Innholdsfortegnelse[Gjemme seg][Forestilling]
Store tekst-til-bilde-modeller gjorde et betydelig fremskritt i utviklingen av AI ved å produsere høykvalitets og diversifisert bildesyntese fra en gitt tekstmelding.
Disse modellene er ikke i stand til å syntetisere unike representasjoner av emner i ulike settinger eller å gjenskape utseendet til emner i et gitt referansesett.
Nyutgitte teknologier som OpenAIs DALL.E2 eller StabilityAIs Stabil diffusjon og Midjourney tar allerede internett med storm. Det er nå på tide å tilpasse resultatene. Men hvordan?
Google DreamBooth AI har kommet.
DreamBooth har evnen til å gjenkjenne emnet for et bilde, dekonstruere det fra dets opprinnelige kontekst, og deretter presist syntetisere det til en ny ønsket kontekst. I tillegg kan den brukes med nåværende AI-bildegeneratorer.
I denne artikkelen skal vi ta en dyp titt på DreamBooth, bruken, opplæringen, begrensningene og mye mer.
Hva er Dreambooth?
drømmebod, en splitter ny tekst-til-bilde-spredningsmodell, ble presentert av Google. En skriftlig melding kan brukes som veiledning av Google DreamBooth AI for å generere et bredt spekter av bilder av brukerens valgte motiv i forskjellige innstillinger.
En forskergruppe fra Boston University og Google utviklet DreamBooth, en banebrytende teknikk for å endre tekst-til-bilde-modeller som har gjennomgått omfattende forhåndsopplæring.
Det overordnede konseptet er ganske enkelt: de ønsker å øke språkvisjonsordboken slik at uvanlige token-ID-er assosieres med tilpassede emner som brukere kan definere.
Hovedmålet med modellen er å koble brukere til tekst-til-bilde spredningsmodell ved å gi dem ressursene de trenger for å produsere fotorealistiske representasjoner av forekomstene av det valgte emnet.
Som en konsekvens ser denne teknikken ut til å fungere godt for å oppsummere utfordringer i en rekke situasjoner.
Googles DreamBooth skiller seg fra tidligere tekst-til-bilde-verktøy, som f.eks DALL-E2, Stabil diffusjonog midt på reisen, ved at det gir brukerne mer kontroll over emnebildet før de lar dem manipulere diffusjonsmodellen ved hjelp av tekstbaserte input.
Egenskaper
- DreamBooth AI kan forbedre en tekst-til-bilde-modell med 3-5 bilder.
- Originale fotorealistiske bilder kan lages med DreamBooth AI.
- I tillegg kan DreamBooth AI lage bilder av et emne fra flere vinkler.
Søknad
Kunstgjengivelser
Denne oppgaven skiller seg spesifikt fra stiloverføring, som beholder semantikken til kildescenen mens stilen til et annet bilde integreres i den originale scenen.

Basert på den kreative tilnærmingen, kan AI utføre betydelige sceneendringer samtidig som identifikasjonen og emneforekomsten opprettholdes.
Eiendomsendring
Emneforekomstens egenskaper kan modifiseres av DreamBooth AI.

Tilbehør
Den sterke komposisjonen før generasjonsmodellen er det som gjør DreamBooth AIs evne til å pryde objekter så interessant.

Rekontekstualisering
DreamBooth AI kan produsere karakteristiske bilder for en bestemt emneforekomst ved å gi en trent modell en setning som inkluderer den unike identifikatoren og klassesubstantivet.

Det kan generere motivet i unike, tidligere uhørte stillinger, artikulasjoner og scenestruktur i stedet for å endre omgivelsene. Realistiske refleksjoner og skygger, samt interaksjoner mellom motivet og omkringliggende objekter.
Dreambooth opplæring
I denne opplæringen vil vi følge Google Collab-notatbok, og jeg vil lede deg gjennom det, som vil få deg til å forstå og bruke det på egen hånd.
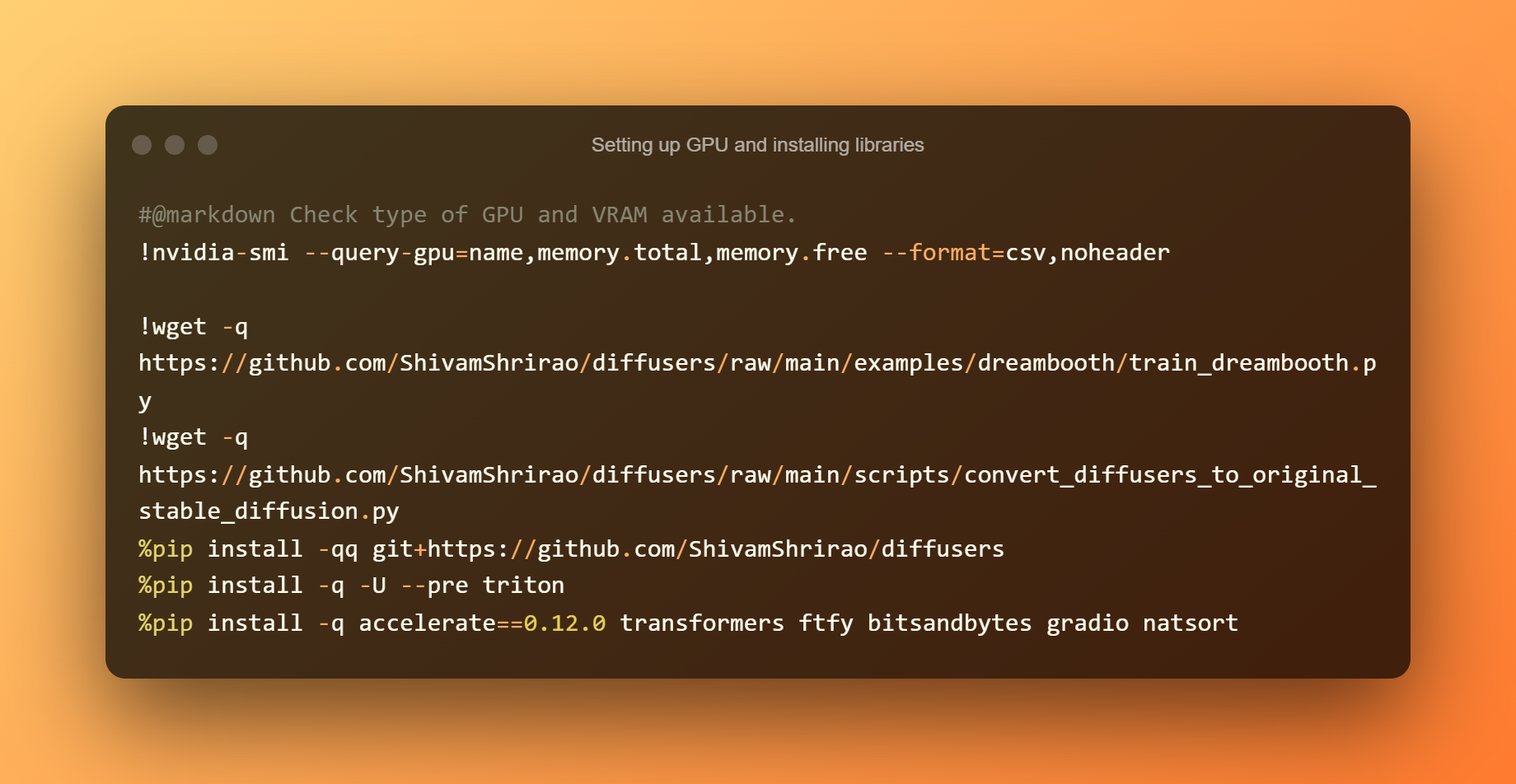
Sette opp GPU og installere biblioteker
Å finne ut hvilke GPU- og VRAM-typer som er tilgjengelige er det første trinnet. Det er også nødvendig å installere noen få krav og avhengigheter. Bare trykk på avspillingsknappen, og vent til den er ferdig.
Opprett en konto på Huggingface og generer et token
Det neste trinnet er å registrere deg for en Huggingface-konto. Når du er ferdig, klikker du på innstillinger øverst til høyre. Du kommer på neste side.
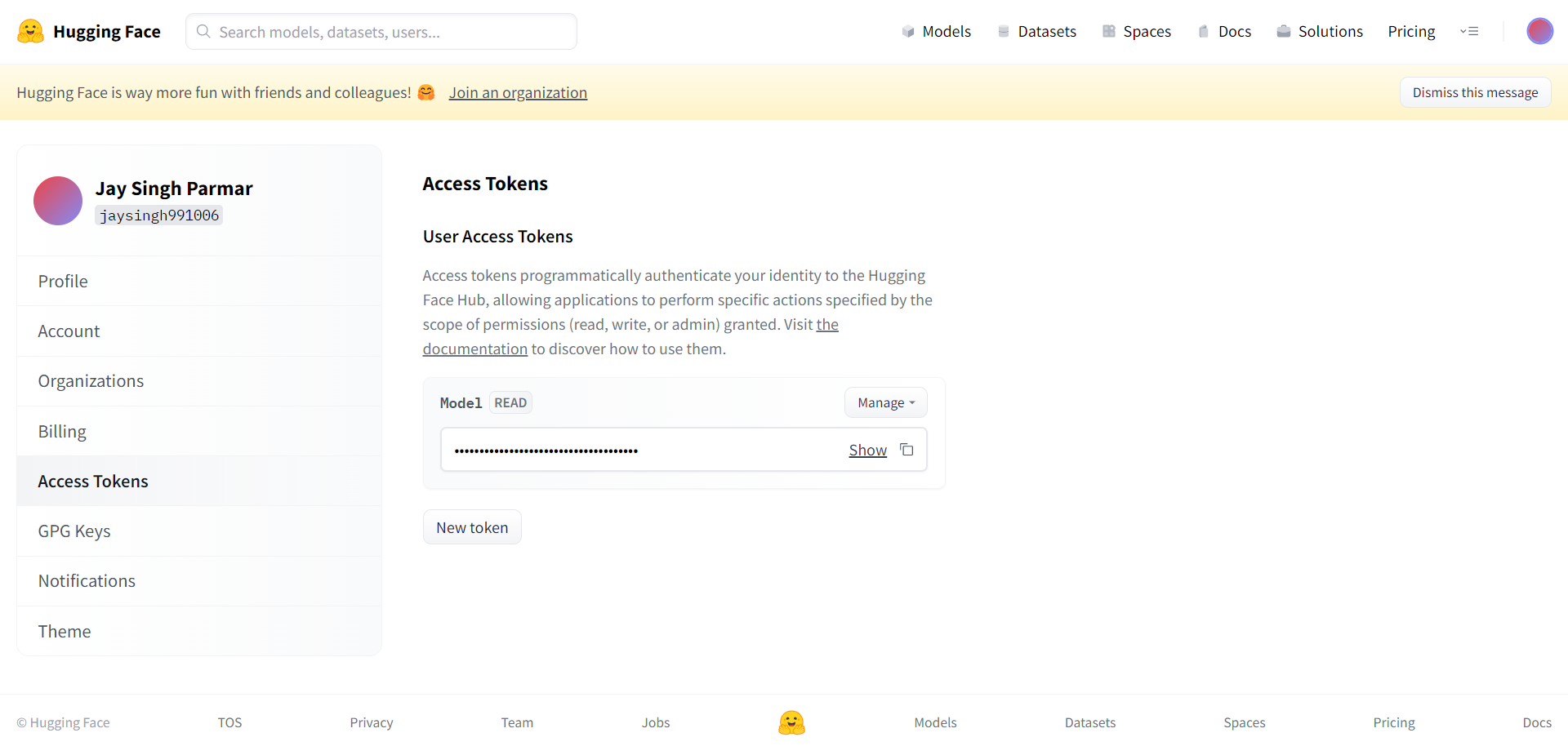
Opprett token og navn som forespurt herfra. Tokenet skal kopieres og limes inn i Google-samarbeidet i cellen nedenfor.

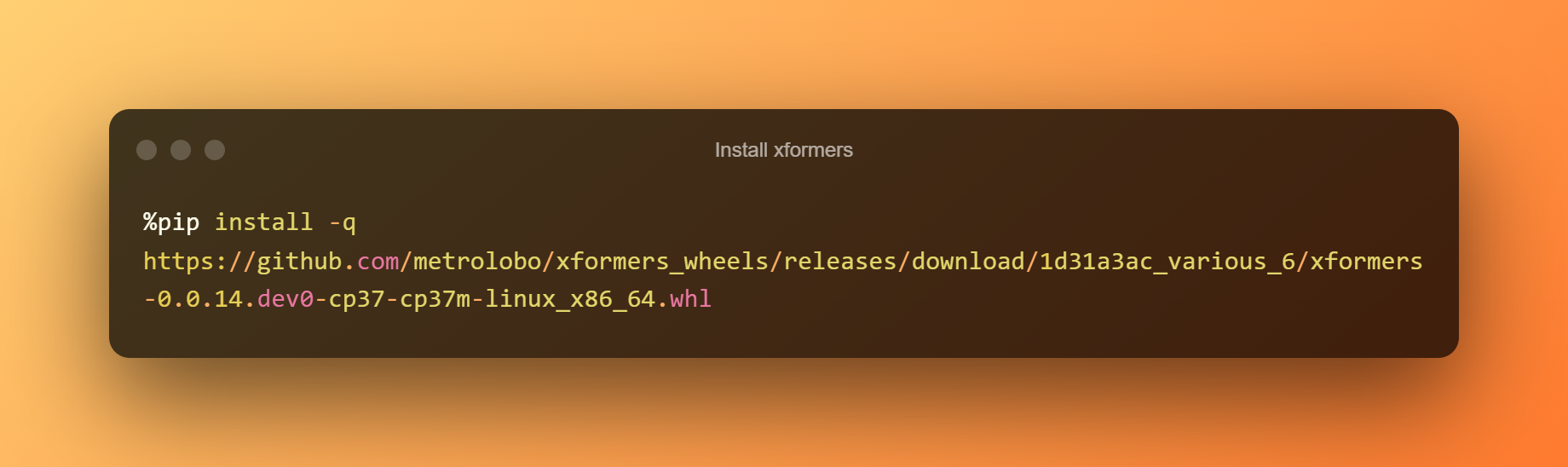
Installer xformers
I dette stadiet kan du ganske enkelt trykke på avspillingsknappen for å installere xformers ved å klikke på kjøretiden.
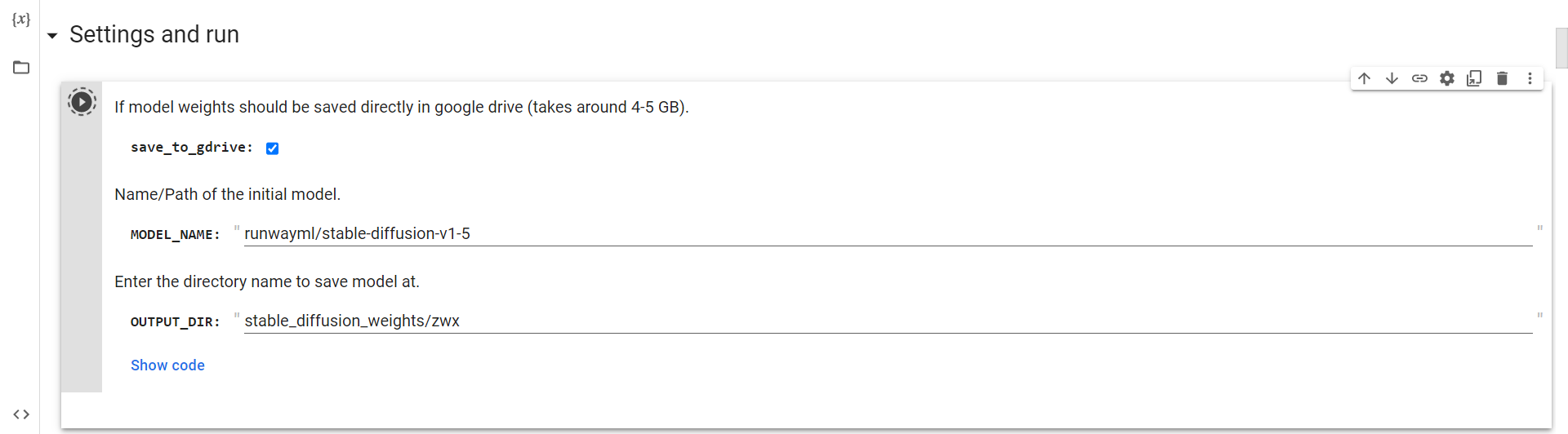
Koble til Disk
Nå må du bare kjøre denne cellen for å koble til Google Drive.
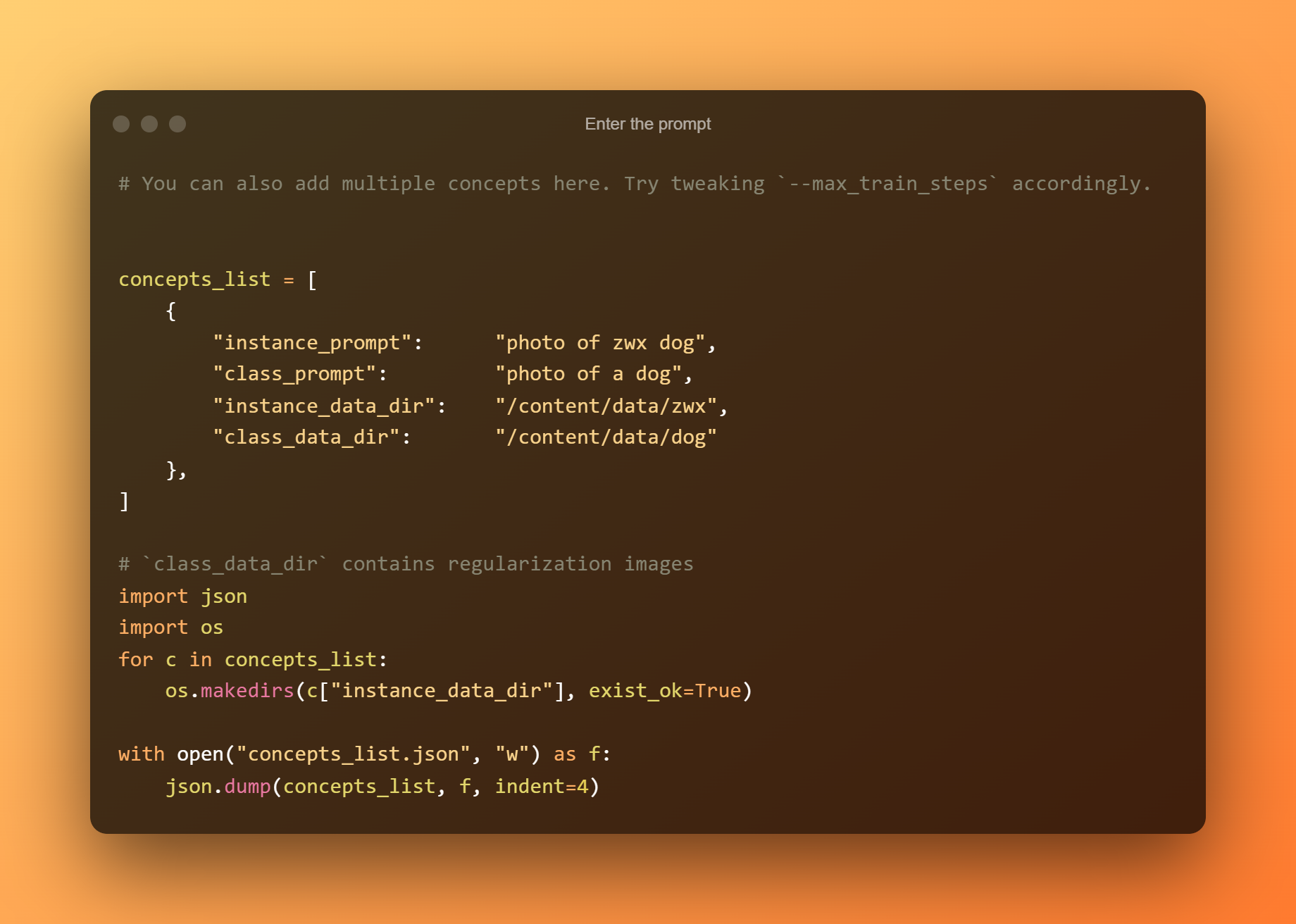
Skriv inn ledeteksten
I den følgende cellen må du bare skrive inn ledeteksten.
Laster opp bilder
I dette trinnet må du bare laste opp bildene du ville trene.

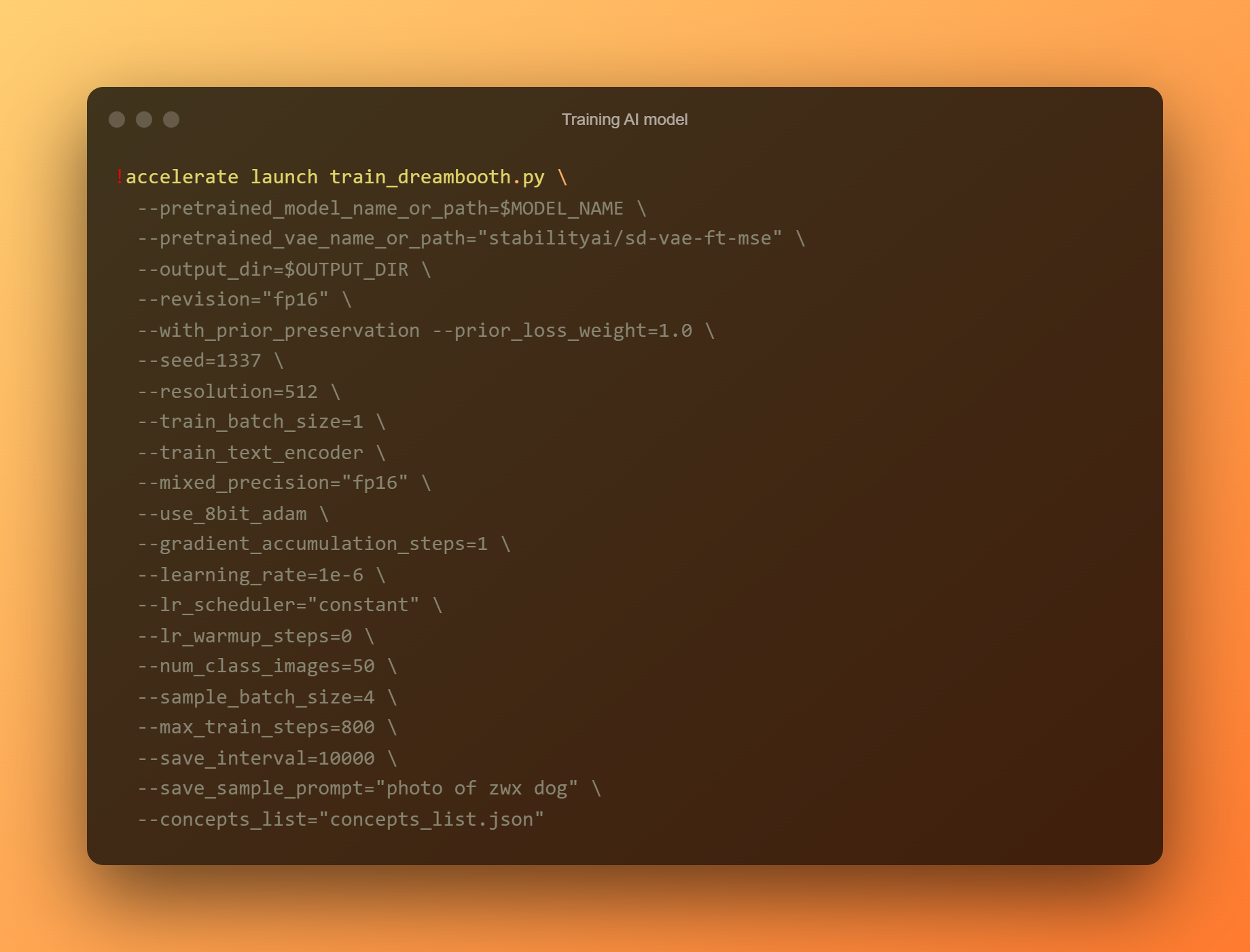
Tren AI-modell
Dette er den viktigste fasen, siden du vil bruke DreamBooth til å trene en ny AI-modell basert på alle dine innsendte referansebilder. Du må begrense oppmerksomheten til to inndatafelt. "—instance prompt" er den første parameteren. Du må oppgi et svært distinkt navn her.
Argumentet '–konseptliste' er det andre kritiske inndatafeltet. Den må gis nytt navn for å matche den som ble brukt i delen "Endre ledeteksten".
Generer AI-bilder
AI-bildene vil bli laget på dette stadiet, hvor du kan legge inn tekstinstruksjonene.

Dreambooth-begrensninger
- Ledeteksten blir en barriere for å gjøre iterasjoner i emnet med høye detaljeringsgrader. DreamBooth kan endre emnets kontekst, men hvis modellen ønsker å endre emnet selv, er det problemer med rammen.
- Et annet problem er å overtilpasse utgangsbildet til inngangsbildet. Hvis det ikke er nok bilder levert, kan det hende at emnet ikke vurderes eller kan blandes med konteksten til de innsendte bildene. Når det spørs om en kontekst for en odde generasjon, skjer det samme.
konklusjonen
For å produsere utdata fra én enkelt tekstinndata, krever hoveddelen av tekst-til-bilde-modeller millioner av parametere og biblioteker.
DreamBooth forenkler innhenting og bruk av innhold for forbrukere ved å kreve bare innspill fra tre til fem emnefotografier sammen med en tekstlig bakgrunn.





Legg igjen en kommentar