É uma tarefa crucial e desejável em visão computacional e gráficos produzir filmes de retrato criativos do mais alto calibre.
Embora tenham sido propostos vários modelos eficazes para tonificação de imagens de retratos baseados no potente StyleGAN, essas técnicas orientadas a imagens têm desvantagens claras quando usadas com vídeos, como o tamanho fixo do quadro, a exigência de alinhamento facial, a ausência de detalhes não faciais , e inconsistência temporal.
Uma revolucionária estrutura VToonify é usada para lidar com a difícil transferência de estilo de vídeo de retrato de alta resolução controlada.
Examinaremos o estudo mais recente sobre o VToonify neste artigo, incluindo sua funcionalidade, desvantagens e outros fatores.
O que é Vtoonify?
A estrutura VToonify permite a transmissão personalizável de estilo de vídeo de retrato de alta resolução.
O VToonify usa as camadas de média e alta resolução do StyleGAN para criar retratos artísticos de alta qualidade com base nas características de conteúdo em várias escalas recuperadas por um codificador para reter os detalhes do quadro.
A arquitetura totalmente convolucional resultante usa faces não alinhadas em filmes de tamanho variável como entrada, resultando em regiões de rosto inteiro com movimentos realistas na saída.

Essa estrutura é compatível com os modelos atuais de tonificação de imagem baseados em StyleGAN, permitindo que eles sejam estendidos para tonificação de vídeo e herda características atraentes, como cor ajustável e personalização de intensidade.
Esta estudo apresenta duas instâncias de VToonify baseadas em Toonify e DualStyleGAN para transferência de estilo de vídeo de retrato baseado em coleção e baseado em exemplar, respectivamente.
Extensas descobertas experimentais mostram que a estrutura VToonify proposta supera as abordagens existentes na criação de filmes de retrato artísticos de alta qualidade e temporalmente coerentes com parâmetros de estilo variáveis.
Os pesquisadores fornecem a Bloco de anotações do Google Colab, para que você possa sujar as mãos nele.
Como funciona o Tech & Data Studio:
Para realizar a transferência ajustável de estilo de vídeo de retrato de alta resolução, o VToonify combina as vantagens da estrutura de tradução de imagem com a estrutura baseada em StyleGAN.
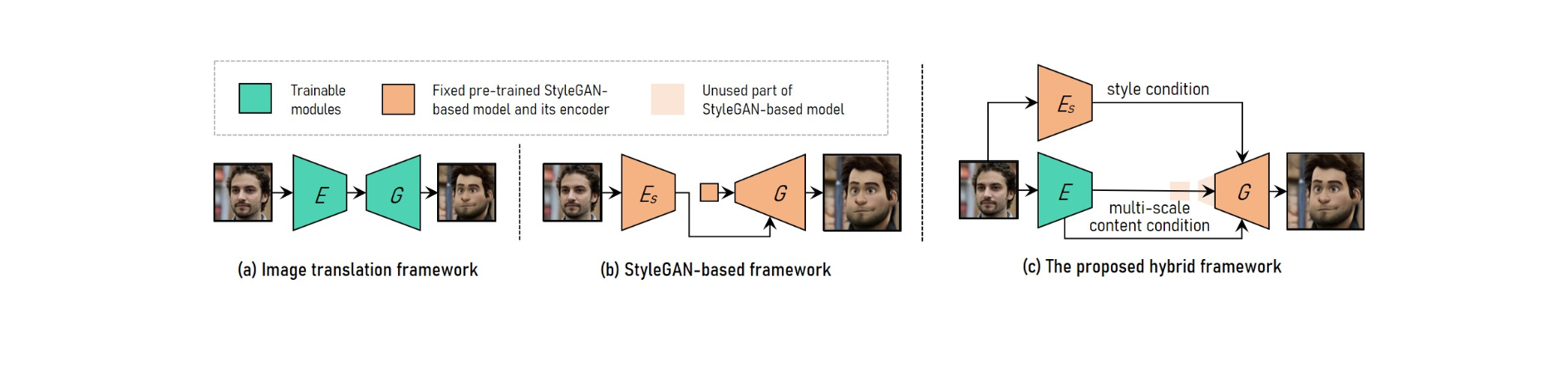
Para acomodar diferentes tamanhos de entrada, o sistema de tradução de imagens emprega redes totalmente convolucionais. O treinamento do zero, por outro lado, impossibilita a transmissão de estilo controlado e de alta resolução.
O modelo StyleGAN pré-treinado é usado na estrutura baseada em StyleGAN para alta resolução e transferência de estilo controlada, embora seja limitado ao tamanho fixo da imagem e às perdas de detalhes.
O StyleGAN é modificado na estrutura híbrida, excluindo seu recurso de entrada de tamanho fixo e camadas de baixa resolução, resultando em uma arquitetura de codificador-gerador totalmente convolucional semelhante à da estrutura de tradução de imagem.
Para manter os detalhes do quadro, treine um codificador para extrair características de conteúdo multiescala do quadro de entrada como um requisito de conteúdo adicional para o gerador. Vtoonify herda a flexibilidade de controle de estilo do modelo StyleGAN, colocando-o no gerador para destilar seus dados e modelo.
Limitações do StyleGAN e Vtoonify proposto
Retratos artísticos são comuns em nosso cotidiano, bem como em negócios criativos como arte, meios de comunicação social avatares, filmes, publicidade de entretenimento e assim por diante.
Com o desenvolvimento de deep learning tecnologia, agora é possível criar retratos artísticos de alta qualidade a partir de fotos de rosto da vida real usando a transferência automática de estilo de retrato.
Há uma variedade de maneiras bem-sucedidas criadas para transferência de estilo baseada em imagem, muitas das quais são facilmente acessíveis a usuários iniciantes na forma de aplicativos móveis. O material de vídeo rapidamente se tornou um dos pilares de nossos feeds de mídia social nos últimos anos.
A ascensão das mídias sociais e filmes efêmeros aumentou a demanda por edição de vídeo inovadora, como transferência de estilo de vídeo de retrato, para gerar vídeos interessantes e bem-sucedidos.
As técnicas existentes orientadas à imagem têm desvantagens significativas quando aplicadas a filmes, limitando sua utilidade na estilização automatizada de vídeo de retrato.
O StyleGAN é uma espinha dorsal comum para o desenvolvimento de um modelo de transferência de estilo de imagem de retrato devido à sua capacidade de criar rostos de alta qualidade com gerenciamento de estilo ajustável.
Um sistema baseado em StyleGAN (também conhecido como toonificação de imagem) codifica um rosto real no espaço latente do StyleGAN e, em seguida, aplica o código de estilo resultante a outro StyleGAN ajustado no conjunto de dados de retrato artístico para criar uma versão estilizada.
O StyleGAN cria imagens com rostos alinhados e em tamanho fixo, o que não favorece rostos dinâmicos em imagens do mundo real. O corte e o alinhamento do rosto no vídeo às vezes resultam em um rosto parcial e gestos desajeitados. Os pesquisadores chamam esse problema de 'restrição de colheita fixa' do StyleGAN.
Para faces desalinhadas, o StyleGAN3 foi proposto; no entanto, só suporta um tamanho de imagem definido.
Além disso, um estudo recente descobriu que codificar faces não alinhadas é mais desafiador do que faces alinhadas. A codificação de rosto incorreta é prejudicial à transferência de estilo de retrato, resultando em problemas como alteração de identidade e componentes ausentes nos quadros reconstruídos e estilizados.
Conforme discutido, uma técnica eficiente para transferência de estilo de vídeo de retrato deve lidar com os seguintes problemas:
- Para preservar movimentos realistas, a abordagem deve ser capaz de lidar com rostos desalinhados e tamanhos de vídeo variados. Um tamanho de vídeo grande ou um ângulo de visão amplo pode capturar mais informações enquanto evita que o rosto saia do quadro.
- Para competir com os gadgets de alta definição comumente utilizados atualmente, é necessário vídeo de alta resolução.
- O controle de estilo flexível deve ser oferecido para que os usuários alterem e escolham sua escolha ao desenvolver um sistema realista de interação com o usuário.
Para isso, os pesquisadores sugerem o VToonify, uma nova estrutura híbrida para tonificação de vídeo. Para superar a restrição de colheita fixa, os pesquisadores primeiro estudam a equivariância de tradução no StyleGAN.
O VToonify combina os benefícios da arquitetura baseada em StyleGAN e a estrutura de tradução de imagem para obter uma transferência ajustável de estilo de vídeo de retrato de alta resolução.
Seguem as principais contribuições:
- Pesquisadores investigam a restrição de corte fixo do StyleGAN e propõem uma solução baseada na equivariância da tradução.
- Os pesquisadores apresentam uma estrutura VToonify totalmente convolucional exclusiva para transferência de estilo de vídeo de retrato de alta resolução controlada que suporta faces não alinhadas e diferentes tamanhos de vídeo.
- Os pesquisadores constroem o VToonify nos backbones do Toonify e DualStyleGAN e condensam os backbones em termos de dados e modelo para permitir a transferência de estilo de vídeo de retrato com base em coleção e com base em exemplos.
Comparando o Vtoonify com outros modelos de última geração
Toonificar
Ele serve como base para a transferência de estilo baseada em coleção em faces alinhadas usando StyleGAN. Para recuperar os códigos de estilo, os pesquisadores devem alinhar rostos e cortar 256256 fotos para PSP. Toonify é usado para gerar um resultado estilizado com códigos de estilo 1024*1024.
Por fim, eles realinham o resultado no vídeo ao local original. A área não estilizada foi definida como preta.

DualStyleGAN
É uma espinha dorsal para a transferência de estilo baseada em exemplos com base no StyleGAN. Eles usam as mesmas técnicas de pré e pós-processamento de dados que o Toonify.
Pix2pix HD
É um modelo de tradução de imagem para imagem que é comumente usado para condensar modelos pré-treinados para edição de alta resolução. Ele é treinado usando dados pareados.
Os pesquisadores utilizam o pix2pixHD como suas entradas de mapa de instância adicionais, pois ele usa o mapa de análise extraído.
Moção de Primeira Ordem
FOM é um modelo típico de animação de imagem. Ele foi treinado em 256256 fotos e tem um desempenho ruim com outros tamanhos de imagem. Como consequência, os pesquisadores primeiro dimensionam os quadros de vídeo para 256*256 para FOM para animação e, em seguida, redimensionam os resultados para o tamanho original.
Para uma comparação justa, FOM emprega o primeiro quadro estilizado de sua abordagem como sua imagem de estilo de referência.
DaGAN
É um modelo de animação de rosto 3D. Eles usam os mesmos métodos de preparação e pós-processamento de dados que o FOM.

Vantagens
- Pode ser empregado nas artes, avatares de mídia social, filmes, publicidade de entretenimento e assim por diante.
- Vtoonify também pode ser utilizado no metaverso.
Limitações
- Essa metodologia extrai os dados e o modelo dos backbones baseados em StyleGAN, resultando em viés de dados e modelo.
- Os artefatos são causados principalmente por diferenças de tamanho entre a região da face estilizada e as demais seções.
- Essa estratégia é menos bem-sucedida ao lidar com coisas na região do rosto.
Conclusão
Finalmente, VToonify é uma estrutura para tonificação de vídeo de alta resolução controlada por estilo.
Essa estrutura alcança ótimo desempenho no manuseio de vídeos e permite amplo controle sobre o estilo estrutural, estilo de cor e grau de estilo, condensando modelos de toonificação de imagem baseados em StyleGAN em termos de dados sintéticos e estruturas de rede.





Deixe um comentário