Kazalo[Skrij][Pokaži]
Podjetja zajemajo več podatkov kot kdaj koli prej, saj se nanje vedno bolj zanašajo pri sprejemanju pomembnih poslovnih odločitev, izboljšanju ponudbe izdelkov in zagotavljanju boljših storitev za stranke.
S količino podatkov, ki se ustvarja z eksponentno hitrostjo, ponuja oblak več prednosti za obdelavo podatkov in analitiko, vključno z razširljivostjo, zanesljivostjo in razpoložljivostjo.
V oblačnem ekosistemu obstaja tudi več orodij in tehnologij za obdelavo in analitiko podatkov. Dve vrsti struktur za shranjevanje velikih podatkov, ki se najpogosteje uporabljata, sta podatkovna skladišča in podatkovna jezera.
Čeprav je uporaba podatkovnega jezera manj privlačna, saj ne morete poizvedovati po modelu in podatkih, medtem ko so še relevantni, je uporaba podatkovnega skladišča za pretočno shranjevanje podatkov potratna.

Wkatero vrsto arhitekture oblaka izberemo?
Ali naj razmislimo o novejših konceptih za podatkovno jezero ali naj se zadovoljimo z omejitvami skladišča ali z omejitvami jezera?
Nova arhitektura shranjevanja podatkov, imenovana "jezero podatkov", združuje prilagodljivost podatkovnih jezer z upravljanjem podatkov v skladiščih podatkov.
Razumevanje različnih metod shranjevanja velikih podatkov je bistveno za izgradnjo zanesljivega cevovoda za shranjevanje podatkov za poslovno inteligenco (BI), analitiko podatkov in strojno učenje (ML) delovne obremenitve, odvisno od zahtev vašega podjetja.
V tej objavi si bomo podrobneje ogledali Data Warehouse, Data Lake in Data Lakehouse z njihovimi prednostmi, omejitvami ter prednostmi in slabostmi. Začnimo.
Kaj je Data Warehouse?
Podatkovno skladišče je centralizirano skladišče podatkov, ki ga uporablja organizacija za shranjevanje ogromnih količin podatkov iz številnih virov. Podatkovno skladišče deluje kot edini vir »resnice podatkov« za organizacijo in je bistveno za poročanje in poslovno analitiko.
Običajno podatkovna skladišča združujejo relacijske nabore podatkov iz več virov, kot so aplikacijski, poslovni in transakcijski podatki, za shranjevanje preteklih podatkov. Podatki se pred nalaganjem v skladiščni sistem transformirajo in očistijo v podatkovnih skladiščih, tako da jih je mogoče uporabiti kot en sam vir resnice podatkov.
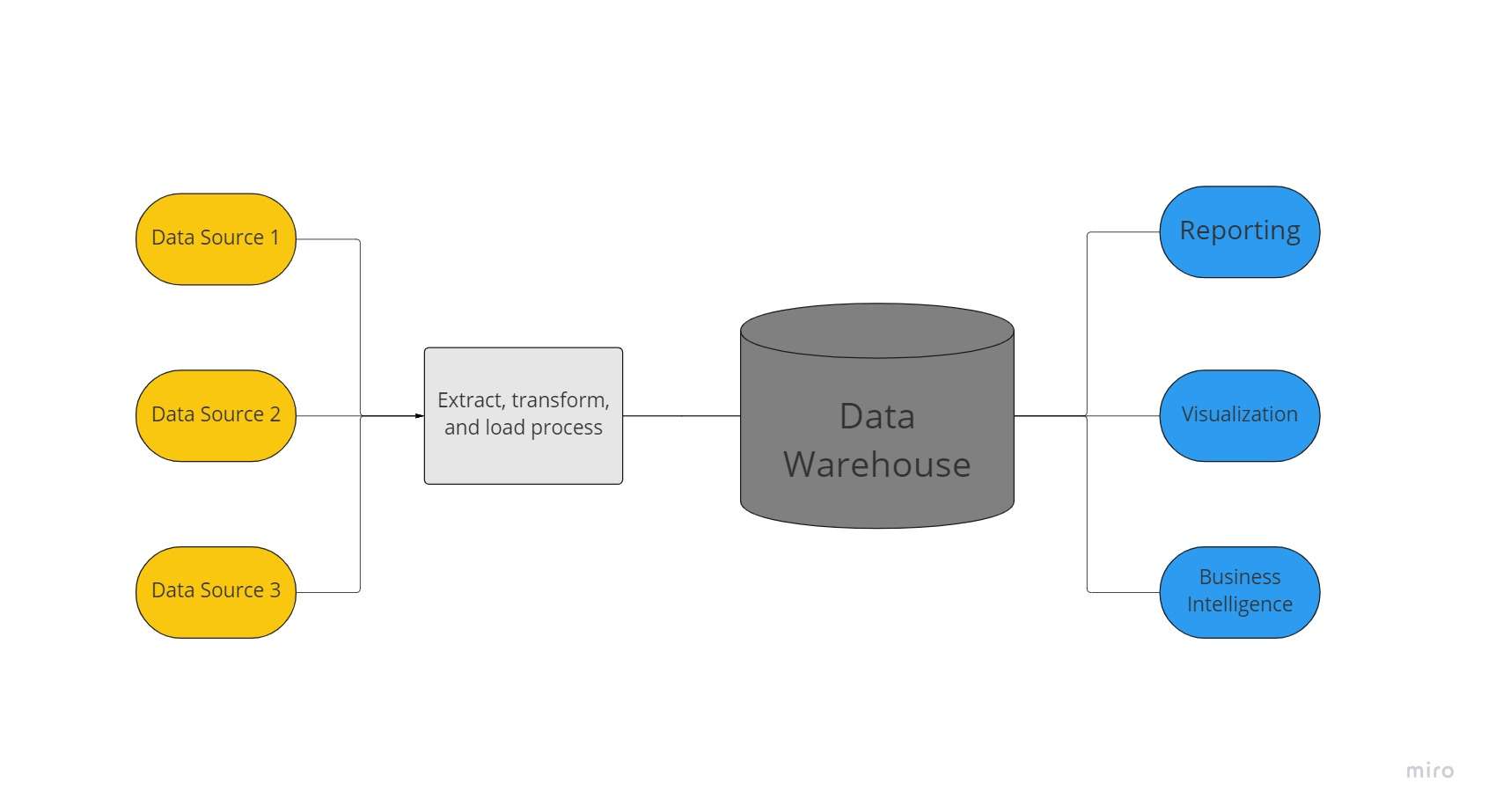
Podjetja vlagajo v podatkovna skladišča zaradi svoje sposobnosti hitrega ponujanja poslovnih vpogledov z vseh področij podjetja. Z uporabo orodij BI, odjemalcev SQL in drugih manj sofisticiranih (tj. nepodatkovnih) analitičnih rešitev, poslovni analitiki, podatkovni inženirji in odločevalci lahko dostopajo do podatkov iz podatkovnih skladišč.
Vzdrževanje skladišča z vedno večjim obsegom podatkov je drago, poleg tega podatkovno skladišče ne more obdelati neobdelanih ali nestrukturiranih podatkov. Poleg tega ni idealna možnost za sofisticirane tehnike analize podatkov, kot je strojno učenje ali napovedno modeliranje.
Podatkovno skladišče torej zagotavlja hitrejše odgovore na poizvedbe in podatke višje kakovosti. Google Big Query, Amazon Redshift, Azure SQL Data warehouse in Snowflake so storitve v oblaku, ki so na voljo za podatkovna skladišča.
Prednosti podatkovnega skladišča
- Povečanje učinkovitosti in hitrosti delovnih obremenitev poslovne inteligence in podatkovne analitike: Podatkovna skladišča skrajšajo čas priprave in analize podatkov. Z lahkoto se lahko povežejo z orodji za analizo podatkov in poslovno inteligenco, saj so podatki iz podatkovnega skladišča zanesljivi in dosledni. Poleg tega skladišča podatkov prihranijo čas, potreben za zbiranje podatkov, in ekipam omogočajo uporabo podatkov za poročila, nadzorne plošče in druge analitične zahteve.
- Povečanje konsistentnosti, kakovosti in standardizacije podatkov: Organizacije zbirajo podatke iz različnih virov, vključno s podatki o uporabnikih, prodaji in transakcijah. Podjetje lahko zaupa podatkom za poslovne zahteve, ker skladiščenje podatkov združuje podatke podjetja v enotno, standardizirano obliko, ki lahko deluje kot en sam vir resničnih podatkov.
- Izboljšanje odločanja na splošno: Skladiščenje podatkov omogoča boljše sprejemanje odločitev, saj ponuja centralizirano shrambo tako za nedavne kot za stare podatke. Z obdelavo podatkov v podatkovnih skladiščih za natančne vpoglede lahko odločevalci ocenijo tveganja, razumejo želje strank ter izboljšajo blago in storitve.
- Zagotavljanje boljše poslovne inteligence: Skladiščenje podatkov premosti vrzel med ogromnimi neobdelanimi podatki, ki se pogosto zbirajo rutinsko kot nekaj samoumevnega, in kuriranimi podatki, ki zagotavljajo vpoglede. Delujejo kot temelj za shranjevanje podatkov v organizaciji, kar ji omogoča, da odgovori na zapletena vprašanja o svojih podatkih in uporabi odgovore za sprejemanje upravičenih poslovnih odločitev.
Omejitve podatkovnega skladišča
- Pomanjkanje prilagodljivosti podatkov: Medtem ko so podatkovna skladišča odlična pri ravnanju s strukturiranimi podatki, so lahko polstrukturirani in nestrukturirani formati podatkov, kot so analitika dnevnika, pretakanje in podatki družbenih medijev, zanje izziv. Zaradi tega priporočamo podatkovna skladišča za primere uporabe, ki vključujejo strojno učenje in Umetna inteligenca težko.
- Draga namestitev in vzdrževanje: Namestitev in vzdrževanje podatkovnih skladišč je lahko drago. Poleg tega podatkovno skladišče pogosto ni statično; stara se in potrebuje pogosto vzdrževanje, ki je drago.
Prednosti
- Podatke je preprosto najti, pridobiti in poizvedovati.
- Dokler so podatki že čisti, je priprava podatkov SQL preprosta.
Proti
- Prisiljeni ste uporabljati samo enega ponudnika analitike.
- Analiziranje in shranjevanje nestrukturiranih ali tekočih podatkov je precej drago.
Kaj je Data Lake?
Vsako vrsto podatkov obljubljajo in omogočajo podatkovna jezera. Koristno je imeti podatke na dostopen način v središču in na voljo za branje.
Podatkovno jezero je centraliziran, izjemno prilagodljiv prostor za shranjevanje, kjer se hranijo ogromne količine organiziranih in nestrukturiranih podatkov v neobdelani, nespremenjeni in neformatirani obliki.
Podatkovno jezero uporablja ravno arhitekturo in objekte, shranjene v neobdelanem stanju za shranjevanje podatkov, v nasprotju s podatkovnimi skladišči, ki shranjujejo relacijske podatke, ki so bili predhodno »očiščeni«.
Podatkovna jezera so v nasprotju s podatkovnimi skladišči, ki imajo težave pri rokovanju s podatki v tem formatu, prilagodljiva, zanesljiva in cenovno dostopna ter podjetjem omogočajo boljši vpogled v nestrukturirane podatke.
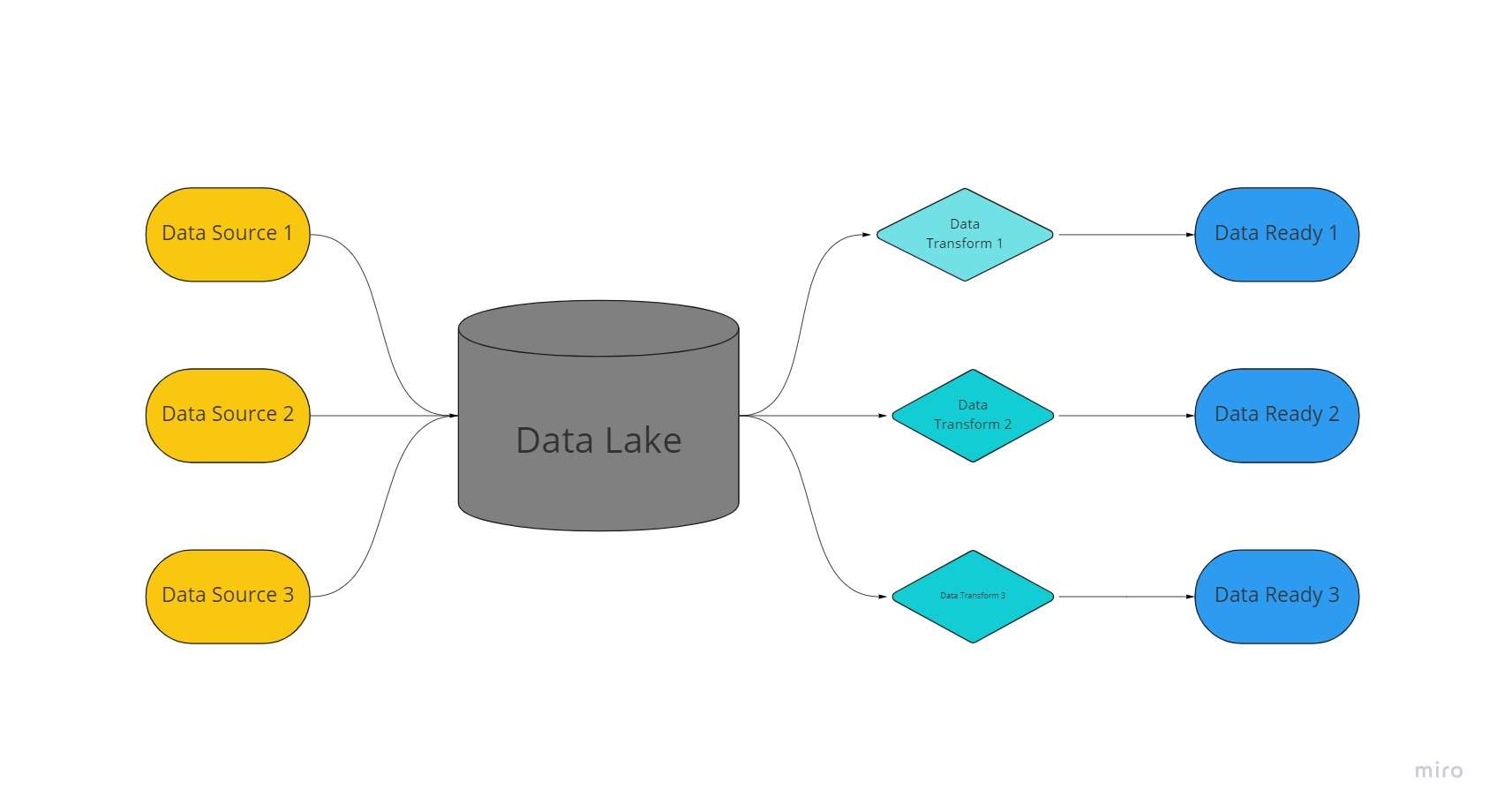
V podatkovnih jezerih se podatki ekstrahirajo, naložijo in preoblikujejo (ELT) za analitične namene, namesto da bi imeli shemo ali podatke vzpostavljene v času zbiranja podatkov.
Uporaba tehnologij za številne vrste podatkov iz naprav IoT, družbeni mediji, in pretakanje podatkov, podatkovna jezera omogočajo strojno učenje in napovedno analitiko.
Poleg tega lahko podatkovno jezero uporablja podatkovni znanstvenik, ki lahko obdeluje neobdelane podatke. Podatkovno skladišče pa je za podjetja enostavnejše za uporabo. Popoln je za profiliranje uporabnikov, napovedna analitika, strojno učenje in druge naloge.
Čeprav podatkovna jezera rešujejo več težav s podatkovnimi skladišči, je njihova kakovost podatkov slaba in hitrost poizvedb nezadostna. Poleg tega za izvajanje poizvedb SQL potrebujejo dodatna orodja za poslovne uporabnike. Podatkovno jezero, ki je slabo strukturirano, lahko naleti na težavo s stagnacijo podatkov.
Prednosti podatkovnega jezera
- Podpora za široko paleto primerov uporabe strojnega učenja in znanosti o podatkih Za obdelavo podatkov v podatkovnih jezerih je preprosteje uporabiti drug stroj in algoritme globokega učenja, saj se podatki hranijo na odprt, neobdelan način.
- Vsestranskost podatkovnih jezer, ki vam omogoča shranjevanje podatkov v kateri koli obliki ali mediju brez zahteve po prednastavljeni shemi, je velika prednost. Podprti so lahko prihodnji primeri uporabe podatkov in analizirati je mogoče več podatkov, če podatke pustimo v prvotnem stanju.
- Da bi se izognili shranjevanju obeh vrst podatkov v različnih kontekstih, lahko podatkovna jezera vsebujejo tako strukturirane kot nestrukturirane podatke. Za shranjevanje različnih vrst organizacijskih podatkov ponujajo eno samo lokacijo.
- V primerjavi s tradicionalnimi podatkovnimi skladišči so podatkovna jezera cenejša, ker so zgrajena tako, da se hranijo na poceni osnovni strojni opremi, kot je objektno shranjevanje, ki je pogosto namenjeno nižji ceni na shranjeni gigabajt.
Omejitve podatkovnega jezera
- Primeri uporabe analitike podatkov in poslovnega obveščanja so slabo ocenjeni: Podatkovna jezera lahko postanejo neorganizirana, če niso ustrezno vzdrževana, zaradi česar jih je težko povezati z orodji za poslovno obveščanje in analitiko. Poleg tega, kadar je to potrebno za primere uporabe poročanja in analitike, pomanjkanje doslednosti podatkovne strukture in transakcijska podpora ACID (atomicity, consistency, isolation, and durability) lahko povzroči neoptimalno delovanje poizvedb.
- Nedoslednost podatkovnih jezer onemogoča uveljavljanje zanesljivosti in varnosti podatkov, kar ima za posledico pomanjkanje obojega. Morda bo težko razviti ustrezne standarde varnosti podatkov in upravljanja, ki bodo poskrbeli za občutljive vrste podatkov, saj lahko podatkovna jezera obravnavajo katero koli obliko podatkov.
Prednosti
- Cenovno dostopne rešitve za vse vrste podatkov.
- Sposoben ravnati s podatki, ki so tako organizirani kot delno strukturirani.
- Idealno za zapleteno obdelavo podatkov in pretakanje.
Proti
- Potreben je sofisticiran cevovod.
- Počakajte, da podatki postanejo poizvedljivi.
- Za zagotavljanje zanesljivosti in kakovosti podatkov je potreben čas.
Kaj je Data Lakehouse?
Nova arhitektura shranjevanja velikih podatkov, imenovana "podatkovno jezero", združuje največje vidike podatkovnih jezer in podatkovnih skladišč. Vse vaše podatke, ne glede na to, ali so strukturirani, polstrukturirani ali nestrukturirani, je mogoče shraniti na enem mestu z najboljšim možnim strojnim učenjem, poslovno inteligenco in zmogljivostmi pretakanja zahvaljujoč podatkovnemu jezeru.
Podatkovna jezera vseh vrst so pogosto izhodišče za podatkovne jezerce; nato se podatki preoblikujejo v format Delta Lake (odprtokodni sloj za shranjevanje, ki prinaša zanesljivost podatkovnim jezerom).
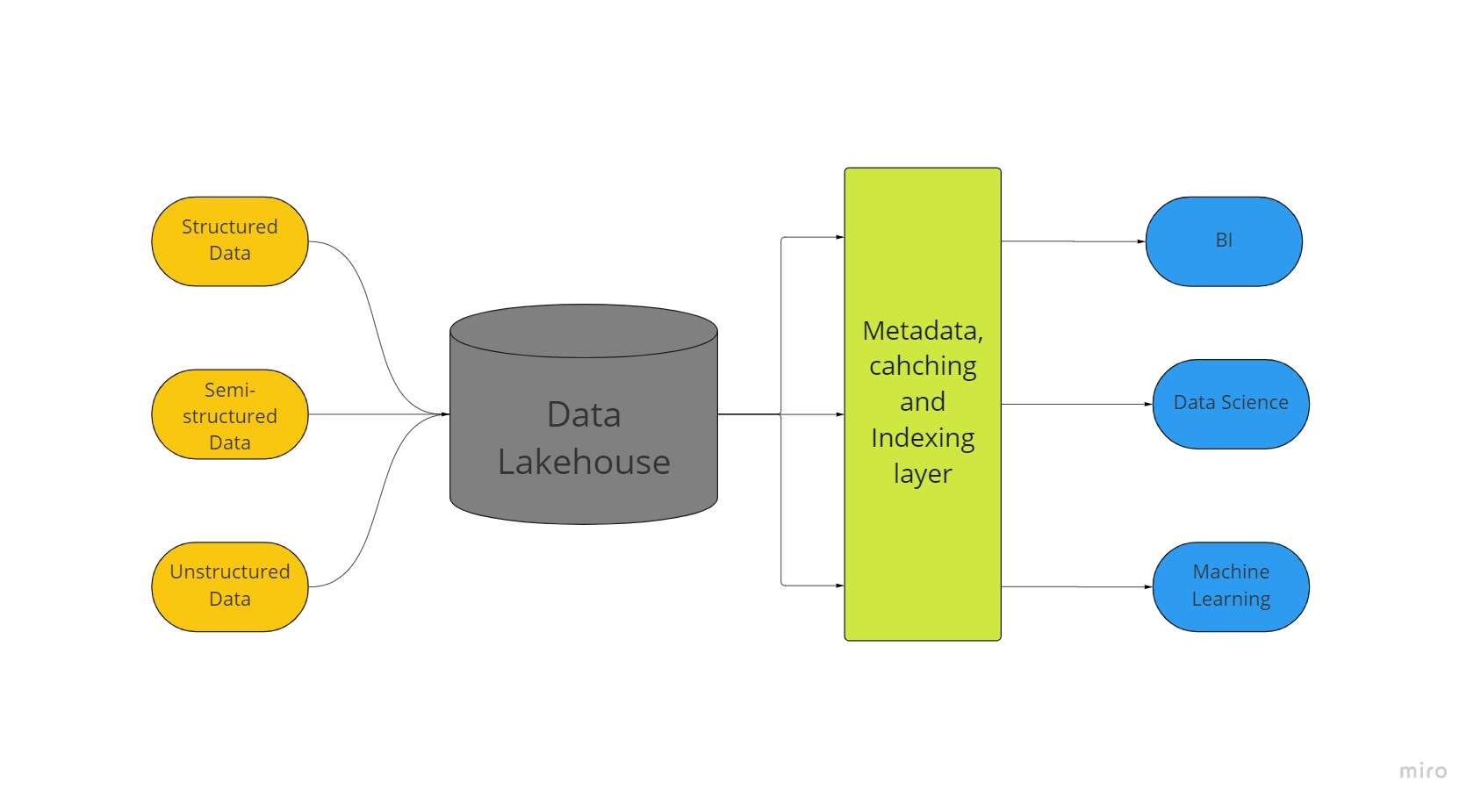
Podatkovna jezera z delta jezeri omogočajo transakcijske postopke ACID iz običajnih podatkovnih skladišč. V bistvu sistem lakehouse uporablja poceni shranjevanje za vzdrževanje ogromnih količin podatkov v njihovi izvirni obliki, podobno kot podatkovna jezera.
Dodajanje sloja metapodatkov na vrh shrambe daje tudi strukturo podatkov in omogoča orodja za upravljanje podatkov, kot so tista v podatkovnih skladiščih.
To številnim ekipam omogoča dostop do vseh podatkov podjetja prek enega sistema za različne pobude, kot so podatkovna znanost, strojno učenje in poslovna inteligenca.
Prednosti Data Lakehouse
- Podpora za večji nabor delovnih obremenitev: Da bi olajšali sofisticirane analize, data lakehouse uporabnikom omogočajo neposreden dostop do nekaterih najbolj priljubljenih orodij za poslovno inteligenco (Tableau, PowerBI). Poleg tega lahko podatkovni znanstveniki in inženirji strojnega učenja zlahka uporabljajo podatke, saj podatkovne jezerce uporabljajo formate odprtih podatkov (kot je Parquet) skupaj z API-ji in ogrodji strojnega učenja, kot je Python/R.
- Stroškovna učinkovitost: Jezera podatkov uporabljajo poceni rešitve za shranjevanje objektov za implementacijo stroškovno učinkovitih značilnosti shranjevanja podatkovnih jezer. S ponudbo ene same rešitve se podatkovne jezernice odpravljajo tudi stroški in čas, povezani z upravljanjem različnih sistemov za shranjevanje podatkov.
- Zasnova podatkovnega jezera zagotavlja celovitost sheme in podatkov, kar poenostavlja gradnjo učinkovitih sistemov za varnost in upravljanje podatkov. Enostavnost različico podatkov, upravljanje in varnost.
- Data lakehouses ponujajo enotno, večnamensko platformo za shranjevanje podatkov, ki se lahko prilagodi vsem zahtevam podatkov podjetja, kar zmanjša podvajanje podatkov. Večina podjetij se odloči za hibridno rešitev zaradi prednosti podatkovnega skladišča in podatkovnega jezera. Ta strategija bi medtem lahko povzročila drago podvajanje podatkov.
- Podpora odprtih formatov. Odprti formati so vrste datotek, ki jih lahko uporabljajo številne programske aplikacije in katerih specifikacije so javno dostopne. Glede na poročila so Lakehouses sposobni shranjevati podatke v običajnih formatih datotek, kot sta Apache Parquet in ORC (Optimized Row Columnar).
Omejitve Data Lakehouse
Največja pomanjkljivost podatkovnega jezera je, da je še vedno mlada in razvijajoča se tehnologija. Negotovo je, ali bo zaradi tega izpolnil svoje zaveze. Preden lahko podatkovne jezerce tekmujejo z uveljavljenimi sistemi za shranjevanje velikih podatkov, lahko traja leta.
Vendar je glede na hitrost, s katero se pojavljajo sodobne inovacije, težko reči, ali jih ne bo na koncu nadomestil drugačen sistem za shranjevanje podatkov.
Prednosti
- Ena platforma ima vse podatke, kar pomeni, da je treba vzdrževati manj imen gostiteljev.
- Atomičnost, konsistenca, izolacija in žilavost so nespremenjeni.
- Cenovno je bistveno ugodnejša.
- Ena platforma ima vse podatke, kar pomeni, da je treba vzdrževati manj imen gostiteljev.
- Enostaven za upravljanje in hitro odpravljanje težav
- Poenostavite gradnjo cevovoda
Proti
- Nastavitev lahko traja nekaj časa.
- Je premlad in predaleč, da bi ga označili za uveljavljen sistem shranjevanja.
Skladišče podatkov proti jezeru podatkov proti jezeru podatkov
Podatkovno skladišče ima dolgo zgodovino v aplikacijah za korporativno obveščanje, poročanje in analitiko in je prva tehnologija za shranjevanje velikih podatkov.
Po drugi strani pa so podatkovna skladišča draga in imajo težave pri ravnanju z raznolikimi in nestrukturiranimi podatki, kot so pretočni podatki. Za strojno učenje in delovne obremenitve podatkovne znanosti so bila razvita podatkovna jezera za upravljanje neobdelanih podatkov v različnih oblikah v cenovno dostopnem pomnilniku.
Čeprav so podatkovna jezera učinkovita pri nestrukturiranih podatkih, nimajo transakcijskih zmogljivosti ACID podatkovnih skladišč, zaradi česar je težko zagotoviti doslednost in zanesljivost podatkov.
Najnovejša arhitektura za shranjevanje podatkov, znana kot »podatkovna jezera«, združuje zanesljivost in doslednost podatkovnih skladišč s cenovno dostopnostjo in prilagodljivostjo podatkovnih jezer.
zaključek
Skratka, izdelava podatkovnega jezera iz nič je lahko težavna. Poleg tega boste skoraj zagotovo uporabljali platformo, zasnovano za omogočanje odprte podatkovne arhitekture lakehouse.
Zato bodite previdni in pred nakupom raziščite številne funkcije in izvedbe vsake platforme. Podjetja, ki iščejo zrelo, strukturirano podatkovno rešitev s poudarkom na primerih uporabe poslovne inteligence in analitike podatkov, lahko razmislijo o skladišču podatkov.
Vendar bi morala podjetja, ki iščejo razširljivo in cenovno dostopno rešitev za velike podatke za napajanje delovnih obremenitev za podatkovno znanost in strojno učenje na nestrukturiranih podatkih, razmisliti o podatkovnih jezerih.
Upoštevajte, da vaše podjetje potrebuje več podatkov, kot jih lahko zagotovita podatkovno skladišče in tehnologije podatkovnega jezera, ali da iščete rešitev za integracijo prefinjene analitike in operacij strojnega učenja v vaše podatke. A podatkov Lakehouse je v tej situaciji smiselna možnost.





Pustite Odgovori