Web scraping a devenit o metodă crucială pentru obținerea de date perspicace de pe platformele de internet în societatea actuală bazată pe date.
Fiind un site de socializare extrem de popular, Instagram oferă o mulțime de materiale generate de utilizatori. Și, aceste date generate pot fi utilizate pentru marketing, cercetare și alte motive.
Utilizatorii pot extrage date de pe Instagram cu ușurință și eficiență, datorită scraper-urilor Instagram bogate în funcții Bright Data, un lider razuire web instrument. În această postare, vom oferi o prezentare amănunțită, pas cu pas, a procesului de scraping Instagram.
Deci, haideți să vedem pașii pentru cum putem răzui datele de pe Instagram.
Înțelegerea Instagram Scrapers din Bright Data
Cu ajutorul a două web scrapers universale și a unui set de date pre-compilat, Bright Data oferă o varietate de servicii de scraping Instagram. Aceste tehnologii oferă versatilitate în extragerea datelor și se adaptează la diverse cerințe.
Să examinăm fiecare dintre aceste opțiuni mai detaliat:
a. Scraping Browser
Tehnologia inovatoare cunoscută sub numele de Scraping Browser a fost creată pentru a îndeplini cerințele proiectelor de data scraping. Oferă tot ceea ce este necesar pentru răzuirea la scară în interiorul unui singur browser. Se remarcă datorită automatizării integrate de deblocare a site-ului web, ceea ce îl face singurul browser de acest fel din întreaga lume.
Scraping Browser oferă utilizatorilor acces la funcții robuste care depășesc browserele automate și fără cap, permițându-le să treacă chiar și dincolo de cele mai dificile scripturi și bariere ale site-urilor pentru detectarea botului.
Curatarea datelor este mai eficientă și mai simplă datorită caracteristicilor sale de ajustare automată, care gestionează cu ușurință blocurile noi, soluțiile CAPTCHA, amprentele și reîncercările și apare ca un utilizator autentic.
Folosind AI pentru a depăși sistemele de detectare a bot-ului
Utilizând tehnologia AI de ultimă oră, Scraping Browser poate depăși sistemele de detectare a bot-ului și se poate adapta continuu la strategiile lor de schimbare. Pentru a debloca mai bine paginile web, Scraping Browser învață din încercările acestor sisteme de a detecta și bloca încercările de scraping și își modifică comportamentul în mod corespunzător.
Depășește eficiența proxy-urilor convenționale, imitând comportamentul unui browser folosit de un utilizator real. În consecință, clienții se pot concentra asupra obiectivelor lor pentru colectarea datelor fără a fi nevoiți să facă față dificultății și cheltuielilor procedurilor de detectare a bot-ului în curs.
b. Web Scraper IDE
Un instrument robust de scraping web creat pentru dezvoltatori, Web Scraper IDE poate gestiona sarcini complexe de scraping. Reduce considerabil timpul de dezvoltare, oferind în același timp scalabilitate infinită, datorită soluției sale complet găzduite și caracteristicilor de scraping pre-construite. Aplicația permite construirea rapidă și scalabilă de scrapers online, oferind șabloane de cod și funcții JavaScript gata făcute de pe site-uri web populare.
Tot ceea ce este necesar pentru un web scraping de succes este furnizat de Web Scraper IDE. Este o soluție completă pentru extragerea datelor online, deoarece opțiunile de integrare le permit clienților să planifice accesările cu crawlere sau să le lanseze prin API și să se conecteze cu sistemele de stocare principale.
Cum să-l folosească? - Tutorial
Mai întâi, navigați la tabloul de bord al utilizatorului de pe site.

Să începem cu pașii noștri pentru a răzui Instagram.
1- Navigați la Contul Meu și faceți clic pe secțiunea Datasets & Web Scraper IDE.
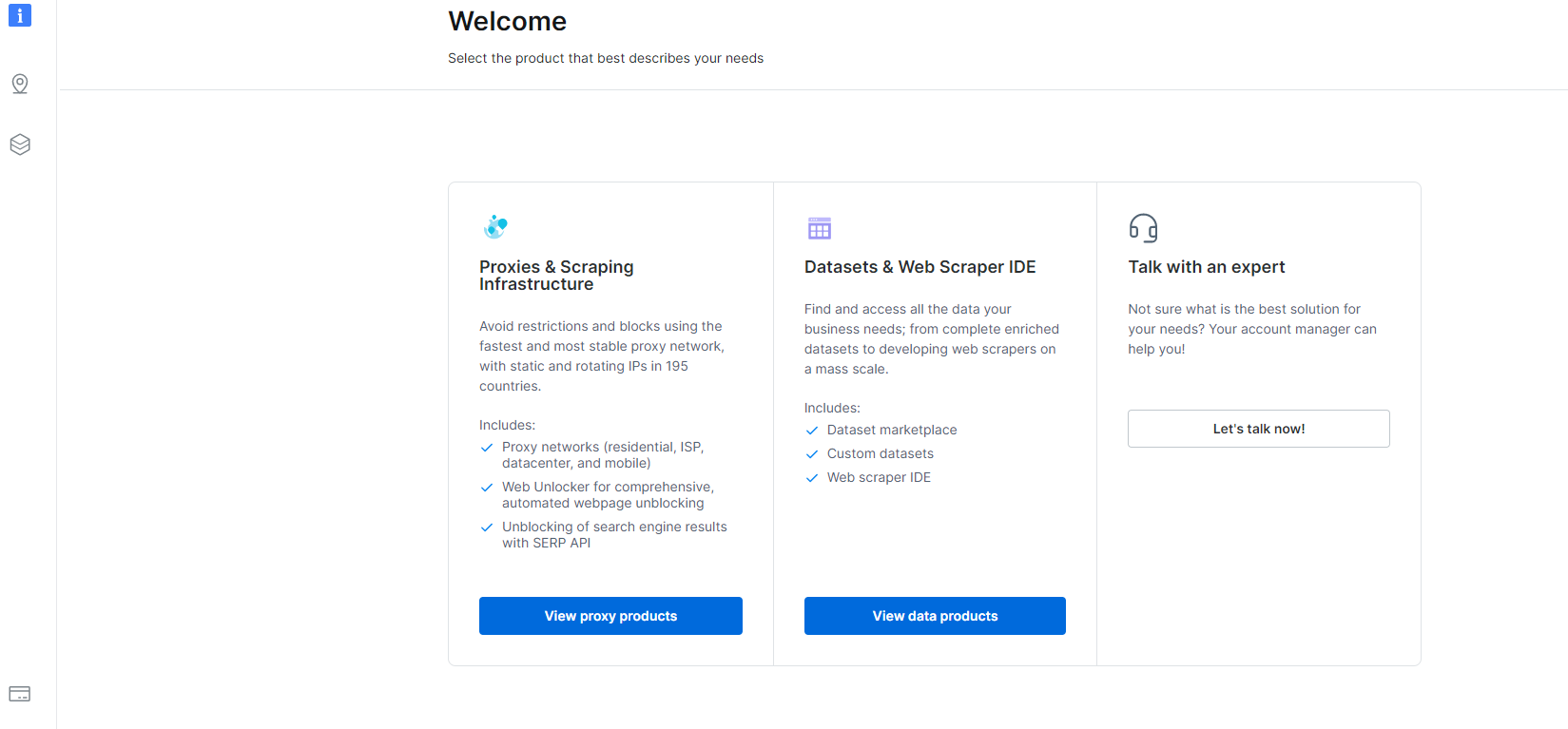
2- Odată ce sunteți acolo, faceți clic pe My Scrapers.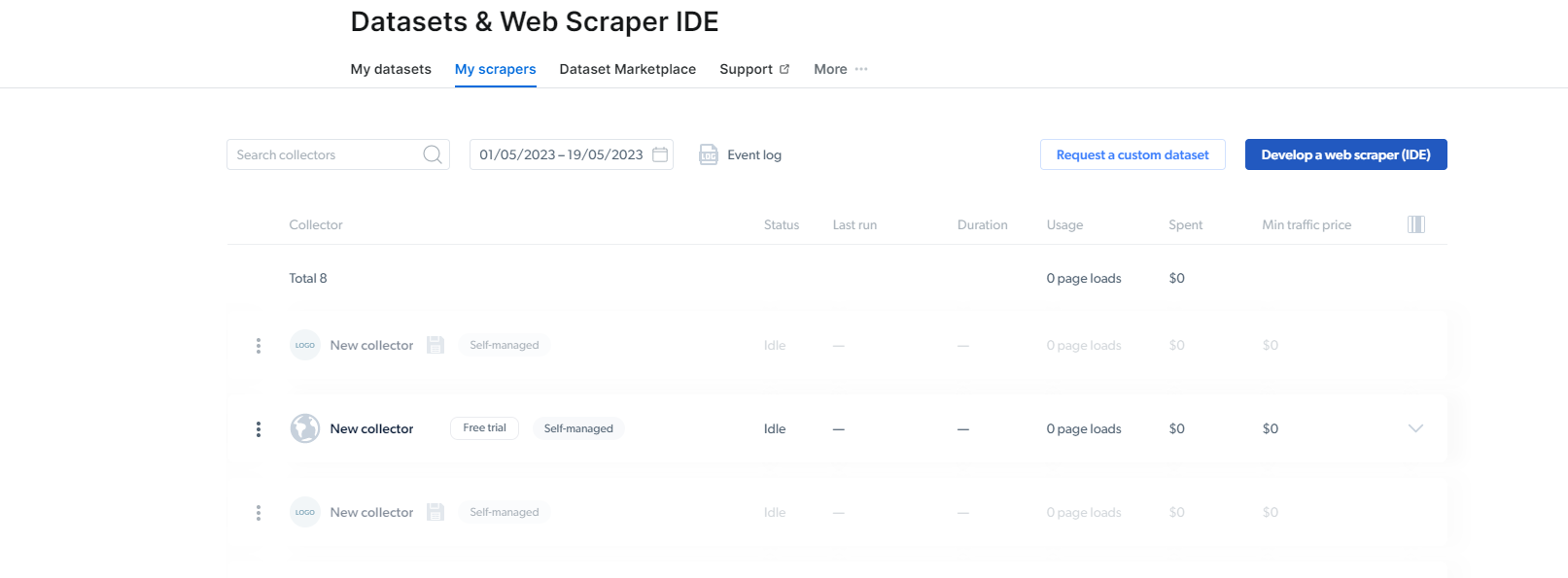
Aici, trebuie să faceți clic pe „Dezvoltați un web scraper (IDE)”. Aici vom crea scraperul nostru pentru Instagram.
3-Acum, trebuie să dezvoltăm un nou web scraper. Doar pentru acest exemplu, aleg să răzuiesc contul „NASA”. Acest lucru este doar de dragul acestui exemplu.
Deci, codul meu va arăta astfel:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Trebuie să faceți clic pe butonul „play” din dreapta sus pentru a rula acest cod.
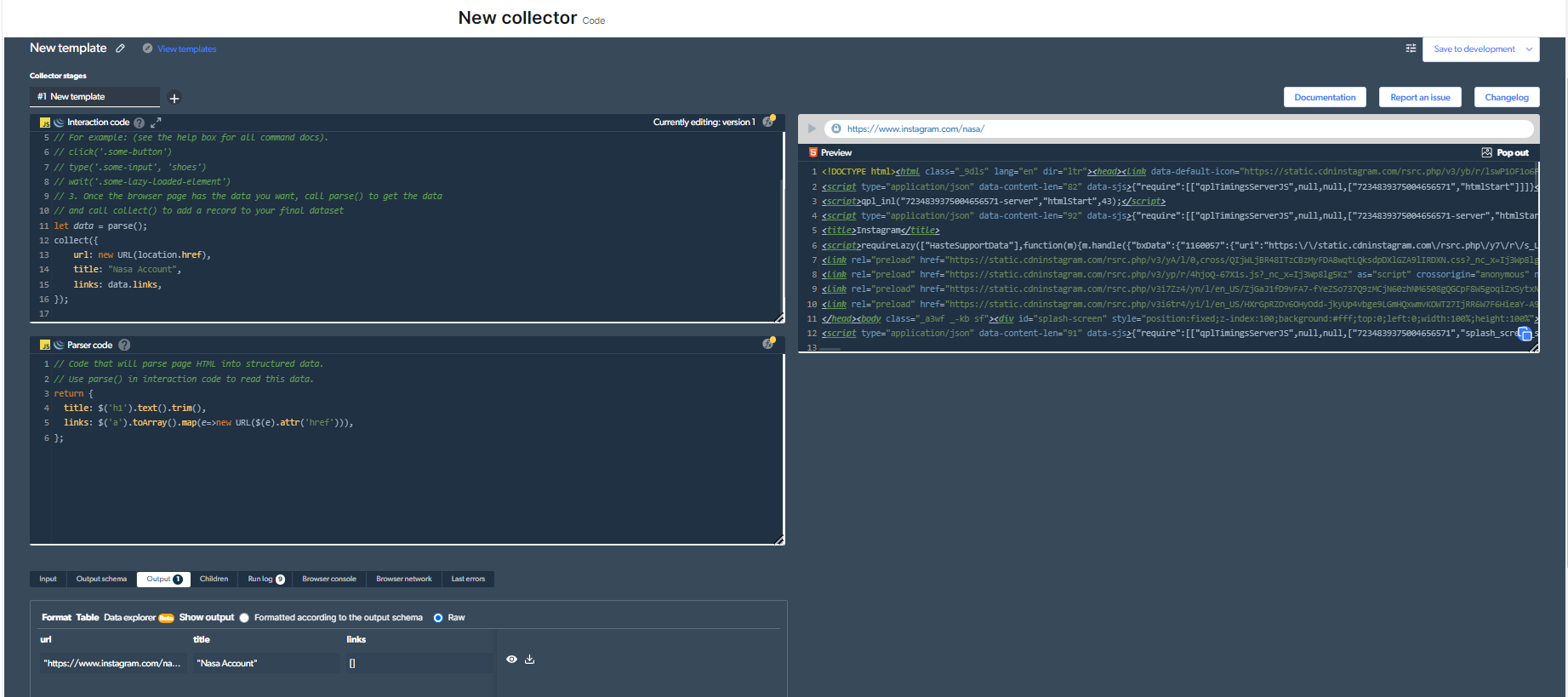
4- Acum, vom avea o ieșire.
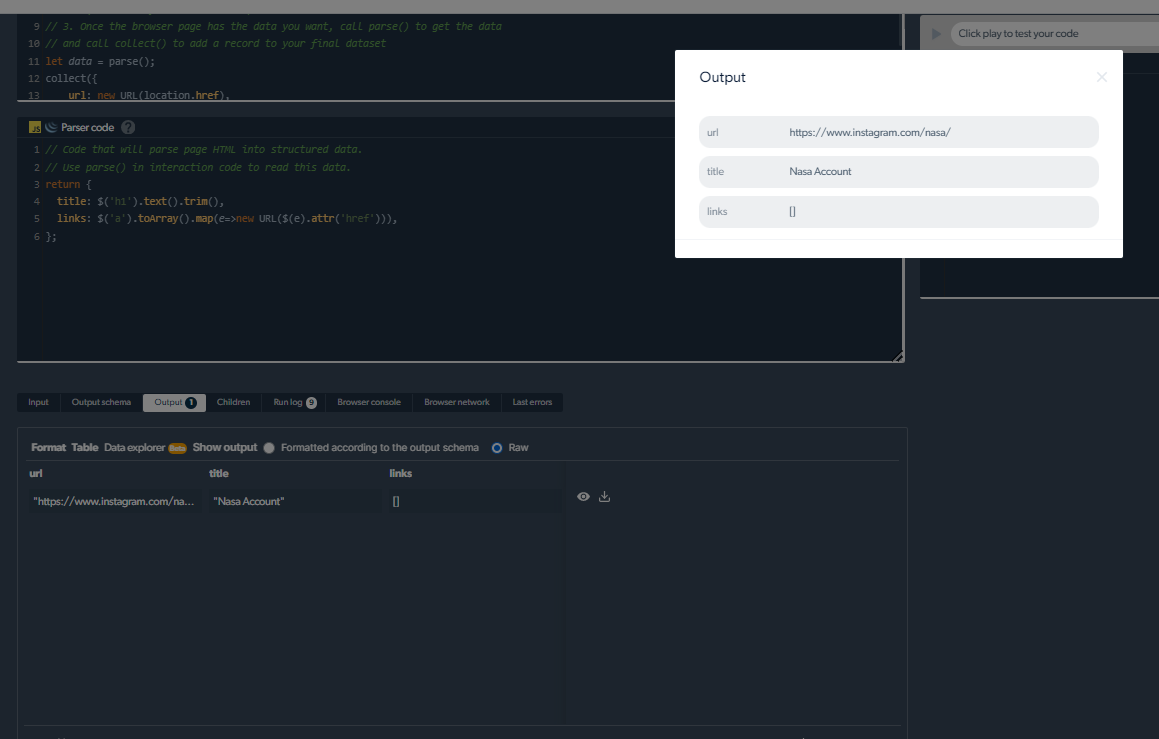
Gestionarea problemelor de răzuire
Postările de pe Instagram cu butonul „Afișați mai multe” ar putea fi dificil de capturat de către scrapers. Cu toate acestea, scraper-urile Instagram de la Bright Data sunt făcute pentru a gestiona cu succes o astfel de complexitate. Aceste răzuitoare au abilități de ultimă oră pentru a parcurge paginarea și încărcarea butoanelor suplimentare.
Scraper-urile Instagram de la Bright Data gestionează eficient aceste dificultăți pentru a permite extragerea amănunțită a datelor, permițându-vă să colectați întreaga colecție de informații necesare analizei sau studiului dumneavoastră.
Puteți ocoli provocările prezentate de natura dinamică a postărilor Instagram utilizând aceste instrumente de răzuire.
c. Set de date precolectat
Bright Data înțelege că nu toată lumea vrea să-și ruleze racleta. Ei furnizează un set de date precolectat pentru Instagram pentru a atrage astfel de consumatori.
Acest set de date oferă o mulțime de informații utile, cum ar fi urmăritori, profiluri, postări și multe altele.
Bright Data oferă opțiuni de personalizare pentru a personaliza setul de date în funcție de nevoile dvs., indiferent dacă doriți un întreg set de date sau un subset de date specializate. Această abordare evită construirea și gestionarea unui scraper, oferindu-vă date gata de utilizat pentru analiză și perspective.
Acum, să verificăm infrastructura care face aceste instrumente atât de eficiente: infrastructura proxy și Web Unlocker.
Dezlănțuiți puterea proxy-urilor
Utilizarea proxy-uri este esențial în timpul web scraping pentru a garanta că acțiunile tale trec neobservate.
Bright Data oferă o selecție largă de servicii proxy care sunt personalizate în funcție de cerințele dumneavoastră. Puteți alege din Procurări rezidențiale, care oferă peste 72 de milioane de IP-uri rotate de pe dispozitive reale din 195 de țări.
Puteți alege proxy-uri ISP, care oferă peste 700,000 de IP-uri de acasă reale în întreaga lume pentru utilizare pe termen lung; Datacenter Proxies, care au peste 770,000 de IP-uri partajate din orice locație geografică; și Mobile Proxies, care formează cea mai mare rețea mobilă real-peer 3G/4G cu peste 7,000,000 de IP-uri.
Prin utilizarea acestor proxy, se pot colecta cu ușurință date în timp ce se prezintă drept utilizator autorizat în numeroase locuri.

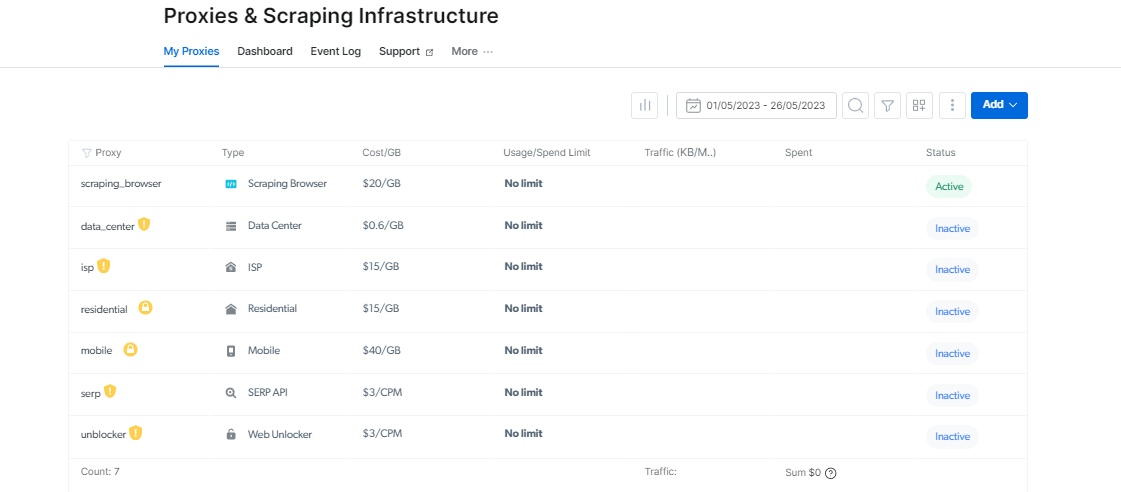
Manager proxy: faceți gestionarea proxy mai ușoară
Gestionarea mai multor proxy-uri ar putea fi dificilă, dar Proxy Manager o simplifică.
Această interfață open-source vă permite să vă gestionați toate proxy-urile de pe o singură platformă. Spuneți la revedere setării și comutării manuale a proxy-urilor. Proxy Manager simplifică procedura și economisește timp și efort.
Extensie browser proxy: schimbați-vă locația cu ușurință
Trebuie să colectați date web din mai multe regiuni? Sunteți acoperit de extensia noastră de browser proxy. Vă puteți schimba locația de navigare cu un singur clic pentru a obține informații specifice regiunii.
Profitați de flexibilitatea și simplitatea colectării datelor din mai multe regiuni fără complicații tehnologice.
Cum functioneazã? - Tutorial
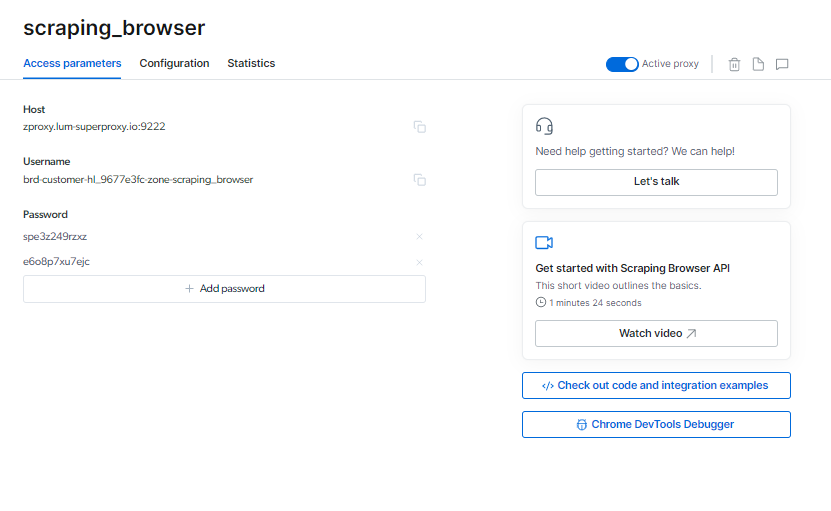
Îți poți găsi Scraping Browser informații de conectare pe pagina Parametrii de acces, care vor fi utilizate atunci când începeți o nouă sesiune de browser.
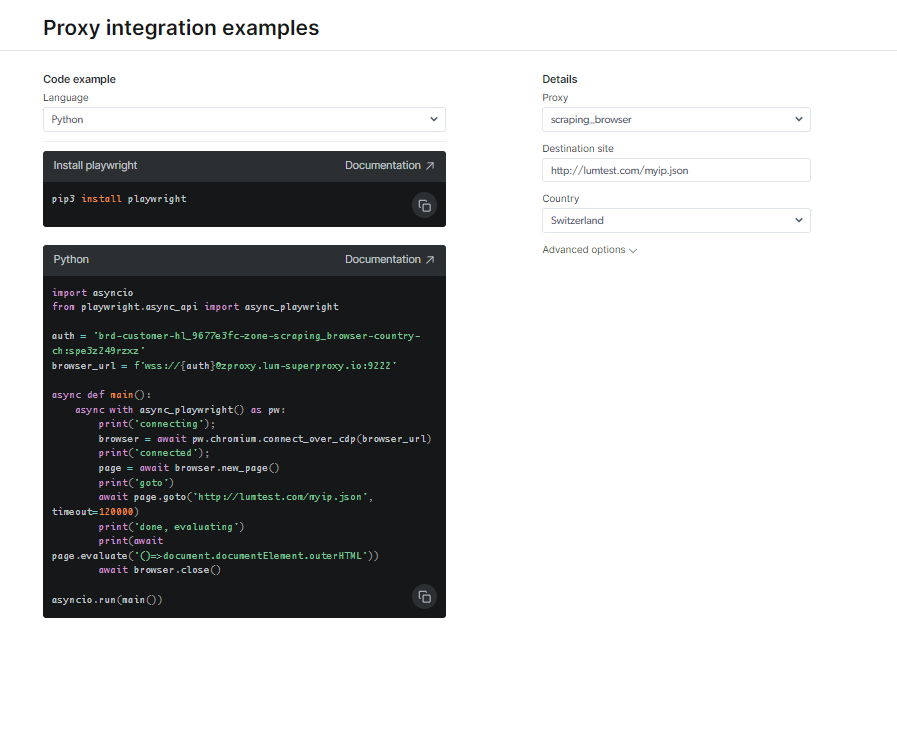
Consultați documentația și mostrele de cod, inclusiv un exemplu de script complet funcțional, care este gata de utilizare, sau urmăriți un scurt videoclip cu instrucțiuni de pornire. De exemplu; aici este Cod Python exemplu pentru integrare:
Doriți ajutor? Pentru o conversație cu unul dintre specialiști, puteți da clic pe pictograma de chat.
Rețineți că aveți control complet asupra sesiunilor de browser în timp ce utilizați Scraping Browser și puteți efectua orice operațiune care este acceptată de Puppeteer, Playwright sau de utilizarea directă a protocolului Chrome DevTools.
Deblocarea site-ului web fără blocări
Scraping Browser este conceput pentru a funcționa la scară și după cum este necesar. Nu trebuie să vă faceți griji că sunteți interzis; puteți porni câte sesiuni de browser aveți nevoie.
Această capacitate, atunci când este asociată cu puterea proxy-urilor, garantează o colectare continuă de date, permițându-vă să obțineți în mod eficient datele pe care le doriți.
Abilitățile de deblocare încorporate ale Scraping Browser și rețeaua proxy robustă vă ajută să economisiți timp, să sporiți productivitatea și să descoperiți noi oportunități.
De asemenea, puteți verifica statisticile direct din aceeași pagină.
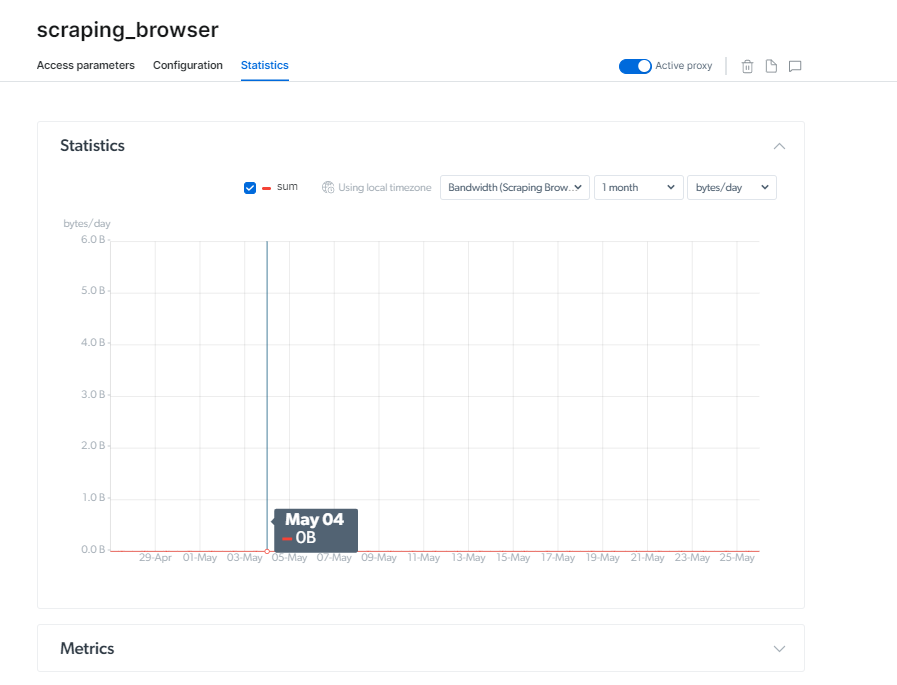
Prețul browserului Scraping
Bright Data oferă opțiuni de preț personalizabile pentru a îndeplini o varietate de scopuri. Puteți alege fie o perioadă de facturare lunară, fie anuală.
Opțiunea Pay as You Go vă permite să plătiți doar pentru ceea ce utilizați, fără niciun angajament necesar, începând de la 20.00 USD/GB și 0.1 USD/oră.
Planul de creștere de 500 USD este potrivit pentru afaceri în creștere, cu o taxă redusă de 15.30 USD/GB și 0.1 USD/oră.
Pachet de afaceri, care costă 1000 USD, este cea mai populară opțiune, API-ul Scraping Browser costând 13.50 USD/GB și 0.1 USD/oră.
Contactând direct echipa Bright Data, utilizatorii întreprinderilor se pot bucura de o scalare infinită și de prețuri personalizate. Începeți o încercare gratuită astăzi pentru a descoperi potențialul browserului de scraping al Bright Data și pentru a vă schimba eforturile de scraping online.
Site Unlocker
Web Unlocker este un instrument puternic creat pentru a depăși restricțiile site-ului și pentru a oferi o colectare ușoară a datelor. Depășește mai multe provocări, inclusiv cookie-uri, agenți de utilizator de browser specifici site-ului și soluții captcha, prin utilizarea procedurilor automate.
Folosind rotația automată a adresei IP, utilizatorii Web Unlocker pot răzui continuu site-urile web țintă, asigurând accesul constant la datele importante.
Îmbunătățirea călătoriilor de solicitare a dezvoltatorilor
Câteva caracteristici fac Web Unlocker popular printre dezvoltatori. Programul eficientizează procesul de colectare a datelor prin identificarea automată a agenților utilizatori necesari pentru fiecare site web, economisind timp și resurse valoroase.
Web Unlocker se adaptează în timp real pentru a evita detectarea ca răspuns la strategiile în continuă schimbare utilizate de blocarea roboților, asigurând accesul continuu la site-urile web de interes. Algoritmii de învățare automată ai platformei pot rezolva rapid captch-urile, un obstacol frecvent în calea inițiativelor de colectare a datelor.

Prețul Web Unlocker
Începând de la aproximativ 2.03 USD per mia de cereri (CPM), Web Unlocker oferă mai multe opțiuni de preț pentru a satisface diferite cerințe. O perioadă de încercare gratuită de 7 zile este disponibilă utilizatorilor pentru a le începe și a le permite să testeze funcțiile Web Unlocker înainte de a se angaja.
Web Unlocker are capacitatea de adaptare pentru a suporta diverse modele de utilizare, indiferent dacă consumatorii doresc o abordare cu plata pe măsură sau au nevoie de un plan personalizat, potrivit cerințelor lor specifice. În plus, cei care aleg planuri de preț pe termen lung ar putea economisi 32%.
Comparație între Web Unlocker și proxy-uri autogestionate
Web Unlocker oferă numeroase beneficii instantanee față de proxy-urile autogestionate. Pentru o implementare fără probleme, oferă o tehnică extinsă de integrare care combină funcțiile super proxy și Proxy Manager. Utilizatorii își pot extinde efectiv operațiunile de colectare a datelor cu un număr infinit de conexiuni simultane.
Web Unlocker oferă deblocare automată, rezolvă CAPTCHA-urile și gestionează cu succes modificările de marcare pe site-urile web țintă.
Platforma garantează extragerea continuă și de încredere a datelor prin implementarea unui sistem de reîncercare automată și efectuarea de apeluri asincrone pentru anumite domenii. În plus, colecția în creștere a online Unlocker de solicitări de antet HTTP, cookie-uri de browser specifice site-ului și gadget-uri simulate le permite utilizatorilor să rămână nedetectați, permițându-le în același timp să obțină date online în timp real.
Gânduri finale și lucruri importante de reținut
În cele din urmă, în timp ce utilizați Bright Data pentru scraping Instagram, este esențial să aveți în vedere câteva puncte vitale.
Vă rugăm să rețineți că capacitățile lor de scraping sunt limitate la date disponibile public, prin practici etice.
Ar trebui să respectați întotdeauna termenii și politicile de confidențialitate Instagram. Scrapingul ar trebui să se facă în mod etic și responsabil, fără a încălca drepturile utilizatorilor sau fără a încălca orice lege.
În al doilea rând, actualizați și ajustați regulat parametrii de scraping pentru a asigura acuratețea și relevanța datelor preluate. Platforma și algoritmii Instagram se pot schimba, prin urmare, trebuie să vă modificați strategiile de scraping în consecință.
În cele din urmă, utilizați ajutorul și resursele platformei Bright Data pentru a optimiza succesul eforturilor dvs. de scraping Instagram. Interacționați cu documentația, tutorialele și serviciul pentru clienți pentru a vă îmbunătăți cunoștințele despre instrumentele lor de răzuire.
Puteți obține informații utile, puteți influența luarea deciziilor înțeleapte și puteți reuși în inițiativele dvs. bazate pe date pe platforma Instagram, urmând aceste bune practici și utilizând puterea capabilităților de scraping Instagram ale Bright Data.





Lasă un comentariu