Innholdsfortegnelse[Gjemme seg][Forestilling]
Vi kan nå beregne omfanget av rommet og de små forviklingene til subatomære partikler takket være datamaskiner.
Datamaskiner slår mennesker når det gjelder telling og beregning, samt følger logiske ja/nei-prosesser, takket være elektroner som beveger seg med lysets hastighet via kretsene.
Imidlertid ser vi dem ikke ofte som "intelligente", siden datamaskiner tidligere ikke kunne utføre noe uten å bli undervist (programmert) av mennesker.
Maskinlæring, inkludert dyp læring og kunstig intelligens, har blitt et buzzword i vitenskapelige og teknologiske overskrifter.
Maskinlæring ser ut til å være allestedsnærværende, men mange mennesker som bruker ordet vil slite med å definere hva det er, hva det gjør og hva det best brukes til.
Denne artikkelen søker å tydeliggjøre maskinlæring samtidig som den gir konkrete eksempler fra den virkelige verden på hvordan teknologien fungerer for å illustrere hvorfor den er så nyttig.
Deretter skal vi se på de ulike maskinlæringsmetodene og se hvordan de brukes til å møte forretningsutfordringer.
Til slutt vil vi konsultere krystallkulen vår for noen raske spådommer om fremtiden for maskinlæring.
Hva er maskinlæring?
Maskinlæring er en disiplin innen informatikk som gjør det mulig for datamaskiner å utlede mønstre fra data uten å bli eksplisitt lært hva disse mønstrene er.
Disse konklusjonene er ofte basert på bruk av algoritmer for automatisk å vurdere de statistiske egenskapene til dataene og utvikle matematiske modeller for å skildre forholdet mellom ulike verdier.
Sammenlign dette med klassisk databehandling, som er basert på deterministiske systemer, der vi eksplisitt gir datamaskinen et sett med regler som skal følges for at den skal utføre en bestemt oppgave.
Denne måten å programmere datamaskiner på er kjent som regelbasert programmering. Maskinlæring skiller seg fra og overgår regelbasert programmering ved at den kan utlede disse reglene på egen hånd.
Anta at du er en banksjef som ønsker å finne ut om en lånesøknad kommer til å mislykkes på lånet.
I en regelbasert metode vil banksjefen (eller andre spesialister) uttrykkelig informere datamaskinen om at dersom søkerens kredittscore er under et visst nivå, bør søknaden avvises.
Imidlertid vil et maskinlæringsprogram ganske enkelt analysere tidligere data om kunders kredittvurderinger og låneresultater og bestemme hva denne terskelen skal være alene.
Maskinen lærer av tidligere data og lager sine egne regler på denne måten. Selvfølgelig er dette bare en primer om maskinlæring; virkelige maskinlæringsmodeller er betydelig mer kompliserte enn en grunnleggende terskel.
Ikke desto mindre er det en utmerket demonstrasjon av potensialet til maskinlæring.
Hvordan fungerer a maskin lære?
For å gjøre ting enkelt, "lærer" maskiner ved å oppdage mønstre i sammenlignbare data. Betrakt data som informasjon du samler inn fra omverdenen. Jo mer data en maskin mates, jo "smartere" blir den.
Imidlertid er ikke alle data like. Anta at du er en pirat med et livsformål å avdekke de begravde rikdommene på øya. Du vil ha en betydelig mengde kunnskap for å finne premien.
Denne kunnskapen, som data, kan enten ta deg på riktig eller feil måte.
Jo større informasjon/data som innhentes, jo mindre tvetydighet er det, og omvendt. Som et resultat er det viktig å vurdere hva slags data du mater maskinen din for å lære av.
Men når en betydelig mengde data er gitt, kan datamaskinen lage spådommer. Maskiner kan forutse fremtiden så lenge den ikke avviker mye fra fortiden.
Maskiner "lærer" ved å analysere historiske data for å finne ut hva som sannsynligvis vil skje.
Hvis de gamle dataene ligner de nye dataene, vil det du kan si om de tidligere dataene sannsynligvis gjelde for de nye dataene. Det er som om du ser tilbake for å se fremover.
Hva er typene maskinlæring?
Algoritmer for maskinlæring klassifiseres ofte i tre brede typer (selv om andre klassifiseringsordninger også brukes):
- Veiledet læring
- Uovervåket læring
- Forsterkningslæring
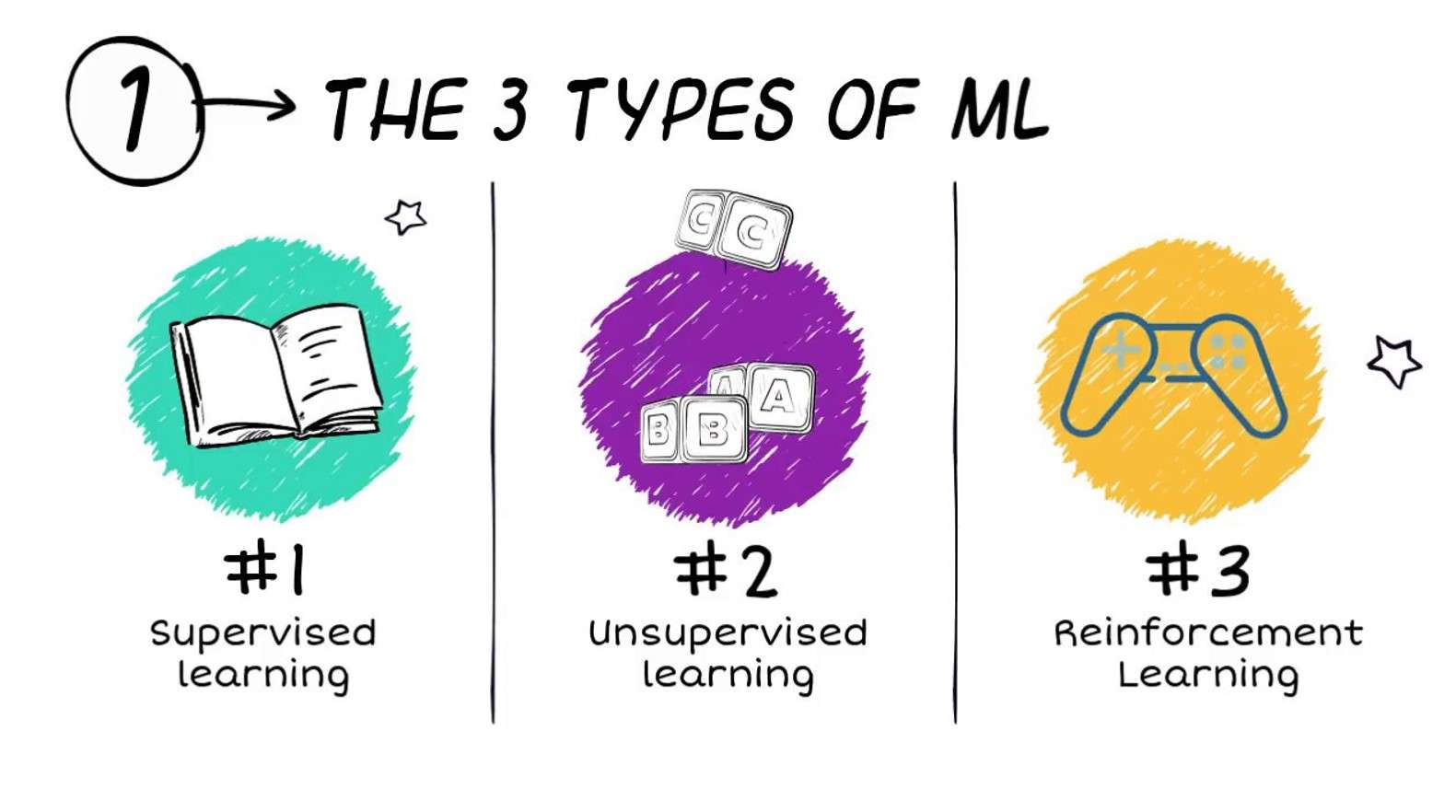
Veiledet læring
Overvåket maskinlæring refererer til teknikker der maskinlæringsmodellen gis en samling av data med eksplisitte etiketter for mengden av interesse (denne mengden blir ofte referert til som responsen eller målet).
For å trene AI-modeller bruker semi-overvåket læring en blanding av merkede og umerkede data.
Hvis du jobber med umerkede data, må du foreta noen datamerking.
Merking er prosessen med å merke prøver for å hjelpe til trene en maskinlæring modell. Merking gjøres først og fremst av mennesker, noe som kan være kostbart og tidkrevende. Det finnes imidlertid teknikker for å automatisere merkeprosessen.
Lånesøknadssituasjonen vi diskuterte før er en utmerket illustrasjon av veiledet læring. Vi hadde historiske data om tidligere lånesøkeres kredittvurderinger (og kanskje inntektsnivåer, alder og så videre) samt spesifikke etiketter som fortalte oss om vedkommende misligholdt lånet eller ikke.
Regresjon og klassifisering er to undergrupper av veiledet læringsteknikker.
- Klassifisering – Den bruker en algoritme for å kategorisere data riktig. Spamfiltre er ett eksempel. "Spam" kan være en subjektiv kategori - grensen mellom spam og ikke-spam kommunikasjon er uskarp - og spamfilteralgoritmen avgrenser seg hele tiden avhengig av tilbakemeldingen din (som betyr e-post som mennesker markerer som spam).
- Regresjon – Det er nyttig for å forstå sammenhengen mellom avhengige og uavhengige variabler. Regresjonsmodeller kan forutsi numeriske verdier basert på flere datakilder, for eksempel salgsinntektsestimater for et bestemt selskap. Lineær regresjon, logistisk regresjon og polynomregresjon er noen fremtredende regresjonsteknikker.
Uovervåket læring
I uovervåket læring får vi umerket data og leter bare etter mønstre. La oss late som du er Amazon. Kan vi finne noen klynger (grupper av lignende forbrukere) basert på kundens kjøpshistorikk?
Selv om vi ikke har eksplisitte, avgjørende data om en persons preferanser, kan vi i dette tilfellet bare vite at et spesifikt sett med forbrukere kjøper sammenlignbare varer, gi oss kjøpsforslag basert på hva andre individer i klyngen også har kjøpt.
Amazons "du kan også være interessert i"-karusell er drevet av lignende teknologier.
Uovervåket læring kan gruppere data gjennom clustering eller assosiasjon, avhengig av hva du ønsker å gruppere sammen.
- Gruppering – Uovervåket læring forsøker å overvinne denne utfordringen ved å søke etter mønstre i dataene. Hvis det er en lignende klynge eller gruppe, vil algoritmen kategorisere dem på en bestemt måte. Å prøve å kategorisere kunder basert på tidligere kjøpshistorikk er et eksempel på dette.
- Association – Uovervåket læring forsøker å takle denne utfordringen ved å prøve å forstå reglene og betydningene som ligger til grunn for ulike grupper. Et hyppig eksempel på et assosiasjonsproblem er å fastslå en kobling mellom kundekjøp. Butikker kan være interessert i å vite hvilke varer som ble kjøpt sammen og kan bruke denne informasjonen til å ordne plasseringen av disse produktene for enkel tilgang.
Forsterkningslæring
Forsterkende læring er en teknikk for å lære maskinlæringsmodeller for å ta en rekke målorienterte beslutninger i en interaktiv setting. Spillbrukstilfellene nevnt ovenfor er utmerkede illustrasjoner på dette.
Du trenger ikke å legge inn AlphaZero tusenvis av tidligere sjakkpartier, hver med et "bra" eller "dårlig" trekk merket. Bare lær det spillets regler og målet, og la det prøve ut tilfeldige handlinger.
Positiv forsterkning gis til aktiviteter som tar programmet nærmere målet (som å utvikle en solid bondeposisjon). Når handlinger har motsatt effekt (som for tidlig skifte av kongen), får de negativ forsterkning.
Programvaren kan til slutt mestre spillet ved å bruke denne metoden.
Forsterkningslæring er mye brukt i robotikk for å lære roboter for kompliserte og vanskelige å konstruere handlinger. Noen ganger brukes det i forbindelse med veiinfrastruktur, for eksempel trafikksignaler, for å forbedre trafikkflyten.
Hva kan gjøres med maskinlæring?
Bruken av maskinlæring i samfunnet og industrien resulterer i fremskritt i et bredt spekter av menneskelige bestrebelser.
I vårt daglige liv styrer maskinlæring nå Googles søke- og bildealgoritmer, slik at vi kan matches mer nøyaktig med informasjonen vi trenger når vi trenger den.
I medisin, for eksempel, brukes maskinlæring på genetiske data for å hjelpe leger å forstå og forutsi hvordan kreft sprer seg, noe som gjør det mulig å utvikle mer effektive terapier.
Data fra verdensrommet samles inn her på jorden via massive radioteleskoper – og etter å ha blitt analysert med maskinlæring hjelper det oss å løse mysteriene til sorte hull.
Maskinlæring i detaljhandel forbinder kjøpere med ting de ønsker å kjøpe på nettet, og hjelper også butikkansatte med å skreddersy tjenesten de yter til kundene sine i den fysiske verden.
Maskinlæring brukes i kampen mot terror og ekstremisme for å forutse oppførselen til de som ønsker å skade de uskyldige.
Natural language processing (NLP) refererer til prosessen med å la datamaskiner forstå og kommunisere med oss på menneskelig språk gjennom maskinlæring, og det har resultert i gjennombrudd innen oversettelsesteknologi så vel som de stemmestyrte enhetene vi i økende grad bruker hver dag, som f.eks. Alexa, Google dot, Siri og Google Assistant.
Uten spørsmål viser maskinlæring at det er en transformasjonsteknologi.
Roboter som er i stand til å jobbe sammen med oss og øke vår egen originalitet og fantasi med sin feilfrie logikk og overmenneskelige hastighet, er ikke lenger en science fiction-fantasi – de er i ferd med å bli en realitet i mange sektorer.
Brukstilfeller for maskinlæring
1. Cybersikkerhet
Etter hvert som nettverk har blitt mer kompliserte, har cybersikkerhetsspesialister jobbet utrettelig for å tilpasse seg det stadig voksende spekteret av sikkerhetstrusler.
Å motvirke raskt utviklende skadelig programvare og hacking-taktikker er utfordrende nok, men spredningen av Internet of Things (IoT)-enheter har fundamentalt transformert cybersikkerhetsmiljøet.
Angrep kan skje når som helst og hvor som helst.
Heldigvis har maskinlæringsalgoritmer aktivert cybersikkerhetsoperasjoner for å holde tritt med denne raske utviklingen.
Prediktiv analyse muliggjør raskere oppdagelse og demping av angrep, mens maskinlæring kan analysere aktiviteten din i et nettverk for å oppdage unormalt og svakheter i eksisterende sikkerhetsmekanismer.
2. Automatisering av kundeservice
Å administrere et økende antall nettbaserte kundekontakter har belastet mye organisasjon.
De har rett og slett ikke nok kundeservicepersonell til å håndtere mengden av henvendelser de mottar, og den tradisjonelle tilnærmingen med å outsource problemer til en kontakt senter er bare uakseptabelt for mange av dagens kunder.
Chatbots og andre automatiserte systemer kan nå møte disse kravene takket være fremskritt innen maskinlæringsteknikker. Bedrifter kan frigjøre personell til å utføre mer kundestøtte på høyt nivå ved å automatisere hverdagslige og lavt prioriterte aktiviteter.
Når den brukes på riktig måte, kan maskinlæring i bedrifter bidra til å strømlinjeforme problemløsning og gi forbrukerne den typen hjelpsom støtte som gjør at de blir engasjerte merkevaremestere.
3. Kommunikasjon
Å unngå feil og misoppfatninger er avgjørende i alle typer kommunikasjon, men mer i dagens forretningskommunikasjon.
Enkle grammatiske feil, feil tone eller feilaktige oversettelser kan forårsake en rekke problemer med e-postkontakt, kundeevalueringer, videokonferanse, eller tekstbasert dokumentasjon i mange former.
Maskinlæringssystemer har avansert kommunikasjon langt utover Microsofts Clippys heftige dager.
Disse maskinlæringseksemplene har hjulpet enkeltpersoner til å kommunisere enkelt og presist ved å bruke naturlig språkbehandling, sanntids språkoversettelse og talegjenkjenning.
Mens mange enkeltpersoner misliker autokorrigeringsfunksjoner, verdsetter de også å være beskyttet mot pinlige feil og upassende tone.
4. Objektgjenkjenning
Mens teknologien for å samle inn og tolke data har eksistert en stund, har det vist seg å være en villedende vanskelig oppgave å lære datasystemer å forstå hva de ser på.
Objektgjenkjenningsfunksjoner blir lagt til et økende antall enheter på grunn av maskinlæringsapplikasjoner.
En selvkjørende bil, for eksempel, gjenkjenner en annen bil når den ser en, selv om programmerere ikke ga den et eksakt eksempel på den bilen som skal brukes som referanse.
Denne teknologien brukes nå i detaljhandel for å hjelpe til med å fremskynde betalingsprosessen. Kameraer identifiserer produktene i forbrukernes handlekurver og kan automatisk fakturere kontoene deres når de forlater butikken.
5. Digital markedsføring
Mye av dagens markedsføring gjøres på nett, ved hjelp av en rekke digitale plattformer og programvare.
Når bedrifter samler inn informasjon om forbrukerne og deres kjøpsatferd, kan markedsføringsteam bruke denne informasjonen til å bygge et detaljert bilde av målgruppen deres og oppdage hvilke personer som er mer tilbøyelige til å oppsøke produktene og tjenestene deres.
Maskinlæringsalgoritmer hjelper markedsførere med å forstå alle disse dataene, og oppdage betydelige mønstre og attributter som lar dem kategorisere muligheter nøye.
Den samme teknologien tillater stor digital markedsføringsautomatisering. Annonsesystemer kan settes opp for å oppdage nye potensielle forbrukere dynamisk og gi relevant markedsføringsinnhold til dem på riktig tid og sted.
Fremtiden for maskinlæring
Maskinlæring er absolutt stadig mer populært ettersom flere bedrifter og store organisasjoner bruker teknologien til å takle spesifikke utfordringer eller drive innovasjon.
Denne fortsatte investeringen demonstrerer en forståelse for at maskinlæring produserer avkastning, spesielt gjennom noen av de ovennevnte etablerte og reproduserbare brukstilfellene.
Tross alt, hvis teknologien er god nok for Netflix, Facebook, Amazon, Google Maps og så videre, er sjansen stor for at den også kan hjelpe bedriften din med å få mest mulig ut av dataene sine.
Som ny maskinlæring modeller utvikles og lanseres, vil vi se en økning i antall applikasjoner som skal brukes på tvers av bransjer.
Dette skjer allerede med ansiktsgjenkjenning, som en gang var en ny funksjon på din iPhone, men som nå implementeres i et bredt spekter av programmer og applikasjoner, spesielt de som er relatert til offentlig sikkerhet.
Nøkkelen for de fleste organisasjoner som prøver å komme i gang med maskinlæring er å se forbi de lyse futuristiske visjonene og oppdage de virkelige forretningsutfordringene som teknologien kan hjelpe deg med.
konklusjonen
I den postindustrialiserte tidsalderen har forskere og fagfolk prøvd å lage en datamaskin som oppfører seg mer som mennesker.
Tenkemaskinen er AIs viktigste bidrag til menneskeheten; den fenomenale ankomsten til denne selvgående maskinen har raskt endret bedriftens driftsforskrifter.
Selvkjørende kjøretøy, automatiserte assistenter, autonome produksjonsansatte og smarte byer har i det siste demonstrert levedyktigheten til smarte maskiner. Maskinlæringsrevolusjonen, og fremtiden for maskinlæring, vil være med oss i lang tid.





Legg igjen en kommentar