Hva om vi kunne bruke kunstig intelligens til å svare på et av livets største mysterier – proteinfolding? Forskere har jobbet med dette i flere tiår.
Maskiner kan nå forutsi proteinstrukturer med utrolig presisjon ved å bruke dyplæringsmodeller, endre medikamentutvikling, bioteknologi og vår kunnskap om grunnleggende biologiske prosesser.
Bli med meg på en utforskning inn i det spennende riket av AI-proteinfolding, der banebrytende teknologi kolliderer med selve livets kompleksitet.
Avdekke mysteriet med proteinfolding
Proteiner fungerer i kroppen vår som små maskiner for å utføre viktige oppgaver som å bryte ned mat eller transportere oksygen. De må brettes riktig for at de skal fungere effektivt, akkurat som en nøkkel må kuttes riktig for å passe inn i en lås. Så snart proteinet er opprettet, starter en veldig komplisert foldeprosess.
Proteinfolding er prosessen der lange kjeder av aminosyrer, proteinets byggesteiner, foldes til tredimensjonale strukturer som dikterer funksjonen til proteinet.
Tenk på en lang perlestreng som må bestilles i en presis form; dette er hva som skjer når et protein folder seg. Likevel, i motsetning til perler, har aminosyrer unike egenskaper og interagerer med hverandre på forskjellige måter, noe som gjør proteinfolding til en kompleks og følsom prosess.
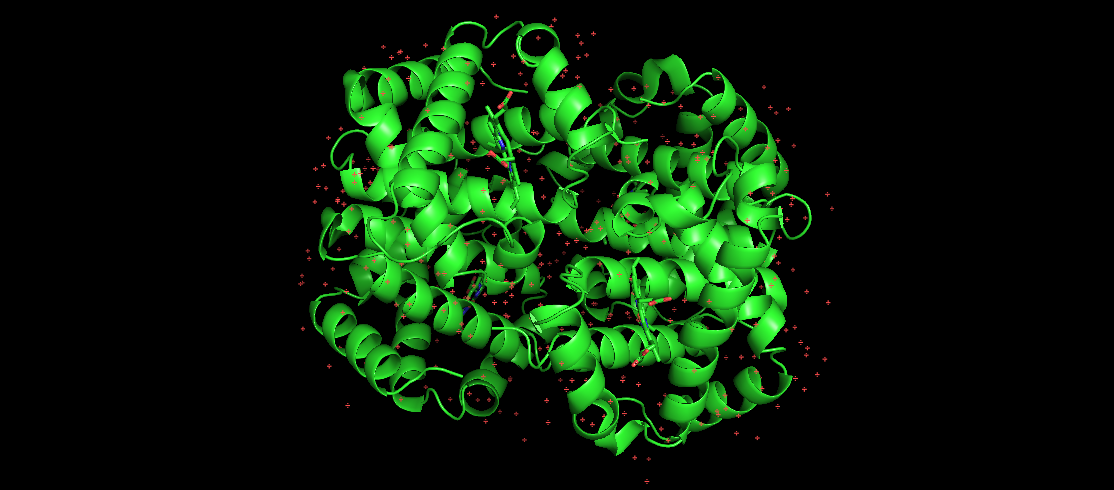
Bildet her representerer humant hemoglobin, som er et velkjent foldet protein
Proteiner må foldes raskt og presist, ellers vil de bli feilfoldet og defekte. Det kan føre til sykdommer som Alzheimers og Parkinsons. Temperatur, trykk og tilstedeværelsen av andre molekyler i cellen har alle en effekt på foldeprosessen.
Etter flere tiår med forskning prøver forskere fortsatt å finne ut nøyaktig hvordan proteiner folder seg.
Heldigvis forbedrer fremskritt innen kunstig intelligens utviklingen i sektoren. Forskere kan forutse strukturen til proteiner mer nøyaktig enn noen gang før ved å bruke maskinlæringsalgoritmer å undersøke enorme mengder data.
Dette har potensial til å endre medisinutvikling og øke vår molekylære kunnskap om sykdommen.
Kan maskiner yte bedre?
Konvensjonelle proteinfoldeteknikker har begrensninger
Forskere har prøvd å finne ut proteinfolding i flere tiår, men prosessens intrikate har gjort dette til et utfordrende emne.
Konvensjonelle metoder for prediksjon av proteinstrukturer bruker en kombinasjon av eksperimentelle metoder og datamodellering, men disse metodene har alle ulemper.
Eksperimentelle teknikker som røntgenkrystallografi og kjernemagnetisk resonans (NMR) kan være tidkrevende og kostbare. Og datamodeller er noen ganger avhengige av enkle antagelser, noe som kan føre til feilaktige spådommer.
AI kan overvinne disse hindringene
Heldigvis, kunstig intelligens gir nytt løfte om mer nøyaktig og effektiv prediksjon av proteinstruktur. Maskinlæringsalgoritmer kan undersøke enorme mengder data. Og de avdekker mønstre som folk ville savne.
Dette har resultert i etableringen av nye programvareverktøy og plattformer som er i stand til å forutsi proteinstruktur med uovertruffen presisjon.
De mest lovende maskinlæringsalgoritmene for prediksjon av proteinstruktur
AlphaFold-systemet bygget av Google DeepMind teamet er en av de mest lovende fremskritt på dette området. Den har fått stor fremgang de siste årene ved å bruke dyp læringsalgoritmer å forutsi strukturen til proteiner basert på deres aminosyresekvenser.
Nevrale nettverk, støttevektormaskiner og tilfeldige skoger er blant flere maskinlæringsmetoder som viser løfte for å forutsi proteinstruktur.
Disse algoritmene kan lære av enorme datasett. Og de kan forutse korrelasjonene mellom forskjellige aminosyrer. Så, la oss se hvordan det fungerer.

Ko-evolusjonære analyser og den første AlphaFold-generasjonen
Suksessen til AlphaFold er bygget på en dyp nevrale nettverksmodell som ble utviklet ved bruk av co-evolusjonær analyse. Konseptet med samevolusjon sier at hvis to aminosyrer i et protein samhandler med hverandre, vil de utvikle seg sammen for å beholde sin funksjonelle kobling.
Forskere kan oppdage hvilke par av aminosyrer som sannsynligvis vil være i kontakt i 3D-strukturen ved å sammenligne aminosyresekvensene til mange lignende proteiner.
Disse dataene fungerer som grunnlaget for den første iterasjonen av AlphaFold. Den forutsier lengdene mellom aminosyreparene så vel som vinklene til peptidbindingene som forbinder dem. Denne metoden overgikk alle tidligere tilnærminger for å forutsi proteinstruktur fra sekvens, selv om nøyaktigheten fortsatt var begrenset for proteiner uten tilsynelatende maler.

AlphaFold 2: En radikalt ny metodikk
AlphaFold2 er en dataprogramvare laget av DeepMind som bruker et proteins aminosyresekvens for å forutsi 3D-strukturen til proteinet.
Dette er viktig fordi et proteins struktur dikterer hvordan det fungerer, og forståelse av funksjonen kan hjelpe forskere med å utvikle medisiner som retter seg mot proteinet.
Det nevrale nettverket AlphaFold2 mottar som input proteinets aminosyresekvens samt detaljer om hvordan den sekvensen sammenlignes med andre sekvenser i en database (dette kalles en "sekvensjustering").
Det nevrale nettverket gir en prediksjon om proteinets 3D-struktur basert på denne inngangen.
Hva skiller det fra AlphaFold2?
I motsetning til andre tilnærminger, forutsier AlphaFold2 den virkelige 3D-strukturen til proteinet i stedet for bare separasjonen mellom par av aminosyrer eller vinklene mellom bindingene som forbinder dem (som tidligere algoritmer gjorde).
For at det nevrale nettverket skal forutse hele strukturen på en gang, er strukturen kodet ende-til-ende.
En annen viktig egenskap ved AlphaFold2 er at den gir et estimat på hvor sikker den er i prognosen. Dette presenteres som en fargekoding på den forventede strukturen, der rødt representerer høy konfidens og blått antyder lav konfidens.
Dette er nyttig siden det informerer forskere om stabiliteten til spådommen.
Forutsi den kombinerte strukturen av flere sekvenser
Den siste utvidelsen av Alphafold2, kjent som Alphafold Multimer, forutser den kombinerte strukturen til flere sekvenser. Den har fortsatt høye feilrater selv om den yter langt bedre enn tidligere teknikker. Bare %25 av 4500 proteinkomplekser ble forutsagt.
70 % av de grove områdene for kontaktdannelse ble korrekt forutsagt, men den relative orienteringen til de to proteinene var feil. Når medianjusteringsdybden er mindre enn omtrent 30 sekvenser, synker nøyaktigheten av Alphafold multimer-prediksjoner betydelig.
Slik bruker du Alphafold-spådommer
De predikerte modellene fra AlphaFold tilbys i de samme filformatene og kan brukes på samme måte som eksperimentelle strukturer. Det er avgjørende å ta hensyn til nøyaktighetsestimatene som tilbys med modellen for å forhindre misforståelser.
Det er spesielt nyttig for kompliserte strukturer som sammenvevde homomerer eller proteiner som bare foldes i nærvær av en
ukjent ligand.
Noen utfordringer
Hovedproblemet med å bruke predikerte strukturer er å forstå dynamikken, ligandselektiviteten, kontrollen, allosteri, post-translasjonelle endringer og kinetikk for binding uten tilgang til protein og biofysiske data.
Maskinlæring og fysikkbasert molekylær dynamikkforskning kan brukes til å overvinne dette problemet.
Disse undersøkelsene kan dra nytte av spesialisert og effektiv dataarkitektur. Mens AlphaFold har oppnådd enorme fremskritt når det gjelder å forutsi proteinstrukturer, er det fortsatt mye å lære innen strukturell biologi, og AlphaFold-spådommer er bare utgangspunktet for fremtidige studier.
Hva er andre bemerkelsesverdige verktøy?
RoseTTAFold
RoseTTAFold, opprettet av forskere fra University of Washington, bruker også dyplæringsalgoritmer for å forutsi proteinstrukturer, men den integrerer også en ny tilnærming kjent som "torsjonsvinkeldynamikksimuleringer" for å forbedre de forutsagte strukturene.
Denne metoden har gitt oppmuntrende resultater og kan være nyttig for å overvinne begrensningene til eksisterende AI-proteinfoldingsverktøy.
trRosetta
Et annet verktøy, trRosetta, forutsier proteinfolding ved å bruke en nevrale nettverket trent på millioner av proteinsekvenser og strukturer.
Den bruker også en "malbasert modellering"-teknikk for å lage mer presise spådommer ved å sammenligne målproteinet med sammenlignbare kjente strukturer.
Det har blitt demonstrert at trRosetta er i stand til å forutsi strukturene til små proteiner og proteinkomplekser.
DeepMetaPSICOV
DeepMetaPSICOV er et annet verktøy som fokuserer på å forutsi proteinkontaktkart. Disse brukes som en guide for å forutsi proteinfolding. Det bruker dyp læring tilnærminger for å forutsi sannsynligheten for restinteraksjoner inne i et protein.
Disse brukes deretter til å forutsi det overordnede kontaktkartet. DeepMetaPSICOV har vist potensial i å forutsi proteinstrukturer med stor nøyaktighet, selv når tidligere tilnærminger har mislyktes.
Hva holder fremtiden?
Fremtiden for AI-proteinfolding er lys. Dyplæringsbaserte algoritmer, spesielt AlphaFold2, har nylig gjort store fremskritt når det gjelder pålitelig forutsigelse av proteinstrukturer.
Dette funnet har potensial til å transformere medikamentutvikling ved å la forskere forstå strukturen og funksjonen til proteiner, som er vanlige terapeutiske mål.
Ikke desto mindre gjenstår problemer som å forutsi proteinkomplekser og oppdage den reelle funksjonelle statusen til forventede strukturer. Mer forskning er nødvendig for å løse disse problemene og øke nøyaktigheten og påliteligheten til AI-proteinfoldingsalgoritmer.
Likevel er de potensielle fordelene med denne teknologien enorme, og den har potensial til å føre til produksjon av mer effektive og presise medisiner.





Legg igjen en kommentar