Vivemos tempos emocionantes, com anúncios sobre tecnologia de ponta toda semana. A OpenAI acaba de lançar o modelo de texto para imagem de ponta DALLE 2.
Apenas algumas pessoas obtiveram acesso antecipado a um novo sistema de IA que pode gerar gráficos realistas a partir de descrições em linguagem natural. Ainda está fechado ao público.
Estabilidade AI então lançou o Difusão Estável model, uma variante de código aberto do DALLE2. Este lançamento mudou tudo. Pessoas de toda a internet publicavam resultados rápidos e se surpreendiam com arte realista.
O que é difusão estável?
Difusão Estável é um modelo de aprendizado de máquina capaz de criar imagens a partir de texto, alterar imagens de acordo com o texto e preencher detalhes em imagens de baixa resolução ou poucos detalhes.
Ele foi treinado em bilhões de fotos e pode fornecer resultados equivalentes a DALL-E2 e Meio da Jornada. IA de estabilidade inventou, e foi tornado público em 22 de agosto de 2022.
Mas com recursos computacionais locais limitados, o modelo Stable Diffusion leva muito tempo para criar imagens de alta qualidade. A execução do modelo online usando um provedor de nuvem nos fornece recursos computacionais quase infinitos e nos permite adquirir excelentes resultados muito mais rapidamente.
Hospedar o modelo como um microsserviço também permite que outros aplicativos criativos explorem mais prontamente o potencial do modelo sem ter que lidar com as complexidades de executar modelos de ML online.
Neste post, tentaremos demonstrar como desenvolver um modelo de difusão estável e implantá-lo na AWS.
Construir e implantar difusão estável
BentoML e Amazon Web Services EC2 são duas opções para hospedar online o modelo Stable Diffusion. BentoML é uma estrutura de código aberto para dimensionamento aprendizado de máquina Serviços. Com o BentoML, criaremos um serviço de dispersão confiável e o implantaremos no AWS EC2.
Preparando o ambiente e baixando o modelo de difusão estável
Instale os requisitos e clone o repositório.
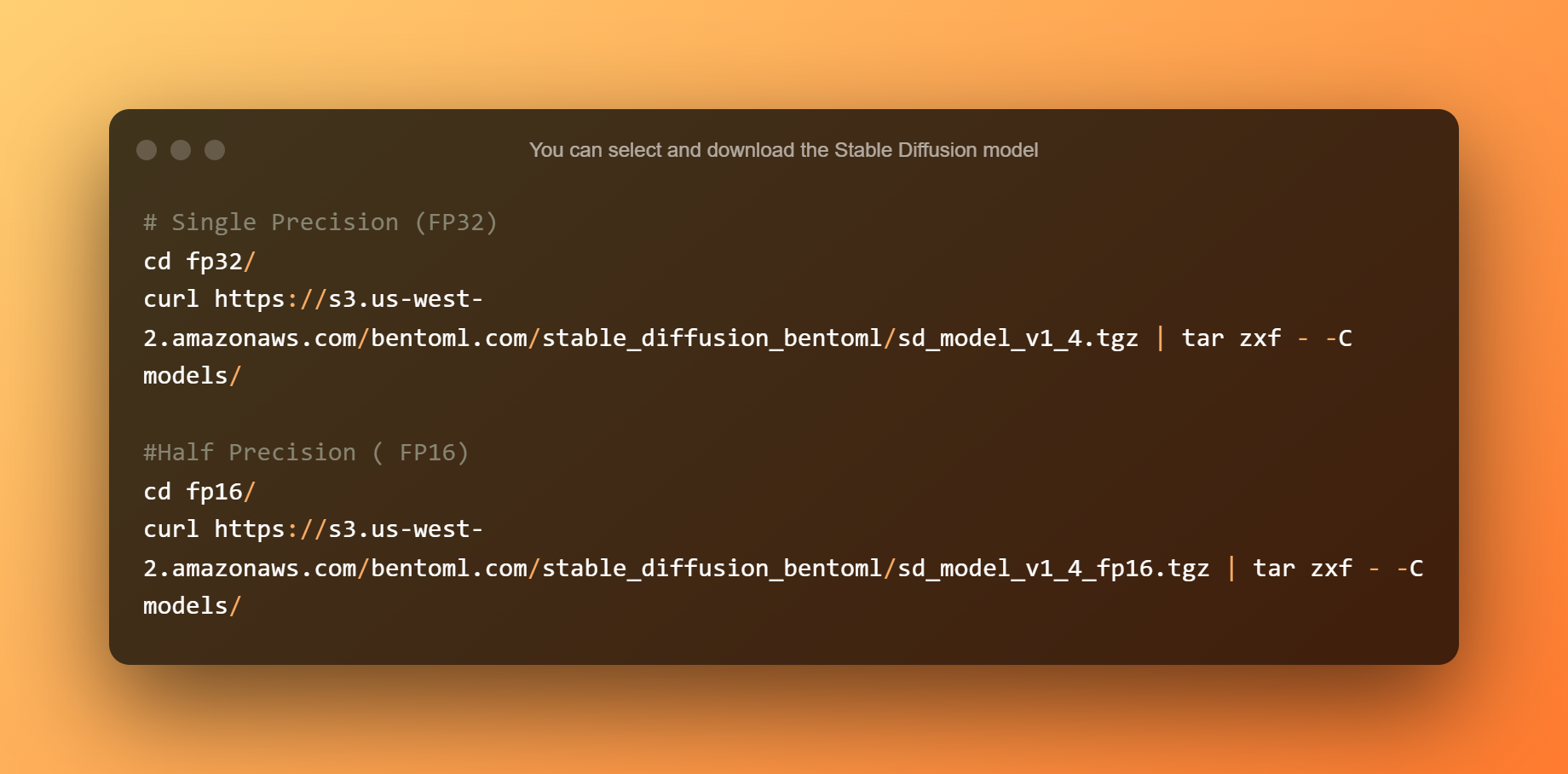
Você pode selecionar e baixar o modelo de difusão estável. A precisão simples é adequada para CPUs ou GPUs com mais de 10 GB de VRAM. Meia precisão é ideal para GPUs com menos de 10 GB de VRAM.
Construindo Difusão Estável
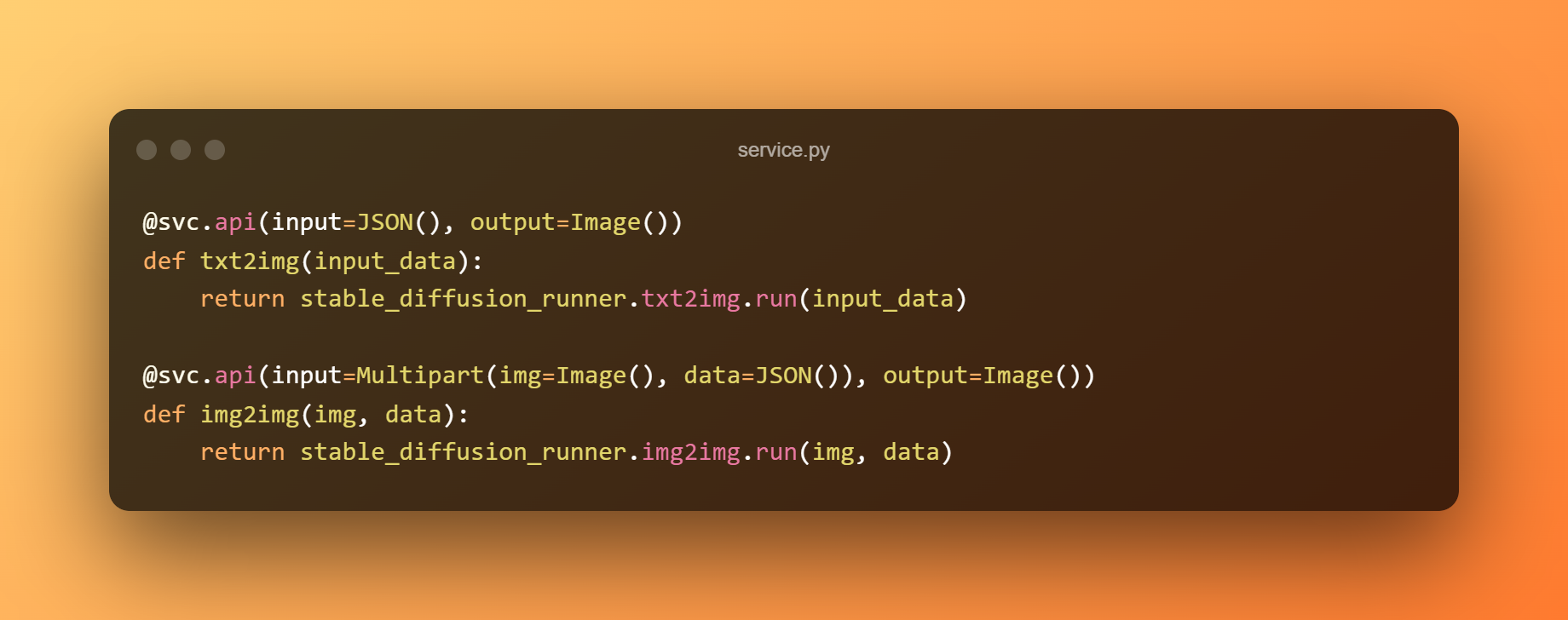
Construiremos um serviço BentoML para servir o modelo por trás de um API RESTful. O exemplo a seguir usa o modelo de precisão única para previsão e o módulo service.py para conectar o serviço à lógica de negócios. Podemos expor as funções como APIs marcando-as com @svc.api.
Além disso, podemos definir os tipos de entrada e saída das APIs nos parâmetros. O endpoint txt2img, por exemplo, recebe uma entrada JSON e produz uma saída Image, enquanto o endpoint img2img aceita uma entrada Image e JSON e retorna uma saída Image.
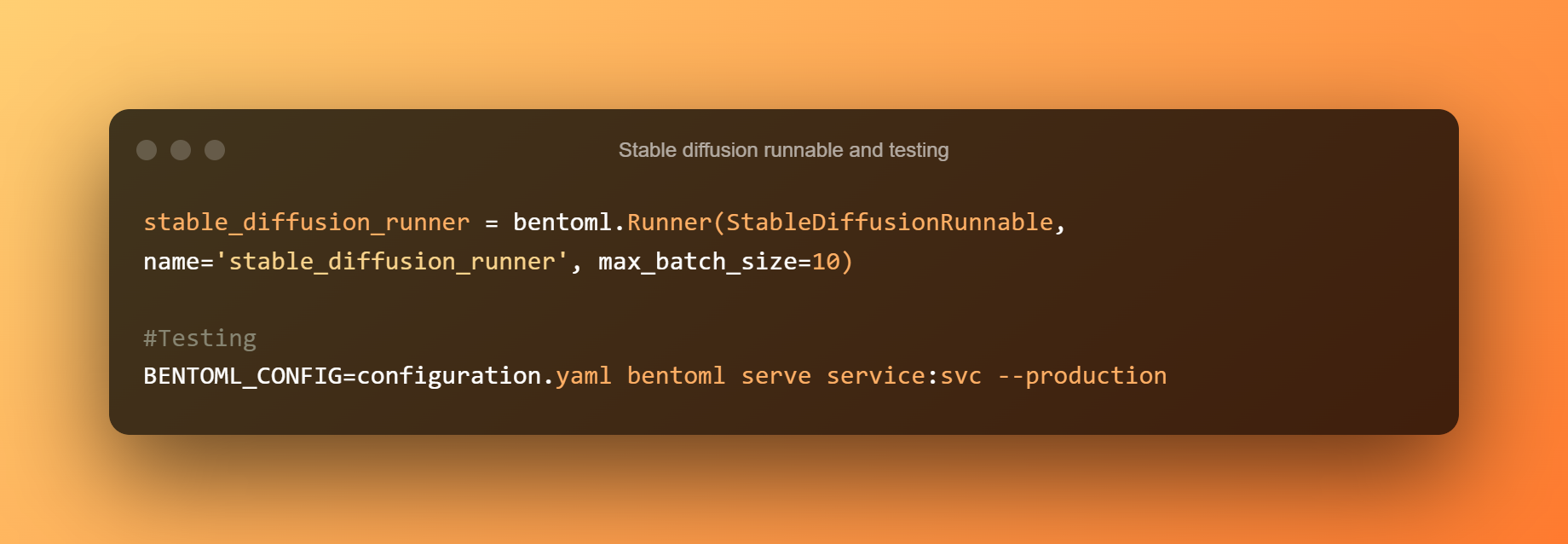
Um StableDiffusionRunnable define a lógica de inferência essencial. O executável é responsável por executar os métodos de tubulação txt2img do modelo e enviar as entradas relevantes. Para executar a lógica de inferência de modelo nas APIs, um Runner personalizado é construído a partir do StableDiffusionRunnable.
Em seguida, use o seguinte comando para iniciar um serviço BentoML para teste. executando localmente o Modelo de difusão estável a inferência em CPUs é bastante lenta. Cada solicitação levará cerca de 5 minutos para ser processada.
Texto para imagem
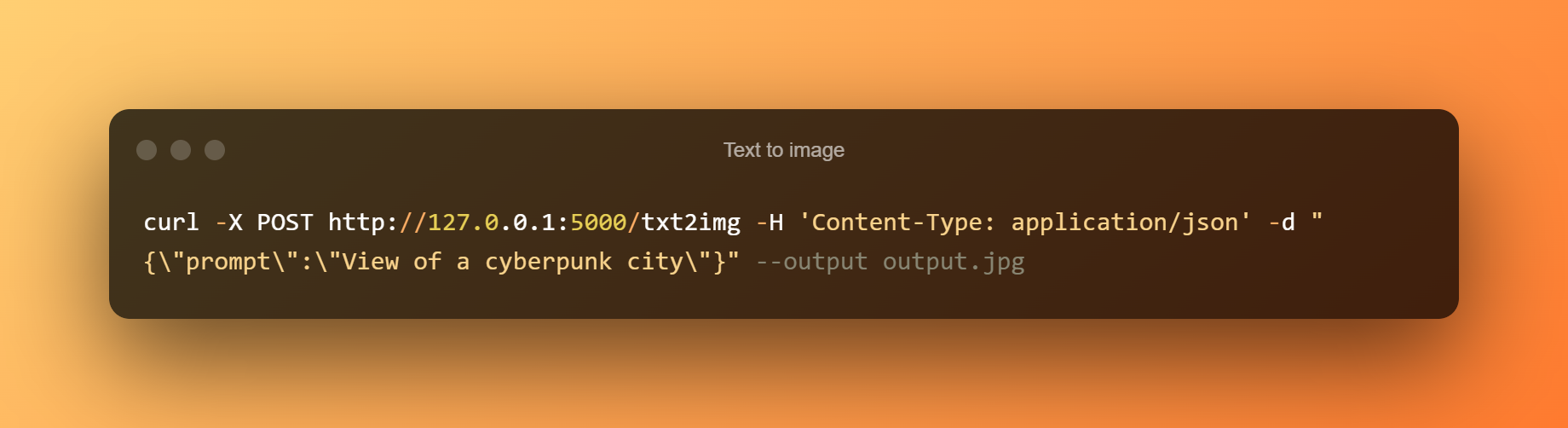
Saída de texto para imagem

O arquivo bentofile.yaml define os arquivos e dependências necessários.
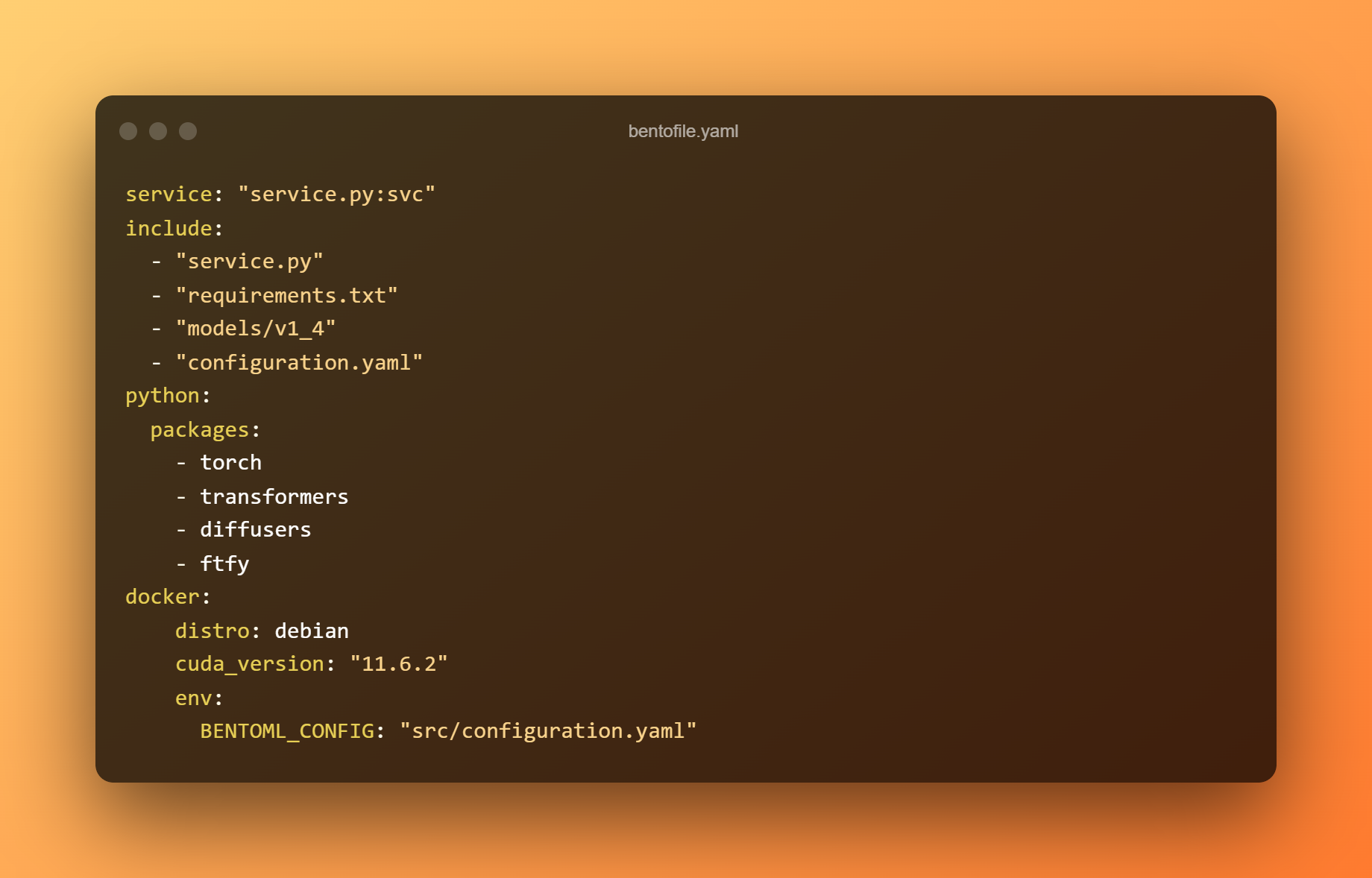
Use o comando abaixo para construir um bento. Um Bento é o formato de distribuição de um serviço BentoML. É um arquivo autocontido que contém todos os dados e configurações necessários para iniciar o serviço.

O bento de difusão estável foi concluído. Se você não conseguiu gerar o bento corretamente, não entre em pânico; você pode baixar o modelo pré-construído usando os comandos listados na próxima seção.
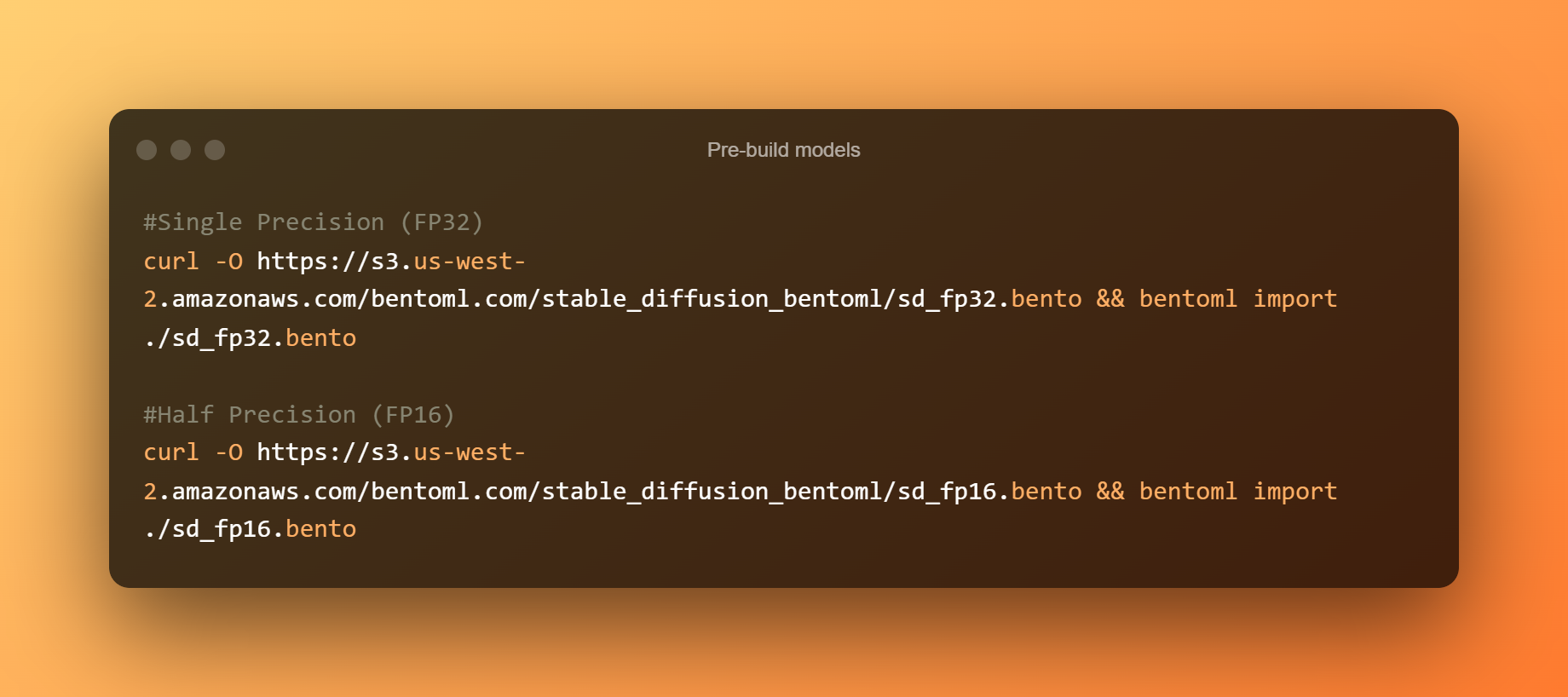
Modelos pré-construídos
A seguir estão os modelos pré-construídos:
Implantar o modelo de difusão estável para EC2
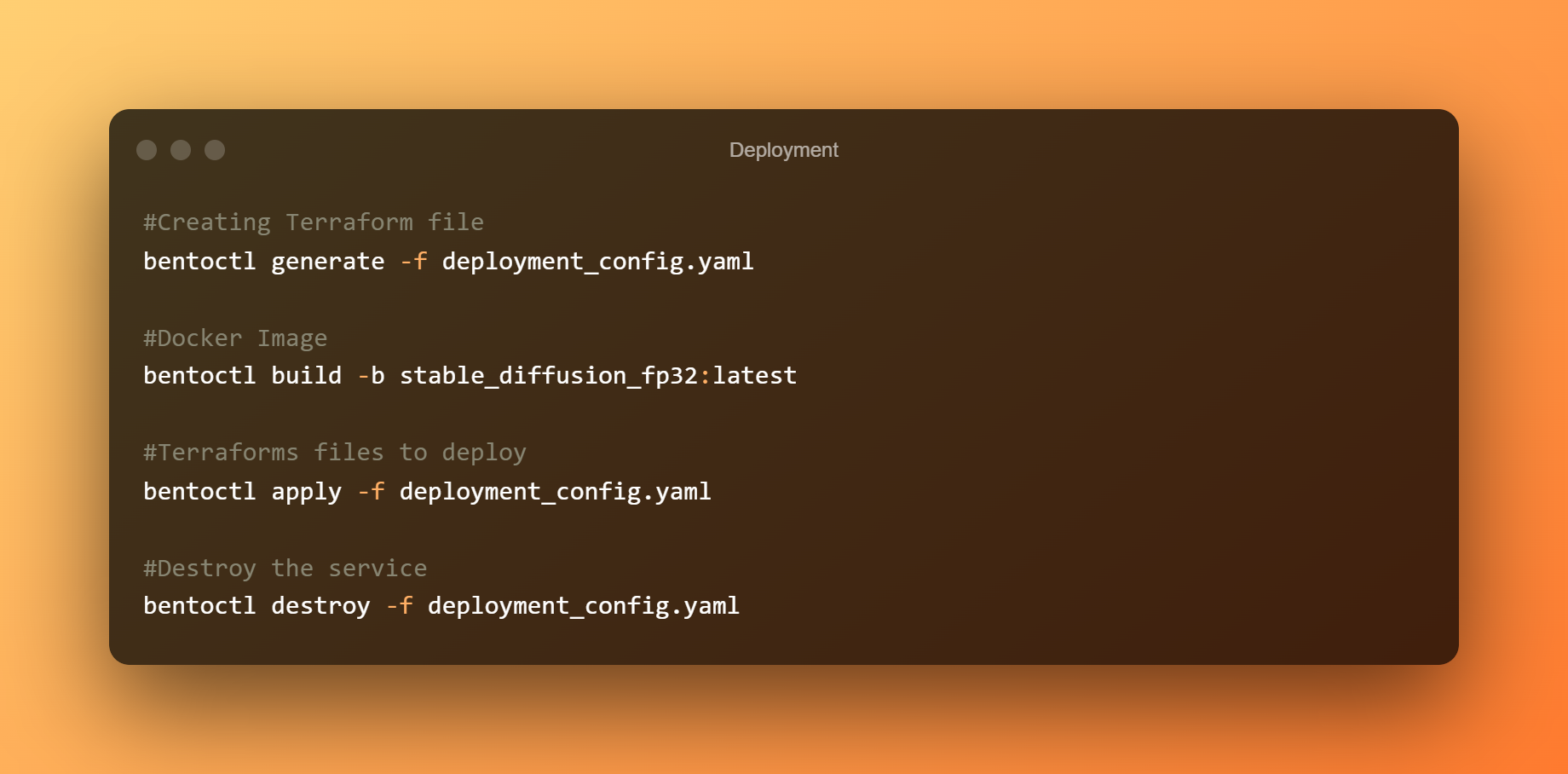
Para implantar o bento no EC2, usaremos o bentoctl. bentoctl pode permitir que você implante seus bentos em qualquer plataforma na nuvem usando o Terraform. Para criar e aplicar arquivos do Terraform, instale o operador AWS EC2.

No arquivo config.yaml de implantação, a implantação já foi configurada. Sinta-se à vontade para editar de acordo com seus requisitos. O Bento é implantado por padrão em um host g4dn.xlarge com o Aprendizagem profunda AMI GPU PyTorch 1.12.0 (Ubuntu 20.04) AMI na região us-west-1.
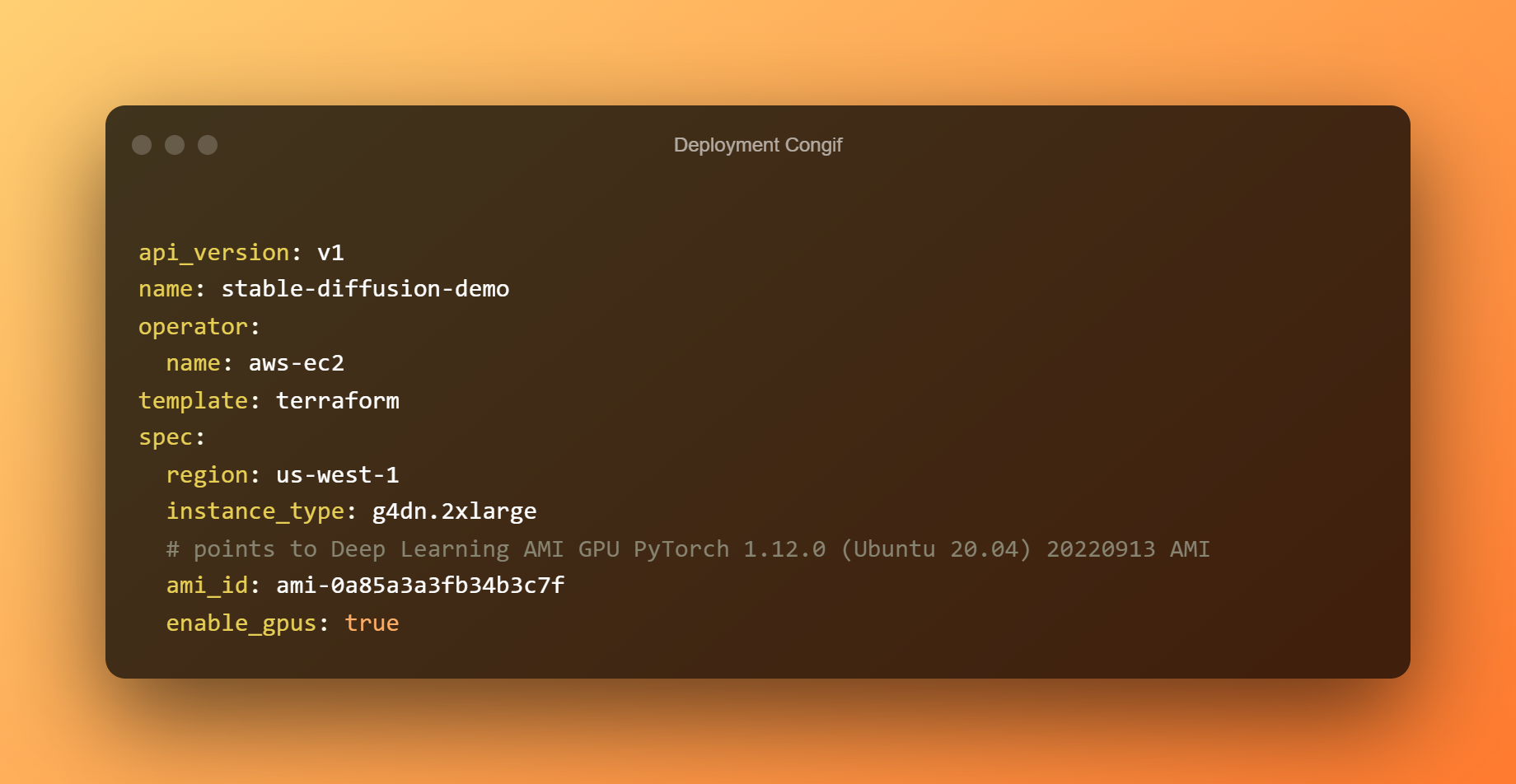
Crie os arquivos do Terraform agora. Crie a imagem do Docker e carregue-a no AWS ECR. Dependendo da sua largura de banda, o upload da imagem pode levar muito tempo. Ao implantar o bento no AWS EC2, use os arquivos do Terraform.
Para acessar a interface do usuário do Swagger, conecte-se ao console do EC2 e abra o endereço IP público em um navegador. Por fim, se o serviço Stable Diffusion BentoML não for mais necessário, remova a implantação.
Conclusão
Você deve ser capaz de ver como o SD e seus modelos complementares são fascinantes e poderosos. O tempo dirá se vamos iterar ainda mais no conceito ou passar para abordagens mais sofisticadas.
No entanto, atualmente existem iniciativas em andamento para treinar modelos maiores com ajustes para melhor compreensão do entorno e das instruções. Tentamos desenvolver o serviço Stable Diffusion usando o BentoML e o implantamos no AWS EC2.
Conseguimos executar o modelo Stable Diffusion em um hardware mais poderoso, criar imagens com baixa latência e ir além de um único computador implantando o serviço no AWS EC2.





Deixe um comentário