A nova e aprimorada IA melhorou as habilidades, a compreensão e a capacidade de produzir imagens de alta resolução. Você pode ter se deparado recentemente com algumas imagens estranhas e divertidas circulando pela internet.
Um cão Shiba Inu está vestido com uma boina e uma gola alta preta. E uma lontra-marinha à maneira da “Garota com brinco de pérola” do pintor holandês Vermeer. E há uma xícara de sopa que parece um monstro lanoso.
essas imagens não foram criados por um artista humano.
Em vez disso, DALL-E 2, um novo sistema de IA que pode converter descrições textuais em imagens, as criou.
Basta escrever o que você quer ver e a IA criará para você – com detalhes vívidos, ótima qualidade e, em alguns casos, inventividade genuína. Neste post, vamos dar uma olhada no último estudo da OpenAI, DALL.E 2, bem como como ele funciona e muito mais. Vamos começar.
Então, o que exatamente é DALL.E 2?
O DALL-E 2 é um “modelo generativo”, um tipo de algoritmo de aprendizado de máquina que gera saídas complicadas em vez de realizar tarefas de previsão ou classificação nos dados de entrada.
Você fornece ao DALL-E 2 uma descrição escrita e ele cria uma imagem que corresponde a ele. Ao combinar conceitos, qualidades e estilos, o DALLE 2 da OpenAI pode produzir gráficos e arte inovadores e realistas a partir de uma descrição linguística básica.
A versão mais recente, DALLE 2, é considerada mais versátil, capaz de fazer fotos a partir de legendas em resoluções mais altas e em um espectro mais amplo de estilos criativos. Por exemplo, as fotos abaixo (da postagem do blog DALL-E 2) são criadas pela descrição “Um astronauta andando a cavalo”.
Uma descrição conclui “como um esboço a lápis”, enquanto a outra conclui “de maneira fotorrealista”.

Também pode alterar as fotografias existentes com uma precisão surpreendente. Assim, você pode adicionar ou excluir elementos mantendo cores, reflexos e sombras, mantendo a aparência da imagem original.
Como funciona o Tech & Data Studio:
O DALL-E 2 utiliza os modelos CLIP e difusão, dois sofisticados deep learning abordagens desenvolvidas nos últimos anos. No entanto, baseia-se na mesma noção que todas as outras redes neurais: aprendizagem de representação. O CLIP treina simultaneamente dois redes neurais em fotos e legendas.
Uma rede aprende as representações visuais na imagem, enquanto a outra aprende as representações de texto. Durante o treinamento, as duas redes tentam modificar seus parâmetros para que imagens e descrições comparáveis resultem em incorporações semelhantes.
A “difusão”, um tipo de modelo generativo que aprende a fazer imagens gradualmente ruidosamente e desobstruindo suas amostras de treinamento, é a outra abordagem de aprendizado de máquina utilizada no DALL-E 2. Os modelos de difusão são semelhantes aos autoencoders, pois transformam os dados de entrada em um representação de incorporação e, em seguida, use as informações de incorporação para recriar os dados originais.
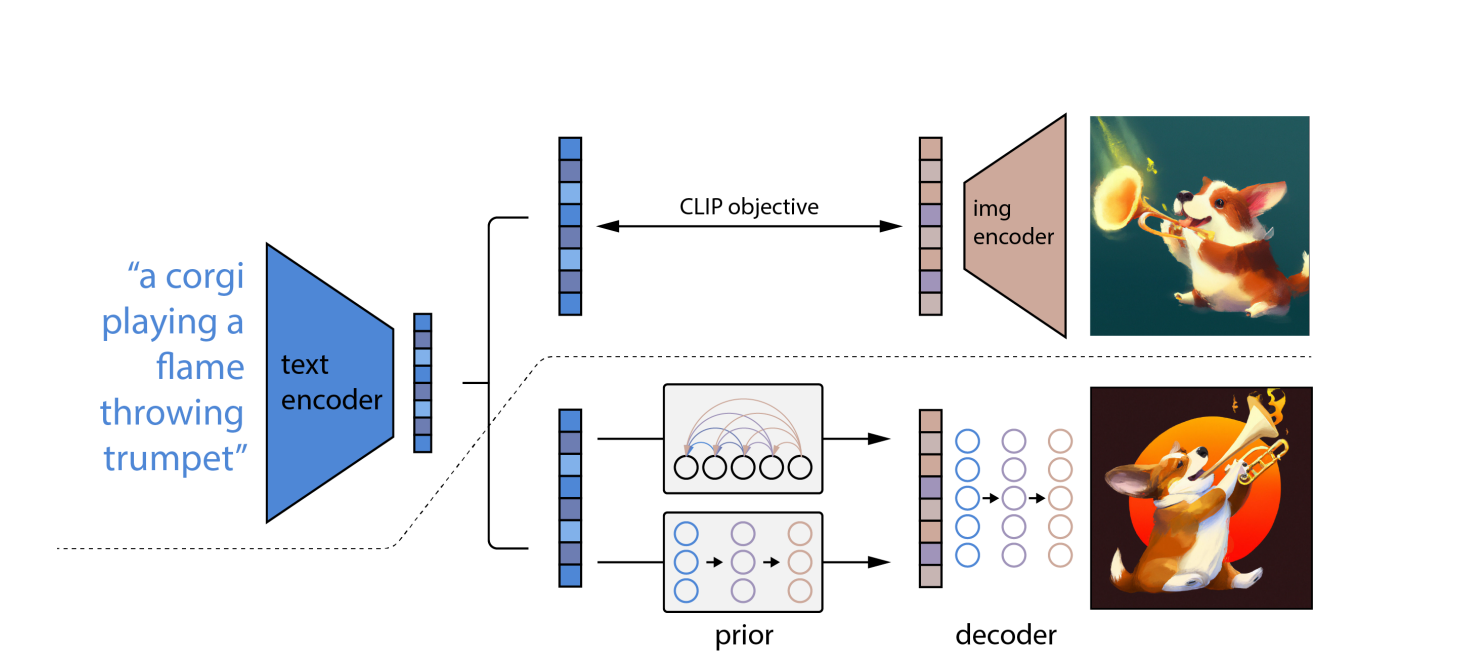
Usando OpenAIs modelo de linguagem O CLIP, que pode conectar descrições textuais com fotografias, primeiro traduz o prompt escrito em uma forma intermediária que incorpora as propriedades cruciais que uma imagem deve ter para corresponder a esse prompt (de acordo com o CLIP).
Em segundo lugar, o DALL-E 2 cria um arquivo compatível com CLIP imagem usando um modelo de difusão, que é uma rede neural.
Em fotos distorcidas com pixels aleatórios, os modelos de difusão são aprendidos. Eles aprendem como restaurar a forma original das fotos. Os modelos de difusão podem produzir imagens sintéticas de alta qualidade, especialmente quando usados em conjunto com uma abordagem de orientação que prioriza a precisão sobre a diversidade.
Como conseqüência, modelo de difusão pega os pixels aleatórios e usa o CLIP para convertê-los em uma nova imagem que corresponda à palavra prompt. Devido ao conceito de difusão, o DALL-E 2 pode produzir imagens de alta resolução mais rapidamente do que o DALL-E.
Caso de uso DALL.E 2
Nos últimos vinte anos, visão computacional a tecnologia progrediu de uma noção simples para um grande avanço. Apesar desses avanços, os modelos de reconhecimento de imagens e objetos ainda enfrentam obstáculos significativos na vida cotidiana. A ausência de conjuntos de dados é uma das desvantagens mais significativas do reconhecimento de imagem e da visão computacional. Como há escassez de dados em ambas as extremidades, treinar modelos de reconhecimento de imagem para fornecer resultados 100% precisos é quase difícil.
Felizmente, o novo modelo de aprendizado de máquina da OpenAI pode preencher a lacuna na tecnologia. DALLE 2 é capaz de gerar imagens incríveis com base em descrições de texto. Essa produção de imagem falsa pode fornecer dados para modelos de reconhecimento de imagem com base em seus requisitos. A ausência de dados é um obstáculo significativo para a identificação de objetos e imagens.
Na era digital, os conjuntos de dados são onipresentes, mas ainda estamos procurando atalhos para alimentar o modelo de IA, para que ele possa fornecer bons resultados. No entanto, não é simples treinar um modelo de reconhecimento de imagem. Ela exige um grande número de conjuntos de dados com pequenas diferenças, que talvez não tenhamos conseguido recuperar de forma simples.
Então, qual é a resposta: A resposta é DALLE 2. O gerador de imagens OpenAI, com sua capacidade de produzir imagens a partir de textos e alterar as existentes, pode ajudar a preencher a lacuna. Isso ajudará na geração de dados de treinamento adicionais e, ao mesmo tempo, reduzirá a quantidade de rotulagem humana necessária. Apesar do benefício significativo, você deve estar ciente de produções de imagens fraudulentas e imagens que excluem a inclusão. Isso pode levar a métodos de detecção de imagem produzindo resultados tendenciosos.
Limitações
O DALL.E 2 pode ter uma influência prejudicial se cair em mãos erradas, de acordo com a OpenAI. No mundo de deep fakes de hoje, o modelo pode ser facilmente usado para espalhar informações falsas ou imagens racistas, e é por isso que o OpenAI só permite que os desenvolvedores usem o DALL.2 por convite. A modelo deve cumprir uma rigorosa restrição de conteúdo para todas as sugestões que receber.
Para excluir o potencial do DALL.E 2 de criar quaisquer imagens hostis ou violentas, o conjunto de dados foi criado sem qualquer armamento mortal. Embora o OpenAI tenha declarado que planeja transformá-lo em uma API no futuro, no caso do DALL.E 2, está disposto a proceder com cautela.
Conclusão
DALL-E 2 é outra descoberta interessante da pesquisa OpenAI que abre as portas para novos aplicativos.
Um exemplo é a criação de grandes conjuntos de dados para atender a um dos principais gargalos da visão computacional – os dados. Embora o caso econômico de muitos aplicativos baseados em DALL-E seja determinado pelo preço e pelas políticas que a OpenAI estabelece para seus usuários de API, todos eles, sem dúvida, avançarão na produção de imagens.





Deixe um comentário