Spis treści[Ukryć][Pokazać]
Firmy przechwytują więcej danych niż kiedykolwiek, ponieważ w coraz większym stopniu polegają na nich przy podejmowaniu ważnych decyzji biznesowych, ulepszaniu oferty produktów i zapewnianiu lepszej obsługi klienta.
Dzięki ilości danych tworzonych w tempie wykładniczym chmura oferuje szereg korzyści w zakresie przetwarzania i analizy danych, w tym skalowalność, niezawodność i dostępność.
W ekosystemie chmury istnieje również kilka narzędzi i technologii do przetwarzania i analizy danych. Dwa rodzaje struktur przechowywania danych big data, które są najczęściej wykorzystywane, to hurtownie danych i jeziora danych.
Chociaż korzystanie z jeziora danych jest mniej atrakcyjne, ponieważ nie można wysyłać zapytań do modelu i danych, gdy są one nadal istotne, korzystanie z magazynu danych do przechowywania danych strumieniowych jest marnotrawstwem.

Wjaki rodzaj architektury chmury wybieramy?
Czy powinniśmy rozważyć nowsze koncepcje dotyczące Data Lakehouse, czy powinniśmy zadowolić się ograniczeniami magazynu lub ograniczeniami jeziora?
Nowatorska architektura przechowywania danych, zwana „domem jeziora danych”, łączy możliwości adaptacyjne jezior danych z zarządzaniem danymi w hurtowniach danych.
Zrozumienie różnych metod przechowywania dużych zbiorów danych jest niezbędne do zbudowania niezawodnego potoku przechowywania danych na potrzeby analizy biznesowej (BI), analizy danych i uczenie maszynowe (ML), w zależności od wymagań Twojej firmy.
W tym poście przyjrzymy się bliżej hurtowniom danych, Data Lake i Data Lakehouse, wraz z ich zaletami, ograniczeniami oraz zaletami i wadami. Zaczynajmy.
Co to jest hurtownia danych?
Hurtownia danych to scentralizowane repozytorium danych używane przez organizację do przechowywania ogromnych ilości danych z wielu źródeł. Hurtownia danych działa jako jedyne źródło „prawdy danych” dla organizacji i jest niezbędna do raportowania i analizy biznesowej.
Zazwyczaj hurtownie danych łączą relacyjne zestawy danych z kilku źródeł, takich jak dane aplikacyjne, biznesowe i transakcyjne, w celu przechowywania danych historycznych. Przed załadowaniem do systemu magazynowego dane są przekształcane i oczyszczane w hurtowniach danych, dzięki czemu mogą być wykorzystywane jako pojedyncze źródło prawdziwości danych.
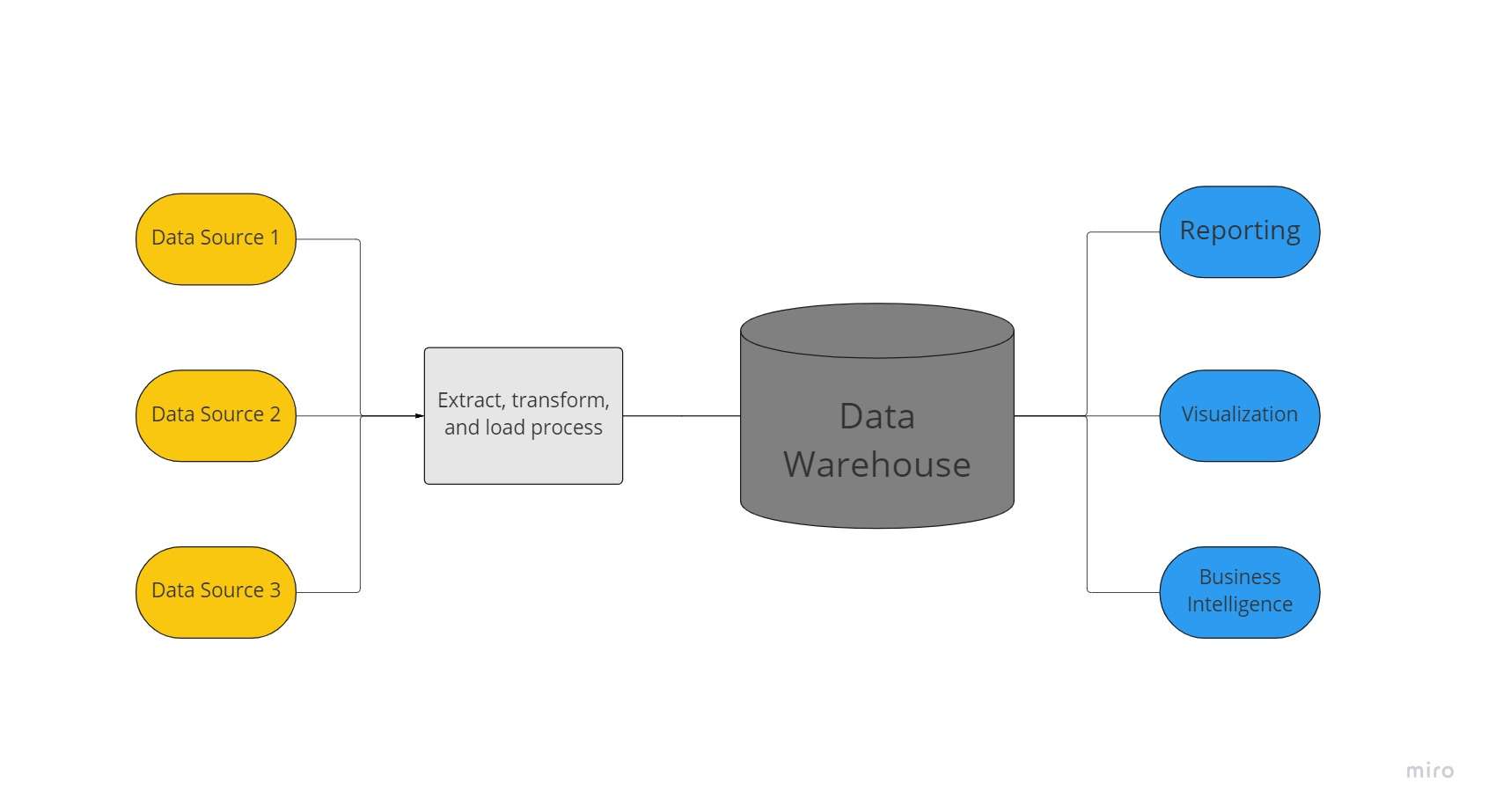
Ze względu na ich zdolność do szybkiego oferowania informacji biznesowych ze wszystkich obszarów firmy, firmy inwestują w hurtownie danych. Z wykorzystaniem narzędzi BI, klientów SQL i innych mniej zaawansowanych (tj. nie data science) rozwiązań analitycznych, analitycy biznesowi, inżynierowie danych i decydenci mogą uzyskać dostęp do danych z hurtowni danych.
Utrzymanie hurtowni ze stale rosnącą ilością danych jest kosztowne, a hurtownia danych nie może obsługiwać danych surowych lub nieustrukturyzowanych. Ponadto nie jest to idealna opcja dla zaawansowanych technik analizy danych, takich jak uczenie maszynowe lub modelowanie predykcyjne.
Hurtownia danych zapewnia zatem szybsze odpowiedzi na zapytania i dane o wyższej jakości. Google Big Query, Amazon Redshift, Azure SQL Data Warehouse i Snowflake to usługi w chmurze dostępne dla hurtowni danych.
Korzyści z hurtowni danych
- Zwiększenie wydajności i szybkości obciążeń związanych z analizą biznesową i analizą danych: Hurtownie danych skracają czas potrzebny na przygotowanie i analizę danych. Mogą łatwo łączyć się z narzędziami do analizy danych i analizy biznesowej, ponieważ dane z hurtowni danych są niezawodne i spójne. Ponadto hurtownie danych oszczędzają czas potrzebny na zbieranie danych i zapewniają zespołom możliwość wykorzystania danych do raportów, pulpitów nawigacyjnych i innych wymagań analitycznych.
- Zwiększenie spójności, jakości i standaryzacji danych: Organizacje zbierają dane z różnych źródeł, w tym dane dotyczące użytkowników, sprzedaży i transakcji. Firma może zaufać danym w zakresie wymagań biznesowych, ponieważ hurtownie danych kompilują dane firmowe do jednolitego, znormalizowanego formatu, który może działać jako pojedyncze źródło prawdziwości danych.
- Ogólne usprawnienie procesu decyzyjnego: Hurtownia danych ułatwia podejmowanie lepszych decyzji, oferując scentralizowany magazyn zarówno dla najnowszych, jak i starych danych. Przetwarzając dane w hurtowniach danych w celu uzyskania dokładnych informacji, decydenci mogą oceniać ryzyko, rozumieć potrzeby klientów oraz ulepszać towary i usługi.
- Zapewnienie lepszej analizy biznesowej: Hurtownia danych wypełnia lukę między ogromnymi nieprzetworzonymi danymi, które są często rutynowo gromadzone jako rzecz oczywistą, a wyselekcjonowanymi danymi, które zapewniają wgląd. Działają jako podstawa przechowywania danych organizacji, umożliwiając odpowiadanie na skomplikowane pytania dotyczące jej danych i wykorzystywanie odpowiedzi do podejmowania uzasadnionych decyzji biznesowych.
Ograniczenia Hurtowni Danych
- Brak elastyczności danych: Podczas gdy hurtownie danych doskonale radzą sobie z obsługą danych ustrukturyzowanych, formaty danych częściowo ustrukturyzowanych i nieustrukturyzowanych, takie jak analiza logów, przesyłanie strumieniowe i dane z mediów społecznościowych, mogą być dla nich wyzwaniem. To sprawia, że rekomendowanie hurtowni danych dla przypadków użycia związanych z uczeniem maszynowym i sztuczna inteligencja trudny.
- Kosztowne w instalacji i utrzymaniu: Hurtownie danych mogą być kosztowne w instalacji i utrzymaniu. Ponadto hurtownia danych często nie jest statyczna; starzeje się i wymaga częstej konserwacji, co jest kosztowne.
ZALETY
- Dane można łatwo znaleźć, pobrać i przeszukać.
- Dopóki dane są już czyste, przygotowanie danych SQL jest proste.
Wady
- Jesteś zmuszony korzystać tylko z jednego dostawcy analiz.
- Analizowanie i przechowywanie danych nieustrukturyzowanych lub przepływających jest dość kosztowne.
Co to jest jezioro danych?
Każdy rodzaj danych jest obiecany i możliwy dzięki jeziorach danych. Korzystne jest posiadanie danych w przystępny sposób, centralnie ulokowanych i dostępnych do odczytu.
Jezioro danych to scentralizowana, niezwykle elastyczna przestrzeń dyskowa, w której ogromne ilości uporządkowanych i nieustrukturyzowanych danych są przechowywane w ich nieprzetworzonej, niezmienionej i niesformatowanej formie.
Data Lake wykorzystuje płaską architekturę i obiekty przechowywane w stanie nieprzetworzonym do przechowywania danych, w przeciwieństwie do hurtowni danych, które zapisują dane relacyjne, które wcześniej zostały „wyczyszczone”.
Jeziora danych, w przeciwieństwie do hurtowni danych, które mają trudności z obsługą danych w tym formacie, są elastyczne, niezawodne i niedrogie oraz umożliwiają przedsiębiorstwom uzyskanie lepszego wglądu w dane nieustrukturyzowane.
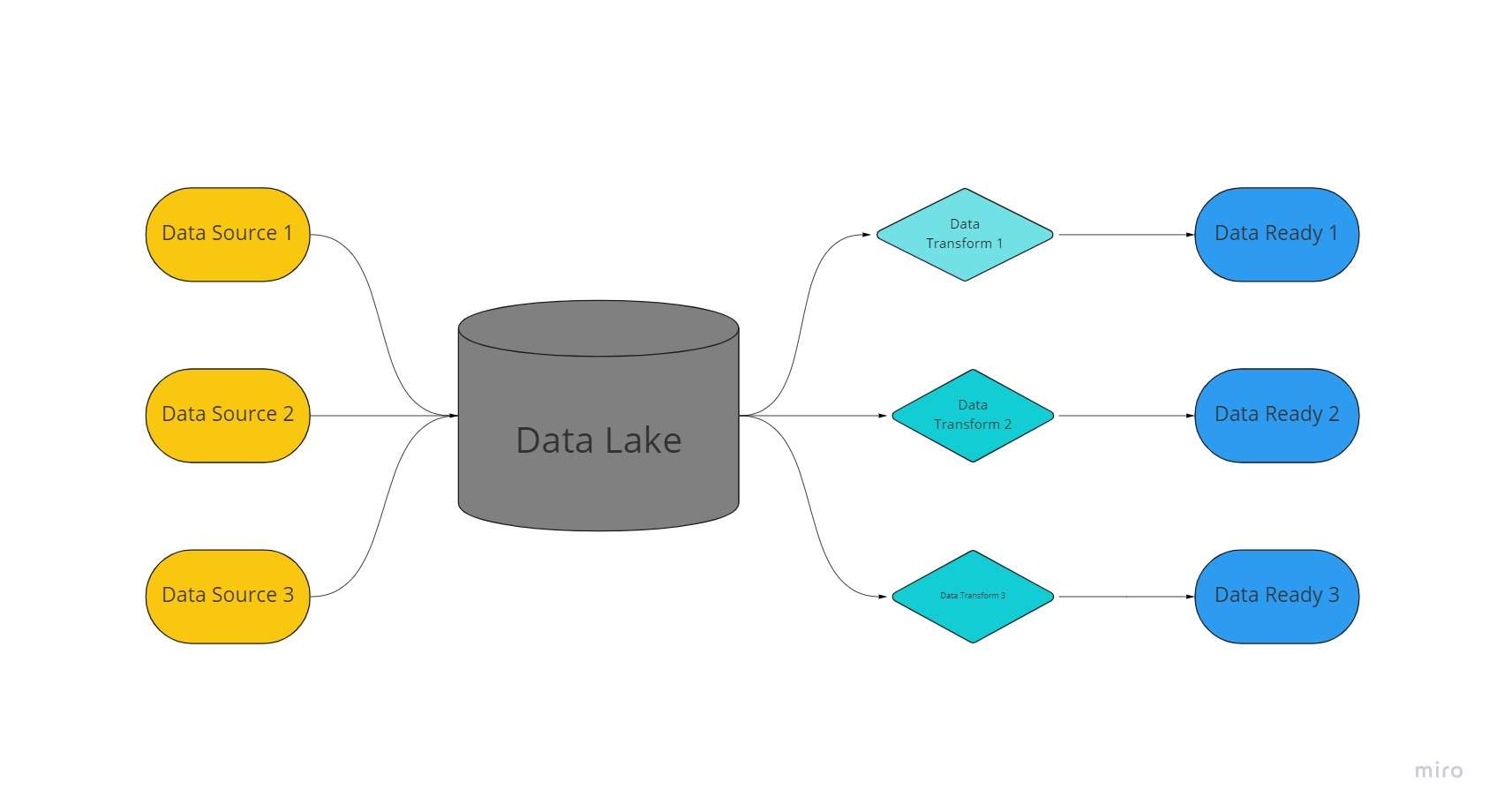
W jeziorach danych dane są wyodrębniane, ładowane i przekształcane (ELT) do celów analitycznych, a nie w celu ustalenia schematu lub danych w momencie gromadzenia danych.
Wykorzystanie technologii dla wielu rodzajów danych z urządzeń IoT, Media społecznościowe, a strumieniowe przesyłanie danych, jeziora danych umożliwiają uczenie maszynowe i analizę predykcyjną.
Ponadto specjalista ds. danych, który może przetwarzać nieprzetworzone dane, może korzystać z jeziora danych. Z drugiej strony hurtownia danych jest łatwiejsza w użyciu dla firm. Idealnie nadaje się do profilowania użytkowników, analityka predykcyjna, uczenie maszynowe i inne zadania.
Chociaż jeziora danych rozwiązują kilka problemów z hurtowniami danych, ich jakość danych jest niska, a szybkość zapytań niewystarczająca. Dodatkowo wymaga dodatkowych narzędzi dla użytkowników biznesowych do wykonywania zapytań SQL. Jezioro danych o słabej strukturze może mieć problem ze stagnacją danych.
Korzyści z Data Lake
- Obsługa szerokiego zakresu zastosowań uczenia maszynowego i analizy danych Łatwiej jest używać różnych algorytmów uczenia maszynowego i głębokiego uczenia do obsługi danych w jeziorach danych, ponieważ dane są przechowywane w sposób otwarty, nieprzetworzony.
- Dużą zaletą jest wszechstronność Data Lakes, która umożliwia przechowywanie danych w dowolnym formacie lub nośniku bez konieczności stosowania gotowego schematu. Przyszłe przypadki użycia danych mogą być obsługiwane, a więcej danych można przeanalizować, jeśli dane pozostaną w oryginalnym stanie.
- Aby uniknąć konieczności przechowywania obu typów danych w różnych kontekstach, jeziora danych mogą zawierać zarówno dane strukturalne, jak i nieustrukturyzowane. Do przechowywania różnego rodzaju danych organizacyjnych oferują jedną lokalizację.
- W porównaniu z tradycyjnymi hurtowniami danych, jeziora danych są tańsze, ponieważ są zbudowane tak, aby można je było przechowywać na niedrogim, standardowym sprzęcie, takim jak obiektowa pamięć masowa, która często jest nastawiona na niższy koszt za jeden gigabajt przechowywany.
Ograniczenia Data Lake
- Przypadki użycia analizy danych i analizy biznesowej osiągają słabe wyniki: jeziora danych mogą stać się niezorganizowane, jeśli nie są odpowiednio konserwowane, co utrudnia połączenie ich z narzędziami analizy biznesowej i analitycznej. Dodatkowo, gdy jest to konieczne do raportowania i analizy przypadków użycia, brak spójnego struktury danych a obsługa transakcyjna ACID (niepodzielność, spójność, izolacja i trwałość) może prowadzić do nieoptymalnej wydajności zapytań.
- Niespójność jezior danych uniemożliwia wyegzekwowanie niezawodności i bezpieczeństwa danych, co skutkuje brakiem obu. Opracowanie odpowiednich standardów bezpieczeństwa i zarządzania danymi w celu obsługi wrażliwych typów danych może być trudne, ponieważ jeziora danych mogą obsługiwać dowolny formularz danych.
ZALETY
- Rozwiązania dostępne dla wszystkich rodzajów danych.
- Potrafi obsługiwać dane, które są zarówno zorganizowane, jak i częściowo ustrukturyzowane.
- Idealny do skomplikowanego przetwarzania danych i przesyłania strumieniowego.
Wady
- Potrzebuje zaawansowanego potoku do zbudowania.
- Daj dane trochę czasu, aby stały się możliwe do odpytywania.
- Gwarantowanie niezawodności i jakości danych wymaga czasu.
Co to jest Data Lakehouse?
Nowatorska architektura przechowywania dużych zbiorów danych, zwana „domem jezior danych”, łączy w sobie najlepsze aspekty jezior danych i hurtowni danych. Wszystkie dane, zarówno ustrukturyzowane, częściowo ustrukturyzowane, jak i nieustrukturyzowane, mogą być przechowywane w jednym miejscu dzięki najlepszym możliwym funkcjom uczenia maszynowego, analizy biznesowej i przesyłania strumieniowego dzięki Data Lakehouse.
Jeziora danych wszelkiego rodzaju są często punktem wyjścia dla Data Lakehouses; następnie dane są przekształcane do formatu Delta Lake (warstwa pamięci masowej typu open source, która zapewnia niezawodność w jeziorach danych).
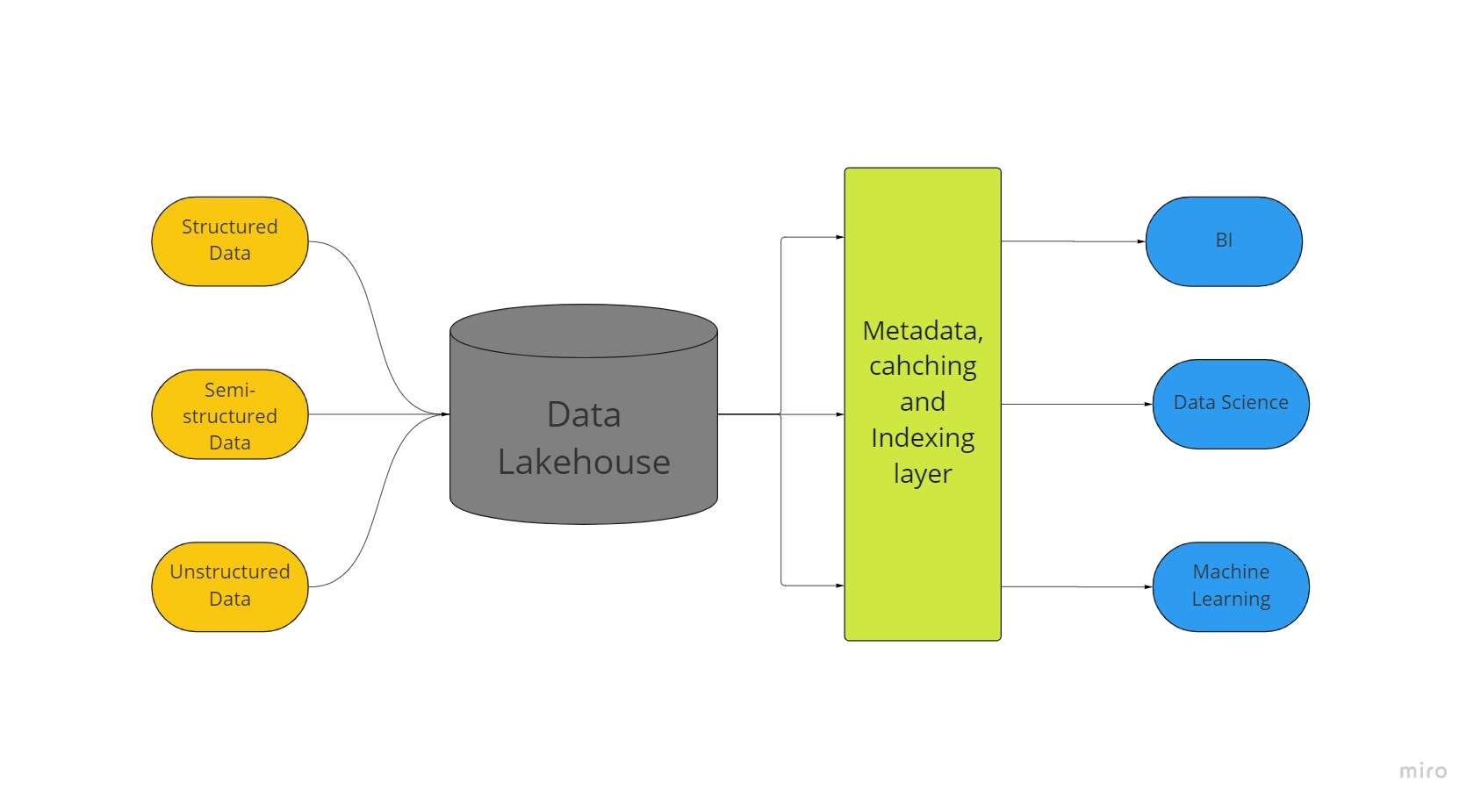
Jeziora danych z jeziorami delta umożliwiają procedury transakcyjne ACID z konwencjonalnych hurtowni danych. Zasadniczo system Lakehouse wykorzystuje niedrogą pamięć masową do przechowywania ogromnych ilości danych w ich oryginalnej formie, podobnie jak jeziora danych.
Dodanie warstwy metadanych na górze sklepu zapewnia również strukturę danych i wzmacnia narzędzia do zarządzania danymi, takie jak te, które można znaleźć w hurtowniach danych.
Dzięki temu wiele zespołów może uzyskiwać dostęp do wszystkich danych firmy za pośrednictwem jednego systemu dla różnych inicjatyw, takich jak analiza danych, uczenie maszynowe i analiza biznesowa.
Korzyści z Data Lakehouse
- Obsługa większego zakresu obciążeń: Aby ułatwić zaawansowane analizy, Data Lakehouses zapewniają użytkownikom bezpośredni dostęp do niektórych z najpopularniejszych narzędzi do analizy biznesowej (Tableau, PowerBI). Ponadto naukowcy zajmujący się danymi i inżynierowie uczenia maszynowego mogą z łatwością korzystać z danych, ponieważ Data Lakehouses wykorzystują formaty otwartych danych (takie jak Parquet) wraz z interfejsami API i platformami uczenia maszynowego, takimi jak Python/R.
- Opłacalność: Data Lakehouses wykorzystują niedrogie rozwiązania obiektowej pamięci masowej w celu wdrożenia opłacalnych charakterystyk pamięci masowej Data Lakes. Oferując jedno rozwiązanie, Data Lakehouses eliminują również wydatki i czas związane z zarządzaniem różnymi systemami przechowywania danych.
- Projekt Data Lakehouse zapewnia integralność schematu i danych, ułatwiając tworzenie skutecznych systemów bezpieczeństwa i zarządzania danymi. Łatwość wersjonowanie danych, zarządzanie i bezpieczeństwo.
- Data lakehouses oferują pojedynczą, wielofunkcyjną platformę do przechowywania danych, która może spełnić wszystkie wymagania firmy dotyczące danych, co ogranicza powielanie danych. Większość firm wybiera rozwiązanie hybrydowe ze względu na zalety zarówno hurtowni danych, jak i jeziora danych. W międzyczasie taka strategia może skutkować kosztownym powielaniem danych.
- Wsparcie otwartych formatów. Otwarte formaty to typy plików, które mogą być używane przez wiele aplikacji i których specyfikacje są publicznie dostępne. Według doniesień Lakehouses są w stanie przechowywać dane w popularnych formatach plików, takich jak Apache Parquet i ORC (Optimized Row Columnar).
Ograniczenia Data Lakehouse
Największą wadą Data Lakehouse jest to, że jest to wciąż młoda i rozwijająca się technologia. Nie ma pewności, czy w rezultacie wywiąże się ze swoich zobowiązań. Zanim jeziora danych będą mogły konkurować z uznanymi systemami przechowywania dużych zbiorów danych, może minąć wiele lat.
Jednak biorąc pod uwagę tempo, w jakim pojawiają się nowoczesne innowacje, trudno powiedzieć, czy inny system przechowywania danych ostatecznie go nie zastąpi.
ZALETY
- Jedna platforma zawiera wszystkie dane, co oznacza, że trzeba utrzymywać mniej nazw hostów.
- Atomowość, spójność, izolacja i wytrzymałość pozostają nienaruszone.
- Jest znacznie tańszy.
- Jedna platforma zawiera wszystkie dane, co oznacza, że trzeba utrzymywać mniej nazw hostów.
- Proste w zarządzaniu i szybkie naprawianie wszelkich problemów
- Uprość budowę rurociągu
Wady
- Konfiguracja może zająć trochę czasu.
- Jest zbyt młody i zbyt odległy, aby kwalifikować się jako ustalony system przechowywania.
Hurtownia danych vs Data Lake vs Data Lakehouse
Hurtownia danych ma długą historię w aplikacjach do analizy, raportowania i analizy korporacyjnej i jest pierwszą technologią przechowywania dużych zbiorów danych.
Z drugiej strony hurtownie danych są drogie i mają problemy z obsługą zróżnicowanych i nieustrukturyzowanych danych, takich jak dane strumieniowe. W przypadku obciążeń związanych z uczeniem maszynowym i analizą danych opracowano jeziora danych umożliwiające zarządzanie nieprzetworzonymi danymi w różnych formach w niedrogiej pamięci masowej.
Chociaż jeziora danych są skuteczne w przypadku danych nieustrukturyzowanych, brakuje im możliwości transakcyjnych ACID hurtowni danych, co utrudnia zagwarantowanie spójności i niezawodności danych.
Najnowsza architektura przechowywania danych, znana jako „data lakehouse”, łączy niezawodność i spójność hurtowni danych z przystępną ceną i możliwościami adaptacji jezior danych.
Wnioski
Podsumowując, zbudowanie od podstaw Data Lakehouse może być trudne. Co więcej, prawie na pewno będziesz korzystać z platformy zaprojektowanej w celu umożliwienia architektury Open Data Lakehouse.
Dlatego przed dokonaniem zakupu należy uważnie zbadać wiele funkcji i implementacji każdej platformy. Firmy poszukujące dojrzałego, ustrukturyzowanego rozwiązania danych, skupiającego się na analizach biznesowych i przypadkach użycia analizy danych, mogą rozważyć hurtownię danych.
Jednak przedsiębiorstwa poszukujące skalowalnego, przystępnego cenowo rozwiązania Big Data do obsługi obciążeń związanych z analizą danych i uczeniem maszynowym na danych nieustrukturyzowanych powinny rozważyć jeziora danych.
Weź pod uwagę, że Twoja firma potrzebuje więcej danych, niż może dostarczyć hurtownia danych i technologie Data Lake, lub że szukasz rozwiązania integrującego zaawansowane operacje analityczne i uczenie maszynowe na Twoich danych. A Lakehouse danych jest rozsądną opcją w tej sytuacji.





Dodaj komentarz