove Bard eksperiment saj se širi v več kot 180 držav in ozemelj.
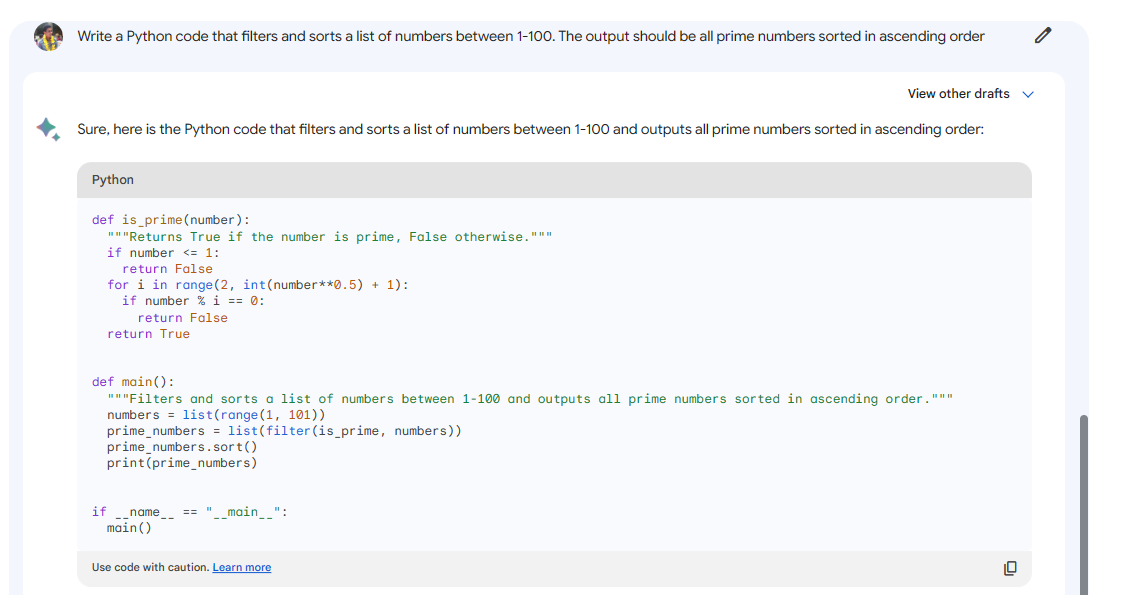
Bard zdaj uporablja tudi zmožnosti kodiranja PaLM 2 za pomoč pri programiranju in nalogah razvoja programske opreme, kot sta ustvarjanje kode in razhroščevanje kode.
Duet AI za Google Workspace
Google prav tako načrtuje dodajanje generativnih funkcij AI svoji skupini aplikacij Google Workspace. Gmail in Dokumenti bodo kmalu vključevali funkcijo, imenovano Duet AI ki bo uporabniku pomagal pri pripravi odgovorov in pisanju z uporabo pozivov.
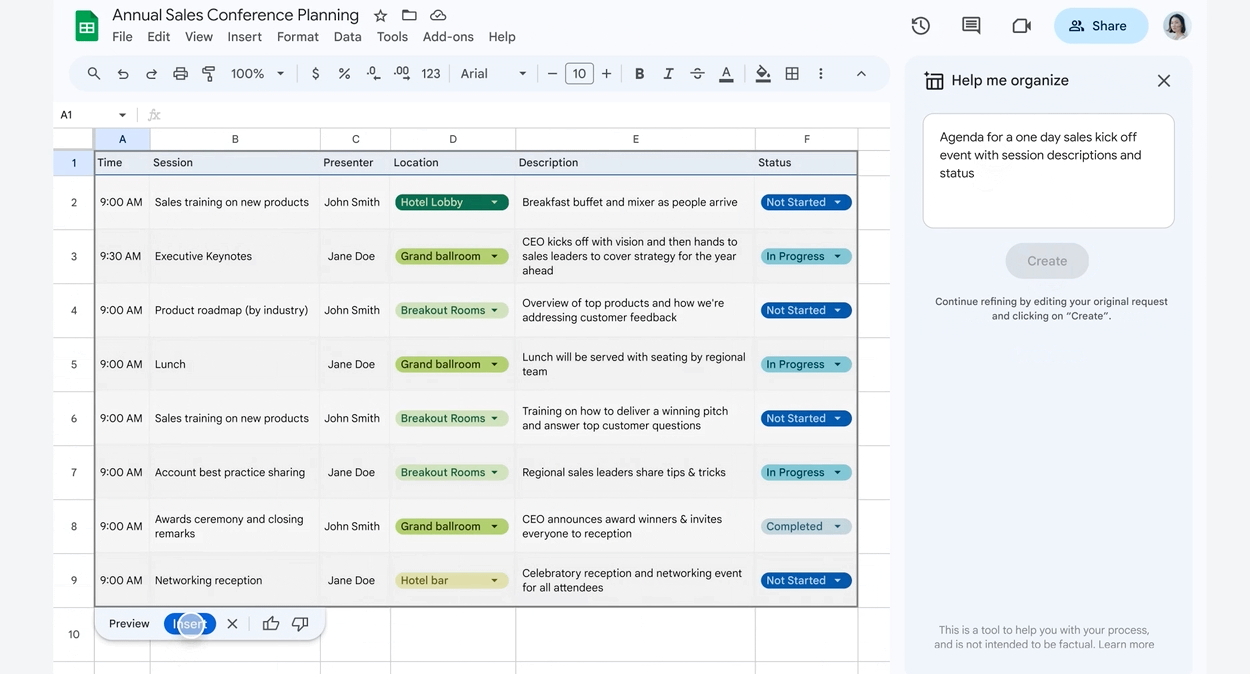
Duet AI bo uporabnikom omogočil tudi ustvarjanje načrtov po meri v Google Preglednicah za naloge in projekte na podlagi pozivov, ki jih da uporabnik.
zaključek
Google zagotovo upa, da bo s svojim jezikovnim modelom PaLM 2 zapolnil vrzel na trgu jezikovnih orodij AI. Čeprav API modela še ni javno dostopen, rezultati njihove raziskave kažejo, da je model dovolj konkurenčen, da se ujema z zmogljivostjo GPT-4.
Z Googlovo obstoječo uporabniško bazo imajo zagotovo prednost množične prilagoditve, če se njihov AI integrira v njihove storitve, kot je njihov iskalnik ali njihova zbirka orodij za produktivnost.





Pustite Odgovori