Spis treści[Ukryć][Pokazać]
Nowa i ulepszona sztuczna inteligencja poprawiła zdolności, zrozumienie i zdolność do tworzenia obrazów o wyższej rozdzielczości. Być może natknąłeś się ostatnio na dziwne i zabawne obrazy unoszące się w Internecie.
Pies Shiba Inu ubrany jest w beret i czarny golf. I wydra morska w stylu „Dziewczyny z perłą” holenderskiego malarza Vermeera. I jest kubek zupy, który wygląda jak włochaty potwór.
Te obrazy nie zostały stworzone przez ludzkiego artystę.
Zamiast tego stworzył je DALL-E 2, nowy system sztucznej inteligencji, który może konwertować opisy tekstowe na obrazy.
Po prostu napisz, co chcesz zobaczyć, a sztuczna inteligencja stworzy to za Ciebie – z żywymi szczegółami, świetną jakością, a w niektórych przypadkach prawdziwą inwencją. W tym poście przyjrzymy się bliżej najnowszemu badaniu OpenAI, DALL.E 2, a także temu, jak to działa, i nie tylko. Zacznijmy.
Czym dokładnie jest? DALL.E 2?
DALL-E 2 to „model generatywny”, rodzaj algorytmu uczenia maszynowego, który generuje skomplikowane dane wyjściowe zamiast wykonywać zadania przewidywania lub klasyfikacji na danych wejściowych.
Dajesz DALL-E 2 pisemny opis, a on tworzy obraz, który mu odpowiada. Łącząc koncepcje, cechy i style, dalle 2 OpenAI może tworzyć innowacyjną, realistyczną grafikę i sztukę na podstawie podstawowego opisu językowego.
Mówi się, że najnowsza wersja, DALLE 2, jest bardziej wszechstronna, umożliwiająca tworzenie zdjęć z podpisów w wyższej rozdzielczości i w szerszym spektrum kreatywnych stylów. Na przykład poniższe zdjęcia (z wpisu na blogu DALL-E 2) są tworzone przez opis „Astronauta na koniu”.
Jeden opis kończy się „jak szkic ołówkiem”, podczas gdy drugi kończy się „w sposób fotorealistyczny”.

Potrafi także zmieniać istniejące fotografie z zadziwiającą precyzją. Można więc dodawać lub usuwać elementy, zachowując kolory, odbicia i cienie, a wszystko to przy zachowaniu oryginalnego wyglądu obrazu.
Jak to działa?
DALL-E 2 wykorzystuje modele CLIP i dyfuzyjne, dwa wyrafinowane głęboka nauka podejścia opracowane w ostatnich latach. Opiera się jednak na tym samym założeniu, co wszystkie inne głębokie sieci neuronowe: nauka reprezentacji. CLIP jednocześnie trenuje dwa sieci neuronowe na zdjęciach i podpisach.
Jedna sieć uczy się reprezentacji wizualnych na obrazie, podczas gdy druga uczy się reprezentacji tekstowych. Podczas uczenia obie sieci próbują modyfikować swoje parametry, tak aby porównywalne obrazy i opisy dawały podobne osadzania.
„Dyfuzja”, rodzaj modelu generatywnego, który uczy się robić obrazy poprzez stopniowe zaszumianie i odszumianie próbek treningowych, to inne podejście do uczenia maszynowego wykorzystywane w DALL-E 2. Modele dyfuzji są podobne do autokoderów, ponieważ przekształcają dane wejściowe w reprezentacji osadzania, a następnie użyj informacji o osadzeniu, aby odtworzyć oryginalne dane.
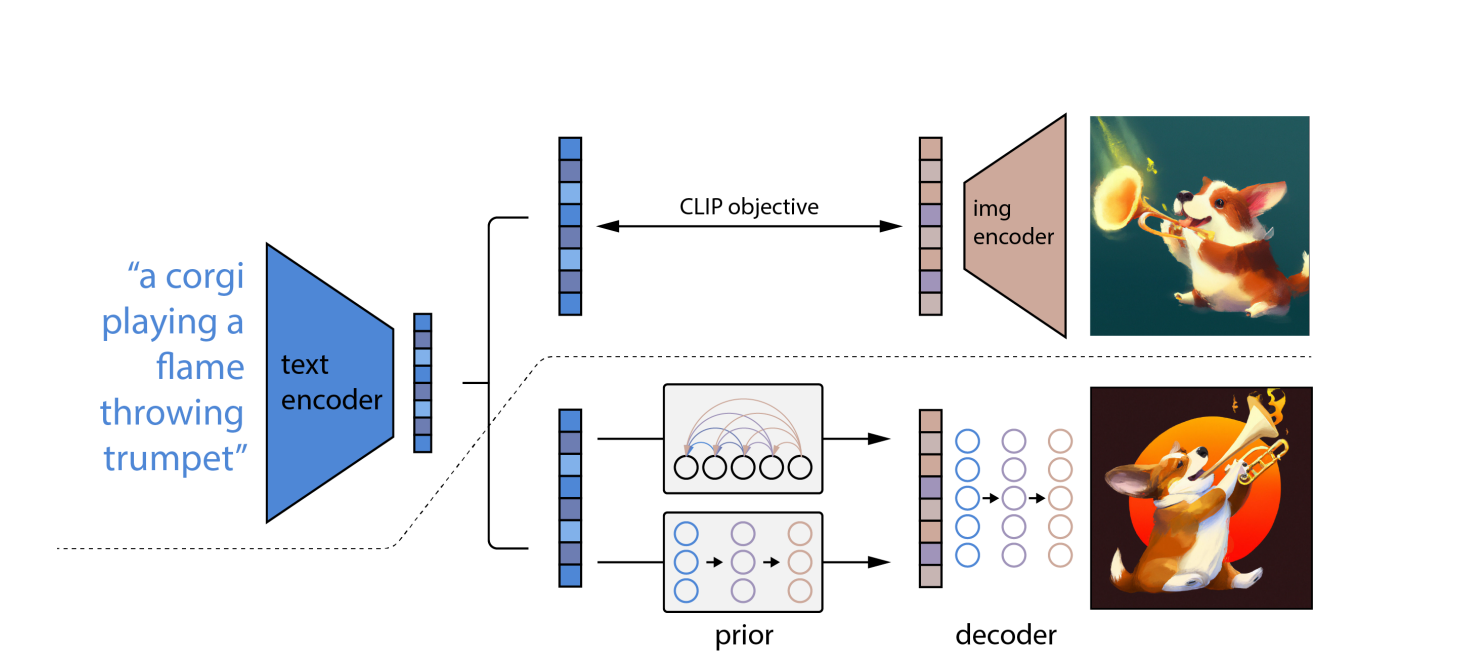
Korzystanie z OpenAI model języka CLIP, który może łączyć opisy tekstowe z fotografiami, najpierw tłumaczy pisemną podpowiedź na formę pośrednią, która zawiera kluczowe właściwości, jakie powinien mieć obraz, aby pasował do tej podpowiedzi (zgodnie z CLIP).
Po drugie, DALL-E 2 tworzy zgodny z CLIP obraz za pomocą modelu dyfuzyjnego, który jest siecią neuronową.
Na zniekształconych zdjęciach z losowymi pikselami wyuczone są modele dyfuzji. Uczą się, jak przywrócić zdjęciom pierwotną formę. Modele dyfuzyjne mogą generować wysokiej jakości obrazy syntetyczne, zwłaszcza w połączeniu z podejściem przewodnim, które przedkłada dokładność nad różnorodność.
W związku z tym model dyfuzyjny pobiera losowe piksele i używa CLIP do konwersji ich na nowy obraz, który pasuje do zachęty słowa. Ze względu na koncepcję dyfuzji, DALL-E 2 może wytwarzać obrazy o wyższej rozdzielczości szybciej niż DALL-E.
DALL.E 2 przypadek użycia
W ciągu ostatnich dwudziestu lat wizja komputerowa technologia rozwinęła się od prostego pojęcia do wielkiego przełomu. Pomimo tych postępów modele rozpoznawania obrazów i obiektów wciąż napotykają na poważne przeszkody w życiu codziennym. Brak zbiorów danych jest jedną z najbardziej znaczących wad rozpoznawania obrazów i widzenia komputerowego. Ponieważ po obu stronach brakuje danych, szkolenie modeli rozpoznawania obrazu w celu uzyskania 100% dokładnych wyników jest prawie trudne.
Na szczęście nowy model uczenia maszynowego OpenAI może wypełnić lukę w technologii. DALLE 2 jest w stanie generować niesamowite zdjęcia na podstawie opisów tekstowych. Ta produkcja fałszywego obrazu może dostarczać dane do modeli rozpoznawania obrazu w oparciu o ich wymagania. Brak danych jest istotną przeszkodą w identyfikacji obiektów i obrazów.
W erze cyfrowej zbiory danych są wszechobecne, ale wciąż szukamy skrótów do zasilania modelu AI, aby mógł zapewnić dobre wyniki. Jednak wytrenowanie modelu rozpoznawania obrazów nie jest proste. Wymaga to dużej liczby zestawów danych z niewielkimi różnicami, których moglibyśmy nie być w stanie po prostu odzyskać.
A więc, jaka jest odpowiedź: odpowiedzią jest DALLE 2. Generator obrazów OpenAI, który może tworzyć obrazy z tekstów i zmieniać już istniejące, może pomóc wypełnić lukę. Pomoże to w generowaniu dodatkowych danych treningowych, a jednocześnie zmniejszy ilość wymaganego oznakowania ludzkiego. Pomimo znaczących korzyści, należy być świadomym oszukańczych produkcji obrazów i obrazów, które wykluczają włączenie. Może to prowadzić do tego, że metody wykrywania obrazów dadzą wyniki stronnicze.
Ograniczenia
Według OpenAI DALL.E 2 może mieć szkodliwy wpływ, jeśli wpadnie w niepowołane ręce. W dzisiejszym świecie głębokich fałszerstw model ten można łatwo wykorzystać do rozpowszechniania fałszywych informacji lub rasistowskich obrazów, dlatego OpenAI pozwala programistom używać DALL.2 tylko na zaproszenie. Modelka musi przestrzegać rygorystycznego ograniczenia treści dla wszystkich otrzymywanych sugestii.
Aby wykluczyć możliwość tworzenia przez DALL.E 2 jakichkolwiek wrogich lub brutalnych zdjęć, zestaw danych został utworzony bez żadnej śmiercionośnej broni. Chociaż OpenAI oświadczył, że planuje przekształcić go w API w przyszłości, w przypadku DALL.E 2 jest gotów postępować ostrożnie.
Wnioski
DALL-E 2 to kolejne interesujące odkrycie badawcze OpenAI, które otwiera drzwi do nowych zastosowań.
Jednym z przykładów jest tworzenie ogromnych zbiorów danych w celu rozwiązania jednego z głównych wąskich gardeł wizji komputerowej – danych. Chociaż ekonomiczne uzasadnienie dla wielu aplikacji opartych na DALL-E będzie determinowane przez cenę i zasady, które OpenAI ustanowi dla swoich użytkowników API, wszystkie one niewątpliwie przyspieszą produkcję zdjęć.





Dodaj komentarz