A movimentação e o armazenamento de dados cresceram em importância como resultado da constante expansão do setor de TI e dos milhões de pontos de dados que são produzidos a cada segundo.
Além disso, esses dados devem ser claros e simples de compreender para apoiar a tomada de decisões precisas.
Para manter a competitividade e alcançar o sucesso a longo prazo, sua empresa deve armazenar e movimentar dados usando as soluções mais eficientes disponíveis.
Por causa disso, mais empresas estão utilizando malhas de dados. Uma das melhores maneiras de economizar tempo, dinheiro e recursos é usar uma malha de dados para processar dados e permitir o aprendizado de máquina de IA.
Neste artigo, examinaremos detalhadamente o Data Fabric, incluindo seus usos, principais componentes, vantagens e outros detalhes vitais.
Então, o que é o Data Fabric?
Independentemente de onde eles estejam localizados, gerencie e observe seus dados e aplicativos. Em sua essência, uma malha de dados é uma arquitetura de dados integrada que é segura, versátil e adaptável.
Uma malha de dados, que combina o melhor da nuvem, núcleo e borda, é, em muitos aspectos, uma nova abordagem estratégica para a operação de armazenamento de sua empresa.
Embora seja controlado centralmente, ele pode chegar a qualquer lugar, incluindo nuvens locais, públicas e privadas, bem como dispositivos de borda e IoT.
Silos de dados do tamanho de arranha-céus e infraestruturas diversas e desconectadas são coisa do passado. Uma malha de dados é baseada em uma coleção abrangente de ferramentas de gerenciamento de dados que garantem consistência em todos os ambientes vinculados.
Por meio da automação, agiliza o gerenciamento demorado, agiliza o desenvolvimento, o teste e a implantação e protege seus ativos XNUMX horas por dia.
Não importa onde seus dados e aplicativos estejam localizados, você pode acompanhar as despesas de armazenamento, o desempenho e a eficiência de uma única plataforma.
Você pode rapidamente (e, em alguns casos, automaticamente) fazer alterações em sua infraestrutura de nuvem híbrida assim que tiver conhecimento acionável sobre ela, como corrigir erros, resolver problemas de segurança e conformidade e expandir e reduzir a computação.
Em resumo, o Data Fabric melhora a implantação da infraestrutura e a eficiência da manutenção, reduz custos e aumenta o desempenho.
Por que você deve usar um Data Fabric?
Qualquer empresa centrada em dados precisa de uma estratégia abrangente que supere obstáculos como tempo, espaço, vários tipos de software e localizações de dados. Os dados não devem estar escondidos atrás de firewalls ou dispersos em vários lugares, mas devem estar disponíveis para as pessoas que precisam deles.
Para ter sucesso, as empresas precisam de uma solução de dados à prova de futuro e um ambiente seguro, eficaz e unificado. Isso pode ser feito com uma malha de dados.
As necessidades das empresas modernas de conexão em tempo real, autoatendimento, automação e mudanças universais não podem ser atendidas pela integração de dados tradicional.
Embora a coleta de dados de muitas fontes geralmente não seja um problema, muitas empresas lutam para integrar, processar, selecionar e transformar dados com dados de outras fontes.
Para fornecer uma compreensão profunda dos consumidores, parceiros e mercadorias, essa etapa crítica no processo de gerenciamento de dados deve ocorrer. Devido à sua capacidade de atualizar seus sistemas, atender melhor os clientes e fazer uso de computação em nuvem, as empresas ganham uma vantagem competitiva como resultado.
Onde quer que os usuários da organização estejam, a malha de dados pode ser imaginada como um tecido espalhado globalmente. Nessa rede, o usuário pode estar em qualquer local e ainda ter acesso irrestrito e em tempo real aos dados em qualquer outro local.
Componentes principais do Data Fabric
Os componentes principais que compõem uma malha de dados podem ser escolhidos e reunidos de várias maneiras. A malha de dados pode, assim, ser implementada de várias maneiras. Vejamos os elementos primários de uma malha de dados.
- Catálogo de Dados Aumentado
- Camada de Persistência
- Gráfico conhecimento
- Mecanismo de insights e recomendações
- Preparação de dados e camada de entrega de dados
- Orquestração e operações de dados
Você pode dar uma olhada nos principais pilares da arquitetura do Data Fabric de acordo com Gartner.
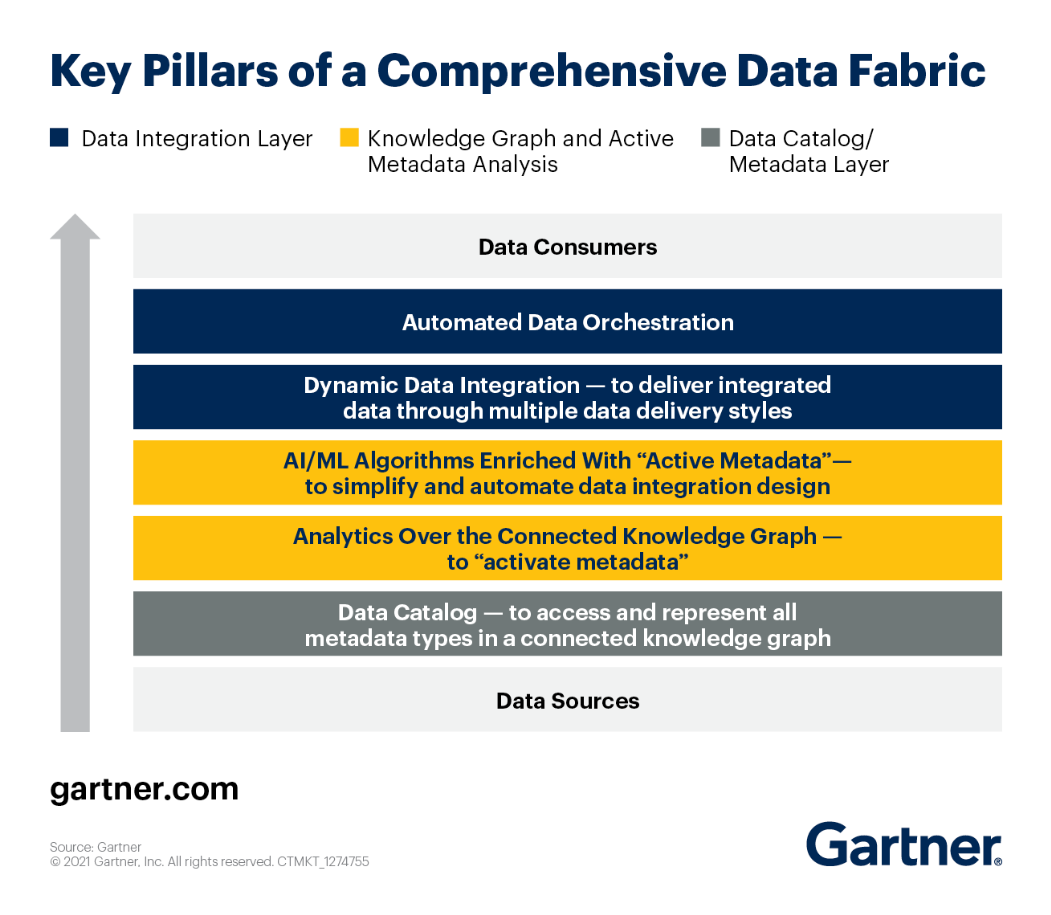
Vejamos cada um deles de perto.
- Catálogo de Dados Aumentado - dá aos usuários acesso a todos os tipos de metadados por meio de um gráfico de conhecimento forte. Além disso, desenvolve associações distintas entre as informações existentes e as mostra visualmente de maneira compreensível. Usando aprendizado de máquina para vincular ativos de dados com terminologia organizacional, catálogos de dados aprimorados criam a camada semântica de negócios para a malha de dados.
- Camada de Persistência – Dependendo do caso de uso, uma variedade de modelos relacionais e não relacionais podem ser usados para armazenar dados dinamicamente.
- Metadados ativos – uma parte distinta de uma malha de dados. dá à malha de dados a capacidade de reunir, compartilhar e analisar vários tipos de metadados. Em contraste com os metadados passivos, os metadados ativos rastreiam o uso contínuo de dados por sistemas e pessoas (metadados baseados em design e em tempo de execução).
- Gráfico conhecimento – Outra unidade fundamental para malhas de dados. Eles usam IDs padrão, esquemas adaptáveis etc. para exibir um ambiente de dados vinculado. Os gráficos de conhecimento tornam a malha de dados pesquisável e auxiliam no seu entendimento.
- Insights e mecanismo de recomendação – cria pipelines de dados confiáveis e fortes para casos de uso operacionais e analíticos.
- Preparação de dados e camada de entrega de dados – Os dados podem ser recuperados de qualquer fonte e enviados para qualquer destino usando qualquer mecanismo, incluindo ETL (em massa), mensagens, CDC, virtualização e API.
- Orquestração e operações de dados – Este componente usa dados para coordenar todas as tarefas em cada estágio do fluxo de trabalho de ponta a ponta. Ele permite que você escolha quando e com que frequência executar pipelines, bem como gerenciar os dados que esses pipelines produzem.
Benefícios
Dados íntegros em um contexto distribuído são acessíveis, carregados, integrados e compartilhados em uma malha de dados. Ao fazer isso, as empresas podem acelerar a transição digital e maximizar o valor de seus dados.
Abaixo estão descritas as principais vantagens do modelo de malha de dados.
Eficiência:
Uma malha de dados pode compilar resultados de consultas anteriores, permitindo que o sistema verifique a tabela agregada em vez dos dados brutos no back-end.
Devido aos tempos de resposta mais rápidos de solicitações individuais, permitir que as solicitações acessem conjuntos de dados menores em vez de verificar os dados brutos do armazenamento completo também resolve o problema de várias solicitações simultâneas.
As empresas podem responder rapidamente a consultas urgentes devido à capacidade da malha de dados de reduzir significativamente os tempos de resposta às consultas.
Integração inteligente
Para integrar dados em diversos tipos de dados e endpoints, as malhas de dados usam gráficos de conhecimento semântico, gerenciamento de metadados e aprendizado de máquina.
Isso ajuda as equipes de gerenciamento de dados a agrupar conjuntos de dados relevantes e incorporar novas fontes de dados ao ecossistema de dados de uma empresa.
Esse recurso automatiza partes do gerenciamento de tarefas de dados, resultando na economia de produtividade indicada acima, mas também ajuda a quebrar os silos do sistema de dados, centralizar os procedimentos de governança de dados e aprimorar a qualidade geral dos dados.
Segurança de dados mais eficaz
Também não implica sacrificar a segurança dos dados e as proteções de privacidade para estender o acesso aos dados.
Na verdade, exige o reforço das barreiras de controle de acesso e a implementação de mais medidas de governança de dados para garantir que determinadas funções sejam as únicas com acesso a um determinado conjunto de dados.
Além disso, as arquiteturas de malha de dados permitem que técnicos e equipes de segurança para implementar mascaramento de dados e criptografia em torno de informações confidenciais e sensíveis, reduzindo a probabilidade de compartilhamento de dados e hacks de sistema.
Democratização de dados
Os aplicativos de autoatendimento são facilitados por designs de malha de dados, estendendo o alcance do acesso a dados além de mais pessoal técnico, como engenheiros de dados, desenvolvedores e equipes de análise de dados.
Ao permitir que os usuários de negócios façam escolhas de negócios mais rápidas e ao liberar os usuários técnicos para priorizar as atividades que melhor utilizam seus conjuntos de habilidades, a eliminação de gargalos de dados leva a um aumento na produtividade.
Os casos de uso
Uma arquitetura de malha de dados destina-se a oferecer uma estrutura abrangente para lidar com todas as formas de informações armazenadas para que possam ser utilizadas quando necessário.
Esses tipos de dados podem ser usados para qualquer coisa, desde uma previsão de vendas até um relatório sobre o estado da infraestrutura de TI de uma organização ou terminais de usuário.
Os casos de uso da arquitetura de malha de dados são idênticos aos casos de uso de qualquer outro tipo de dados em uma empresa, incluindo vendas, marketing, TI, segurança cibernética e muito mais.
No entanto, os dados em uma organização geralmente são organizados, semiestruturados ou não estruturados em quase todos os casos de uso. Um banco de dados relacional pode armazenar dados estruturados e ser prontamente utilizado, como registros de banco de dados.
Os dados que não foram limpos ou categorizados são chamados de dados não estruturados e devem ser preparados para uso quando necessário.
Várias formas de dados não estruturados que muitas empresas podem adquirir e armazenar para uso futuro incluem aprendizado de máquina, análises, dados de sensores, computação em nuvem e aplicativos de produtividade.
Em dados semiestruturados, que incluem dados de um tipo reconhecido salvos com dados não estruturados (como arquivos zip, páginas da web e e-mails), ambos os aspectos estão presentes.
Numerosos casos de uso possíveis com base na capacidade da malha de dados de ajudar as empresas a acessar e usar seus dados de forma mais rápida e eficaz podem ser encontrados pesquisando seu uso.
Exemplos típicos incluem:
- Detecção de fraude
- Análise IoT
- Logística da cadeia de suprimentos
- Análise de dados em tempo real
- Inteligência do cliente
- Aumento da eficiência operacional
- Análise de manutenção preventiva
- Além disso, os modelos de risco de retorno ao trabalho
- Garantia de transações com cartões de crédito
- Previsão de churn, detecção de fraudes e pontuação de crédito
Conclusão
Em conclusão, os silos de dados devem se desintegrar progressivamente à medida que nossos níveis de uso de dados aumentam para abrir espaço para empresas conectadas.
A implantação de malhas de dados representa um avanço significativo nesse caminho, classificando-se entre as descobertas mais inovadoras desde o desenvolvimento de bancos de dados relacionais na década de 1970.
Isso ocorre porque a malha de dados é mais do que uma tecnologia ou um único item.
Dados e operações de negócios estão intrinsecamente entrelaçados por meio do design da arquitetura, um procedimento sistemático e uma mudança de mentalidade.
O Data Fabric reduz custos, aumenta o desempenho e facilita a implantação e manutenção de infraestrutura mais eficazes. Pode ser o componente-chave para garantir que cada processo, aplicativo e decisão de negócios seja orientado por dados.





Deixe um comentário